coSTAR: Wie wir KI-Agenten bei Databricks schnell und ohne Probleme ausliefern
Wie wir von zweiwöchigen manuellen Überprüfungen zu automatisierten Test-und-Verfeinerungsprozessen in Stunden übergegangen sind
von Alkis Polyzotis
- Wir entwickeln und stellen Agenten bei Databricks mit einer umfassenden, automatisierten Test- und Verfeinerungsmethodik namens coSTAR (coupled Scenario, Trace, Assess, Refine) bereit, die wir mit MLflow entwickelt haben. Die Methodik ist um eine Analogie zur traditionellen Softwareentwicklung strukturiert, wobei LLM-Juroren als Testsuite und ein Coding-Assistent zur automatischen Verfeinerung der Agentenimplementierung verwendet werden, bis die Tests erfolgreich sind.
- Diese Methodik hat die frühere langsame, manuelle "Ausführen, Überprüfen, Beheben, Wiederholen"-Entwicklungsschleife eliminiert, die anfällig für Regressionen war und an Vertrauen mangelte. coSTAR hat die Zeit zur Überprüfung von Änderungen von zwei Wochen auf Stunden reduziert, was eine höhere Entwicklungsgeschwindigkeit ermöglicht.
- Dieselben Tests werden in der Produktion ausgeführt, um Probleme mit dem tatsächlichen Benutzerverkehr zu erkennen, und als Teil unserer CI/CD-Pipelines, um Regressionen zu kennzeichnen, die durch Änderungen in abhängiger Infrastruktur verursacht werden.
Sie würden niemals einen Coding-Assistenten Ihren Code refaktorisieren lassen, ohne eine Testsuite. Ohne Tests fliegt der Assistent blind. Er könnte eine Funktion reparieren und drei andere stillschweigend kaputt machen. Die Tests schließen den Kreis: Führen Sie sie aus, beobachten Sie Fehler, reparieren Sie den Code, führen Sie sie erneut aus. Keine Tests, kein Vertrauen.
Bei Databricks entwickeln und setzen wir kontinuierlich Agenten ein, die eine breite Palette von Funktionalitäten abdecken, von neuen Funktionen auf der Databricks-Plattform (z. B. die Data-Engineering-, Trace-Analyse- und Machine-Learning-Funktionen in Genie Code) über OSS-Projekte (z. B. den MLflow-Assistenten) bis hin zu internen Engineering-Workflows (z. B. On-Call-Support oder automatisierte Code-Reviewer). Diese Agenten können langwierige Aufgaben ausführen, Tausende von Codezeilen generieren und unter anderem neue Daten- und KI-Assets erstellen. Obwohl wir frühzeitig einige grundlegende Prüfungen hatten, fehlte uns die Art von umfassender, automatisierter Testsuite, die uns ein vertrauensvolles Iterieren ermöglicht hätte. Dieser Beitrag beschreibt, wie wir diese Lücke mit MLflow und der von uns entwickelten Best-Practice-Methodik coSTAR (coupled Scenario, Trace, Assess, Refine) geschlossen haben. coSTAR führt zwei gekoppelte Schleifen aus: eine, die Juroren mit menschlichem Expertenurteil abgleicht, damit sie vertrauenswürdig sind, und eine, die diese vertrauenswürdigen Juroren nutzt, um den Agenten automatisch zu verfeinern, bis er alle Testszenarien besteht.
