Mlflow administré
Créez de meilleurs modèles et applications d’IA générative


Qu'est-ce que Managed MLflow ?
Managed MLflow étend les fonctionnalités de MLflow, une plateforme open source développée par Databricks pour créer de meilleurs modèles et applications d’IA générative, en mettant l’accent sur la fiabilité, la sécurité et l’évolutivité de l’entreprise. La dernière mise à jour de MLflow introduit des fonctionnalités innovantes GenAI et LLMOps qui améliorent sa capacité à gérer et à déployer des modèles de langage volumineux (LLM). Cette LLM prise en charge étendue est obtenue grâce à de nouvelles intégrations avec les outils de standard de Secteurs d’activité,LLM OpenAI et Hugging Face Transformers, ainsi qu’avec le MLflow serveur de déploiements . De plus, l’intégration de MLflow avec les frameworks LLM (par exemple, LangChain) permet un développement simplifié de modèles pour la création d’applications d’IA générative pour une variété de cas d’utilisation, notamment les chatbots, le résumé de documents, la classification de texte, l’analyse des sentiments et bien plus encore.
Avantages
Développement de modèles
Améliorez et accélérez la gestion du cycle de vie du machine learning grâce à un cadre standardisé pour les modèles prêts pour la production. Les recettes de MLflow gérées permettent un démarrage de projet ML transparent, une itération rapide et un déploiement de modèle Monter en charge à grande échelle. Créez des applications telles que des chatbots, des résumés de documents, l’analyse des sentiments et la classification sans effort. Développez facilement des applications d’IA générative (par exemple, des chatbots, des résumés de documents) avec les offres LLM de MLflow, qui s’intègrent de manière transparente à LangChain, Hugging Face et OpenAI.
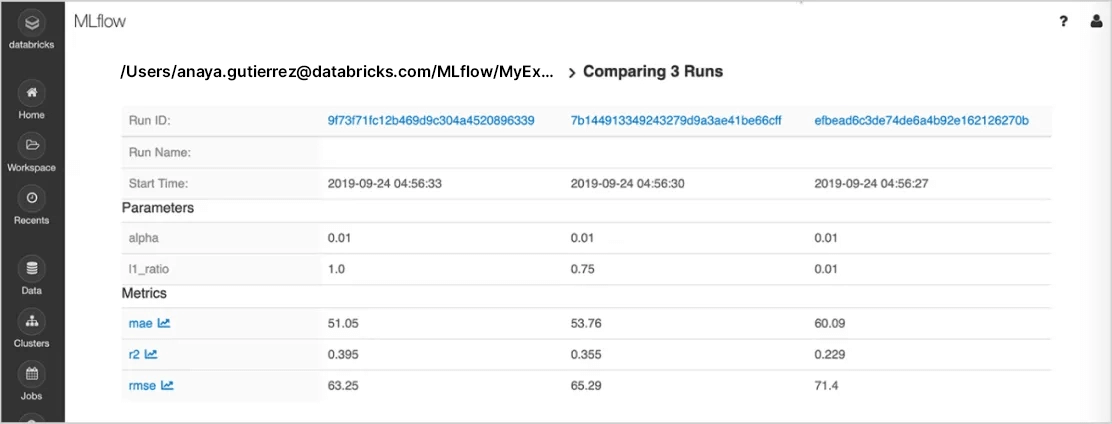
Suivi des tests
Exécutez l’expérimentation avec n’importe quelle bibliothèque, infrastructure ou langage ML , et gardez automatiquement une trace des paramètres, des métriques, du code et des modèles de chaque expérimentation. En utilisant MLflow sur Databricks, vous pouvez partager, gérer et comparer en toute sécurité les résultats de l’expérimentation ainsi que les artefacts et les versions de code correspondants, grâce aux intégrations intégrées avec l' Databricks Espace de travail et Notebook. Vous serez également en mesure d’évaluer les résultats de l’expérimentation GenAI et d’améliorer la qualité grâce à MLflow fonctionnalité d’évaluation.
