Scalabilità della memoria per agenti AI
La scalabilità dell'inferenza ha portato gli LLM al punto in cui possono ragionare attraverso la maggior parte delle situazioni pratiche, a condizione che abbiano il contesto giusto. Per molti agenti del mondo reale, il collo di bottiglia non è più la capacità di ragionamento, ma l'ancoraggio dell'agente alle informazioni corrette: fornire al modello ciò di cui ha bisogno per il compito da svolgere.
Ciò suggerisce un nuovo asse per la progettazione degli agenti. Invece di concentrarsi esclusivamente su modelli più potenti o prompt migliori, possiamo chiederci: l'agente migliora man mano che accumula più informazioni? Chiamiamo questa scalabilità della memoria: la proprietà per cui le prestazioni dell'agente migliorano con la quantità di conversazioni passate, feedback degli utenti, traiettorie di interazione (sia riuscite che fallite) e contesto aziendale memorizzati nella sua memoria. L'effetto è particolarmente pronunciato in contesti aziendali, dove la conoscenza tribale è abbondante e un singolo agente serve molti utenti.
Ma questo non è ovvio a priori. Più memoria non rende automaticamente un agente migliore: tracce di bassa qualità possono insegnare lezioni sbagliate e il recupero diventa più difficile man mano che il deposito cresce. La domanda centrale è se gli agenti possano utilizzare memorie più grandi in modo produttivo piuttosto che semplicemente accumularle.
Abbiamo compiuto i primi passi in questa direzione in Databricks attraverso ALHF e MemAlign, che adattano il comportamento dell'agente in base al feedback umano, e l'Instructed Retriever, che consente agli agenti di ricerca di tradurre istruzioni complesse in linguaggio naturale e schemi di origine della conoscenza in query di ricerca precise e strutturate. Insieme, questi sistemi dimostrano che gli agenti possono essere più utili attraverso la memoria persistente. Questo post presenta i risultati sperimentali che dimostrano il comportamento di scalabilità della memoria, discute l'infrastruttura necessaria per supportarla in produzione e fornisce una visione lungimirante degli agenti basati sulla memoria.
Cos'è la Scalabilità della Memoria?
La scalabilità della memoria è la proprietà per cui le prestazioni di un agente migliorano man mano che la sua memoria esterna cresce. Qui "memoria" si riferisce a un deposito persistente di informazioni con cui l'agente può interagire al momento dell'inferenza, distinto dai pesi del modello o dalla finestra di contesto corrente.
Ciò rende la scalabilità della memoria un asse distinto e complementare sia alla scalabilità parametrica che alla scalabilità al momento dell'inferenza, colmando lacune nella conoscenza del dominio e nell'ancoraggio che né la dimensione del modello né la capacità di ragionamento possono chiudere da sole. I miglioramenti dovuti alla scalabilità della memoria non si limitano alla qualità delle risposte. Quando un agente ha memorizzato gli schemi pertinenti, le regole del dominio o le azioni passate riuscite per un ambiente, può saltare l'esplorazione ridondante e risolvere le query più velocemente. Nei nostri esperimenti, osserviamo la scalabilità sia in termini di accuratezza che di efficienza.
Relazione con l'apprendimento continuo
L'apprendimento continuo si concentra tipicamente sull'aggiornamento dei parametri del modello nel tempo, il che funziona bene in contesti limitati ma diventa computazionalmente costoso e fragile con molti utenti concorrenti, agenti e progetti in rapida evoluzione. La scalabilità della memoria pone una domanda diversa: un agente con migliaia di utenti si comporta meglio di uno con un singolo utente? Espandendo lo stato esterno condiviso di un agente mantenendo i pesi dell'LLM congelati, la risposta può essere sì: un modello di flusso di lavoro appreso da un utente può essere recuperato e applicato immediatamente a un altro, senza alcun riaddestramento. Questa è una proprietà che l'apprendimento continuo, focalizzato com'è sugli aggiornamenti dei parametri del modello di un singolo utente, non è mai stato progettato per fornire.
Relazione con il contesto lungo
Le ampie finestre di contesto potrebbero sembrare un sostituto della memoria, ma affrontano problemi diversi. Impacchettare milioni di token grezzi in un prompt aumenta la latenza, aumenta i costi di calcolo e degrada la qualità del ragionamento poiché i token irrilevanti competono per l'attenzione. La scalabilità della memoria si basa invece sul recupero selettivo: decidere non solo quanta contesto includere, ma cosa includere, mostrando solo le informazioni ad alto segnale pertinenti al compito corrente.
