Latenz in Apache Spark Structured Streaming unterschreitet eine Sekunde
Verbesserung des Offset-Managements in Project Lightspeed
von Jerry Peng, Pranav Anand, Sourav Gulati, Karthik Ramasamy, Michael Armbrust und Matei Zaharia
Apache Spark Structured Streaming ist die führende Open-Source-Plattform für die Stream-Verarbeitung. Es ist auch die Kerntechnologie hinter dem Streaming auf der Databricks Lakehouse Platform und bietet eine einheitliche API für die Batch- und Stream-Verarbeitung. Da die Nutzung von Streaming schnell zunimmt, möchten verschiedene Anwendungen es für die Entscheidungsfindung in Echtzeit nutzen. Einige dieser Anwendungen, insbesondere solche, die operativer Natur sind, erfordern eine geringere Latenz. Während das Design von Spark einen hohen Durchsatz und eine einfache Nutzung bei geringeren Kosten ermöglicht, wurde es nicht für Latenzzeiten im Subsekundenbereich optimiert.
In diesem Blog konzentrieren wir uns auf die Verbesserungen, die wir am Offset-Management vorgenommen haben, um die inhärente Verarbeitungslatenz von Structured Streaming zu verringern. Diese Verbesserungen zielen in erster Linie auf operative Anwendungsfälle wie Echtzeit-Monitoring und -Warnungen ab, die einfach und zustandslos sind.
Umfassende Auswertungen dieser Verbesserungen zeigen, dass die Latenz um 68–75 % – oder um das bis zu 3-fache – verbessert wurde: von 700–900 ms auf 150–250 ms bei Durchsätzen von 100.000 Ereignissen/Sek., 500.000 Ereignissen/Sek. und 1 Mio. Ereignissen/Sek. Structured Streaming kann jetzt Latenzen von unter 250 ms erreichen und erfüllt damit die SLA-Anforderungen für einen großen Teil der operativen Workloads.
Dieser Artikel setzt voraus, dass der Leser über ein grundlegendes Verständnis von Spark Structured Streaming verfügt. Weitere Informationen finden Sie in der folgenden Dokumentation:
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Motivation
Apache Spark Structured Streaming ist eine verteilte Stream-Processing-Engine, die auf der Apache Spark SQL Engine aufbaut. Es bietet eine API, die es Entwicklern ermöglicht, Datenströme zu verarbeiten, indem sie Streaming-Abfragen auf die gleiche Weise wie Batch-Abfragen schreiben, was das Nachvollziehen und Testen von Streaming-Anwendungen erleichtert. Laut Maven-Downloads ist Structured Streaming heute die am weitesten verbreitete verteilte Open-Source-Streaming-Engine. Einer der Hauptgründe für seine Beliebtheit ist die Performance – hoher Durchsatz bei geringeren Kosten mit einer End-to-End-Latenz von unter wenigen Sekunden. Structured Streaming gibt Benutzern die Flexibilität, den Kompromiss zwischen Durchsatz, Kosten und Latenz auszugleichen.
Da die Nutzung von Streaming in Unternehmen rasant zunimmt, besteht der Wunsch, einer Vielzahl von Anwendungen die Nutzung von Streaming-Datenarchitekturen zu ermöglichen. In unseren Gesprächen mit vielen Kunden sind wir auf Anwendungsfälle gestoßen, die eine konsistente Latenz im Subsekundenbereich erfordern. Solche Anwendungsfälle mit niedriger Latenz entstehen bei Anwendungen wie betrieblichen Warnmeldungen und Echtzeit-Monitoring, auch bekannt als "operative Workloads". Um diese Workloads in Structured Streaming zu integrieren, haben wir 2022 eine Initiative zur Performance-Verbesserung unter Project Lightspeed gestartet. Diese Initiative hat potenzielle Bereiche und Techniken identifiziert, die zur Verbesserung der Verarbeitungslatenz genutzt werden können. In diesem Blog erläutern wir einen solchen Verbesserungsbereich im Detail: das Offset-Management zur Fortschritts-Tracking und wie damit Latenzzeiten im Subsekundenbereich für operative Workloads erzielt werden.
Was sind operative Arbeitslasten?
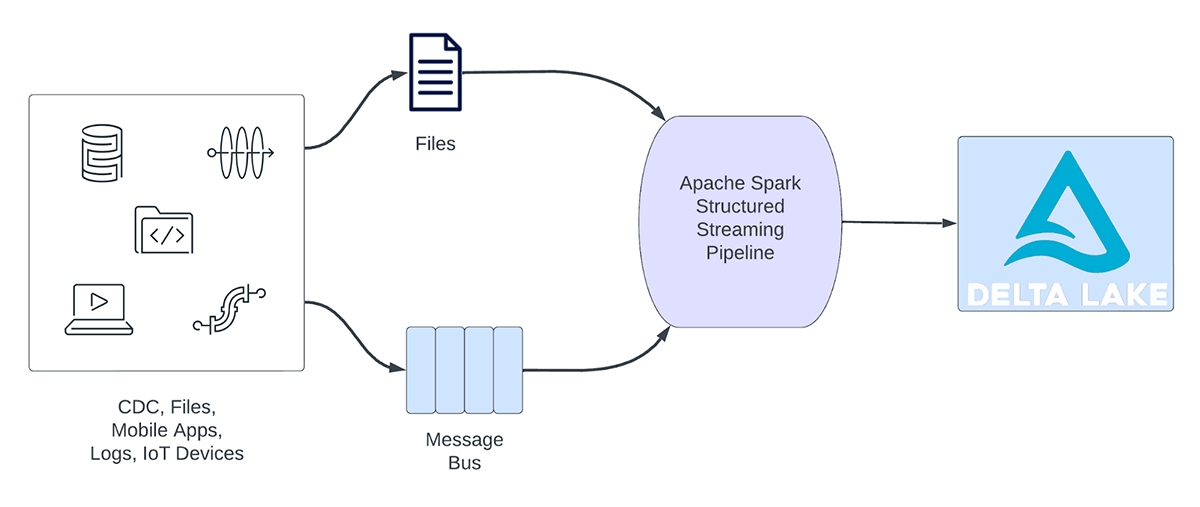
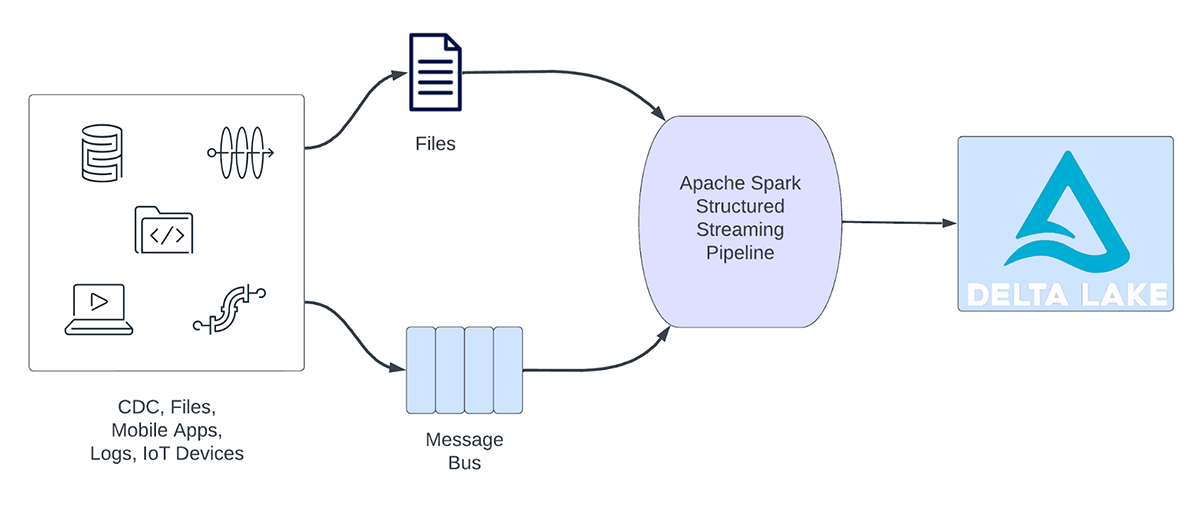
Streaming-Workloads lassen sich grob in analytische und operative Workloads einteilen. Abbildung 1 veranschaulicht sowohl analytische als auch operative Workloads. Analytische Workloads erfassen, transformieren, verarbeiten und analysieren Daten typischerweise in Echtzeit und schreiben die Ergebnisse in Delta Lake, das auf Objektspeichern wie AWS S3, Azure Data Lake Gen2 und Google Cloud Storage basiert. Diese Ergebnisse werden von nachgelagerten Data-Warehousing-Engines und Visualisierungstools genutzt.
{kind=link}
{kind=link}
Abbildung 1. Analytische vs. operative Workloads
Einige Beispiele für analytische Arbeitslasten sind:
- Kundenverhaltensanalysen: Eine Marketingfirma kann Streaming-Analysen verwenden, um das Kundenverhalten in Echtzeit zu analysieren. Durch die Verarbeitung von Clickstream-Daten, Social-Media-Feeds und anderen Informationsquellen kann das System Muster und Präferenzen erkennen, die für eine gezieltere Kundenansprache verwendet werden können.
- Sentimentanalyse: Ein Unternehmen könnte Streaming-Daten von seinen Social-Media-Konten nutzen, um die Kundenstimmung in Echtzeit zu analysieren. So könnte das Unternehmen beispielsweise nach Kunden suchen, die sich positiv oder negativ über die Produkte oder Dienstleistungen des Unternehmens äußern.
- IoT Analytics: Eine Smart City kann Streaming Analytics nutzen, um Verkehrsfluss, Luftqualität und andere Metriken in Echtzeit zu überwachen. Durch die Verarbeitung von Daten von stadtweit eingebetteten Sensoren kann das System Trends erkennen und Entscheidungen über Verkehrsmuster oder Umweltrichtlinien treffen.
