Modernisieren Sie Ihre Data-Engineering-Plattform mit Lakeflow in Azure Databricks
Databricks Lakeflow on Azure bietet eine moderne, für Unternehmen geeignete und zuverlässige Data-Engineering-Lösung
von Joanna Zouhour und Katie Cummiskey
- Lakeflow bietet eine einheitliche End-to-End-Lösung für Data Engineers, die auf Azure Databricks arbeiten, einschließlich Datenaufnahme, -transformation und Orchestrierung
- Von einheitlicher Sicherheit und Governance bis hin zu integrierter Beobachtbarkeit, serverless compute, Streaming-Verarbeitung und einer Code-First-Benutzeroberfläche können Azure Databricks-Anwender von einer Vielzahl von Lakeflow-Funktionen in Kombination mit ihrer Azure-Datenplattform profitieren.
- Dateningenieure, die Lakeflow auf Azure Databricks verwenden, können produktionsreife Datenpipelines bis zu 25-mal schneller erstellen und bereitstellen, eine höhere Performance feststellen und eine Reduzierung der ETL-Kosten von bis zu 83 % verzeichnen.
Data Engineers sind zunehmend frustriert über die Anzahl der unverbundenen Tools und Lösungen, die sie zum Erstellen produktionsreifer Pipelines benötigen. Ohne eine zentralisierte Datenintelligenz-Plattform oder eine einheitliche Governance haben Teams mit vielen Problemen zu kämpfen, darunter:
- Ineffiziente Performance und lange Startzeiten
- Zersplitterte Benutzeroberfläche und ständiger Kontextwechsel
- Fehlende granulare Sicherheit und Kontrolle
- Komplexes CI/CD
- Eingeschränkte Sichtbarkeit der Datenherkunft
- usw.
Das Ergebnis? Langsamere Teams und weniger Vertrauen in Ihre Daten.
Mit Lakeflow auf Azure Databricks können Sie diese Probleme lösen, indem Sie alle Ihre Data-Engineering-Aufgaben auf einer einzigen Azure-nativen Plattform zentralisieren.

Eine einheitliche Data-Engineering-Lösung für Azure Databricks
Lakeflow ist eine durchgängige, moderne Data-Engineering-Lösung, die auf der Databricks Data Intelligence Platform auf Azure aufbaut und alle wesentlichen Data-Engineering-Funktionen integriert. Mit Lakeflow erhalten Sie:
- Integrierte Datenaufnahme, Transformation und Orchestrierung an einem Ort
- Verwaltete Ingestion-Konnektoren
- Deklaratives ETL für eine schnellere und einfachere Entwicklung
- Inkrementelle und Streaming-Verarbeitung für schnellere SLAs und aktuellere Erkenntnisse
- Native Governance und Lineage über Unity Catalog, die integrierte Governance-Lösung von Databricks
- Integrierte Observability für Datenqualität und Pipeline-Zuverlässigkeit
Und vieles mehr! Alles in einer flexiblen und modularen Oberfläche, die sich an die Bedürfnisse aller Benutzer anpassen lässt, unabhängig davon, ob sie programmieren oder eine Point-and-Click-Oberfläche verwenden möchten.
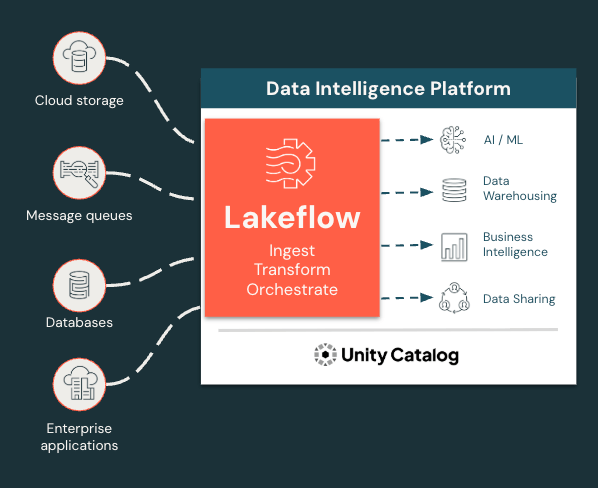
Ingestieren, transformieren und orchestrieren Sie alle Workloads an einem Ort
Lakeflow vereinheitlicht das Data-Engineering-Erlebnis, sodass Sie schneller und zuverlässiger arbeiten können.
