Ricerca 3x più veloce: scaling parallelo al test-time con Instructed-Retriever-1
Oggi annunciamo un importante aggiornamento che rende Agent Bricks Knowledge Assistant sia più veloce che di qualità superiore. Il tempo di generazione delle risposte è diminuito di 2 volte e il tempo di ricerca è ridotto di oltre 3 volte, portando il Time To First Token (TTFT) a circa due secondi.¹ In questo modo, gli utenti di Knowledge Assistant otterranno risposte notevolmente più veloci per tutti i loro casi d'uso, senza alcuna riconfigurazione richiesta e senza compromessi in termini di qualità.
Questi miglioramenti sono supportati da Instructed-Retriever-1, un modello specializzato nel recupero progettato per lo scaling parallelo in fase di test. A differenza del recupero agentico standard, in cui un agente lavora in modo sequenziale e ragiona su ciascun risultato prima di decidere il passaggio successivo, il nostro approccio distribuisce questo lavoro in parallelo. Instructed-Retriever-1 è un singolo modello addestrato per entrambe le fasi di recupero: la generazione di query per aumentare il recall e il reranking per aumentare la precisione, eseguiti in parallelo per mantenere bassa la latenza. In questo post descriviamo come questo approccio consenta di ottenere prestazioni Pareto-ottimali, come addestriamo un singolo modello per supportare l'intera pipeline di recupero e come convalidiamo le prestazioni su carichi di lavoro aziendali reali.
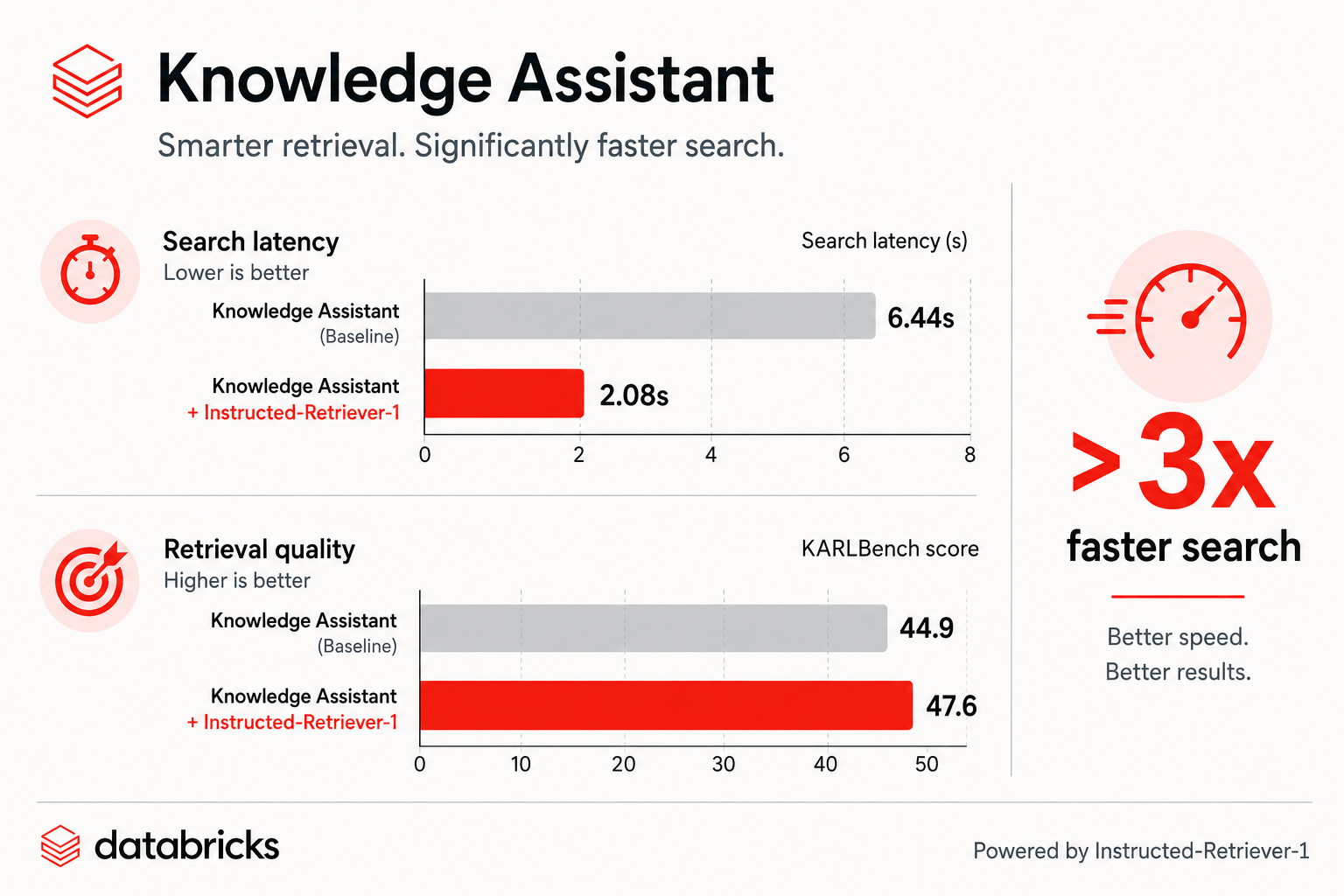
Figura: su KARLBench, Knowledge Assistant con Instructed-Retriever-1 migliora sia la latenza di ricerca che la qualità del recupero.
