Databricksで実現する高並行・低遅延の次世代データウェアハウス
スケールとコスト効率を両立 ― 実践的アプローチでモダンDWHを構築
によって Ben Dunmire, ダン・ルーク 、 Jen Lim による投稿
- Databricksでデータウェアハウス、分析、AIを統合し、最適なコストとパフォーマンスをAIが自動で最適化。
- スケール、パフォーマンス、コスト目標に合わせてアーキテクチャをチューニングし、最大の効果を実現。
- ビジネスの成長に合わせて拡張できる、サブセカンド応答の本番レベル・データウェアハウスを提供。
Databricksデータウェアハウスでの本番環境向け分析の実装
高並行・低遅延なデータウェアハウスは、データがビジネス意思決定の中核を担う企業にとって欠かせない存在です。
数百人規模の同時利用を支え、インタラクティブ分析での高速なクエリ性能を実現し、リアルタイムなインサイトを通じて迅速かつ的確な意思決定を可能にします。
本番環境レベルのデータウェアハウスは、単なるサポートシステムではなく、成長とイノベーションを加速させる原動力です。
Databricksは、データ・分析�・AIワークロードを統合するレイクハウスアーキテクチャを業界に先駆けて提唱しました。
これにより、データの重複や複雑なシステム連携といったコストのかかる課題を解消します。
レイクハウスには自律的なパフォーマンス最適化機能が組み込まれており、競争力のあるコストパフォーマンスを実現しながら、運用を大幅に簡素化します。
さらにオープンなレイクハウスとして、Databricks SQLを通じて重要なデータへの高速かつ安全なアクセスを提供し、BI・分析・AIツールを統一されたセキュリティとガバナンスのもとで活用できます。
多くのユーザーがこれら外部ツールを介してデータウェアハウスにアクセスするため、このオープンな相互運用性は極めて重要です。
Databricksプラットフォームは、データ量やユーザー数の増加だけでなく、チームが活用するツールの多様化にもシームレスにスケールします。
また、Databricks AI/BIやDatabricksなどの強力な組み込み機能を提供しつつ、既存エコシステムとの柔軟な連携を維持します。
本ブログでは、Databricks Data Intelligence Platformを活用して高並行・低遅延のパフォーマンスを最大化する方法を、レイクハウス導入のあらゆる段階(設計初期・実装中・運用最適化フェーズ)にある企業向けに包括的に解説します。
以下のトピックについて詳しく見ていきます。
- データウェアハウスのコアアーキテクチャコンポーネントとそのプラットフォームパフォーマンスへの集合的な影響。
- これらのアーキテクチャ要素の最適化をガイドする構造化されたパフォーマンスチューニングフレームワーク。
- スケールで持続的なパフォーマンスを確保するためのベストプラクティス、監視戦略、およびチューニング方法論。
- 実際のケーススタディを通じて、これらの原則がどのように連携して機能するかを示します。
主要なアーキテクチャ上の考慮事項
伝統的なデータウェアハウスの基本原則の多くは依然として適用されますが、例えば、堅固なデータモデリング、堅固なデータ管理、組み込みのデータ品質などですが、本番用の最新のレイクハウスを設計するには、より全体的なアプローチが必要です。これには、統一されたガバナンスフレームワークが中心的な役割を果たし、Unity Catalog (AWS | Azure | GCP) はそれを提供するための重要な役割を果たします。Unity Catalogは、すべてのデータとAI資産にわたるアクセス制御、系統追跡、監査可能性を標準化することで、データ量、ユーザーの同時接続数、プラットフォームの複雑さが増すにつれてますます必要となる一貫したガバナンスをスケールで確保します。
効果的な設計には次の要素が必要です:
- 実証済みのアーキテクチャのベストプラクティスの採用
- 相互に連結されたコンポーネント間のトレードオフの理解
- ビジネス要件に基づいた並行性、レイテンシ、スケールの明確な目標
レイクハウスでは、パフォーマンスの結果は設計フェーズの初期に行われたアーキテクチャの選択によって影響を受けます。これらの意図的な設計決定は、以下の5つの重要な軸にわたって、現代のレイクハウスが伝統的なデータウェアハウスから根本的に逸脱していることを示しています:

これらのアーキテクチャの考慮点を念頭に置き、高並行性と低レイテンシをスケールで実現する本番環境向けデータウェアハウスの実装についての実用的なフレームワークを探求しましょう。
技術的な解決策の詳細
以下のフレームワークは、エンタープライズ顧客との実際のエンゲージメントを通じて開発されたベストプラクティスとアーキテクチャ原則をまとめています。新しいデータウェアハウスを構築する場合、既存のプラットフォームから移行する場合、または既存のレイクハウスをチューニングする場合でも、これらのガイドラインは、生産までの時間を短縮しながら、スケーラブルでパフォーマンスが高く、コスト効率の良い結果を提供します。
ユースケース駆動型の評価から始める
実装する前に、最も遅いダッシュボードや最もリソースを消費するパイプラインなど、重要なワークロードの迅速な評価をお勧めします。このアプローチは、パフォーマンスのギャップを特定し、最適化のためのエリアを優先するのに役立ちます。
分析を枠組み化するための以下の質問をします:
- 最も重要なパフォーマンス指標は何ですか(例えば、クエリの遅延、スループット、同時実行性)そしてそれらはビジネスの期待とどのように比較されますか?
- このワークロードを誰が、いつ、どの程度の頻度で使用しているのか?
- コンピューティングコストは、ワークロードのビジネス価値に比例していますか?
