Original Blog : Fine-Tuning Large Language Models with Hugging Face and DeepSpeed
翻訳: junichi.maruyama
ChatGPTのセンセーショナルなリリースを受け、大規模言語モデル(LLM)が現在脚光を浴びています。多くの人が、このようなモデルを自分のアプリケーションでどのように活用できるかを考えています。しかし、これは変換器ベースのモデルのいくつかの進歩の一つに過ぎず、他の多くのモデルは、チャットだけでなく、翻訳、分類、要約などのタスクでオープンかつ容易に利用できます。
以前のブログでは、人気のあるHugging Face トランスフォーマーライブラリを通じて、Databricks上でこれらのモデルにアクセスするための基本的な方法を説明しました。T5やBERT のような、あらかじめ訓練された既製のLLMは、追加のデータや訓練なしで、実世界のさまざまな問題に対してうまく機能します。しかし、特定のタスクでより良いパフォーマンスを発揮するために、これらのモデルを「Fine-Tuning」することが価値ある、あるいは不可欠な場合があります。
このブログでは、T5�言語モデルファミリーを最小サイズから最大サイズまで簡単にFine-Tuningし、シンプルなユースケース(多くの製品レビューから製品レビューの概要を構築する)向けに特化させる方法を探ります。また、DatabricksのHugging Faceを使用し、MLflow integration.も行います。
また、MicrosoftのDeepSpeed を導入し、非常に大きな言語モデルのFine-Tuningを加速させる予定です。110億のパラメータを持つモデルでも、Databricks上でFine-Tuningするのは難しいことではありません-それが必要なことであれば!
課題: 製品レビューの要約
あなたがカメラ製品を販売するEコマースサイトを運営しているとしましょう。ユーザーは商品に対してレビューを残しています。あなたは、ユーザーが100のレビューを吟味するのではなく、商品に対するすべてのレビューを1つの要約に凝縮できたらいいと考えています。あなたは、何十万ものレビューと、ユーザーが提供した見出し(レビューの「要約」のようなもの)を収集し、LLMを使ってこれらの製品要約を作成したいと考えています。
この例では、そのようなデータセットの代用として、Amazonの顧客による1億3000万件の商品レビューを含む、Amazon Customer Reviewデータセットを使用することにします。ここで注目すべきは、レビューのテキストと見出し��、そして当然ながら「カメラ」カテゴリのものだけである。
このデータセットのフリーテキストは、完全にきれいなものではありません。あなたのeコマースサイトが保持する素敵なキュレーションされたデータセットを模倣するために、データをロードし、いくつかの基本的なクリーニング(詳細は付属のノートブックを参照)を適用し、Deltaテーブルとして記述します。ここでは、レビューの長さを(やや任意に)100トークンに制限しています。これは、非常に長いシーケンスがいくつかあるとメモリ不足のエラーが発生するためです。短い配列の方がFine-Tuningが早く、もちろんある程度の精度は犠牲になりますが、レビューテキストの一部は省略されています。
...
def clean_text(text, max_tokens):
...
approx_tokens = 0
cleaned = ""
for fragment in split_regex.split(text):
approx_tokens += len(fragment.split(" "))
if (approx_tokens > max_tokens):
break
cleaned += fragment
return cleaned.strip()
@udf('string')
def clean_review_udf(review):
return clean_text(review, 100)
...
camera_reviews_df.select("product_id", "review_body", "review_headline").\
sample(0.1, seed=42).\
withColumn("review_body", clean_review_udf("review_body")).\
withColumn("review_headline", clean_summary_udf("review_headline")).\
filter("LENGTH(review_body) > 0 AND LENGTH(review_headline) > 0").\
write.format("delta").save("/tmp/.../review/cleaned")
| review_body | review_headline |
|---|
| Great camera for the price. | Five Stars |
| im not happy, the cable gets out. need a stronger closer | Two Stars |
Nice camera for the price. Be aware that it comes in at 240, the 933 cameras come in at 480, so this is not quite as sharp. Does the job for what I need, tho I do wish I would have known this before I bought it. | Nice camera, not as sharp as previous model |
| I was really happy with these stickers. They came promptly and they were just as expected. I like all of the designs. | I was really happy with these stickers |
| don't try to recharge these with an auto charger cord or adapter plug! it will actually drain the battery. | warning! don't try to recharge these with ... |
That's better. Start from here, then see what large language models can do with this data.