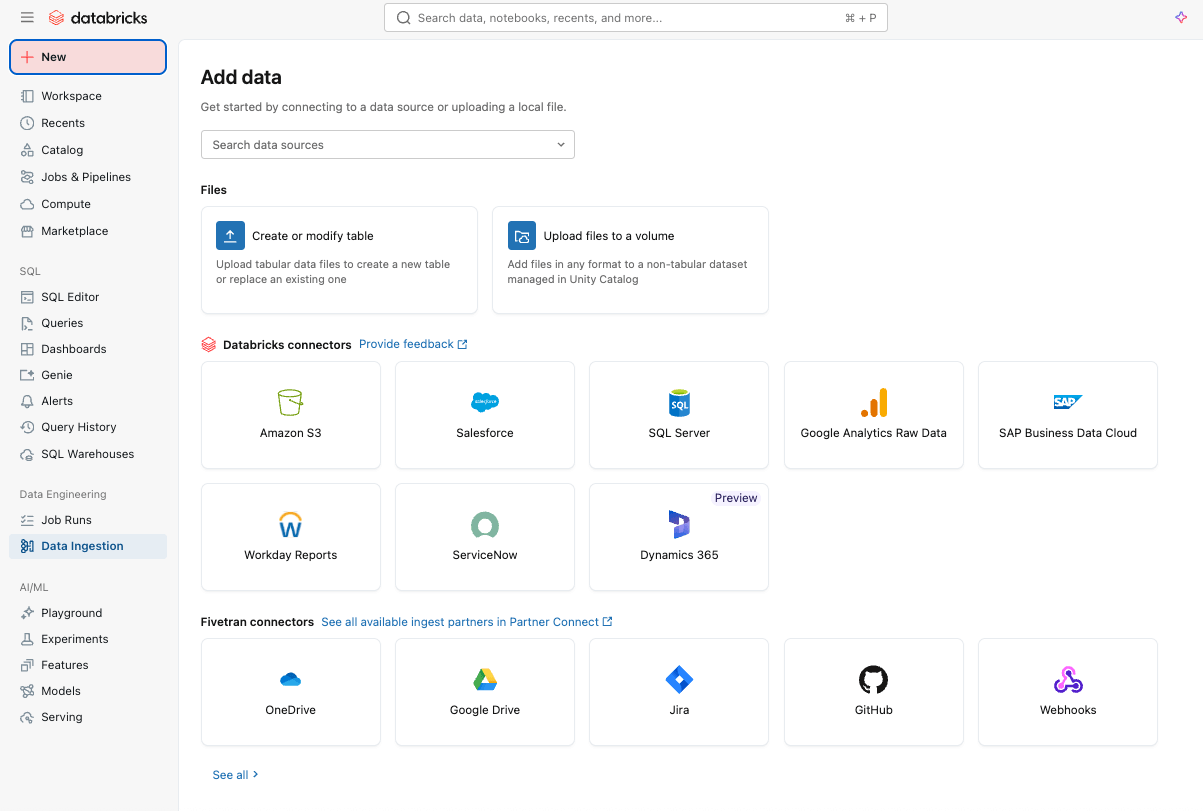
Einfache und effiziente Datenaufnahme mit Lakeflow Connect
Sie können ganz einfach Daten mit Lakeflow Connect über eine Point-and-Click-Oberfläche oder eine einfache API in Ihre Plattform erfassen.
Sie können sowohl strukturierte als auch unstrukturierte Daten aus einer Vielzahl unterstützter Quellen in Azure Databricks erfassen, darunter beliebte SaaS-Anwendungen (z. B. Salesforce, Workday, ServiceNow), Datenbanken (z. B. SQL Server), Cloud-Speicher, Message-Busse und mehr. Lakeflow Connect unterstützt auch Azure-Netzwerkmuster wie Private Link und die Bereitstellung von Ingestion-Gateways in einem VNet für Datenbanken.
Für die Echtzeit-Ingestion sehen Sie sich Zerobus Ingest an, eine serverlose Direct-Write-API in Lakeflow auf Azure Databricks. Sie überträgt Ereignisdaten direkt in die Datenplattform, wodurch ein Message-Bus für eine einfachere Ingestion mit geringerer Latenz nicht mehr erforderlich ist.