この評価は、ターゲットとなる改善の基盤を作り、ビジネスへの影響と最適化の努力を整合させるのに役立ちます。
実装フレームワーク
以下のフレームワークは、Databricks上でウェアハウスを実装または近代化するためのステップバイステップのアプローチを概説しています:
- 現状を評価し、目標を優先順位付けする
- 既存のアーキテクチャをパフォーマンス、コスト、スケーラビリティの目標と比較して評価します。
- 並行性、レイテンシ、スケール、コスト、SLAなどのビジネス(および技術)要件を定義し、ゴールポストが移動しないようにします。
- ビジネスに最も影響を与えるギャップを特定し、価値と複雑さ(新規設計、移行中、または製品内)に基づいて修正を優先します。
- ウェアハウスアーキテクチャとガバナンスの定義
- 論理的なセグメンテーションを設計します:どのチームまたはユースケースが共有するか、または専用のSQLウェアハウスを必要とするかを決定します。
- ウェアハウスのサイズを適切に設定し、タグを適用し、デフォルトを定義します(例:キャッシュ設定、タイムアウトなど)。
- デフォルトのキャッシング、ウェアハウスのタイムアウト、BIツールからのJDBCタイムアウト、SQL設定パラメータなどの細かい設定を理解し、計画します(AWS | Azure | GPC)。
- ウェアハウスの管理モデルを確立し、管理者(AWS |� Azure | GCP)とエンドユーザー(AWS | Azure | GCP)の役割と責任をカバーします。
- トレーニングに投資し、実装テンプレートを提供して、チーム間での一貫性を確保します。
- 監視可能性(オブザーバビリティ)を有効にする
- 最適化とベストプラクティスの実装
- 観測可能性からの洞察を活用して、ワークロードのパフォーマンスをビジネスと技術の要件と一致させます。
- AI機能を実装し、コスト、レイアウト、計算効率を向上させます。
- 学んだことを再利用可能なテンプレート、ドキュメンテーション、チェックリストにコード化して、ベストプラクティスをチーム全体にスケールします。
- 努力(複雑さ、タイムライン、専門知識)対影響(パフォーマンス、コスト、メンテナンスオーバーヘッド)のマトリックスを使用して、段階的に最適化し、優先順位をつけます。
以下のセクションでは、このフレームワークの各ステージを通じて、どのように思慮深い設計と実行がDatabricks上での高並行性、低遅延、ビジネスに合わせたコストパフォーマンスを可能にするかを理解しましょう。
現状を評価し、目標を優先順位付けする
ベストプラクティスとチューニング技術に深く入る前に、レイクハウスのパフォーマンスを形成する基本的なレバー、例えばコンピュートサイジング、データレイアウト、データモデリングを理解することが重要です。これらは、チームが直接影響を与えて高並行性、低レイテンシ、スケールの目標を達成することができる領域です。

下記のスコアカードは、各レバーの成熟度を評価し、努力を集中すべき場所を特定するためのシンプルなマトリックスを提供します。それを使用するには、各レバーを3つの次元で評価します:ビジネスニーズをどれだけ満たしているか、ベストプラクティスとどれだけ一致しているか、チームがその領域で持っている技術能力のレベル、そしてガバナンスです。各交差点に対してRed-Amber-Green(RAG)の評価を適用し、強み(緑)、改善の余地(アンバー)、重要なギャップ(赤)を素早く視覚化します。このブログの後半部分で紹介するベストプラクティスと評価手法は、評価を行うための情報を提供します。これをより詳細な成熟度評価と組み合わせて使用します。この演習は、チーム間の議論を促進し、隠れたボトルネックを明らかにし、トレーニング、アーキテクチャの変更、自動化など、どこに投資するべきかを優先順位付けするのに役立ちます。
レイクハウスのパフォーマンスを駆動するコンポーネントとそれらを実装するためのフレームワークが定義されたら、次に何をすべきでしょうか?ベストプラクティス(何をするか)、チューニング手法(どのように行うか)、評価方法(いつ行うか)の組み合わせが、パフォーマンス目標を達成するためのアクションを提供します。
重点は、高性能なデータウェアハウスを運用するために調和して働くいくつかの重要なコンポーネントのための具体的なベストプラクティスと詳細な設定技術に置かれます。
ウェアハウスアーキテクチャとガバナンスの定義
コンピュート (Databricks SQLウェアハウス)
コンピューティングは主要なパフォーマンスレバーとしてよく見られますが、コンピューティングのサイジング決定は常にデータレイアウト設計とモデリング/クエリと一緒に考慮されるべきで、これらは直接必要なパフォーマンスを達成するために必要なコンピューティングに影響を与えます。
