Databricks for Good e Virtue Foundation: Collaborazione per connettere volontari medici a servizi sanitari essenziali in 72 Paesi
- La Virtue Foundation ha collaborato con Databricks per il Bene per sfruttare l'IA e migliorare i risultati sanitari globali.
- Il risultato ha permesso alla Virtue Foundation di abbinare meglio le competenze dei medici alle opportunità di volontariato nei paesi in via di sviluppo dove tali competenze mediche sono più necessarie.
- Insieme, i team di Databricks e Virtue Foundation stanno fornendo set di dati fondamentali aggiornati in un formato facilmente accessibile e utilizzabile.
Introduzione
Virtue Foundation è un'organizzazione no-profit focalizzata sulla fornitura di servizi sanitari globali e sulla creazione di un mercato efficiente per l'assistenza sanitaria filantropica a livello mondiale. Ad oggi, ha fornito assistenza a oltre 50.000 pazienti, con un'attenzione particolare al Ghana e alla Mongolia. La spina dorsale di questo mercato è la cura dei dati sulle strutture sanitarie globali attraverso VF Match, una piattaforma che collega i professionisti medici a opportunità di volontariato in 72 paesi a basso e medio-basso reddito. Databricks for Good collabora strettamente con Virtue Foundation dal 2024 per sfruttare l'IA al fine di aggregare dati in questi paesi e renderli utilizzabili.
Un proof of concept iniziale ha dimostrato che gli LLM potevano estrarre informazioni strutturate da diverse fonti di dati web per creare una mappa dell'infrastruttura sanitaria e, cosa più importante, delle lacune nei servizi nelle aree con risorse insufficienti. Tuttavia, scalare questa funzionalità e portarla in produzione ha posto molte sfide. Da quella prima iterazione, abbiamo costruito una piattaforma basata su Databricks che ha trasformato il POC in un sistema di livello produttivo che aggrega dati da migliaia di strutture sanitarie e organizzazioni no-profit in tutto il mondo.
In questo articolo, illustriamo come abbiamo migliorato il nostro lavoro precedente per consentire ulteriormente a Virtue Foundation di abbinare la propria comunità di volontari medici con le esigenze critiche in questi paesi.
Costruire le fondamenta: dati sanitari di 72 paesi
Il cuore di VF Match è il Foundational Data Refresh (FDR): un set di dati completo su strutture sanitarie e organizzazioni no-profit, costruito da zero a partire da varie fonti web. Acquisiamo e aggiorniamo sistematicamente i dati da 72 paesi a basso e medio-basso reddito in tutto il mondo.
Due fonti di dati complementari alimentano questo aggiornamento:
- Overture Maps: Un dataset geospaziale open source di Meta e Microsoft, che fornisce posizioni autorevoli per le strutture sanitarie.
- Bright Data: Infrastruttura industriale di web scraping che acquisisce informazioni in tempo reale da Internet.
Il cuore dell'FDR è una pipeline di estrazione delle informazioni alimentata dai modelli GPT di OpenAI. L'elaborazione di oltre 25 milioni di pagine web tramite LLM con garanzie di produzione ha richiesto di ripensare le pipeline di inferenza LLM tradizionali. Invece di tentare l'estrazione one-shot, la nostra pipeline suddivide il compito in passaggi mirati: classificazione della rilevanza medica, identificazione del tipo di organizzazione (struttura medica o ONG) ed estrazione di specialità, attrezzature e procedure.