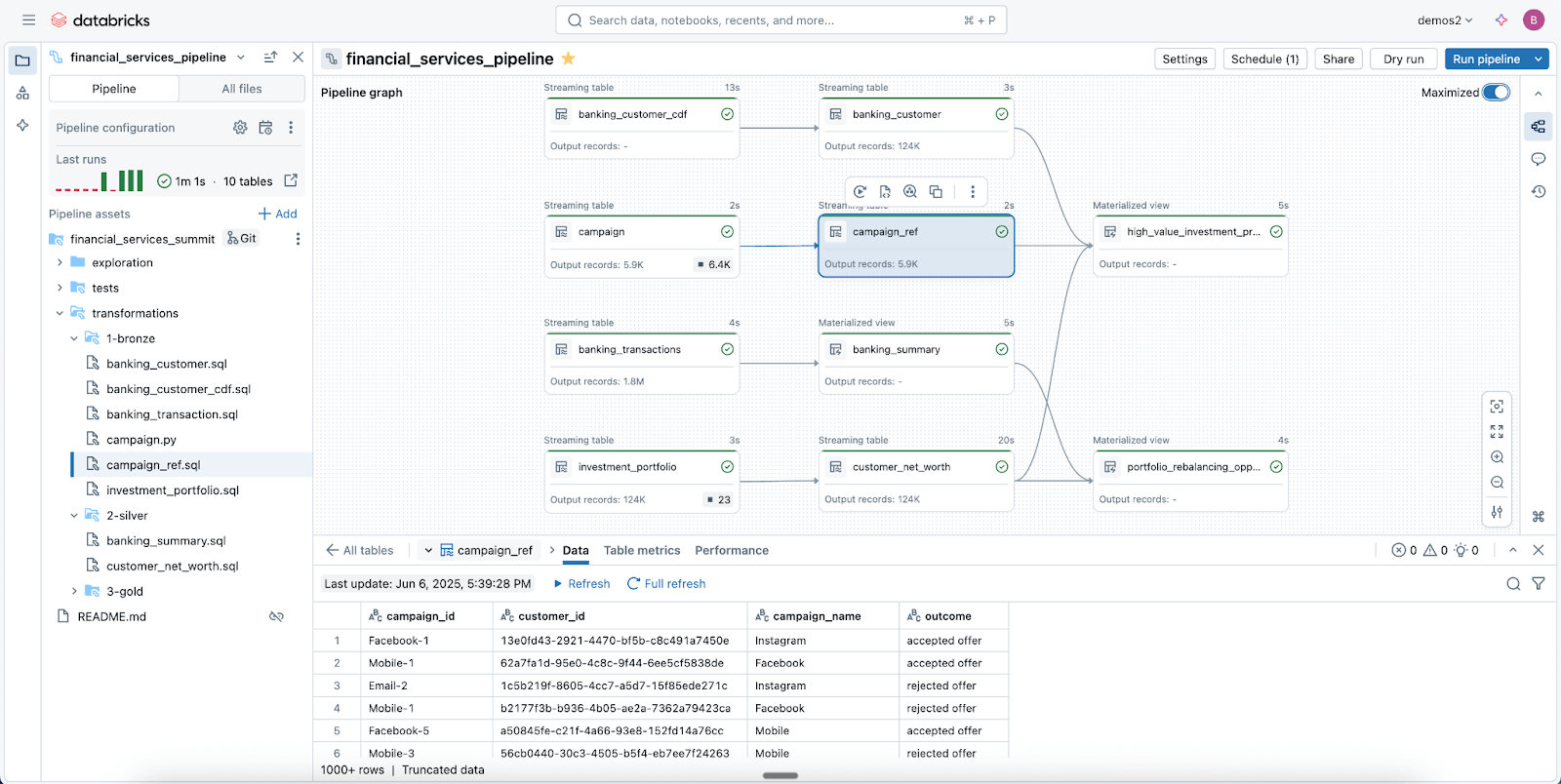
Zuverlässige Datenpipelines leicht gemacht mit Spark Declarative Pipelines
Nutzen Sie Lakeflow Spark Declarative Pipelines (SDP), um Ihre Daten einfach zu bereinigen, zu formen und so zu transformieren, wie Ihr Unternehmen sie benötigt.
SDP ermöglicht es Ihnen, zuverlässige Batch- und Streaming-ETL mit nur wenigen Zeilen Python (oder SQL) zu erstellen. Deklarieren Sie einfach die benötigten Transformationen, und SDP kümmert sich um den Rest – einschließlich Abhängigkeits-Mapping, Bereitstellungsinfrastruktur und Datenqualität.