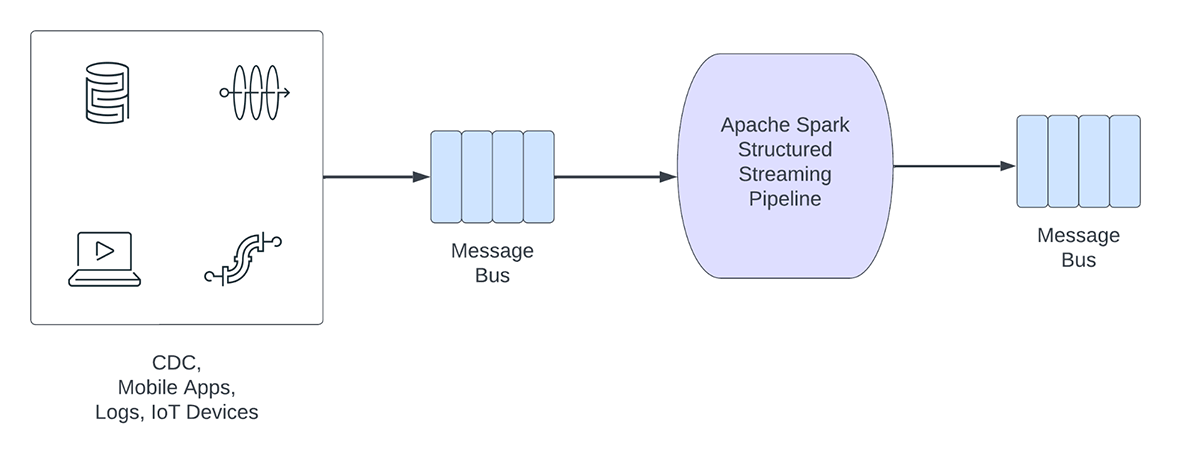
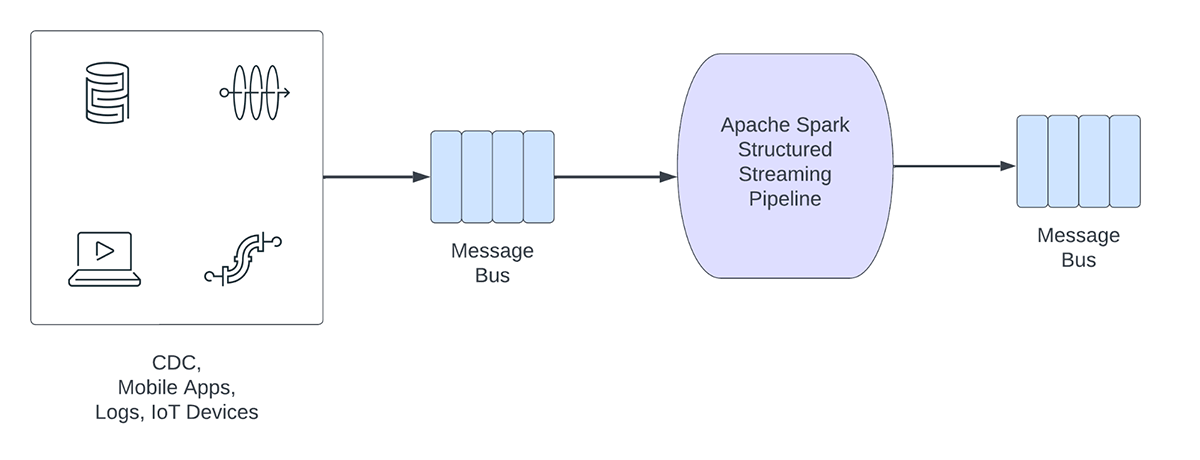
Andererseits erfassen und verarbeiten operative Workloads Daten in Echtzeit und triggern automatisch einen Geschäftsprozess. Einige Beispiele für solche Workloads sind:
- Cybersecurity: Ein Unternehmen könnte Streaming-Daten aus seinem Netzwerk verwenden, um Sicherheits- oder Performance-Probleme zu überwachen. Zum Beispiel könnte das Unternehmen nach Verkehrsspitzen oder unbefugtem Zugriff auf Netzwerke suchen und einen Alert an die Sicherheitsabteilung senden.
- Lecks bei personenbezogenen Daten: Ein Unternehmen kann die logs von Microservices überwachen, analysieren und erkennen, ob personenbezogene Daten (PII) preisgegeben werden, und wenn dies der Fall ist, den Eigentümer des Microservice per E-Mail benachrichtigen.
- Aufzugs-Einsatzsteuerung: Ein Unternehmen könnte die Streaming-Daten des Aufzugs nutzen, um zu erkennen, wann ein Notrufknopf betätigt wird. Wenn aktiviert, könnte es zusätzliche Aufzugsinformationen abrufen, um die Daten anzureichern, und eine Benachrichtigung an das Sicherheitspersonal senden.
- Proaktive Wartung: Mithilfe von Streaming-Daten eines Stromgenerators die Temperatur überwachen und bei Überschreiten eines bestimmten Schwellenwerts den Vorgesetzten informieren.
Operative Streaming-Pipelines weisen die folgenden Merkmale auf:
- Die Latenzerwartungen liegen in der Regel im Subsekundenbereich
- Die Pipelines lesen aus einem Message Bus.
- Die Pipelines führen in der Regel einfache Berechnungen mit Datentransformation oder Datenanreicherung durch.
- Die Pipelines schreiben in einen Message-Bus wie Apache Kafka oder Apache Pulsar oder schnelle Key-Value-Stores wie Apache Cassandra oder Redis zur Downstream-Integration in den Geschäftsprozess
Für diese Anwendungsfälle haben wir beim Profiling von Structured Streaming festgestellt, dass das Offset-Management zur Nachverfolgung des Fortschritts von Micro-Batches viel Zeit in Anspruch nimmt. Im nächsten Abschnitt werden wir das bestehende Offset-Management überprüfen und in den folgenden Abschnitten darlegen, wie wir es verbessert haben.
