3x schnellere Suche: Paralleles Test-Time-Scaling mit Instructed-Retriever-1
Heute kündigen wir ein wichtiges Update an, das den Agent Bricks Knowledge Assistant sowohl schneller als auch qualitativ hochwertiger macht. Die Zeit für die Antwortgenerierung hat sich um das Zweifache verringert, und die Suchzeit ist um mehr als das Dreifache gesunken, wodurch die Time To First Token (TTFT) auf etwa zwei Sekunden reduziert wird.¹ Dadurch erhalten Nutzer des Knowledge Assistant spürbar schnellere Antworten in all ihren Anwendungsfällen, ohne dass eine Neukonfiguration erforderlich ist oder Abstriche bei der Qualität gemacht werden müssen.
Diese Verbesserungen werden durch Instructed-Retriever-1 ermöglicht, ein auf Retrieval spezialisiertes Modell, das für paralleles Test-Time-Scaling entwickelt wurde. Im Gegensatz zum standardmäßigen agentischen Retrieval, bei dem ein Agent sequenziell arbeitet und jedes Ergebnis analysiert, bevor er den nächsten Schritt bestimmt, fächert unser Ansatz diese Arbeit parallel auf. Instructed-Retriever-1 ist ein einzelnes Modell, das für beide Retrieval-Phasen trainiert wurde: Query-Generierung zur Erhöhung des Recall und Reranking zur Erhöhung der Precision, die parallel ausgeführt werden, um die Latenz niedrig zu halten. In diesem Beitrag beschreiben wir, wie dieser Ansatz zu einer Pareto-optimalen Leistung führt, wie wir ein einzelnes Modell trainieren, um die gesamte Retrieval-Pipeline zu unterstützen, und wie wir die Leistung bei realistischen Enterprise-Workloads validieren.
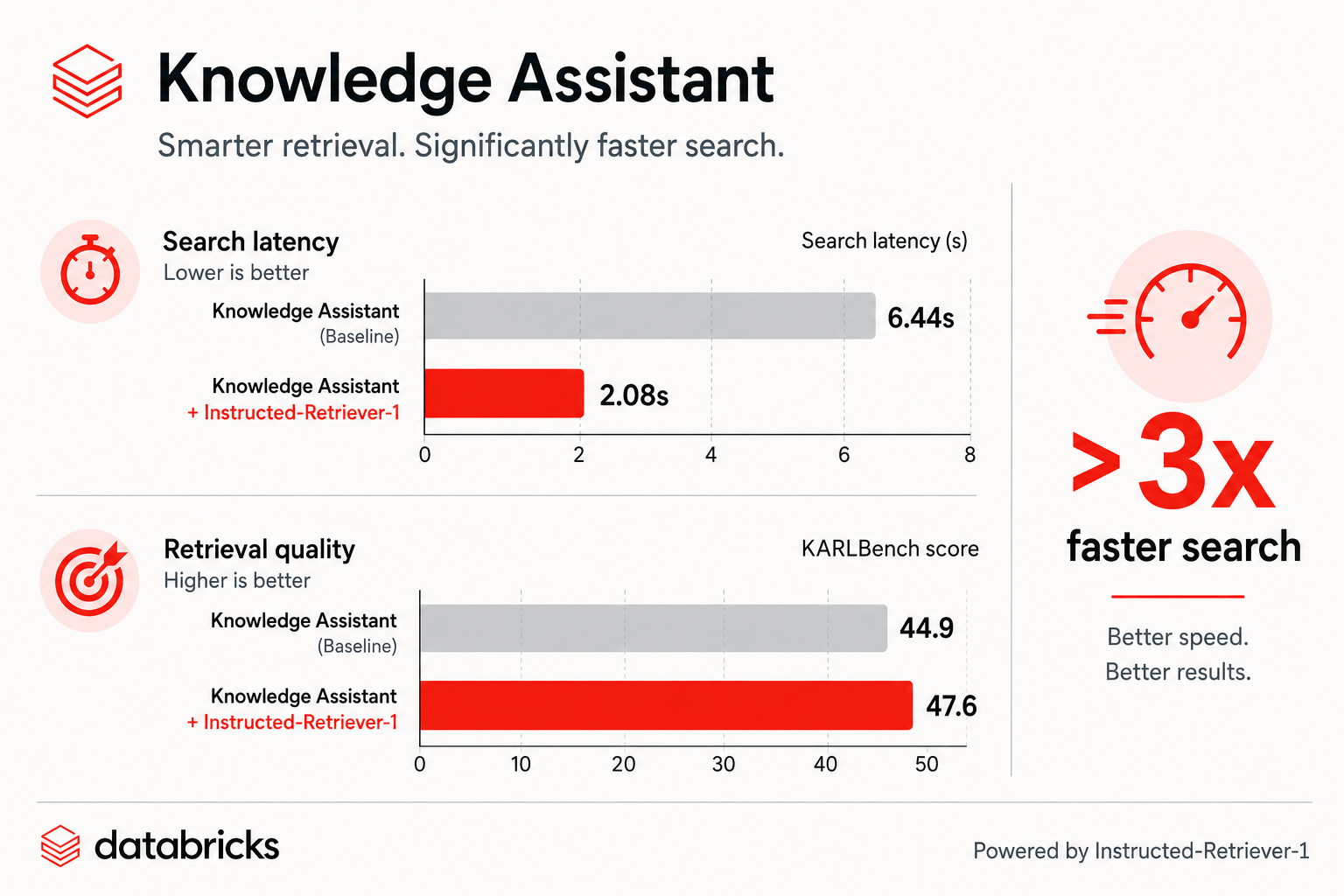
Abbildung: Auf KARLBench verbessert der Knowledge Assistant mit Instructed-Retriever-1 sowohl die Suchlatenz als auch die Retrieval-Qualität.
