Erstellen einer Echtzeit-Produktsuche auf Databricks
von Jiayi Wu, Luke Lefebure und Adam Gurary
- Wie man ein Echtzeit-Produktsuchsystem auf Databricks aufbaut, einschließlich der für moderne Sucherlebnisse erforderlichen Komponenten für Aufnahme, Abruf und Ranking.
- Eine Referenzarchitektur, die Databricks AI Search, Lakeflow und Lakebase verwendet, um Produktdaten zu verarbeiten, relevante Ergebnisse abzurufen und Echtzeit-Betriebssignale wie Preise, Lagerbestände und Benutzerpräferenzen zu integrieren.
- Best Practices und Metriken für den Betrieb von Suchen im großen Maßstab, einschließlich der Bewertung der Abrufqualität, der Latenzüberwachung und wie Agenten und Anwendungen auf Suchsystemen aufbauen können.
Stellen Sie sich vor, Sie entwerfen ein Suchsystem für einen Online-Marktplatz, der Autos verkauft. Innerhalb von Millisekunden erwarten die Nutzer Ergebnisse, die ihrem Budget entsprechen, ihren Vorlieben entsprechen, in ihrer Nähe verfügbar sind und relevant erscheinen.
So sieht die moderne Produktsuche im Web aus. Es ist nicht nur ein Nachschlagewerkzeug, sondern eine Echtzeit-Entscheidungsmaschine, die fast augenblicklich abrufen, filtern, einstufen und antworten muss – und das alles unter Berücksichtigung von Geschäfts- und technischen Kennzahlen wie Umsatz, Klickrate, Latenz und Relevanz.
Databricks bietet die End-to-End-Plattform für den Aufbau dieser Systeme – von der skalierbaren Datenerfassung (Lakeflow) über die Vektor-gestützte Abfrage (AI Search) bis hin zu operativen Echtzeitdaten (Lakebase) und agentenbasierten Sucherlebnissen (Agent Bricks). Dieser Blogbeitrag erläutert, wie diese Komponenten zusammenwirken, um die Produktsuche in Echtzeit zu ermöglichen.
Komponenten für die Produktsuche
Bei der Produktsuche geht es nicht einfach darum, eine Frage zu beantworten oder Informationen über einen Chatbot bereitzustellen. Es ist ein Entdeckungs- und Entscheidungsprozess – dynamisch, personalisiert und eng mit dem Umsatz verbunden. Käufer erwarten, zu stöbern, zu vergleichen und zu erkunden. Das Ziel ist nicht, eine einzige Antwort zu generieren, sondern eine Rangliste von Optionen zu präsentieren, die relevant, vertrauenswürdig und überlegenswert erscheinen.
Ein Echtzeit-Produktsuchsystem besteht im Allgemeinen aus 3 Segmenten (Abbildung 1).
- Ingestion bereitet Produktdaten für die Suche vor. Produkttitel, Beschreibungen und Attribute werden verarbeitet, in Embeddings umgewandelt, mit Metadaten angereichert und für schnelle Abrufe indiziert.
- Retrieval findet relevante Kandidaten durch die Generierung einer Kandidatenmenge mittels Volltext-, semantischer oder hybrider Suche in Kombination mit strukturierten Filterungen.
- Refinement bestimmt, wie Ergebnisse interpretiert und geordnet werden sollen, indem Abfrageverständnis, Ranking-Logik, Personalisierung und Geschäftsregeln angewendet werden.

{kind=link}
Hinter der Suchleiste
Keine dieser Erfahrungen ist ohne eine starke Infrastruktur und aussagekräftige Metriken möglich.
- Infrastruktur ermöglicht Geschwindigkeit und Relevanz.
- Metriken beweisen, dass Ihr System tatsächlich schnell und relevant ist – nicht nur auf dem Papier.
Moderne Produktsuche erfordert beides: die technische Grundlage zur Bereitstellung von Ergebnissen und die Metrikdisziplin zur kontinuierlichen Validierung, dass diese Ergebnisse gut genug sind.
