Lakehouse für Unternehmen, die in der Cloud geboren wurden
Schnellere Entwicklung und Skalierung von Daten-, Analytics- und KI-Funktionen auf einer leistungsstarken Datenplattform

Next-Generation Products Built on Databricks Lakehouse
Hear from Built on Lakehouse customers Hunters and Kythera Labs as they share about innovating with data, their journey to the Lakehouse, data platform considerations and architecture guidance.
Je schneller Sie wachsen, desto komplexer werden Ihre Daten. Schnellere Innovationen auf der Databricks Lakehouse-Plattform – ein einfacher, kosteneffizienter Ansatz für Daten, Analysen und KI, der Tausende von digital nativen Unternehmen und Start-ups produktiver macht.
Innovate with open source flexibility
Use your data however and wherever you want — no vendor lock-in. Apache Spark™ developers created the lakehouse with open formats and APIs.
Build scalable data workloads
Ensure reliable, lightning-fast performance on ETL workloads — for streaming and batch data — while Databricks automatically manages your infrastructure.
Access data insights faster
Ingest, transform and query all your data in one place. Stop managing servers and scale on demand with serverless. Up to 12x better price/performance.
Develop next-gen apps with ML
Speed up your ML lifecycle from experimentation to production. Boost productivity with tools like collaborative notebooks, MLflow and MLOps.
Erste Schritte mit Databricks
Databricks testen
Starten Sie Ihre 14-tägige kostenlose Testversion mit Databricks on AWS in wenigen einfachen Schritten. Suchen und finden Sie Ressourcen für sich und Ihr gesamtes Datenteam.
Kompetenzen entwickeln
Absolvieren Sie auf Ihre Bedürfnisse zugeschnittene Schulungen und Zertifizierungen, einschließlich Data Analytics, Data Engineering, Data Science und Machine Learning.
Kosten optimieren
Mit einem verwalteten Dienst können Sie die Infrastrukturkosten um bis zu 40 % senken und gleichzeitig Ihre Produktivität steigern. Informieren Sie sich über unsere nutzungsbasierte Abrechnung und die ermäßigten Tarife.
Technischer Support
Mit unseren Databricks-Experten erhalten Sie notwendige Antworten schneller. Außerdem können Sie Ihre Datenlösung mit unseren Selfservice-Notebooks im Handumdrehen entwickeln.

Aufbauprogramme
Erstellen Sie Ihre datengesteuerten Anwendungen auf dem Lakehouse und beschleunigen Sie Ihr Geschäftswachstum mit Databricks
Databricks für Startups
Starten Sie schnell mit dem Startprogramm. Erfahren Sie, wie Sie kostenlose Guthaben, Expertenratschläge und Unterstützung bei der Markteinführung erhalten.
Aufbaupartner
Werden Sie ein integrierter Partner, um Zugang zu technischen, Markteinführungs- und Co-Marketing-Vorteilen zu erhalten, mit denen Sie Ihre Reichweite vergrößern und Ihr Geschäft ausbauen können.
Unternehmen der nächsten Generation, die auf Databricks setzen
Lösungsarchitekturen für Digital-Native-Unternehmen
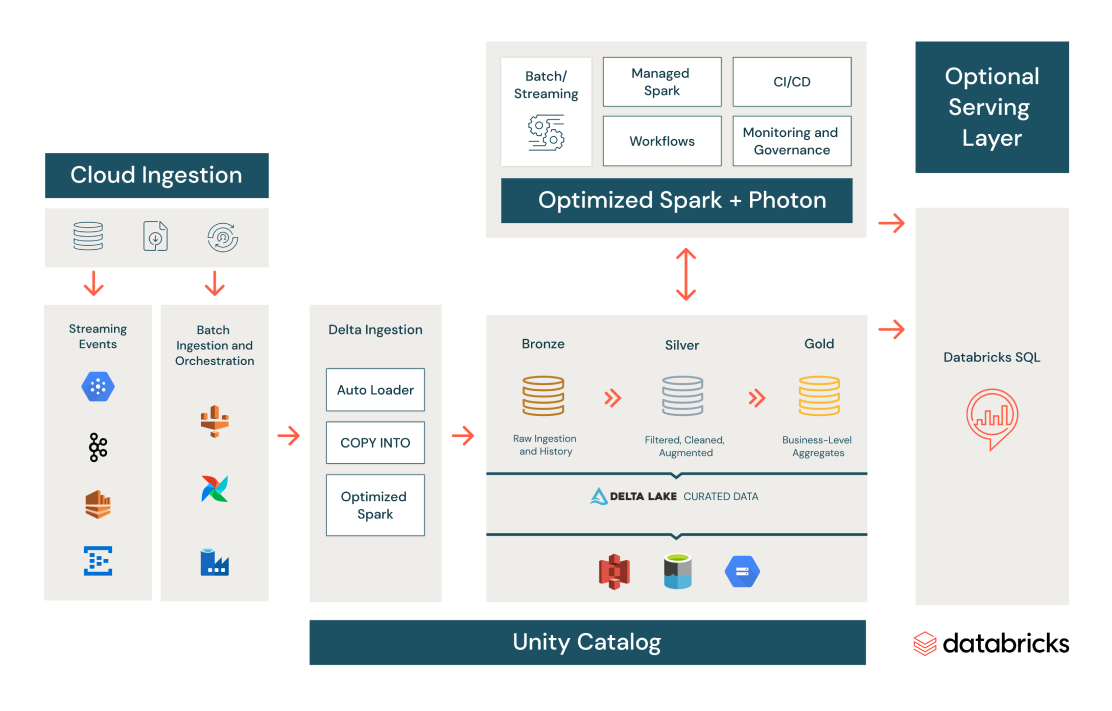
Leistungsstarke, skalierbare ETL-Pipelines
Erstellen Sie eine konsistente Data-Engineering- und ETL-Plattform, um sich in jeder Cloud ganz der Gewinnung wertvoller Erkenntnisse zu widmen. Nie wieder Pipelines entwickeln und warten, nie wieder ETL-Workloads ausführen.