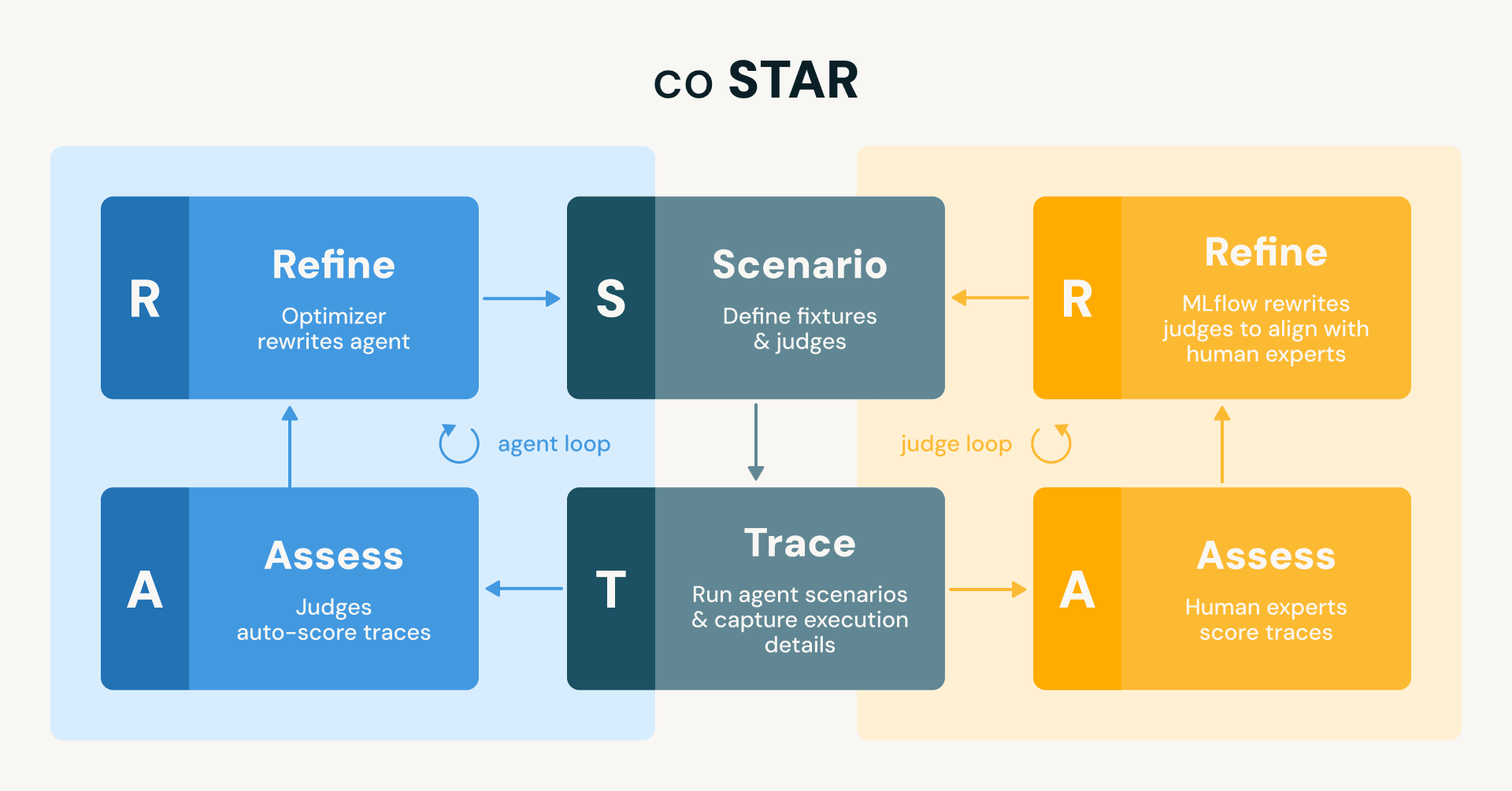
Abbildung: Das coSTAR-Framework führt zwei gespiegelte STAR-Schleifen aus (Szenario → Trace → Assess → Refine). Die Agentenschleife (blau) verwendet Juroren, um Traces automatisch zu bewerten und den Agenten zur Abstimmung mit den Juroren zu verfeinern. Die Jurorenschleife (orange) verwendet menschliche Experten, um Traces zu bewerten und verfeinert die Juroren zur Abstimmung mit ihren Bewertungen. Beide Schleifen teilen sich dieselben Szenarien und Traces.
Das Problem: Codieren ohne Tests
Anfangs sah unsere Entwicklungs-Schleife so aus: Agent ausführen, Ausgabe manuell überprüfen, Fehler finden, Coding-Assistenten anweisen, ihn zu beheben. Wiederholen.
Wenn Sie das an das Schreiben von Code ohne Tests und die manuelle Qualitätssicherung jeder Änderung erinnert, dann ist es genau das. Und es scheiterte genau so, wie Sie es vorhersagen würden. Die offensichtliche Reaktion ist: "Dann schreiben Sie Tests." Aber das Testen von Agenten unterscheidet sich strukturell vom Testen einer deterministischen Funktion, und mehrere Herausforderungen verschärfen sich gleichzeitig:
- Nicht-Determinismus. Dieselbe Implementierung, dieselbe Eingabe kann bei verschiedenen Ausführungen unterschiedliche Ausgaben erzeugen. Tests müssen Eigenschaften der Ausgabe auswerten, anstatt exakte Ausgaben zu behaupten.
