教師あり学習と教師なし学習:各機械学習アプローチの違いと能力の理解
によって Databricks Staff による投稿
- 教師あり学習と教師なし学習は異なる目的を果たします。教師あり学習はラベル付きデータを使用して正確な予測と分類を行いますが、教師なし学習は生のラベルなしデータから隠れたパターンを見つけるため、それぞれ異なるビジネス目標に適しています。
- 最新のMLは両方の方法論を融合させています。半教師あり学習や自己教師あり学習のような技術は、それぞれのパラダイムの強みを組み合わせています。
- 真の課題はシステム構築にあります。エンタープライズMLの成功は、信頼性の高いデータパイプライン、強力なガバナンス、およびモデルライフサイクル全体を通じた継続的な評価の中で、両方の方法論をオーケストレーションすることにかかっています。
機械学習システムは、データから学習して予測を行ったり、情報を分類したり、人間が手動で特定するのが難しいパターンを発見したりします。
教師あり学習とは?
教師あり学習では、モデルはラベル付きデータを使用してトレーニングされます。このデータでは、各入力に既知の出力がペアになっています。モデルは、予測をこれら��の正解と比較し、繰り返し誤差を減らすことで学習します。
このプロセスの中心には、特徴と結果の間の明示的な関係を学習する機械学習モデルがあります。ラベル付きデータの存在は明確なガイダンスを提供するため、教師あり学習は、精度、トレーサビリティ、再現性が不可欠な問題に適しています。
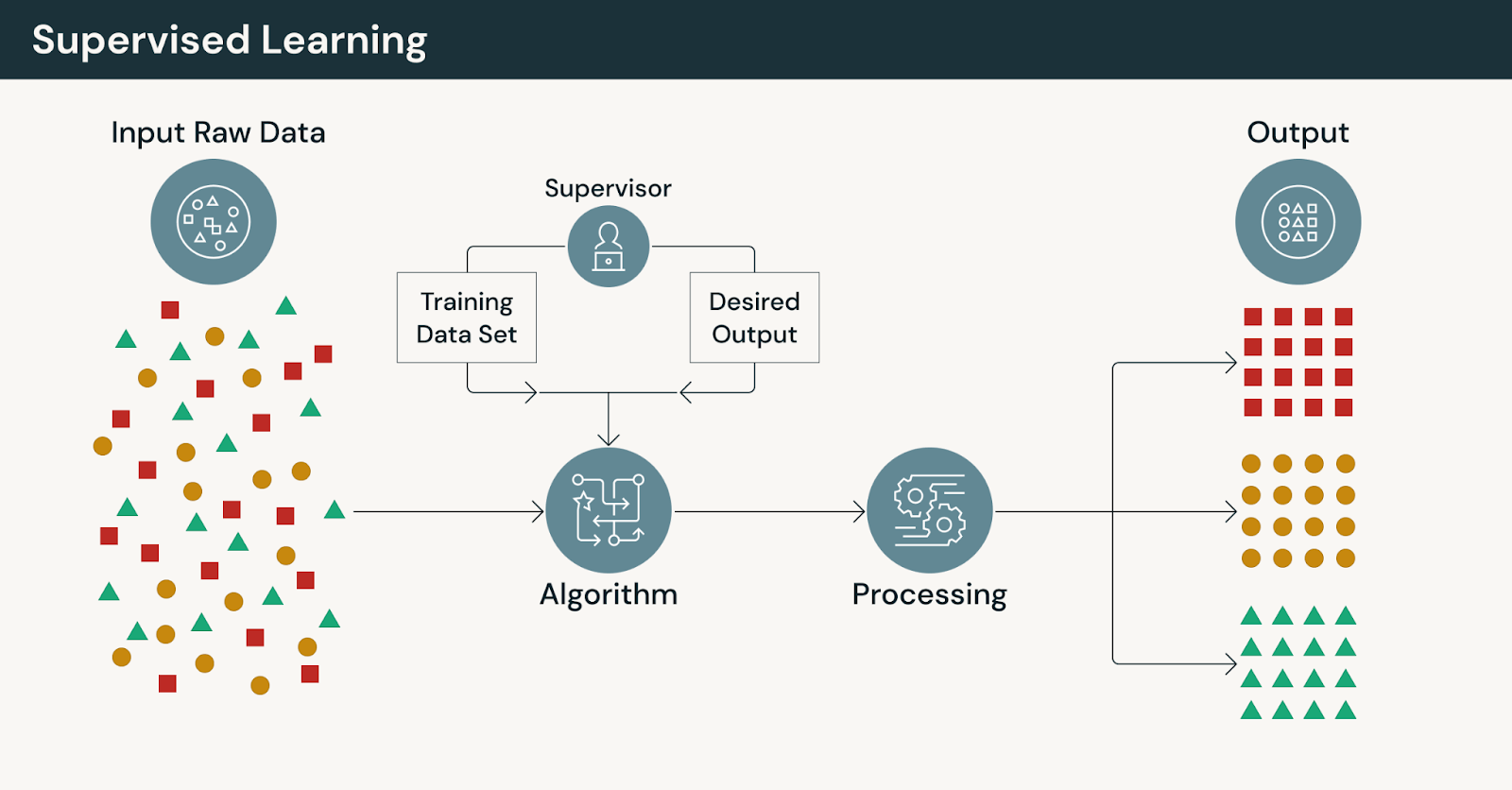
教師あり学習の仕組み
典型的な教師あり学習ワークフローには、次のものが含まれます。
- 既知の結果を持つ過去のトレーニングデータの収集
- ラベル付きトレーニングデータセットの準備と検証
- 関連するシグナルを捉える特徴量のエンジニアリング
- グラウンドトゥルースに対するモデルのトレーニングと評価
- モデルのデプロイとパフォーマンスの経時的な追跡
このワークフローは、ラベルの可用性と品質に依存します。これは、データ量が増加するにつれて、制約が顕著になることがよくあります。
教師あり学習の種類