Architektur-Übersicht
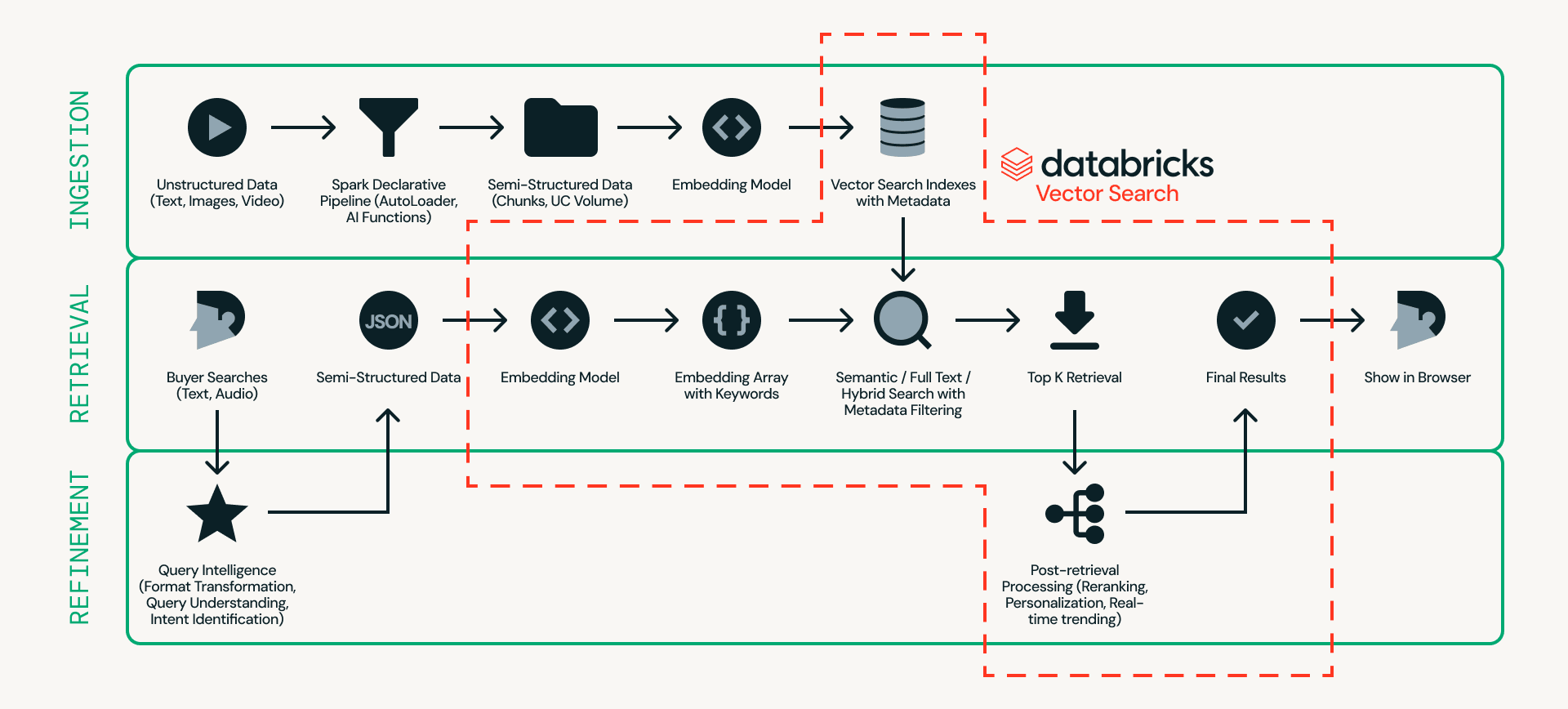
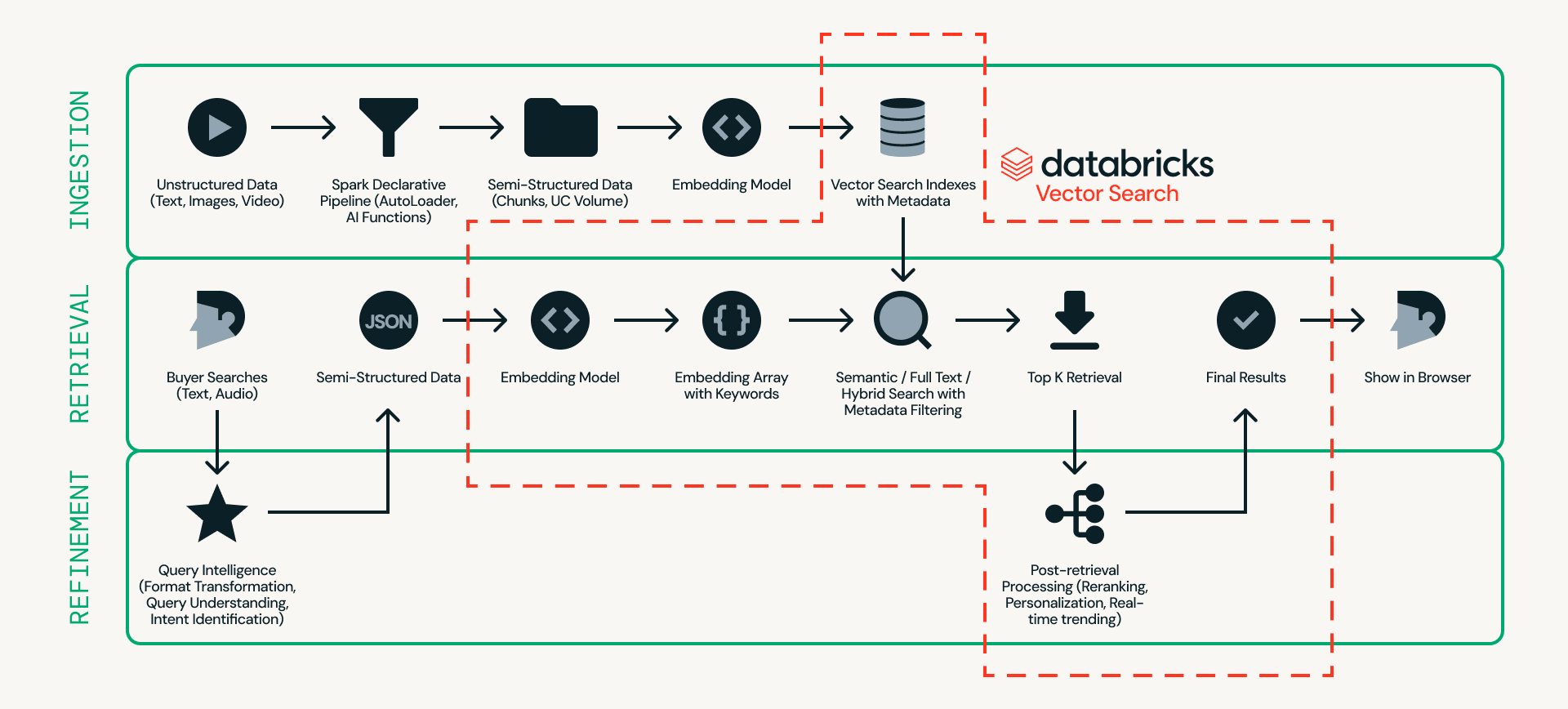
Betrachten wir zunächst die Architektur. Abbildung 2 zeigt ein detailliertes Beispiel einer Echtzeit-Produktsucharchitektur.
{kind=link}
Im Zentrum dieses Designs steht Databricks AI Search, das Ingestion, Retrieval und Refinement auf einer einzigen Plattform handhabt – wodurch die Notwendigkeit entfällt, mehrere externe Systeme miteinander zu verbinden.
- Ingestion bereitet Produktdaten für eine effiziente Suche vor. Unstrukturierte Quellen wie Produktangebote und Bilder werden durch skalierbare Pipelines mithilfe von Databricks Auto Loader, Lakeflow Spark Declarative Pipeline und AI Functions (z. B. ai_parse_document) verarbeitet. Die Daten können dann in Databricks AI Search in Chunks aufgeteilt und mit Metadaten (z. B. Automodell, Farbe oder Preis) in Embeddings umgewandelt werden.
- Retrieval verarbeitet Echtzeitabfragen. Benutzereingaben werden in Embeddings und strukturierte Filter umgewandelt, und Databricks AI Search ruft die Top-Kandidaten mithilfe von semantischer Suche, Volltextsuche oder hybrider Suche mit Metadatenfilterung ab.
- Refinement verbessert abgerufene Kandidaten zu Endergebnissen. Während die Abfrage eine starke Basis liefert, verfeinert diese Schicht die Ergebnisse durch Interpretation der Absicht, Anwendung von Ranking-Logik und Einbeziehung von Personalisierungs- und Geschäftsregeln, falls erforderlich. Operativer Echtzeitkontext wie Sitzungsstatus, Lagerbestand, Preisgestaltung und Benutzerpräferenzen kann über Lakebase bereitgestellt werden, was Latenzen von unter 10 ms ermöglicht, um die endgültige Reihenfolge zu beeinflussen.
