Piattaforma Aperta, Pipeline Unificate: Perché dbt su Databricks sta Accelerando
Esegui dbt su un lakehouse aperto e unificato con governance integrata e prestazioni-prezzo elevate
- Le fondamenta aperte prevengono il vendor lock-in. Crea workflow dbt con formati di tabella aperti e governance open source Unity Catalog.
- Una piattaforma unificata elimina la proliferazione di strumenti. Esegui dbt insieme a ingestion e BI in un unico posto con governance e orchestrazione integrate.
- Ottieni un forte rapporto prezzo/prestazioni con minima messa a punto e overhead operativo.
dbt porta struttura ai flussi di lavoro di trasformazione dei dati. I team lo utilizzano per trasformare i dati grezzi in set di dati curati che alimentano il consumo downstream come dashboard di BI, modelli AI/ML e reporting interfunzionale.
Ma la realtà è questa: dbt è potente solo quanto la piattaforma dati su cui viene eseguito.
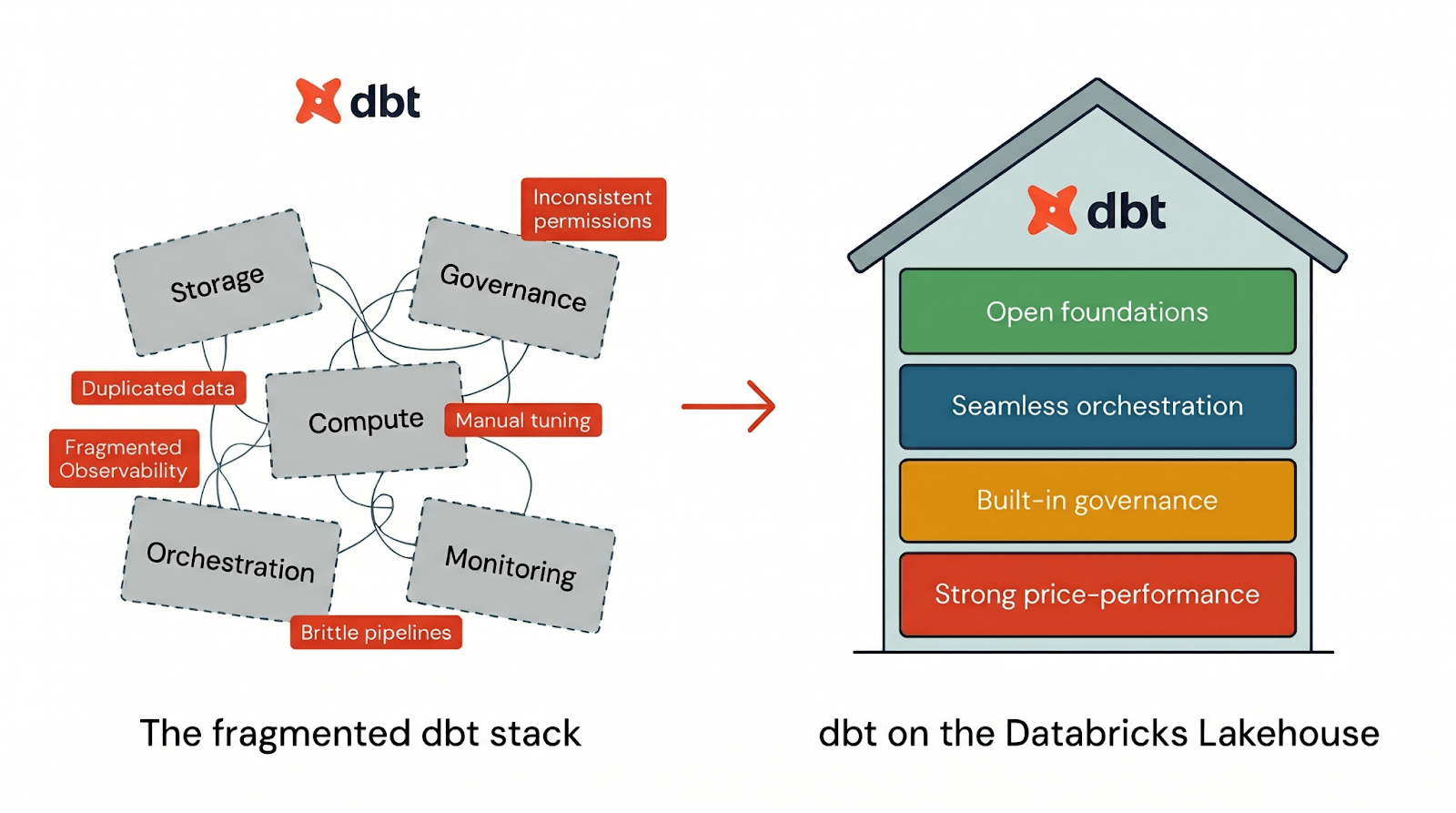
La maggior parte degli stack di dati ti costringe a mettere insieme storage, calcolo, governance, orchestrazione e monitoraggio su più sistemi. Il risultato? Dati duplicati, permessi incoerenti, osservabilità frammentata e ottimizzazione delle prestazioni che diventa un lavoro part-time. È per questo che un numero crescente di team sta consolidando i propri flussi di lavoro dbt su Databricks.
