MemEx: uno scratchpad programmabile per agenti LLM
Nel 1945, Vannevar Bush immaginò una macchina delle dimensioni di una scrivania che avrebbe esteso la memoria di uno scienziato memorizzando ogni documento, annotazione e percorso di pensiero per poterli richiamare su richiesta. La chiamò MemEx. Bush stava risolvendo un problema umano: menti sopraffatte da informazioni che non potevano tenere a portata di mano. Otto decenni dopo, gli agenti LLM si scontrano con un muro notevolmente simile.
Nell'attuale paradigma di Agentic Tool Calling, la finestra di contesto è l'unico substrato persistente su cui il modello può operare. Si tratta di uno spazio condiviso che contiene il prompt di sistema, la query dell'utente, il ragionamento del modello, le chiamate ai tool e gli output grezzi dei tool. Gli output dei tool sono i peggiori colpevoli: una singola query SQL potrebbe restituire milioni di righe e, negli attuali sistemi di gestione, queste righe vengono trascinate in ogni turno successivo anche se solo una singola cella era davvero importante. L'agente non ha modo di sezionare, riassumere o archiviare il risultato prima che inondi la finestra.
Ci scontiamo costantemente con questo muro in Databricks. I nostri agenti in produzione, da Genie ad Agent Bricks, a un certo punto si imbattono negli stessi limiti di contesto. Genie ne fornisce un chiaro esempio: una singola query effettua una ricerca nell'intero workspace di un cliente, chiamando molti tool per estrarre dati da tabelle, indici vettoriali e dashboard. Per risolvere questo problema, abbiamo creato un nostro MemEx e lo abbiamo validato all'interno di molteplici agenti interni e in produzione.
