Rapid NLP Development With Databricks, Delta, and Transformers
Free form text data can offer actionable insights unavailable in structured data fields. An insurance company may leverage its claims adjusters’ notes to understand characteristics of a claim that are otherwise unknowable. An IT division may efficiently analyze support ticket requests to route them to the proper in-depth team. Generating this level of value from free-form text can be challenging but a family of models, referred to as transformer models, provide a powerful toolset that enterprise data science practitioners can easily leverage.
Transformer models use a neural network architecture called self-attention that captures text semantics more effectively and efficiently than prior methods. They are also a form of transfer learning, meaning they have been trained on large text corpuses by the model developers using techniques such as masked language modeling and next sentence prediction. The models are designed to generate word embeddings that can be used for a wide variety of downstream tasks including text classification, the focus of this article.
This article provides a high-level overview of transformer models and considerations when training them. For more in depth implementation details, including integration with Delta Lake and Managed MLflow, see the solution accelerator.
Getting started with transformers
Hugging Face is a company that focuses on making transformer models discoverable and accessible. It provides access to a wide variety of models and datasets. Using the transformers library, which is maintained by Hugging Face, artifacts can be downloaded and used within your Databricks Workspace. The library is included in Databricks ML Runtime version 10.4 and above and can be pip installed in earlier versions.
To start using the library, pick a transformer architecture, such as bert-base-uncased, from the Hugging Face model hub. Then, execute the code below to download its tokenizer and model.
Data pre-processing with tokenizers
The tokenizer performs several pre-processing steps. First, it splits text into tokens and maps tokens to the model’s vocabulary. BERT’s vocabulary consists of 30,522 entries of words, pieces of words, numbers, punctuation and symbols. The model also contains special tokens that capture information such as the start of an observation ([CLS]) and the separation of sequences ([SEP]).


If a token does not exist within BERT’s vocabulary, such as the token “Databricks”, it is split into pieces to make a match.
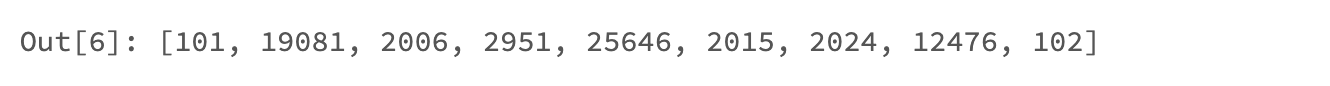

Tokenizers also perform truncation and padding of input sequences. Each model has a maximum accepted tokenized sequence length. In the case of BERT and many other models, that length is 512 tokens. When tokenizing an input text, all resulting tokens generated after the first 512 will be dropped, or ‘truncated’.
Additionally, token sequences will be ‘padded’. Transformer models are trained on batches of data rather than the entire training data set at once. Each batch must be of the same length, though the length of text observations can vary widely. Some tokenized sequences may be much longer than 512 elements, others may be much shorter. Padding adds zeros to the tokenized sequences when necessary to create uniform lengths. This zero value represents the token id for another special token in BERT’s vocabulary, [PAD].

A tokenizer’s truncation and padding behavior are configurable and there are various strategies that can be tested and compared. Truncating to shorter lengths speed’s training time; though if longer sequences are common, the loss of information could hinder predictive performance. Consider dynamic padding as a good, general strategy—this technique pads sequences during model training rather than tokenization. Since the only requirement is that records within a batch are of the same length, dynamic padding pads each batch to the length of the longest sequence in the batch, keeping the number of padded tokens to a minimum.
Classifying text using word embeddings
The tokenized text can be passed directly to the model to generate word embeddings, with one embedding for each input token, including the special tokens. These embeddings can then be used for a variety of natural language processing tasks.

For text classification, for example, it is common to use only the embedding associated with each observation's special [CLS] token. That embedding can be passed to a feed-forward neural network that classifies the text into a set of user-defined categories. The transformers library implements this architecture out of the box through its AutoModelForSequenceClassification class. This class allows the user to pass a transformer model name and a ‘classification head’ will be attached to the end of the model�’s neural network layers. Simply specify the number of labels to classify. As an example, the banking77 dataset available on the Hugging Face data hub contains banking-related questions classified into 77 intents. Therefore, the model’s num_labels parameter is set to 77.