教師あり学習の問題は、一般的に2つのカテゴリに分類されます。
- 分類:スパムメールと正規メール、またはポジティブとネガティブの感情のように、入力データを事前定義されたクラスに割り当てること。
- 回帰:需要予測、価格設定、リスクスコアなどの連続値を予測すること。輸送会社は、過去のルートパフォーマンス、季節パタ��ーン、運用要因に基づいてフライト時間を予測するために回帰モデルを使用し、スケジューリングの最適化と正確な顧客期待の設定を支援します。
どちらの場合も、モデルのパフォーマンスは既知の結果に対して直接測定できるため、評価と説明責任が簡素化されます。
一般的な教師あり学習アプリケーション
教師あり機械学習は、一般的に次のような目的で使用されます。
- メールフィルタリングとコンテンツモデレーション
- 顧客フィードバックにおける感情分析
- 予測と予測分析
- 画像とドキュメントの分類
多くの自然言語処理アプリケーションは、汎用モデルをドメイン固有のタスク、ポリシー、または語彙に適応させるために、教師ありファインチューニングに依存しています。
業界を横断する教師あり学習
教師あり学習アプリケーションは、事実上すべてのセクターにまたがっており、一部のユースケースは最新のデジタルインフラストラクチャの基盤となっています。
サイバーセキュリティ:スパム検出システムは、正規メッセージと悪意のあるメッセージのラベル付き例でトレーニングされた教師ありモデルを使用して、毎日数十億通のメールを分析します。最新のスパム検出は、単純なキーワードマッチングを超えて、送信者の評判、メッセージ構造、添付ファイルの分析、および行動パターンを組み込んでいます。
ヘルスケアとライフサイエンス:教師あり学習は、ラベル付きの生物医学およびゲノムデータで�予測モデルをトレーニングして、疾患関連のバリアントと治療ターゲットに関連付けられたパターンを特定することを含みます。これらのモデルをスケーラブルな分析プラットフォーム内で適用することにより、研究者は遺伝的特徴と臨床結果の関係を定量化し、薬物ターゲットのより正確な予測を可能にし、仮説駆動型の発見を加速することができます。