Was ist Offset-Management?
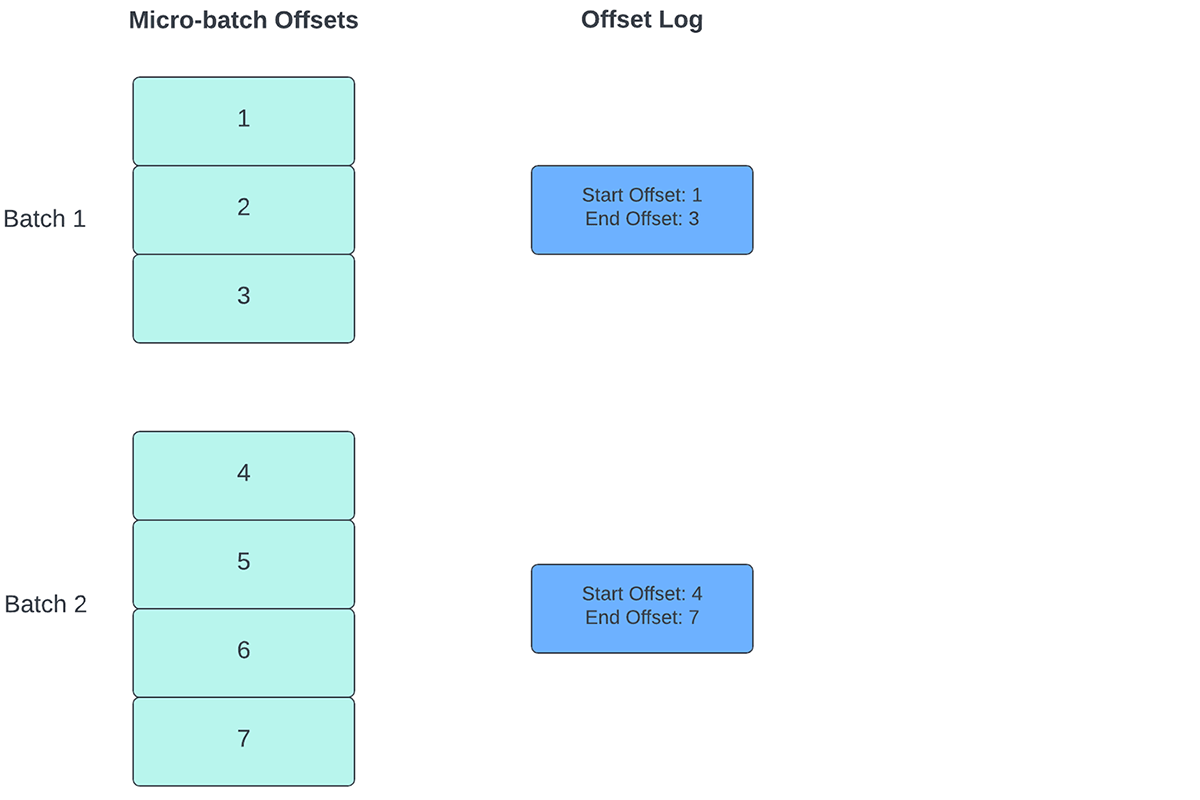
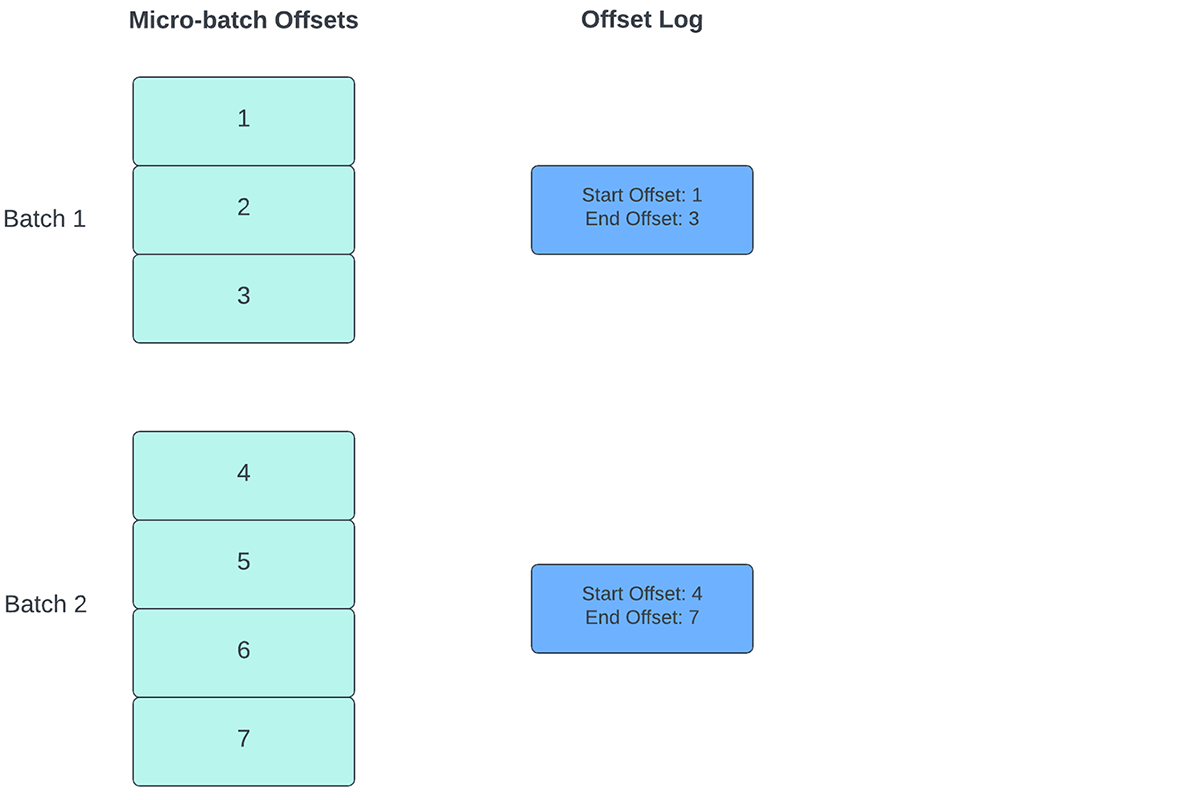
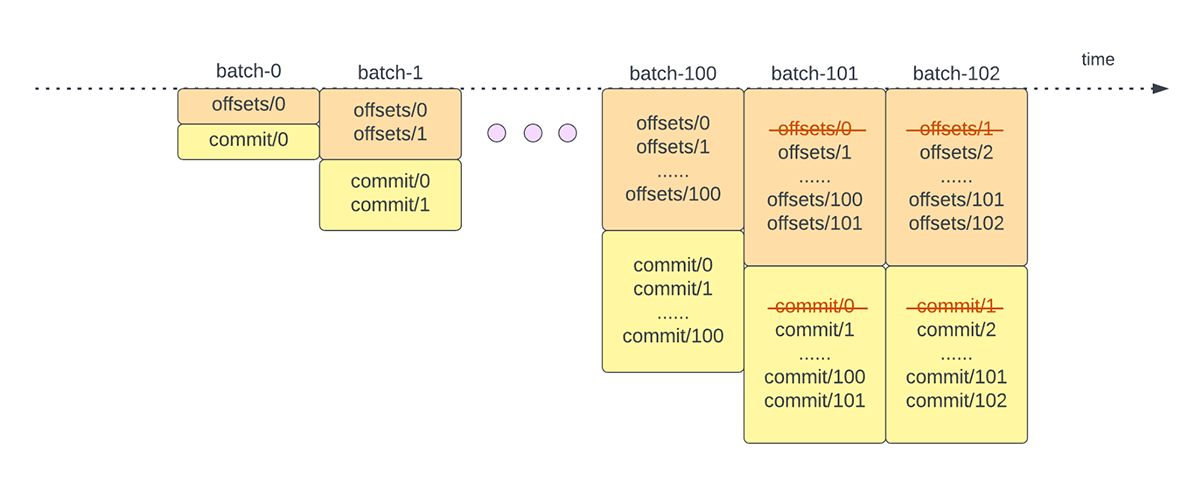
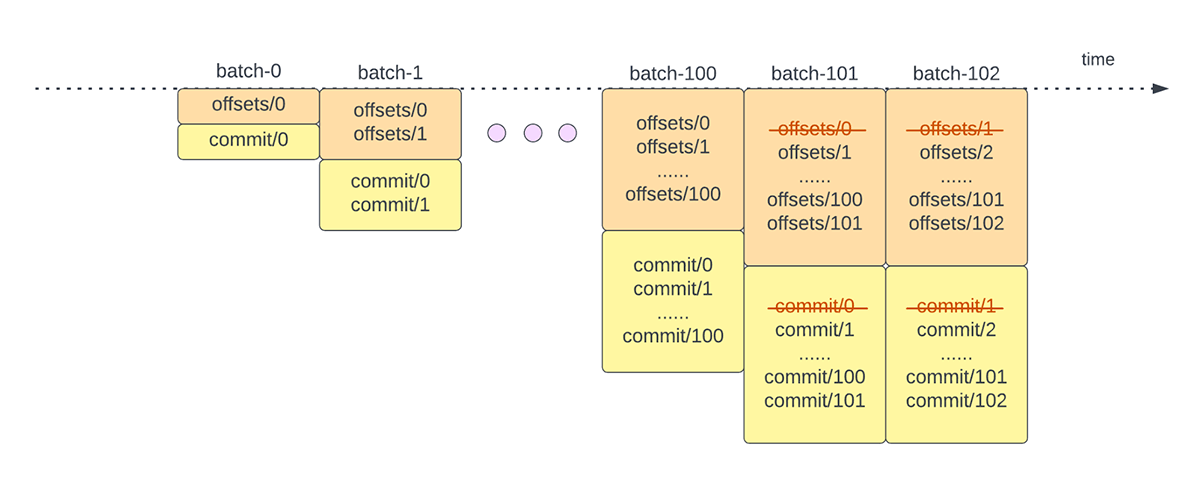
Um den Fortschritt zu verfolgen, bis zu welchem Punkt die Daten verarbeitet wurden, verlässt sich Spark Structured Streaming auf das Persistieren und Verwalten von Offsets, die als Fortschrittsindikatoren verwendet werden. Typischerweise wird ein Offset konkret durch den Quell-Connector definiert, da verschiedene Systeme unterschiedliche Möglichkeiten haben, den Fortschritt oder die Positionen in den Daten darzustellen. Eine konkrete Implementierung eines Offsets kann beispielsweise die Zeilennummer in einer Datei sein, um anzugeben, wie weit die Daten in der Datei verarbeitet wurden. Dauerhafte logs (wie in Abbildung 2 dargestellt) werden verwendet, um diese Offsets zu speichern und den Abschluss von Micro-Batches zu markieren.
{kind=link}
In Structured Streaming werden Daten in Einheiten von Micro-Batches verarbeitet. Für jeden Mikro-Batch werden zwei Offset-Management-Operationen durchgeführt. Einer zu Beginn jedes Micro-Batches und einer am Ende.
- Zu Beginn jedes Micro-Batch (bevor die eigentliche Datenverarbeitung beginnt) wird ein Offset berechnet, basierend darauf, welche neuen Daten aus dem Zielsystem gelesen werden können. Dieser Offset wird in einem dauerhaften Log namens "offsetLog" im Checkpoint-Verzeichnis gespeichert. Dieser Offset wird verwendet, um den Datenbereich zu berechnen, der in "diesem" Micro-Batch verarbeitet wird.
- Am Ende jedes Micro-Batches wird ein Eintrag im dauerhaften Protokoll, dem "commitLog", festgeschrieben, um anzuzeigen, dass „dieser“ Micro-Batch erfolgreich verarbeitet wurde.
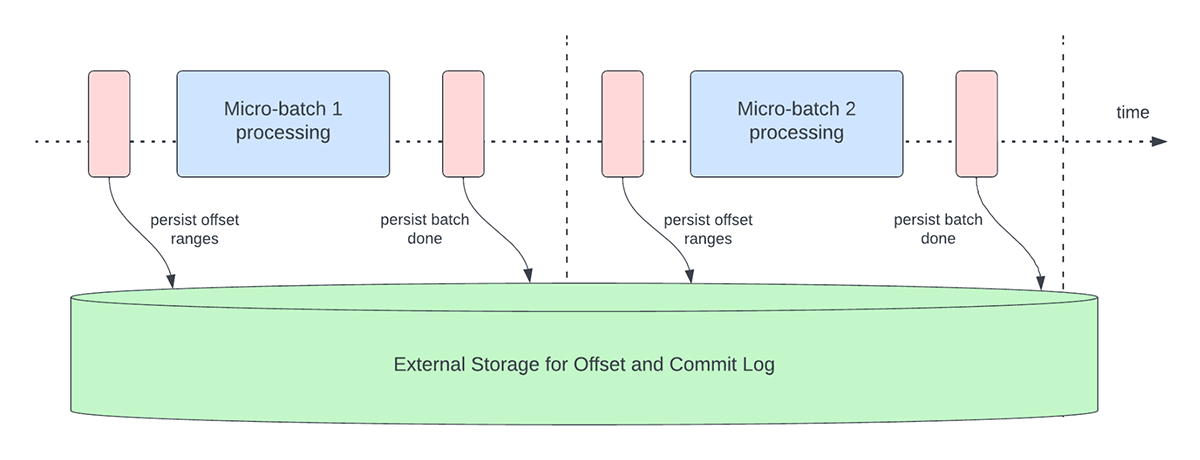
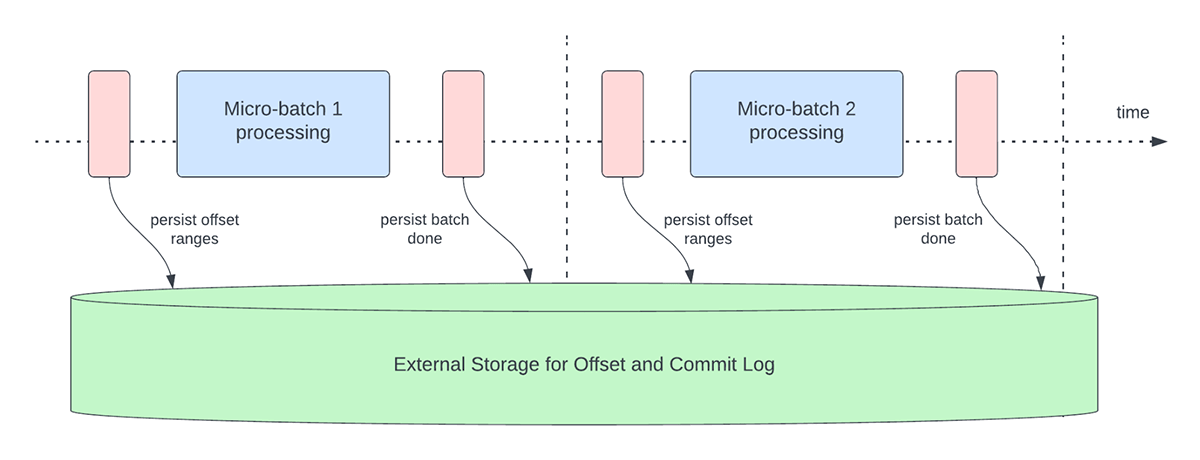
Abbildung 3 unten zeigt den aktuellen Betrieb zur Offset-Verwaltung.