Tipi di Memoria
Non tutte le memorie servono allo stesso scopo. Due distinzioni sono importanti in pratica:
Episodica vs. semantica. Le memorie episodiche sono registrazioni grezze di interazioni passate: log di conversazione, traiettorie di chiamata di strumenti, feedback degli utenti. Le memorie semantiche sono competenze e fatti generalizzati distillati da tali interazioni (ad esempio, "gli utenti in questo spazio intendono sempre il trimestre fiscale quando dicono 'trimestre'"). Ciascun tipo richiede diverse strategie di archiviazione, elaborazione e recupero: memorie episodiche per il recupero diretto e memorie semantiche distillate da un LLM per un'ampia corrispondenza di pattern.
Personale vs. organizzativa. Alcune memorie sono specifiche per le preferenze e i flussi di lavoro di un singolo utente; altre rappresentano la conoscenza organizzativa condivisa: convenzioni di denominazione, query comuni, regole aziendali. Il sistema di memoria deve definire in modo appropriato l'ambito del recupero e degli aggiornamenti: mostrare la conoscenza organizzativa in modo ampio mantenendo privato il contesto individuale, rispettando permessi e ACL.
Esperimenti: MemAlign su Genie Space
MemAlign è la nostra esplorazione di come potrebbe essere un semplice framework di memoria per agenti AI. Memorizza le interazioni passate come memorie episodiche, utilizza un LLM per distillarle in regole e pattern generalizzati (memorie semantiche) e recupera le voci più pertinenti al momento dell'inferenza per guidare l'agente. Per i dettagli sul framework, vedere il nostro precedente post sul blog.
Abbiamo testato MemAlign su Databricks Genie Spaces, un'interfaccia in linguaggio naturale in cui gli utenti aziendali pongono domande sui dati in linguaggio naturale e ricevono risposte basate su SQL. Un esempio della query e della risposta del compito è fornito di seguito