1. Scaling parallelo in fase di test per la ricerca
La nostra ricerca precedente ha dimostrato che la qualità può migliorare con un calcolo aggiuntivo in fase di test. Tuttavia, la maggior parte dei sistemi di ricerca agentici odierni impiega tale calcolo in operazioni sequenziali, come chiamate a strumenti, cicli di ragionamento e azione e ragionamento chain-of-thought. Questi metodi migliorano la qualità della ricerca, ma a scapito di una latenza e di costi notevolmente superiori. Per l'addestramento di Instructed-Retriever-1, seguiamo una strada diversa: anziché scalare il calcolo in modo sequenziale, lo parallelizziamo durante la fase di ricerca iniziale. Ampliando la gamma di prove recuperate e selezionando in anticipo il contesto più pertinente, otteniamo una ricerca altamente efficace con una latenza significativamente inferiore.
Il miglioramento della ricerca iniziale dipende fortemente dall'harness di addestramento. Il nostro harness fornisce al modello le istruzioni dell'utente e lo schema preciso dell'indice di recupero sottostante, e li propaga a tutte le fasi successive di generazione di query e filtri, reranking e generazione delle risposte. Abbiamo descritto come ottenere questo risultato nel nostro precedente blog su Instructed Retriever, e utilizziamo lo stesso harness di ricerca per l'addestramento del nostro modello Instructed-Retriever-1. Questo approccio è particolarmente importante per le domande di livello aziendale, che spesso comportano vincoli specifici del dominio come periodo di tempo, organizzazione, tipo di documento o area di prodotto.
La generazione parallela di query e filtri migliora il recall del set di candidati esplorando simultaneamente molteplici formulazioni e aspetti della stessa richiesta. Ciò consente al sistema di effettuare ricerche più ampie mantenendo bassa la latenza. Una ricerca più ampia crea una sfida di aggregazione. Formulazioni diverse possono restituire chunk sovrapposti o solo parzialmente pertinenti. Per selezionare il contesto più utile dal set di candidati unito, utilizziamo un groupwise reranker multi-pivot. I candidati vengono classificati in gruppi paralleli, ciascuno ancorato a uno o più chunk pivot, e le classifiche dei gruppi vengono unite in un ordinamento finale. Questo approccio coglie i vantaggi principali del confronto delle prove nel contesto, mantenendo efficiente il reranking.
Insieme, queste fasi forniscono due parametri di regolazione per lo scaling in fase di test: l'aumento del numero di formulazioni di query e filtri migliora il recall, mentre l'aumento del numero di pivot migliora la precisione. Poiché entrambe le fasi possono utilizzare il parallelismo, il sistema può scambiare un calcolo aggiuntivo in fase di test con un contesto di qualità superiore, preservando al contempo una bassa latenza.