{kind=link}
Eine weitere Offset-Management-Operation wird am Ende jedes Micro-Batch durchgeführt. Bei diesem Vorgang handelt es sich um eine Bereinigung, um alte und nicht mehr benötigte Einträge sowohl aus dem offsetLog als auch aus dem commitLog zu löschen/kürzen, damit diese logs nicht unbegrenzt wachsen.
{kind=link}
Diese Offset-Betriebe werden auf dem kritischen Pfad und inline mit der eigentlichen Verarbeitung der Daten ausgeführt. Das bedeutet, dass sich die Laufzeit dieser Vorgänge direkt auf die Verarbeitungslatenz auswirkt und keine Datenverarbeitung stattfinden kann, bis diese Vorgänge abgeschlossen sind. Dies wirkt sich auch direkt auf die Clusterauslastung aus.
Durch unsere Benchmarking- und Performance-Profiling-Maßnahmen haben wir festgestellt, dass diese Operationen zur Offset-Verwaltung einen Großteil der Verarbeitungszeit in Anspruch nehmen können, insbesondere bei zustandslosen Single-State-Pipelines, die häufig für Anwendungsfälle der operativen Alarmierung und Echtzeit-Monitoring eingesetzt werden.
Performanceverbesserungen in Structured Streaming
Asynchrones Fortschritts-Tracking
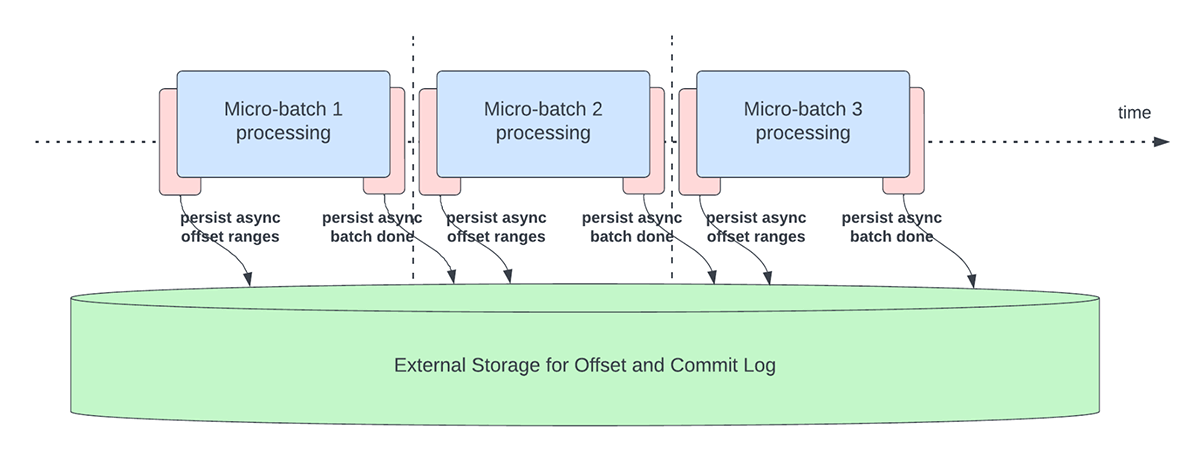
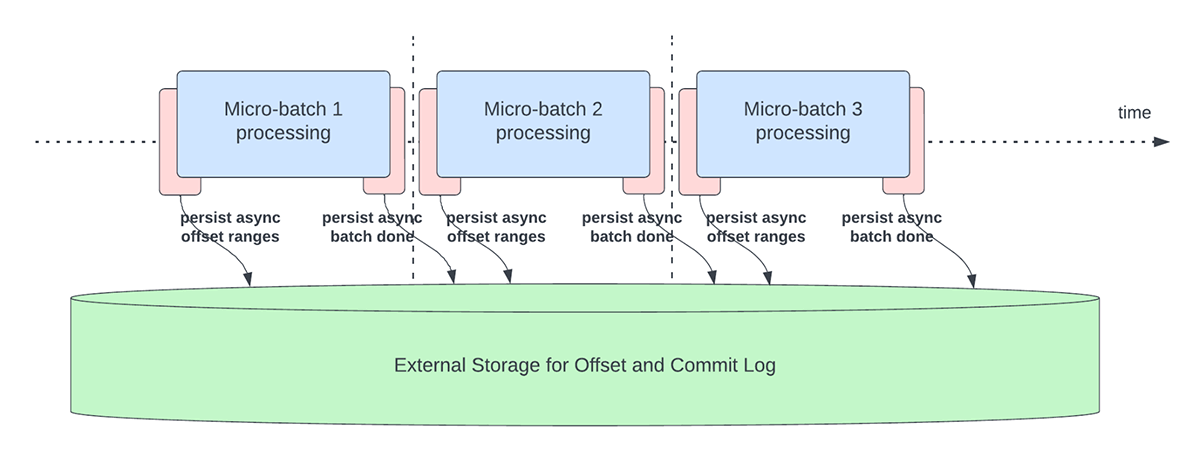
Dieses Feature wurde entwickelt, um den Latenz-Overhead beim Persistieren von Offsets für das Fortschritts-Tracking zu reduzieren. Wenn dieses Feature aktiviert ist, können Structured Streaming-Pipelines den Fortschritt asynchron und parallel zur eigentlichen Datenverarbeitung innerhalb eines Micro-Batches checkpointen, d. h. das offsetLog und das commitLog aktualisieren. Mit anderen Worten, die eigentliche Datenverarbeitung wird durch diese Offset-Verwaltungsbetriebe nicht blockiert, was die Latenz von Anwendungen erheblich verbessert. Die nachstehende Abbildung 5 zeigt dieses neue Verhalten für das Offset-Management.
{kind=link}
In Verbindung mit der asynchronen Durchführung von Updates können Benutzer die Frequenz konfigurieren, mit der der Fortschritt per Checkpoint gesichert wird. Dies ist hilfreich für Szenarien, in denen Offset-Management-Betriebe mit einer höheren Rate auftreten, als sie verarbeitet werden können. Dies geschieht in Pipelines, wenn die für die eigentliche Datenverarbeitung aufgewendete Zeit im Vergleich zu diesen Offset-Management-Vorgängen deutlich geringer ist. In solchen Szenarien entsteht ein ständig wachsender Rückstand an Offset-Management-Betrieben. Um diesen wachsenden Rückstand einzudämmen, muss die Datenverarbeitung blockiert oder verlangsamt werden, was das Verarbeitungsverhalten im Wesentlichen auf dasselbe zurücksetzt, als ob diese Offset-Management-Betriebe inline mit der Datenverarbeitung ausgeführt worden wären. Ein Benutzer muss die Checkpoint-Frequenz in der Regel nicht konfigurieren oder einstellen, da ein angemessener Defaultwert festgelegt wird. Es ist wichtig zu beachten, dass die Zeit für die Wiederherstellung nach einem Fehler mit der Zunahme der Checkpoint-Intervallzeit zunimmt. Im Falle eines Fehlers muss eine Pipeline alle Daten vor dem letzten erfolgreichen Checkpoint erneut verarbeiten. Benutzer können diesen Kompromiss zwischen geringerer Latenz während der normalen Verarbeitung und der Wiederherstellungszeit im Falle eines Fehlers abwägen.
Die folgenden Konfigurationen werden eingeführt, um dieses Feature zu aktivieren und zu konfigurieren:
asyncProgressTrackingEnabled – asynchrone Fortschrittsnachverfolgung aktivieren oder deaktivierenDefault: falsch
asyncProgressCheckpointingInterval – das Intervall, in dem wir Offsets und Abschluss-Commits committen.Default: 1 Minute
Das folgende Codebeispiel veranschaulicht, wie Sie dieses Feature aktivieren:
Beachten Sie, dass dieses Feature nicht mit Trigger.once oder Trigger.availableNow funktioniert, da diese Trigger Pipelines manuell oder zeitgesteuert ausführen. Daher ist die asynchrone Fortschrittsnachverfolgung nicht relevant. Die Abfrage schlägt fehl, wenn sie mit einem der oben genannten Trigger übermittelt wird.
Anwendbarkeit und Einschränkungen
In der/den aktuellen Version(en) gibt es einige Einschränkungen, die sich mit der Weiterentwicklung des Features ändern können:
- Derzeit wird die asynchrone Fortschritts-Tracking nur in zustandslosen Pipelines mit Kafka-Sink unterstützt.
- Eine End-to-End-Verarbeitung mit „Exactly Once“-Garantie wird mit diesem asynchronen Fortschritts-Tracking nicht unterstützt, da die Offset-Bereiche für einen Batch im Fehlerfall geändert werden können. Allerdings unterstützen viele Sinks, wie z. B. der Kafka-Sink, nur „At-least-once“-Garantien, sodass dies möglicherweise keine neue Einschränkung ist.
Asynchrone Logs-Bereinigung
Dieses Feature wurde entwickelt, um den Latenz-Overhead der Log-Bereinigungen zu beheben, die inline innerhalb eines Micro-Batch durchgeführt wurden. Indem dieser Logs-Bereinigungs-/Löschvorgang asynchron im Hintergrund ausgeführt wird, können wir den Latenz-Overhead beseitigen, den dieser Vorgang bei der eigentlichen Datenverarbeitung verursacht. Außerdem müssen diese Löschvorgänge nicht mit jedem Micro-Batch durchgeführt werden und können in einem entspannteren Schedule erfolgen.
