Lakeflow: una nuova era di data engineering agentico
La fondazione dati unificata e in tempo reale su cui la tua azienda può fare affidamento
di Bilal Aslam, Ray Zhu, Manish Dalwadi, Saad Ansari e Giselle Goicochea
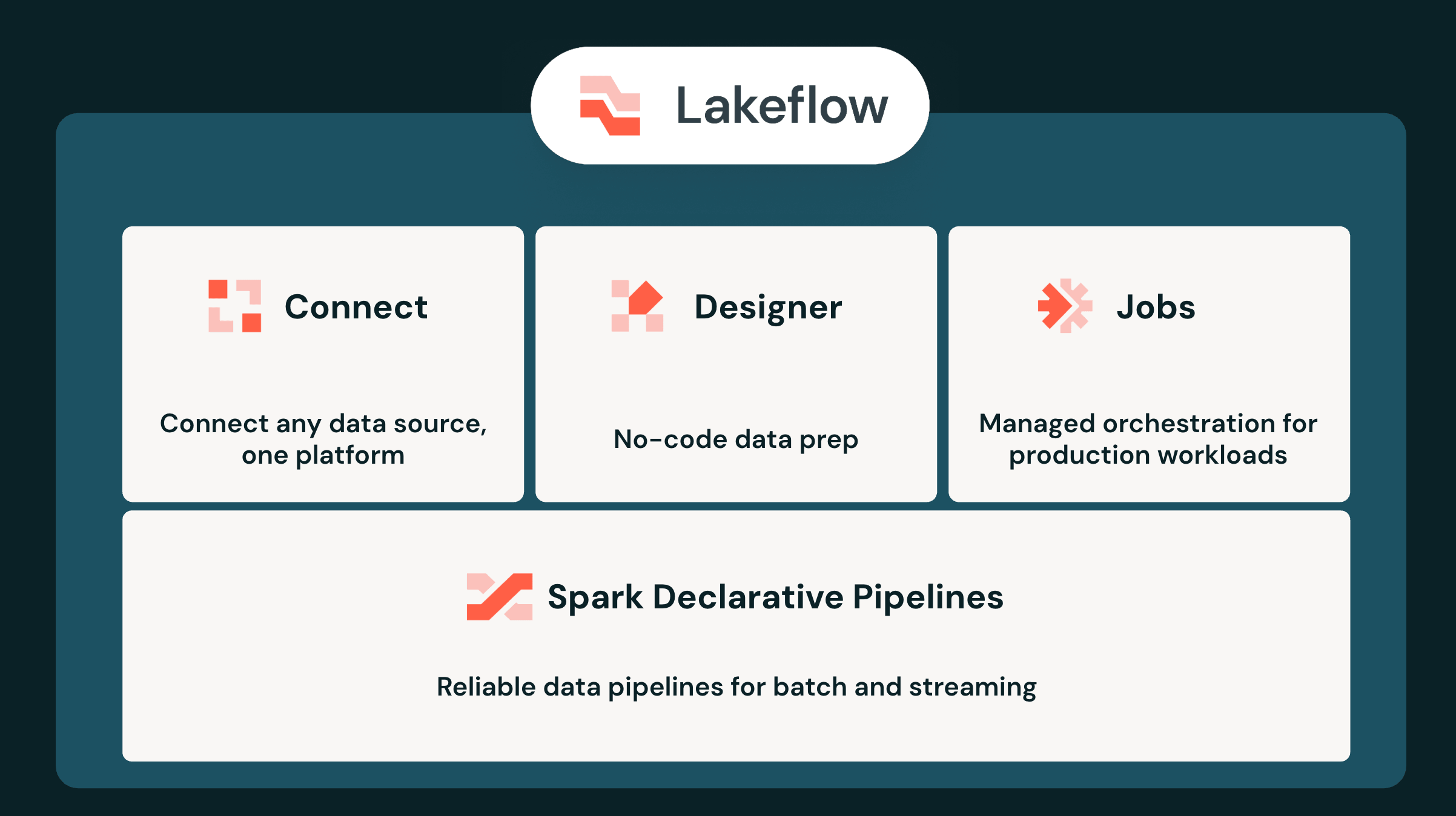
- Fondazione unificata per l'AI agentica: Lakeflow unifica ingestione, trasformazione e orchestrazione sotto Unity Catalog, eliminando il divario causato dalla frammentazione degli strumenti e offrendo agli agenti AI un'unica fonte di contesto attendibile e in tempo reale.
- Ingestione e streaming ad alte prestazioni: connettiti a oltre 100 origini dati aziendali con Lakeflow Connect, trasmetti dati di eventi ad alto volume tramite interfacce multiple su Zerobus Ingest e ottieni una latenza nell'ordine dei millisecondi con la Real-Time Mode per le pipeline dichiarative Spark.