Per eseguire dbt in modo efficace, una piattaforma necessita di quattro cose:
- Fondamenta aperte in modo che i tuoi flussi di lavoro dbt non siano bloccati in uno stack proprietario
- Orchestrazione senza interruzioni per eseguire pipeline dbt end-to-end in un unico posto
- Governance integrata che fa parte del flusso di lavoro dbt predefinito
- Prestazioni-prezzo elevate in modo che dbt venga eseguito velocemente fin dal primo giorno senza ottimizzazione manuale
Databricks offre tutti e quattro i pilastri integrati nativamente in un'unica piattaforma. Quando esegui dbt su Databricks, ottieni l'esperienza dello sviluppatore dbt su un'architettura lakehouse progettata per apertura, governance, prestazioni e semplicità operativa fin dal primo giorno. Vediamo come ognuno di questi funziona in pratica:
Eseguire dbt su Databricks ci ha permesso di consolidare una vasta eredità di notebook e oltre 7 sistemi sorgente in un'unica piattaforma dati governata. Con Unity Catalog, gestiamo 341 tenant, più ambienti e la condivisione di dati con partner esterni tramite isolamento a livello di catalogo. La nostra documentazione dbt fluisce direttamente in UC, in modo che gli analisti possano autoservirsi senza colli di bottiglia. Pubblicando in formati aperti e Delta Sharing, i partner e i team downstream possono consumare facilmente set di dati generati da dbt attraverso strumenti e ambienti. È una piattaforma per la creazione, ma una piattaforma aperta per il consumo. —Sohan Chatterjee, Head of Data and Analytics, iSolved
Esegui dbt su fondamenta aperte senza vendor lock-in
Il vendor lock-in è uno dei rischi strategici più significativi per la strategia dati di un'organizzazione. dbt è costruito con un framework di adattatori aperti, il che significa che la tua logica di trasformazione non è bloccata su un'unica piattaforma. dbt è aperto per progettazione, e Databricks fornisce una piattaforma aperta su cui eseguirlo. Molti stack di dati moderni sono incentrati su uno strato di storage proprietario che offre convenienza a breve termine ma introduce attrito a lungo termine. Nel tempo, ciò porta a dati duplicati e pipeline di esportazione per servire diversi consumatori, formati di storage che limitano l'interoperabilità e costi di commutazione crescenti man mano che i requisiti della piattaforma evolvono.
Databricks è un lakehouse aperto: una piattaforma unificata in cui i tuoi dati risiedono in formati di tabella aperti e sono accessibili tramite interfacce aperte, garantendo che lo storage e la governance non siano legati a un singolo motore di query. Su Databricks, i modelli dbt diventano tabelle in formati aperti, Delta Lake e Apache Iceberg, garantendo che i tuoi dati trasformati rimangano accessibili in tutto il panorama dei dati senza esportazioni o mantenimento di copie parallele. Questa apertura è importante specificamente per i flussi di lavoro dbt. Le tue tabelle silver e gold attentamente modellate diventano prodotti di dati riutilizzabili che gli utenti downstream possono consumare tramite qualsiasi motore di query, non solo attraverso la piattaforma in cui viene eseguito dbt.
Questa apertura si estende oltre lo storage. Unity Catalog è costruito attorno a standard aperti di catalogo e accesso che supportano letture e scritture governate da motori esterni. Databricks SQL segue gli standard ANSI, garantendo che le tue query rimangano portabili tra le piattaforme per ridurre le riscritture specifiche del vendor. Ciò significa che i tuoi flussi di lavoro dbt vengono eseguiti su uno stack progettato per la portabilità, non per il lock-in.
Orchestra pipeline dbt end-to-end con Lakeflow Jobs
L'orchestrazione è dove si accumula la complessità operativa. Accoppiare dbt con un orchestratore esterno oltre a Databricks significa due sistemi da gestire, due posti in cui eseguire il debug e passaggi fragili tra di essi.