金融サービス:教師あり学習は、ラベル付きの過去のトランザクションデータでリスクおよび不正検出モデルをトレーニングするために使用され、システムが正規の活動と疑わしい活動を区別できるようにしました。既知の結果(確認された不正ケースや検証済みの顧客行動など)から学習することにより、モデルは誤検知を減らしながらリアルタイム検出精度を向上させました。スケーラブルなデータプラットフォーム内にデプロイされたこれらの教師ありモデルは、より迅速な意思決定とより回復力のある金融リスク管理をサポートしました。
小売および消費財:ラベル付きの過去の販売、価格設定、プロモーションデータを使用して、需要を予測し、在庫決定を大規模に最適化するために予測モデルがトレーニングされました。既知の結果(過去の製品の動きや地域需要パターンなど)から学習することにより、システムは数千の場所で予測精度を向上させました。これにより、より正確な補充、在庫切れの削減、サプライチェーン運用と顧客需要との間のより緊密な連携が可能になりました。
顧客体験:顧客のインタラクションとプロファイルデータの統合およびラベル付きデータで予測モデルがト��レーニングされ、オーディエンスをセグメント化し、顧客行動を予測するのに役立つパターンを学習しました。これらの教師ありモデルは、より正確な顧客インサイトを可能にし、ターゲットマーケティングおよびパーソナライゼーション戦略をサポートしました。これにより、チャネル全体で顧客エンゲージメントとエクスペリエンスを向上させる実行可能なインサイトの提供が迅速化されました。
メディアおよびエンターテイメント:ラベル付きのゲームプレイ、エンゲージメント、および行動データを使用して、プレイヤーのアクティビティとコンテンツインタラクションのパターンを特定する予測モデルをトレーニングしました。既知の結果(チャーンシグナル、ゲーム内行動、コミュニティトレンドなど)から学習することにより、システムはより正確な予測と迅速なコンテンツ最適化を可能にしました。これにより、プレイヤーエクスペリエンスの向上、ライブオペレーションの意思決定の改善、グローバルなゲームエコシステム全体でのデータ駆動型の開発がサポートされました。
各アプリケーションには共通の要件があります。問題空間を正確に表す信頼性の高いラベル付きトレーニングデータと、モデルのパフォーマンスが低下したときに検出するための継続的な監視です。