- Sviluppo e operazioni agentici: crea pipeline in modo visivo con Lakeflow Designer, accelera la scrittura del codice con Genie Code, riduci il carico operativo con Genie ZeroOps e consolida gli orchestratori legacy con Lakeflow Jobs.
Tutte le attività di analytics, AI e applicazioni partono dai dati. Negli ultimi decenni, gli strumenti di data engineering si sono moltiplicati per coprire una vasta gamma di casi d'uso e profili utente. Di conseguenza, la maggior parte delle aziende si ritrova con uno stack di dati molto complesso e frammentato, difficile da integrare, gestire o governare. Con l'AI che supporta tutti i dati e i professionisti dell'AI, questi stack di dati così fragili saranno sottoposti a una pressione ancora maggiore.
Ecco perché abbiamo deciso di creare Databricks Lakeflow, una piattaforma unificata per tutto il data engineering, dall'ingestione alla trasformazione e all'orchestrazione. Tutte le funzionalità di Lakeflow sono completamente integrate e governate a livello centrale da Unity Catalog. Nell'era degli agenti, questa architettura unificata offre vantaggi significativi, consentendo agli agenti non solo di creare, ma anche di gestire le pipeline di dati. Oggi, al Data + AI Summit, annunciamo la prossima grande evoluzione di Databricks Lakeflow.
Genie Code e Lakeflow Designer: sviluppo di pipeline basato su agenti
Genie Code è ora profondamente integrato in ogni aspetto dell'esperienza utente di Lakeflow. Puoi usare Genie Code per creare connettori di ingestione, creare pipeline in Python e SQL e sviluppare job con task, trigger e dipendenze. Tutto questo è reso possibile dallo stack di data engineering unificato, che fornisce a Genie Code un contesto end-to-end completo per tutti i carichi di lavoro di ingestione, trasformazione e orchestrazione.
Ora generalmente disponibile, Lakeflow Designer democratizza il data engineering in tutta l'azienda. Questa interfaccia visiva, no-code e basata sull'AI consente ai team di creare pipeline utilizzando un'area di lavoro drag-and-drop e prompt in linguaggio naturale. Gli analisti aziendali e gli utenti non tecnici possono creare pipeline ETL pronte per la produzione senza scrivere codice. Ogni Flow visivo creato in Designer viene eseguito nativamente su una Spark Declarative Pipeline pronta per la produzione, garantendo zero perdite di traduzione senza passaggi di consegne complessi. I data engineer possono facilmente esaminare e perfezionare questo codice direttamente sul posto, senza cambiare contesto o riscrivere la logica.
Genie ZeroOps: metti il pilota automatico alle operazioni sui dati e sull'AI
Annunciato oggi, Genie ZeroOps aiuta i team di dati a gestire gli asset di dati e AI in produzione. Genie ZeroOps è un agente AI in background appositamente progettato che monitora e gestisce gli asset di dati e AI. ZeroOps rileva i guasti ed esegue l'analisi delle cause principali per identificare cosa è andato storto, utilizzando metriche sulla qualità dei dati, log degli errori e dati di lineage da Unity Catalog. Inoltre, genera proposte di correzione e le convalida in un ambiente sandbox sicuro e isolato governato da Unity Catalog. L'applicazione di una correzione avviene con un approccio human-in-the-loop, quindi Genie ZeroOps si occupa del lavoro più pesante, lasciando a te il controllo. Similmente allo sviluppo basato su agenti, la funzionalità di Genie ZeroOps è possibile solo grazie alla completa consapevolezza del contesto e alla governance end-to-end abilitate da uno stack di dati unificato con Lakeflow.
Lakeflow Connect: un ecosistema in rapida crescita con oltre 100 connettori integrati
Il valore delle pipeline automatizzate dipende interamente dai dati che vi scorrono all'interno. Per creare una "memoria aziendale" completa e fornire una base di conoscenza agli agenti AI come Databricks Genie, hai bisogno di un accesso continuo al contesto governato più recente, che copra ogni area della tua attività. Lakeflow Connect semplifica questo processo importando in modo incrementale nuovi dati da un elenco in continua crescita di sistemi aziendali direttamente nelle tabelle Delta governate da Unity Catalog.
Oggi annunciamo che Lakeflow Connect si sta espandendo per supportare più di 100 connettori nativi e gestiti tra applicazioni aziendali, database, sorgenti di file e cloud storage. Ora puoi eliminare i fragili strumenti di terze parti ed eseguire pipeline di ingestione ottimizzate per i casi d'uso di cui i clienti hanno più bisogno:
- Enterprise Knowledge Management: unifica i dati aziendali provenienti da Jira (Beta), GitHub (Beta) e Confluence (GA) insieme a documenti non strutturati, contratti e PDF da SharePoint (GA), Google Drive (Beta) e Outlook (Beta). Alimenta applicazioni AI sensibili al contesto, agenti di supporto e l'elaborazione intelligente dei documenti su un'unica base.
