Spark Connect がApache Spark 3.4で利用可能になりました
Run Spark Applications Everywhere
によって アラン・フォルティング, Hyukjin Kwon, Xiao Li, Herman van Hövell, ステファニア・レオーネ, マーティン・�グルンド, Reynold Xin(レイノルド・シン) 、 Kris Mo による投稿
Original Blog : Spark Connect Available in Apache Spark 3.4
翻訳: junichi.maruyama
昨年、Data and AI SummitでSpark Connectが紹介されました。最近リリースされたApache SparkTM 3.4の一部として、Spark Connectは一般的に利用できるようになりました。また、最近Databricks ConnectをSpark Connectをベースに再アーキテクトしました。このブログ記事では、Spark Connectとは何か、どのように機能するのか、どのように使用するのかについて説明します。
IDE、Notebook、最新のデータアプリケーションをSparkクラスタに直接接続できるようになります
Spark Connectは、クライアントとサーバーを分離したアーキテクチャで、あらゆるアプリケーションからSparkクラスタへのリモート接続を可能にし、どこでも実行できるようにします。このクライアントとサーバーの分離により、最新のデータアプリケーション、IDE、ノートブック、およびプログラミング言語がSparkにインタラクティブにアクセスできるようになります。
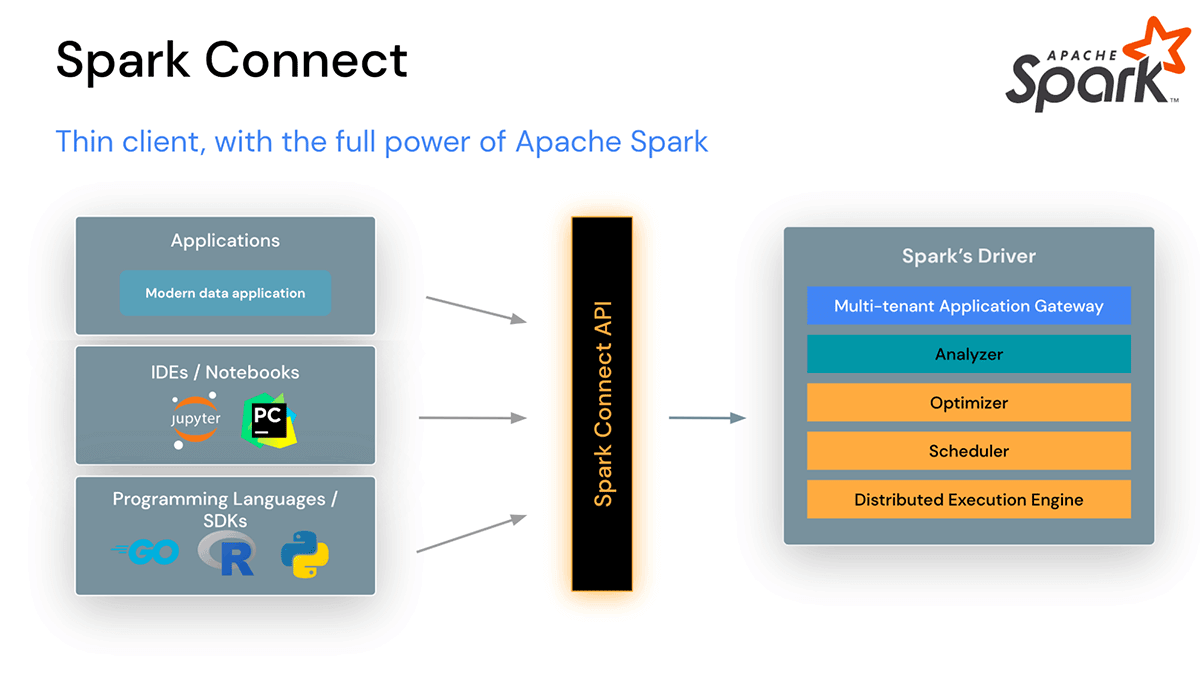
Spark Connectは安定性、アップグレード、デバッグ、観測性を向上させます
この新しいアーキテクチャにより、Spark Connectは一般的な運用上の問題も軽減しています:
安定性: 安定性:メモリを大量に使用するアプリケーションは、Sparkクラスタの外で独自のプロセスで実行できるため、自身の環境にのみ影響を与えるようになりました。ユーザーはクライアント環境で独自の依存関係を定義することができ、Sparkドライバーの潜在的な依存関係の競合を心配する必要がありません。
例えば、分析または変換のためにSparkから大規模なデータセットを取得するクライアントアプリケーションがある場合、そのアプリケーションはもはやSparkドライバ上で実行されることはないでしょう。つまり、そのアプリケーションがメモリやCPUサイクルを大量に使用しても、Sparkドライバ上の他のアプリケーションとリソースを奪い合うことはなく、他のアプリケーションの速度低下や障害を引き起こす可能性はありません。
アップグレードのしやすさ: 従来、Sparkのアップグレードは、同じSparkクラスタ上のすべてのアプリケーショ��ンをクラスタと同時にアップグレードする必要があったため、非常に面倒でした。Spark Connectでは、クライアントとサーバーが分離されているため、アプリケーションはサーバーから独立してアップグレードすることが可能です。これにより、Sparkのアップグレード時にクライアントアプリケーションに変更を加える必要がないため、アップグレードが非常に容易になりました。
デバッグ可能性と観察可能性: Spark Connectは、お気に入りのIDEから直接、開発中のインタラクティブなステップスルーデバッグを可能にします。同様に、アプリケーションのフレームワークネイティブメトリクスとロギングライブラリを使用して、アプリケーションを監視することができます。