1. Paralleles Test-Time-Scaling für die Suche
Unsere bisherige Forschung hat gezeigt, dass sich die Qualität durch zusätzliche Rechenleistung zur Testzeit (Test-Time-Compute) verbessern lässt. Die meisten agentischen Suchsysteme verwenden diese Rechenleistung heute jedoch für sequenzielle Operationen wie Tool-Aufrufe, Reason-Act-Schleifen und Chain-of-Thought-Denkprozesse. Diese Methoden verbessern zwar die Suchqualität, gehen jedoch mit einer erheblich höheren Latenz und höheren Kosten einher. Für das Training von Instructed-Retriever-1 gehen wir einen anderen Weg: Anstatt die Rechenleistung sequenziell zu skalieren, parallelisieren wir sie während der ersten Suchphase. Indem wir das Spektrum der abgerufenen Belege erweitern und den relevantesten Kontext direkt im Vorfeld auswählen, erreichen wir eine hocheffektive Suche bei deutlich geringerer Latenz.
Die Verbesserung der ersten Suche hängt stark von der Trainingsumgebung (Training Harness) ab. Unsere Umgebung stellt dem Modell die Benutzeranweisungen und das präzise Schema des zugrunde liegenden Retrieval-Index zur Verfügung und leitet diese an alle nachfolgenden Phasen der Query- und Filtergenerierung, des Rerankings und der Antwortgenerierung weiter. Wir haben in unserem früheren Instructed Retriever-Blog beschrieben, wie dies erreicht werden kann, und wir verwenden dieselbe Suchumgebung beim Training unseres Instructed-Retriever-1-Modells. Dieser Ansatz ist besonders wichtig für Fragen in Unternehmen (Enterprise-Fragen), die häufig domänenspezifische Einschränkungen wie Zeitraum, Organisation, Dokumententyp oder Produktbereich beinhalten.