Il nostro obiettivo è misurare come le prestazioni dell'agente scalano man mano che gli forniamo più memoria, utilizzando due fonti di dati: esempi curati (etichettati) e log di conversazione utente grezzi (non etichettati).
Scalabilità con dati etichettati
Abbiamo valutato MemAlign su domande non viste distribuite su 10 spazi Genie, aggiungendo incrementalmente frammenti di esempi di addestramento annotati alla memoria dell'agente. La nostra baseline è un agente che utilizza istruzioni Genie curate da esperti (schemi di tabella scritti manualmente, regole del dominio ed esempi few-shot).
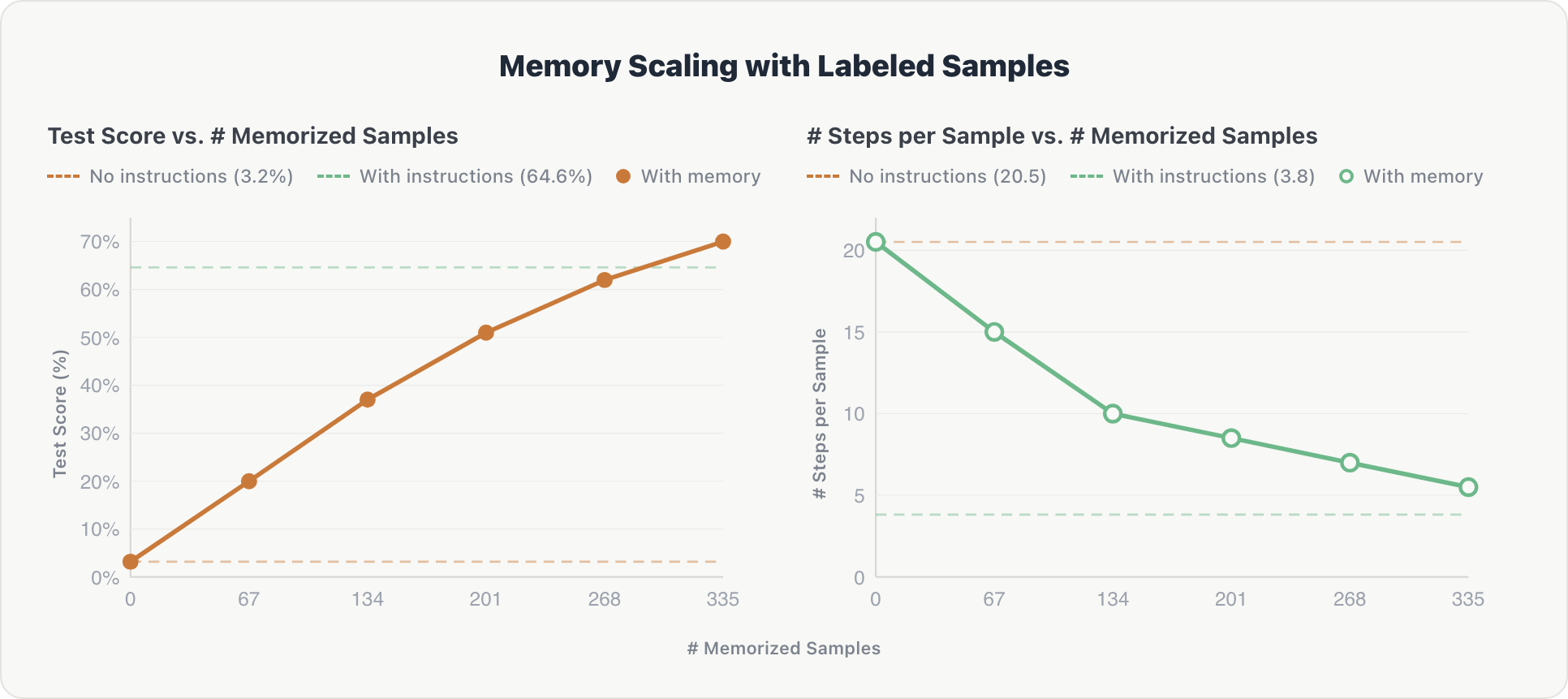
I risultati mostrano una scalabilità costante lungo entrambe le dimensioni:
Accuratezza. I punteggi dei test sono aumentati costantemente con ogni frammento di memoria aggiuntivo, passando da quasi zero al 70%, superando infine la baseline curata da esperti di circa il 5%. Dopo ispezione, i dati etichettati manualmente si sono rivelati più completi e quindi più utili rispetto agli schemi di tabella e alle regole del dominio scritti manualmente.
Efficienza. Il numero medio di passaggi di ragionamento per esempio è diminuito da circa 20 a circa 5 man mano che la memoria cresceva. L'agente ha imparato a recuperare il contesto pertinente direttamente anziché esplorare il database da zero, avvicinandosi all'efficienza delle istruzioni codificate (circa 3,8 passaggi).
L'effetto è cumulativo: poiché i campioni memorizzati coprono 10 diversi spazi Genie, ogni frammento contribuisce con informazioni cross-dominio che si basano sulla conoscenza pregressa.
Scalabilità con log utente non etichettati
La memoria può scalare con dati rumorosi del mondo reale? Per scoprirlo, abbiamo eseguito MemAlign in uno spazio Genie attivo e gli abbiamo fornito log di conversazione utente storici senza risposte di riferimento. Un giudice LLM ha filtrato questi log per verificarne l'utilità, e solo quelli di alta qualità sono stati memorizzati.