t5-smallを使ったクイックサマリー
T5 (Text-to-Text Transfer Transformer)は、Googleが提供する汎用LLMのファミリーです。要約、分類、翻訳など多くのタスクに役立ち、「小さい」(~60Mパラメータ)からかなり大きい(~11Bパラメータ)ものまで、いくつかのサイズが用意されている。これらのサイズは、ますます強力になる一方で、扱うにはますます高価になっています。これらのLLMを扱う際の重要なテーマは、「シンプルに保つ」ことです。小さいモデルで十分であれば、それを使用し、可能であれば既製のリソースで始める。大きなモデルを使った推論には時間とコストがかかるので、レイテンシーや予算の制約から、最初から大きなモデルは使えないかもしれません。
前回のブログでは、SparkとHugging Faceを使ってT5を簡単に適用する方法を紹介しましたが、ここでも同じことが可能です。入力テキストと出力テキストがかなり短いので、まもなくわかるように、このデータセットですぐにうまく機能するかどうかは不明です。いくつかの新要素を加えての総括です:
os.environ['TRANSFORMERS_CACHE'] = "/dbfs/.../cache/hf"
summarizer_pipeline = pipeline("summarization",
model="t5-small", tokenizer="t5-small", num_beams=10)
summarizer_broadcast = sc.broadcast(summarizer_pipeline)
@pandas_udf('string')
def summarize_review(reviews):
pipe = summarizer_broadcast.value(
("summarize: " + reviews).to_list(), batch_size=8, truncation=True)
return pd.Series([s['summary_text'] for s in pipe])
camera_reviews_df = spark.read.format("delta").load("/tmp/.../review/cleaned")
display(camera_reviews_df.withColumn("summary",
summarize_review("review_body")).select("review_body", "summary").limit(10))
| review_body | summary |
|---|
| Great camera for the price. | great camera for the price for the camera. the camera is a great choice for a professional photographer. it is the best camera in the world. |
| im not happy, the cable gets out. need a stronger closer | im not happy, the cable gets out. need a stronger closer closer to the cable. click here for all the latest tv news. |
| Nice camera for the price. Be aware that it comes in at 240, the 933 cameras come in at 480, so this is not quite as sharp. Does the job for what I need, tho I do wish I would have known this before I bought it. | the 933 cameras come in at 240, so this is not quite as sharp. I wish I would have known this before I bought it. |
| I was really happy with these stickers. They came promptly and they were just as expected. I like all of the designs. | the stickers came promptly and they were just as expected. I like all of the designs and the designs. the stickers are a great addition to the stickers. |
| don't try to recharge these with an auto charger cord or adapter plug! it will actually drain the battery. | don't try to recharge these with an auto charger cord or adapter plug. it will actually drain the battery. if you want to recharge them, it's a good idea. |