SQLウェアハウスの適切なサイジングは、コスト効率の良いスケーリングにとって重要です。正確なサイジングを事前に予測するための絶対的な方法はありませんが、SQLウェアハウスの計算を組織化し、サイジングするための主要なヒューリスティックスの一部を以下に示します。
- SQLサーバーレスウェアハウスを有効にする:彼らは瞬時の計算、弾力的なオートスケーリングを提供し、完全に管理されており、バースト性や不規則なBI/分析ワークロードを含むすべてのタイプの使用に対して操作を簡素化します。Databricksはインフラストラクチャを完全に管理し、そのインフラストラクチャコストは組み込まれており、TCO削減の可能性を提供します。
- ワークロードとユーザーを理解する:ユーザー(人間/自動化)とそのクエリパターン(対話型BI、アドホック、スケジュールレポート)をセグメント化し、アプリケーションのコンテキスト、目的、チーム、機能などによる論理的なグループ化によってスコープを持つ異なるウェアハウスを使用します。これらのセグメントによって、より細かいサイジング制御と独立した監視が可能なマルチウェアハウスアーキテクチャを実装します。コスト帰属のためのタグが強制されていることを確認します。騒々しい隣人を防ぐための今後の機能にアクセスするために、Databricksのアカウント担当者に連絡してください。
- 反復的なサイジングとスケーリング:初期のウェアハウスサイズや最小/最大クラスタ設定を過度に考える必要はありません。次のセクションで説明するメカニズムを使用して、実際のワークロードパフォーマンスを監視することに基づいた調整は、事前の推測よりもはるかに効果的です。データ量やユーザー数は、必要な計算量を正確に推定するものではありません。クエリの種類、パターン、クエリ負荷の同時実行性がより良い指標であり、Intelligent Workload Management(IWM)から自動的に利益を得ることができます(AWS | Azure | GCP)。
- リサイズとスケールのタイミングを理解する:リソースが重い、複雑なクエリ(大規模な集約やマルチテーブル結合など)を処理する必要がある場合や、ディスクスピルの頻度やメモリ利用率を監視する場合は、ウェアハウスのサイズ("Tシャツサイズ")を増やします。バースト性の同時使用や、多くのクエリが実行を待つ結果としての持続的なキューイングが見られる場合には、オートスケーリングのためのクラスターの数を増やします。これは、いくつかの集中的なクエリが保留中であるのではなく、多くのクエリが実行を待っている結果です。
- 可用性とコストのバランス:オートストップ設定を構成します。サーバーレスの迅速なコールドスタートは、アイドル期間における大幅なコスト削減をもたらします。
レイクハウス内の物理データ(ファイル)レイアウト
高速なクエリは、クエリエンジンがメタデータと統計を使用して関連するファイルのみを読み込むデータスキップから始まります。データの物理的な組織はこのプルーニングに直接影響を与えるため、ファイルレイアウトの最適化は高並行性、低遅延パフォーマンスにとって重要です。
Databricks上でのデータレイアウト技術の進化は、最適なファイル組織のための様々なアプローチを提供します。
新しいテーブルについては、Databricksは管理テーブルをデフォルトにし、Auto Liquid Clustering(AWS | Azure | GCP)とPredictive Optimization(AWS | Azure | GCP)を使用することを推奨します。Auto Liquid Clusteringはクエリパターン��に基づいてデータをインテリジェントに組織化し、初期のクラスタリング列をヒントとして指定することで一つのコマンドで有効にすることができます。Predictive Optimizationは、OPTIMIZE、VACUUM および ANALYZEのようなメンテナンスジョブを自動的に処理します。
既存のデプロイメントで外部テーブルを使用している場合は、これらのAI機能を最大限に活用するために、高読み取りおよびレイテンシ感度の高いテーブルを優先して管理テーブルへの移行を検討してください。Databricksは自動化されたソリューション(AWS | Azure | GCP)を提供し、ALTER TABLE...SET MANAGEDコマンドを使用して移行プロセスを簡素化します。さらに、Databricksはオープンテーブルフォーマット戦略の一部として管理Icebergテーブルをサポートしています。
データモデリング / クエリング
モデリングは、ビジネス要件がデータ構造に出会う場所です。常に最終的な消費パターンを理解し、それらのビジネスニーズに対して組織の好みの方法論—Kimball、Inmon、Data Vault、または非正規化のアプローチを使用してモデル化を開始します。Databricksのレイクハウスアーキテクチャはすべてをサポートします。
