Datenpipelines mit niedriger Latenz für Streaming-Daten mit Delta Live Tables und Apache Kafka
von Frank Munz
Delta Live Tables (DLT) ist das erste ETL-Framework, das einen einfachen deklarativen Ansatz zur Erstellung zuverlässiger Datenpipelines verwendet und die zugrunde liegende Infrastruktur für Batch- und Streaming-Daten im großen Maßstab vollständig verwaltet. Viele Anwendungsfälle erfordern umsetzbare Erkenntnisse, die aus nahezu Echtzeitdaten gewonnen werden. Delta Live Tables ermöglicht Streaming-Datenpipelines mit geringer Latenz, um solche Anwendungsfälle mit geringen Latenzen zu unterstützen, indem Daten direkt von Event-Bussen wie Apache Kafka, AWS Kinesis, Confluent Cloud, Amazon MSK oder Azure Event Hubs aufgenommen werden.
Dieser Artikel führt Sie durch die Verwendung von DLT mit Apache Kafka und stellt den erforderlichen Python-Code für die Aufnahme von Streams bereit. Die empfohlene Systemarchitektur wird erläutert und relevante DLT-Einstellungen, die berücksichtigt werden sollten, werden im Laufe des Artikels behandelt.
Streaming-Plattformen
Event-Busse oder Message-Busse entkoppeln Nachrichtenproduzenten von Konsumenten. Ein beliebter Streaming-Anwendungsfall ist die Sammlung von Click-Through-Daten von Benutzern, die eine Website durchsuchen, wobei jede Benutzerinteraktion als Ereignis in Apache Kafka gespeichert wird. Der Ereignisstrom von Kafka wird dann für Echtzeit-Streaming-Datenanalysen verwendet. Mehrere Nachrichten-Konsumenten können dieselben Daten von Kafka lesen und die Daten verwenden, um etwas über Zielgruppeninteressen, Konversionsraten und Absprunggründe zu erfahren. Die Echtzeit-Streaming-Ereignisdaten aus den Benutzerinteraktionen müssen oft auch mit tatsächlichen Käufen korreliert werden, die in einer Rechnungsdatenbank gespeichert sind.
Apache Kafka
Apache Kafka ist ein beliebter Open-Source-Event-Bus. Kafka verwendet das Konzept eines Topics, eines append-only verteilten Logs von Ereignissen, in dem Nachrichten für eine bestimmte Zeit gepuffert werden. Obwohl Nachrichten in Kafka nach dem Konsumieren nicht gelöscht werden, werden sie auch nicht unbegrenzt gespeichert. Die Nachrichtenaufbewahrung für Kafka kann pro Topic konfiguriert werden und beträgt standardmäßig 7 Tage. Abgelaufene Nachrichten werden schließlich gelöscht.
Dieser Artikel konzentriert sich auf Apache Kafka; die diskutierten Konzepte gelten jedoch auch für viele andere Event-Busse oder Messaging-Systeme.
Streaming-Datenpipelines
In einer Datenfluss-Pipeline können Delta Live Tables und ihre Abhängigkeiten mit einer Standard-SQL-Anweisung Create Table As Select (CTAS) und dem DLT-Schlüsselwort „live“ deklariert werden.
Bei der Entwicklung von DLT mit Python wird der Dekorator @dlt.table verwendet, um eine Delta Live Table zu erstellen. Um die Datenqualität in einer Pipeline sicherzustellen, verwendet DLT Erwartungen, bei denen es sich um einfache SQL-Constraint-Klauseln handelt, die das Verhalten der Pipeline bei ungültigen Datensätzen definieren.
Da Streaming-Workloads oft mit unvorhersehbaren Datenvolumen einhergehen, setzt Databricks verbessertes Autoscaling für Datenfluss-Pipelines ein, um die gesamte End-to-End-Latenz zu minimieren und gleichzeitig die Kosten durch Abschalten unnötiger Infrastruktur zu senken.
Delta Live Tables werden für jeden Pipeline-Lauf vollständig neu berechnet, in der richtigen Reihenfolge und genau einmal.