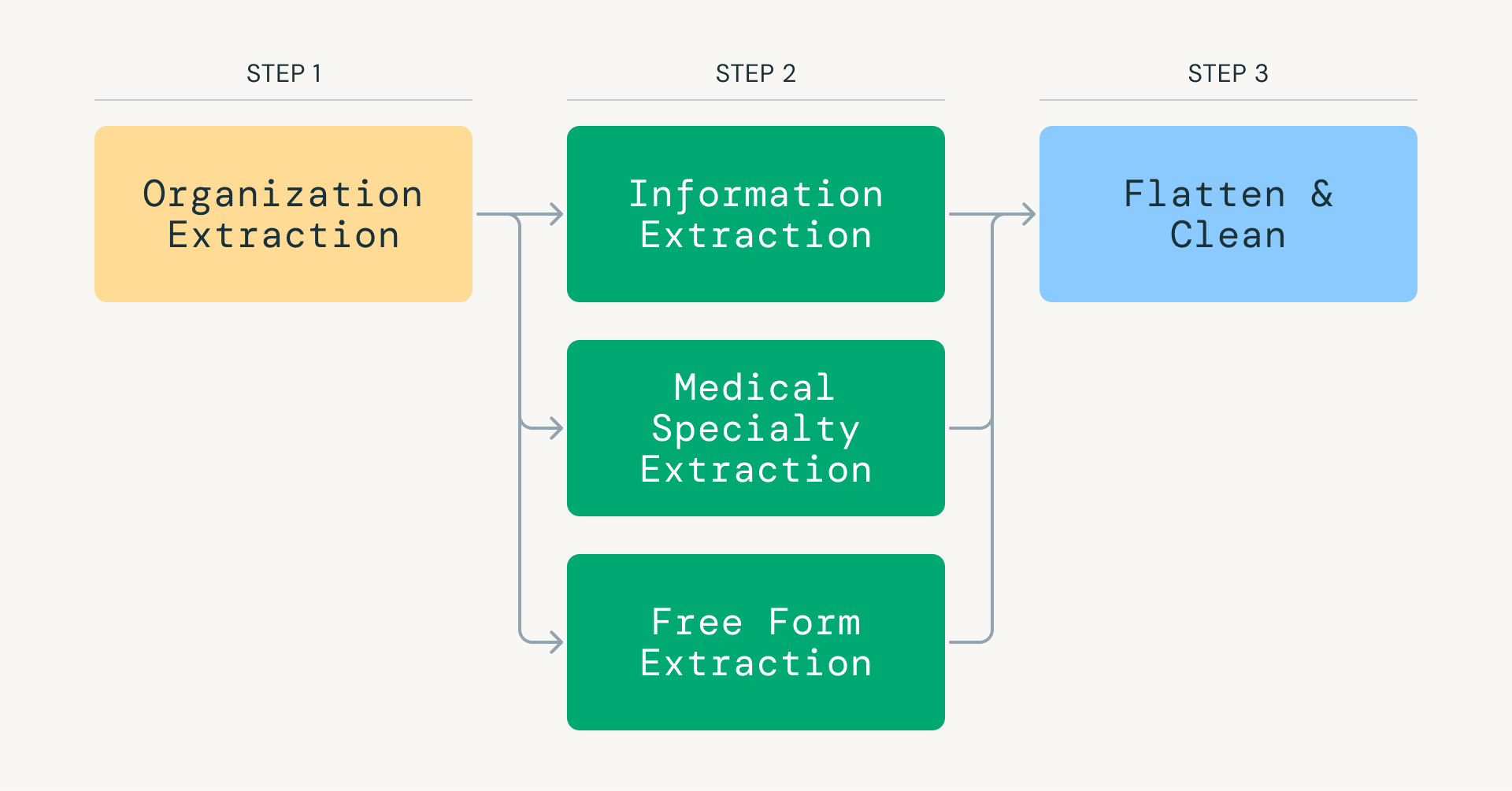 Fig 1: Passaggi chiave del Foundational Data Refresh (FDR).">
Fig 1: Passaggi chiave del Foundational Data Refresh (FDR).">Questo approccio riduce drasticamente il consumo di token, concentrando ogni invocazione del modello su un compito specifico e ad alta precisione. Databricks e Apache Spark vengono utilizzati per orchestrare e parallelizzare in modo efficiente i dati acquisiti tramite scraping, distribuendo i carichi di lavoro su migliaia di executor e consentendo un'inferenza LLM ad alto throughput.
Diverse caratteristiche critiche rendono questa pipeline scalabile e pronta per la produzione:
- Modellazione dei dati estensibile: I dati di ogni passaggio sono archiviati in uno schema a stella, semplificando l'analisi a valle e migliorando le prestazioni delle query.