Nutzen Sie produktionsfertige Tools wie Delta Live Tables, Unity Catalog und Workflows.
Genießen Sie robuste Git-Integration, Orchestrierung und Datenqualitätskontrollen.
Vereinheitlichen Sie Batch- und Streaming-Operationen in einer vereinfachten Architektur und optimieren Sie Entwicklung und Tests von Daten-Pipelines.
Gewährleisten Sie höchste Datenqualität und verbessertes Data Skipping mit Delta Lake – einem Open-Source-Dateiprotokoll, das von Apache Spark, Trino, Presto, Flink u. a. verwendet werden kann.
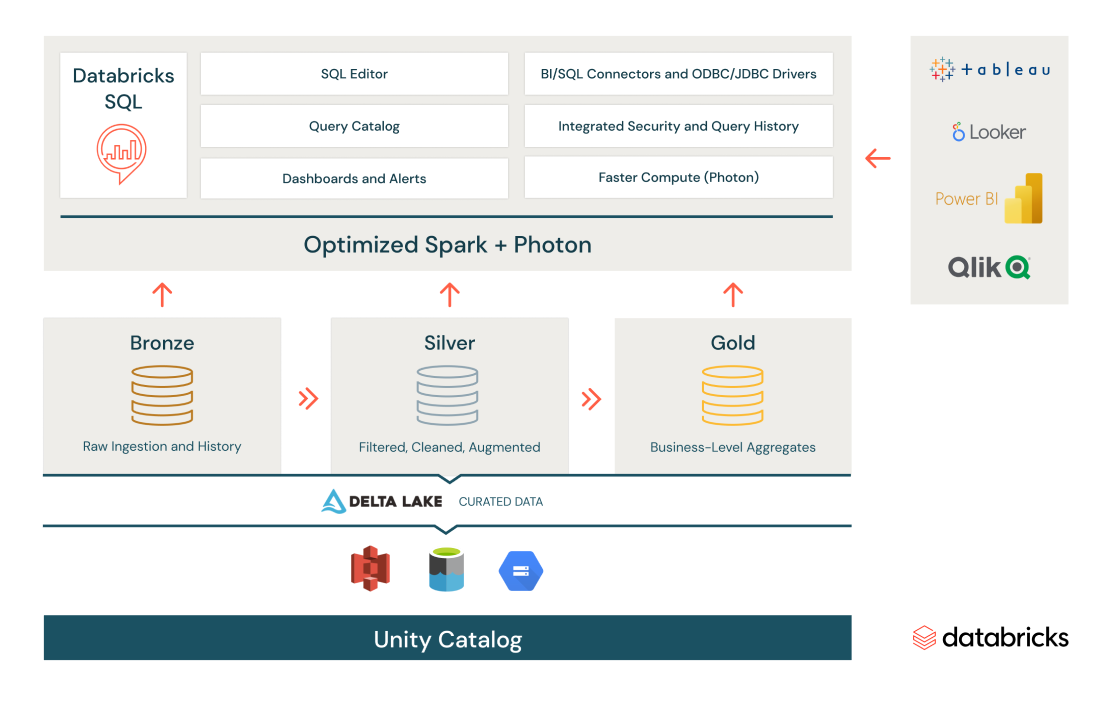
SQL-Analytics und Data Warehousing
Daten erfassen, transformieren und abfragen von zentraler Stelle aus – so gewinnen Sie im Nu geschäftliche Echtzeiterkenntnisse.