SDP minimiert Entwicklungszeit und Betriebsaufwand und kodifiziert standardmäßig Best Practices für das Data Engineering. Dies vereinfacht die Implementierung von Inkrementalisierung oder komplexen Mustern wie SCD Typ 1 & 2 auf wenige Codezeilen. Die gesamte Leistungsfähigkeit von Spark Structured Streaming, unglaublich einfach gemacht.
Und da Lakeflow in Azure Databricks integriert ist, können Sie Azure Databricks-Tools wie Databricks Asset Bundles (DABs), Lakehouse Monitoring und mehr verwenden, um in Minutenschnelle produktionsreife, gesteuerte Pipelines bereitzustellen.
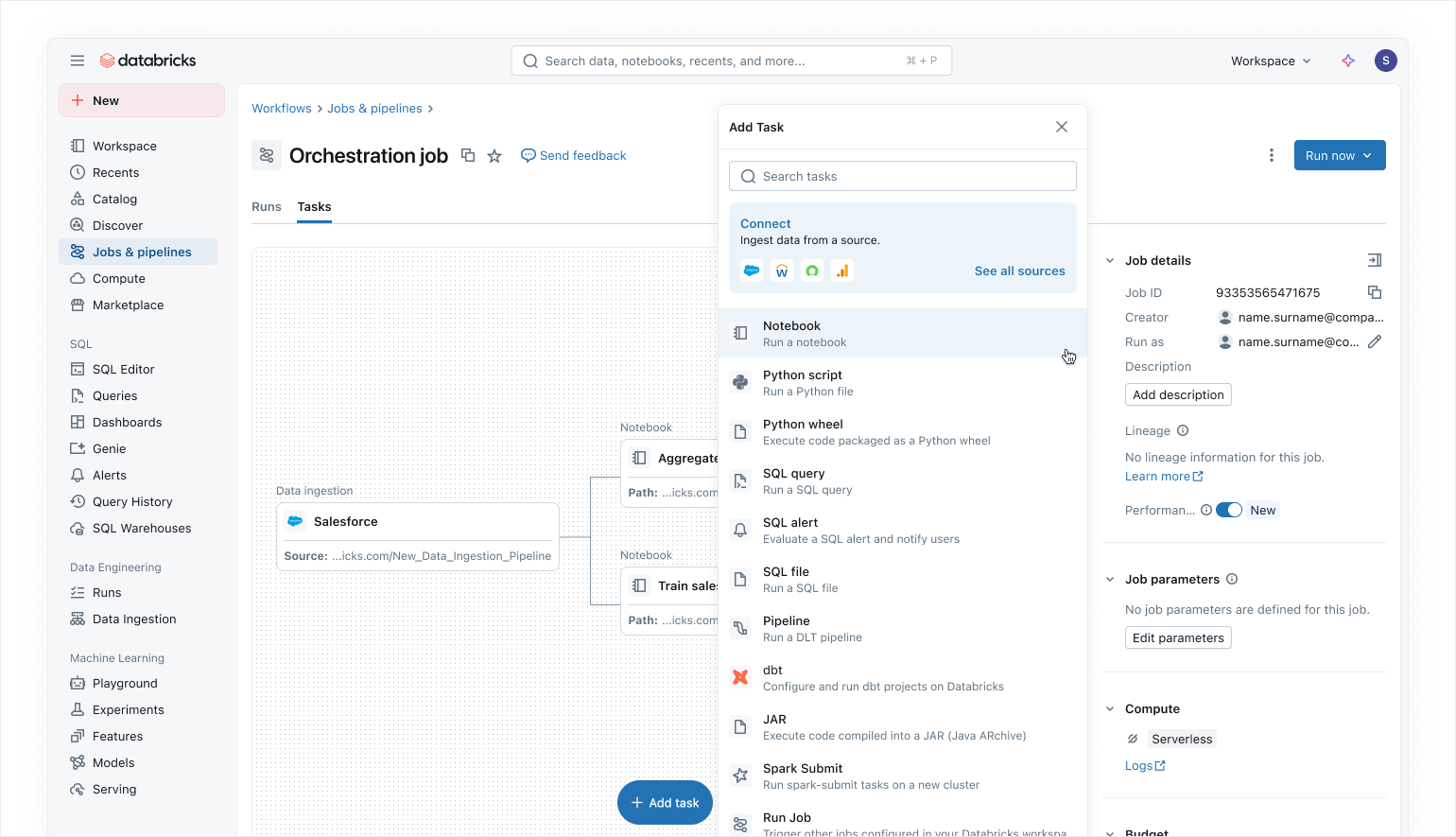
Moderne Data-First-Orchestrierung mit Lakeflow Jobs
Verwenden Sie Lakeflow Jobs, um Ihre Daten- und KI-Workloads auf Azure Databricks zu orchestrieren. Mit einem modernen, vereinfachten Data-First-Ansatz ist Lakeflow Jobs der vertrauenswürdigste Orchestrator für Databricks, der die Verarbeitung großer Datenmengen und KI sowie Echtzeitanalysen mit einer Zuverlässigkeit von 99,9 % unterstützt.