- Langsame Feedbackschleifen. Eine einzelne Agentenausführung kann zehn Minuten dauern. Es gibt kein Iterieren, wie es eine untersekundenschnelle Testsuite ermöglicht. Jeder Bewertungszyklus ist teuer.
- Kaskadierende Fehler. Eine falsche Entscheidung in Schritt 3 verursacht einen Fehler in Schritt 7. Bis das Symptom auftritt, ist die Ursache mehrere Schritte zurück in der Agentenausführung vergraben.
- Subjektive Qualität. Für viele Testdimensionen (Ist dieser Feature-Engineering-Code gut? Ist dieser Datenbereinigungsansatz angemessen?) gibt es keine Wahrheit. Die Bewertung dieser Dimensionen hängt von Fachwissen ab.
Diese Einschränkungen prägten jede nachfolgende Designentscheidung. Sie sind auch das, was dieses Problem interessant macht: Wir bauen nicht nur einen Test-Runner, sondern eine automatisierte Optimierungsmethodik für stochastische, langlaufende, mehrstufige Prozesse, bei denen "korrekt" eine Ermessensentscheidung ist.
Die Analogie, die unseren Ansatz leitet
Wenn man genau hinsieht, passt die Agentenentwicklung sauber in die Entwicklungs-Schleife, die jeder Ingenieur bereits kennt:
| Traditionelle Software | Agentenentwicklung |
|---|---|
| Quellcode | Agentenimplementierung (einschließlich Prompts, Auswahl von FMs, Tools) |
| Testsuite | LLM-Juroren |
| Test-Fixtures (Setup, Eingabe, erwartete Ausgabe) | Szenariodefinitionen (Anfangszustand, Prompt, Erwartungen) |
| Test-Runner / Harness | Test-Harness führt den zu testenden Agenten aus, erzeugt Traces |
| Testkorrektheit (prüfen die Tests das Richtige?) | Juroren-Abgleich (stimmt der Juror mit menschlichen Experten überein?) |
| Coding-Assistent repariert Code, bis Tests bestanden sind | Coding-Assistent verfeinert die Implementierung, bis Juroren bestehen |
| CI führt alle Tests bei jeder Änderung aus | CI führt Szenarien + Juroren bei jeder Änderung aus |
| Produktionsüberwachung | Dieselbe Juroren laufen auf Live-Traffic |
Diese Analogie ist nicht nur illustrativ. Sie ist die buchstäbliche Architektur unseres Systems, das wir coSTAR nennen: zwei coupled Schleifen, die Szenariodefinitionen als Test-Fixtures, Trace-Erfassung als Test-Harness, Assessment mit Juroren als Testsuite und Refinement als Rot-Grün-Schleife verwenden. Lassen Sie uns jedes Teil durchgehen.
S - Szenariodefinitionen
Im traditionellen Testen richtet ein Test-Fixture die Vorbedingungen ein: Datenbank erstellen, mit Daten füllen, Umgebung konfigurieren. Unser Äquivalent ist eine Szenariodefinition: eine strukturierte Beschreibung des Anfangszustands, des Benutzer-Prompts und der erwarteten Ergebnisse.
Hier ist ein vereinfachtes Szenario zum Testen eines Data Analyst Agenten gegen einen unordentlichen Datensatz:
Jedes Szenario bündelt Setup, Eingabe und Erfolgskriterien an einem Ort, genau wie ein Test-Fixture. Wir pflegen eine Suite davon für verschiedene Agenten, die gängige Fälle, Randfälle und bekannte frühere Fehler abdeckt. Die Suite wächst im Laufe der Zeit, wenn wir neue Fehlerarten entdecken: Jeder Fehler, den wir in der Produktion finden, wird zu einem neuen Szenario, genauso wie jeder Produktionsfehler zu einem Regressionstest werden sollte.
Warum dieser Aufwand mit dieser Struktur? Weil Agentenausführungen teuer sind. Ein einzelnes Szenario dauert Minuten. Wir müssen überlegt entscheiden, was wir testen, und die Szenariodefinitionen müssen portabel sein: dasselbe Szenario kann gegen verschiedene Agentenimplementierungen oder verschiedene Versionen desselben Agenten ausgeführt werden.