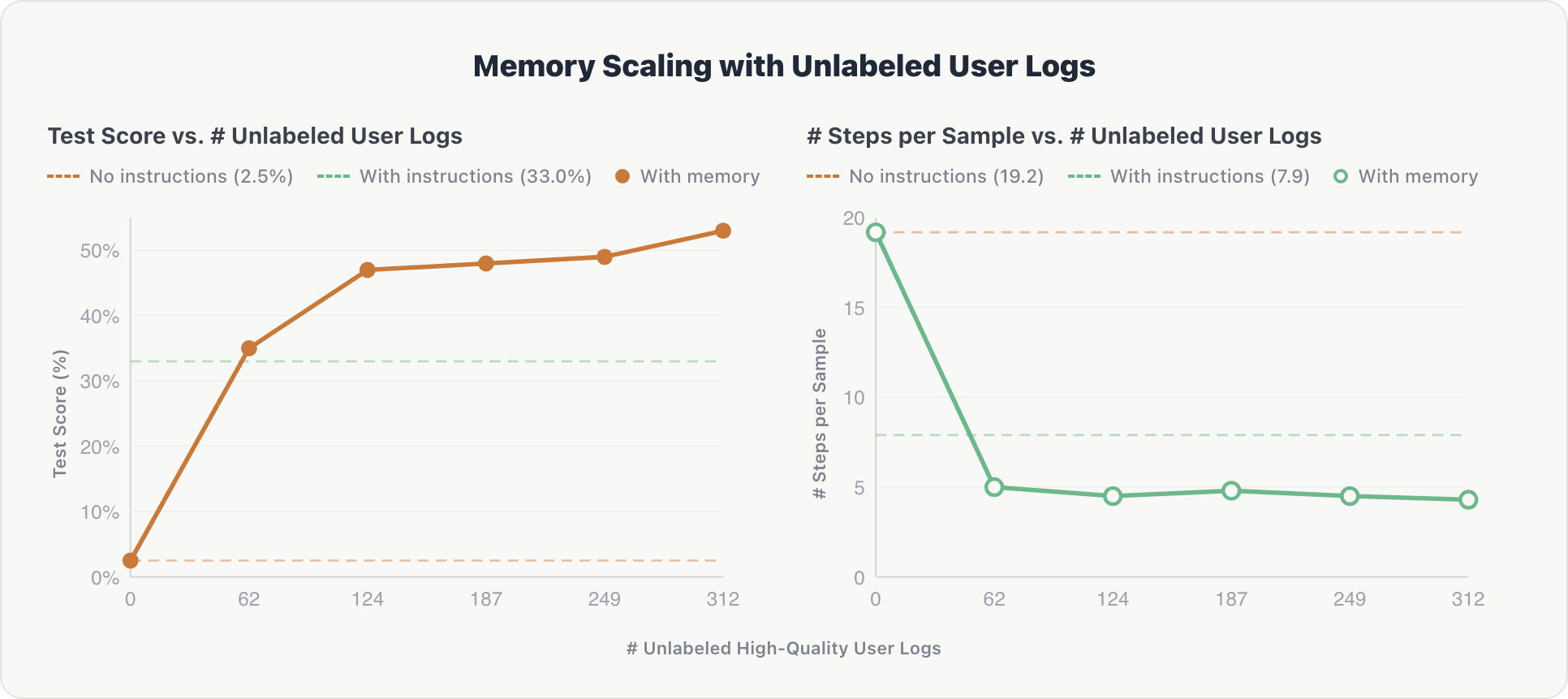
La curva di scalabilità segue un modello simile ed è più ripida all'inizio:
Accuratezza. L'agente ha mostrato un netto guadagno iniziale. Dopo il primo frammento di log, ha estratto informazioni chiave su tabelle pertinenti e preferenze utente implicite. Le prestazioni sono aumentate dal 2,5% a oltre il 50%, superando la baseline curata da esperti (33,0%) dopo soli 62 record di log.
Efficienza. I passaggi di ragionamento sono diminuiti da circa 19 a circa 4,3 dopo il primo frammento e sono rimasti stabili. L'agente ha interiorizzato presto lo schema dello spazio ed evitato esplorazioni ridondanti nelle query successive.
Il punto chiave: le interazioni utente non curate, filtrate solo da un giudice automatizzato e senza riferimento, possono sostituire le istruzioni di dominio ingegnerizzate a mano, costose e dispendiose in termini di tempo. Ciò indica anche agenti che migliorano continuamente dall'uso normale e possono scalare oltre i limiti dell'annotazione umana.
Esperimenti: Deposito di Conoscenza Organizzativa
Gli esperimenti sopra mostrano come avviene lo scaling della memoria con le interazioni dell'utente. Ma le aziende hanno anche conoscenze esistenti che precedono qualsiasi interazione dell'utente: schemi di tabelle, query di dashboard, glossari aziendali e documentazione interna. Abbiamo testato se il pre-calcolo di questa conoscenza organizzativa in un archivio di memoria strutturato potesse migliorare le prestazioni dell'agente.
Abbiamo valutato questo archivio di conoscenza su un benchmark interno di ricerca dati e su PMBench, che testa la ricerca esaustiva di fatti su documenti interni misti come note di riunioni di product manager e materiali di pianificazione.