Unity Catalogの機能は、系統、主キー(PK)、制約、スキーマ進化の機能を備え、観察可能性と発見を超えて拡張します。これらはDatabricksクエリオプティマイザーに重要なヒントを提供し、より効率的なクエリプランを可能にし、クエリパフォーマンスを向上させます。例えば、PKと外部キーをRELYで宣言することで、オプティマイザーは冗長な結合を排除し、速度に直接影響を与えます。Unity Catalogの強力なスキーマ進化のサポートも、データモデルが時間とともに適応する際の敏捷性を保証します。Unity Catalogは、ANSI SQLに基づく標準的なガバナンスモデルを提供します。
その他の関連リソースには、データウェアハウジングモデリングテクニックや、ディメンショナルデータウェアハウジングの3部構成のシリーズ(パート1、パート2、パート3)があります。
監視可能性を有効にする
モニタリングの有効化とアクションチューニングの決定は、コンピューティング、物理ファイルレイアウト、クエリ効率など、データウェアハウスコンポーネント間の相互関連性を完璧に強調します。
- ダッシュボードやアプリケーションを通じて観測性を確立します。
- パフォーマンスのボトルネックを特定��し、診断し、それを修正するための学習パターンを定義します。
- アラートとエージェントによる修正アクションを通じて自動化を反復的に構築します。
- ボトルネックを引き起こす一般的な傾向をコンパイルし、それらを開発のベストプラクティス、コードレビューチェック、テンプレートに組み込みます。
継続的な監視は、生産性における持続的な高パフォーマンスとコスト効率を確保するために不可欠です。標準的なパターンを理解することで、使用が進化するにつれてチューニングの決定を洗練することができます。
モニターと調整:各ウェアハウスの組み込みモニタリングタブ(AWS | Azure | GCP)を使用して、ピーク時の同時クエリ、利用率、その他の重要な統計についてリアルタイムの洞察を得ます。�これは観察のためのクイックリファレンスを提供しますが、アラートとアクションを駆動するためのさらなる技術で補完する必要があります。
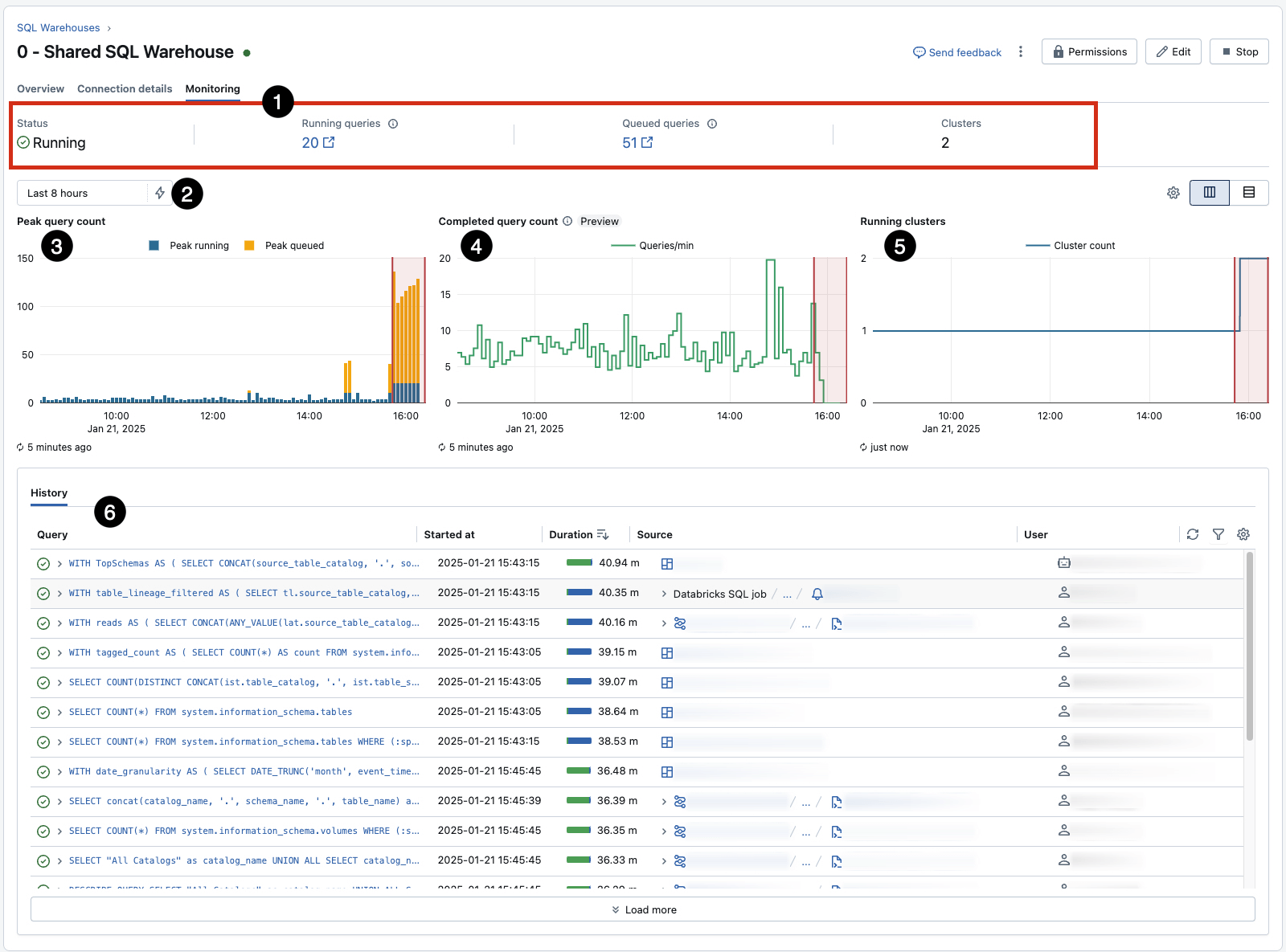
- 特に3に注目してください。これは、特定のウェアハウスの並行性制限によるキューイングを示し、リサイズによって影響を受ける可能性があります。また、5は、キューに対する自動スケーリングイベントを示し、6はクエリ履歴をキャプチャし、長時間実行される効率の悪いワークロードを特定し調査するための良い出発点となります。
システムテーブルを活用する:より詳細で、特別な監視をサポートします。時間とともに、カスタムダッシュボードとアラートを開発しますが、準備された提供物を活用します:
- 以下のGranular SQL Warehouse Monitoring Dashboard は、誰が何をコストドライバーとしているかを理解することで、スケーリング決定をより理解しやすくする包括的なビューを提供します。
- 以下のDBSQL Workflow Advisorは、スケーリング、クエリパフォーマンスを横断してボトルネックとコスト帰属を特定するビューを提供します。
- カスタムSQLアラート(AWS | Azure | GCP)を導入し、上記の監視イベントから学習した組み込みの通知を行います。
コストの帰属と観測可能性に興味があるお客様のために、この専用ブログ、From Chaos to Control: A Cost Maturity Journey with Databricks、コスト成熟度の旅については、貴重なリソースです。
クエリプロファイルを利用する:クエリプロファイル(AWS | Azure | GCP)ツールは、個々のクエリパフォーマンス問題の主要な診断ツールです。詳細な実行計画を提供し、必要なコンピュートに影響を与えるボトルネックを特定するのに役立ちます。
 |
|

クエリプロファイルから探すべきいくつかの開始点の提案:
- プルーニングが行われているか確認します。プルーニングが行われるべき(AWS | Azure | GCP)(つまり、テーブルのメタデータ/統計を使用してストレージから読み取るデータを減らす)、これは述語や結合を適用する場合に期待されますが、それが発生していない場合、ファイルレイアウト戦略を分析します。理想的には、読み取られるファイル/パーティションの数は少なく、プルーニングされるファイルの数は多いべきです。
- 「スケジューリング」でかなりの時間(数秒以上)が費やされていると、キューイングが発生していることを示唆します。