Beachten Sie, dass dieses Feature/diese Verbesserung keine Einschränkungen hinsichtlich der Art der Pipelines oder Workloads hat, die sie verwenden können. Daher ist dieses Feature standardmäßig im Hintergrund für alle Structured Streaming Pipelines aktiviert.
Benchmarks
Um die Performance des asynchronen Fortschritts-Trackings und der asynchronen Log-Bereinigung zu verstehen, haben wir einige Benchmarks erstellt. Unser Ziel bei den Benchmarks ist es, den Performance-Unterschied zu verstehen, den das verbesserte Offset-Management in einer End-to-End-Streaming-Pipeline bietet. Die Benchmarks sind in zwei Kategorien unterteilt:
- Rate von der Quelle zur Statistik-Senke – In diesem Benchmark haben wir eine einfache, zustandslose Quelle und Senke zur Erfassung von Statistiken verwendet, mit der sich der Performance-Unterschied der Core-Engine ohne externe Abhängigkeiten ermitteln lässt.
- Kafka-Quelle zu Kafka-Senke – Für diesen Benchmark übertragen wir Daten von einer Kafka-Quelle zu einer Kafka-Senke. Dies entspricht einem Praxisszenario, um zu sehen, wie der Unterschied in einem Produktionsszenario aussehen würde.
Für beide Benchmarks haben wir die End-to-End-Latenz (50. Perzentil, 99. Perzentil) bei verschiedenen Dateneingaberaten (100.000 Ereignisse/Sek., 500.000 Ereignisse/Sek., 1 Mio. Ereignisse/Sek.) gemessen.
Benchmark-Methodik
Die Hauptmethodik bestand darin, Daten aus einer Quelle mit einem bestimmten konstanten Durchsatz zu generieren. Die generierten Datensätze enthalten Informationen darüber, wann sie erstellt wurden. Auf der Senkenseite verwenden wir die Apache DataSketches -Bibliothek, um in jedem Batch die Differenz zwischen dem Zeitpunkt, zu dem die Senke den Datensatz verarbeitet, und dem Zeitpunkt seiner Erstellung zu erfassen. Dies wird zur Berechnung der Latenz verwendet. Wir haben für alle Experimente denselben Cluster mit der gleichen Anzahl von Knoten verwendet.
Hinweis: Für den Kafka-Benchmark legen wir einige Knoten eines Clusters für die Ausführung von Kafka und die Generierung von Daten zur Einspeisung in Kafka beiseite. Wir berechnen die Latenz eines Datensatzes erst, nachdem der Datensatz erfolgreich in Kafka (auf der Senke) veröffentlicht wurde.
Rate Source zu Stat Sink Benchmark
Für diesen Benchmark haben wir einen Spark-Cluster mit 7 Worker-Knoten (i3.2xlarge – 4 Kerne, 61 GiB Speicher) unter Verwendung der Databricks runtime (11.3) verwendet. Wir haben die End-to-End-Latenz für die folgenden Szenarien gemessen, um den Beitrag jeder Verbesserung zu quantifizieren.
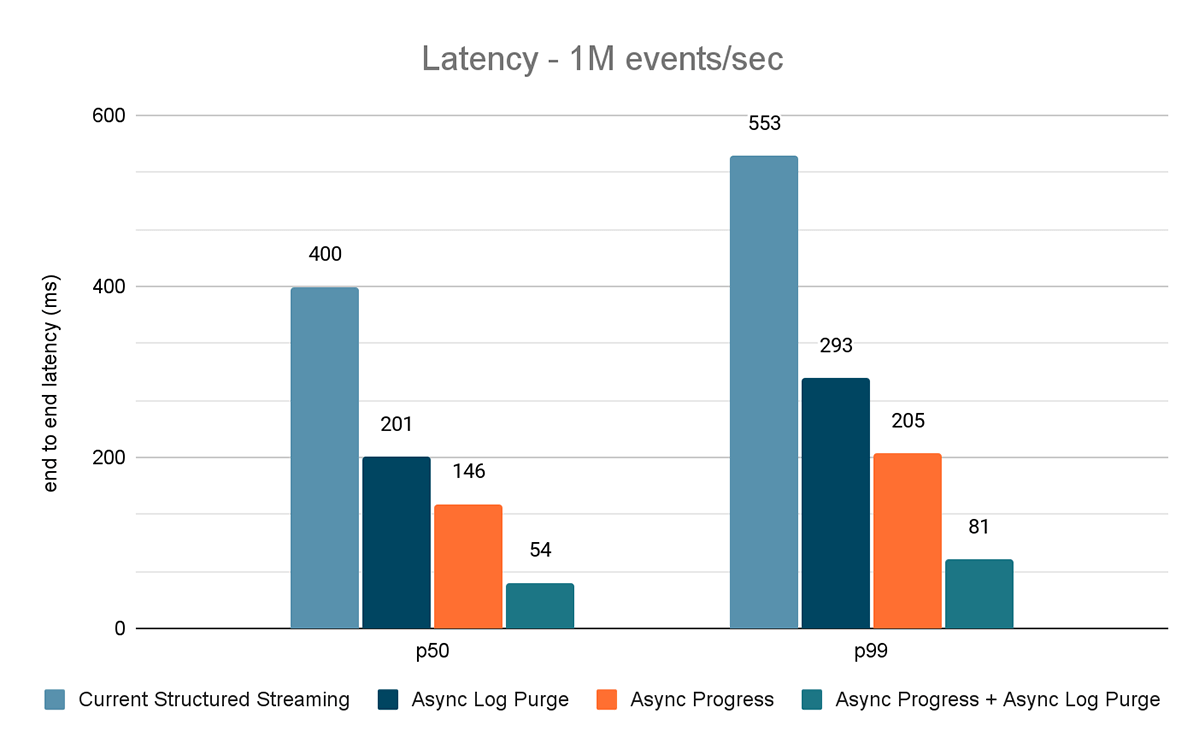
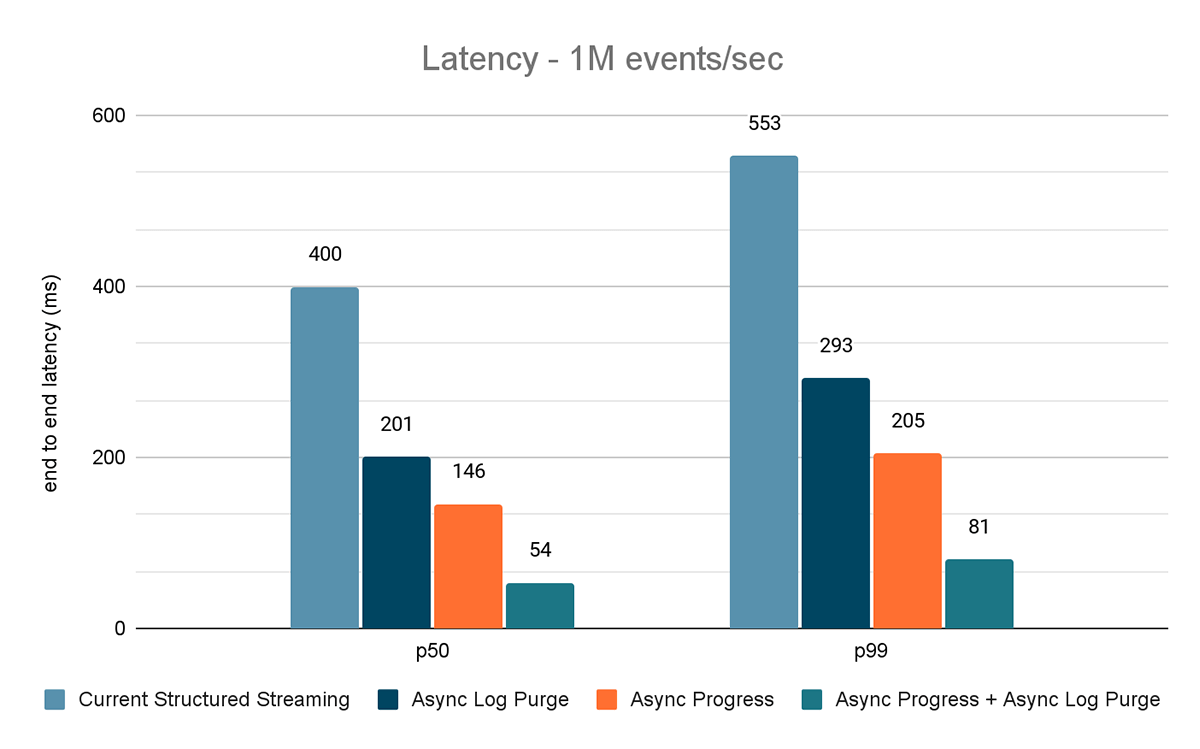
- Aktuelles Structured Streaming – dies ist die Basislatenz ohne die oben genannten Verbesserungen
- Asynchrone Log-Bereinigung – dies misst die Latenz, nachdem nur die asynchrone Log-Bereinigung angewendet wurde
- Async Progress – dies misst die Latenz nach Anwendung des asynchronen Fortschritts-Trackings
- Asynchroner Fortschritt + asynchrone Log-Bereinigung – dies misst die Latenz, nachdem beide Verbesserungen angewendet wurden
Die Ergebnisse dieser Experimente sind in den Abbildungen 6, 7 und 8 dargestellt. Wie Sie sehen können, reduziert Async Log Purging die Latenz konsistent um etwa 50 %. Ebenso verbessert Async Progress Tracking allein die Latenz um etwa 65 %. In Kombination reduziert sich die Latenz um 85–86 % und sinkt auf unter 100 ms.