- MarTech: acquisisci i dati delle campagne e dei clienti direttamente da Meta Ads (Beta), TikTok Ads (Beta), Google Ads (Beta) e HubSpot (GA) per offrire una personalizzazione in tempo reale.
- IT & Security Operations: centralizza i log e la telemetria per una solida analisi SIEM.
- Query-based capture per tutti i connettori di database e le sorgenti di Lakehouse Federation (GA): interroga direttamente il database per l'acquisizione delle modifiche senza la necessità di analizzare i log (log parsing).
Per le organizzazioni con sistemi specializzati o proprietari, i Community Connectors (Beta) offrono una soluzione open source basata su Databricks. Distribuisci un connettore predefinito della community o creane uno tuo da condividere all'interno della tua organizzazione o con l'ecosistema più ampio.
Panasonic ha utilizzato Lakeflow Connect per unificare i dati provenienti da SAP, Workday e SharePoint, sostituendo i fragili ETL legacy con un'unica piattaforma per un'intelligence governata e in tempo reale.
“Passando da uno stack ETL legacy rigido alla piattaforma Databricks, i nostri team di BI possono ora individuare e accedere facilmente ai dati critici, riducendo i tempi di aggiornamento di Power BI del 50%. Stiamo trasformando dati esterni e incoerenti in asset affidabili e pronti per la produzione, che sbloccano nuove intuizioni di business e rafforzano il vantaggio competitivo di Panasonic.”—Jerry Deng, BI Director, Panasonic
Stiamo anche rendendo più facile per le organizzazioni ridurre in modo permanente il TCO dell'ingestione di grandi volumi di dati con il piano gratuito (Free Tier) di Lakeflow Connect. I clienti ricevono automaticamente 100 DBU gratuiti al giorno, supportando fino a 100 milioni di record giornalieri sui connettori SaaS e database gestiti più diffusi.
Zerobus Ingest: ingestione senza Kafka per i tuoi produttori di dati
Zerobus Ingest sta cambiando il modo in cui le organizzazioni gestiscono grandi volumi di dati sugli eventi, senza la necessità di un message bus. Con scritture quasi in tempo reale in meno di 5 secondi e un throughput elevato fino a 100 MB/s (oltre 10 GB/s per tabella), Zerobus distribuisce i dati direttamente sulla tua piattaforma su scala.
Tuttavia, le prestazioni contano solo se i tuoi produttori possono connettersi senza attriti. Una migrazione dovrebbe essere semplice come una modifica della configurazione. Da quando ha raggiunto la General Availability all'inizio di quest'anno, Zerobus si è espanso per andare incontro ai tuoi produttori di dati ovunque operino:
- API compatibili con Kafka (Beta): i tuoi produttori Kafka esistenti inviano i dati direttamente a Databricks, senza richiedere modifiche al codice.
- API gRPC e REST (GA): stream gRPC persistenti per applicazioni ad alte prestazioni o API REST stateless per webhook e funzioni serverless.
- Ecosistema SDK (GA): gli SDK pronti per la produzione per Python, Java, Rust, Go e TypeScript semplificano l'integrazione diretta di Zerobus nelle tue applicazioni personalizzate.
- OpenTelemetry (Public Preview): invia metriche, tracce e log direttamente al lakehouse con una semplice modifica della configurazione.
Questa flessibilità multi-interfaccia fornisce un ponte diretto e a bassa latenza verso il cloud per le aziende globali. Ad esempio, Meta utilizza Zerobus Ingest per collegare i suoi data center on-premise al cloud, consentendo lo sviluppo rapido di soluzioni basate sui dati su scala.
“Abbiamo ridotto la latenza della nostra pipeline end-to-end a meno di un minuto con Zerobus Ingest e Spark Declarative Pipelines, accelerando il time-to-value.”—Srikanth Sakhamuri, Data Engineering Leader, Meta
Una volta che i dati arrivano nelle tabelle Delta gestite da Unity Catalog, sono immediatamente accessibili agli strumenti di AI e BI a valle, come Databricks Genie. Come parte di uno stack analitico in tempo reale end-to-end, Zerobus acquisisce i dati e li elabora utilizzando la Real-Time Mode in Apache Spark™Declarative Pipelines (SDP), li trasforma e Lakehouse//RT, un nuovo tipo di data warehouse basato su un motore nativo in tempo reale, li distribuisce con prestazioni nell'ordine dei millisecondi.