Parallele Query- und Filtergenerierung verbessert den Recall der Kandidatenmenge, indem gleichzeitig mehrere Formulierungen und Aspekte derselben Anfrage untersucht werden. Dadurch kann das System eine breitere Suche durchführen und gleichzeitig die Latenz niedrig halten. Eine breitere Suche stellt eine Herausforderung bei der Aggregation dar. Verschiedene Formulierungen können sich überschneidende oder nur teilweise relevante Chunks zurückgeben. Um den nützlichsten Kontext aus der zusammengeführten Kandidatenmenge auszuwählen, verwenden wir einen Multi-Pivot gruppenweisen Reranker. Die Kandidaten werden in parallelen Gruppen eingestuft, die jeweils durch einen oder mehrere Pivot-Chunks verankert sind, und die Gruppen-Rankings werden zu einer endgültigen Reihenfolge zusammengeführt. Dies nutzt die wesentlichen Vorteile des Vergleichs von Belegen im Kontext und hält gleichzeitig das Reranking effizient.
Zusammen bieten diese Phasen zwei Stellschrauben für das Test-Time-Scaling: Die Erhöhung der Anzahl der Query- und Filterformulierungen verbessert den Recall, während die Erhöhung der Anzahl der Pivots die Precision verbessert. Da beide Phasen Parallelität nutzen können, kann das System zusätzliche Rechenleistung zur Testzeit gegen einen qualitativ hochwertigeren Kontext eintauschen und gleichzeitig eine niedrige Latenz beibehalten.