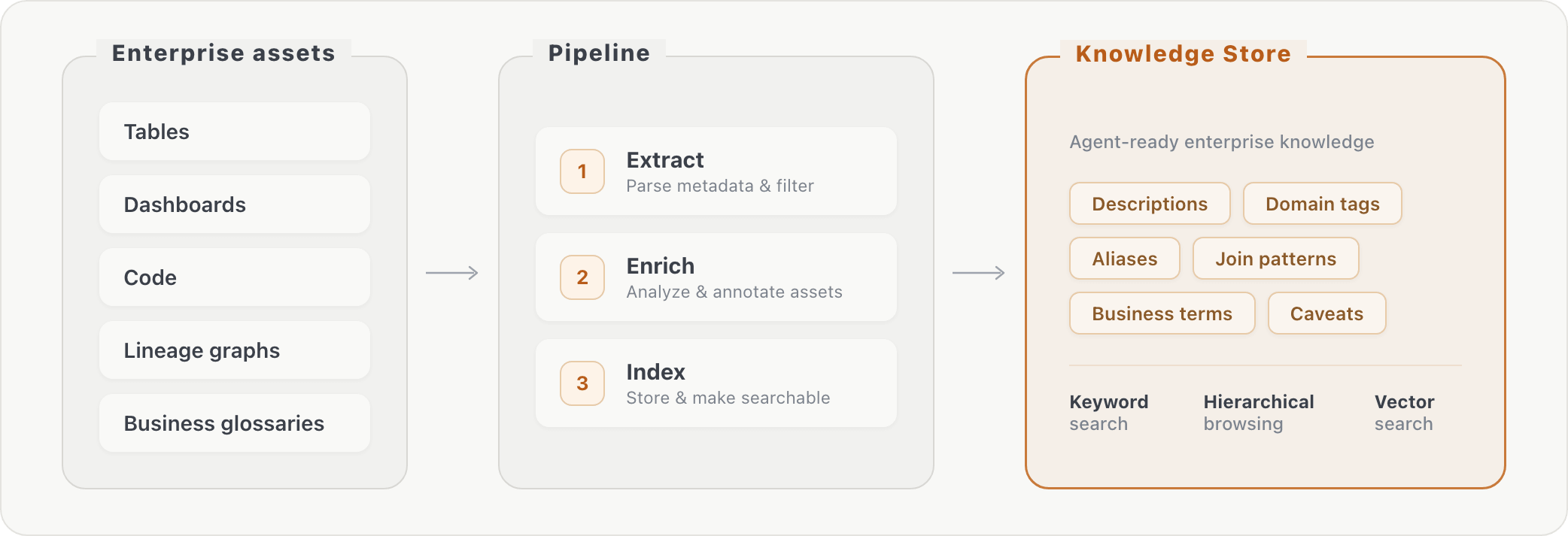
La nostra pipeline elabora i metadati grezzi del database in conoscenza recuperabile in tre fasi: (1) estrazione di informazioni sugli asset, (2) arricchimento degli asset tramite trasformazioni aggiuntive e (3) indicizzazione del contenuto arricchito. Al momento della query, l'agente può cercare il contesto aziendale tramite ricerca per parole chiave o navigazione gerarchica. Questo colma il divario tra come gli utenti aziendali formulano le domande ("consumo AI") e come i dati sono effettivamente archiviati (nomi di colonne specifici in tabelle specifiche).
L'aggiunta dell'archivio di conoscenza ha migliorato l'accuratezza di circa il 10% su entrambi i benchmark valutati. I guadagni si sono concentrati su domande che richiedevano bridging di vocabolario, join di tabelle e conoscenza a livello di colonna, ovvero informazioni che l'agente non avrebbe potuto scoprire solo tramite l'esplorazione dello schema.
Infrastruttura per lo Scaling della Memoria
Lo scaling della memoria nelle implementazioni aziendali richiede un'infrastruttura robusta oltre un semplice archivio vettoriale. Di seguito, discuteremo tre sfide chiave che questa infrastruttura deve affrontare: archiviazione scalabile, gestione della memoria e governance.
Archiviazione Scalabile
La memoria più semplice è il file system: file markdown in cartelle gerarchiche, navigati e cercati con strumenti shell standard. La memoria basata su file funziona bene su piccola scala e per utenti individuali, ma manca di indicizzazione, query strutturate e ricerca di similarità efficiente. Man mano che la memoria cresce a migliaia di voci tra molti utenti, il recupero degrada e la governance diventa difficile da applicare.
Archivi dati dedicati sono il passo successivo naturale. Database vettoriali standalone gestiscono bene la ricerca semantica ma mancano di capacità relazionali come join e filtraggio. I moderni sistemi basati su PostgreSQL offrono un'alternativa più unificata: supportano nativamente query strutturate, ricerca full-text e ricerca di similarità vettoriale in un unico motore.