T - Trace Capture
Um unsere Testsuite auszuführen, verwenden wir ein Harness, das den Prompt jedes Szenarios an den zu testenden Agenten (AUT) sendet. Jede Ausführung wird als MLflow Trace erfasst: ein strukturiertes Protokoll jedes Tool-Aufrufs, jeder Zwischenausgabe und jedes Artefakts, das der Agent produziert. Stellen Sie es sich wie einen Flugschreiber vor: Es erfasst alles, was der Agent getan hat, in der richtigen Reihenfolge, sodass wir jeden Teil der Ausführung im Nachhinein inspizieren können.
Eine wichtige architektonische Entscheidung: Wir entkoppeln Ausführung von Bewertung. Das Test-Harness erzeugt Traces; die Juroren (die wir als nächstes vorstellen) bewerten sie. Dies sind getrennte Schritte. Durch das Speichern von Traces können wir Juroren überarbeiten, ohne Szenarien erneut auszuführen. Einen Schwellenwert ändern? Bewerten Sie die aufgezeichneten Traces in Sekunden neu. Einen neuen Juror hinzufügen? Führen Sie ihn gegen alle gesammelten Traces aus. Verdacht auf einen falschen Juror? Vergleichen Sie seine Urteile mit den Aufzeichnungen und debuggen Sie ihn offline. Eine teure Agentenausführung liefert Daten, die mehrmals wiederverwendet werden, einschließlich Kandidaten für den Golden Set, den wir später zur Abstimmung der Juroren verwenden werden.
A - Assess with Judges
Juroren arbeiten mit Traces und beurteilen Eigenschaften der Ausführung: Hat der Agent gültigen Code produziert? Hat die Ausgabe einen Qualitätsschwellenwert erreicht? Hat der Agent den richtigen Prozess befolgt? Wie bereits erwähnt, unterscheidet sich diese Bewertung von traditionellen Unit-Tests: Die Agentenausgabe ist nicht-deterministisch und reichhaltig, daher ist die Behauptung exakter Ausgaben im Wesentlichen nutzlos.
Der Standardansatz zur Implementierung dieser Juroren ist "LLM-as-a-Judge": Füttern Sie den vollständigen Trace in ein Modell und bitten Sie um eine Bewertung und, was noch wichtiger ist, um eine Begründung für diese Bewertung. Das ist jedoch, als würde man einen Test schreiben, der den gesamten Programmzustand in eine Assertion einfügt. Es ist teuer, fehleranfällig und schwer zu debuggen. Für unsere Agenten kann ein einzelner Trace Tausende von Zeilen lang sein. Das Einfügen in das Kontextfenster eines Juroren verschlechtert die Urteilsqualität.
Stattdessen verwenden wir MLflows agentic Judges: Juroren, die selbst Agenten sind und mit Werkzeugen ausgestattet sind, um den Trace selektiv zu erkunden. Genau wie ein gut geschriebener Test eine bestimmte Funktion aufruft und einen bestimmten Rückgabewert prüft, ruft ein agentic Judge ein bestimmtes Werkzeug auf dem Trace auf und prüft eine bestimmte Eigenschaft.
Hier sind einige Beispiel-Juroren, die wir für unsere Agenten verwendet haben:
Skill-Invocation-Juror untersucht den Trace und stellt fest, ob der Agent Skills aufgerufen hat, die vom Szenario anvisiert sind (wenn nicht, ist der Zweck des Skills für den AUT nicht klar):
Best-Practices-Juror prüft, ob die Ausgabe den Best Practices gemäß der offiziellen Databricks-Dokumentation entspricht:
Outcome Judge inspects the trace for output assets and asserts certain properties. Going back to the Data Analyst example, identify the part of the trace where engineering code was authored and evaluate whether the code is appropriate for the task at hand:
This judge is interesting because it tackles the subjective quality problem head-on: what counts as good feature engineering depends on domain expertise. An LLM judge can't get this right out of the box. It's tempting to try writing out the complete criteria in the judge's prompt: "prefer median imputation over mean for skewed distributions, always scale features before distance-based models, ..." But encoding a domain expert's full judgment into a prompt is laborious and brittle. It's much easier for humans to look at an example and say "this is good" or "this is bad" than to write out the complete spec. This is exactly why alignment works, as we'll cover shortly.
In general, our test suite for a single agent includes judges across several categories:
Deterministic checks, things we can verify mechanically, no LLM needed:
- Syntax/linting on generated code
- Output schema validation (do expected tables exist? are column types correct?)
- Tool sequence linting (did the agent read the error logs before trying to fix the issue, or did it skip straight to editing code?)