- Checkpointing basato sullo stato: Ogni record traccia il proprio stato di elaborazione, consentendo alle pipeline di riprendere da qualsiasi punto senza rielaborare righe con costose chiamate LLM.
- Registro di estrazione configurabile: Ogni metodo di estrazione è controllato da un oggetto strutturato che specifica il prompt di sistema, rendendo la logica di estrazione modulare, riproducibile ed estensibile.
- Elaborazione distribuita scalabile: Il sistema elabora carichi di lavoro sbilanciati e multi-terabyte utilizzando Spark per il parallelismo, Photon per le prestazioni su larga scala e un'orchestrazione di livello produttivo.
Queste garanzie sono applicate tramite Lakeflow Jobs, che orchestra più di 15 attività interdipendenti con ramificazioni condizionali, esecuzione parallela e politiche di riprova intelligenti. Il risultato è un sistema che elabora i dati delle strutture sanitarie su larga scala con la precisione degli esperti medici.
Risoluzione delle entità su larga scala
Una volta che i dati delle strutture e delle organizzazioni no-profit vengono acquisiti tramite scraping ed estratti utilizzando un LLM, emerge una sfida classica: la risoluzione delle entità. La stessa struttura può apparire in più fonti di dati con variazioni di nome, indirizzi incoerenti o dettagli di contatto mancanti. La deduplicazione tradizionale fallisce in questi scenari a causa di dati disordinati, quindi utilizziamo Splink, un framework open source di collegamento probabilistico dei record. Utilizzando le informazioni ottenute nel nostro passaggio di IE, Splink valuta le coppie corrispondenti tramite confronti ponderati tra campi come numero di telefono, indirizzo e altro. Il risultato è una chiave unificata per struttura, garantendo che gli utenti finali vedano un unico record autorevole per ogni struttura medica e ONG.