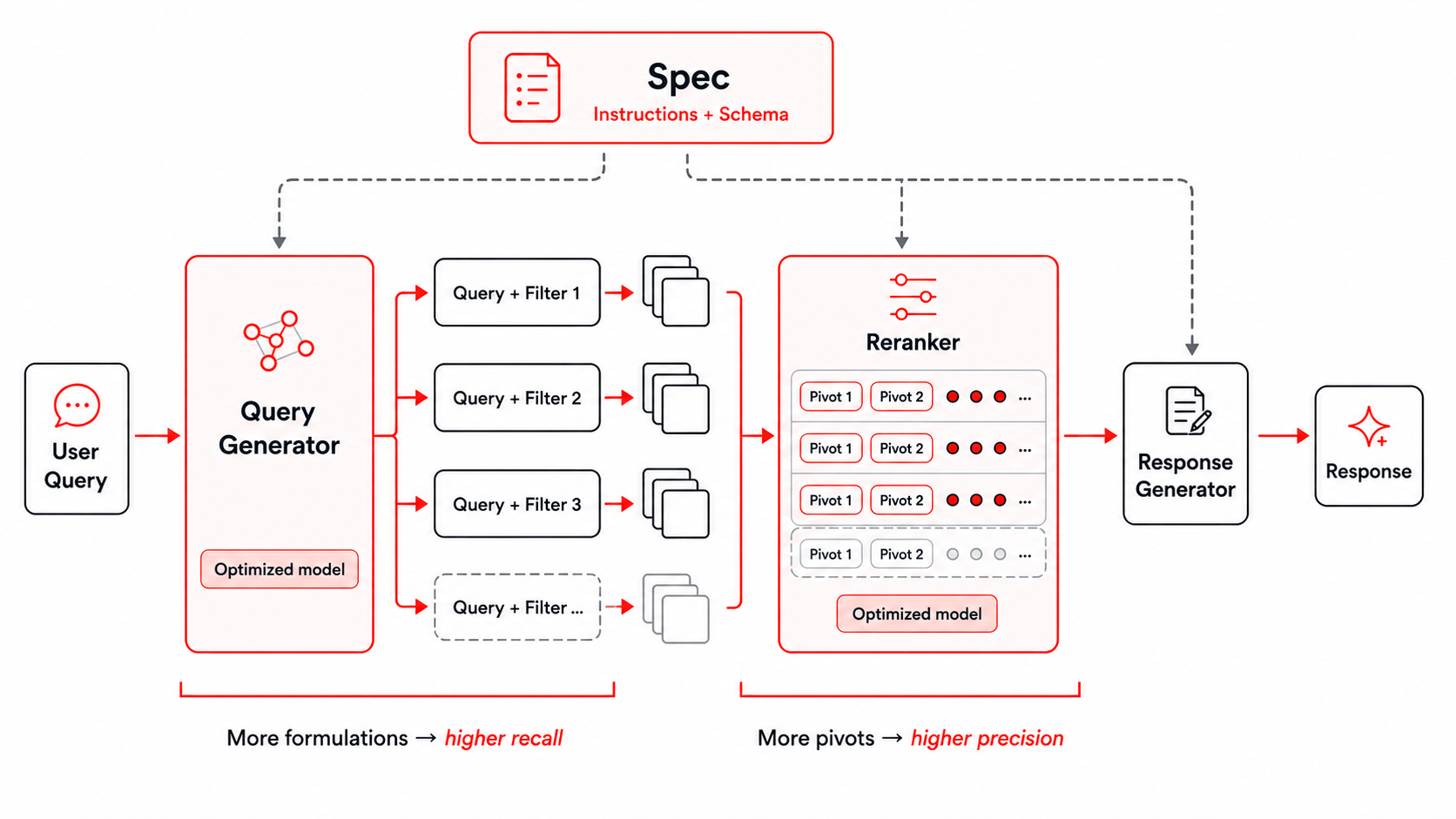
Figura: l'harness di ricerca utilizzato per Instructed-Retriever-1.
2. Addestramento di Instructed-Retriever-1
Lo scaling parallelo in fase di test per la ricerca richiede un modello in grado di fare bene due cose: generare ricerche efficaci e valutare le prove recuperate. Abbiamo addestrato Instructed-Retriever-1 come un singolo modello specializzato nel recupero che supporta la generazione parallela di query e il reranking. Il risultato è un modello che eguaglia la qualità di recupero di Claude Sonnet 4.5 su KARLBench mantenendo al contempo una bassa latenza.