Einige praktische Richtlinien beim Aufbau von Suchsystemen auf Databricks:
- Experimentieren Sie einfach mit Modellen. Tauschen Sie Embedding-Modelle mit minimalem Aufwand aus und nutzen Sie native Reranking-Funktionen. Zukünftige Updates werden das Fine-Tuning von Reranking-Modellen mit einem Klick direkt auf der Plattform ermöglichen, was die Relevanzoptimierung vereinfacht.
- Stellen Sie Anwendungsstatus mit Suchgeschwindigkeit bereit. Verwenden Sie Lakebase, um Echtzeit-Anwendungsstatus – Sitzungskontext, Lagerbestand, Preisgestaltung, Benutzerpräferenzen – mit Latenzen von unter 10 ms zu speichern. Managed CDC synchronisiert Lakebase automatisch mit Delta, sodass Ranking-Modelle und Analysen immer die aktuellen operativen Daten ohne benutzerdefinierte Pipelines widerspiegeln.
- Testen Sie die Skalierbarkeit vor der Produktion. Validieren Sie Latenz und Durchsatz unter realistischer Last, einschließlich Szenarien mit hohem QPS. Sie können Produktions-Workloads heute mit dem Notebook zum Lasttest von Suchvorgängen simulieren, wobei eine native Ein-Klick-Lasttestunterstützung in einer zukünftigen Version verfügbar sein wird. Für anhaltenden Traffic nutzen Sie High QPS Endpoints, um die Nebenläufigkeit im großen Maßstab zu bewältigen, und überwachen Sie die Leistung durch Endpoint-Observability, um Latenz, Durchsatz und Systemzustand zu verfolgen.