LLM-based checks, judgment calls that require understanding context:
- Code diff guidelines (did the agent change unrelated lines? did it introduce deprecated APIs?)
- Best practice adherence (is the generated code following the conventions for this domain?)
Operational metrics, signals that don't pass/fail individually but track health over time:
- Token usage (high token counts often signal the agent is struggling, retrying, backtracking, or going in circles)
- Tool call counts and failure ratios (a spike in failed tool calls indicates something is wrong)
- Latency (wall-clock time for the agent to complete the task)
The operational metrics deserve a note. They don't gate a release the way pass/fail judges do, but they're critical for cost management and early warning. If token usage doubles after a change, something went wrong even if all judges still pass; the agent is probably doing more work than it should. We track these over time and alert on anomalies.
Growing the test suite over time
Test suites don't get authored in one sitting. They evolve over time. They start with the simplest checks that give a signal: does the output exist? Does it parse? Then structural checks follow: does the output have the right schema, the right columns, the right types? Only later come end-to-end data validation judges: does the output actually produce correct results when you run it?
This mirrors how test suites mature in traditional software. Exhaustive integration tests don't come on day one. It starts with smoke tests, then unit tests as failure modes emerge, building toward end-to-end coverage over time. The key is that the infrastructure supports adding new judges cheaply, so the test suite grows alongside the agent.
Testing the Tests: Judge Alignment
Here's a problem every engineer knows: a flaky or wrong test suite that greenlights bad code ships bugs with confidence. Similarly, judges who approve poor outcomes give a false sense of security. This is where the second loop of the coSTAR framework comes in: the same scenarios and traces that drive agent refinement also drive judge refinement, with human expert scores as the ground truth. This matters because, unlike traditional testing where test correctness can be verified by inspection, LLM judges are stochastic and can drift in how they interpret natural-language criteria. So we need a way to verify them and keep them aligned with human experts.
To do this alignment, we first curate a Golden Set of typically dozens of examples of agent outputs that our engineers have manually assessed. This is the ground truth the judges must agree with. Then we leverage MLflow's alignment capabilities (powered by techniques like GEPA and MemAlign) to automatically refine the judge against the Golden Set. Notice this is structurally the same STAR loop we use to refine the AUT itself, but the assess step is performed by human experts and the refine step applies to the judge.
R - Refine
With judges that the judge loop has aligned against human expert judgment, we can now trust the agent loop. A coding assistant treats the agent as its codebase and the judges as its test suite. It reads failures, diagnoses root causes, patches the agent, and re-runs everything. The engineer is still the reviewer and final arbiter of the proposed changes to the agent, but this automated iteration saves considerable human effort in analyzing and improving the agent.
Here's what one iteration looked like for the Data Analyst agent:
Red. We ran the initial version of the agent against our scenario suite. The best-practices judge flagged a discrepancy: our agent was generating code for logical views that was different from our official recommendations/documentation. While this discrepancy would not affect correctness, it had implications on the maintenance and deployment of the generated code. This is an example of an insidious regression that would be hard to catch by manual investigation.
Green. The coding assistant analyzed the judge feedback and identified the gap: the agent was using a skill that was not prescriptive about the type of views that should be created (temporary vs permanent). After adding the relevant guidance to the skill, the tests passed successfully and the change was verified to not introduce other regression (based on other test scenarios).
Regression Tests for Infrastructure, Not Just the Agent
So far we've described judges as tests for the agent, catching regressions when the agent implementation changes. But in practice, the agent itself isn't the only thing that changes. The agent depends on external tools and infrastructure, and those change too.
Our agents call MCP tools, standardized interfaces for data access, code execution, environment setup, and more. These tools have their own development teams and release cycles. When a tool changes its implementation (say, a code execution tool starts returning stderr in a different format, or a data access tool changes how it handles null values) the agent hasn't changed at all, but the agent's behavior can break.
Because we run our judges on every nightly build, they act as regression tests against the full stack, not just the agent’s current implementation. When a tool team ships a change that causes an agent to start failing its judges then we catch the error immediately, before it reaches customers. More importantly, the judge's failure tells us what broke (the specific quality dimension that regressed), which makes it far easier to triage whether the root cause is in the agent or in a tool the agent depends on.
This is the same value that integration tests provide in traditional software: they guard the contract between the code and its dependencies. The only difference is that here, the "code" is an agent and the "dependencies" are MCP tools.