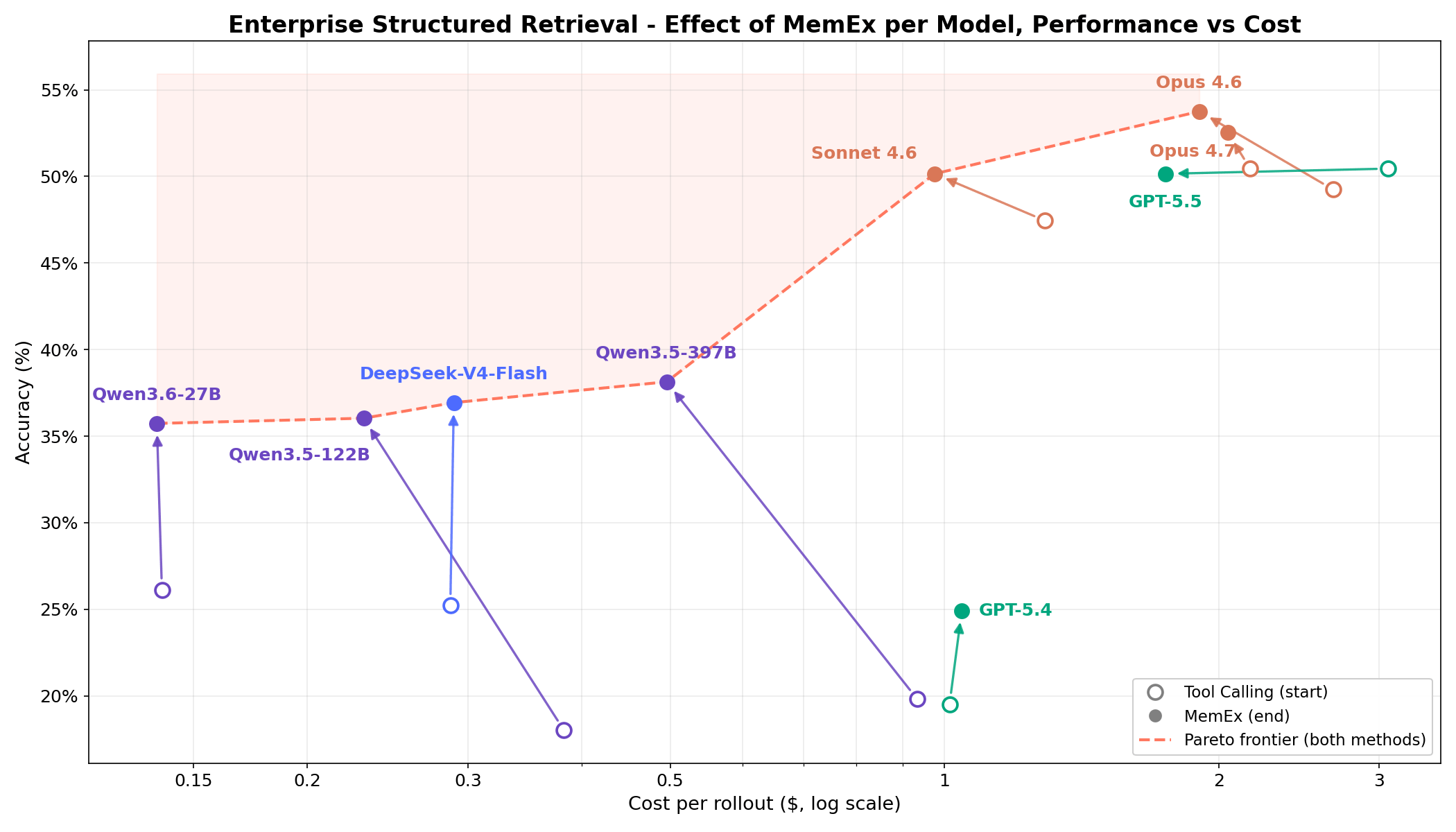
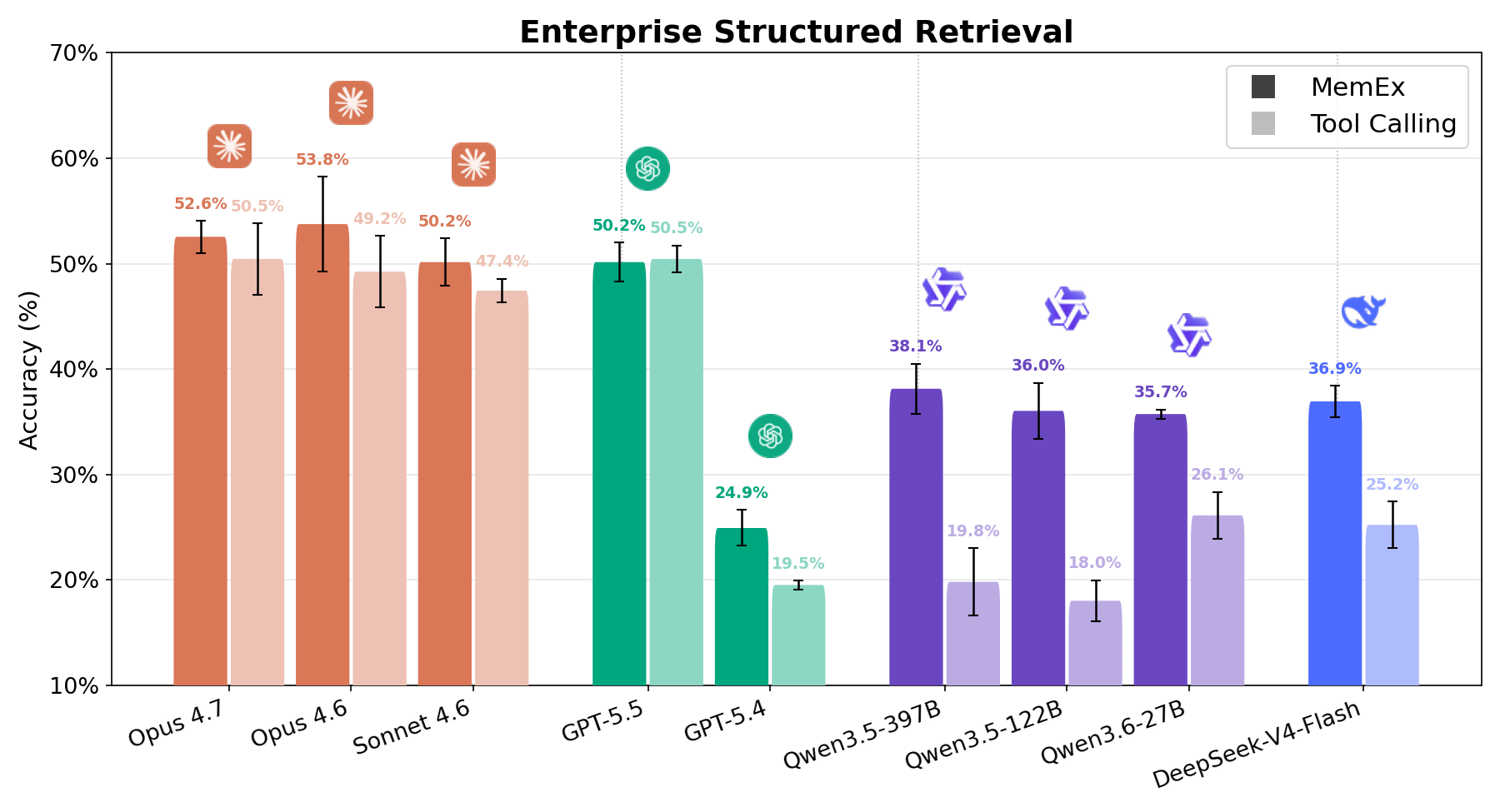
Su compiti complessi di recupero strutturato aziendale, la Figura 1 mostra che MemEx sposta la frontiera costo-accuratezza per ogni modello. I modelli di frontiera come Opus 4.6 e Sonnet 4.6 guadagnano 2-5 punti percentuali con un costo in token inferiore del 25-30%. I modelli open-weights come Qwen3.5-122B (18% → 36%) e Qwen3.5-397B (20% → 38%) quasi raddoppiano la loro accuratezza con un costo in token inferiore del 40-50%. Poiché MemEx può operare su input arbitrariamente lunghi, sblocca anche altre due applicazioni: l'auditing delle traiettorie degli agenti, inclusa quella di MemEx, che normalmente non entrerebbero in una singola finestra di contesto, e il pensiero parallelo su più traiettorie.
Come funziona MemEx
{kind=link}
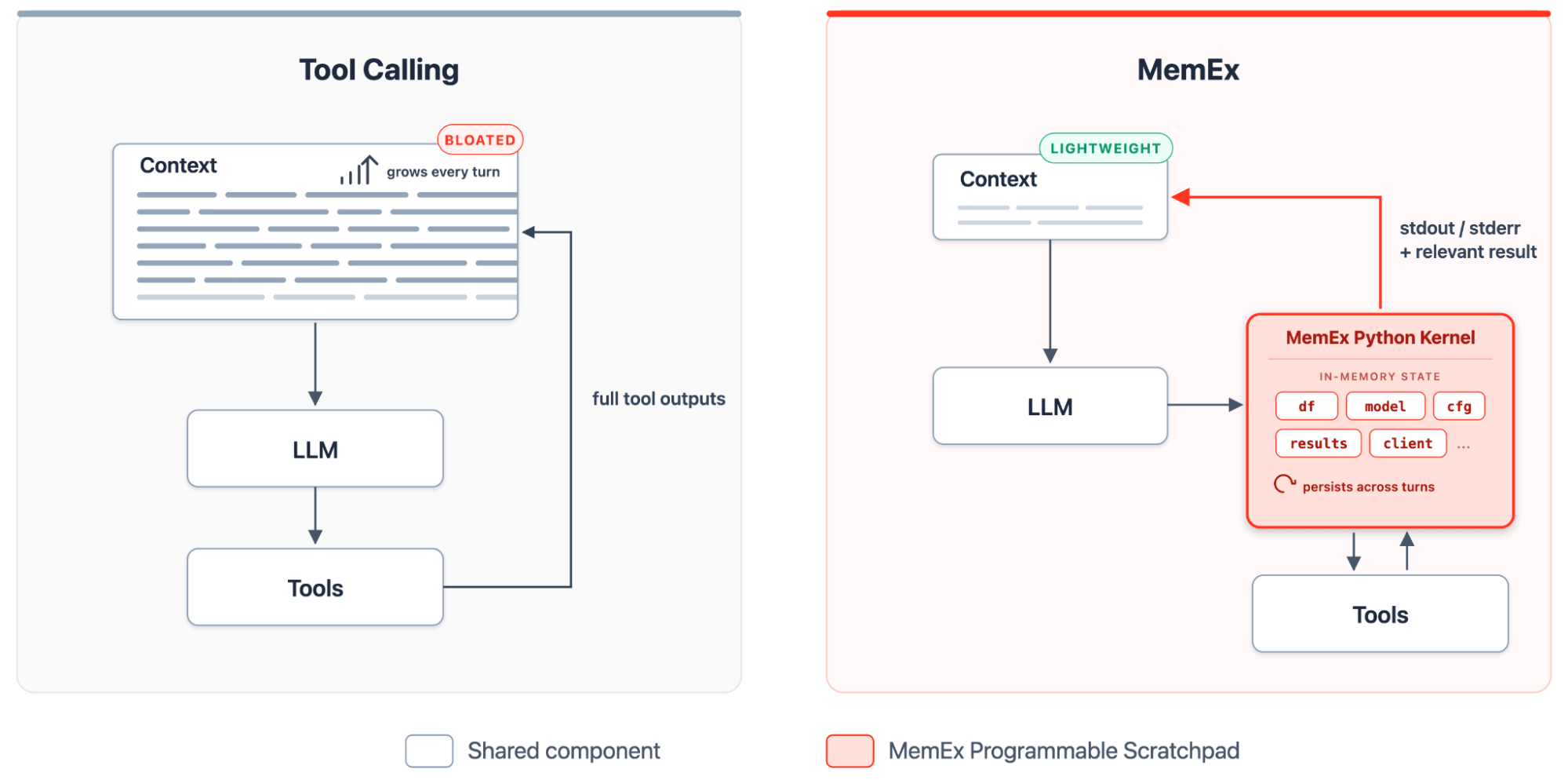
MemEx fornisce all'LLM un blocco note programmabile: un kernel Python tipizzato che contiene gli output dei tool, li trasforma con il codice e materializza solo le istruzioni print come token nel contesto. All'interno di questo ambiente, il rollout diventa un programma Python che si estende autonomamente. Durante ogni turno, l'agente scrive un nuovo blocco, il kernel mantiene attivo lo stato e il blocco successivo si basa su quello precedente. I tool sono esposti come funzioni Python tipizzate con parametri tipizzati e valori di ritorno tipizzati. Gli output dei tool arrivano come oggetti Python nello scope di MemEx, dove persistono tra i vari turni. L'agente li compone con il codice, definisce funzioni helper quando un pattern si ripete e genera sub-agenti come chiamate di funzioni asincrone sullo stesso scope.