Im Gegensatz dazu sind Streaming Delta Live Tables zustandsbehaftet, inkrementell berechnet und verarbeiten nur Daten, die seit dem letzten Pipeline-Lauf hinzugefügt wurden. Wenn sich die Abfrage, die eine Streaming-Live-Tabelle definiert, ändert, werden neue Daten basierend auf der neuen Abfrage verarbeitet, aber vorhandene Daten werden nicht neu berechnet. Streaming-Live-Tabellen verwenden immer eine Streaming-Quelle und funktionieren nur über Append-only-Streams wie Kafka, Kinesis oder Auto Loader. Streaming-DLTs basieren auf Spark Structured Streaming.
Sie können mehrere Streaming-Pipelines verketten, z. B. Workloads mit sehr großem Datenvolumen und geringen Latenzanforderungen.
Direkte Aufnahme aus Streaming-Engines
Delta Live Tables, die in Python geschrieben sind, können Daten direkt aus einem Event-Bus wie Kafka mithilfe von Spark Structured Streaming aufnehmen. Sie können eine kurze Aufbewahrungsfrist für das Kafka-Topic festlegen, um Compliance-Probleme zu vermeiden, Kosten zu senken und dann von der kostengünstigen, elastischen und steuerbaren Speicherung zu profitieren, die Delta bietet.
Als ersten Schritt in der Pipeline empfehlen wir, die Daten unverändert in eine Bronze-Tabelle (Rohdaten) aufzunehmen und komplexe Transformationen zu vermeiden, die wichtige Daten verwerfen könnten. Wie jede Delta-Tabelle behält die Bronze-Tabelle den Verlauf bei und ermöglicht die Durchführung von GDPR- und anderen Compliance-Aufgaben.
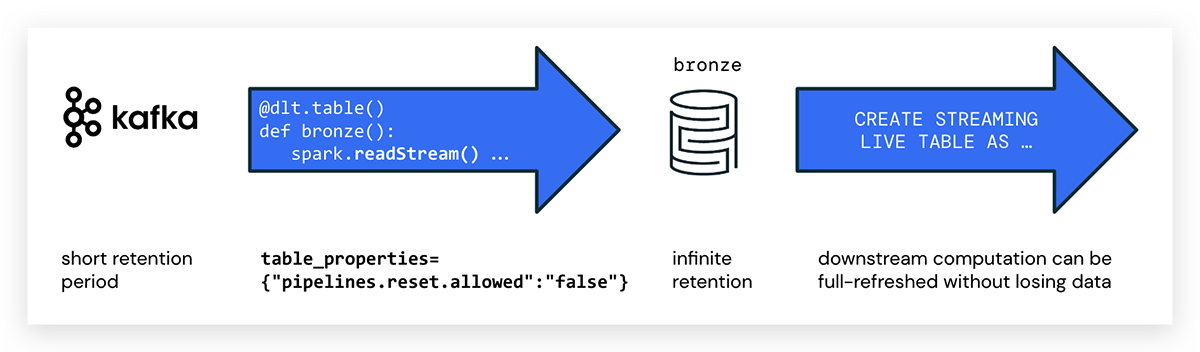
Beim Schreiben von DLT-Pipelines in Python verwenden Sie die Annotation @dlt.table, um eine DLT-Tabelle zu erstellen. Es gibt kein spezielles Attribut, um Streaming-DLTs in Python zu kennzeichnen; verwenden Sie einfach spark.readStream(), um auf den Stream zuzugreifen. Beispielcode zum Erstellen einer DLT-Tabelle mit dem Namen kafka_bronze, die Daten aus einem Kafka-Topic konsumiert, sieht wie folgt aus:
pipelines.reset.allowed
Beachten Sie, dass Event-Busse Nachrichten normalerweise nach einer bestimmten Zeit ablaufen lassen, während Delta für unendliche Aufbewahrung konzipiert ist.