From Eval to Production Monitoring
There's one more extension of the testing analogy that turned out to be surprisingly valuable: running the same judges on production traffic.
In traditional software, testing doesn't stop at CI. Production gets monitored too: error rates, latency percentiles, business metrics on live traffic. The same test logic that validates code in dev often reappears as health checks and alerts in prod.
We do the same thing. The judges we built for eval are designed to score any agent conversation, not just eval scenarios. So we run them (or a sampled subset) on real production conversations. This gives us:
- Early warning on drift. If judge's pass rate drops on production conversations, something changed. Maybe a model upgrade degraded quality, maybe user prompts shifted in a way the agent handles poorly. We see it in the judge scores before we see it in user complaints.
- Real-world signal for the test suite. Production conversations that judges flag as failures become candidates for new eval scenarios. This is how the test suite grows organically: real failures feed back into eval, closing the loop between production and development.
- Cost monitoring at the agent level. We track token usage and tool call counts on production conversations. A quality-neutral change that triples cost is still a regression.
Die zentrale Erkenntnis ist, dass die gleiche Bewertungsinfrastruktur (Juroren, Metriken, aufgezeichnete Spuren) doppelt genutzt wird. Bauen Sie sie einmal für die Evaluierung, und das Produktionsmonitoring ergibt sich als Nebeneffekt.
Wo wir jetzt stehen
Wir haben diese Methodik für mehrere Agenten übernommen, die wir auf der Databricks-Plattform veröffentlicht haben (z. B. die Datenverarbeitung, maschinelles Lernen und Trace-Analysefunktionen in Genie), interne Agenten für die Entwicklerproduktivität sowie andere kundenorientierte Agenten (z. B. AI Dev Kit oder den OSS MLflow Assistant). Insgesamt haben wir greifbare Vorteile gesehen:
- Im Vergleich zu manuellen Evaluierungen haben die automatisierten Testsuiten die Zeit für die Überprüfung von Änderungen von 2 Wochen auf Stunden reduziert. Entsprechend hat dies unseren Teams ermöglicht, Verbesserungen mit höherer Geschwindigkeit auszuliefern.
- Mehrere Testsuiten sind auf Hunderte von Testszenarien pro Agent angewachsen, was unser Vertrauen in das Erkennen von Regressionen erhöht hat.
- Integrationstests haben Änderungen in der abhängigen Infrastruktur gekennzeichnet, die es uns ermöglichten, Regressionen in der Produktion zu verhindern. Beispiele für diese Änderungen sind das TODO-Management-Verhalten im zugrunde liegenden Modell, latenzbeeinflussende Änderungen oder Modelländerungen.
MLflow war auch als GenAI-Testplattform von entscheidender Bedeutung und hat unseren Ingenieuren geholfen, die Methodik zu standardisieren, die Entwicklung von Tests zu beschleunigen und Best Practices teamübergreifend zu teilen.
Was (noch) nicht funktioniert
Die Testanalogie ist auch hier nützlich. Unsere Einschränkungen entsprechen bekannten Testproblemen:
Die Szenariogenerierung ist manuell (das Schreiben von Testfällen ist teuer). Wir haben die Bewertung, Ausrichtung und Optimierung automatisiert, aber die Generierung der Szenarien selbst ist immer noch eine menschliche Aufgabe. Jedes Szenario erfordert die Erstellung eines realistischen Anfangszustands, eines aussagekräftigen Prompts und korrekter Erwartungen. Dies ist der Engpass, der die Größe der Testsuite einschränkt, und eine enge Testsuite führt direkt zum nächsten Problem. Die Automatisierung der Szenariogenerierung (Synthese vielfältiger, realistischer Testfälle aus Produktionsverkehrsmustern oder aus der Spezifikation des Agenten) ist ein aktiver Arbeitsbereich für uns.
Der Coding-Assistent kann sich überanpassen (Testsuite zu eng). Wenn die Testsuite nicht genügend Fälle abdeckt, entwickelt der Coding-Assistent eine Agentenimplementierung, die diese spezifischen Eingaben meistert, aber bei neuen Eingaben versagt. Dies ist das Agentenäquivalent zum Schreiben von Code, der Unit-Tests besteht, aber in der Produktion fehlschlägt. Wir mildern dies, indem wir Produktionsfehler zurück in die Evaluierung einspeisen und die Abdeckung im Laufe der Zeit erweitern, aber solange die Szenariogenerierung nicht automatisiert ist, wächst die Testsuite langsamer, als wir möchten.
