Enabling Evolutionary Database Development: database branching with Lakebase
A (mostly) three part series
by Pramod Sadalage and Kevin Hartman
Why this series exists
The methodology described in Evolutionary Database Design and operationalized in Refactoring Databases: Evolutionary Database Design has been clear for twenty years. The seven practices, the catalog of 70+ named refactorings, the transition mechanics – all of it documented, peer-reviewed, taught.
That methodology reached CI/CD in 2010 with Continuous Delivery (Chapter 12: Managing Data). Migrations became first-class artifacts in the deployment pipeline. The discipline of database-changes-as-code reached the broader CI/CD movement. What CD didn't solve was per-pipeline isolation: pipelines could run migrations, but they still needed a target database, and that target was shared. Practice #4 – Everybody gets their own database instance – has stayed aspirational on most teams because true per-developer production-shaped databases cost time, money, and DBA cycles. The compensating layer that emerged to work around the gap (mock objects, shared staging environments, in-memory database substitutes, DBA ticket queues) became foundational methodology by default, not by design.
In 2026, copy-on-write database branching arrives in Databricks Lakebase. A one-second, zero-storage-at-creation branch of a terabyte-scale production database is now an O(1) operation. The constraint that kept Practice #4 aspirational has lifted.
This series describes what changes when the constraint lifts: not the methodology – that holds – but the practices that emerge for the first time, the team-scale governance that becomes automatic, the role evolution for the DBA, and the new substrate that agents share with their human counterparts.
Meet Jen
Jen is the developer character from Evolutionary Database Design. In that essay she implemented a database refactoring – splitting an inventory_code field into location_code, batch_number, and serial_number – as a routine user story, illustrating that DBAs and developers can collaborate, schemas can evolve in small increments, and migrations carry the change forward safely.
The series picks up with Jen twenty years later. The methodology she follows is the same one she followed in 2003. What's new is the substrate underneath her workflow: copy-on-write database branching, which makes the practices she has been reading about operationally real at production scale. Across the three parts of this series she is the same Jen at three scopes – her day (Part 1), her new playbook (Part 2), and her team (Part 3).
Part 1: Jen’s story: one feature, one database change
To understand how this works, let’s walk through the journey of how a developer named Jen implements a task that states that the user should be able to see, search and update the location, batch and serial number of a production in inventory.
The following describes the various steps Jen has to take to accomplish this task, while describing the steps we will try to compare how Jen's workflow changes when working with traditional databases and using Lakebase that allows database branching at minimal cost.
Jen starts working on her feature task
Jen picks up what looks like a straightforward feature. The product team wants to allow users to capture location, batch and serial number of an item during inventory addition and use it later in the application flow. From the outside, the change feels small: add a field to the screen, save the value, show it in the Inventory screen for an item, and maybe use it in a downstream decision later.
For Jen, the application change is easy to picture. She knows where the form lives. She knows which service handles the request. She can see the model object that needs more attributes. But the moment she traces the change all the way through, she sees the real dependency, the database has to change too.
Some new columns are needed, existing data in the production environment needs to be preserved and has to be semantically correct. The application must handle old and new data safely and she needs to add tests to prove that the new fields are stored, read, and displayed correctly. What looked like a simple feature is now a coordinated application and database change, with the added responsibility of ensuring existing production schema and data is migrated to the new schema.
Shared database
Jen creates a code branch for the work she about to embark on, and since they are using a shared database and the rest of the team is using the same database for development, she immediately starts thinking about all the changes she is going to introduce in the database layer that could affect other users of the shared database and starts planning on how she can make it safe for others, could she run make the application change locally and be able to run her unit and integration tests? Each option has costs. She can wait. She can ask the team to coordinate. She can stand up her own local Postgres in Docker, seed it with a stale pg_dump from a week ago, and hope the differences don't matter. She can fall back running a local database in a container or to an in-memory database H2 or SQLite that runs fast but uses the wrong dialect, so her tests pass locally and surface unknown failures on real Postgres. Can she even test her schema and data migration scripts? This fear of breaking others slows her down and at the same time does not allow her to experiment with multiple options of building the feature.