Varianti serverless di questa architettura che separano l'archiviazione dal calcolo e forniscono archiviazione durevole e a basso costo sono una scelta naturale. Abbiamo utilizzato Lakebase, costruito sul motore PostgreSQL serverless di Neon, grazie al suo costo scalabile a zero e al supporto sia per la ricerca vettoriale che esatta. Il branching nativo del database semplifica anche il ciclo di sviluppo: gli ingegneri possono creare una copia dello stato della memoria dell'agente per i test senza influire sulla produzione.
Gestione della Memoria
La sola archiviazione scalabile non è sufficiente. Un sistema di memoria deve anche gestire i suoi contenuti:
- Bootstrapping. I nuovi agenti soffrono di problemi di cold-start. L'ingestione di asset aziendali esistenti (wiki, documentazione, guide interne) tramite parsing ed estrazione di documenti fornisce una base di memoria iniziale che può alleviare alcuni di questi problemi, come dimostrato dai nostri esperimenti sull'archivio di conoscenza organizzativa.
- Distillazione. Le memorie episodiche grezze sono utili per il recupero diretto ma diventano costose da archiviare e cercare su larga scala. Distillarle periodicamente in memorie semantiche (regole e pattern compressi) mantiene l'archivio di memoria trattabile e fornisce insight generalizzabili all'agente, che potrebbero non essere evidenti dalla sola memoria episodica.
- Consolidamento. Man mano che la memoria cresce, è importante mantenere il sistema coerente, compatto e aggiornato. Ciò richiede pipeline che rimuovono duplicati, eliminano informazioni obsolete e risolvono conflitti tra voci vecchie e nuove.
Sicurezza
La memoria introduce requisiti di governance che non esistono per gli agenti stateless. Man mano che gli agenti accumulano conoscenze profondamente contestuali, comprese le preferenze dell'utente, i flussi di lavoro proprietari e i pattern di dati interni, gli stessi principi di governance che si applicano ai dati aziendali devono estendersi alla memoria dell'agente.
I controlli di accesso devono essere consapevoli dell'identità: le singole memorie dovrebbero rimanere private, mentre la conoscenza organizzativa può essere condivisa entro limiti controllati dall'accesso. Questo si mappa naturalmente al tipo di permessi granulari che piattaforme come Unity Catalog già applicano per gli asset di dati, come la sicurezza a livello di riga, l'oscuramento delle colonne e il controllo degli accessi basato sugli attributi.
Estendere questi controlli alle voci di memoria significa che un agente che recupera contesto per un utente non può inavvertitamente mostrare le interazioni private di un altro utente.
Oltre al controllo degli accessi, sono importanti la data lineage e l'auditabilità. Quando il comportamento di un agente è plasmato dalla sua memoria, i team devono tracciare quali memorie hanno influenzato una determinata risposta e quando tali memorie sono state create o aggiornate. I requisiti di conformità e normativi, in particolare nei settori regolamentati, richiedono che gli archivi di memoria supportino le stesse garanzie di osservabilità dei dati sottostanti: tracciamento completo della lineage, policy di conservazione e la possibilità di eliminare voci specifiche su richiesta.
Garantire che la memoria giusta raggiunga l'utente giusto, e solo quell'utente, è un problema di progettazione centrale su larga scala.
Cosa Ostacola
Ogni asse di scaling incontra alla fine il proprio collo di bottiglia. Lo scaling parametrico è limitato dalla disponibilità di dati di addestramento di alta qualità. Lo scaling al momento dell'inferenza può degenerare in un eccesso di riflessione, dove catene di ragionamento più lunghe aggiungono costi senza aggiungere segnale, degradando infine le prestazioni all'aumentare della lunghezza della sequenza. Lo scaling della memoria ha limiti analoghi: problemi di qualità, ambito e accesso.
La qualità della memoria è difficile da mantenere. Alcune memorie sono sbagliate fin dall'inizio; altre diventano sbagliate nel tempo. Un agente stateless commette errori isolati, ma un agente dotato di memoria può trasformare un errore in uno ricorrente memorizzandolo e recuperandolo in seguito come prova. Abbiamo visto agenti citare notebook di esecuzioni precedenti che erano a loro volta errati, quindi riutilizzare quei risultati con ancora più fiducia. La staleness è più sottile: un agente che ha appreso lo schema del trimestre precedente potrebbe continuare a interrogare tabelle che nel frattempo sono state rinominate o eliminate. Il filtraggio all'ingestione aiuta, ma i sistemi di produzione necessitano di più del filtraggio. Necessitano di provenienza, stime di confidenza, segnali di freschezza e rivalidazione periodica.