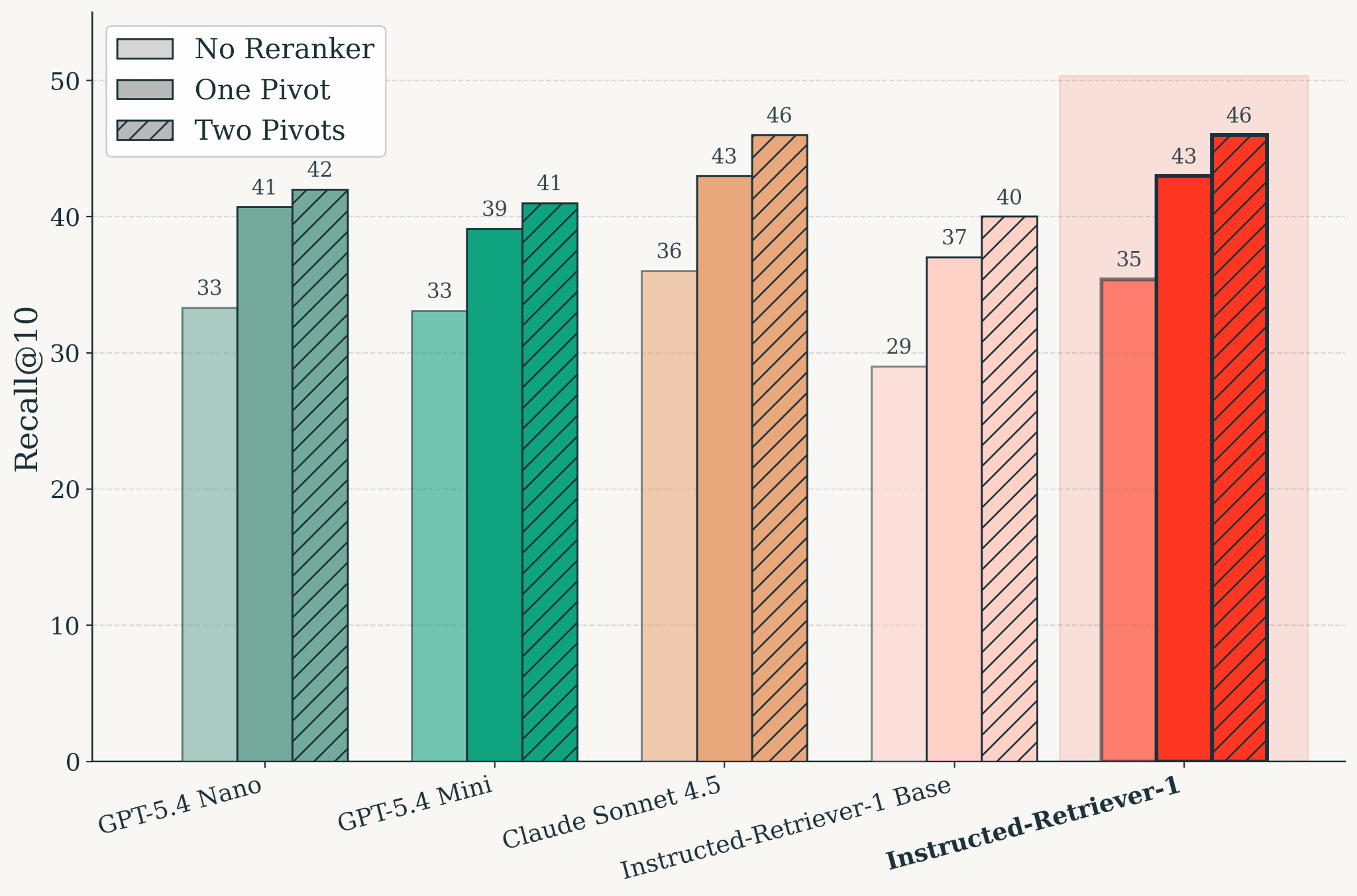
Figura: qualità del recupero su KARLBench dopo l'addestramento, valutata in base alle configurazioni di reranking. Instructed-Retriever-1 eguaglia la qualità di recupero di Claude Sonnet 4.5. Tra i vari modelli, il reranking basato su pivot migliora il Recall@10 rispetto all'impostazione senza reranker, e due pivot migliorano ulteriormente la qualità rispetto a un solo pivot.