The model can then be fine-tuned on a training dataset. During training, the learnable parameters of all layers in the network can be updated, including the layers that generate the embeddings and the classification head. From this fine-tuned model, we can generate predicted labels and their probabilities.
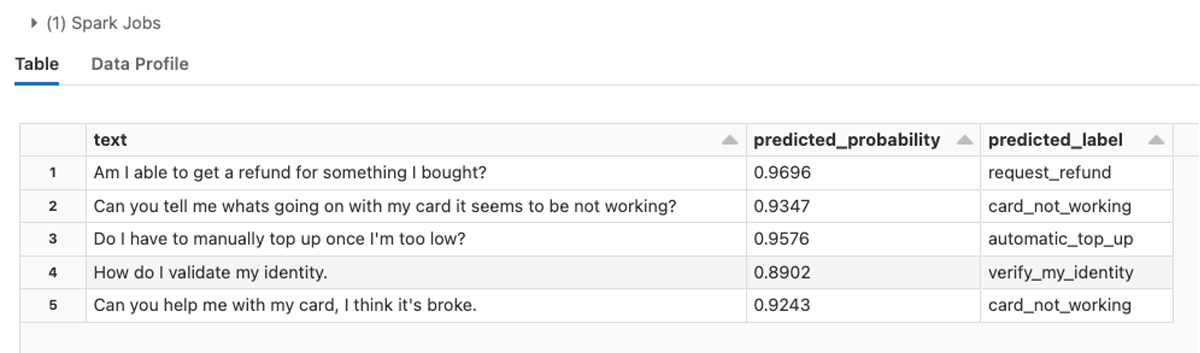
See the solution accelerator for a detailed model training implementation using the banking77 dataset and others.
Optimizing transformer models
Transformer models are large and computationally intensive to train and apply for inference. The BERT model discussed in this article has 110 million learnable parameters. Some more recent architectures are vastly larger; as an extreme example, GPT-3, has 175 billion parameters. Fortunately, there are methods to decrease model training time and speed up inference.
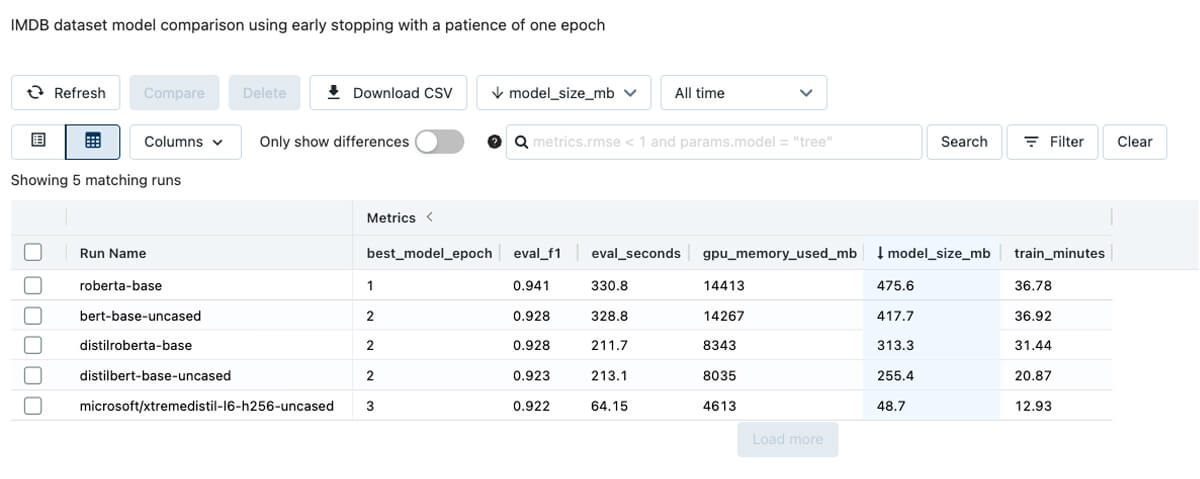
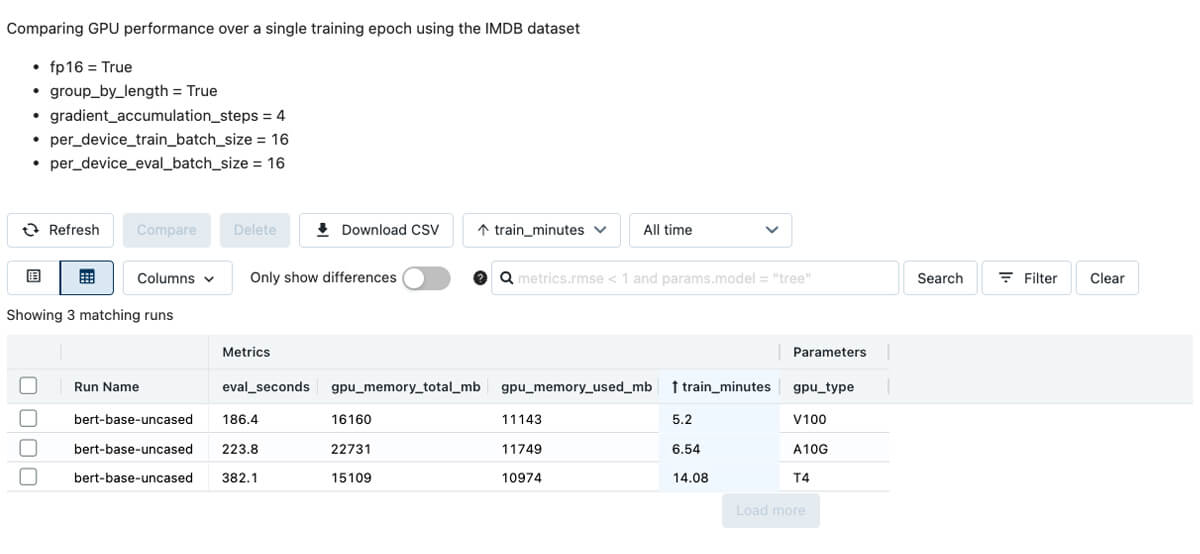
A family of models, referred to as distilled models, reduces the model size and computational complexity by compressing a larger model, a teacher, into a smaller version, a student. In the Hugging Face model hub, these models typically include ‘distil’ in their name, for example, distilbert-base-uncased. Distilled models can be fine tuned more quickly and can score records much faster than their larger teachers. The below Experiment compares models on the IMDB dataset, which includes movie reviews and their sentiment. Notice the large variation in model size, GPU memory consumption, training time, and time to score all evaluation dataset records. Interestingly, predictive performance is similar across the models.
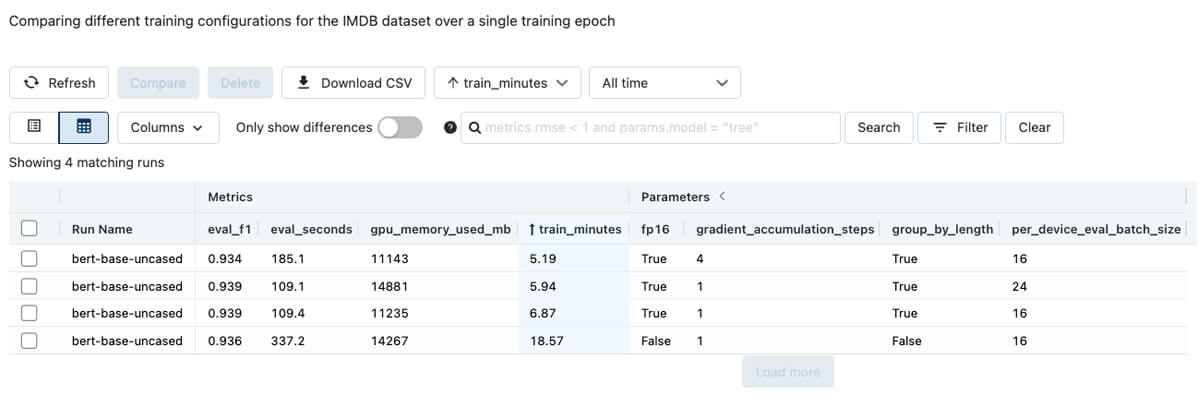
In addition to distillation, training configuration and GPU type have a large impact. Training and inference times can be reduced considerably by adjusting the settings in the transformer's Trainer class, which governs the fine-tuning process. When fine-tuning a model on the IMDB data set, adjusting settings related to batch size, numerical precision during training (referred to as fp16 below), and gradient accumulation steps led to major reductions in training and inference times over a single training epoch.