In Lakeflow Jobs können Sie alle Ihre Abhängigkeiten visualisieren, indem Sie SQL-Workloads, Python-Code, Dashboards, Pipelines und externe Systeme in einem einzigen einheitlichen DAG koordinieren. Die Workflow-Ausführung ist einfach und flexibel mit datensensitiven Triggern wie Tabellenaktualisierungen oder Dateieingängen und Ablaufsteuerungs-Tasks. Dank No-Code- Backfill-Ausführungen und integrierter Observability macht es Lakeflow Jobs einfach, Ihre Downstream-Daten aktuell, zugänglich und genau zu halten.
Als Benutzer von Azure Databricks können Sie semantische Power BI-Modelle auch mit der Power BI-Task in Lakeflow Jobs automatisch aktualisieren und aktualisieren (weitere Informationen finden Sie hier). Das macht Lakeflow Jobs zu einem nahtlosen Orchestrator für Azure-Workloads.
Integrierte Sicherheit und einheitliche Governance
Mit Unity Catalog erbt Lakeflow zentralisierte Kontrollen für Identität, Sicherheit und Governance für die Bereiche Datenerfassung, Transformation und Orchestrierung. Verbindungen speichern Anmeldeinformationen sicher, Zugriffsrichtlinien werden für alle Workloads konsistent durchgesetzt und granulare Berechtigungen stellen sicher, dass nur die richtigen Benutzer und Systeme Daten lesen oder schreiben können.
Unity Catalog bietet außerdem eine durchgängige Datenherkunft von der Erfassung über Lakeflow Jobs bis hin zu nachgelagerten Analysen und Power BI, was die Nachverfolgung von Abhängigkeiten und die Sicherstellung der Compliance vereinfacht. System Tables bieten Einblicke in den Betrieb und die Sicherheit über Jobs, Benutzer und die Datennutzung hinweg. So können Teams die Qualität überwachen und Best Practices durchsetzen, ohne externe Protokolle zusammensetzen zu müssen.
Gemeinsam bieten Lakeflow und Unity Catalog Azure Databricks-Benutzern standardmäßig governed Pipelines, was zu einer sicheren, prüfbaren und produktionsbereiten Datenbereitstellung führt, auf die Teams vertrauen können.
Lesen Sie unseren Blog darüber, wie Unity Catalog OneLake unterstützt.
Flexible User Experience und Authoring für alle
Zusätzlich zu all diesen Features ist Lakeflow unglaublich flexibel und einfach zu bedienen und eignet sich daher für jeden in Ihrer Organisation, insbesondere für Entwickler.
Code-First-Benutzer lieben Lakeflow dank seiner leistungsstarken Execution Engine und fortschrittlichen, entwicklerorientierten Tools. Mit dem Lakeflow Pipeline Editor können Entwickler eine IDE nutzen und robuste Entwickler-Tools verwenden, um ihre Pipelines zu erstellen. Lakeflow Jobs bietet außerdem Code-First-Authoring und Entwickler-Tools mit dem DB Python SDK und DABs für wiederholbare CI/CD-Muster.