MemEx fa parte della famiglia code-as-action introdotta da CodeAct (Wang et al., 2024), con varianti di produzione nel Programmatic Tool Calling di Anthropic e in Cloudflare Code Mode. MemEx si distingue perché si inserisce in un framework agentico esistente in stile ReAct (Yao et al., 2022), con scope persistente, primitive di sub-agenti e ritorni tipizzati integrati. Insieme, questi elementi sbloccano funzionalità che mancano al paradigma di chiamata dei tool JSON/XML:
- Gestione di input arbitrariamente grandi: documenti, dataset e altri oggetti di grandi dimensioni possono essere mantenuti nello scope di Python come variabili.
- Ritorno di oggetti tipizzati: gli output dei tool sono oggetti Python tipizzati mantenuti in memoria, non stringhe che il modello deve materializzare o analizzare nuovamente a ogni turno.
- Composizione delle chiamate ai tool: l'output di una chiamata confluisce direttamente negli argomenti della chiamata successiva all'interno di una singola riga di codice. Gli output intermedi non devono essere materializzati nel contesto dell'agente.
- Sezionamento degli output dei tool: gli output possono essere pre-elaborati, filtrati o riassunti nel codice prima che il modello li veda.
- Generazione di sub-agenti asincroni: gli agenti possono generare programmaticamente sub-agenti che vengono eseguiti in parallelo all'agente genitore e aggregare i loro risultati senza dover passare nuovamente attraverso il modello principale.
Esempio di agente LLM con MemEx
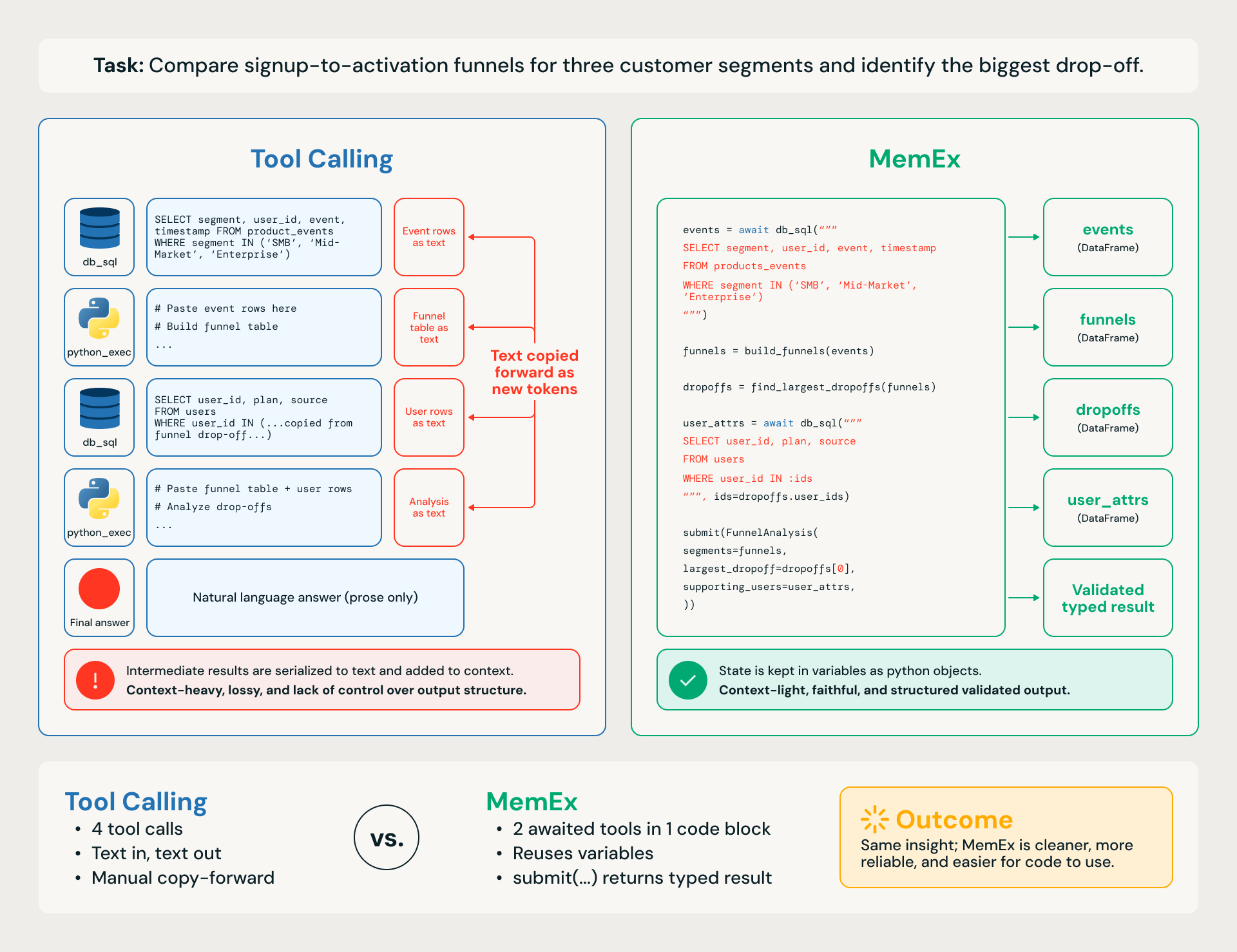
Prendiamo un compito aziendale concreto, come il confronto dei funnel da registrazione ad attivazione per tre segmenti di clienti e l'identificazione del calo maggiore (Figura 1). Il flusso di lavoro prevede quattro passaggi:
- recuperare gli eventi di registrazione e attivazione dal data warehouse
- unirli per utente
- calcolare i tassi di conversione per segmento in ogni fase
- classificare i cali tra i vari segmenti.