たとえば、Visual Studio CodeでSpark Connectクライアントアプリケーションをインタラクティブにステップスルーし、オブジェクトを検査し、デバッグコマンドを実行して、コードの問題をテストし修正することができます。
Spark Connectの仕組み
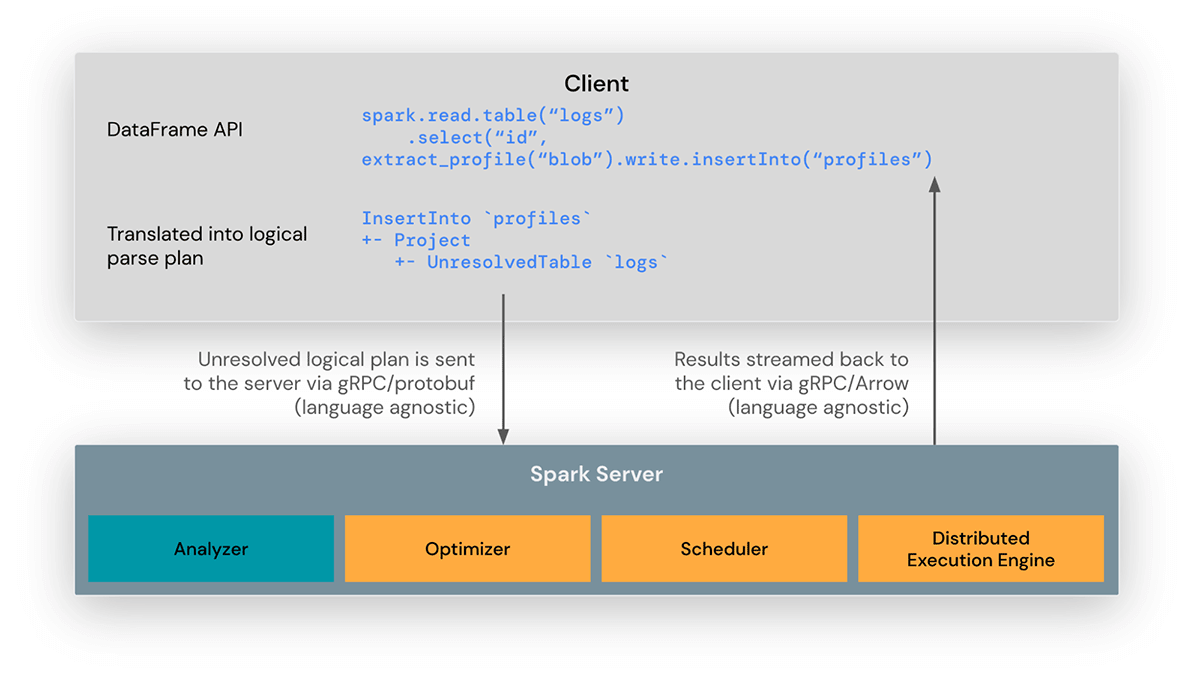
Spark Connectクライアントライブラリは、Sparkアプリケーションの開発を簡素化するために設計されています。これは、アプリケーションサーバー、IDE、ノートブック、プログラミング言語など、あらゆる場所に埋め込むことができる薄いAPIです。Spark Connect APIは、クライアントとSparkドライバ間の言語に依存しないプロトコルとして未解決の論理計画を使用するSparkのDataFrame APIをベースとしています。
Spark Connectクライアントは、DataFrameの操作を未解決の論理クエリプランに変換し、プロトコルバッファを使用してエンコードします。これらは、gRPCフレームワークを使用してサーバーに送信されます。
Sparkドライバに組み込まれたSpark Connectエンドポイントは、未解決の論理プランを受信してSparkの論理プラン演算子に変換します。これはSQLクエリの解析に似ており、属性と関係が解析され、最初の解析プランが構築されます。そこから、標準的なSparkの実行プロセスが開始され、Spark ConnectがSparkのすべての最適化と機能拡張を活用できるようにします。結果は、Apache Arrowでエンコードされた結果バッチとして、gRPCを通じてクライアントにストリーミングバックされます。
Spark Connectの使用方法
Spark 3.4からSpark Connectが利用できるようになり、PySparkとScalaのアプリケーションをサポートしています。Spark Connectクライアントライブラリを使用して、クライアントアプリケーションからSpark ConnectでApache Sparkサーバーに接続する例について説明します。
Sparkアプリケーションを書くときに、Spark Connectを考慮する必要があるのは、Sparkセッションを作成するときだけです。それ以外のコードは、これまでとまったく同じです。
Spark Connectを使用するには、コードを変更することなく、アプリケーションに環境変数(SPARK_REMOTE)を設定するだけで拾えるようにするか、Sparkセッションを作成する際に明示的にSpark Connectをコードに含めることができます。
Jupyterノートブックの例を見てみましょう。このノートブックでは、ローカルのSparkクラスターへのSpark Connectセッションを作成し、PySpark DataFrameを作成して、リスナー数による音楽アーティスト上位10人を表示しています。
この例では、Sparkセッションを作成する際にremoteプロパティを設定することで、Spark Connectを使用することを明示的に指定しています(SparkSession.builder.remote...)。
Jupyter notebook code using Spark Connect
例題で使用したデータセットは、こちらからダウンロードできます: Music artists popularity | Kaggle