教師なし学習とは?
ラベル付き例から学習する代わりに、教師なし機械学習はラベルなしデータを分析して、事前定義されたターゲットなしでパターン、構造、または関係を特定します。
これにより、MLプロジェクトの初期段階で、チームがまだ尋ねるべき質問を知らない場合、またはラベル付けが非現実的または費用がかかりすぎる場合に、教師なし学習が特に価値が高くなります。
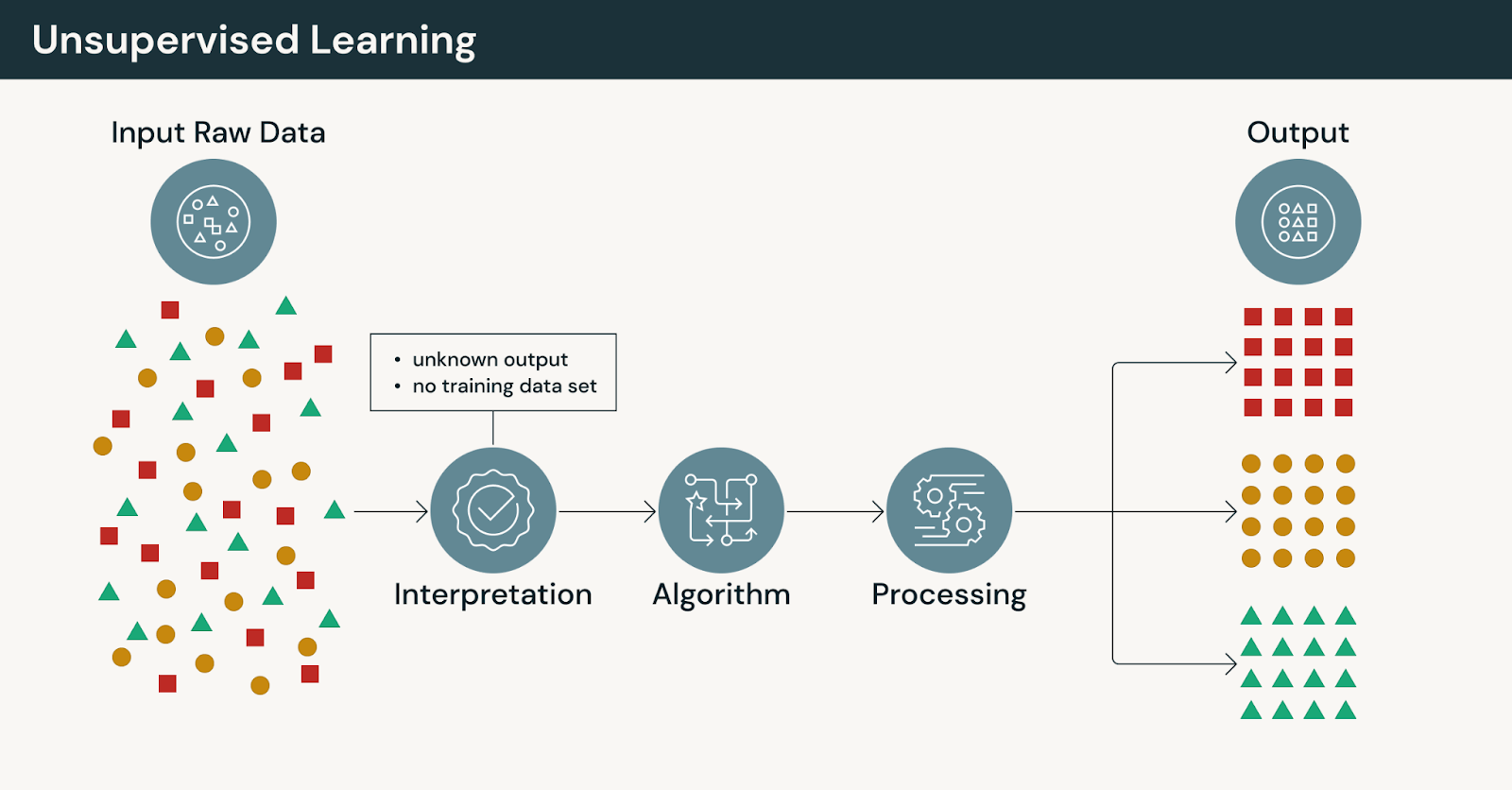
教師なし学習の仕組み
教師なし学習では:
- モデルは、明示的な人間提供のラベルなしで動作します
- アルゴリズムは、類似性に基づいてデータをグループ化、圧縮、または整理します
- 出力には、ドメインエキスパートによる解釈と検証が必要です
正解がないため、教師なし学習は予測よりも探索を重視します。
教師なし学習の種類
一般的な教師なし手法には、次のものがあります。
- クラスタリング:類似のデータポイントをグループ化して構造を明らかにすること
- 次元削減:分析のために複雑なデータセットを単純化すること
- アソシエーションルール学習:変数間の関係を特定すること
これらの手法の多くは、事前に明示的に定義されていなかったパターンを表面化するために、クラスタリングアルゴリズムに依存しています。
一般的な教師なし学習アプリケーション
教師なし機械学習は、次のような目的で広く使用されています。
- マーケティングおよびパーソナライゼーションにおける顧客セグメンテーション戦略。事前に定義されたカテゴリでは�なく、行動、好み、価値によって類似のデータポイントをグループ化するためにクラスタリングを使用します。
- 不正防止および運用監視のための異常検出システム
- 探索的データ分析および行動パターン発見
- 大規模な類似性検索とグループ化
- マーケットバスケット分析および製品推奨システム。Aprioriアルゴリズムなどのアルゴリズムは、どのアイテムが関連付けられるべきかを指示されずに、購入パターンと製品の関連性を発見します。
組織がより多くの生データを蓄積するにつれて、教師なし学習は、網羅的なラベリング作業を待つことなく価値を抽出する方法を提供します。