Führen Sie auch umfangreichste SQL- und BI-Anwendungen aus – mit einem bis zu 12 Mal besseren Preis-Leistungs-Verhältnis. Außerdem garantieren Sie so Data Governance und Sicherheit.
Bewältigen Sie High Concurrency mit vollständig verwaltetem Load Balancing und Skalierung der Compute-Ressourcen.
Nutzen Sie offene Formate und APIs sowie Erfassung, Transformation und BI-Tools nach Wahl mit maßgeschneiderten Konnektoren.
Reduzieren Sie den Aufwand für das Ressourcenmanagement mit Serverless Compute.
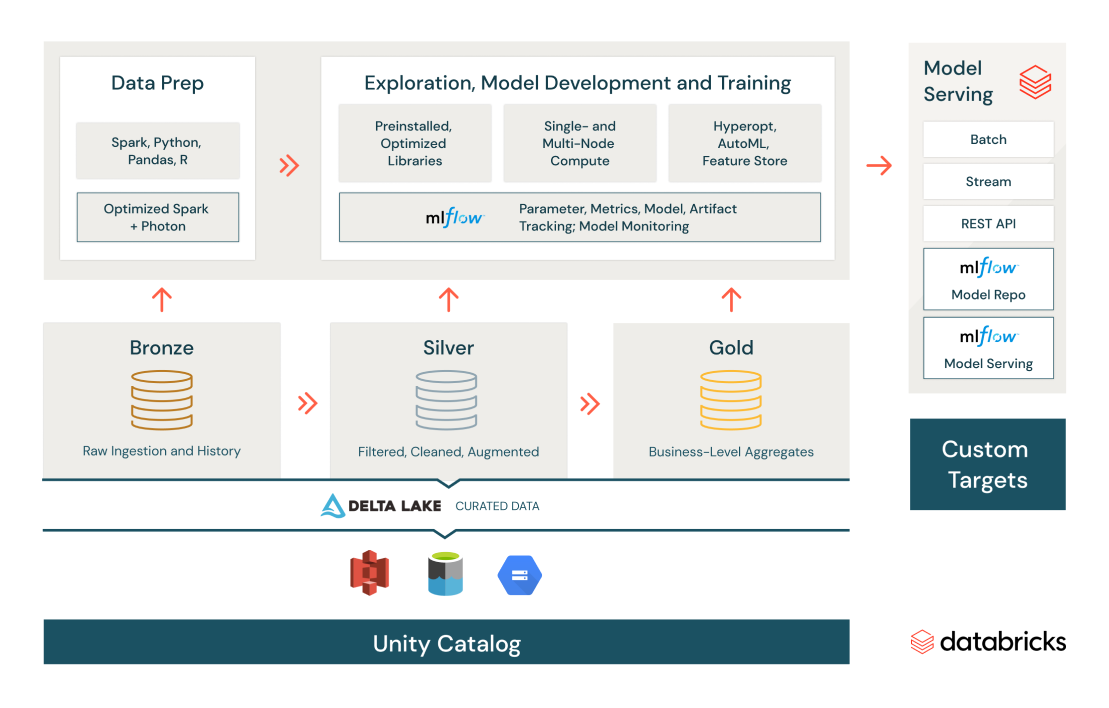
Innovatives Machine Learning
Beschleunigen Sie ML und Data Science durch Ausbau von Produktivität und Kollaboration im Lakehouse.
Nutzen Sie Tools und Optionen für die Zusammenarbeit mit Glass-Box-AutoML.
Mit einem gehosteten Feature Store können Sie Daten und Funktionen im Self-Service vorbereiten, verarbeiten und verwalten und auch Ihre Modelle managen.
Standardisieren Sie den ML-Lebenszyklus vom Experiment bis zur Produktion mithilfe von MLflow, um Modellparameter, Metriken und Iterationen im zeitlichen Verlauf zu beobachten.
Stellen Sie Modelle im Batch oder mit Serverless-Echtzeit-REST-Endpoints bereit.
Branchenlösungen
Next-Generation-Branchenführer entwickeln Datenanalyse- und KI-Lösungen mit Databricks

Technischer Leitfaden
Lösung gemeinsamer Datenherausforderungen
Für Startups und Digital Natives
Erfahren Sie, wie Sie Datenanwendungsfälle bei der Skalierung unterstützen und gleichzeitig die Kosteneffizienz und Produktivität steigern können. Sie profitieren von Architekturdiagrammen, Schritt-für-Schritt-Lösungen und Schnellstartanleitungen. Sie finden auch Anwendungsfälle aus der Praxis von führenden Unternehmen wie Grammarly, Rivian, ButcherBox, Abnormal Security, Iterable und Zipline.
Ressourcen
E-Books
Schnellstart-Leitfäden
Blogs
Ready to get started?