- 'クライアントによる結果の取得'の時間が大部分を占めている場合、外部ツール/アプリケーションとSQLウェアハウス間のネットワーク問題を示しています。
- キャッシュから読み取られるバイト数は、同じテーブルを使用して同じウェアハウスでクエリを実行するユーザーが自然にキャッシュされたデータを利用するため、使用パターンによって異なります。
- DAG(Directed Acyclic Graph–AWS | Azure | GCP)は、ステップを時間、使用したメモリ、読み取った行の量で識別することができます。これは、非常に複雑なクエリのパフォーマンス問題を絞り込むのに役立ちます。
- 小さなファイル問題(データファイルが最適なサイズよりも大幅に小さいため、処理が非効率的になる)を検出するためには、理想的には、平均ファイルサイズはテーブルのサイズに応じて128MBから1GBの間であるべきです。
- クエリプランの大部分はソーステーブルのスキャンに費やされます。
- 実行します
DESCRIBE DETAIL [Table Name]. 平均ファイルサイズを見つけるために、sizeInBytesをnumFilesで割ります。または、クエリプロファイルで、[Bytes read] / [Files read]を使用します。
- 効率の悪いシャッフルハッシュジョインを検出するには:
- DAGの結合ステップを選択し、「結合アルゴリズム」を確認します。
- ファイルの剪定がない/低い。
- DAGでは、��シャッフルは両方のテーブル(結合の両側、左側の画像のように)で発生します。テーブルの一方が十分に小さい場合は、代わりに ブロードキャストハッシュ結合 を実行することを検討してください(右側の画像に示されています)。
- 適応的クエリ実行(AQE)は、ブロードキャストジョインに対してデータサイズが<=30 MBをデフォルトとします - 一般的に、データサイズが200 MB未満のテーブルはブロードキャストの評価候補となります。1 GBが上限です。
- 常にフィルターが適用されていることを確認し、ソースデータセットを減らします。
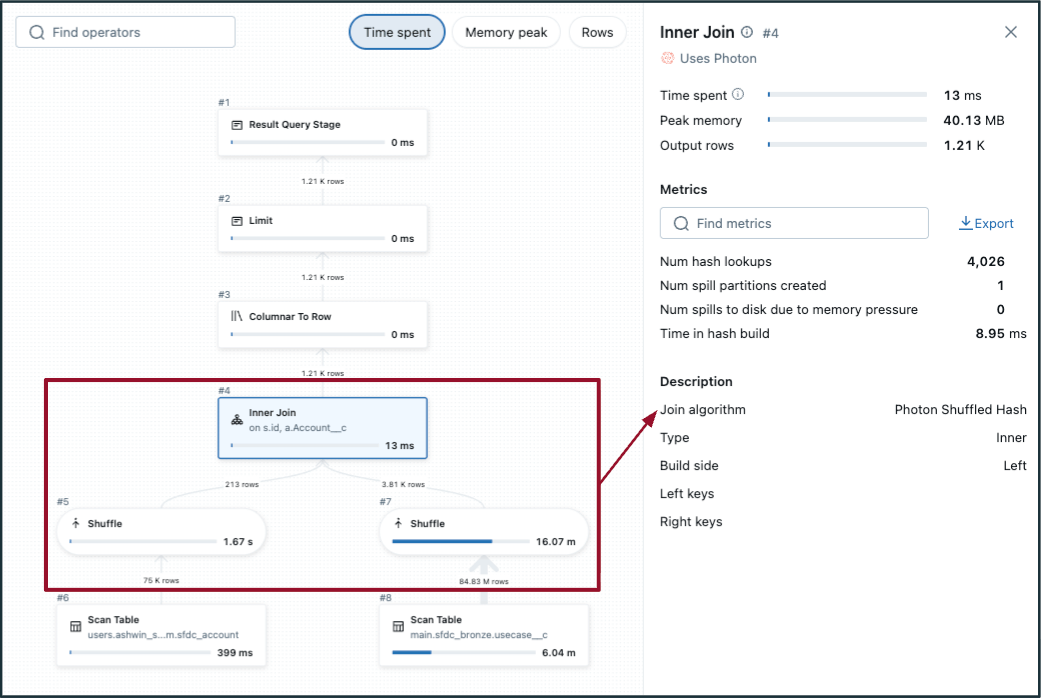 | 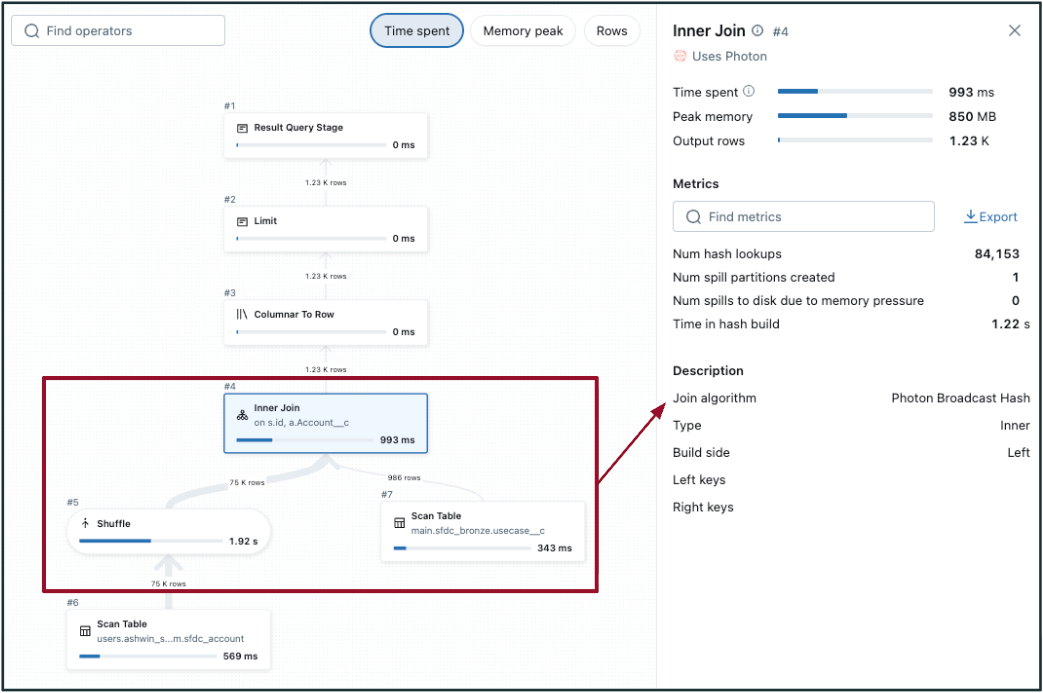 |
最適化とベストプラクティスの実装
パフォーマンスの問題:4つのS + キューイング
新しいワークロードの計算を設定するか、最適化するかに関わらず、最も一般的なパフォーマンス問題を理解することは必要です。これらは一般的なモニカーである「4つのS」に当てはまり、5つ目(キューイング)が追加されます:
SQLウェアハウスのクエリレイテンシを減らすために、スピル、キューイングおよび/またはシャッフル(スキューと小さなファイルは後で取り上げます)が主なパフォーマンスボトルネックであるかどうかを判断します。この包括的なガイドは詳細を提供します。根本原因を特定した後、以下のガイドラインを適用してSQLウェアハウスのサイズを適切に調整し、影響を��測定します。
- ディスクスピル(メモリからディスクへ):SQLウェアハウスがメモリを使い果たし、一時的な結果をディスクに書き込むとスピルが発生します。これはメモリ内処理よりも大幅に遅いです。クエリプロファイルでは、「spill (bytes)」または「spill time」に対する任意の量が、これが発生していることを示しています。
スピルを軽減するために、SQLウェアハウスのTシャツサイズを増やしてメモリを提供します。クエリのメモリ使用量は、早期のフィルタリング、スキューの減少、結合の簡素化などのクエリ最適化技術を通じても減らすことができます。ファイルレイアウトの改善 - 適切なサイズのファイルを使用するか、Liquid Clusteringを適用することで、実行中にスキャンされ、シャッフルされるデータ量をさらに制限することができます。
システムテーブル上のヘルパークエリは、SQLアラートやAI/BIダッシュボードに変換することができます
- クエリキューイング:SQLウェアハウス監視画面が持続的なキューイング(ピーク時のキューイングクエリが>10)を示し、それがオートスケーリングイベントで即座に解決しない場合、ウェアハウスの最大スケーリング値を増やします。キューイングは、クエリが利用可能なリソースを待つため、直接レイテンシを追加します。
システムテーブル上のヘルパークエリは、SQLアラートやAI/BIダッシュボードに変換することができます
- 高並列化/低シャッフル:クエリが多くの独立したタスクに分割可能で、大規模なデータセットに対するフィルターや集計など、Query Profilesで低シャッフルを示す場合、SQLウェアハウスのTシャツサイズを増やすことでスループットを改善し、キューイングを減らすことができます。低シャッフルはノード間のデータ移動が最小限であることを示し、より効率的な並列実行を可能にします。