Per preparare i dati per l'addestramento, creiamo ambienti di recupero sintetici in stile aziendale a partire da un ampio corpus di pre-addestramento, indipendentemente dal nostro benchmark di valutazione. Li creiamo utilizzando l'approccio di sintesi dei dati agentica descritto nel report KARL. Gli ambienti risultanti riflettono i tipi di attività che Knowledge Assistant deve gestire, tra cui ricerca di fatti, riepilogo, raccomandazione, risoluzione di problemi e supporto decisionale su corpora che combinano documenti non strutturati con metadati strutturati.
Il modello viene addestrato in due fasi per acquisire molteplici capacità di ricerca. Il modello risultante supporta sia la generazione di query e filtri, sia funzionalità di recupero in stile verifica, abilitando le due fasi che rendono utile nella pratica lo scaling parallelo in fase di test.
3. Convalida di Instructed-Retriever-1 in produzione
Migliorare il recupero è importante solo se funziona su carichi di lavoro reali e rientra nei vincoli di latenza della produzione. Valutiamo Instructed-Retriever-1 su un set di dati interno su larga scala rappresentativo dell'utilizzo di Knowledge Assistant, misurando se i due meccanismi di scaling introdotti sopra migliorano la qualità del recupero: la generazione parallela di query e filtri per il recall e il reranking multi-pivot per la precisione.
Figura: dimostrazione di Knowledge Assistant supportato da Instructed-Retriever-1.
Qualità del recupero su carichi di lavoro reali
Il nostro set di dati di valutazione si basa su carichi di lavoro reali di Knowledge Assistant, in cui le risposte utili spesso richiedono molteplici prove di supporto anziché un singolo documento di riferimento. Valutiamo il recupero in due fasi. In primo luogo, misuriamo la latenza e la qualità della generazione delle query in tutti i sistemi candidati. Per la qualità, utilizziamo i punteggi della rubrica di valutazione LLM-judge per specificità, ampiezza e pertinenza. Queste metriche rilevano se le query generate sono mirate, coprono gli aspetti importanti della richiesta e rimangono utili per rispondere alla domanda.
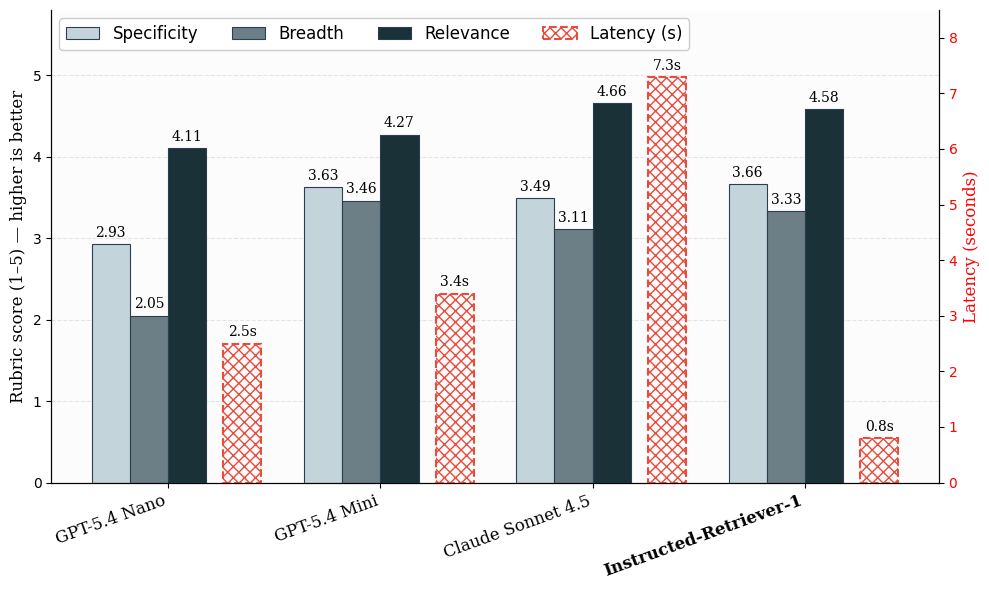
Figura: qualità e latenza della generazione di query su esempi interni simili alla produzione. I punteggi medi della rubrica valutano la qualità della generazione delle query in termini di specificità, ampiezza e pertinenza su una scala da 1 a 5. La latenza è calcolata per una fase di generazione delle query.