教師あり学習と教師なし学習の主な違い
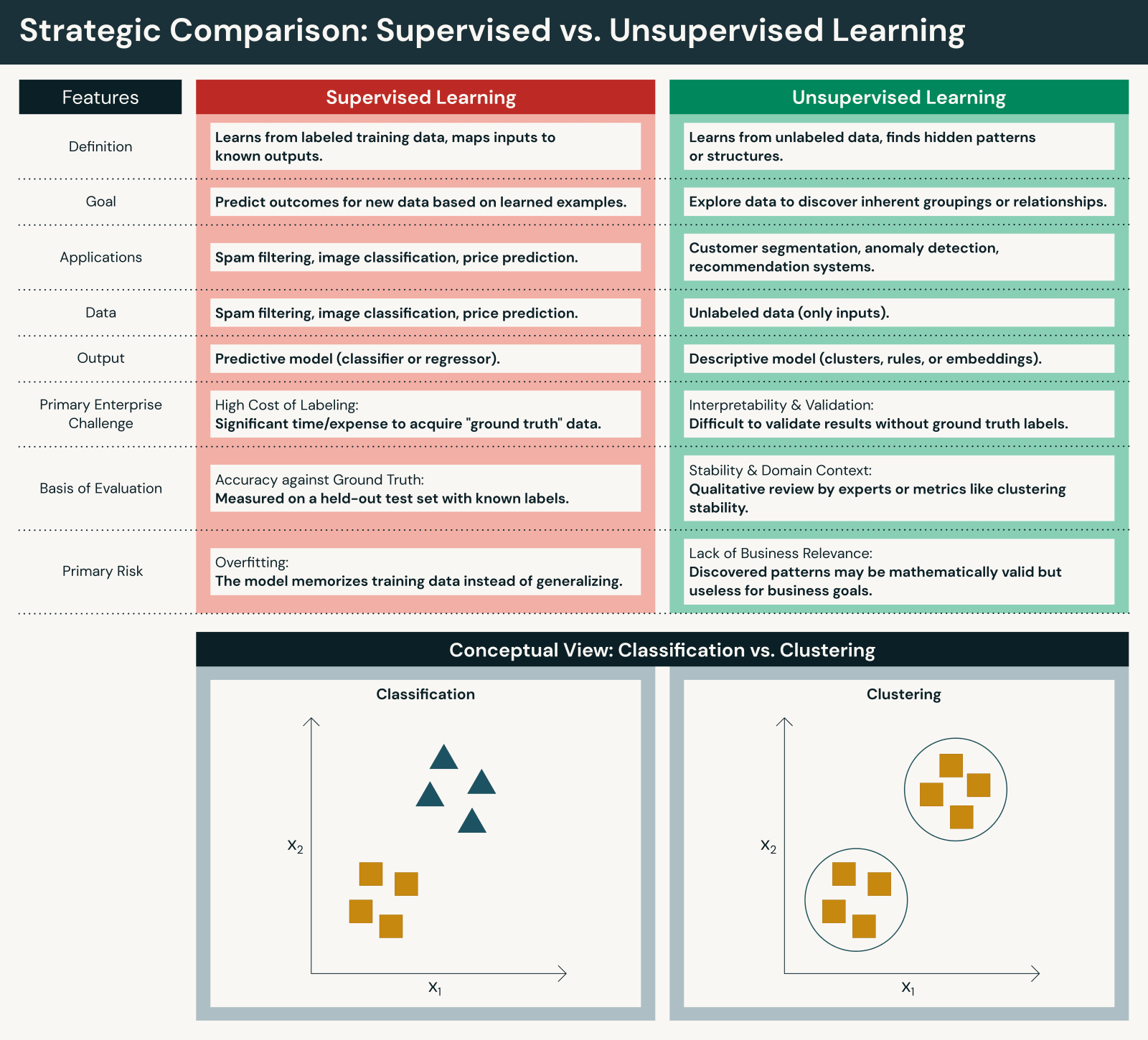
どちらのアプローチも基本的ですが、重要な点で異なります。
データと人的労力
- 教師あり学習は、手動アノテーションまたは専門家レビューを通じて作成されることが多いラベル付きデータセットを必要とします。教師あり機械学習はラベリングにかなりの人的介入を必要としますが、この人的介入は、精度がビジネス目標と一致することを保証します。
- 教師なし学習は生データで直接動作するため、初期準備は削減されますが、解釈の労力は増加します。教師なし機械学習はトレーニング中の人的介入を減らしますが、結果の解釈には人的介入が必要です。
目的
- 教師あり学習は、既知の結果に対する予測と分類に焦点を当て、精度高く結果を予測します。
- 教師なし学習は、データ内のパターンを発見するために、発見と洞察の生成に焦点を当てます。
評価と透明性
- 教師ありモデルは、正解(正解率、適合率、再現率、F1、RMSEなど)に対する明確なパフォーマンス指標を使用して評価できます。
- 教師なし学習モデルは、有用性を評価するために間接的な評価とドメインコンテキスト(シルエットスコア、エルボー法、ドメイン専門家による検証など)を必要とします。
スケーラビリティ
- 教師あり学習は、ラベリングの制約により、多くの場合、よりゆっくりとスケールします。
- 教師なし学習は、データ量に応じて自然にスケールしますが、ノイズの多い結果を生成する可能性があります。
エンタープライズ環境では、これらの主な違いにより、チームは排他的な選択ではなく、ハイブリッドアプローチを採用するようになります。
エンタープライズ向けエージェントAIプレイブック

半教師あり学習と自己教師あり学習
最新のMLシステムは、ますますパラダイムを融合させています。
半教師あり学習は、少量のラベル付きデータセットと、はるかに大きなラベルなしデータのプールを組み合わせて、ラベリングコストを削減しながら予測精度を維持します。