Lakeflow Jobs rimuove tale complessità trattando dbt come tipo di attività di prima classe all'interno di una pipeline unificata. Invece di mantenere uno strato di orchestrazione separato, i team eseguono dbt insieme all'ingestione upstream e alle azioni downstream in un unico flusso di lavoro. Ad esempio, puoi ingerire dati grezzi con Auto Loader, trasformare i dati con modelli dbt, quindi attivare aggiornamenti di dashboard o riaddestramento ML, tutto in un'unica pipeline con logica di retry e gestione delle dipendenze unificate. dbt su Databricks abilita anche l'ingestione direttamente tramite tabelle di streaming. Per gli utenti di dbt Platform, l'attività dbt Platform (in Beta) consente a Lakeflow di attivare e gestire flussi di lavoro dbt in esecuzione in dbt Platform.
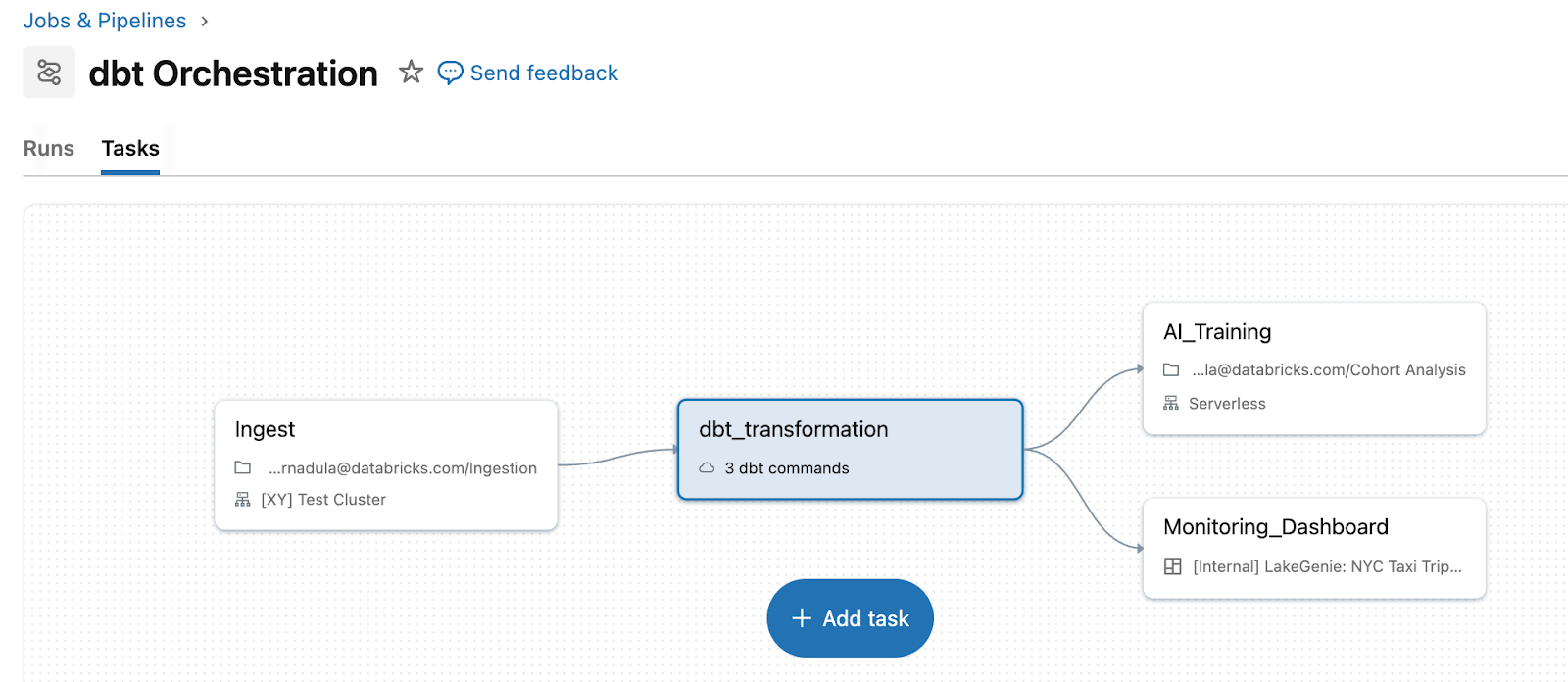
Quando dbt viene orchestrato tramite Lakeflow, fallimenti, retry e contesto sono visibili in un unico posto. Invece di passare da un orchestratore dbt separato ai log di Databricks, puoi vedere il fallimento, le attività downstream interessate e i dashboard impattati direttamente nella stessa visualizzazione di esecuzione del job.