Per il reranking, manteniamo fisso l'insieme dei candidati recuperati e valutiamo l'efficacia con cui ciascun reranker fa emergere le prove più utili. Per ottenere etichette di rilevanza dense, utilizziamo un giudice LLM per assegnare un punteggio a ciascun chunk su una scala di rilevanza in stile TREC da 0 a 3, quindi calcoliamo nDCG@10 dalle classifiche risultanti. Claude Sonnet 4.5 e Instructed-Retriever-1 ottengono rispettivamente un punteggio di 80,1 e 81,0 nDCG@10. Si tratta di incrementi del +12,8% e del +14,1% rispetto a uno scenario senza reranking, a dimostrazione dell'efficacia del nostro reranker di gruppo multi-pivot.
Nel complesso, su carichi di lavoro realistici, Instructed-Retriever-1 offre prestazioni elevate in tutte le metriche della rubrica di generazione delle query e rimane competitivo con la baseline più solida nel reranking. Questo supporta l'uso di un singolo modello specializzato nel recupero sia per la generazione delle query che per la selezione dei candidati.
Prestazioni di serving
Lo scaling parallelo in fase di test è utile solo se la potenza di calcolo aggiuntiva può essere erogata in modo efficiente e si adatta al numero di ricerche. A tal fine, Instructed-Retriever-1 utilizza un'architettura Mixture-of-Experts e ottimizzazioni di serving che includono la quantizzazione FP8,2 la decodifica speculativa e un ulteriore perfezionamento dell'infrastruttura per l'intera pipeline di recupero. Nelle nostre valutazioni, il formato FP8 non mostra alcun degrado della qualità, migliorando al contempo la velocità di inferenza e il throughput rispetto a BF16.3 La decodifica speculativa aggiunge un ulteriore incremento di velocità del 30%+ per il percorso combinato di generazione delle query e reranking.
Conclusione
Questo aggiornamento introduce il Parallel Test-Time Scaling nello stack di ricerca in produzione. Il sistema esegue un recupero ampio attraverso la generazione parallela di query e filtri, per poi eseguire un reranking preciso grazie al confronto delle prove multi-pivot. Instructed-Retriever-1 gestisce entrambe le fasi con un unico modello specializzato nel recupero, addestrato per la generazione della ricerca e il ranking delle prove. Il risultato è un Knowledge Assistant migliore e più veloce: il tempo di ricerca si riduce di oltre 3 volte, il tempo di generazione delle risposte si riduce di 2 volte, il TTFT è di circa 2s e la latenza end-to-end è costantemente inferiore a 10s nella nostra configurazione di valutazione offline.¹ I primi utenti, come la Baylor University e altri, stanno già notando la differenza.
"(La nuova esperienza è) più concisa, con una sensazione di maggiore reattività che fa emergere prima le informazioni chiave: un notevole miglioramento della UX per i nostri casi d'uso." —Kyle Van Pelt, Director of Process and Governance, Enrollment Management presso la Baylor University.
Inizia oggi stesso a chiedere di più al tuo Knowledge Assistant. Il rollout di Instructed-Retriever-1 è iniziato per tutti i clienti, aiutando i team a recuperare un contesto di qualità superiore con tempi di attesa ridotti; potrai porre più domande, scoprire più informazioni e passare dalla domanda alla risposta più velocemente. Provalo ora.
1 Le stime di latenza sono misurate come media delle valutazioni offline, con una lunghezza media di circa 256 token di output. La latenza effettiva può variare in base alla struttura dei dati nelle specifiche istanze di Knowledge Assistant e nelle query.
2 Utilizziamo la libreria ModelOpt di NVIDIA per la quantizzazione FP8.
3 Abbiamo valutato i modelli BF16 e FP8 su KARLBench in 10 prove. Il formato FP8 non ha mostrato alcun degrado della qualità statisticamente significativo rispetto a BF16: la differenza media di punteggio è stata di +0,33 punti, con un errore standard di 1,69 punti e un intervallo di confidenza al 95% di [-2,99, 3,65].
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.