Since in a shared database, one developer may be testing a business logic change, another is debugging a data migration, someone else created test data that Jen does not understand. If Jen applies her schema change to the shared database, she may break someone else’s work. If someone else changes the schema while she is testing, her results may no longer be reliable. If she adds test data, it may interfere with another developer’s assumptions.
Jen can wait until the shared database is free, which protects the team from collisions, but it turns a small feature into a scheduling problem and productivity loss. She can coordinate manually with the other developers: “Are you using dev right now?” “Can I run a migration?” “Please don’t reset the data for the next hour.” something like a baton in a relay race, That works for a while, but it does not scale, especially with a remote or multi timezone team.
Jen thinks of another option, using a local in-memory database, she knows that this setup does not match the state of the database used by the rest of the team, which means she will not have the confidence in her solution as the change may work locally and still fail later when its meets the real data and schema in higher environments like staging and production.
The real problem Jen is encountering is of slower feedback she can make the change, but finding out if the change works, but fast and realistic feedback and without this feedback the database change becomes something the team treats carefully and ends up picking the first solution that works and never experiments or tries multiple solutions, thus leading to suboptimal solutions, reduced productivity and dissatisfied developers.
Individual database branches
Using Lakebase, Jen has the ability to branch a database for her individual use and this capability completely changes the way she works.
Instead of waiting for the shared development database to become available, Jen creates a database branch databricks postgres create-branch for her feature or using a VS Code / Cursor Extension. This changes the shape of the work immediately. She is no longer asking the team for a quiet window. She’s no longer negotiating with other developers about who can run which migration and when and no longer trying to protect her half-finished change from everyone else’s half-finished changes. She has her own isolated database space, created from the same kind of database environment the application will eventually use in production.
The branch gives Jen a fast copy of the database state she needs to work against. She now has the same Postgres engine, the same schema, the same governance policies, and the same production-shaped data she'd see if she queried production directly. The only difference: this branch can be modified, discarded, or recreated without affecting any other workload. She is not testing against a simplified local database that behaves differently from production. She is working with the same database type the team uses in production, with the same kinds of schema rules, constraints, indexes, reference data, and migration history that make database changes succeed or fail in the real world. That realism matters because many database problems do not appear in isolated unit tests. They appear when a new migration meets existing structure, existing data, existing assumptions, and existing application behavior.
Now Jen can treat the database change as part of design, not just as a deployment step. She can try the obvious version first: add the new columns, set a default logic to split the existing column, create a database migration script, update the application, and run the tests. Then she can ask better questions. Should this migration script work for production data volumes, is the data quality in production the way her script expects them to be? Is a data migration script hiding missing business information? Should the preference be modeled as simple columns, a lookup table, or a separate item_information table because more information is likely to come later? Will the query pattern need an index? Will this design make downstream reporting easier or harder? In the old workflow, these questions often get compressed because changing the database is expensive.
In the branched workflow, Jen can explore them while the feature is still being shaped. The DBA can pair with her to guide her on production nuances and data volumes, thus providing valuable input in the design of the solution instead of being an after the fact reviewer.
Making the application and database change together
Jen writes the migration script. Whatever her team uses – Flyway, Liquibase, Alembic, Knex, Prisma – the script lives in the code repo, alongside the application changes. Schema and data migration travels with code.
(This is the Split Column refactoring – one of ~70 patterns catalogued in Refactoring Databases, the book that operationalized the seven practices.)
She applies the migration to her branch using flyway migrate. The tool runs in under a second against real-shaped data. She updates her repository code to read and write the three new columns. She runs her test suite. Tests pass against real Postgres no mocks, no in-memory substitutes.
If she wants a clean slate to try a different approach, she discards the branch and creates a fresh one off production. Another second. No cleanup tickets. No DBA involved.
Same Jen. Same refactoring. What changed is the capability.
Space to fail faster
The ability to experiment is important. Evolutionary design and development is not just about moving quickly through a predefined checklist. It is also about learning as the work becomes more concrete. Jen may discover that the first schema design works but creates awkward application logic. She may discover that the second design is cleaner but makes migration of existing records more complicated. She may discover that a small normalization decision now would make future changes easier. The first migration script she wrote the SUBSTRING indexes are off by one. The destructive DROP COLUMN ran before she could verify the new columns have been populated correctly. Because she has her own branch, these discoveries are inexpensive. She can apply a migration, run the application, inspect the data, roll forward with another migration, or reset and try a different path.