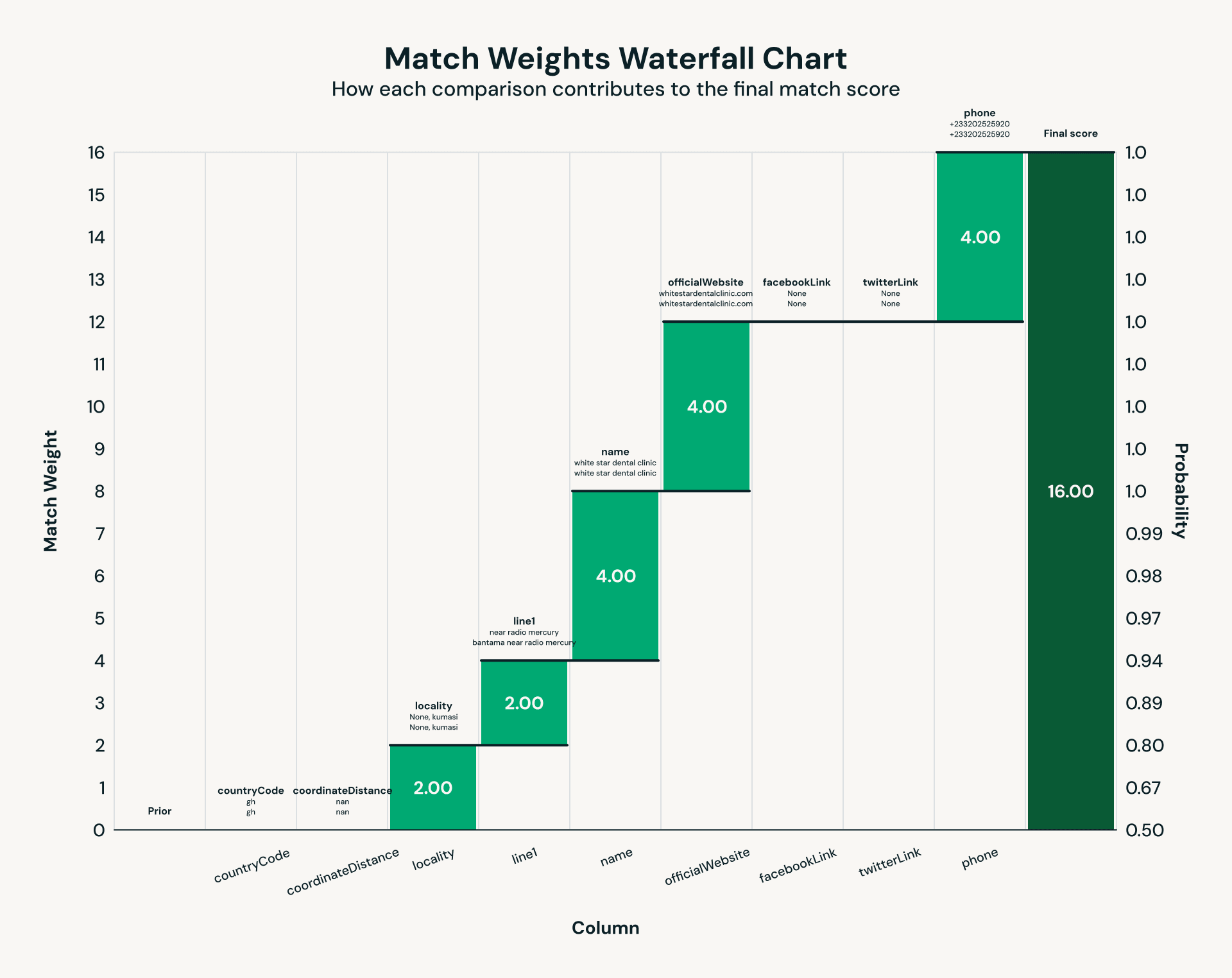 Fig 2: Esempio di set di regole per la risoluzione delle entità tramite Splink.">
Fig 2: Esempio di set di regole per la risoluzione delle entità tramite Splink.">L'esecuzione del matching probabilistico su migliaia di strutture sanitarie e organizzazioni no-profit ha rivelato i classici colli di bottiglia prestazionali che emergono su scala terabyte. Il cuore del collegamento dei record è il confronto a coppie, che crea carichi di lavoro intrinsecamente sbilanciati: i confronti comuni producono partizioni massicce mentre la maggior parte degli altri rimane molto più piccola. Le prime esecuzioni lo hanno reso dolorosamente chiaro, con una partizione Spark in esecuzione per 30 minuti mentre la mediana si completava in 52 secondi – un caso da manuale di stragglers (la "maledizione dell'ultimo reducer") che degradano le prestazioni del job. L'abilitazione di Photon, il motore di query vettorizzato di Databricks, ha ridotto le partizioni di dati nel caso peggiore da 30 minuti a circa 2 minuti: un miglioramento di 15 volte.
VF Agent: il linguaggio naturale incontra i dati sanitari
Guardando al futuro, abbiamo sviluppato un prototipo di un agente che consente agli esperti di analizzare i dati utilizzando il linguaggio naturale. Utilizziamo un'architettura multi-agente costruita in LangGraph e sfruttiamo Databricks Model Serving, AI Search e Genie.