Rendi la governance parte del flusso di lavoro dbt predefinito
Man mano che i flussi di lavoro dbt scalano, la governance diventa il collo di bottiglia. I team necessitano di risposte chiare sul contenuto delle tabelle, sulla proprietà e sui permessi di accesso. Negli stack tradizionali, questo contesto è frammentato tra strumenti di catalogo separati, sistemi di permessi e viste di lineage incomplete che non si collegano end-to-end.
Databricks risolve questo problema con Unity Catalog, che unifica il controllo degli accessi, la scoperta e il lineage per l'intero lakehouse – non solo all'interno di dbt, ma anche nell'ingestione, BI, ML/AI e oltre. Con Unity Catalog, non è necessario rieseguire le istruzioni di grant ogni volta che dbt ricrea una tabella. I permessi sono gestiti a livello di schema e persistono attraverso le ricostruzioni delle tabelle. Controlli granulari come filtri a livello di riga, maschere di colonna e controllo degli accessi basato su attributi si applicano in modo coerente tra dbt, strumenti di BI e notebook.
Ad esempio, quando si persistono la documentazione dbt in Unity Catalog utilizzando la funzionalità dbt persist_docs, le descrizioni delle colonne e il contesto curati in dbt diventano ricercabili dove i dati vengono interrogati e consumati. Unity Catalog fornisce lineage dei dati a livello di colonna che traccia il flusso dei dati dall'ingestione grezza attraverso le trasformazioni dbt all'utilizzo downstream. Quando uno schema sorgente cambia, puoi vedere istantaneamente quali modelli dbt e asset downstream sono interessati. Questo livello di visibilità è impossibile quando le pipeline di dati attraversano sistemi disconnessi.
La governance dei costi è importante quanto la governance dei dati. Con i tag delle query, puoi associare un contesto aziendale alle esecuzioni dbt e monitorare la spesa per team, progetto o ambiente tramite le Tabelle di sistema. I team possono finalmente rispondere alla domanda "quanto costano le nostre pipeline dbt di analisi di marketing?" con dati reali anziché stime. Inoltre, il monitoraggio granulare dei costi di DBSQL (in anteprima privata) fornisce anche il monitoraggio aggregato dei costi per tutti i carichi di lavoro dbt.
Esegui dbt con prestazioni elevate e costi contenuti fin dal primo giorno
L'ottimizzazione di un data warehouse per le prestazioni richiede in genere un lavoro manuale continuo. I team finiscono spesso per sacrificare la velocità di sviluppo per l'igiene delle prestazioni.
Databricks astrae questa complessità combinando un motore di esecuzione ad alte prestazioni con funzionalità che funzionano nativamente con dbt,offrendo miglioramenti della velocità senza overhead manuale.
Prestazioni integrate
- Photon engine accelera i carichi di lavoro SQL tramite esecuzione vettorizzata, offrendo prestazioni fino a12 volte migliori in termini di rapporto prezzo-prestazioni rispetto ai data warehouse cloud. I warehouse SQL serverless includono Photon per impostazione predefinita, quindi i team ottengono prestazioni accelerate senza costi aggiuntivi.
- Ottimizzazione predittiva utilizza l'IA per monitorare le tabelle e automatizzare la manutenzione, ottenendo query fino a20 volte più veloci. Ciò riduce la necessità di post-hook OPTIMIZE manuali su cui gli ingegneri dbt facevano storicamente affidamento.
Funzionalità di prestazioni sbloccate tramite la configurazione dbt
- L'integrazione di dbt conLiquid Clustering, che sostituisce rigide strategie di partizionamento con un approccio flessibile che si adatta dinamicamente alla crescita del volume dei dati, con conseguenti velocità fino a 10 volte più veloci senza ottimizzazione manuale
- Viste Materializzate in dbt, basate su Spark Declarative Pipelines open-source, gestiscono l'elaborazione incrementale automaticamente. Databricks gestisce la complessità nel determinare cosa necessita di aggiornamenti ed elabora solo i record nuovi o modificati, anziché ricalcolare interi set di dati. Ciò offre costi di calcolo inferiori rispetto a inefficienti aggiornamenti batch pianificati.
Con queste funzionalità, gli utenti dedicano meno tempo all'ottimizzazione e più tempo alla creazione di pipeline che rimangono performanti all'aumentare dei set di dati. Solo nel 2025, Databricks SQL ha ottenuto un miglioramento delle prestazioni del10% sui carichi di lavoro ETL (query con scritture) senza richiedere alcuna configurazione aggiuntiva.
Inizia oggi stesso
Databricks riunisce archiviazione aperta, governance unificata, prestazioni elevate e operazioni integrate in un unico posto per i flussi di lavoro dbt. Unisciti agli oltre 2900 clienti che eseguono già dbt su Databricks. Inizia seguendo laguida rapida.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.