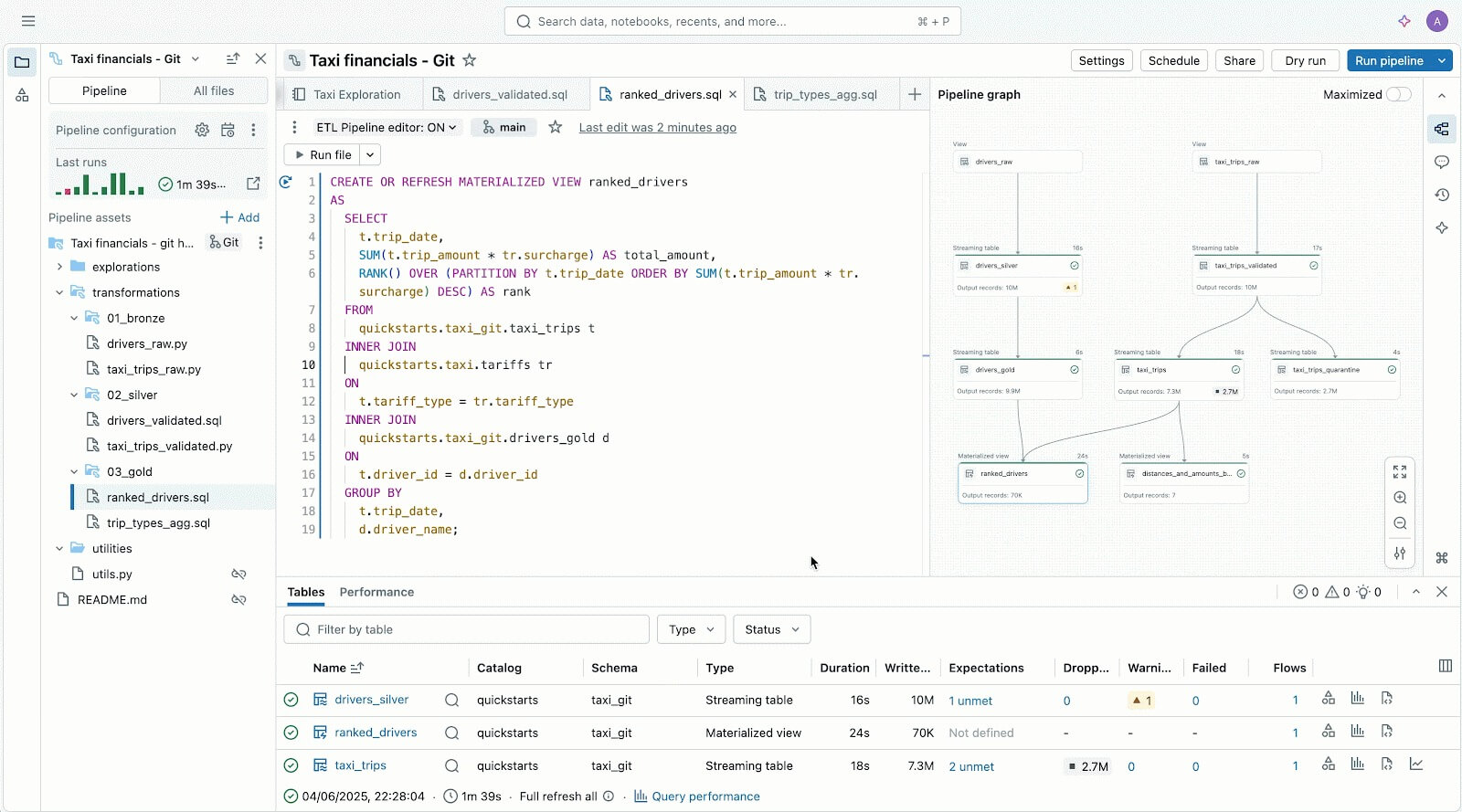
Lakeflow Pipelines Editor zum Erstellen und Testen von Datenpipelines – alles an einem Ort.
Für Einsteiger und Geschäftsanwender ist Lakeflow sehr intuitiv und einfach zu bedienen, mit einer einfachen Point-and-Click-Oberfläche und einer API für die Datenaufnahme über Lakeflow Connect.
Weniger Raten, genauere Fehlerbehebung mit nativer Observability
Monitoring-Lösungen sind oft von Ihrer Datenplattform isoliert, was die Operationalisierung der Beobachtbarkeit erschwert und Ihre Pipelines anfälliger für Ausfälle macht
Lakeflow Jobs in Azure Databricks bietet Dateningenieuren die tiefe End-to-End-Transparenz, die sie benötigen, um Probleme in ihren Pipelines schnell zu verstehen und zu beheben. Mit den Observability-Funktionen von Lakeflow können Sie Leistungsprobleme, Abhängigkeitsengpässe und fehlgeschlagene Tasks in einer einzigen UI mit unserer einheitlichen Ausführungsliste sofort erkennen.