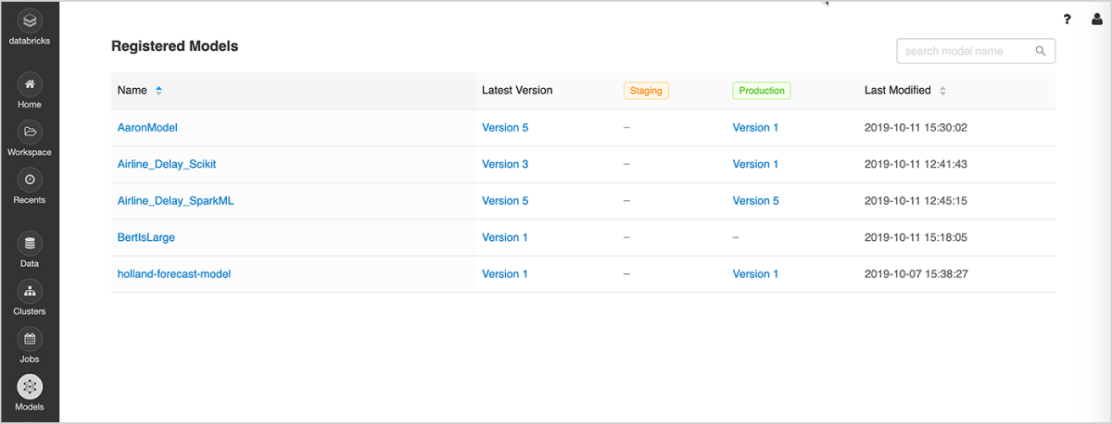
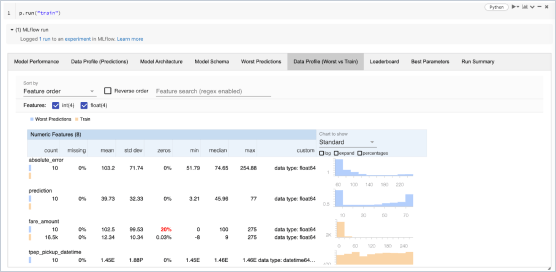
Gestion de modèles
Au sein d'un même emplacement centralisé, vous allez pouvoir partager des modèles ML, collaborer pour les faire passer de l'expérimentation aux tests et à la production, intégrer des workflows d'approbation et de gouvernance et assurer le suivi des déploiements ML et de leurs performances. Le Registre de modèles MLflow facilite le partage d'expertise et de connaissances et vous aide à garder le contrôle.
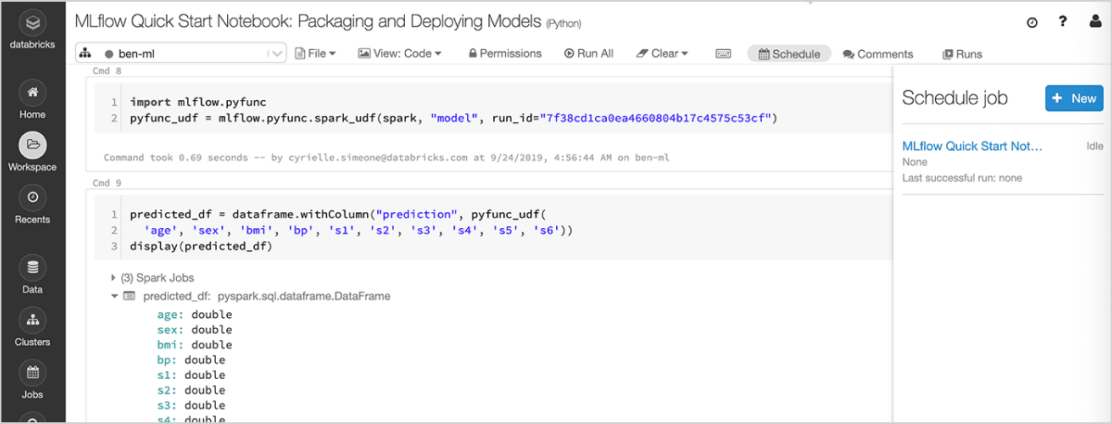
Déploiement de modèles
Déployez rapidement des modèles en production pour les inférences par batch sur Apache Spark™ ou sous forme d'API REST grâce aux intégrations natives avec les conteneurs Docker, Azure ML ou Amazon SageMaker. Avec Managed MLflow sur Databricks, vous pouvez mettre en service et surveiller les modèles de production à l'aide de l'ordonnanceur Databricks et des clusters auto-gérés en fonction de vos besoins métier.
