LLMOpsとは何ですか?
微調整、迅速なエンジニアリング、評価、AIガバナンスを考慮した、本番環境でのLLMの開発、展開、管理のためのプラクティスとツール
によって Databricks Staff による投稿
- 基盤モデルの選択、微調整戦略(フル微調整、PEFT、LoRA)、プロンプトエンジニアリング、検索拡張生成(RAG)パイプライン、マルチモデルアンサンブルオーケストレーションなど、LLM固有のワークフローに対応します。
- 指標(パープレキシティ、BLEU、ROUGE、ヒューマンフィードバック)、A/Bテスト、安全性のためのレッドチーム演習、バイアス検出、体系的な実験によるプロンプト最適化を通じてモデルのパフォーマンスを測定する評価フレームワークを実装します。
- 推論レイテンシ、トークン消費コスト、出力品質のドリフト、毒性スコア、ユーザー満足度を追跡しながら、モデルのバージョン管理、ロールバック機能、AIガバナンスポリシーへの準拠を管理しながら、本番環境のデプロイメントを監視します。
LLMOps とは
大規模言語モデル運用(LLMOps)には、運用環境における大規模言語モデルの運用管理に使用されるプラクティス、テクニック、ツールが含まれます。
OpenAI の GPT、Google の Bard、Databricks の Dolly などのリリースに象徴されるように、LLM の�最新の進歩は、LLM を構築し展開する企業の著しい成長を促していいます。そのため、これらのモデルの運用方法に関するベストプラクティスを構築する必要性が生じています。LLMOps は、大規模な言語モデルの効率的なデプロイメント、モニタリング、メンテナンスを可能にします。LLMOps は、従来の機械学習運用(MLOps)と同様に、データサイエンティスト、DevOps エンジニア、IT プロフェッショナルのコラボレーションを必要とします。LLMOps の構築方法については、こちらをご覧ください。
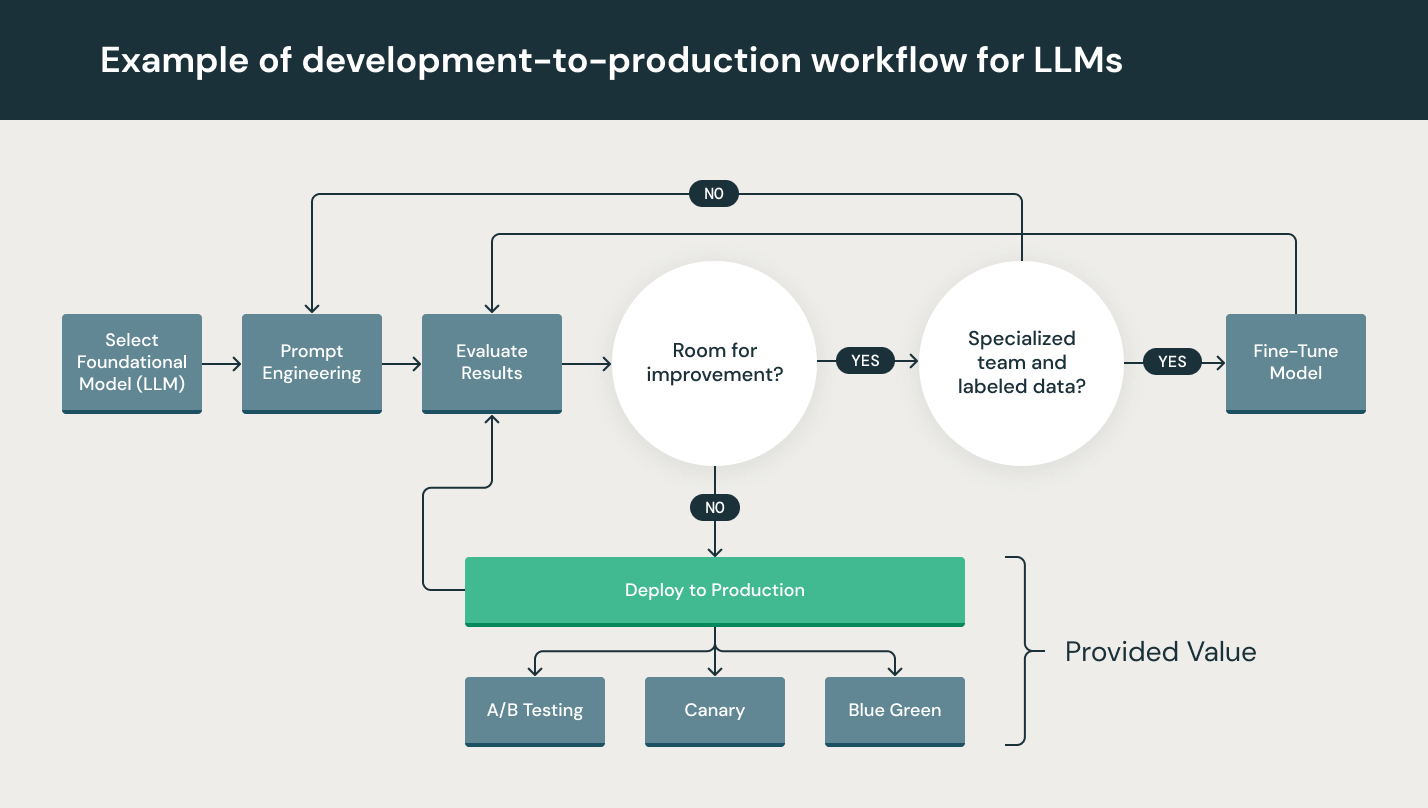
大規模言語モデル(LLM)は、自然言語処理(NLP)モデルの新しいクラスであり、オープンな質問応答から要約、任意に近い指示に従うといったさまざまなタスクにおいて、従来の技術水準から大きく飛躍しています。MLOps の運用要件は通常、LLMOps にも当てはまりますが、LLM のトレーニングと配備には課題があり、LLMOps 独自のアプローチが必要になります。
LLMOps と MLOps の違い
MLOps のプラクティスを調整するためには、LLM によって機械学習(ML)のワークフローと要件がどのように変化するかを考慮する必要があります。主な検討事項は以下のとおりです。
- 計算リソース:大規模な言語モデルの学習と微調整には、通常、大規模なデータセットに対して桁違いの計算を実行する必要があります。この処理を高速化するために、GPU のような特殊なハードウェアが使われ、より高速なデータ並列演算が行われます。大規模言語モデルのトレーニングやデプロイメントには、こうした特殊な計算リソースへのアクセスが不可欠です。また、推論にかかるコストから、モデルの圧縮や蒸留の技術も重要視されることがあります。