Un agente di Tool Calling dotato di python_exec lavora un passaggio alla volta. Ogni query SQL e ogni calcolo programmatico è una chiamata a un tool separata, con DataFrame intermedi serializzati in testo e incollati nuovamente nei turni successivi. La traccia è pesante in termini di token, il che la rende soggetta a perdite di informazioni, lenta, costosa e incline a piccoli errori a cascata nel compito a valle.
Un agente MemEx scrive lo stesso flusso di lavoro come un singolo blocco di codice: le query restituiscono DataFrame nativi nello scope, le funzioni helper li compongono e la risposta finale viene restituita come un oggetto tipizzato e validato tramite submit(). Stesso pensiero, spazio d'azione diverso.
Per i compiti che si scompongono in sotto-problemi, l'agente può generare sub-agenti dall'interno di un blocco. Quando genera sub-agenti, l'agente genitore può passare l'accesso condiviso a qualsiasi oggetto. I sub-agenti vengono eseguiti in parallelo con il genitore e possono restituire i risultati all'agente principale al termine del lavoro. Ad esempio:
La scomposizione ricorsiva diventa un'altra espressione nello stesso programma Python.
MemEx è sviluppato su aroll, il framework di rollout agentici di Databricks. Aroll alimenta già sistemi in produzione come Genie, Supervisor Agent di Agent Bricks e progetti di ricerca come KARL. MemEx si collega allo stesso loop di agenti e agli stessi tool che aroll utilizza già per il Tool Calling.
Quali sono le prestazioni di MemEx nei compiti agentici aziendali?
Abbiamo eseguito valutazioni comparative dirette su 9 modelli di frontiera in cui abbiamo confrontato le chiamate ai tool strutturate in parallelo (Tool Calling) rispetto ai blocchi di codice Python (MemEx). Nessun prompt tuning, nessuna ottimizzazione per singolo compito. Abbiamo effettuato il confronto su due tipologie di lavoro agentico aziendale: lettura fondata su un ampio corpus di testo (OfficeQA) e recupero strutturato su un ampio workspace di dati relazionali eterogenei (Enterprise Structured Retrieval).
In entrambi i task, l'agente MemEx è migliore e più economico dell'agente Tool Calling!