La governance deve estendersi alla distillazione. Scalare la memoria in un'organizzazione richiede la distillazione delle interazioni ripetute in memorie semantiche riutilizzabili. Ma l'astrazione non rimuove la sensibilità. Una memoria come "per l'azienda Y, unisci le tabelle CRM, market-intelligence e partnership" può sembrare innocua pur rivelando un interesse di acquisizione confidenziale. La sfida è rendere la memoria ampiamente utile senza trasformare pattern privati in conoscenza condivisa. I controlli di accesso e le etichette di sensibilità devono sopravvivere alla distillazione, non solo all'ingestione.
Memorie utili potrebbero rimanere irraggiungibili. Anche se la memoria è accurata e aggiornata, l'agente deve ancora scoprire che esiste. Il recupero è intrinsecamente metacognitivo: l'agente deve decidere cosa chiedere al suo archivio di memoria prima di sapere cosa c'è dentro. Quando non riesce ad anticipare che una memoria pertinente potrebbe aiutare, non emette mai la query corretta e ricade in un'esplorazione lenta e ridondante. In pratica, il divario tra conoscenza archiviata e conoscenza accessibile potrebbe essere il principale limite allo scaling della memoria.
Queste non sono argomentazioni contro lo scaling della memoria. Sono i problemi di ricerca che devono ancora essere risolti per rendere robusto lo scaling della memoria. Il problema centrale non è solo archiviare più cronologia; è insegnare all'agente come trovare la memoria giusta, come usarla in modo appropriato e come mantenerla aggiornata e correttamente definita.
Uno Sguardo al Futuro: L'Agente come Memoria
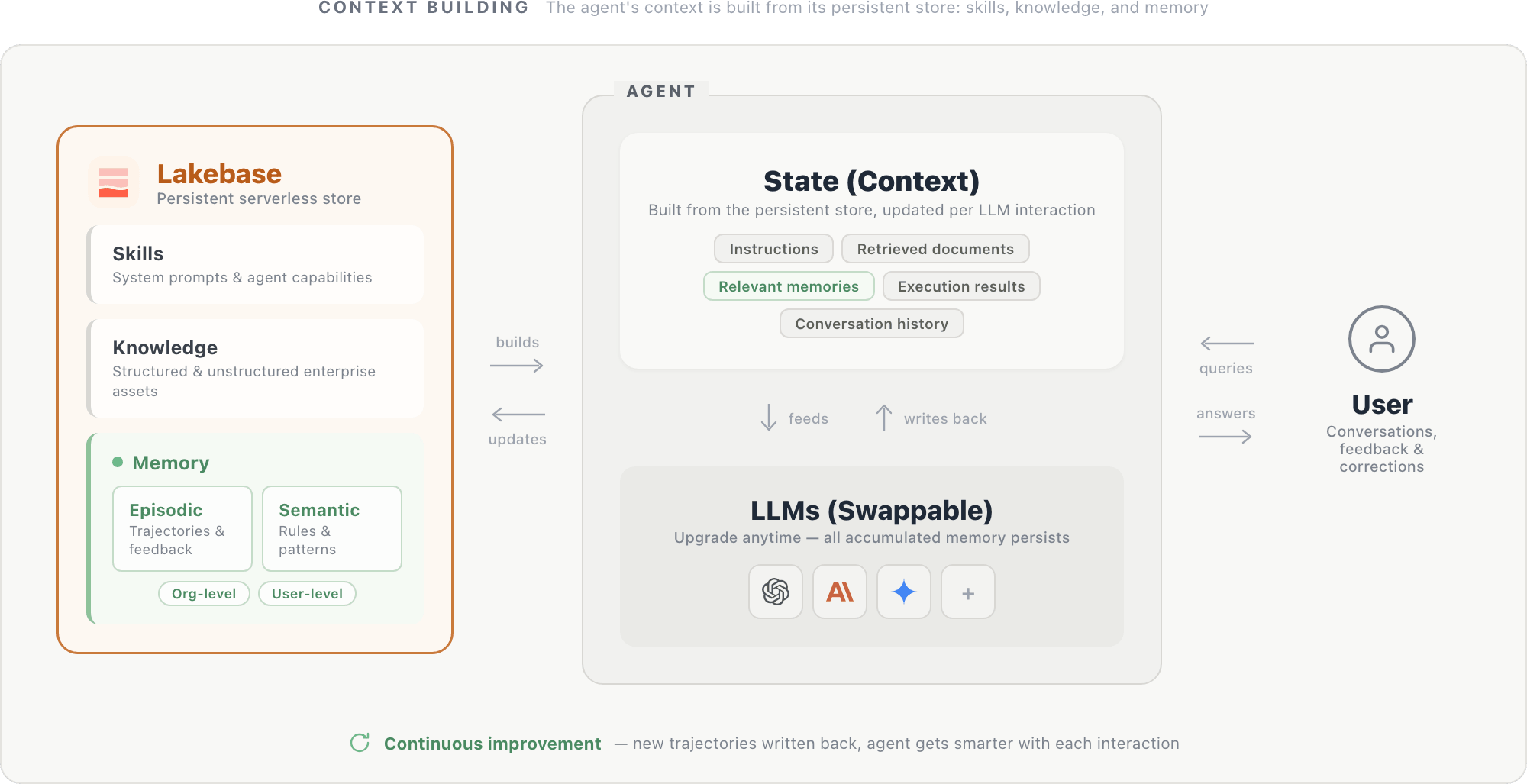
Gli esperimenti e l'infrastruttura sopra descritti indicano un pattern di progettazione naturale: un agente la cui identità risiede nella sua memoria, non nei suoi pesi del modello.
In questo design, il contesto di un agente è costruito da un archivio persistente ospitato in un database serverless come Lakebase. L'archivio contiene tre componenti: prompt di sistema e capacità dell'agente (skill), asset aziendali strutturati e non strutturati (conoscenza) e memorie episodiche e semantiche definite a livello di organizzazione e utente. Insieme, questi componenti formano lo stato dell'agente: istruzioni, documenti recuperati, memorie pertinenti, risultati di esecuzione (da query SQL, chiamate API e altri strumenti) e cronologia delle conversazioni. Questo stato viene fornito all'LLM ad ogni passaggio e aggiornato dopo ogni interazione.