- 転移学習 (Transfer Learning):多くの大規模言語モデルは、ゼロから作成・学習される従来の ML モデルとは異なり、基礎モデルからスタートし、より特定のドメインで性能を向上させるために新しいデータで微調整されます。ファインチューニングをすることで、より少ないデータと計算リソースで、特定のアプリケーションに対して最先端の性能を発揮できます。
- 人間のフィードバック:大規模言語モデルの学習において、人間のフィードバックによる強化学習(RLHF)は大きな進歩のひとつです。一般的に、LLM タスクは非常にオープンエンドであることが多いため、LLM のパフォーマンスを評価するには、アプリケーションのエンドユーザーからのフィードバックが不可欠です。このフィードバックループを LLMOps パイプラインに統合することで、評価を簡素化し、将来の LLM の微調整のためのデータを提供します。
- ハイパーパラメータのチューニング: 従来の ML では、ハイパーパラメータのチューニングは多くの場合、精度や他の測定基準を向上させることを中心に行われます。LLM の場合、チューニングは訓練と推論に必要なコストと計算能力を削減するためにも重要になります。例えば、バッチサイズや学習率を調整することで、学習のスピードとコストを劇的に変えることができます。このように、従来の ML モデルも LLM も、チューニングプロセスを追跡し最適化することで恩恵を受けますが、その重点は異なります。
- パフォーマンス指標:従来の ML モデルは、精度、AUC、F1 スコアなど、非常に明確に定義されたパフォーマンス指標を持っています。これらの指標は、計算が非常に簡単です。ただし、LLM の評価に関しては、バイリンガル評価アンダースタディ(BLEU)やリコール指向ギスティング評価用アンダースタディ(ROUGE)など、まったく異なる一連の標準指標とスコアリングが適用されます。これらは実装時にさらに考慮する必要があります。
- プロンプトエンジニアリング:指示に従うモデルは、複雑なプロンプト(指示のセット)を受け取ることができます。LLM から正確で信頼できる応答を得るためには、これらのプロンプトのテンプレートをエンジニアリングすることが重要です。プロンプトエンジニアリングは、モデルの幻覚�や、プロンプトインジェクション、機密データの漏洩、ジェイルブレイクなどのプロンプトハッキングのリスクを低減できます。
- LLM チェーンやパイプラインの構築:LLM パイプラインは、LangChain や LlamaIndex のようなツールを使って構築され、複数の LLM コールや、ベクターデータベースやウェブ検索のような外部システムへのコールをつなぎ合わせます。このようなパイプラインにより、LLM を知識ベースの Q&A や、一連のドキュメントに基づくユーザの質問への回答などの複雑なタスクに使用できます。LLM アプリケーションの開発は、多くの場合、新しい LLM を構築するのではなく、これらのパイプラインを構築することに重点を置いています。