自己教師あり学習は、モデルが生のデータから独自のトレーニングシグナルを生成できるようにすることで、さらに一歩進んでいます。このアプローチは、多くの最新の基盤モデルを支えており、教師あり学習を開始点ではなく、洗練の役割へと移行させました。
これらの手法により、組織は次のことが可能になります。
- 既存のデータ資産を大規模に活用する
- 新しいデータ分布に迅速に適応する
- 手動ラベリングへの依存を減らす
教師あり学習と教師なし学習が、機械学習のすべての領域を表すわけではないことに注意する価値があります。強化学習は、エージェントが環境との試行錯誤の相互作用を通じて最適な行動を学習し、その行動に対して報酬またはペナルティを受け取る3番目の主要なパラダイムです。強化学習は教師あり対教師なしのスペクトラムの外にありますが、最新のシステムは、タスクの要件に応じて、これら3つのアプローチすべてをますま��す組み合わせています。
教師あり学習と教師なし学習の使い分け
実際には、適切な選択は、データ、目標、および運用上の制約によって異なります。
データを評価する
- 信頼できるラベルはありますか?
- データが増加しても、ラベリングの品質を維持できますか?
- データの変更頻度はどのくらいですか?
目標を定義する
- 結果を予測しますか?教師あり学習が適しています。
- 未知の構造を探求しますか?教師なし学習は、多くの場合、適切な出発点です。
ライフサイクル全体を計画する
アプローチに関係なく、成功するシステムは、データが取り込みからトレーニング、そして本番環境まで一貫して移動する信頼性の高いデータエンジニアリングパイプラインに依存します。
多くのチームは、教師なし探索から始め、ターゲットとメトリックが明確に定義されたら、教師あり学習を導入します。
エンタープライズML戦略における統一されたデータとAIガバナンスが重要な理由
MLシステムがスケールするにつれて、エンタープライズはアクセス、リネージ、コンプライアンス、およびアカウンタビリティを管理する必要があります。
ここで統一されたデータガバナンスが重要になります。ワークフロー全体でデータとモデルを一貫して管理することで、洞察が信頼でき、システムが進化しても監査可能であることが保証されます。
よくある質問への回答
線形回帰は教師あり学習ですか、それとも教師なし学習ですか?