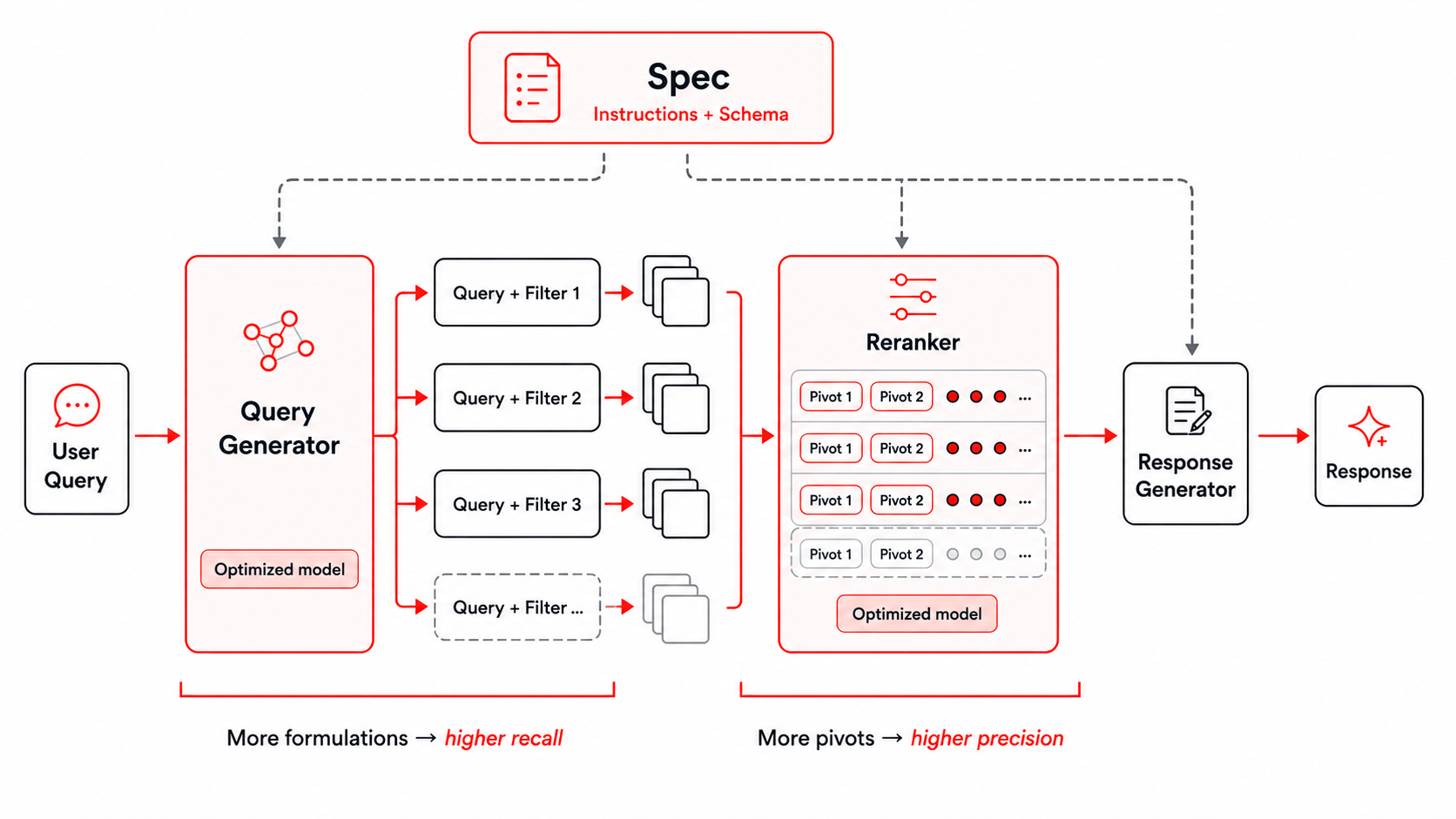
Abbildung: Die für Instructed-Retriever-1 verwendete Suchumgebung.
2. Training von Instructed-Retriever-1
Paralleles Test-Time-Scaling für die Suche erfordert ein Modell, das zwei Dinge gut beherrscht: effektive Suchen zu generieren und abgerufene Belege zu bewerten. Wir haben Instructed-Retriever-1 als ein einzelnes, auf Retrieval spezialisiertes Modell trainiert, das parallele Query-Generierung und Reranking unterstützt. Das Ergebnis ist ein Modell, das die Retrieval-Qualität von Claude Sonnet 4.5 auf KARLBench erreicht und gleichzeitig eine niedrige Latenz beibehält.
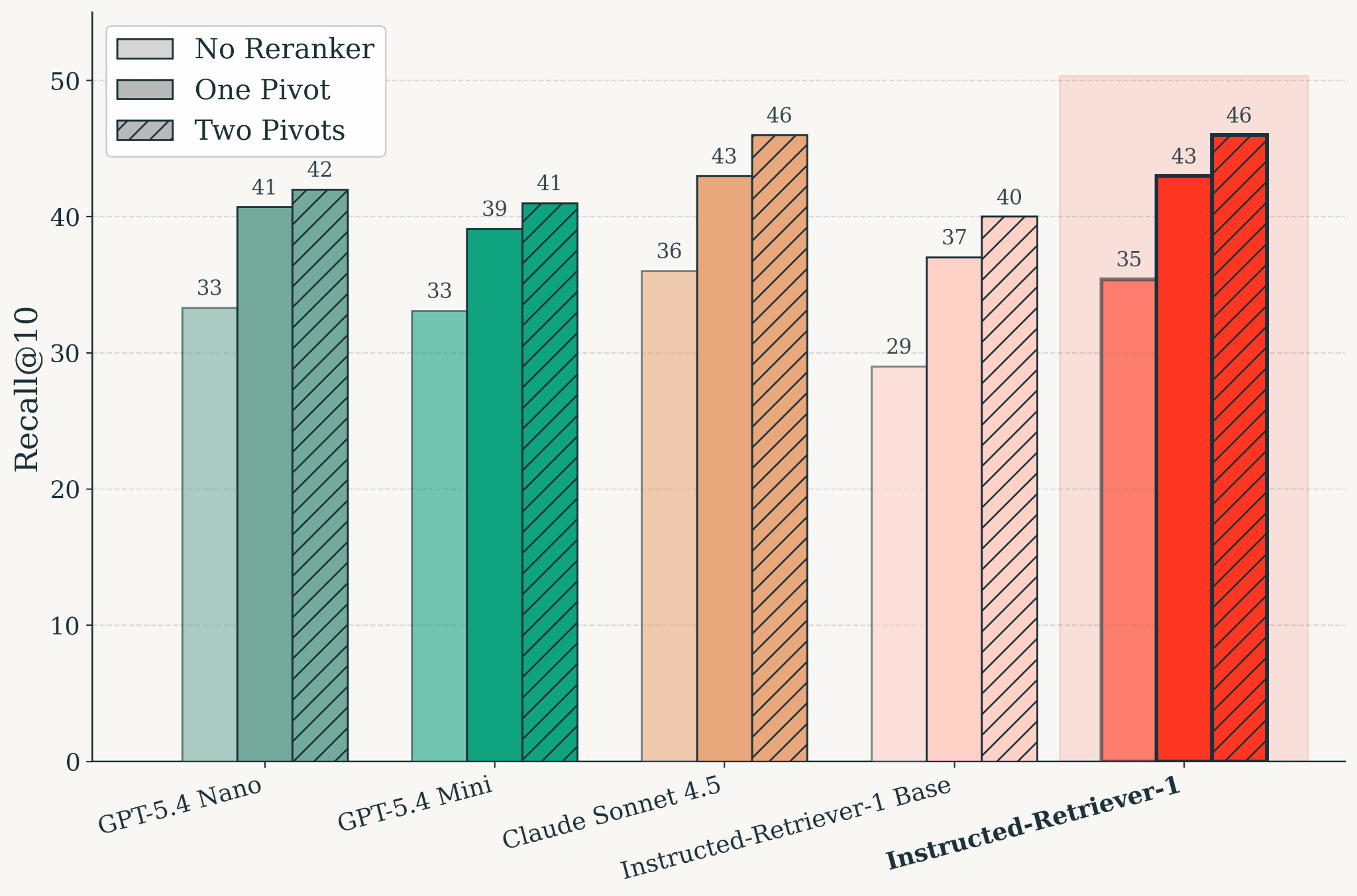
Abbildung: Retrieval-Qualität auf KARLBench nach dem Training, evaluiert über verschiedene Reranking-Konfigurationen hinweg. Instructed-Retriever-1 erreicht die Retrieval-Qualität von Claude Sonnet 4.5. Modellübergreifend verbessert das Pivot-basierte Reranking den Recall@10 im Vergleich zur Einstellung ohne Reranker, und zwei Pivots verbessern die Qualität im Vergleich zu einem Pivot weiter.
Um die Daten für das Training vorzubereiten, erstellen wir unabhängig von unserem Evaluierungs-Benchmark synthetische Retrieval-Umgebungen im Enterprise-Stil aus einem breiten Pretraining-Korpus. Wir