The branch also changes the emotional posture of the work. Jen does not have to be overly cautious because someone else might be depending on the shared development database. She does not have to announce every experiment to the team. She does not have to clean up test data immediately because another developer might trip over it. Her branch is a safe place for unfinished thinking. It can contain temporary tables, failed migration attempts, awkward test data, and half-formed designs without creating noise for anyone else.
At the same time, isolation does not mean detachment from the team’s standards. Jen still writes migration scripts. She still keeps the application code and database change together. She still runs tests. She still expects the final design to be reviewed. The difference is that she can do the messy part of the work privately and quickly before asking the team to reason about the polished version. By the time she opens a pull request, the conversation can focus on whether the design is right, not whether she had a safe place to test it.
This is the key shift: the database branch gives Jen fast, realistic, isolated feedback that she can also get reviewed from her tech leads or DBAs, by showing her database branch. Fast means she can create the environment when she needs it, not when someone provisions it for her. Realistic means she is testing against the same kind of database behavior that matters in production. Isolated means her experiments do not interrupt anyone else. Together, those three properties turn database change from a bottleneck into a normal part of feature development.
Jen can now move the application and database forward together. Her code branch and her database branch become two sides of the same task. One holds the application changes. The other gives those changes a real database to live against. Instead of waiting, coordinating, or pretending with a simplified setup, Jen can design, test, revise, and learn. The feature is still small, but now the database is no longer what makes it slow.
Opening the pull request
Jen commits both the application code and the migration script. She opens a PR.
CI does what Jen just did, but for the team: it creates its own temporary Lakebase branch, applies the migration, runs the application test suite, runs database tests against the migrated schema, validates the migration itself (applies cleanly, idempotent, reversible), and posts a schema-diff comment on the PR showing exactly which database objects changed.
The reviewer can now see what the schema change does inline with the code that uses it, changing their contextual understanding from abstract to concrete.
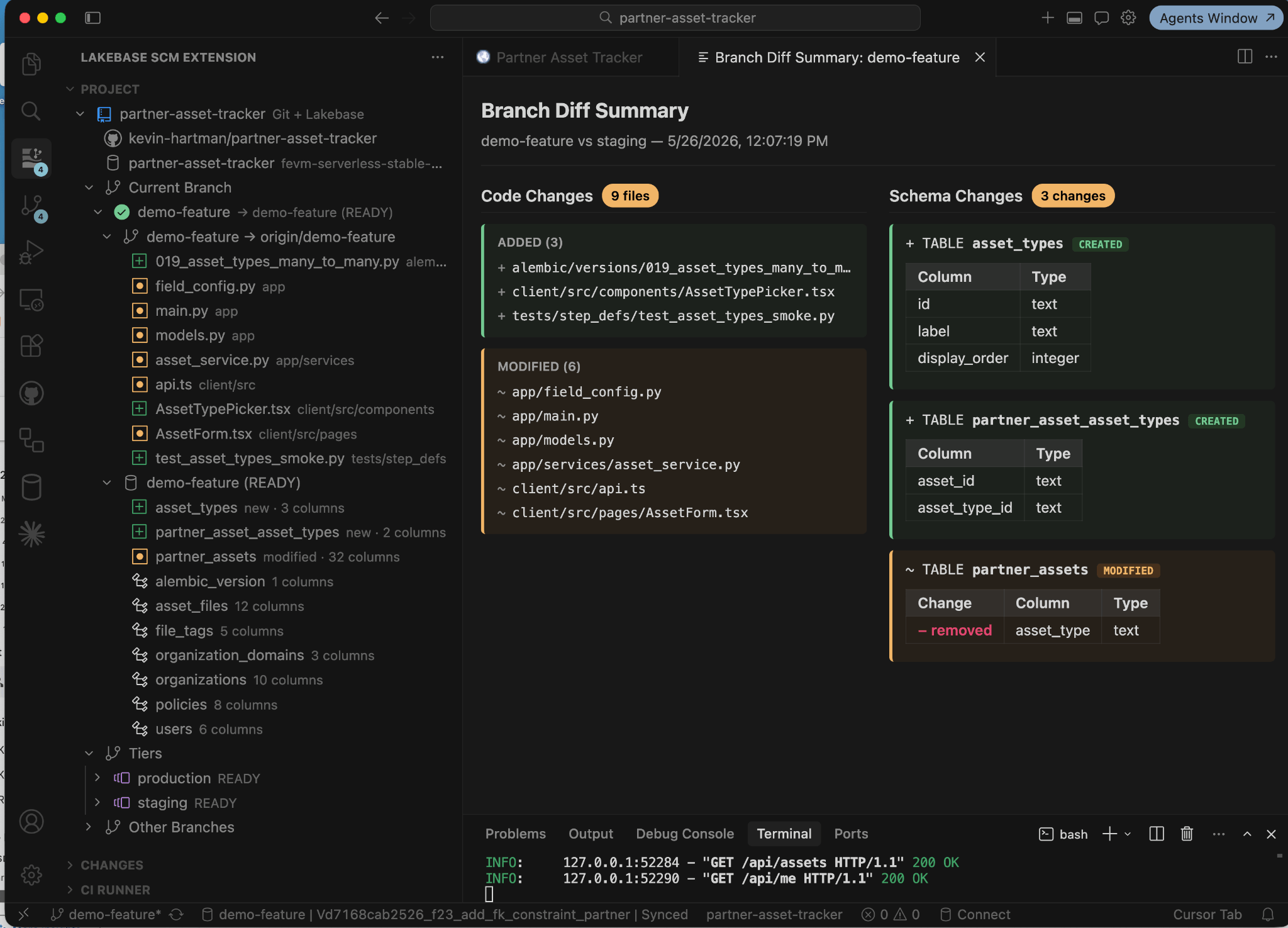
Screenshot of the Branch Diff Summary view from the Lakebase SCM Extension
Reviewing the change