- 狭い変換(例:ポイントルックアップ、集約ルックアップ)は、一般的には並行クエリ処理のためのより多くのスケーリングから利益を得ます。広い変換(複雑な結合と集約)は、一般的にはウェアハウスのサイズを大きくすることからより多くの利益を得ます。
- High Shuffle:逆に、シャッフルが高い場合、クエリ実行中にノード間で大量のデータが交換されます。これは、結合、集約、または不適切に整理されたデータが原因であることが多いです。これは大きなパフォーマンスのボトルネックになる可能性があります。クエリプロファイルでは、高いシャッフルは"シャッフルバイト書き込み"、"シャッフルバイト読み取り"の大きな値、またはシャッフル関連ステージの長い期間によって示されます。これらの指標が��一貫して高い場合、クエリを最適化するか、物理的なデータレイアウトを改善することが、単純に計算をスケーリングアップするよりも良いです。
システムテーブル上のヘルパークエリは、SQLアラートやAI/BIダッシュボードに変換することができます
マクロモニタリングビューを取る
これらの分析とルールは、クエリがマイクロレベルでウェアハウスにどのように影響を与えるかを理解するのに役立ちますが、サイジングの決定はマクロレベルで行われます。一般的には、前のセクションでの監視機能を有効にして(そしてカスタマイズして)何が起こっているかを特定し、その後、スピル、スキュー、キューイングなどの閾値を設定して、リサイズが必要なときの指標として使用します。これらの閾値を評価して、閾値が満たされる頻度や、通常の運用中に閾値が超えられる時間の割合によって、影響スコアを生成します。いくつかの例を共有するための措置(これらをあなたの具体的なビジネス要件とSLAを使用して定義します):
- ピーク時のキューイングクエリが10を超える時間の割合
- 長期間にわたって最高のシャッフルのトップ5%に入るクエリ、またはピーク使用時に常に最高のシャッフルのトップ5%に入るクエリ
- ディスクにスピルするクエリが��少なくとも20%の期間、または実行の25%以上でディスクにスピルするクエリ
これを認識することは必要であり、考慮すべきトレードオフが存在し、すべてのデータウェアハウスに一概に適用できるレシピが存在するわけではありません。キューレイテンシが問題でない場合、たとえばリフレッシュするための夜間クエリなど、超低並行性のためにチューニングしないで、高レイテンシでのコスト効率を認識します。このブログは、あなたのユニークな実装ニーズに基づいてデータウェアハウスを診断し、チューニングするためのベストプラクティスと方法論についてのガイドを提供します。
レイクハウスでの物理データ(ファイル)レイアウトの最適化
以下に、レイクハウスに保存された物理データファイルの管理と最適化のためのいくつかのベストプラクティスを示します。これらと監視技術を使用して、データウェアハウスの分析ワークロードに影響を与える問題を診断し、解決します。
- 必要に応じてテーブルのデータスキップを調整してください(AWS | Azure | GCP)。デルタテーブルは、デフォルトで最初の32列の最小/最大値やその他の統計メタデータを保存します。この数値を増やすと、DML操作の実行時間が長くなる可能性がありますが、追加の列がクエリでフィルタリングされている場合、クエリの実行時間が短縮される可能性があります。
- 小さなファイルの問題があるかどうかを特定するには、テーブルのプロパティ(numFiles、sizeInBytes、clusteringColumns、partitionColumns)を確認し、Liquid Clusteringを使用した予測的最適化を使用するか、適切に整理されたデータの上でOPTIMIZEコンパクションルーチンを実行します。
- 自動リキッドクラスタリングを有効にし、予測最適化の利点を活用して手動チューニングを排除することが推奨されますが、基本的なベストプラクティスを理解し、手動でチューニングを行う能力を持つことは有用です。以下に、クラスタリング列を選択するための有用な経験則を示します。
- 一つの列から始めます、最も自然に述語として使用されるもの(そして以下の提案を使用して)、明らかな候補がいくつかある場合を除きます。大規模なテーブルだけが>1のクラスタキーから利益を得ることがよくあります。
- 使用する列を優先することは、読み取りを書き込みよりも優先することを意味します。それらは1)フィルタ述語として使用され、2) GROUP BYまたはJOIN操作で使用さ��れ、3) MERGE列で使用されるべきです。
- 一般的に、高いカーディナリティ(ただし、ユニークではない)を持つべきです。UUID文字列のような無意味な値は避けてください、それらの列でのクイックルックアップが必要な場合を除きます。