erstellen sie mithilfe des agentischen Datensynthese-Ansatzes, der im KARL-Bericht beschrieben ist. Die resultierenden Umgebungen spiegeln die Arten von Aufgaben wider, die der Knowledge Assistant bewältigen muss, einschließlich der Suche nach Fakten, Zusammenfassungen, Empfehlungen, Problemlösungen und Entscheidungsunterstützung über Korpora hinweg, die unstrukturierte Dokumente mit strukturierten Metadaten kombinieren.
Das Modell wird in zwei Phasen trainiert, um mehrere Suchfunktionen zu erfassen. Das resultierende Modell unterstützt sowohl die Query- und Filtergenerierung als auch verifizierungsartige Retrieval-Funktionen, was die beiden Phasen ermöglicht, die das parallele Test-Time-Scaling in der Praxis nützlich machen.
3. Validierung von Instructed-Retriever-1 in der Produktion
Eine Verbesserung des Retrievals ist nur dann von Bedeutung, wenn sie bei realistischen Workloads funktioniert und die Latenzbeschränkungen in der Produktion einhält. Wir evaluieren Instructed-Retriever-1 auf einem großen internen Datensatz, der repräsentativ für die Nutzung des Knowledge Assistant ist, und messen, ob die beiden oben vorgestellten Skalierungsmechanismen die Retrieval-Qualität verbessern: parallele Query- und Filtergenerierung für den Recall und Multi-Pivot-Reranking für die Precision.