数行のコードと数分の実行で GPUを必要としないのは悪くありません。結果はレビューの簡潔な要約としてもっともらしく見えます。しかし純正モデルは、過度に短いレビューを要約することに少し苦戦しており、最初の2つの要約では少し行き過ぎた表現になっています!これは、Fine-tuningの必要性を示唆しています。
上記のリストは、いくつかの有用な使用法のヒントを強調しています:
- TRANSFORMERS_CACHE環境変数を/dbfs上の場所に設定し、モデルを一度だけダウンロードし、多くのジョブやクラスタで再利用できるようにします。
- パイプラインをブロードキャストすることで、Sparkが効率的に転送・共有することができます。ここでは必須ではありませんが、大きなモデルでは重要です
- Spark で pandas UDFs を使用して、一度に全バッチの入力を効率的に処理する。
- t5-smallのような小さなモデルから始めて、必要に応じてアップグレードしていく
- 要約パイプラインにはいくつかの設定がありますが、そのうちのいくつかは知っておくと便利です:
- min_new_tokens は、出力が短くなりすぎないようにするためのものです。これは、より多くのテキストに対してより長い要約を生成するために以下で使用されます。
- num_beamsは、より多くの可能性を試すことで出力の質を向上させることができますが、その分、計算量は多くなります。
ここまでは目新しいものではありません。しかし、目標は各製品のすべてのレビューを要約することです。Sparkを使えば簡単で、レビューのテキストを集約して代わりにまとめるだけです:
summarizer_pipeline = pipeline("summarization",
model="t5-small", tokenizer="t5-small", num_beams=10, min_new_tokens=50)
summarizer_broadcast = sc.broadcast(summarizer_pipeline)
@pandas_udf('string')
def summarize_review(reviews):
pipe = summarizer_broadcast.value(
("summarize: " + reviews).to_list(), batch_size=8, truncation=True)
return pd.Series([s['summary_text'] for s in pipe])
review_by_product_df = camera_reviews_df.groupBy("product_id").\
agg(collect_list("review_body").alias("review_array"),
count("*").alias("n")).\
filter("n >= 10").\
select("product_id", "n", concat_ws(" ", col("review_array")).alias("reviews")).\
withColumn("summary", summarize_review("reviews"))
display(review_by_product_df.select("reviews", "summary").limit(10))
以下は出力の一例で、簡潔のため集計レビューは切り捨てています:
| reviews | summary |
|---|
| Nothing was wrong with this item. All its functionalities work perfectly. I recommend this item for anyone that want to take black and white photos. This camera wasn't exactly what I had expected, it was much lighter and seemed a bit flimsy, but it was in very good condition and it arrived very quickly, just as the sender advertised it would. It is a very easy to use camera and I am happy I have it to learn on, but the quality of the first role of film I developed was not great. | the camera works well for the photography student for which it was purchased. it arrived very quickly, just as the sender advertised it would. the price was very low considering the battery that this camera needs to work is hard to find, and maybe the seller should have specified it with the information. |