- パーティション列を設定するときのように、カーディナリティを減らさない(例えば、タイムスタンプを日付に変換する)。
- 関連する2つの列(例えば、タイムスタンプとデートスタンプ)を使用しないでください。常に高いカーディナリティを持つ方を選択します。
- CREATE TABLE構文のキーの順序は関係ありません。多次元クラスタリングが使用されています。
すべてをつなぐ:体系的なアプローチ
本ブログでは、データウェアハウス設計における3つの主要なアーキテクチャ上の要素に焦点を当てています。
ただし、高並行性・スケーラビリティ・低レイテンシを備えたデータウェアハウスを構築するためには、これ以外にもETL/ELT、インフラ構成、DevOps、ガバナンスといった重要な要素が関わります。
レイクハウス実装に関する製品視点の詳細はここをご覧ください。また、Databricks、Spark、Delta Lakeワークロードを最適化するための包括的ガイドでも、豊富なベストプラクティスを紹介しています。
データウェアハウスの基盤を構成する「コンピュート」「データレイアウト」「モデリング/クエリ設計」は密接に関連しています。
性能を最適化するためには、モニタリング・最適化・新規ワークロードの標準化を継続的に行う反復的なプロセスが不可欠です。
さらに、技術の進化やビジネス要件の変化に合わせて、最適化の指針(ブループリント)も進化させる必要があります。
つまり、求める同時実行性能・レイテンシ・スケーラビリティに応じてデータウェアハウスをチューニングできるツールとノウハウを持つことが重要です。
その中核を支えるのが、堅牢なガバナンス、透明性の高いモニタリング、そして強固なセキュリティです。
これらは個別の検討項目ではなく、Databricks上で最高水準の�データウェアハウス体験を実現するための“土台”となります。
次に、このフレームワークと基本的なベストプラクティス、チューニングおよびモニタリング手法を実際に適用し、データウェアハウスのパフォーマンスと効率を大幅に改善した顧客事例を見ていきましょう。
リアルワールドのシナリオとトレードオフ
メールマーケティングプラットフォームの最適化
ビジネスコンテキスト
メールマーケティングプラットフォームは、豊富な顧客データに基づいてパーソナライズされた顧客旅行を作成するためのツールをeコマース小売業者に提供します。このアプリケーションは、ユーザーがターゲットとなるオーディエンスに対するメールキャンペーンを組織化し、クライアントがセグメンテーション戦略を策定し、パフォーマンスを追跡するのを支援します。リアルタイムの分析は彼らのビジネスにとって重要であり、顧客はクリックスルーレート、バウンス、エンゲージメントデータなどのキャンペーンパフォーマンス指標に対する即時の可視性を期待しています。
初期の課題
プラットフォームは、分析インフラストラクチャのパフォーマンスとコストの問題を経験していました。彼らは大規模なSQLサーバーレスウェアハウスを1-5クラスターでオートスケーリングし、ピーク時にはXLにアップグレードする必要がありました。彼らのアーキテクチャは以下に依存していました:
- メッセージキューからデルタレイクへのリアルタイムストリーミングデータを、連続した構造化ストリーミングを介して
- ストリーム化されたレコードを履歴テーブルに統合するための夜間ジョブ
- 履歴テーブルとストリーミングデータ間のクエリ時のユニオン
- クエリ時間に実行される複雑な集約と重複排除ロジック
このアプローチは、各顧客ダッシュボードのリフレッシュが集中的な処理を必要とし、コストが高くなり、応答時間が遅くなることを意味しました。
SQLウェアハウスの監視から、大量のキューイング(黄色の列)があり、使用が突発的に発生する期間があり、オートスケーリングが適切に動作していましたが、ワークロードに追いつくことができませんでした:

キューイングの原因を診断するために、クエリ履歴(AWS | Azure | GCP)とシステムテーブルを使用して、キューイングが単に比較的基本的で狭いクエリの高いボリュームによるものか、またはパフォーマンスの低いクエリを改善するための最適化が必要だったかを判断しました。
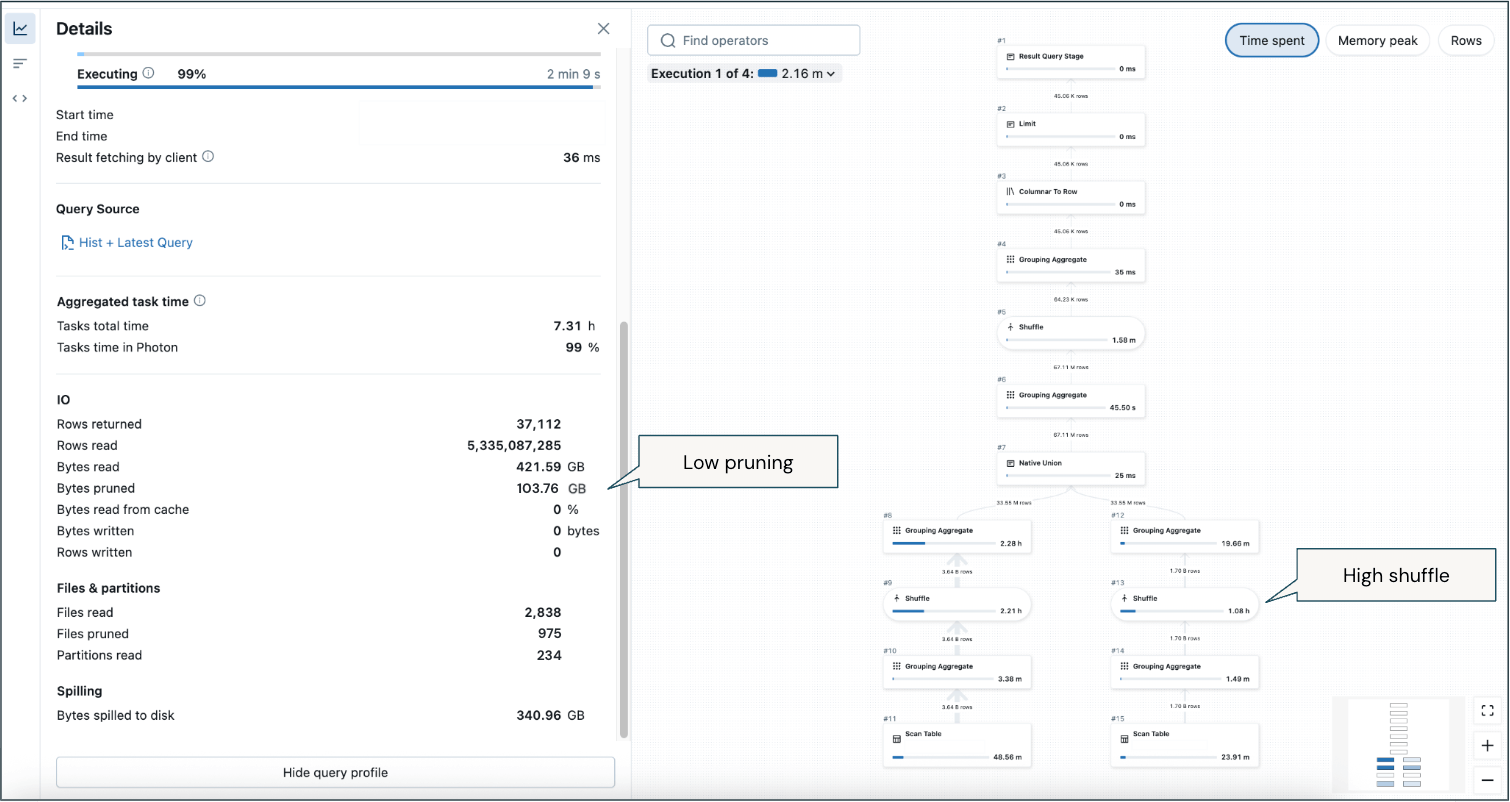
この長時間実行されたクエリのプロファイルからのいくつかの重要なポイント:
- 低いプルーニング(最新の2週間を返すための時間期間に対する大幅なフィルタリングにもかかわらず)は、大量のデータがスキャンされていることを意味します。
- 高シャッフル—分析的な集約により必然的にシャッフルが発生しますが、過去のデータと最近のデータのメモリ使用の大部分です。
- 一部のインスタンスではディスクにスピルします。
これらの学びは、重要なクエリを観察することから、計算、データレイアウト、クエリ技術にわたる最適化アクションにつながりました。