Abbildung: Demonstration des Knowledge Assistant, unterstützt durch Instructed-Retriever-1.
Retrieval-Qualität bei realistischen Workloads
Unser Evaluierungsdatensatz basiert auf realen Workloads des Knowledge Assistant, bei denen nützliche Antworten oft mehrere unterstützende Belege erfordern und nicht nur ein einziges Ground-Truth-Dokument. Wir evaluieren das Retrieval in zwei Phasen. Zuerst messen wir die Latenz und Qualität der Query-Generierung über alle Kandidatensysteme hinweg. Für die Qualität verwenden wir LLM-Judge-Bewertungs-Scores für Spezifität, Breite und Relevanz. Diese Metriken erfassen, ob generierte Queries zielgerichtet sind, die wichtigen Aspekte der Anfrage abdecken und für die Beantwortung der Frage nützlich bleiben.
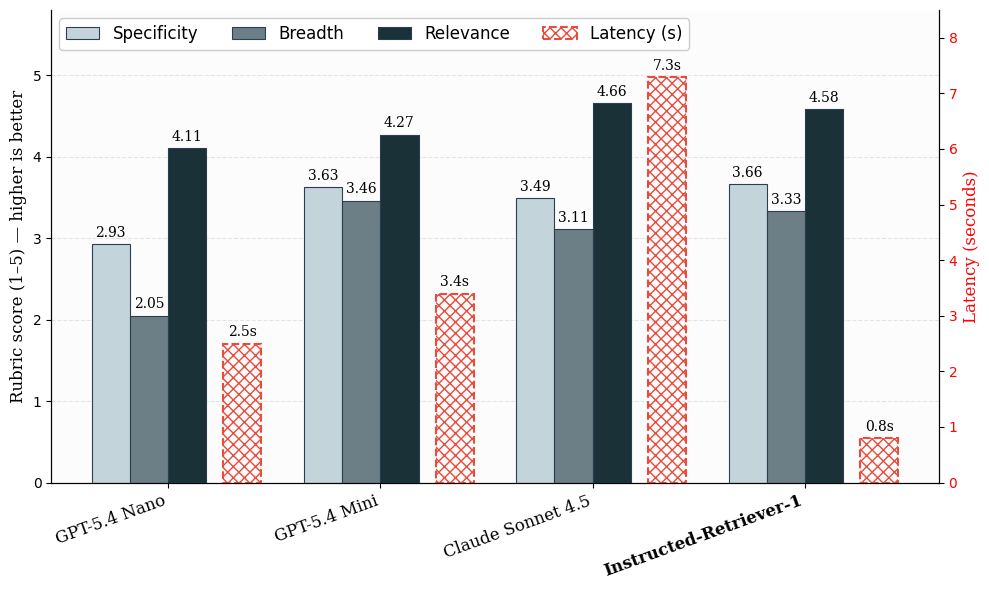
Abbildung: Qualität und Latenz der Query-Generierung bei produktionsnahen internen Beispielen. Mittlere Bewertungs-Scores beurteilen die Qualität der Query-Generierung in Bezug auf Spezifität, Breite und Relevanz auf einer Skala von 1 bis 5. Die Latenz wird für eine Query-Generierungsphase berechnet.
Für das Reranking halten wir die abgerufene Kandidatenmenge konstant und bewerten, wie effektiv jeder Reranker die nützlichsten Belege hervorhebt. Um dichte Relevanz-Labels zu erhalten, nutzen wir einen LLM-Judge, um jeden Chunk auf einer TREC-artigen Relevanzskala von 0 bis 3 zu bewerten, und berechnen anschließend nDCG@10 aus den resultierenden Rankings. Claude Sonnet 4.5 und Instructed-Retriever-1 erreichen dabei 80,1 bzw. 81,0 nDCG@10. Dies entspricht einer Steigerung von +12,8 % bzw. +14,1 % im Vergleich zu einem Szenario ohne Reranking, was die Effektivität unseres Multi-Pivot-Groupwise-Rerankers demonstriert.