Spark Declarative Pipelines: Batch e streaming, SQL e Python, e ora in tempo reale
Ottenere uno streaming a latenza ultra-bassa ha tradizionalmente costretto i team di dati a gestire architetture complesse e frammentate, che spesso richiedevano la manutenzione di un secondo motore specializzato, come Apache Flink, affiancato a Spark. Databricks ha inizialmente risolto la complessità del doppio motore introducendo la Real-Time Mode (RTM) per Spark Structured Streaming. Passando dal micro-batching periodico all'elaborazione continua dei flussi (stream processing), la RTM attualmente alimenta le pipeline di marchi globali tra cui Coinbase, DraftKings e MakeMyTrip.
Ora stiamo portando la stessa potenza nel nostro prodotto ETL unificato: la Real-Time Mode (RTM) per Spark Declarative Pipelines è ora in Public Preview. La RTM per SDP consente di raggiungere latenze end-to-end fino a un minimo di 5 millisecondi, senza la complessità e i costi di gestione di motori separati. Disponibile sia su risorse di calcolo classiche che serverless, offre uno streaming a latenza ultra-bassa insieme ai vantaggi operativi di Spark Declarative Pipelines: esecuzione senza versioni, aggiornamenti automatici dell'infrastruttura e manutenzione con tempi di inattività minimi o nulli.
Inoltre, stiamo rendendo disponibili ovunque sulla piattaforma Databricks le API dichiarative di Spark Declarative Pipelines, tra cui Append, Auto CDC, incremental Replace Where e Materialized View. Ciò significa che gli utenti possono sfruttare l'elaborazione incrementale dei dati direttamente dal prodotto, dal tipo di calcolo e dall'interfaccia utente che già conoscono. Tutte queste API sono ora disponibili in Databricks SQL e saranno disponibili nei Notebook serverless e in Lakeflow Designer nelle prossime settimane.
Lakeflow Jobs: ora con oltre 50 integrazioni
L'orchestrazione non dovrebbe essere la parte più complessa della gestione della pipeline di dati. Che si tratti di eseguire DAG di produzione complessi, pianificare attività o attivare agenti di AI, Lakeflow Jobs è il motore di orchestrazione nativo di Databricks che gestisce tutte queste attività. Portando l'orchestrazione gestita e l'osservabilità end-to-end in ogni livello del ciclo di vita dei dati, i team di dati stanno consolidando gli orchestratori legacy, come Apache Airflow, su un'unica piattaforma unificata.
Orchestrazione sensibile ai dati e al contesto
Ogni pianificazione cron è solo una stima di quando i dati saranno pronti. Lakeflow Jobs ti consente di smettere di indovinare e di iniziare ad attivare le pipeline in base all'effettiva disponibilità dei dati. Utilizzando il linguaggio naturale, puoi chiedere a Genie di scrivere i trigger SQL che definiscono cosa significa “pronto” per i tuoi dati. Il tuo job si attiva non appena le condizioni sono soddisfatte, rispettando i data contract e garantendo di non elaborare mai dati obsoleti.
“Con Lakeflow Jobs, siamo stati in grado di accedere a dati a cui le tecnologie legacy non potevano accedere, consentendoci di generare insight aziendali più approfonditi e affidabili.”—Sachin Wadhwa, Director of Data Architecture and Platforms, The Rank Group
Orchestrazione universale per qualsiasi cosa, ovunque
Per i clienti con flussi di lavoro di dati al di fuori di Databricks, Lakeflow Jobs offre la External Orchestration per estendere in modo nativo la portata ai sistemi esterni, senza richiedere la ricostruzione delle integrazioni da zero. Utilizzando un framework di operatori aperto, puoi avviare senza problemi i job di Snowflake, attivare API REST personalizzate o gestire gli avvisi di Slack e PagerDuty. Le risorse di calcolo vengono sospese in modo intelligente durante l'attesa di condizioni esterne che potrebbero richiedere ore. Stiamo pubblicando oltre 40 esempi di operatori su GitHub e aggiungeremo decine di integrazioni gestite nei prossimi trimestri. Inoltre, ogni credenziale passa attraverso Unity Catalog e dispone di un audit trail completo.
Iniziare con Lakeflow
Lakeflow fornisce la base di dati unificata necessaria per creare applicazioni di AI agentica affidabili. Per approfondire le configurazioni tecniche e vedere queste nuove funzionalità in azione, esplora i nostri tutorial pratici o consulta la nostra documentazione tecnica per iniziare il tuo prossimo progetto.
Pronto a iniziare? Prova Databricks gratuitamente per scoprire Lakeflow oggi stesso.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.