Lakeflow-Systemtabellen und die integrierte Datenherkunft mit Unity Catalog bieten außerdem vollständigen Kontext über Datensätze, Workspaces, Abfragen und nachgelagerte Auswirkungen hinweg, was die Ursachenanalyse beschleunigt. Mit den neu allgemein verfügbaren (GA) Systemtabellen in Jobs können Sie benutzerdefinierte Dashboards für alle Ihre Jobs erstellen und den Zustand Ihrer Jobs zentral überwachen.
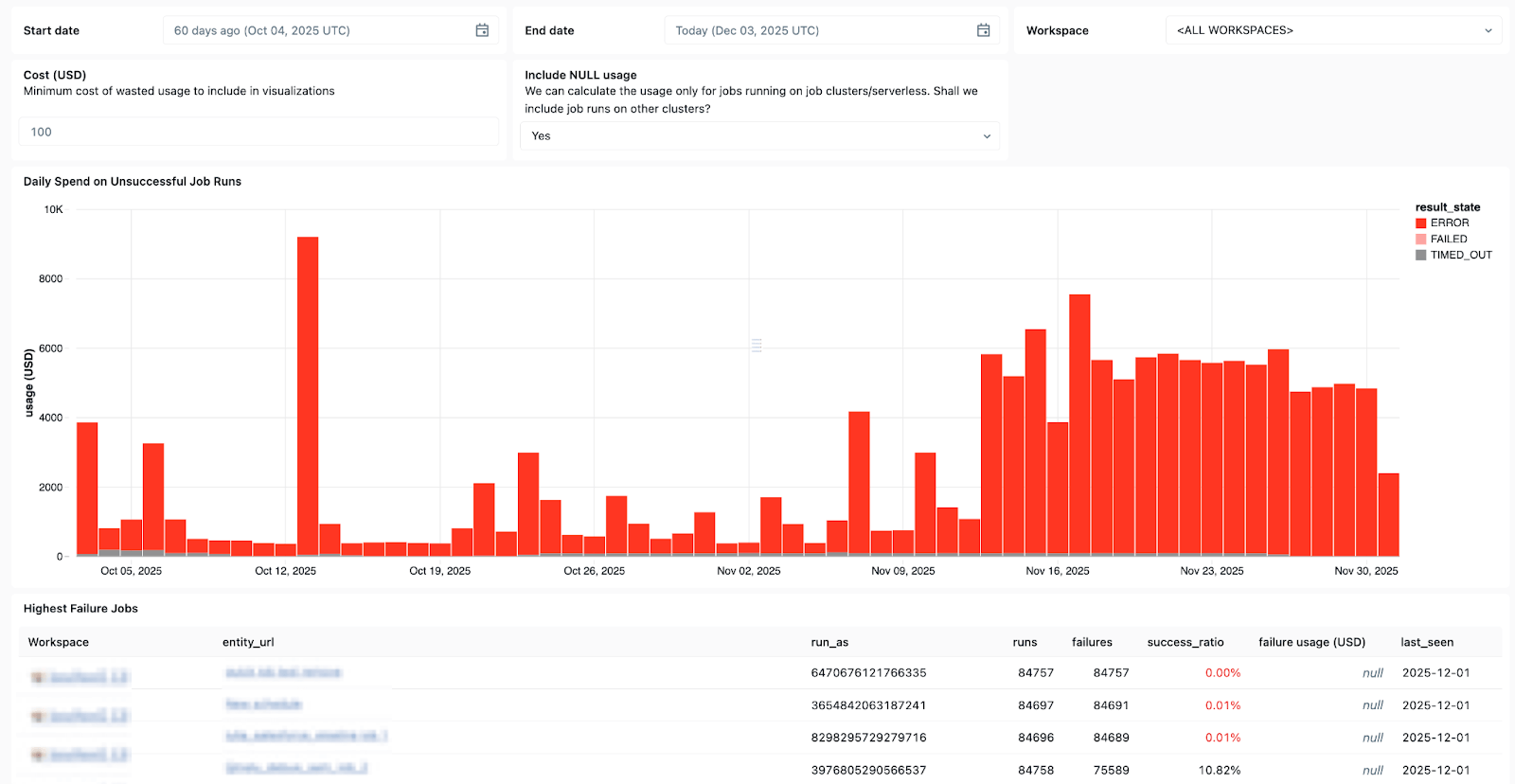
Verwenden Sie Systemtabellen in Lakeflow, um zu sehen, welche Jobs am häufigsten fehlschlagen, allgemeine Fehlertrends zu erkennen und häufige Fehlermeldungen zu identifizieren.