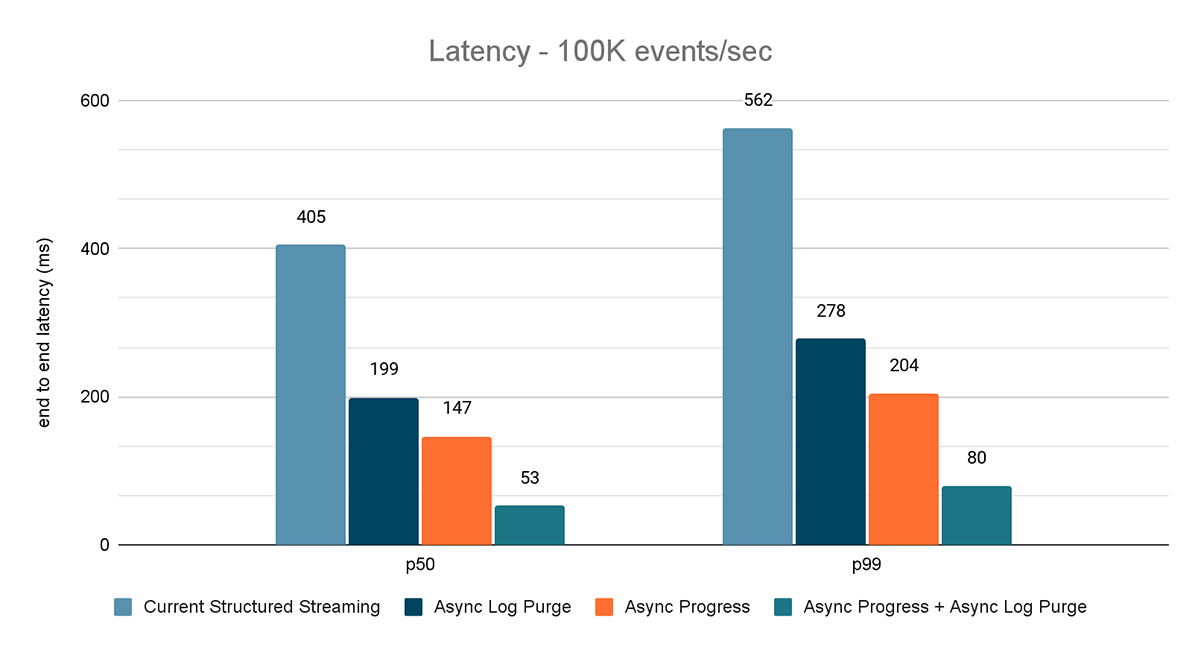
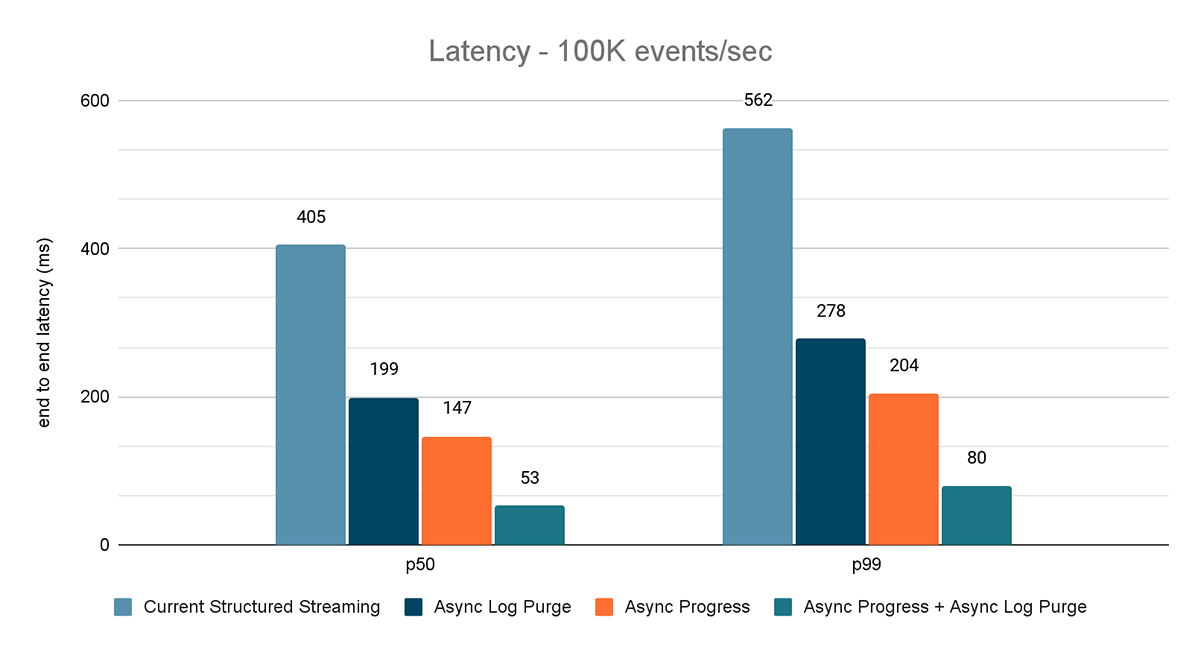{kind=link}
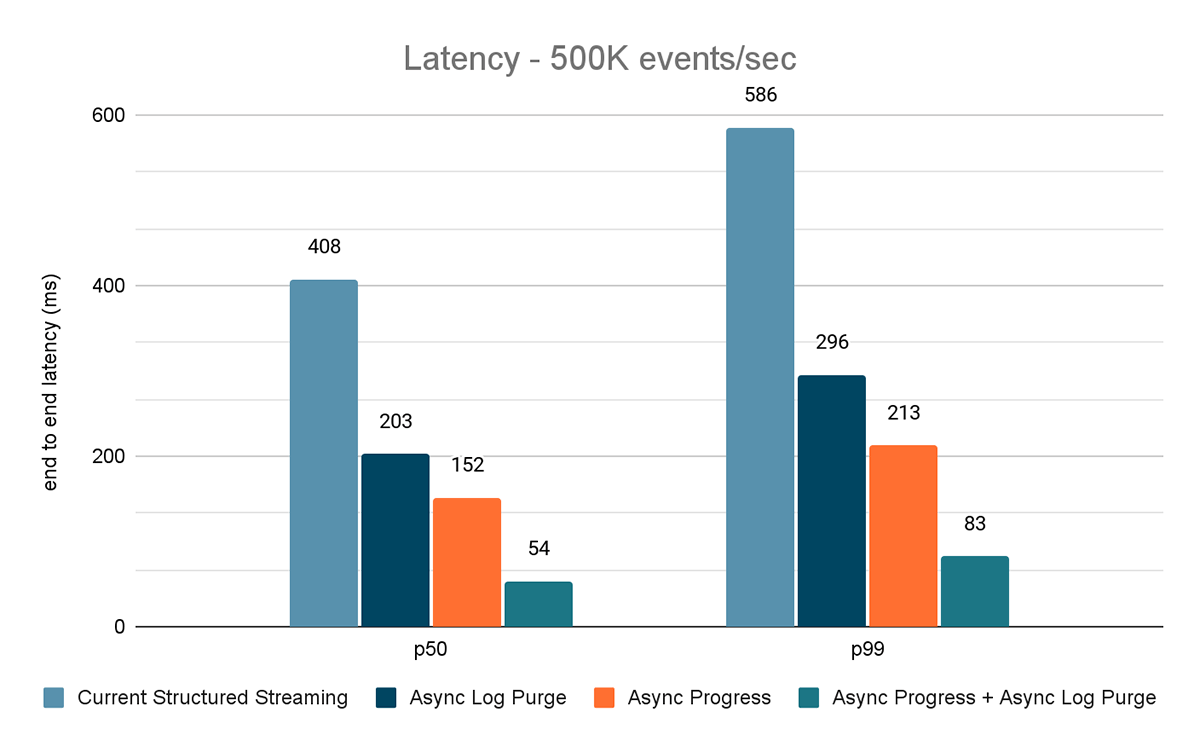
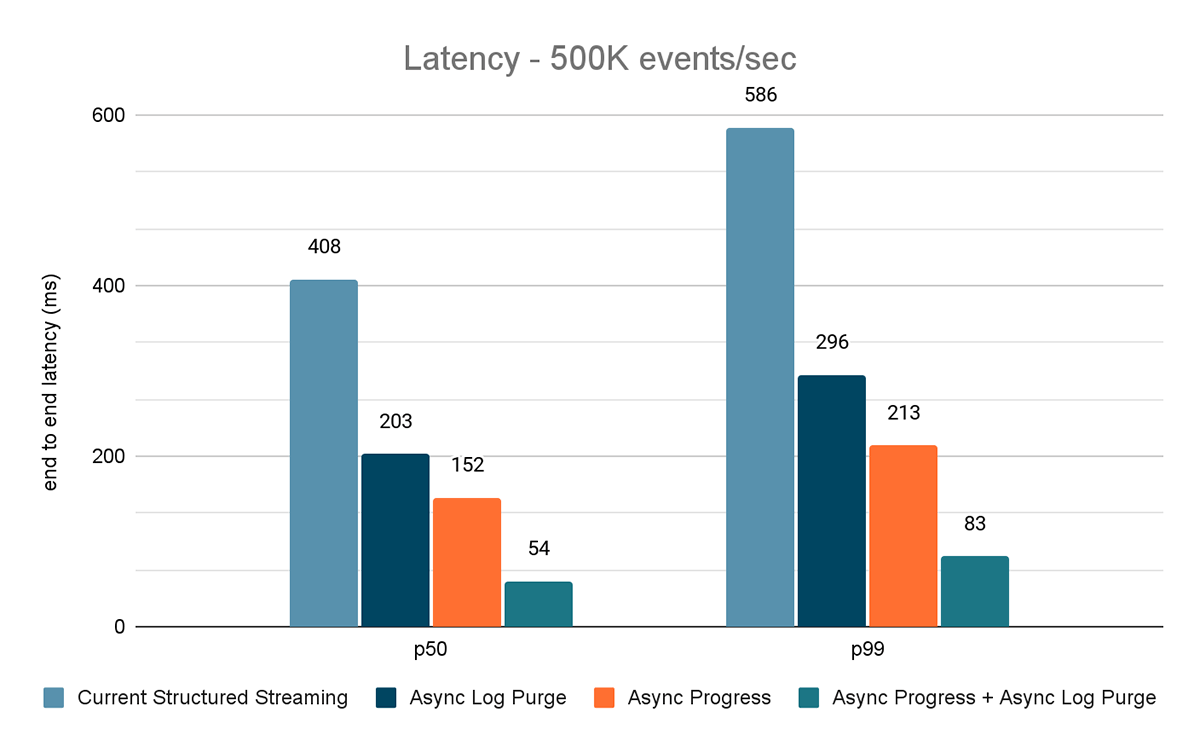{kind=link}
{kind=link}
Kafka-Quelle zu Kafka-Senke Benchmark
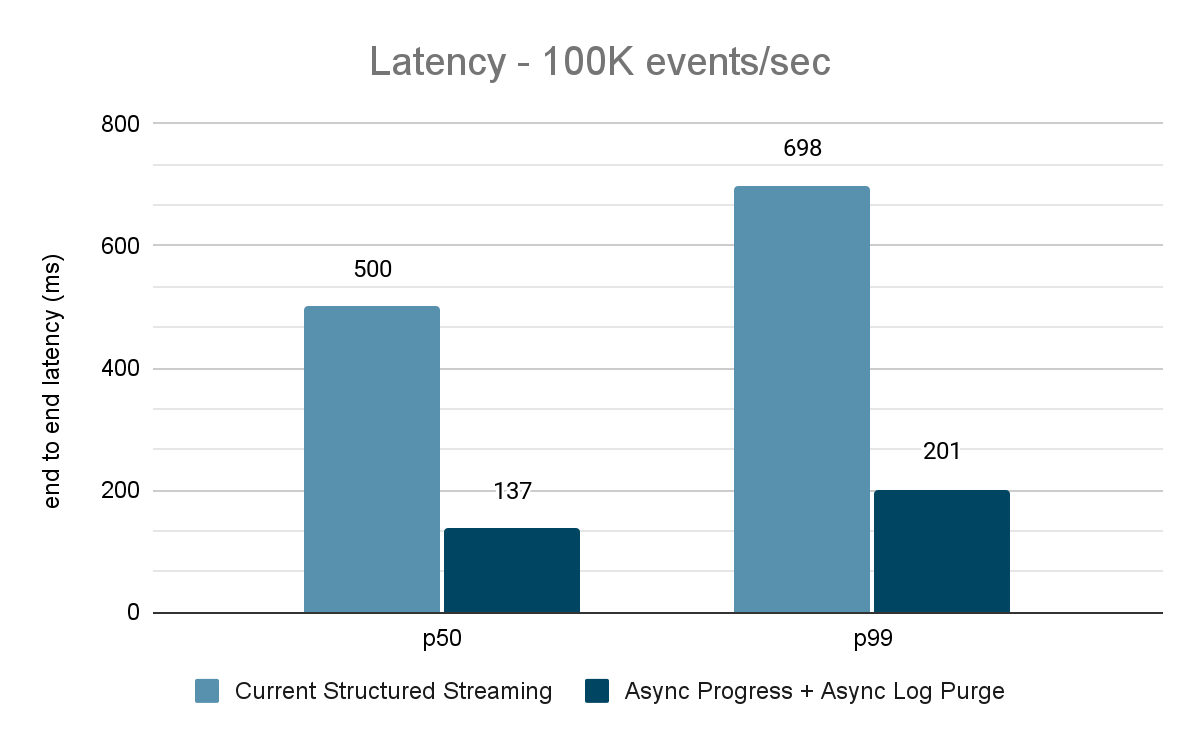
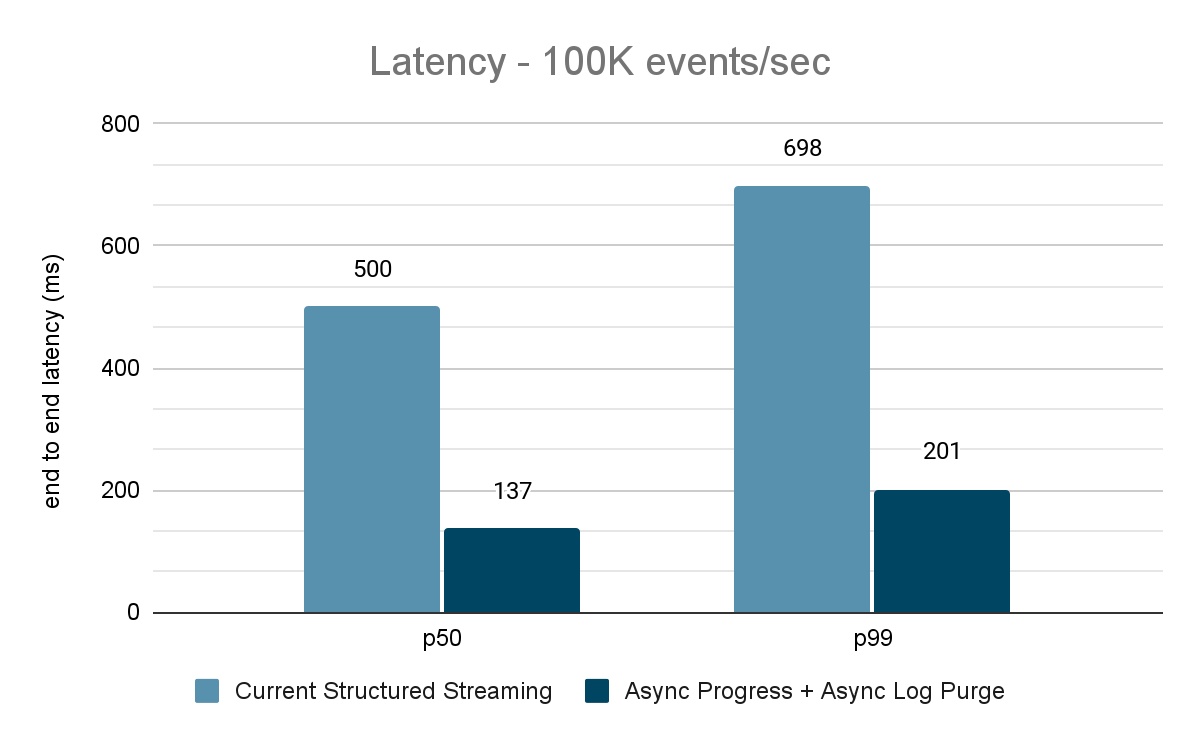
Für die Kafka-Benchmarks haben wir einen Spark-Cluster mit 5 Worker-Nodes (i3.2xlarge – 4 Kerne, 61 GiB Arbeitsspeicher), einen separaten Cluster mit 3 Nodes für die Ausführung von Kafka und 2 weitere Nodes für die Generierung von Daten für die Kafka-Quelle verwendet. Unser Kafka-Topic hat 40 Partitionen und einen Replikationsfaktor von 3.
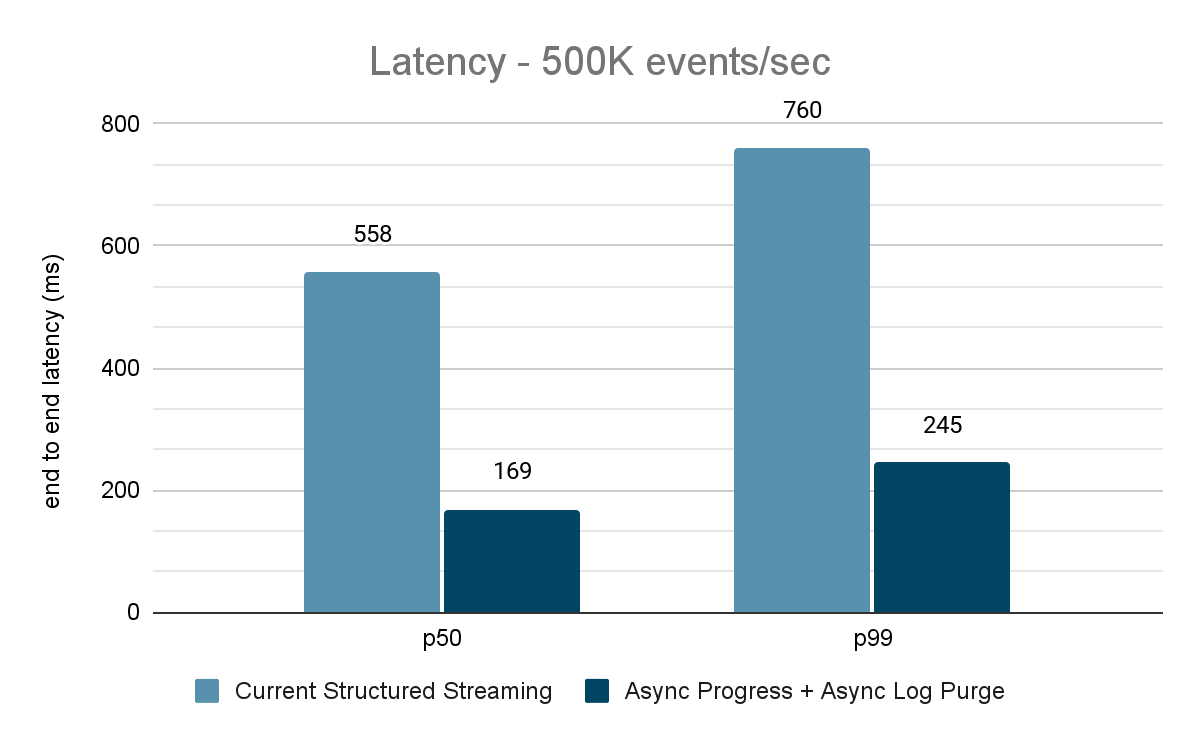
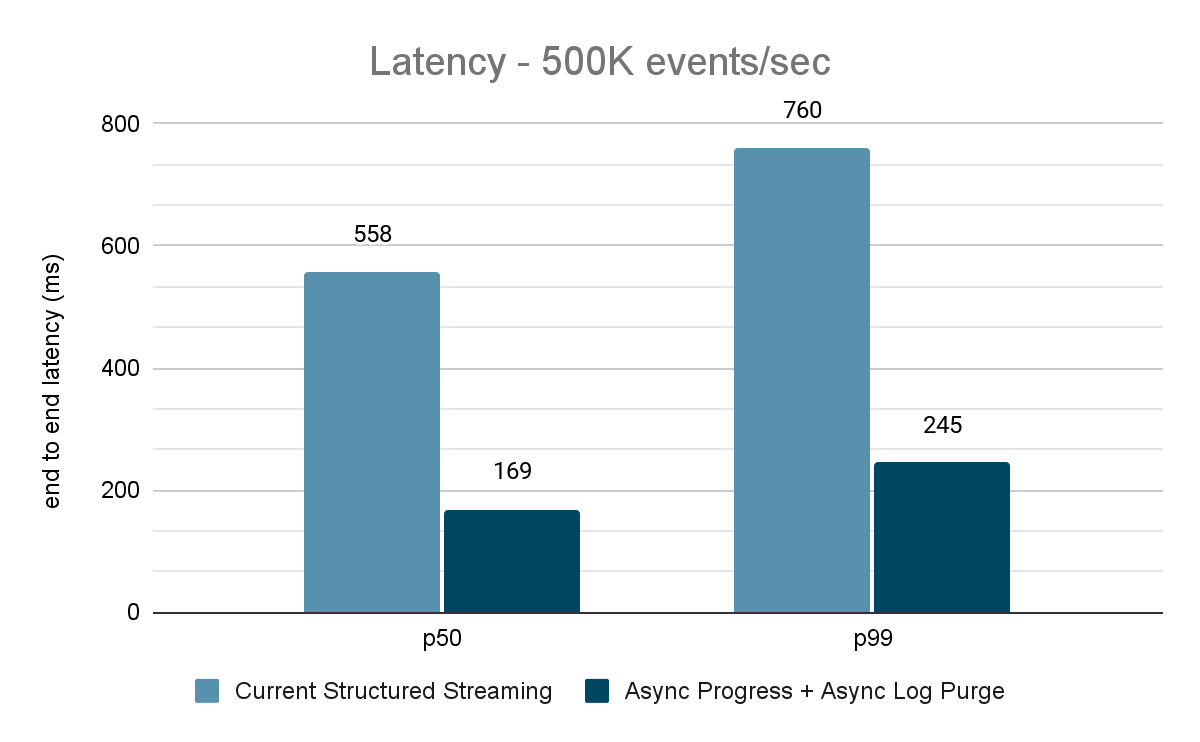
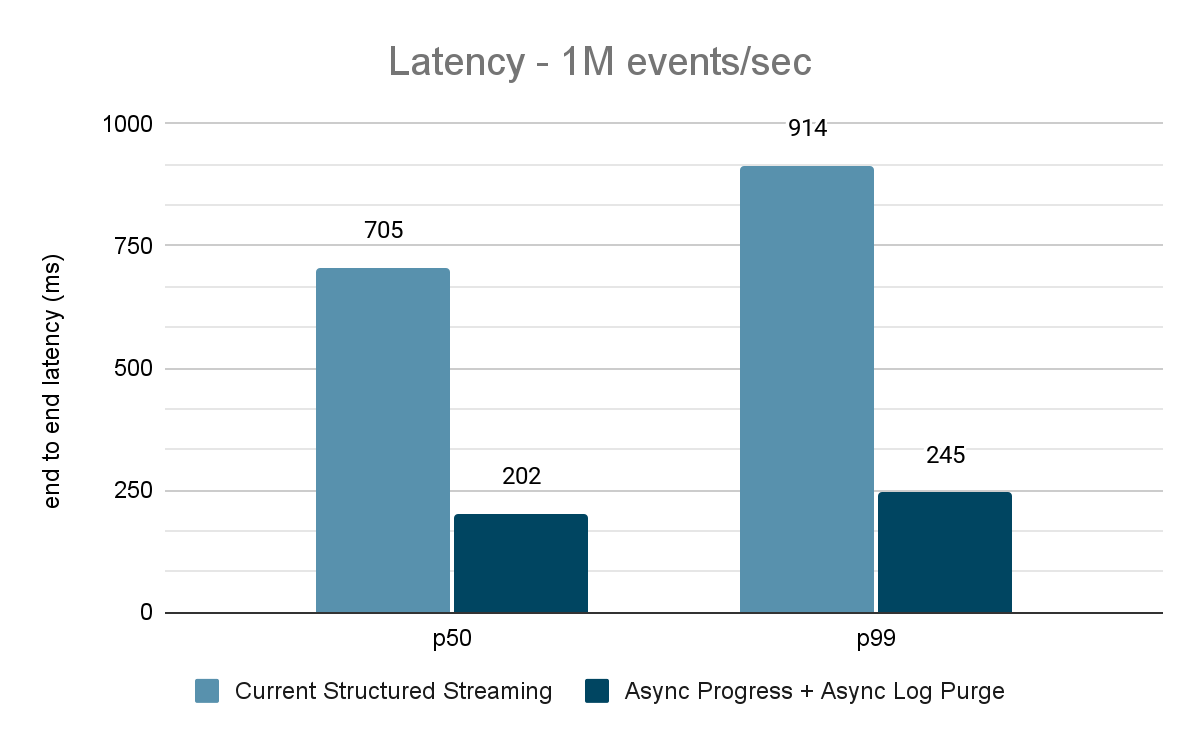
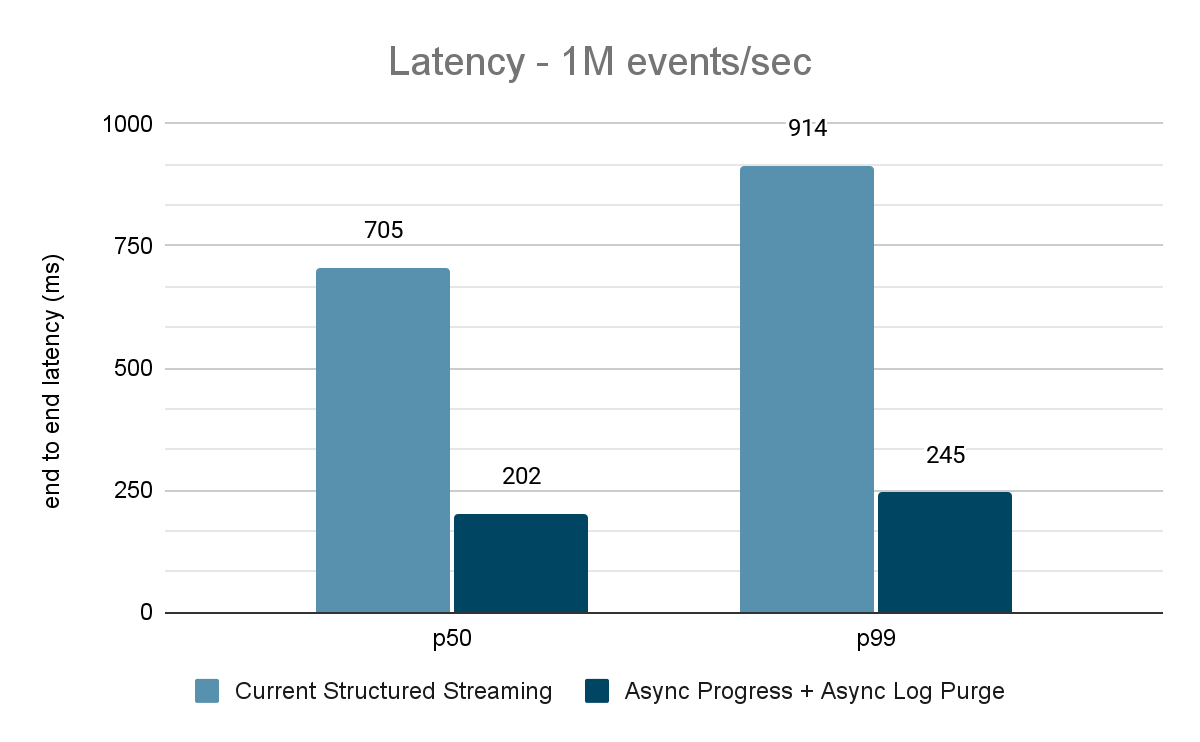
Der Datengenerator veröffentlicht Daten in ein Kafka-Topic, und die strukturierte Streaming-Pipeline konsumiert diese und veröffentlicht sie in einem anderen Kafka-Topic erneut. Die