例えば、ローカルのSparkクラスターで開発およびテストを行い、後でリモートクラスター上の本番環境にコードを移行する場合、Spark Connectを使用すると、異なるSparkクラスター間で簡単に切り替えることができます。
この例では、TEST_ENV環境変数を設定して、アプリケーションが使用するSparkクラスターとデータの場所を指定することで、テスト、ステージング、本番クラスターを切り替えるためにコードを変更する必要がないようにしています。
環境変数で異なるSparkクラスターを切り替える
Spark Connectの使用方法については、Spark Connect Overviewとpark Connect Quickstartのページをご覧ください。
Databricks ConnectはSpark Connectで構築されています
Databricks Runtime 13.0から、Databricks ConnectはオープンソースのSpark Connectで構築されるようになりました。この「v2」アーキテクチャにより、Databricks Connectはシンプルで使い勝手の良いシンクライアントとなりました。IDE、ノートブック、あらゆるアプリケーションなど、Databricksに接続するためのあらゆる場所に組み込むことができ、顧客やパートナーは、あなたのDatabricks Lakehouseをベースに新しい(インタラクティブな)ユーザー体験を構築できるようになります。使い方はとても簡単です: ユーザーはDatabricks Connect libraryをアプリケーションに組み込み、Databricks Lakehouseに接続するだけです。
Apache Spark 3.4でサポートされるAPI
PySpark: Spark 3.4では、Spark ConnectはDataFrame, Functions, Columnを含むほとんどのPySpark APIをサポートしています。サポートされているPySpark APIは、API referenceドキュメントで「Supports Spark Connect」と表示されるので、既存のコードをSpark Connectに移行する前に、使用しているAPIが利用可能かどうかを確認できます。
Scala: Spark 3.4では、Spark ConnectはDataset, functions, Columnなど、ほとんどのScala APIをサポートしています。
ストリーミングのサポートは近々行われる予定であり、今後のSparkリリースでSpark Connectのためのより多くのAPIを提供するためにコミュニティと協力することを楽しみにしています。
Apache Spark 3.4のSpark Connectは、PySparkとScalaのDataFrame/DataSetsに基づくあらゆるアプリケーションからSparkへのアクセスを可能にし、将来的に他のプログラミング言語をサポートするための基礎を築きます。
クライアントアプリケーション開発の簡素化、Sparkドライバのメモリ競合の緩和、クライアントアプリケーションの独立した依存関係管理、クライアントとサーバーの独立したアップグレード、IDEのステップスルーデバッグ、シンクライアントのロギングとメトリックなど、Spark ConnectはSparkへのアクセスをユビキタスにします。
Spark Connectの詳細と開始については、Spark Connect Overview と Spark Connect Quickstart のページをご覧ください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。