最適化アプローチ
Databricksのデリバリーソリューションアーキテクトと協力して、プラットフォームはいくつかの重要な最適化を実装しました:
- マージ頻度の増加:夜間から毎時のマージに変更し、クエリ時間に処理が必要なストリーミングデータの量を大幅に削減しました。
- マテリアライズドビューの実装:集計テーブルを毎時インクリメンタルにリフレッシュするマテリアライズドビューに変換し、リフレッシュ時に複雑な集計ロジックを事前計算し、クエリ時間の処理を最新の1時間分のデータに限定します。
- 現代的なデータの組織化:Hiveスタイルのパーティショニングから自動液体クラスタリングに切り替え、クエリパターンに基づいて最適なクラスタリング列を選択し、時間とともに適応します。
結果
6週間の発見と実装プロセスの後、プラットフォームはデプロイ後すぐに顕著な改善を見ました:
- インフラコストの削減:大規模なサーバーレスウェアハウスから自動スケーリングなしの小規模なサーバーレスウェアハウスにダウンサイズしました。
- クエリパフォー�マンスの改善:エンドユーザーダッシュボードのレイテンシを低減し、顧客体験を向上させます。
- 操作の効率化:頻繁なエンドユーザーのパフォーマンスの苦情とサポートケースからの運用オーバーヘッドを排除しました。
最適化後のクエリプロファイルの例:
- ファイルレイアウトが最適化されると、より多くのファイルプルーニングが行われ、読み取る必要があるデータ/ファイルの量が減少しました。
- ディスクへのスピルはありません。
- 分析的な集約によりシャッフルが依然として発生しますが、より効率的なプルーニングと、ランタイムで計算する必要のない事前集約された要素により、シャッフルの量は大幅に減少します。

この変換は、データモデリングのベストプラクティスを適用し、サーバーレス計算を活用し、Databricksの高度な機能を利用することで、パフォーマンスとコスト効率を大幅に向上させることができます。
主要なポイント
- データウェアハウスの同時実行性、レイテンシ、スケールに焦点を当てた要件を設定してください。その後、ベストプラクティス、観測可能性の機能、およびチューニング技術を使用して、これらの要件を満たします。
- コンピュートの適正サイズ化、強力なデータレイアウトの実践(AIによって大幅に支援)およびデータモデルとクエリの対処を優先にすることに焦点を当てます。
- 最高のデータウェアハウスはDatabricksのレイクハウスです。新機能につながる革新的なアプローチと、基本的なデータウェアハウスの原則を組み合わせて利用します。
- AI/MLを犠牲にせずに伝統的なデータウェアハウスのニーズを満たす(Databricksを使用してそれらを活用しています)。
- 盲目的にサイズを決めたり、チューニングを行わないでください。組み込みの観測性を活用して、コスト節約のアクションを監視、最適化、自動化します。
- BIと分析ワークロードの典型的な変動する使用パターンをサポートし、最適な価格パフォーマンスを提供するためにDatabricks SQL Serverlessを採用します。
次のステップと参考リソース
高並行性、低レイテンシのデータウェアハウスをスケールさせることは、型にはまったレシピを追うことで実現するものではありません。考慮すべきトレードオフがあり、多くのコンポーネントがすべて一緒に働きます。データウェアハウジング戦略を確立しているか、実装中でライブに行くのに苦労しているか、現在のフットプリントを最適化し�ているかに関わらず、このブログで概説したベストプラクティスとフレームワークを考慮して、全体的に取り組むことを検討してください。Databricksがあなたのデータウェアハウスのニーズをすべてサポートする方法について話し合うために、お気軽にお問い合わせください。
Databricks Delivery Solutions Architects (DSAs)は、組織全体のデータとAIのイニシアチブを加速します。彼らはアーキテクチャリーダーシップを提供し、プラットフォームのコストとパフォーマンスを最適化し、開発者の経験を向上させ、プロジェクトの成功を推進します。DSAsは初期のデプロイメントと本番用のソリューションの間のギャップを埋め、データエンジニアリング、技術リーダー、エグゼクティブ、その他のステークホルダーを含むさまざまなチームと密接に連携して、カスタマイズされたソリューションとより早い価値の実現を確保します。DSAからのカスタム実行計画、戦略的ガイダンス、データとAIの旅程全体でのサポートを受けるために、Databricksアカウントチームにお問い合わせください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。