Ergebnisse der Performancebewertung sind in den Abbildungen 9, 10 und 11 dargestellt. Wie man sehen kann, verringert sich die Latenz nach Anwendung von asynchroner Fortschrittsverfolgung und asynchroner Protokollbereinigung bei unterschiedlichen Durchsätzen um 65-75 % oder das 3- bis 3,5-fache.
{kind=link}
{kind=link}
{kind=link}
Zusammenfassung der Performance Ergebnisse
Mit der neuen asynchronen Fortschrittsnachverfolgung und asynchronen Log-Bereinigung können wir sehen, dass beide Konfigurationen die Latenz um das bis zu 3-fache reduzieren. Im Zusammenspiel wird die Latenz über alle Durchsätze hinweg stark reduziert. Die Diagramme zeigen auch, dass die eingesparte Zeit normalerweise eine konstante Zeitspanne ist (200–250 ms für jede Konfiguration) und zusammen können sie pauschal etwa 500 ms einsparen (sodass genügend Zeit für die Batch-Planung und Abfrageverarbeitung bleibt).
Fragen zur Verfügbarkeit
Diese Performance-Verbesserungen sind in der Databricks Lakehouse Platform ab DBR 11.3 verfügbar. Die asynchrone Log-Bereinigung ist in DBR 11.3 und nachfolgenden Versionen standardmäßig aktiviert. Darüber hinaus wurden diese Verbesserungen in Open-Source-Spark eingebracht und sind ab Apache Spark 3.4 verfügbar.
Zukünftige Arbeit
Derzeit gibt es einige Einschränkungen bei den Arten von Workloads und Sinks, die von dem asynchronen Fortschritts-Tracking Feature unterstützt werden. Wir werden künftig die Unterstützung weiterer Workload-Typen mit diesem Feature prüfen.
Dies ist nur der Anfang der vorhersagbaren Features mit geringer Latenz, die wir in Structured Streaming als Teil von Project Lightspeed entwickeln. Darüber hinaus werden wir Structured Streaming weiterhin benchmarken und profilen, um weitere Verbesserungsmöglichkeiten zu finden. Bleiben Sie dran!
Besuchen Sie uns vom 26. bis 29. Juni auf dem Data and KI Summit in San Francisco, um mehr über Project Lightspeed und Daten-Streaming auf der Databricks Lakehouse Platform zu erfahren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.