興味深いですが要約がうまくいっていないのは明らかです。次の論理的なステップとして、より大きなモデルを試すか、これらのモデルの一つをFine-Tuningすることが考えられます。次のセクションでは、その両方を試してみることにします。
既製品のファインチューニング
ファインチューニングとは、あらかじめ訓練されたモデルを新しいデータでさらに訓練し、ある特定のタスクの性能を向上させることを意味します。T5のようなモデルは、ある単語列を別の単語に変換するような多く�のことを行うように訓練されています。ここで、T5が得意とするのは、多くの商品レビューをレビュー要約に変換することです。これはT5が得意とする要約作業のようなもので、手元にある実際のレビューデータによりよく合うように要約を調整することを望んでいるだけです。これは、T5アーキテクチャをゼロからトレーニングするのとは違います。時間がかかるだけでなく、事前に訓練されたT5モデルが持っている言語に関する学習がすべて失われてしまうからです。
上記の例は、既存のモデルと、その作成に費やした研究、データ、計算能力を再利用しているため、起こっていることの複雑さに比べれば、非常にシンプルです。しかし、fine-Tuningはモデルのトレーニングであり、経験豊富な実務家であっても、トレーニングプロセスを継続するために必要なPyTorchやTensorflowのコードを書くことは簡単ではありません。
幸いなことに、これらのオープンソースモデルには、トレーニングやファインチューニングのコードが付属していることが多い。ノートブックユーザーにとって残念なのは、それらがノートブックではなく、Pythonスクリプトであることです。Databricksではノートブックでもシェルコマンドやgitリポジトリからのスクリプト、あるいはWebターミナルでの対話的な実行が可能なためこのような問題はありません。
ファインチューニングスクリプトの入手
実は、Hugging Faceは、T5モデルで動作する便利なFine-Tuningスクリプトを、Trainer APIを通じて提供しています。なぜこれらのスクリプトを使うのが有利なのかは、後で明らかになりますが、最初はちょっと考えにくいかもしれませんね。既存のソリューションを再利用することは、すぐに始められる素晴らしい方法です。
まず、Hugging FaceのGithubリポジトリをDatabricksのRepoとしてクローンします。スパースチェックアウトモードを使用して、レポ全体ではなく、要約例のみをクローンできます:
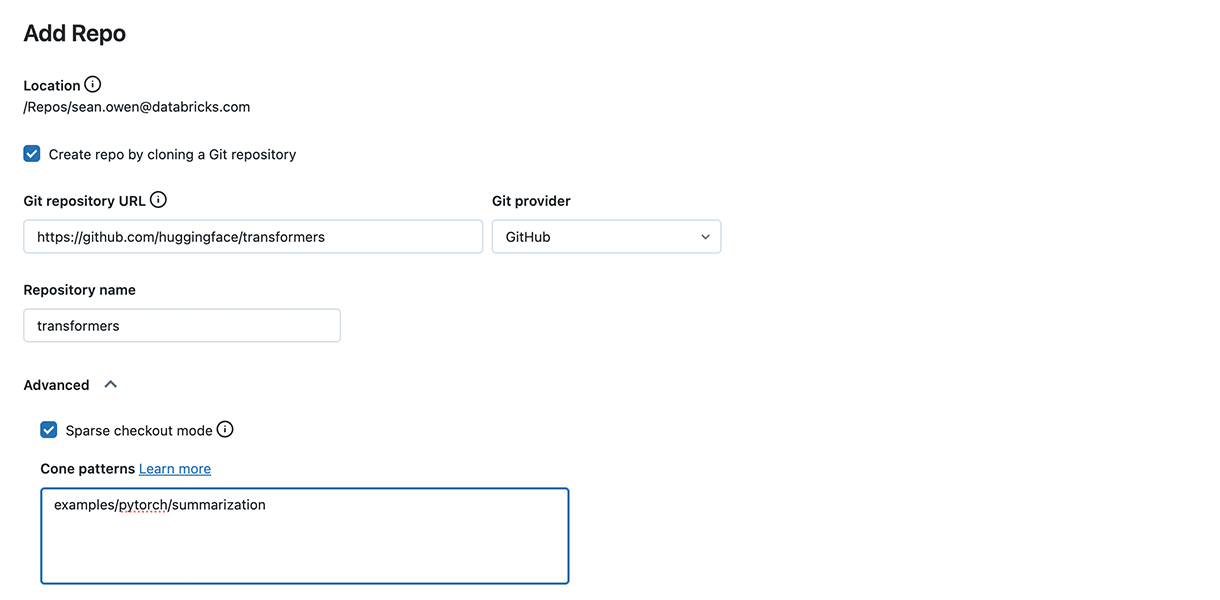
これは run_summarization.py スクリプトのコピーを取得します。 run_summarization.py をコピーして好きなRepoに貼り付けても問題ないです。
一つ小さな変更が必要です。このスクリプトは、トランスフォーマーライブラリのバージョンが、期待するものと一致するかどうかをチェックします。このソースチェックアウトは、transformersのソースインストールを期待しています。このファイルを変更する代わりに %pip install git+https://github.com/huggingface/transformers を追加することもできますが、このチェックを削除しても問題ないでしょう。あなたのコピーから check_min_version("...dev0") を読んでいる��行を削除してください。
環境セットアップ
どこでもそうですが、これらのスクリプトを使うには少し設定が必要です。Databricks Runtime 12.2 ML (GPU - これは間違いなくGPUが必要です!)を利用します:
- ランタイムにまだ入っていない必要なライブラリのインストール:
%pip install 'transformers>=4.26.0' datasets evaluate rouge-score
- DatabricksがホストするMLflowトラッキングサーバーとHugging FaceのMLflow integrationを接続するための環境変数を設定します:
os.environ['DATABRICKS_TOKEN'] = dbutils.notebook.entry_point.\
getDbutils().notebook().getContext().apiToken().get()
os.environ['DATABRICKS_HOST'] = "https://" +
spark.conf.get("spark.databricks.workspaceUrl")
os.environ['MLFLOW_EXPERIMENT_NAME'] =
"/Users/.../fine-tuning-t5"
os.environ['MLFLOW_FLATTEN_PARAMS'] = "true"
t5-smallのFine-Tuningは、最近のGPU1つで簡単にこなせます。これらのモデルには、NVIDIAのA10やA100のような最近のAmpereアーキテクチャのGPUを使用するのが有利です。例えば、AWSではg5インスタンスタイプになります。A10はA100よりも入手しやすいかもしれません。