Die Ausrichtung der Juroren ist teuer (die Kalibrierung von Tests erfordert menschliche Arbeit). Der Aufbau des Golden Sets erfordert, dass Domänenexperten Ausgaben manuell bewerten, genau der Engpass, den wir zu beseitigen versuchen. Und es ist keine einmalige Kosten: Da sich Agenten weiterentwickeln, müssen Juroren neu kalibriert werden. Wir untersuchen Wege, dies intelligenter zu gestalten, indem wir die Unsicherheit der Juroren messen und die spezifischen Beispiele identifizieren, bei denen der Juror unterdefiniert ist und eine menschliche Kennzeichnung die Mehrdeutigkeit tatsächlich auflösen würde. Das Ziel ist aktives Lernen für die Ausrichtung der Juroren: Anstatt Experten zu bitten, eine zufällige Stichprobe zu bewerten, werden nur die Beispiele angezeigt, bei denen der Juror unsicher ist und die Eingabe eines Domänenexperten seine Kriterien am stärksten schärfen würde.
Mehrstufige Fehler sind schwer zuzuordnen (Ursachenanalyse). Wenn ein Agent in Schritt 7 einer 10-stufigen Pipeline fehlschlägt, lag die Ursache in Schritt 7 oder Schritt 3? Unsere Juroren fangen die Symptome auf, aber der Coding-Assistent behebt manchmal den falschen Schritt, wie z. B. das Beheben eines Testfehlers durch Ändern der falschen Funktion. Bessere kausale Verfolgung ist ein aktiver Arbeitsbereich.
Neue Fehlermodi rutschen durch (Abdeckungslücken). coSTAR optimiert innerhalb der Dimensionen, die die Juroren abdecken. Wenn eine neue Klasse von Fehlern auftritt, die kein Juror prüft, ist sie unsichtbar, genau wie ein Fehler im Code, den kein Test ausführt. coSTAR verbessert sich *innerhalb* seiner Testsuite, kann aber die Testsuite nicht von selbst erweitern. Menschen müssen immer noch neue Fehlermodi bemerken und Juroren hinzufügen.
Wichtige Erkenntnisse
- Die Agentenentwicklung hat ein Testproblem. Ohne automatisierte Evaluierung programmieren Sie ohne Tests und erhalten die Regressionen, die Sie verdienen.
- Geben Sie Juroren Werkzeuge, keine Spuren. Ein agentischer Juror, der gezielte Werkzeuge aufruft, ist wie ein fokussierter Unit-Test. Das vollständige Übergeben der Spur an einen Juror ist wie das Übergeben des Programmzustands an eine Assertion. Das skaliert nicht.
- Testen Sie Ihre Tests. LLM-Juroren sind stochastisch. Richten Sie sie anhand von menschenbewerteten Golden Sets aus, genauso wie Sie eine Testsuite anhand einer Spezifikation validieren würden.
- Schließen Sie den Kreislauf. Der eigentliche Gewinn ist der vollständige coSTAR-Kreislauf: vertrauenswürdige Szenarien, aufgezeichnete Spuren, ausgerichtete Juroren und ein Coding-Assistent, der den Agenten verfeinert, bis die Tests bestanden sind. Evaluierung ohne automatisierte Verfeinerung ist nur die halbe Geschichte.
- Einmal bauen, überall überwachen. Dieselben Juroren, die in der Evaluierung validieren, können die Produktion überwachen. Eine Investition, zwei Erträge.
- Kopplung ist entscheidend. Die Verfeinerung des Agenten ist nur so zuverlässig wie die Juroren, die ihn steuern. Die beiden gekoppelten Schleifen von coSTAR – eine, die Vertrauen in die Juroren verdient, und eine, die dieses Vertrauen nutzt, um den Agenten zu verfeinern – machen die automatisierte Verfeinerung sinnvoll und nicht nur schnell.
Wir bauen coSTAR als Teil von MLflow. Wenn Sie ähnliche Probleme angehen, würden wir uns freuen, davon zu hören.
- Probieren Sie Genie Code aus, um die Funktionalität zu sehen, die wir mit der coSTAR-Methodik ausgeliefert haben.
- Folgen Sie den Tutorials auf MLflow, um mit der Definition und Verwendung von LLM-Juroren für die iterative Agentenverfeinerung zu beginnen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.