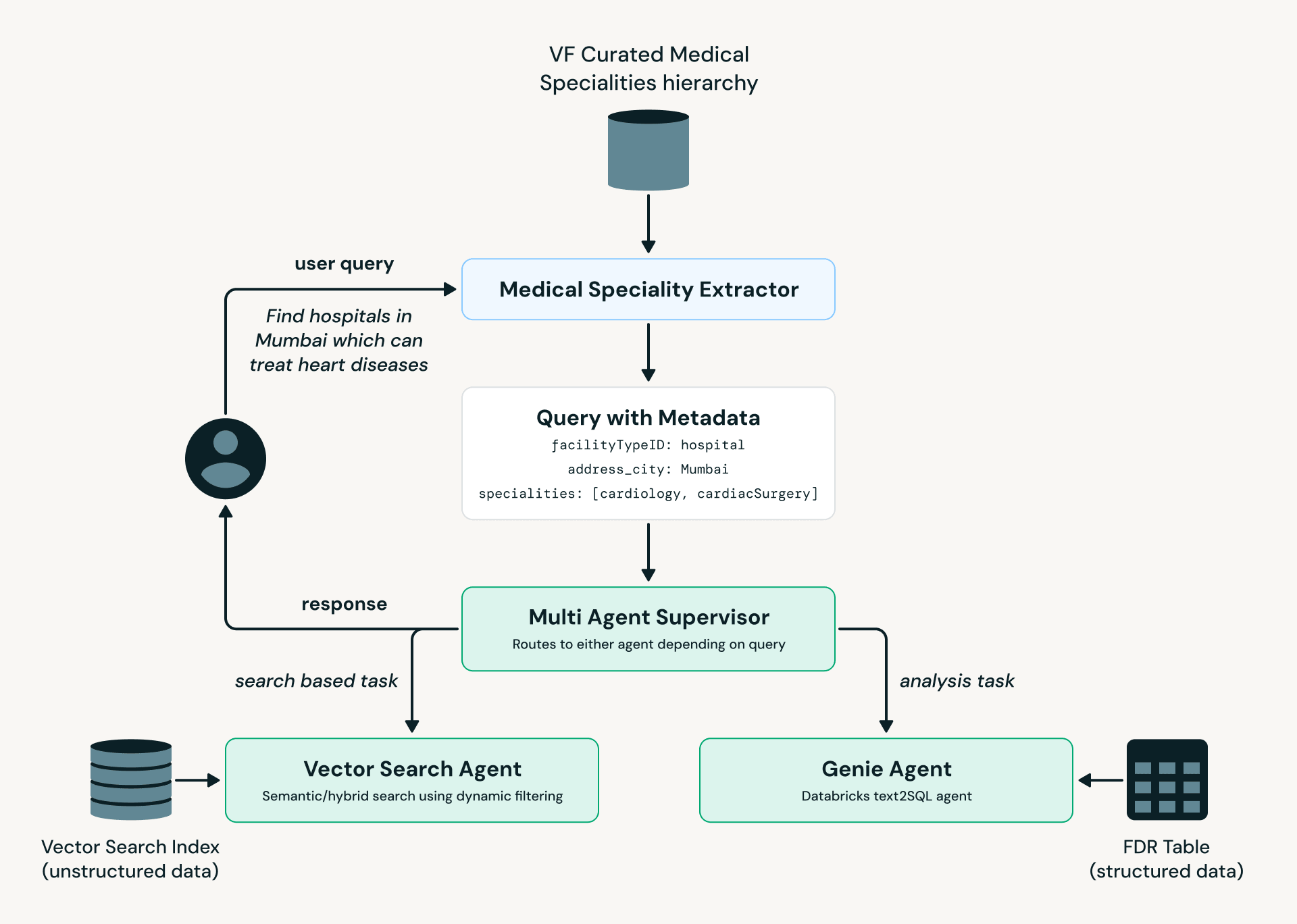 Fig 3: VF Agent: Diagramma di flusso del processo">
Fig 3: VF Agent: Diagramma di flusso del processo">Come illustrato nel diagramma sopra, il Medical Specialty Extractor converte il linguaggio dell'utente in terminologia medica standardizzata, che viene poi passata al Multi-Agent Supervisor. In base all'intento e alla complessità della query, essa viene instradata al AI Search Agent (scoperta e ricerca di strutture) o al Genie Agent (query analitiche su dati strutturati).
Riepilogo
I professionisti sanitari possono ora scoprire opportunità aggiornate più velocemente, trovare corrispondenze con le loro specialità mediche e accedere a dati globali su migliaia di strutture in tutto il mondo. Il percorso di Virtue Foundation dal proof of concept alla produzione dimostra cosa sia possibile quando sistemi AI avanzati sono abbinati a una piattaforma dati unificata.
Il risultato finale è una visione globale dell'infrastruttura sanitaria, che evidenzia dove i volontari medici sono più necessari.
Se desideri saperne di più su questo progetto, consulta:
- Panoramica del progetto Databricks x Virtue Foundation - YouTube
- Intervista UN Bloomberg (YouTube) - intorno al minuto 38:00
- Testimonianza video: Bright Initiative x Virtue Foundation x Databricks
Scopri di più su alcuni dei nostri altri progetti Databricks for Good qui sotto:
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.