- Erstellen Sie von Anfang an agentenbereite Suchen. Jeder AI Search-Index mit verwalteten Embeddings erhält automatisch einen verwalteten MCP-Server. Nutzen Sie ihn für die Zero-Config-Agentenintegration, das VectorSearchRetrieverTool für die Code-First-Steuerung oder richten Sie einen Knowledge Assistant auf Ihren Index, um sofortige Fragen und Antworten mit Zitaten zu erhalten – angetrieben durch Instructed Retriever, das eine um 70 % bessere Genauigkeit als Standard-RAG-Systeme erzielt.
Wichtige Metriken
Ein Suchsystem ist nicht erfolgreich, weil es in einem Diagramm elegant aussieht. Es ist erfolgreich, weil es schnelle, relevante Ergebnisse liefert, die Geschäftsergebnisse erzielen.
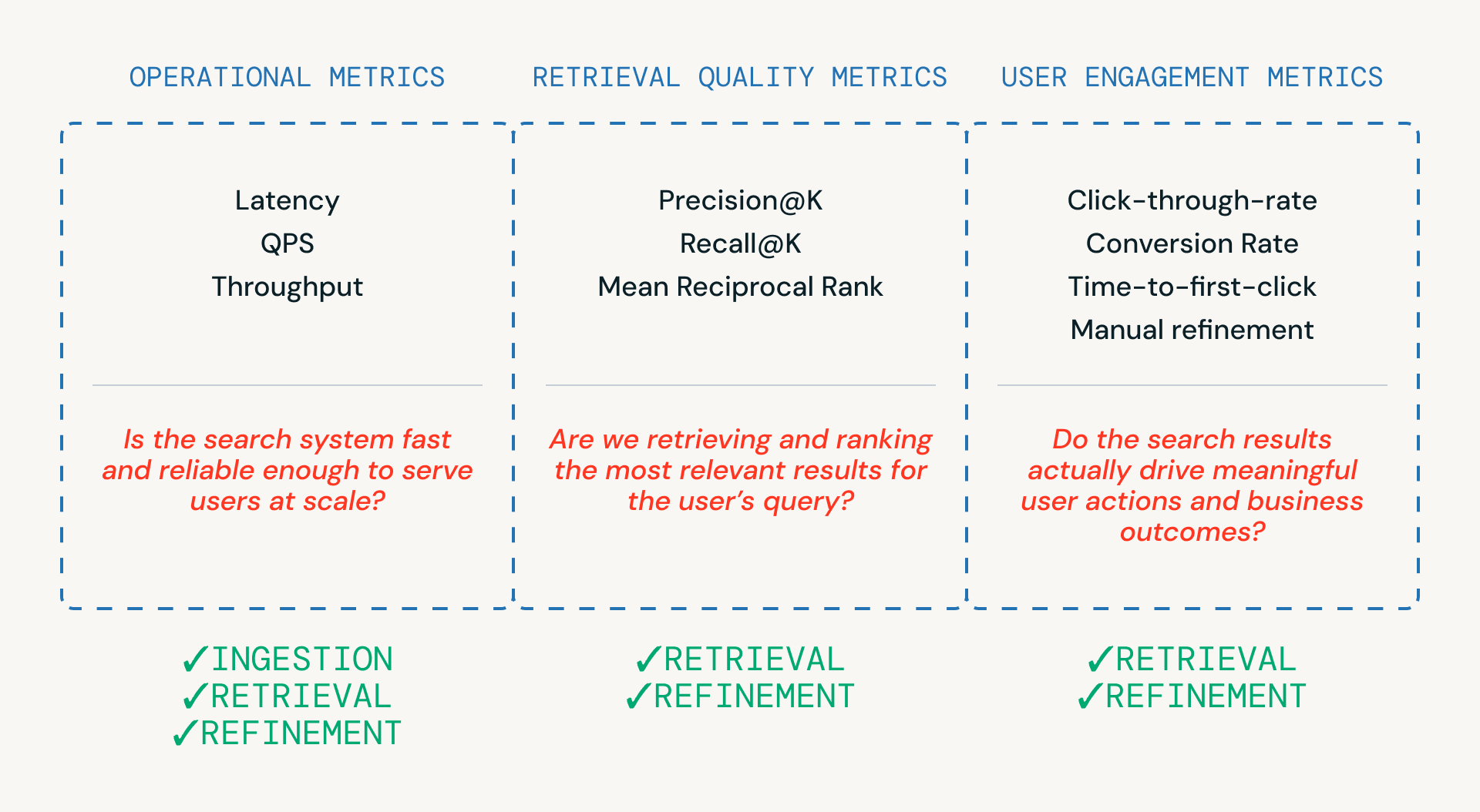
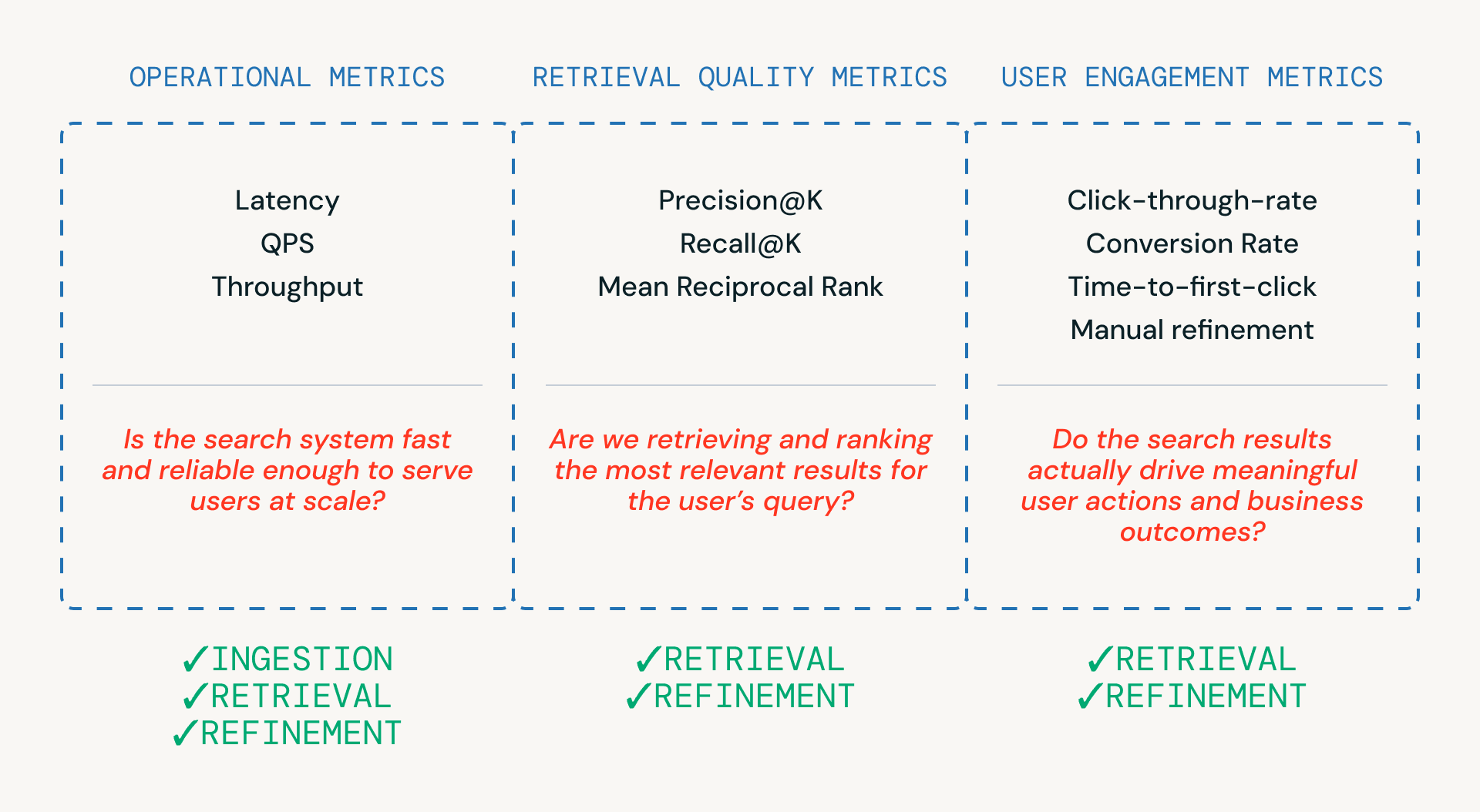
Wie in Abbildung 3 gezeigt, helfen drei Kategorien von Metriken Teams bei der Bewertung einer Suchpipeline – jede ist mit einer anderen Ebene des Systems verbunden.
- Betriebsmetriken stellen sicher, dass das System schnell und zuverlässig genug ist, um Benutzer im großen Maßstab zu bedienen. Diese sind entscheidend für Ingestion-, Retrieval- und Refinement-Schritte.
- Retrieval-Qualitätsmetriken messen, ob das System tatsächlich relevante Kandidaten abruft und einstuft, und sind am engsten mit den Retrieval- und Refinement-Phasen verbunden, in denen Ranking und Reranking stattfinden.
- Nutzer-Engagement-Metriken erfassen das reale Nutzerverhalten – ob Nutzer klicken, verfeinern oder letztendlich konvertieren – und liefern Feedback, das Verbesserungen bei der Abfrage und Verfeinerung im Laufe der Zeit informiert.
{kind=link}
Ein paar praktische Richtlinien zur Bewertung von Suchsystemen auf Databricks:
- Metriken ausbalancieren, nicht nur eine optimieren. Effektive Suchsysteme müssen mehrere Metriken ausbalancieren – man gewinnt selten bei allen Metriken gleichzeitig. Zum Beispiel kann die aggressive Optimierung der Präzision die Latenz erhöhen oder relevante Ergebnisse verbergen, was letztendlich zu frustrierten Käufern führt.
- Echtzeit-Latenz sorgfältig überwachen. Teilen Sie die Latenz nach Pipeline-Stufen auf und verfolgen Sie die Tail-Latenz wie p95/p99, um Engpässe schnell zu identifizieren. Techniken wie Caching können helfen, strenge Latenz-SLAs einzuhalten.
- Metriken systematisch verfolgen. Verwenden Sie MLflow, um Abruf- und Engagement-Metriken über Experimente hinweg zu protokollieren und auszuwerten. Native Abrufgütebewertung wird bald für Databricks AI Search verfügbar sein, was dies noch einfacher macht.
Suche in der Produktion im großen Maßstab — FOX Sports
FOX Sports baute seine KI-gestützte Suchleiste auf Databricks AI Search auf, die Tausende von QPS mit einer 2-fachen Verbesserung der Abfrageerfolgsrate bewältigt. Ihre Architektur, die für den Super Bowl LIX gestartet wurde, demonstriert mehrere Muster, die in diesem Blog behandelt werden:
- Echtzeit-Ingestion. Spark Structured Streaming nimmt kontinuierlich Inhalte in Delta Sync Indexes auf, sobald sie veröffentlicht werden.
- Zweistufige Abfrage. Exakte Entitätserkennung für Spieler und Teams sowie zeitgewichtete semantische Suche für Artikel und Videos, orchestriert von Databricks Model Serving.