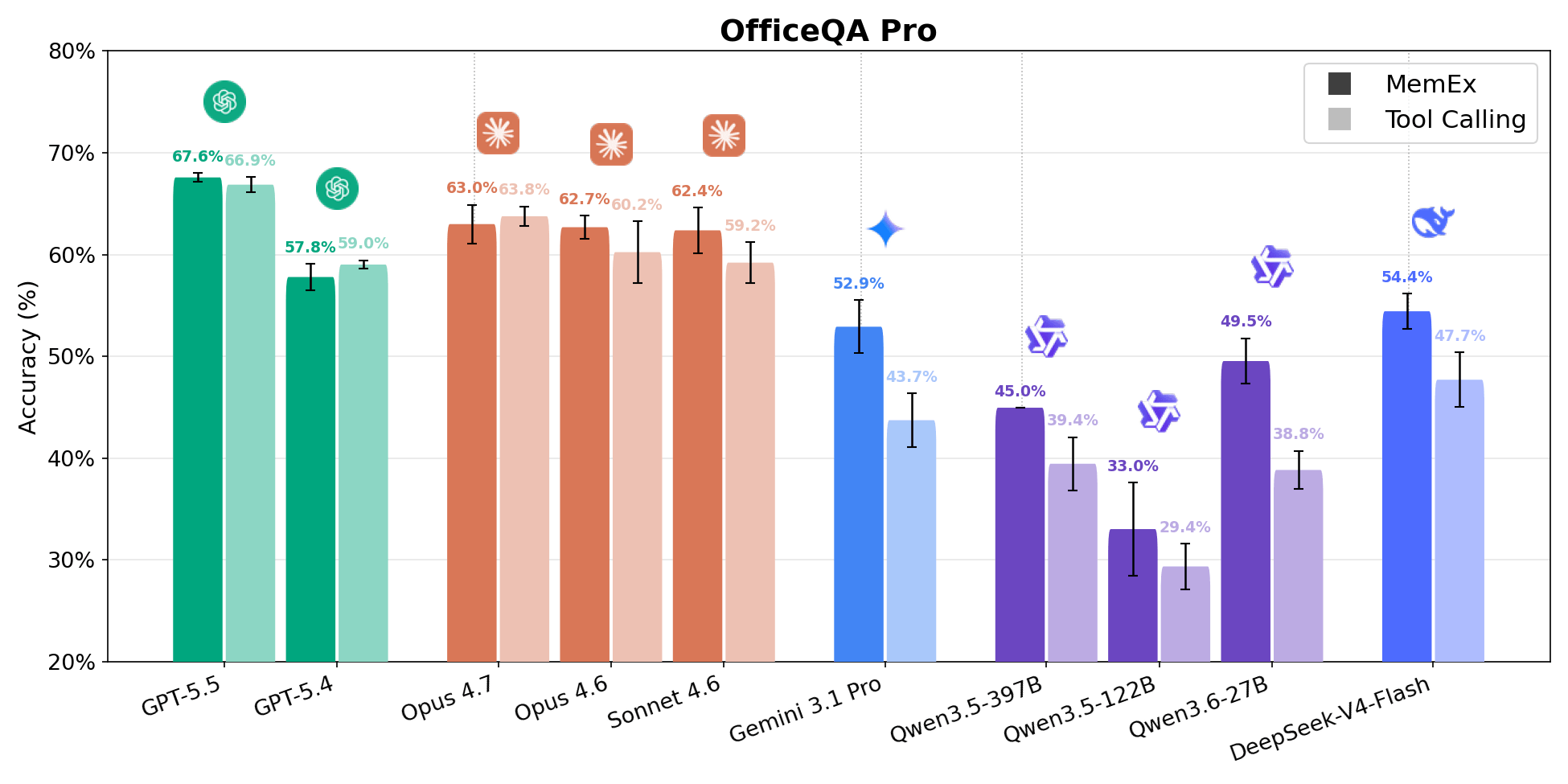
{kind=link}
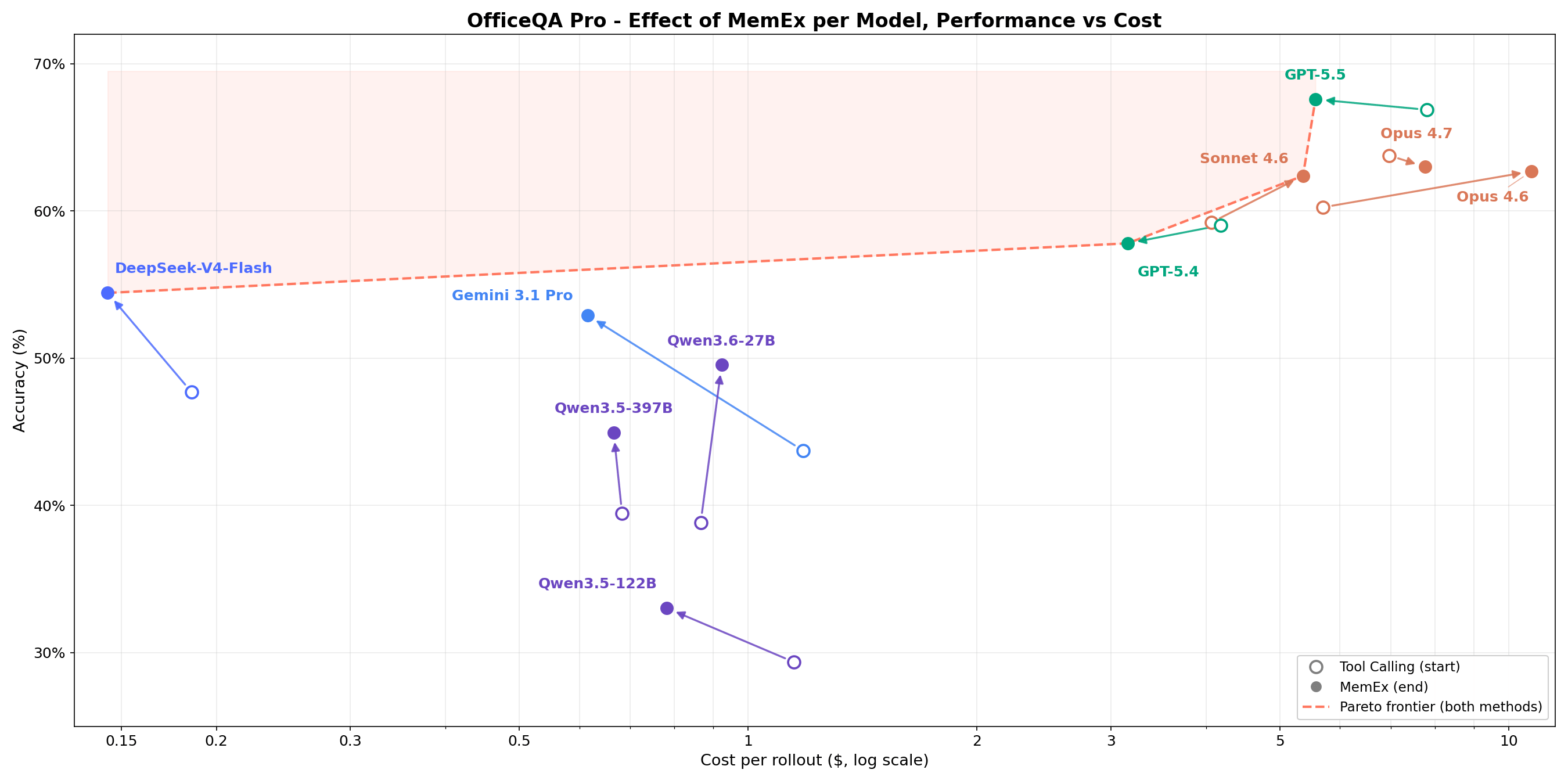
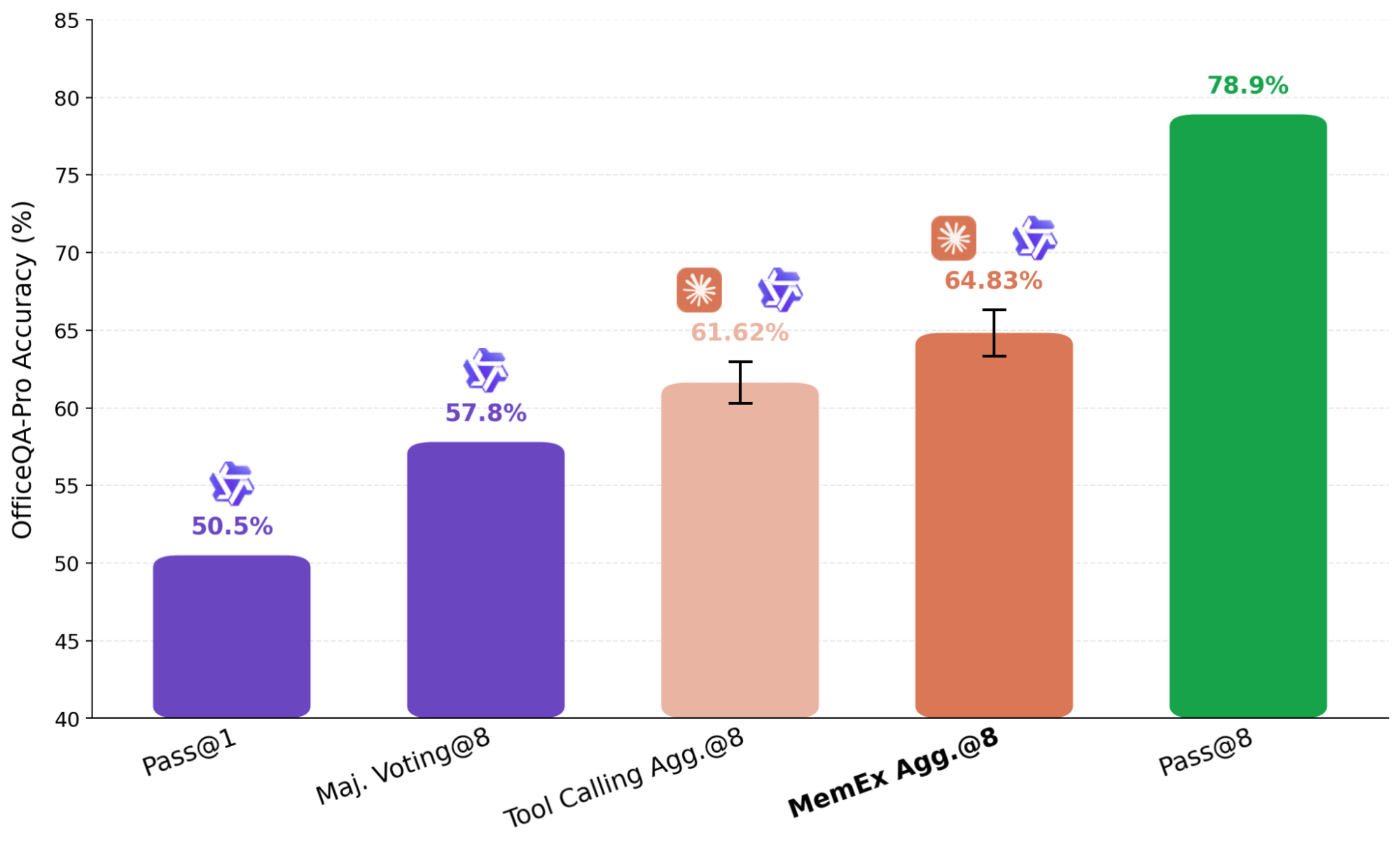
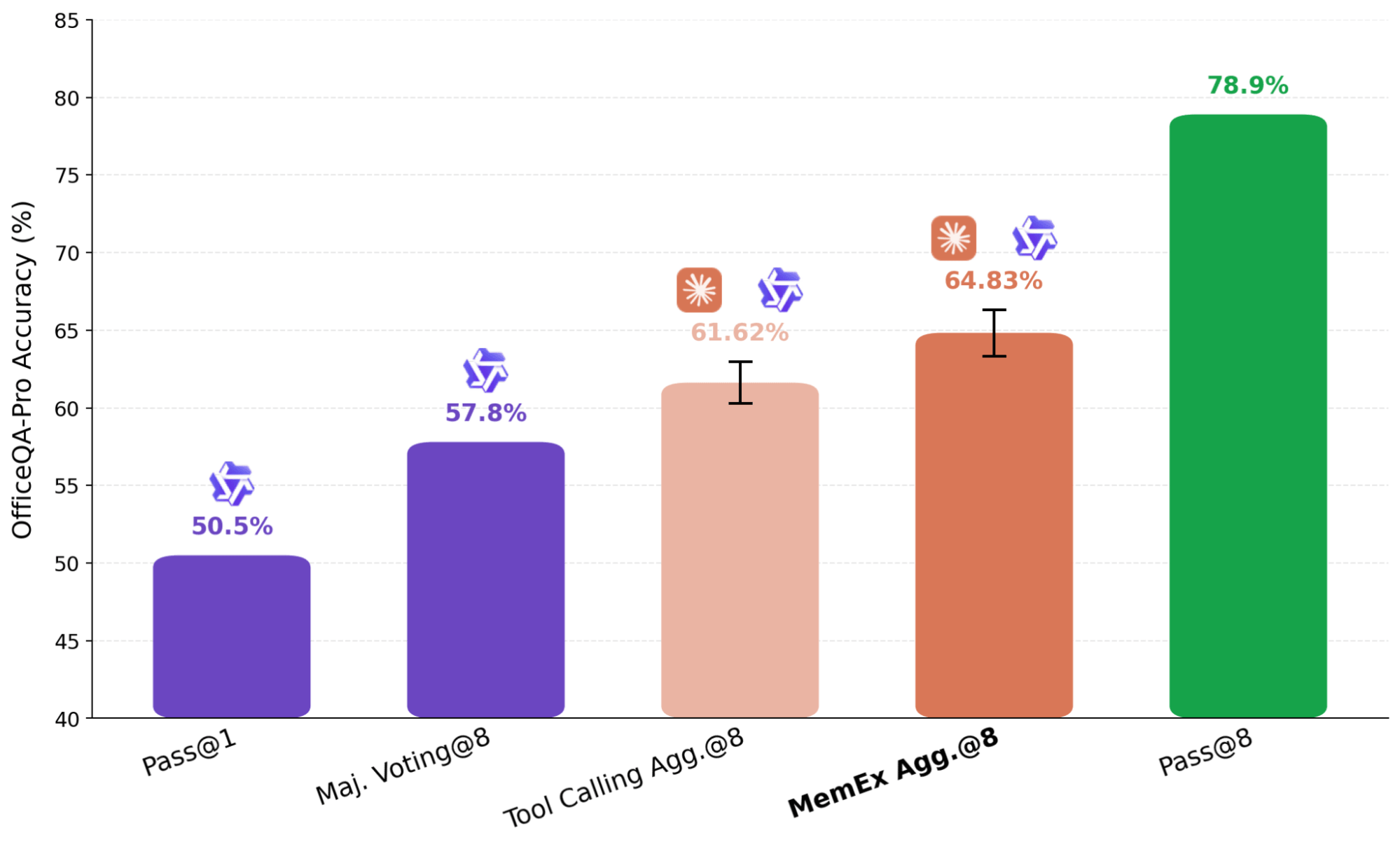
OfficeQA Pro richiede all'agente di rispondere a domande di ragionamento ancorato (grounded reasoning) sul corpus degli U.S. Treasury Bulletins, circa 89.000 pagine dal 1939 a oggi. Una domanda tipica richiede di individuare le prove in più documenti, navigare in tabelle con gerarchie nidificate e celle unite, ed eseguire calcoli sui dati recuperati. Le risposte sono valutate in base alla corrispondenza esatta. Quattro dei cinque punti sulla frontiera di Pareto costo-accuratezza sono configurazioni MemEx. Gemini 3.1 Pro MemEx è il punto di frontiera più economico a 0,62 $ per rollout (accuratezza del 52,9%), e Sonnet 4.6 MemEx si avvicina all'accuratezza di GPT-5.5 Tool Calling a circa il 70% del costo. Su nove modelli, MemEx pareggia o vince su ogni modello. I modelli di fascia media registrano i progressi maggiori, con Qwen 3.6 27B e Gemini 3.1 Pro che guadagnano circa 10 punti percentuali.