このようなスクリプトは、通常ローカルの入力ファイルを必要とします。ここでは、チューニングスクリプトは、(text,summary)ペアのCSVファイルを必要としています。問題ありません。分散ストレージは /dbfsでローカルファイルのように見えます。Deltaデータセットをトレーニングファイルとバリデーションファイルのペアとして書き出せばよいのです:
train_df, val_df = camera_reviews_cleaned_df.randomSplit([0.9, 0.1], seed=42)
train_df.toPandas().to_csv("/dbfs/.../camera_reviews_train.csv", index=False)
val_df.toPandas().to_csv("/dbfs/.../camera_reviews_val.csv", index=False)
Fine-Tuningのチューニング
実際のFine-Tuningは、その後スクリプトを実行することになります。拍子抜けするほどです。
%sh export DATABRICKS_TOKEN && export DATABRICKS_HOST && export MLFLOW_EXPERIMENT_NAME && export MLFLOW_FLATTEN_PARAMS=true && python \
/Workspace/Repos/.../summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file /dbfs/.../review/camera_reviews_train.csv \
--validation_file /dbfs/.../review/camera_reviews_val.csv \
--source_prefix "summarize: " \
--output_dir /dbfs/.../review/t5-small-summary \
--optim adafactor \
--num_train_epochs 8 \
--bf16 \
--per_device_train_batch_size 64 \
--per_device_eval_batch_size 64 \
--predict_with_generate \
--run_name "t5-small-fine-tune-reviews"
このスクリプトには多くのパラメータがあり、ここで取り上げることはできませんが、いくつかの項目は注目に値するでしょう:
- 環境変数のエクスポートにより、MLflow統合が動作するようになる
- source_prefix: "summarize: " は、データがテキストの要約の例であることをT5が理解するのに役立つ
- optim: Adafactor オプティマイザは、ここでは厳密には必要ありませんが、メモリ使用量の削減は、後で大きなモデルをチューニングする際に重要になります。
- bf16: より多くの数値範囲を保持する bfloat16タイプを使用して、より高速な 16 ビット浮動小数点演算を可能にします。これは最新のAmpere GPUを必要とします
- num_train_epochs: ファインチューニングでは、ゼロからのトレーニングほど多くのエポックを必要としないため、一握りのエポックでも問題ない。
- per_device_train_batch_size: この重要なパラメータは、バッチサイズを制御します。どのようなトレーニングでもそうですが、バッチサイズが大きいとGPUメモリを使い果たす可能性があります。これは、より大きなモデルをFine-Tuningする際に重要な問題となりますが、64のような大きな値は、短いシーケンスを持つデータセットや、24GB以上のメモリを持つ最新のGPUでは問題ないでしょう。あなたの走行距離は大きく変わるでしょう。
これは、例えば数ドルするA10 GPUで1時間程度かかります。トレーニング中(とトレーニング後)、MLflowはステップごとの損失などのトレーニングメトリクスを記録します:

トレーニングはもう少し長く続けられたようですが、8エポックはすでに大まかな再コンバージョンを行うのに十分でした。MLflowがどのようにモデルを追跡し、REST APIとしてデプロイすることができるかについての詳細は、付属のノートブックを参照してください。
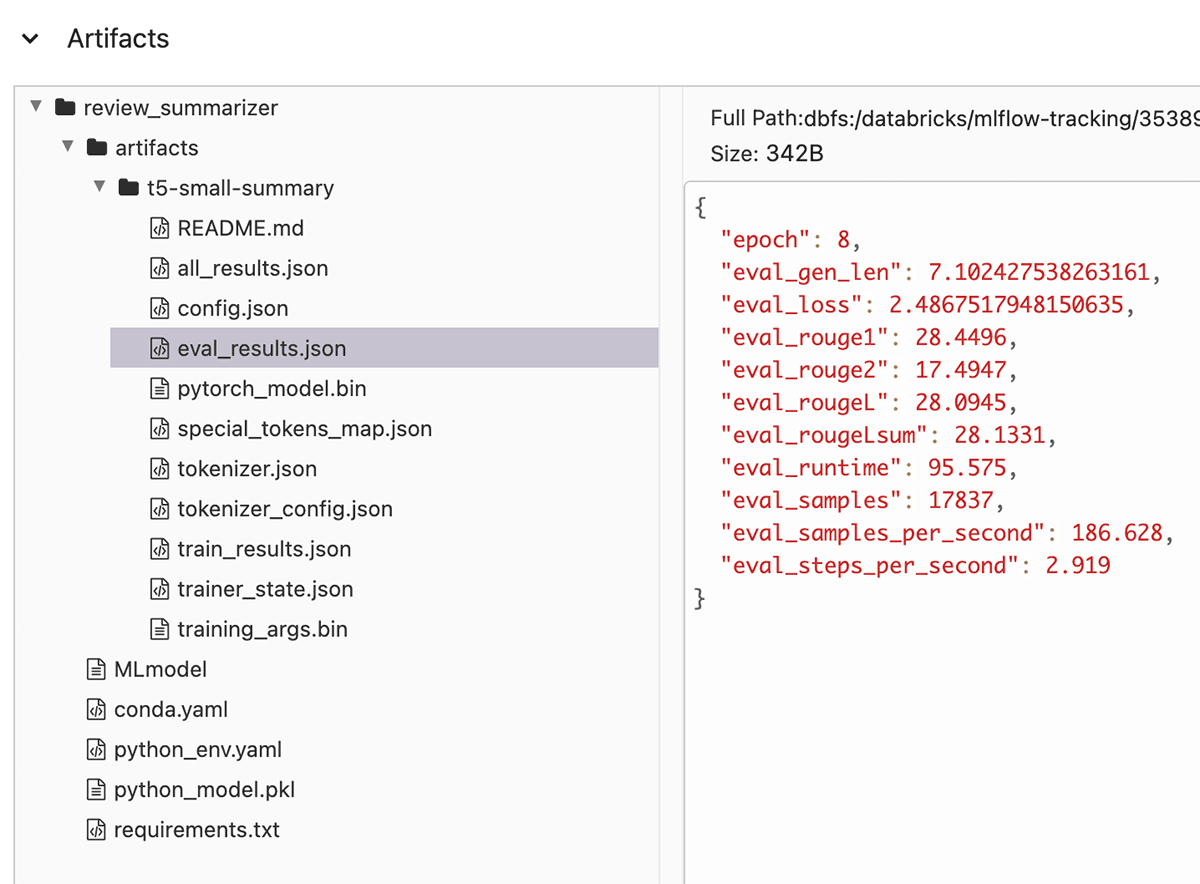
サマリーの品質を評価するROUGE metrics のように、モデルとともに自動的に記録される追加のメトリクスを見つけることができます。このメトリクスは、損失よりも結果の品質についてやや意味のあるイメージを与えるため、Fine-Tuningの期間を決定する際に役立ちます。
以上です!オープンなモデルやツールを使って、DatabricksでT5モデルのFine-Tuningを行いました。結果はどうだったでしょうか?t5-small」をあなたのモデルの出力パスに置き換えて、上述の要約パイプラインを再実行するだけです:
...
summarizer_tuned = pipeline("summarization", \
model="/dbfs/.../review/t5-small-summary", \
tokenizer="/dbfs/.../review/t5-small-summary", \
num_beams=10, min_new_tokens=50)
...