- Produktionsoptimierung. Eine Caching-Schicht und eine Funktion für Trend-Suchen – die über 25 % aller Suchanfragen ausmachen – bewältigen hohe Traffic-Spitzen während Live-Events.
Von der Suche zu intelligenten Anwendungen
Produktsuche existiert nicht isoliert – sie ist eine Ebene in einem breiteren Anwendungsstapel. Hier erfahren Sie, wie der Rest der Databricks-Plattform erweitert, was Sie auf AI Search aufbauen können.
Echtzeitanwendungen mit Lakebase
Für kundenorientierte Suchanwendungen – Marktplätze, Produktkataloge, Medienplattformen – ist der Suchindex nur ein Teil der Geschichte. Anwendungen benötigen auch eine transaktionale Datenbank für den operativen Zustand: Lagerbestände, Preise, Benutzersitzungen, Personalisierungspräferenzen. Lakebase bietet dies als vollständig verwaltete, PostgreSQL-kompatible Datenbank, die nativ in die Databricks-Plattform integriert ist. Die verwaltete bidirektionale Synchronisierung mit Delta Lake bedeutet, dass Ranking-Modelle auf den aktuellsten operativen Daten trainiert werden und analytische Erkenntnisse zurück in die Anwendungsschicht fließen – alles gesteuert durch Unity Catalog.
Agentengesteuerte Suche mit Agent Bricks
Databricks stellt automatisch einen verwalteten MCP-Server für jeden AI Search-Index bereit, wodurch mehrere Integrationsmuster freigeschaltet werden:
- Wissensassistent. Ein Frage-Antwort-Chatbot für Ihre Dokumente. Richten Sie ihn auf einen AI Search-Index und erhalten Sie produktionsreife Dokumentensuche mit Zitaten. Verwendet Instructed Retriever im Hintergrund – 70 % bessere Genauigkeit als Vanilla RAG und 30 % besser als Agentic RAG.
- Benutzerdefinierte Agenten. Verwenden Sie das VectorSearchRetrieverTool oder MCP mit jedem Framework (OpenAI Agents SDK, LangGraph, LlamaIndex). Volle Kontrolle über Abrufparameter, Embeddings und Filter. Bereitstellung als Databricks Apps mit MLflow-Tracing.
- Supervisor-Agent. Orchestriert mehrere Unteragenten: einen Wissensassistenten für Dokumenten-Q&A, einen Genie-Bereich für strukturierte Datenabfragen und UC-Funktionen für benutzerdefinierte Geschäftslogik – alles koordiniert von einem einzigen Supervisor.
Fazit
Der Aufbau eines modernen Produktsuchsystems erfordert mehr als nur einen Suchindex. Er erfordert eine Infrastruktur, die für die Bewältigung von realem Umfang, Leistung und Beobachtbarkeit ausgelegt ist:
- Latenzarme Ausführung. Abfrageverständnis, Abruf, Filterung und Neuordnung müssen innerhalb strenger p95/p99-Latenzbudgets abgeschlossen sein.
- Hybride Abruffähigkeit. Kombinieren Sie semantische Ähnlichkeit (Embeddings) mit strukturierter Filterung wie Preis, Kategorie oder Verfügbarkeit.
- Skalierbarkeit unter Last. Bewältigen Sie hohe QPS und Nebenläufigkeit während Spitzenverkehrszeiten, ohne die Leistung zu beeinträchtigen.
- Beobachtbarkeit. Sorgen Sie für klare Sichtbarkeit von Latenzaufschlüsselungen, Ranking-Leistung und allgemeiner Systemgesundheit.
- Standardmäßig agentenbereit. Jeder AI Search-Index ist ein MCP-Tool, das sofort vom Wissensassistenten, benutzerdefinierten Agenten und Supervisor-Agenten verwendet werden kann.
- Full-Stack-Betriebsunterstützung. Lakebase bietet die transaktionale Datenbank für den Echtzeit-Anwendungszustand, synchronisiert mit Delta ohne ETL.
Bereit zum Erstellen? Folgen Sie dem Leitfaden zur Abrufqualität, um Ihre Suchpipeline zu benchmarken und zu optimieren, sehen Sie, wie FOX Sports KI-gestützte Suche im großen Maßstab aufgebaut hat, und tauchen Sie in die Dokumentation zu AI Search ein, um loszulegen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.