In addition, the choice of GPU type impacts training and inference times.
Although a GPU-backed instance is required for training and also speeds up inference considerably, CPU inference is an option. Consider using distilled models with quantization to boost CPU inference speeds. Quantization uses faster, less precise numerical representations to reduce inference latency. It can be easily applied directly to fine-tuned transformer models.
Quantizing the linear layers of a distilbert-base-uncased model fine tuned on the banking77 dataset reduced its size by about half. CPU-based inference latency was reduced by two-thirds, while the model’s F1 score on the test dataset declined by only 0.01.
Pre-trained and pre-fine tuned
In some cases, it may not be necessary to fine-tune your own text classification model because an out-of-the-box option already exists. For example, the model, distilbert-base-uncased-finetuned-sst-2-english, consists of a pre-trained distilbert-base-uncased model that was fine-tuned on the SST-2 dataset, which contains text and sentiment classifications. The model and tokenizer can be loaded in the form of a pipeline and applied directly to raw text without any additional training. A prior Databricks blog dives deeper into this topic.

Conclusion
Transformers are powerful and accessible, and the Databricks Lakehouse Platform excels at training and managing this family of models. Delta Lake provides the necessary data foundation for efficient and accurate machine learning and analytics. The flexibility to provision Clusters through a friendly user interface, including GPU-backed instances equipped with the Machine Learning Runtime, empowers Data Scientists to train transformers right away. Also, experimentation with different models and training configurations is easily handled by Managed MLFlow; results are clearly documented and shareable, work is never lost, and final models are easily deployed.
To get started training and comparing transformer models, clone this repository as a Repo in your Databricks Workspace.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.