LLMOps が必要な理由
LLM はプロトタイピング (Prototyping)では特に簡単に使用できますが、商用製品で LLM を使用するにはまだ課題があります。LLM の開発ライフサイクルは、データの取り込み、データの準備、プロンプトエンジニアリング、モデルの微調整、モデルの展開、モデルのモニタリングなど、多くの複雑なコンポーネントで構成されています。また、データエンジニアリングからデータサイエンス、ML エンジニアリングに至るまで、チーム間のコラボレーションとハンドオフも必要です。これら全てのプロセスを同期させ、連携させるためには、厳格な運用の厳密さが必要です。LLMOps は、LLM 開発ライフサイクルの実験、反復、デプロイメント、継続的改善を包括します。
LLMOps のメリット
LLMOps の主なメリットは、機械学習のライフサイクルにおける効率性、拡張性、リスク軽減です。
- 効率性:LLMOps により、データチームはモデルとパイプラインの開発を迅速化し、高品質なモデルを提供し、本番環境へのデプロイを迅速に行うことができます。
- 拡張性:MLOps は、広範なスケーラビリティと管理を可能にし、継続的インテグレーション、継続的デリバリー、継続的デプロイメントを目的として、数千のモデルを監督、制御、管理、監視できます。具体的には、MLOps が機械学習パイプラインの再現性を確保し、データチーム間の緊密なコラボレーションを可能にするため、DevOps や IT 部門との衝突を減らし、リリースサイクルを高速化します。
- リスク軽減:LLM は、規制の精査やドリフトチェックが必要になるケースが多々あります。LLMOps により、こうした要求に対するより高い透明性と迅速な対応が可能になり、組織や業界のポリシーへの準拠が確実になります。
エンタープライズ向けエージェントAIプレイブック

LLMOps の構成要素
機械学習プロジェクトにおける LLMOps の範囲は、プロジェクトが要求する範囲に集中することも、拡大することもできます。あるケースでは、LLMOps はデータの準備からパイプラインの生成まで全てを包含できますが、他のプロジェクトではモデルのデプロイプロセスのみの実装が必要になることもあります。大多数の企業は、以下のような LLMOps の原則を導入しています。
- 探索的データ解析(EDA)
- データの準備とプロンプトエンジニアリング (Prompt Engineering)
- モデルのファインチューニング
- モデルのレビューとガバナンス
- モデル推論とサービング
- 人間のフィードバックによるモデルモニタリング
LLMOps のベストプラクティス
LLMOps のベストプラクティスは、LLMOps の原則が適用される段階によって区別できます。
- 探索的データ解析(EDA):再現性、編集性、共有性のあるデータセット、表、可視化方法を作成することで、機械学習のライフサイクルにおいてデータを繰り返し探索、共有、準備できます。