Dies kann dazu führen, dass Quelldaten auf Kafka bereits gelöscht sind, wenn ein vollständiges Refresh für eine DLT-Pipeline ausgeführt wird. In diesem Fall können nicht alle historischen Daten aus der Messaging-Plattform nachgefüllt werden, und Daten würden in den DLT-Tabellen fehlen. Um das Verwerfen von Daten zu verhindern, verwenden Sie die folgende DLT-Tabelleneigenschaft:
pipelines.reset.allowed=false
Das Setzen von pipelines.reset.allowed auf false verhindert Refreshes der Tabelle, verhindert aber keine inkrementellen Schreibvorgänge in die Tabellen oder den Fluss neuer Daten in die Tabelle.
Checkpointing
Wenn Sie ein erfahrener Spark Structured Streaming-Entwickler sind, werden Sie das Fehlen von Checkpointing im obigen Code bemerken. In Spark Structured Streaming ist Checkpointing erforderlich, um Fortschrittsinformationen darüber zu speichern, welche Daten erfolgreich verarbeitet wurden, und im Fehlerfall werden diese Metadaten verwendet, um eine fehlgeschlagene Abfrage genau dort neu zu starten, wo sie unterbrochen wurde.
Während Checkpoints für die Fehlerwiederherstellung mit Exactly-Once-Garantien in Spark Structured Streaming notwendig sind, verwaltet DLT den Zustand automatisch, ohne dass eine manuelle Konfiguration oder explizites Checkpointing erforderlich ist.
Mischen von SQL und Python für eine DLT-Pipeline
Eine DLT-Pipeline kann aus mehreren Notebooks bestehen, aber ein DLT-Notebook muss entweder vollständig in SQL oder Python geschrieben sein (im Gegensatz zu anderen Databricks-Notebooks, in denen Sie Zellen mit unterschiedlichen Sprachen in einem einzigen Notebook haben können).
Wenn Sie SQL bevorzugen, können Sie die Datenaufnahme von Apache Kafka in einem Notebook in Python kodieren und dann die Transformationslogik Ihrer Datenpipelines in einem anderen Notebook in SQL implementieren.
Schema-Mapping
Beim Lesen von Daten aus einer Messaging-Plattform ist der Datenstrom undurchsichtig und ein Schema muss bereitgestellt werden.
Das folgende Python-Beispiel zeigt die Schemadefinition von Ereignissen eines Fitness-Trackers und wie der Wertteil der Kafka-Nachricht diesem Schema zugeordnet wird.
Vorteile
Das Lesen von Streaming-Daten in DLT direkt aus einem Message Broker minimiert die architektonische Komplexität und bietet eine geringere End-to-End-Latenz, da Daten direkt vom Message Broker gestreamt werden und kein Zwischenschritt erforderlich ist.
Streaming-Aufnahme mit Cloud Object Store als Zwischenspeicher
Für bestimmte Anwendungsfälle möchten Sie möglicherweise Daten von Apache Kafka abladen, z. B. mithilfe eines Kafka-Connectors, und Ihre Streaming-Daten in einem Cloud-Objektspeicher als Zwischenspeicher ablegen. In einer Databricks-Arbeitsumgebung kann der objektspezifische Cloud-Speicher des Anbieters dann über das Databricks Files System (DBFS) als Cloud-unabhängiger Ordner zugeordnet werden. Sobald die Daten abgeladen sind, kann Databricks Auto Loader die Dateien aufnehmen.
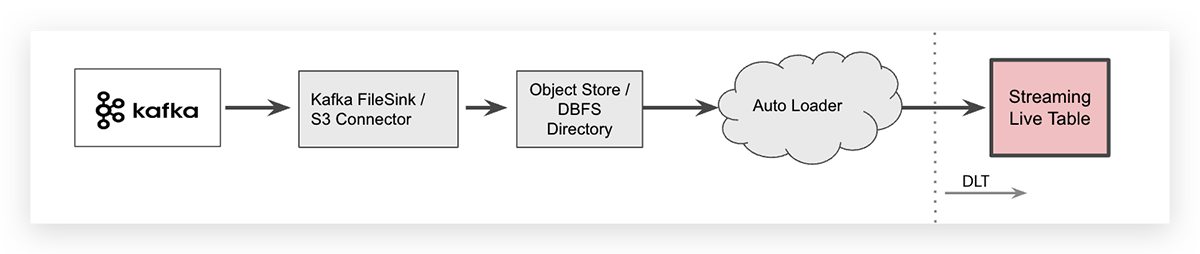
Auto Loader kann Daten mit einer einzigen Zeile SQL-Code aufnehmen. Die Syntax zum Aufnehmen von JSON-Dateien in eine DLT-Tabelle ist unten dargestellt (sie ist zur besseren Lesbarkeit über zwei Zeilen umgebrochen).