Und wenn Probleme auftreten, hilft Ihnen der Databricks Assistant.
Der Databricks Assistant ist ein kontextsensitiver KI-Copilot, der in Azure Databricks integriert ist und Ihnen hilft, sich schneller von Fehlern zu erholen, indem er es Ihnen ermöglicht, Notebooks, SQL-Abfragen, Jobs und Dashboards in natürlicher Sprache schnell zu erstellen und Fehler zu beheben.
Aber der Assistent kann mehr als nur Debugging. Er kann auch PySpark/SQL-Code generieren und erklären, mit Features, die alle auf Unity Catalog basieren, sodass er Ihren Kontext versteht. Er kann auch verwendet werden, um Ausführungen zu Vorschlägen zu machen, Muster aufzudecken und eine Data Discovery sowie EDA durchzuführen, was ihn zu einem großartigen Begleiter für alle Ihre Data-Engineering-Anforderungen macht.
Ihre Kosten und Ihr Verbrauch unter Kontrolle
Je größer Ihre Pipelines sind, desto schwieriger ist es, die Ressourcennutzung richtig zu dimensionieren und die Kosten unter Kontrolle zu halten.
Mit der serverless Datenverarbeitung von Lakeflow wird compute von Databricks automatisch und kontinuierlich optimiert, um inaktive Verschwendung und die Ressourcennutzung zu minimieren. Data Engineers können für mehr Flexibilität entscheiden, ob sie serverless im Performance-Modus für geschäftskritische Workloads oder im Standard-Modus, bei dem die Kosten wichtiger sind, ausführen möchten.
Lakeflow Jobs ermöglicht auch die Cluster-Wiederverwendung, sodass mehrere Tasks in einem Workflow auf dem gleichen Job-Clusterausgeführt werden können, wodurch Kaltstartverzögerungen vermieden werden,und unterstützt eine feingranulare Steuerung, sodass jeder Task entweder auf den wiederverwendbaren Job-Cluster oder seinen eigenen dedizierten Cluster ausgerichtet werden kann. Zusammen mit Serverless Compute minimiert die Cluster-Wiederverwendung Spin‑ups, sodass Data Engineers den operativen Aufwand reduzieren und mehr Kontrolle über ihre Datenkosten erhalten können.
Microsoft Azure + Databricks Lakeflow – eine bewährte, erfolgreiche Kombination
Databricks Lakeflow ermöglicht es Datenteams, schneller und zuverlässiger zu arbeiten, ohne Kompromisse bei Governance, Skalierbarkeit oder Leistung einzugehen. Da Data Engineering nahtlos in Azure Databricks integriert ist, können Teams von einer einzigen End-to-End-Plattform profitieren, die alle Daten- und KI-Anforderungen im großen Maßstab erfüllt.
Azure-Kunden haben durch die Integration von Lakeflow in ihren Stack bereits positive Ergebnisse erzielt, darunter:
- schnellere Pipeline-Entwicklung: Teams können produktionsreife Datenpipelines bis zu 25-mal schneller erstellen und bereitstellen und die Erstellungszeit um 70 % verkürzen.
- Höhere Performance und Zuverlässigkeit: Einige Kunden verzeichnen eine 90-fache Performance-Steigerung und verkürzen die Verarbeitungszeiten von Stunden auf Minuten.
- Mehr Effizienz und Kosteneinsparungen: Automatisierung und optimierte Verarbeitung senken den Betriebsaufwand drastisch. Kunden berichten von jährlichen Einsparungen von bis zu mehreren zehn Millionen Dollar und einer Reduzierung der ETL-Kosten um bis zu 83 %.
Lesen Sie Erfolgsgeschichten von Azure- und Lakeflow-Kunden in unserem Databricks-Blog.
Neugierig auf Lakeflow? Testen Sie Databricks kostenlos, um zu sehen, was die Data-Engineering-Plattform alles zu bieten hat.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.