In the old workflow, the database review question was "will this break the database?" – gated by a DBA who had to look at every change in isolation because every change had production-scale consequences if it got loose. Reviews were synchronous. Schedules collided. The DBA's calendar became a queue and sometimes the DBA would get skipped for “Time to Market” reasons.
In the new workflow, the question is "is this the right design?" The DBA has already seen the schema diff posted by CI. They've already seen the migration run successfully against a real-data branch. Jen can also pull in the DBA for a discussion, to show what she is thinking of and all the other options she has tried. The DBA can review on their schedule, not Jen's. They can provide review much earlier in the solution development cycle and improve the solution around data integrity, indexing strategy, future extensibility or long-term maintainability, not on the protective gatekeeping that used to take all their time.
The team reviews code and database together. One PR. One conversation. Same window.
Merging with confidence
The migration has already been tested against a real data branch. The application has already run against the changed schema. The schema migration has been reviewed. The CI build has run the same exact steps and has been green for an hour.
When Jen merges, the migration applies to the next environment, the branches for database and code for CI environment and Jen are cleaned up. Thus ensuring that the database change is no longer a release-night surprise.
What Jen just did is the fifth practice from the 2003 essay: continuous integration of database changes.
What Jen's journey shows
Database change becomes part of normal development. Branching reduces waiting, risk, and coordination overhead. Jen's daily loop now gives her fast, isolated feedback at the database layer.
In Part 2 – Jen's New Playbook, we explain what lifted and why the compensating layer Jen worked around her whole career can come out: copy-on-write branching, the architecture that makes it work, and the methodology optimizations that follow.
In Part 3 – Jen's Team at Scale, we look at what Jen's story looks like when she's one of fifty developers, or maybe she is working on a white labeled product, or she is working on a modular monolith with lots of domains inside it – governance at branch creation, the DBA reframe, the agent-in-the-loop, and the platform-design work that opens up when the DBA's calendar isn't a ticket queue.
For readers who want the tour of the IDE tooling Jen used in this post, there's the Companion: Plugin Walkthrough – the Lakebase SCM Extension for VS Code / Cursor, end to end.
Finally, a Lakebase App Dev Kit for agents to use accompanied by an ebook for humans to follow will be released shortly.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.