Les dernières mises à niveau de MLflow package de manière transparente les applications GenAI pour le déploiement. Vous pouvez désormais déployer vos chatbots et d’autres applications GenAI telles que le résumé de documents, l’analyse des sentiments et la classification chez Monter en charge, en utilisant Databricks Model Serving.
Features
Tracing
Capture inputs, outputs, and step-by-step execution—including prompts, retrievals, and tool calls—with MLflow’s open-source, OpenTelemetry-compatible tracing. Automatically instrument popular GenAI libraries or ingest traces directly. Debug and iterate faster with interactive timeline views, side-by-side comparisons, and zero vendor lock-in.
Generative AI Evaluation
Evaluate GenAI agents using LLM-as-a-judge and human feedback—right in the MLflow UI. Build datasets from production traces, compare outputs across versions, and assess quality with prebuilt or custom metrics like hallucination or relevance. Incorporate expert feedback via web UIs or app APIs to align with human judgment and continuously improve results.
Prompt Registry and Agent Versioning
Version prompts, agents, and application code in one place with MLflow. Link traces, evaluations, and performance data to specific versions for full lifecycle lineage. Reuse and compare prompts across workflows, manage agent versions with associated metrics and parameters, and integrate with Git and CI/CD to accelerate governed iteration.
Generative AI Monitoring and Alerting
Monitor GenAI quality in real time with MLflow’s dashboards, trace explorers, and automated alerts. Track issues like PII leakage, latency spikes, or unhelpful responses using LLM-judge evaluations and custom metrics. Configure online evaluations and act quickly—before users are affected.
Features
Experiment Tracking
Automatically track parameters, metrics, artifacts, and models from any ML or deep learning framework. MLflow gives you a complete audit trail and supports deep comparisons across architectures, checkpoints, and training workflows—at scale.
Model evaluation for ML and DL
Automatically log built-in and custom metrics for tasks like classification or regression. Compare results against baselines, log artifacts like ROC curves, and validate models on new datasets—before they reach production.
Effortless Model Management & Governance
Discover, share, and manage models centrally with the MLflow Model Registry—integrated with Unity Catalog for end-to-end governance. Track deployment status and collaborate across teams with full visibility into model performance across environments
Deployment at Scale
Deploy models with a reproducible packaging format that includes all code, dependencies, and weights. Serve them as REST APIs or run high-throughput batch inference with ai_query—optimized for both CPU and GPU via Databricks Model Serving.
Consultez les actus sur nos produits publiées sur Azure Databricks et AWS pour découvrir nos dernières fonctionnalités.
Comparaison des offres MLflow
Open Source MLflow | Managed MLflow on Databricks | |
|---|---|---|
Suivi des tests | ||
API de suivi MLflow | ||
Serveur de suivi MLflow | Auto-hébergé | Entièrement géré |
Intégration des notebooks | ||
Intégration des workflows | ||
Projets reproductibles | ||
MLflow Projects | ||
Gestion de modèles | ||
Intégration Git et Conda | ||
Cloud/clusters évolutifs pour l'exécution des projets | ||
MLflow Model Registry | ||
Contrôle de versions des modèles | ||
Déploiements flexibles | ||
Transition d'étape ACL | ||
Intégrations de workflows CI/CD | ||
Sécurité et gestion | ||
Inférence par batch intégrée | ||
MLflow Models | ||
Analyses en streaming intégrées | ||
Haute disponibilité | ||
Mises à jour automatiques | ||
Contrôle d'accès basé sur les rôles | ||
Sécurité et gestion | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles | ||
Sécurité et gestion | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles | ||
Sécurité et gestion | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles | ||
Contrôle d'accès basé sur les rôles |
Ressources
Blogs
VIDÉOS
Tutoriels
Webinaires
Webinaires
Webinaires
Frequently Asked Questions
Ready to get started?