線形回帰は、ラベル付きの出力値を必要とするため、教師あり学習です。
教師あり学習と教師なし学習の主な違いは何ですか?
教師あり学習は、ラベル付きデータを使用して既知の結果を予測します。教師なし学習は、ラベルなしデータでパターンを発見します。
今後知っておくべきこと
いくつかのトレンドがエンタープライズMLを再形成しています。
- 自己教師あり学習は、基盤モデルのトレーニングを支配しています。
- 教師あり学習は、ますます精度レイヤーとして機能しています。
- クラスタリングと埋め込みは、主要なエンタープライズ機能になりつつあります。
- ラベルなしデータの使用が拡大するにつれて、評価とガバナンスの重要性が増しています。
これらのシフトは、サイロではなくシステムで考える必要性を強化します。
課題と限界
教師あり学習と教師なし学習はどちらもエンタープライズMLで重要な役割を果たしますが、それぞれにトレードオフがあり、チームは早期に計画を立てる必要があります。
教師あり学習の課題
データ要件が最大の制約となることがよくあります。特にラベリングにドメインの専門知識が必要な場合、ラベル付きデータセットの作成は時間と費用がかかる可能性があります。多くの場合、モデルの精度はラベルの品質に直接結びついているため、一貫性のない、または偏ったアノテーションは深刻なリスクとなります。
教師ありモデルは、過学習のリスクにも直面します。モデルがトレーニングデータに近すぎる学習をすると、評価��ではうまく機能しても、新しいデータや未知のデータに一般化できない可能性があります。一般的な緩和策には、クロスバリデーション、正則化手法、および実際の変動をよりよく反映するためのトレーニングデータセットの拡張が含まれます。
データ量が増加すると、スケーラビリティの懸念が生じます。人間参加型のラベリングは線形にスケールせず、手動プロセスは大規模または急速に変化するプロジェクトのボトルネックになる可能性があります。慎重な計画なしに、教師ありワークフローはビジネスの要求に追いつくのに苦労する可能性があります。
教師なし学習の課題
教師なし学習は、解釈の難しさから始まり、異なる一連の問題を導入します。ドメインコンテキストなしでは、クラスタやパターンに明白な意味がない場合があり、発見された構造が常にビジネス目標と一致するとは限りません。価値を引き出すには、データサイエンティストと主題専門家との緊密な協力が必要になることがよくあります。
検証の複雑さも課題です。正解ラベルがないため、モデルの品質を客観的に評価することは困難な場合があります。チームは、結果に対する信頼を構築するために、プロキシメトリック、ビジネスとの整合性、または複数のアルゴリズムにわたる比較評価に依存することがよくあります。
最後に、アルゴリズムの選択には実験が必要です。結果は、パラメータの選択、距離測定、または前処理ステップによって大きく異なる可能性があるため、イテレーションは避けられません。
機械学習のベストプラクティス
両方の方法に共通するいくつかのプラクティスは、一貫して結果を向上させます。
- 欠損値や外れ値の適切な処理を含む、高品質の入力データを確保する
- アプローチを選択する前に、明確な問題定義から始める
- 早期にデータ品質チェックと検証プロセスを実装する
- 各パラダイムに適切な評価メトリックを使用する
- 本番ワークフローにコミットする前に、探索的データ分析から始める
信頼性の高いデータエンジニアリングソリューションは、これらのプラクティスを一貫して適用するための基盤を提供し、チームがより自信を持って実験から本番環境へと移行するのに役立ちます。
2026年に知っておくべきこと
いくつかのシフトがすでにエンタープライズMLの実践を再形成しています。
1. 自己教師あり事前トレーニングが、ほとんどの最新基盤モデルを支えています
ほとんどの最先端モデル(大規模言語モデル、コンピュータビジョンシステム、マルチモーダルアーキテクチャなど)は、現在、主に自己教師あり学習を使用してトレーニングされています。これらのモデルは、人間がラベル付けしたデータセットに依存するのではなく、シーケンスの次のトークンを予測したり、入力の一部をマスクして再構築したりするなど、生のデータから独自のトレーニングシグナルを生成します。