| reviews | summary |
|---|
| Nothing was wrong with this item. All its functionalities work perfectly. I recommend this item for anyone that want to take black and white photos. This camera wasn't exactly what I had expected, it was much lighter and seemed a bit flimsy, but it was in very good condition and it arrived very quickly, just as the sender advertised it would. It is a very easy to use camera and I am happy I have it to learn on, but the quality of the first role of film I developed was not great. | Great Camera, Great Price, Great Shipping, Great Customer Service - Great Price - Good Product - Easy to Use & Easy To Use - Just As Good As I Expected - Exactly What I Needed! |
文章は、予想通り、確かにレビューの見出しのような感じです。深みに欠けるかもしれませんね!これは、数��クリックでREST APIにすることもできます。
REST APIを考えるなら、レイテンシーについても考える価値があります。要約を返すのにどれくらいの時間がかかるか?レイテンシーが重要なら、GPUで実行することが重要です。結論から言うと、1つのサマリーを実行するだけで、約480msかかります。
より高度なサマリーを得るには、より大きなT5モデルを試す価値があります。
DeepSpeedでt5-largeにスケールアップする。
t5-largeのような大きなモデルにスケールアップしても、パラメータが60Mに対して770Mと、桁違いの大きさであるにもかかわらず、ほとんど変化はありません。実際、上記のFine-Tuningスクリプトを実行する際に変わるべきことは、以下の通りです:
- 複数のGPUに切り替える - たとえば、1つのGPUではなく、4つのA10 GPUに切り替える
- t5-largeをご指定ください。
- バッチサイズを12個程度に減らす
より大きなモデルは、より多くのハードウェアを必要とし、一度にGPUに搭載できる量が少なくなる。バッチサイズを正しく設定するのは、シーケンスの長さがまちまちで、長い場合もあるため、難しい場合があります。そのため、データ準備ではレビューや要約の長さを制限しています。また、スクリプトにはmax_source_lengthのようなオプションがあり、手動で入力を切り捨てることができます。入力が小さいとスケールアップに役立ちますが、問題によっては、任意に入力を切り捨てることでモデルの品質を損なう可能性があります。
これら��の変更を加えて再実行した場合、うまくいくことがわかるでしょう。また、1エポックあたり2時間かかる。コストは、もはや数ドルではなく、8エポックで90ドル程度になる。このため、エポック数をよく考えることが重要になる。例えば、上のプロットでは、4エポックだけ実行しても損失が大きくなることはないようなので、少なくとも最初のうちは、4エポックだけ実行するのが妥当かもしれません。必要であれば、チェックポイントを再開し、さらにトレーニングを行うことができます。
DeepSpeedに参入
また、Hugging Faceのようなツールがすぐに提供してくれるものよりも、より高度な並列化を利用することが重要になります。幸いなことに、今回もオープンソースにいくつかの答えがあります。MicrosoftのDeepSpeedは、洗練された最適化を多数実装することで、既存の深層学習トレーニングや推論ジョブをほとんど変更することなく高速化することができます。特に興味深いのは、メモリ使用量を減らそうとする最適化セットであるZeROです。詳細や論文については、DeepSpeedのサイトを参照してください。
DeepSpeedは、Hugging FaceのTrainer APIを使用するFine-Tuningジョブを自動的に最適化することができ、既存のFine-Tuningスクリプトを実行するためのドロップイン代替スクリプトを提供しています。これは、既製のトレーニングスクリプトを再利用することが有利である理由の1つです。