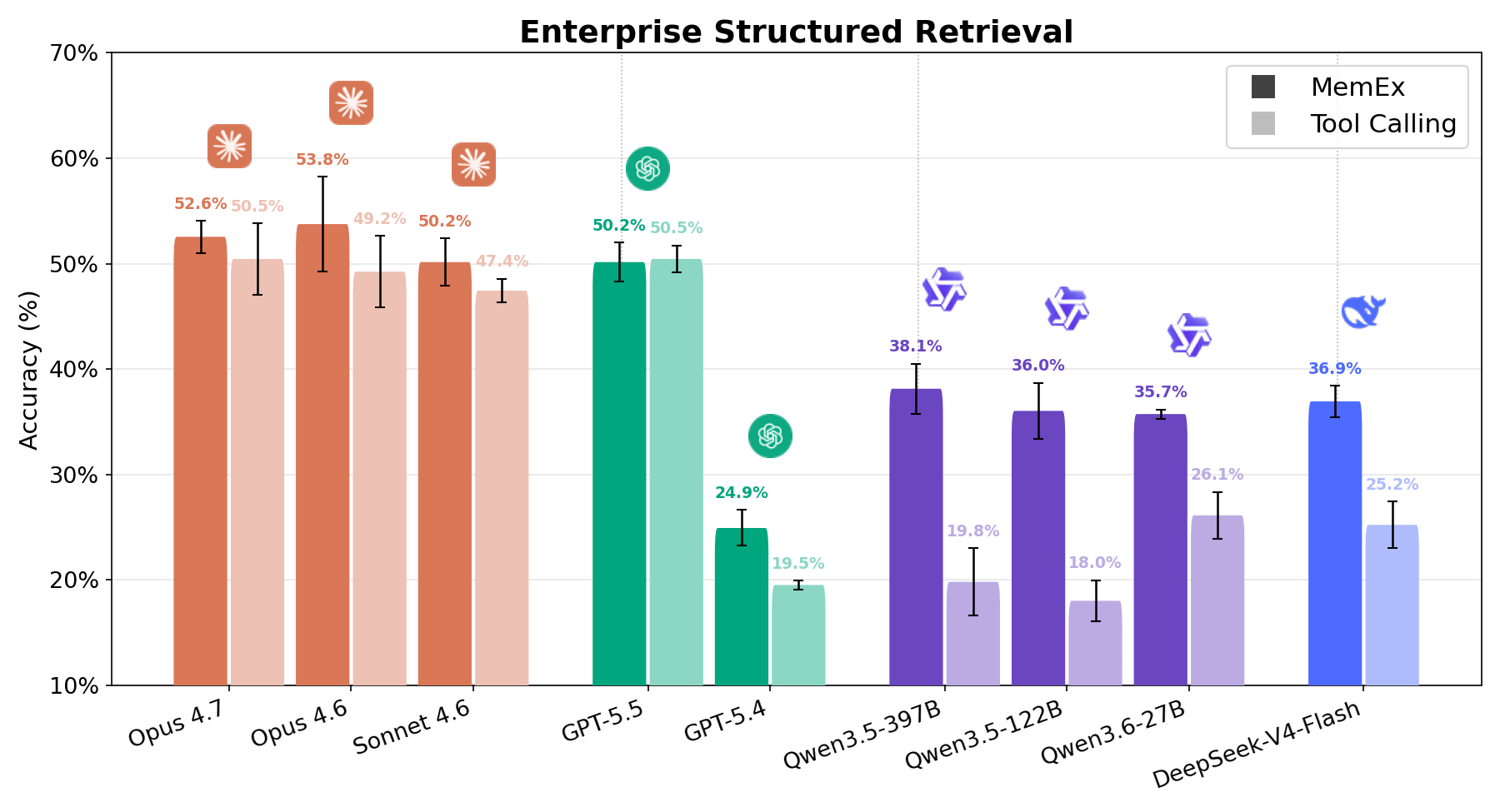
{kind=link}
Enterprise Structured Retrieval richiede all'agente di rispondere a domande in linguaggio naturale su dati relazionali aziendali. All'agente vengono forniti strumenti relativi alla scoperta dello schema (schema-discovery) e all'esecuzione di query SQL, e deve utilizzarli per eseguire il task di analisi dei dati richiesto dall'utente, solitamente con poche informazioni su dove trovare le informazioni rilevanti all'interno del variegato spazio di lavoro. Le risposte dell'agente vengono valutate rispetto alle risposte di riferimento (ground truth) utilizzando sia la validazione deterministica dei dati sia un LLM-as-a-judge. Come mostrato nelle Figure 1 e 6, ogni modello registra un forte miglioramento con MemEx, a esclusione di GPT 5.5 che mostra prestazioni equivalenti. Dal punto di vista dei costi, il risultato è altrettanto solido. Qwen 122B scende da 56 a 28 chiamate di strumenti (tool call) per rollout raddoppiando il proprio punteggio; Sonnet passa da 28 a 17; Opus da 33 a 21.1 Ciò si traduce in un dimezzamento approssimativo dei costi per la maggior parte dei modelli. Il pattern ricalca quello di OfficeQA Pro: più il task è difficile, più gli oggetti nativi e lo stato persistente dimostrano il loro valore.
Ogni confronto è stato eseguito senza prompt tuning, senza adattamento specifico per task e senza ottimizzazioni specifiche per il modello. Il ciclo dell'agente (agent loop), i prompt di sistema e gli strumenti sono identici per entrambi gli harness. L'unica differenza è lo spazio delle azioni: chiamate di strumenti strutturate in JSON/XML rispetto ai blocchi di codice Python di MemEx.
MemEx applicato alle tracce agentiche
Le traiettorie agentiche sono esse stesse oggetti ingombranti. Nel paradigma del Tool Calling, l'analisi delle traiettorie richiede generalmente di appiattirle in testo, un processo che comporta una perdita di informazioni (lossy) ed è pesante in termini di contesto, rendendo spesso infattibile l'analisi simultanea di più traiettorie. Le traiettorie possono persino estendersi su più finestre di contesto, con una compressione intermedia; come può un LLM analizzare una traccia che, per definizione, non rientra nel suo contesto? Ma una traiettoria è semplicemente un altro oggetto Python, quindi MemEx può caricarla direttamente nello scope e ragionarci sopra. Mostriamo due applicazioni: in primo luogo, un agente di audit basato su MemEx che analizza le traiettorie di Qwen 3.6-27B su OfficeQA-Pro per spiegare perché MemEx supera Tool Calling; in secondo luogo, lo scaling in fase di test (test-time scaling) su OfficeQA-Pro, con un agente MemEx che supera un agente Tool Calling equivalente.
MemEx analizza MemEx: analisi delle tracce agentiche
Per analizzare il motivo per cui il passaggio a MemEx ha portato a un aumento delle prestazioni per i modelli open source, come Qwen 3.6-27B, ci affidiamo a MemEx per ottenere una spiegazione. In particolare, istanziamo un agente di audit che acquisisce una domanda di OfficeQA, la relativa risposta di riferimento (ground-truth) e sei traiettorie di risoluzione (3 da un agente MemEx e 3 da un agente Tool Calling) direttamente nel suo scope Python, e chiede a un agente Sonnet 4.6 basato su MemEx di classificare ogni traiettoria errata lungo una tassonomia a quattro assi delle modalità di errore.
| Asse di errore | Definizione | Errori MemEx | Errori Tool Calling |
|---|---|---|---|
Source Selection | Il modello punta al documento o alla tabella errati | 32 | 45 |
Interpretation | Il modello recupera i dati corretti ma ne estrae il significato errato | 28 | 38 |
Search Strategy | Il modello si ferma troppo presto o va oltre la risposta | 6 | 15 |
Execution | Bug nel calcolo intermedio o nella formattazione dell'output finale | 3 | 6 |
Total | - | 69 | 104 |
La nostra analisi si concentra su 66 domande di OfficeQA Pro in cui non tutti e sei i tentativi erano corretti o errati, producendo 173 traiettorie. I quattro assi si dividono in due grandi gruppi:
- Errori di grounding (~83%): casi in cui il modello recupera un valore preliminare invece di una cifra rivista, interpreta male una terminologia ambigua (ad es. varianza campionaria rispetto a quella della popolazione, o precisione di arrotondamento ai "centesimi"), o estrae la colonna errata da una tabella valida.