L'LLM stesso è un motore di ragionamento sostituibile: l'aggiornamento a un modello più recente è semplice, poiché il nuovo modello legge dallo stesso archivio persistente e beneficia immediatamente di tutto il contesto accumulato.
Poiché i modelli di base convergono nelle capacità, il fattore distintivo per gli agenti enterprise sarà sempre più la memoria che hanno accumulato piuttosto che il modello che richiamano. Ipoteticamente, un modello più piccolo con un ricco archivio di memoria può superare un modello più grande con meno memoria — in tal caso, investire nell'infrastruttura di memoria potrebbe generare maggiori rendimenti rispetto allo scaling dei parametri del modello. La conoscenza del dominio, le preferenze dell'utente e i pattern operativi specifici della tua organizzazione non sono presenti in alcun modello di base. Possono essere costruiti solo attraverso l'uso e, a differenza delle capacità del modello, sono unici per ogni deployment.
Conclusione
Proponiamo il Memory Scaling, in cui le prestazioni di un agente migliorano man mano che accumula più esperienza attraverso l'interazione dell'utente e il contesto aziendale nella memoria. I nostri esperimenti iniziali dimostrano che sia l'accuratezza che l'efficienza scalano con la quantità di informazioni memorizzate nella memoria esterna.
Realizzare ciò in produzione richiede sistemi di archiviazione che unifichino la ricerca strutturata e non strutturata, pipeline di gestione che mantengano la memoria coerente e controlli di governance che definiscano correttamente l'ambito di accesso. Questi sono problemi risolvibili con la tecnologia attuale. Il vantaggio è rappresentato da agenti che migliorano veramente con l'uso continuato.
Il lavoro rimanente è sostanziale: la memoria deve rimanere accurata, aggiornata e accessibile man mano che cresce. Ma è proprio per questo che il memory scaling è interessante. Apre un'agenda concreta di sistemi e ricerca per la creazione di agenti che migliorano con l'uso continuato in modi specifici per ogni organizzazione e problema.
Autori: Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
Vorremmo ringraziare Kenneth Choi, Sam Havens, Andy Zhang, Ziyi Yang, Ashutosh Baheti, Sean Kulinski, Alexander Trott, Will Tipton, Gavin Peng, Rishabh Singh e Patrick Wendell per il loro prezioso feedback durante il progetto.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.