DeepSpeedを使用するには、accelerateと一緒にそのパッケージをインストールします。ソースからインストールすることをお勧めしますが、リリースされたパッケージをインストールすることもできます。
DeepSpeedで同じように実行しても、ほんの少ししか変わりません:
%sh export DATABRICKS_TOKEN && export DATABRICKS_HOST && export MLFLOW_EXPERIMENT_NAME && export MLFLOW_FLATTEN_PARAMS=true && deepspeed \
/Workspace/Repos/.../run_summarization.py \
--deepspeed /Workspace/Repos/../ds_config_zero2_no_offload_adafactor.json \
--model_name_or_path t5-large \
--do_train \
--do_eval \
--train_file /dbfs/.../camera_reviews_train.csv \
--validation_file /dbfs/.../camera_reviews_val.csv \
--source_prefix "summarize: " \
--output_dir /dbfs/.../t5-large-summary-ds \
--optim adafactor \
--num_train_epochs 4 \
--gradient_checkpointing \
--bf16 \
--per_device_train_batch_size 20 \
--per_device_eval_batch_size 20 \
--predict_with_generate \
--run_name "t5-large-fine-tune-reviews-ds"
python は deepspeed runner スクリプトに置き換えられます。また、設定ファイルへのパスが必要です。このファイルのオプションについては、ここでは触れませんが、デフォルトの「ZeRO stage 2」構成から始めてマイナーチェンジするのが合理的です。たとえば、現在の設定では、次の2つの編集が必要です:
- bf16 を明示的に有効にする(通常の float16 / fp16 サポートは無効にする)
- オプティマイザーの設定を削除し、AdamWの代わりにAdafactor を使用するようにしました。Adafactorはメモリ消費量が非常に少なく、大規模なモデルの微調整を行う際に良い代替となります。
DeepSpeedでは、さらにいくつかの改良を加えることが可能です:
- gradient_checkpointing:前方パスで大きな中間結果を解放し、後方パスで再計算することで、少し計算量が増える代わりにメモリを節約する。
- デバイスごとのバッチサイズは20まで可能です(必要であればもっと大きくなります)。4GPUの場合、有効なバッチサイズは4 x 20 = 80になることに注意してください。
バッチサイズは重要なチューニングの問題になります。バッチサイズはデバイスごとに調整されることが多いのですが、それは1つのGPUが一度に処理できる量を制約するのは、個々のGPUメモリだからです。バッチサイズが大きいとGPUメモリを使い切らない限りスループットが向上します!最大バッチサイズは、GPUメモリ、入力配列のサイズ、モデル内の最大レイヤーのサイズ、オプティマイザーの設定など、いくつかの要因に依存します。一般的には試行錯誤しながら調整する必要があります。
トレーニングにおいても、過度に大きなバッチサイズが問題になることもあります。しかし非常に大きな言語モデルの場合、一般的には数個、あるいは1個のバッチを各デバイスのメモリに収める方法を見つけることが問題です。少なくともバッチサイズは結果を再現するために重要なので、有効なバッチサイズは(デバイス数×デバイスごとのバッチサイズ)であることは覚えておく必要があります。
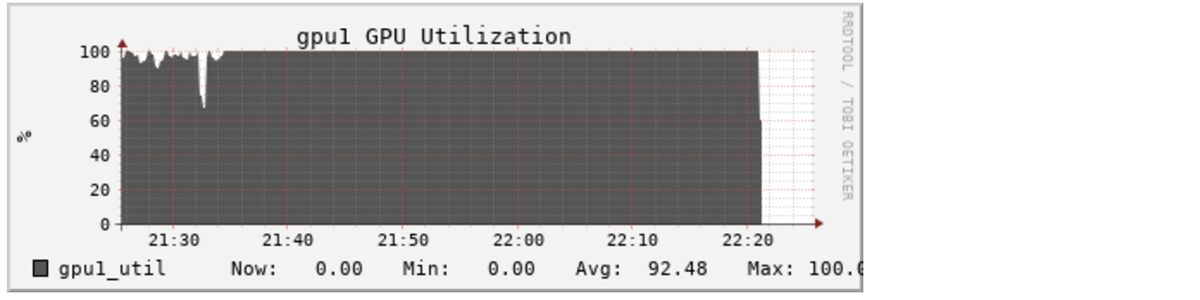
これにより、実行時間は1エポックあたり40分程度に低下しています。3倍速いということは、3倍安�いということでもあり、このチューニングは30ドル程度で済むかもしれません。これは、時間が日単位、コストが数百ドル、数千ドル単位になったときに、ますます価値が高まるでしょう。
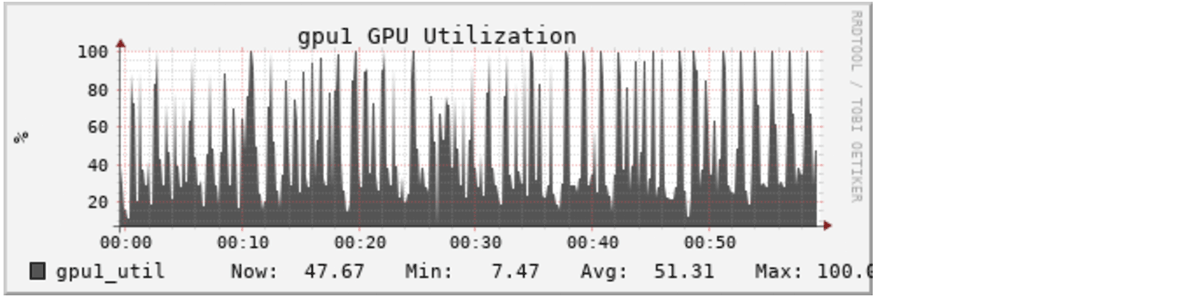
この改善は、DatabricksクラスタのGangliaメトリクスのように、GPUメトリクスで確認することができます:
DeepSpeedを使用しない場合:
With DeepSpeed:
このモデルでサマリーを見るとどうでしょうか?