このシフトは、実用的な現実を反映しています。エンタープライズは膨大な量のラベルなしデータを所有していますが、大規模なラベリングはコストがかかり、遅くなります。自己教師あり学習により、組織は既存のデータ資産から価値を引き出し、後で特定のタスクに適合できる表現を構築できます。
2. 教師ありファインチューニングは、洗練の役割に移行しました
教師あり学習は消えたわけではありませんが、その役割は変化しました。主なトレーニングメカニズムとして機能するのではなく、教師ありファインチューニングは、明確に定義されたビジネス目標のためにモデルを洗練、調整、および検証するためにますます使用されています。
このアプローチにより、チームは、パイプラインの早い段階での不要なラベリングを回避しながら、規制要件、安全上の制約、またはドメイン固有の精度など、精度が最も重要な場所にラベリング作業を集中させることができます。
3. 埋め込みは、主要なエンタープライズ機能になりました
埋め込みは、主要なエンタープライズインフラストラクチャになりました。基盤モデルは、テキスト、画像、音声、および構造化データ全体にわたる意味的意味を捉えるベクトル埋め込みをますます出力しています。これらの埋め込みは、大規模な類似性検索、検索、パーソナライゼーション、異常検出、およびレコメンデーションシステムを強化します。
クラスタリングやその他の類似性ベースの方法は重要ですが、それらは埋め込みのダウンストリームアプリケーションであり、ピアパラダイムではありません。戦略的なシフトは、クラスタリング自体ではなく、最新の統一されたデータプラットフォーム内で検索、検索、および推論を統合する埋め込み中心のアーキテクチャに向けられています。
組織がAIを運用化するにつれて、埋め込みは、自己教師あり�事前トレーニング、教師ありファインチューニング、およびダウンストリームアプリケーション間の接続組織になります。これらは、最新の統一されたデータプラットフォーム内で、探索と精度の両方のワークフローをサポートする共通の表現レイヤーを提供します。
サイロではなくシステムを構築する
教師あり学習と教師なし学習は異なる問題を解決します。そして、最新のMLシステムには両方が必要です。教師あり機械学習は、ラベル付きデータがあり、正確で説明責任のある予測または分類が必要な場合に優れています。教師なし機械学習は、目標が発見であり、定義済みの出力なしに生のデータ内のパターンと洞察をチームが発見するのに役立つ場合に効果を発揮します。ラベル付きデータが限られている場合、半教師あり学習アプローチは両方のパラダイムを組み合わせてギャップを埋めます。
真の課題は、教師あり学習と教師なし学習のどちらかを選択することではなく、アプローチを組み合わせ、時間の経過とともに進化し、本番環境で確実に運用できるシステムを構築することです。効果的なチームは、データの可用性を評価し、主な目標が予測なのか探索なのかを明確にし、各アプローチをサポートするために必要なリソースを評価することから始めます。
機械学習戦略は静的なことはめったにありません。教師なし探索は、後の教師ありモデル開発に情報を提供することが多く、教師ありファインチューニングは、より広範な表現に基づいて構築されたシステムに精度と検証をもたらします。時間の経過とともに、洞察はビジネスインテリジェンスと分析に流れ込み、そこで意思決定に情報を提供し、成果を推進する必要があります。
さらに詳しく知りたい場合は、これらのリソースをご覧ください。
- LLMのファインチューニングと事前トレーニングのコンパクトガイド — LLMのファインチューニングと事前トレーニングのテクニックを学びましょう
ガイドを入手 - 生成AIのビッグブック — 本番品質のGenAIアプリケーションを構築するためのベストプラクティス
ダウンロード - 機械学習ユースケースのビッグブック — 機械学習を機能させるために必要なすべてを入手しましょう
今すぐ読む
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。