- データプレパレーション (Data Preparation)とプロンプトエンジニアリング:データの変換、集約、重複排除を繰り返し、データを可視化し、データチーム間で共有可能にします。LLM への構造化された信頼性の高いクエリーのためのプロンプトを繰り返し開発できます。
- モデルのファインチューニング:Hugging Face Transformers、DeepSpeed、PyTorch、TensorFlow、JAX などの人気のあるオープンソースライブラリを使用して、モデルのパフォーマンスを微調整し、向上させます。
- モデルのレビューとガバナンス:モデルの系統、パイプライン、バージョンを追跡し、ライフサイクルを通じてモデルの成果物および移行を管理します。MLflow のようなオープンソースの MLOps プラットフォームを使用して、機械学習モデルの発見、共有、コラボレーションを行うことも可能です。
- モデル推論とサービング:モデルの更新頻度、推論要求時間などの本番環境に特化した管理を、テストと QA で行います。DevOps の原則を取り入れたリポジトリやオーケストレータなどの CI/CD ツールを利用して、本番前のパイプラインを自動化します。GPU アクセラレーションを使用した REST API モデルのエンドポイントを有効にします。
- 人間のフィードバックによるモデルの監視:モデルのドリフトや悪意のあるユーザーの行動に対するアラートを備えた、モデルとデータの監視パイプラインを作成します。
LLMOps プラットフォームとは
LLMOps プラットフォームは、データサイエンティストとソフトウェアエンジニアに、反復的なデータ探索、実験のトラッキング、プロンプトエンジニアリング、モデルとパイプラインの管理のためのリアルタイムのコワーキング機能、および制御されたモデルの移行、デプロイメント、LLM のモニタリングを容易にするコラボレーション環境を提供します。LLMOps は、機械学習のライフサイクルの運用、同期、監視を自�動化します。
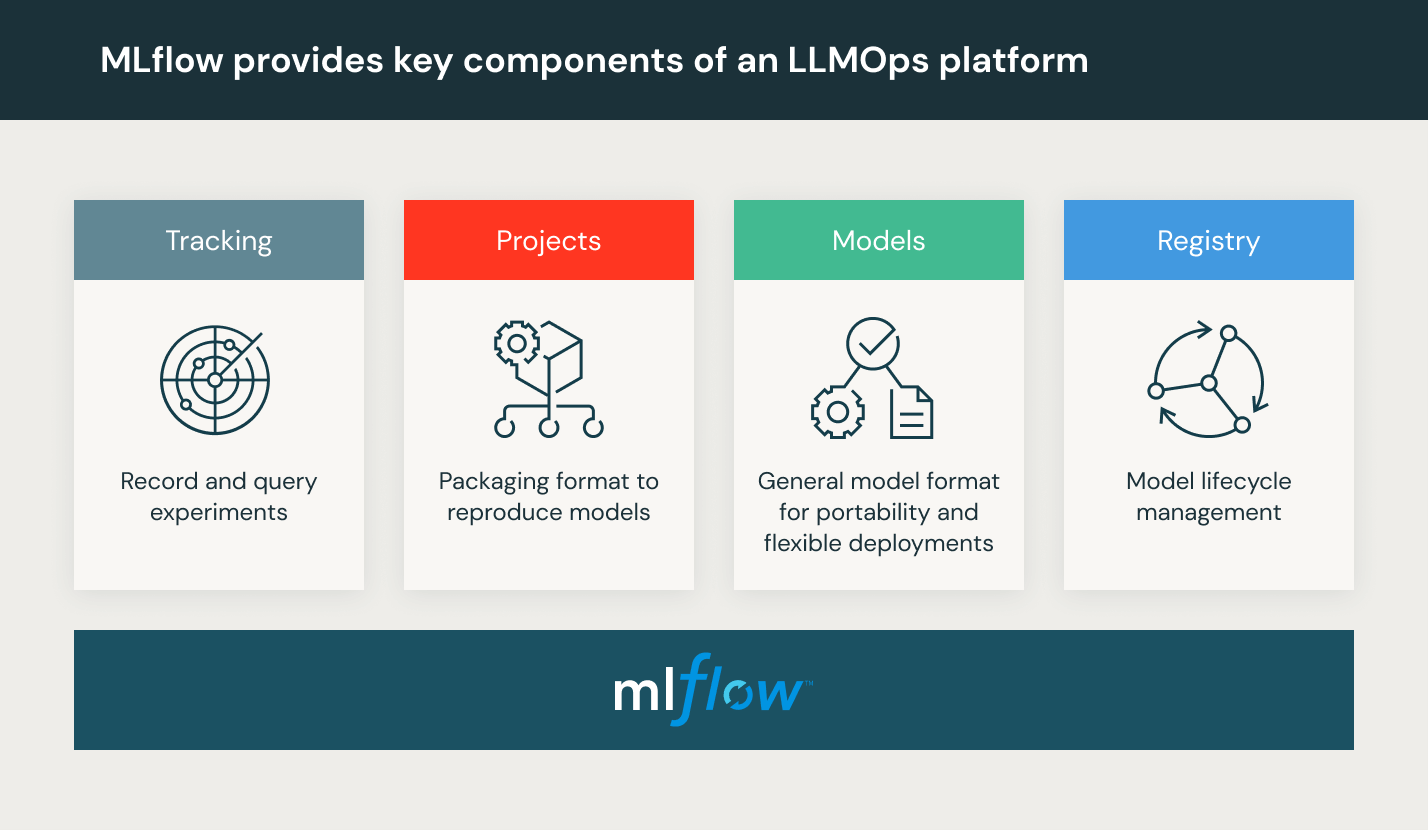
Databricks は、MLflow のフルマネージド環境であり、世界をリードするオープンな MLOps プラットフォームです。Databricks を利用した機械学習は、こちらからお試しいただけます。
FAQ
1. LLMOpsとMLOpsの主な違いは何ですか?
LLMOpsは、特に大規模言語モデルに特化した運用プラクティスで、巨大な計算リソースが求められます。MLOpsよりも、より大規模なデータと計算能力を要する場合が多いです。
2. LLMOpsにおける「転移学習」の利点はなんですか?
転移学習は、既存のモデルを特定のドメインに適用するために新しいデータで微調整するので、少ないデータと計算リソースで、特定のタスクに対する性能を向上させることが可能になります。
3. LLMOpsが提供する主なメリットは何ですか?
LLMOpsは、運用コストの削減、迅速なモデル展開、リスクの管理と軽減が可能になり、組織全体のデータガバナンスとコンプライアンスが向上します。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。