- Errori di strategia di ricerca ed esecuzione: errore nella pianificazione della sequenza di recupero o mancata integrazione corretta dei dati recuperati nei calcoli finali.
Per gli errori di strategia di ricerca ed esecuzione, MemEx rileva che l'agente MemEx ha ottenuto una riduzione degli errori di 2 volte rispetto a Tool Calling. Questo perché, con MemEx, il recupero può confluire direttamente nelle variabili Python, consentendo al modello di evitare di copiare i valori dall'output di uno strumento alla chiamata dello strumento successivo, e più chiamate di strumenti possono essere raggruppate (batch) in un unico turno. Tool Calling non ha questa scorciatoia e deve sempre trascrivere i valori tra le chiamate, il che a volte porta a errori. Ad esempio, in una traiettoria, un valore di 3.501 da un documento recuperato è stato digitato nella chiamata successiva come 3531.
Pensiero parallelo agentico con MemEx
Un approccio comune per scalare il calcolo in fase di test (test-time computation) è il pensiero parallelo, in cui più rollout indipendenti di un task vengono aggregati in una risposta finale. Nel pensiero parallelo agentico, come l'approccio utilizzato in KARL, i riassunti dei tentativi indipendenti vengono passati a un agente aggregatore. Questa fase di riepilogo comporta una perdita di informazioni (lossy) ma è inevitabile nella configurazione standard, poiché inserire più traiettorie complete nella finestra di contesto di un modello è impraticabile. Con MemEx, possiamo invece caricare queste traiettorie come variabili di scope, aggirando completamente la rappresentazione con perdita di informazioni.
{kind=link}
Nel risultato mostrato nella Figura 7, utilizziamo Claude Sonnet 4.6 come aggregatore su otto traiettorie Qwen-3.6-27B generate in modo indipendente. Per garantire che l'aggregatore non si limiti a risolvere nuovamente il problema da solo, lo priviamo dei suoi strumenti di ricerca file, limitandolo alla verifica e alla selezione. L'agente basato su MemEx, che riceve le traiettorie complete come input, supera l'equivalente agente di Tool Calling che riceve solo i loro riassunti. In un caso, l'aggregatore di traiettorie ha rilevato un errore di duplicazione in un bollettino precedente leggendo gli output grezzi degli strumenti dalle traiettorie di input; l'aggregatore di Tool Calling non ha potuto verificare la presenza di dati duplicati poiché il suo input era limitato ai riassunti, e ha ripiegato sul voto di maggioranza sulla fonte corrotta.
Architettura di MemEx
Gli agenti di Tool Calling emettono una o più chiamate a strumenti strutturate per turno (JSON o XML), ciascuna conforme a uno schema di strumenti predefinito, nel ciclo azione-osservazione introdotto da ReAct (Yao et al., 2022). CodeAct (Wang et al., 2024) ha sostituito quel formato con un kernel Python persistente: l'agente emette codice Python arbitrario, e le variabili e le definizioni di funzione vengono mantenute da un turno all'altro. Le varianti di produzione dello stesso paradigma includono Programmatic Tool Calling (PTC) di Anthropic e Cloudflare Code Mode; PTC mantiene anche lo stato tra le richieste riutilizzando lo stesso container, mentre Code Mode no. MemEx estende questo paradigma con quattro aggiunte principali:
- Integrazione immediata (drop-in) degli strumenti con preservazione degli schemi dei parametri.
- Scope Python attivo all'avvio del rollout.
submit()tipizzati per ritorni strutturati.spawn_agent()non bloccanti per sub-agenti paralleli, generalizzando i Recursive Language Models (Zhang et al., 2025).
L'implementazione si basa su tre scelte di progettazione:
Il codice come azione, in un REPL persistente
L'azione dell'agente è un blocco di codice Python arbitrario, eseguito in un namespace che persiste tra i turni. Strumenti, oggetti di scope e risultati precedenti risiedono tutti in quel namespace. L'agente legge le osservazioni (stdout, valori di ritorno, errori), quindi scrive altro codice. Lo stesso ciclo osserva-agisci che esegue il Tool Calling esegue anche MemEx; cambia solo lo spazio delle azioni.
Integrazione immediata (drop-in) per il Tool Calling
Gli strumenti di Tool Calling esistenti vengono inseriti automaticamente come funzioni Python, inclusi gli schemi dei parametri e i metadati del tipo di ritorno. Passare un agente esistente da Tool Calling a MemEx richiede una sola modifica della configurazione.
Esecuzione indipendente dal backend
Lo stesso codice dell'agente viene eseguito in tre backend, selezionati al momento della configurazione:
- In-process per un'iterazione rapida durante la ricerca.
- Subprocess per l'isolamento durante la valutazione.
- Pool per la generazione batch ad alto throughput (dati di addestramento, rollout su larga scala).
Per le distribuzioni in produzione, il kernel può essere sostituito con una sandbox ospitata come Managed Agents di Anthropic. Stesso codice dell'agente, con isolamento del filesystem, controlli del traffico di rete in uscita e limiti di risorse gestiti dall'host.
Quali sono i prossimi passi?
MemEx sta per arrivare nelle mani dei vostri agenti. Lo stiamo distribuendo su tutti gli agenti nativi di Databricks e su Agent Bricks: se oggi sviluppate su agenti Databricks, presto potrete utilizzare MemEx.
Stiamo eseguendo il post-addestramento dei nostri modelli per lo spazio delle azioni di MemEx. MemEx stesso è il substrato: genera dati sintetici, esegue verificatori agentici e alimenta il ciclo di addestramento.
Autori: Ashutosh Baheti, Shubham Toshniwal, Arnav Singhvi, Krista Opsahl-Ong, Sean Kulinski, Sam Havens, Jonathan Li, Marco Cusumano-Towner, Jonathan Chang, Wen Sun, Alexander Trott, Jonathan Frankle, Xing Chen, Matei Zaharia
1 In MemEx, le chiamate agli strumenti sono blocchi di codice Python che possono includere analisi dei dati o altri strumenti chiamati come funzioni asincrone.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.