| reviews | summary |
|---|
| Nothing was wrong with this item. All its functionalities work perfectly. I recommend this item for anyone that want to take black and white photos. This camera wasn't exactly what I had expected, it was much lighter and seemed a bit flimsy, but it was in very good condition and it arrived very quickly, just as the sender advertised it would. It is a very easy to use camera and I am happy I have it to learn on, but the quality of the first role of film I developed was not great. | Great Camera, great condition LIKE NEW. It takes amazing photographs and is easy to handle and work with. Great camera for a photography class and so far am happy with the quality of the photos I have taken with it. Great seller to deal with! |
簡潔��で、レビューの文章から正確な詳細を提供するようになったので、おそらくさらに良くなっています。シングルGPUでのモデルレイテンシは約3秒となり、より大きなモデルへのスケールアウトを検討する際には、すでに躊躇してしまうかもしれません。ここで止まってしまうかもしれませんが、最大のT5モデルまでスケールアウトすることも可能です。
Super-Size It: Fine-Tuning t5-11b
T5の最大モデルはt5-11bで、ご想像の通り110億個のパラメータを持ち、t5-largeの14倍以上です。それをFine-Tuningすることは、クラウドで利用できる最大のタイプとはいえ、1台のマシンで同じ手法で可能です。
%sh export DATABRICKS_TOKEN && export DATABRICKS_HOST && export MLFLOW_EXPERIMENT_NAME && export MLFLOW_FLATTEN_PARAMS=true && deepspeed \
/Workspace/Repos/.../run_summarization.py \
--deepspeed /Workspace/Repos/.../ds_config_zero3_adafactor.json \
--model_name_or_path t5-11b \
--do_train \
--do_eval \
--train_file /dbfs/.../camera_reviews_train.csv \
--validation_file /dbfs/.../camera_reviews_val.csv \
--source_prefix "summarize: " \
--output_dir /dbfs/.../t5-11b-summary \
--optim adafactor \
--num_train_epochs 1 \
--gradient_checkpointing \
--bf16 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--predict_with_generate \
--run_name "t5-11b-fine-tune-reviews"
これは大変な作業で、現実的に考えて、これを合理的な時間で完成させるには、さらにいくつかの変更が必要です:
- 400GB以上のRAMを搭載した8GPUマシン
- 1トレーニングエポック(またはそれ以下)
- 1台あたりのバッチサイズは8(有効バッチサイズは8×8=64)
- パラメーターのオフロードを可能にした、パラメーターの完全なパーティショニングを含む「ZeROステージ3」最適化
しかし、こ�のデータセットと入力サイズでは、1回のエポックに約1.8日かかってしまいます。コストは1エポックあたり数百ドルに近づきます。これは確かにもっとチューニングできますが、予想される計算の規模を知ることができます。この例では、数百ステップ(1エポックの1%)のFine-Tuningで次のようなサマリーを得ることができました:
| reviews | summary |
|---|
| Nothing was wrong with this item. All its functionalities work perfectly. I recommend this item for anyone that want to take black and white photos. This camera wasn't exactly what I had expected, it was much lighter and seemed a bit flimsy, but it was in very good condition and it arrived very quickly, just as the sender advertised it would. It is a very easy to use camera and I am happy I have it to learn on, but the quality of the first role of film I developed was not great. | Great camera for a photography class!! I am very happy with my purchase. Delivery was quick and I received the camera a couple days after purchase. I am taking a black and white film photography class and so far am happy with the results my first roll of film |
質的にも、より良いまとめ方だと思います。しかしこの特定の問題では、たとえそれが完全に可能であったとしても、時間とコストに見合うとは思えません。Fine-Tuningのコストと時間が許容できる場合でも、推論のコストと時間は許容できないかもしれません。例えば t5-11bを使った推論では、GPUで数十秒かかる可能性があり、それは遅すぎるかもしれません。ほとんどの問題では、この規模かそれ以下で十分ですが、非常に大規模なチュ��ーニングは容易に可能です。
Conclusion and Next Directions
大規模言語モデルは、様々なビジネス問題に対する強力な新ツールであり、オープンソースのものは、Databricks上でオープンソースツールを使って、そのまま簡単に適用することができます。このような大規模な言語モデルのFine-Tuningも、オープンソースのツールを使えば同様に簡単です。スクリプトもDatabricksのノートブックでは問題ありません。これらの簡単なアプローチは、ほとんどすべての実世界の問題に対して十分なサイズにスケールアップすることができます。
T5の様々なサイズをFine-Tuningするための迅速な実験の結果、Fine-Tuningと推論の実行に必要なリソースの大きさが桁違いであることがわかります:
| T5 Size | Example Summary | Tuning Time | Tuning Cost | Inference Latency |
|---|
t5-small
60M params
No fine-tuning | the camera works well for the photography student for which it was purchased. it arrived very quickly, just as the sender advertised it would. the price was very low considering the battery that this camera needs to work is hard to find, and maybe the seller should have specified it with the information. | n/a | n/a | 100s of ms |
t5-small
60M params
Fine-tuning | Great Camera, Great Price, Great Shipping, Great Customer Service - Great Price - Good Product - Easy to Use & Easy To Use - Just As Good As I Expected - Exactly What I Needed! | an hour | $10s | 100s of ms |
t5-large
770M params
Fine-tuning | Great Camera, great condition LIKE NEW. It takes amazing photographs and is easy to handle and work with. Great camera for a photography class and so far am happy with the quality of the photos I have taken with it. Great seller to deal with! | several hours | $100s | seconds |
t5-11b
11B params
Fine-tuning | Great camera for a photography class!! I am very happy with my purchase. Delivery was quick and I received the camera a couple days after purchase. I am taking a black and white film photography class and so far am happy with the results my first roll of film | days | $1000s | 10s of seconds |
しかし、最大級のマシンが提供する以上のリソースを必要とするケースは常に存在する。さらに作業を進めれば、これらのツールはDatabricks上のマシンのクラスタに適応させることができ、これは将来のブログのテーマとなります。
Databricksで試してみてください!このノートブックアーカイブをリポジトリにインポートして利用できます。