Beachten Sie, dass Auto Loader selbst eine Streaming-Datenquelle ist und alle neu angekommenen Dateien genau einmal verarbeitet werden. Daher gibt das Schlüsselwort „streaming“ für die Roh-Tabelle an, dass Daten inkrementell in diese Tabelle aufgenommen werden.
Da das Abladen von Streaming-Daten in einen Cloud-Objektspeicher einen zusätzlichen Schritt in Ihrer Systemarchitektur bedeutet, erhöht dies auch die End-to-End-Latenz und verursacht zusätzliche Speicherkosten. Beachten Sie, dass der Kafka-Connector, der Ereignisdaten in den Cloud-Objektspeicher schreibt, verwaltet werden muss, was die betriebliche Komplexität erhöht.
Daher empfiehlt Databricks als Best Practice, direkt auf Ereignisbusdaten von DLT mithilfe von Spark Structured Streaming zuzugreifen, wie oben beschrieben.
Andere Ereignisbusse oder Messaging-Systeme
Dieser Artikel konzentriert sich auf Apache Kafka; die diskutierten Konzepte gelten jedoch auch für andere Ereignisbusse oder Messaging-Systeme. DLT unterstützt jede Datenquelle, die Databricks Runtime direkt unterstützt.
Amazon Kinesis
In Kinesis schreiben Sie Nachrichten in einen vollständig verwalteten, serverlosen Stream. Genau wie Kafka speichert Kinesis Nachrichten nicht dauerhaft. Die Standard-Nachrichtenaufbewahrung in Kinesis beträgt einen Tag.
Bei der Verwendung von Amazon Kinesis ersetzen Sie format("kafka") durch format("kinesis") im Python-Code für die Streaming-Aufnahme oben und fügen Sie Amazon Kinesis-spezifische Einstellungen mit option() hinzu. Weitere Informationen finden Sie im Abschnitt über die Kinesis-Integration in der Spark Structured Streaming-Dokumentation.
Azure Event Hubs
Für Azure Event Hubs-Einstellungen lesen Sie die offizielle Dokumentation von Microsoft und den Artikel Delta Live Tables Rezepte: Aufnahme von Azure Event Hubs.
Zusammenfassung
DLT ist viel mehr als nur das „T“ in ETL. Mit DLT können Sie problemlos Daten aus Streaming- und Batch-Quellen aufnehmen, bereinigen und transformieren – auf der Databricks Lakehouse Platform in jeder Cloud, mit garantierter Datenqualität.
Daten von Apache Kafka können durch direkte Verbindung zu einem Kafka-Broker aus einem DLT-Notebook in Python aufgenommen werden. Datenverlust kann bei einer vollständigen Pipeline-Aktualisierung verhindert werden, selbst wenn die Quelldaten in der Kafka-Streaming-Schicht abgelaufen sind.
Erste Schritte
Wenn Sie ein Databricks-Kunde sind, folgen Sie einfach der Anleitung für den Einstieg. Lesen Sie die Versionshinweise, um mehr darüber zu erfahren, was in dieser GA-Version enthalten ist. Wenn Sie noch kein Databricks-Kunde sind, melden Sie sich für eine kostenlose Testversion an, und Sie können unsere detaillierten DLT-Preise hier einsehen.
Beteiligen Sie sich an der Unterhaltung in der Databricks Community, wo datenbegeisterte Kollegen über Ankündigungen und Updates zum Data + AI Summit 2022 sprechen. Lernen. Vernetzen.
Zu guter Letzt empfehlen wir die Sitzung Dive Deeper into Data Engineering vom Summit. In dieser Sitzung führe ich Sie durch den Code eines weiteren Streaming-Datenbeispiels mit einem Twitter-Livestream, Auto Loader, Delta Live Tables in SQL und Hugging Face Sentimentanalyse.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.