Insgesamt schneidet Instructed-Retriever-1 bei realistischen Workloads in den Rubrik-Metriken für die Query-Generierung stark ab und bleibt beim Reranking im Vergleich mit der stärksten Baseline wettbewerbsfähig. Dies spricht für den Einsatz eines einzigen, auf Retrieval spezialisierten Modells sowohl für die Query-Generierung als auch für die Kandidatenauswahl.
Serving-Performance
Eine parallele Skalierung zur Testzeit ist nur dann nützlich, wenn die zusätzliche Rechenleistung effizient bereitgestellt werden kann und mit der Anzahl der Suchen skaliert. Zu diesem Zweck nutzt Instructed-Retriever-1 eine Mixture-of-Experts-Architektur sowie Serving-Optimierungen wie FP8-Quantisierung,2 spekulative Decodierung und zusätzliche Infrastruktur-Anpassungen für die gesamte Retrieval-Pipeline. In unseren Evaluierungen zeigt FP8 keinen Qualitätsverlust, während es die Inferenzgeschwindigkeit und den Durchsatz im Vergleich zu BF16 verbessert.3 Spekulative Decodierung bringt eine zusätzliche Beschleunigung von über 30 % für den kombinierten Pfad aus Query-Generierung und Reranking.
Fazit
Dieses Update bringt die parallele Skalierung zur Testzeit in den produktiven Such-Stack. Das System sucht breit gefächert über parallele Query- und Filtergenerierung und führt anschließend ein präzises Reranking mittels Multi-Pivot-Belegsvergleich durch. Instructed-Retriever-1 treibt beide Phasen mit einem einzigen, auf Retrieval spezialisierten Modell an, das für die Suchgenerierung und das Ranking von Belegen trainiert wurde. Das Ergebnis ist ein Knowledge Assistant, der sowohl besser als auch schneller ist: Die Suchzeit sinkt um mehr als das 3-Fache, die Zeit für die Antwortgenerierung halbiert sich, die TTFT liegt bei etwa 2 s und die End-to-End-Latenz liegt in unserem Offline-Evaluierungs-Setup konsistent unter 10 s.¹ Frühe Nutzer wie die Baylor University und andere bemerken bereits den Unterschied.
"(Das neue Erlebnis ist) prägnanter, fühlt sich reaktionsschneller an und bringt wichtige Informationen schneller zum Vorschein – eine spürbare UX-Verbesserung für unsere Anwendungsfälle." —Kyle Van Pelt, Director of Process and Governance, Enrollment Management an der Baylor University.
Holen Sie noch heute mehr aus Ihrem Knowledge Assistant heraus. Der Rollout von Instructed-Retriever-1 für alle Kunden hat begonnen. Er hilft Teams dabei, qualitativ hochwertigeren Kontext mit weniger Wartezeit abzurufen. Sie können mehr Fragen stellen, mehr Wissen aufdecken und schneller von der Frage zur Antwort gelangen. Probieren Sie es jetzt aus.
1 Latenzschätzungen gemessen als Durchschnitt über Offline-Evaluierungen hinweg, mit einer durchschnittlichen Länge von etwa 256 Output-Token. Die tatsächliche Latenz kann je nach Datenstruktur in bestimmten Knowledge Assistant-Instanzen und -Queries variieren.
2 Wir verwenden die ModelOpt-Bibliothek von NVIDIA für die FP8-Quantisierung.
3 Wir haben die BF16- und FP8-Modelle auf KARLBench in 10 Testläufen evaluiert. FP8 zeigte keinen statistisch signifikanten Qualitätsverlust im Vergleich zu BF16: Die mittlere Score-Differenz betrug +0,33 Punkte, mit einem Standardfehler von 1,69 Punkten und einem 95%-Konfidenzintervall von [-2,99, 3,65].
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.