Databricks für die Gute und Tugend Stiftung: Partnerschaft zur Verbindung von medizinischen Freiwilligen mit kritischen Gesundheitsdiensten in 72 Ländern
von Priyanka Mehta und Shaunak Sen
- Die Virtue Foundation hat mit Databricks for Good zusammengearbeitet, um KI einzusetzen und die globale Gesundheitsversorgung zu verbessern.
- Dies hat dazu geführt, dass die Virtue Foundation die Fähigkeiten von Klinikern besser auf Freiwilligenarbeit in Entwicklungsländern abstimmen kann, wo diese Fähigkeiten am dringendsten benötigt werden.
- Gemeinsam stellen die Teams von Databricks und der Virtue Foundation aktualisierte Kerndatensätze in einem leicht zugänglichen und umsetzbaren Format bereit.
Einleitung
Die Virtue Foundation ist eine gemeinnützige Organisation, die sich auf die globale Gesundheitsversorgung konzentriert und einen effizienten Marktplatz für globale philanthropische Gesundheitsversorgung schafft. Bis heute haben sie über 50.000 Patienten versorgt, mit einem besonderen Schwerpunkt auf Ghana und der Mongolei. Das Rückgrat dieses Marktplatzes ist die Kuratierung von globalen Daten zu Gesundheitseinrichtungen über VF Match, eine Plattform, die medizinisches Fachpersonal mit ehrenamtlichen Tätigkeiten in 72 Ländern mit niedrigem und niedrigem mittlerem Einkommen verbindet. Databricks for Good arbeitet seit 2024 eng mit der Virtue Foundation zusammen, um KI einzusetzen, Daten aus diesen Ländern zu aggregieren und sie nutzbar zu machen.
Ein erster Proof of Concept zeigte, dass LLMs strukturierte Informationen aus unterschiedlichen Webdatenquellen extrahieren können, um eine Karte der Gesundheitsinfrastruktur und vor allem der Lücken in der Versorgung in unterversorgten Gebieten zu erstellen. Die Skalierung dieser Funktionalität und die Überführung in die Produktion stellten jedoch viele Herausforderungen dar. Seit dieser ersten Iteration haben wir eine auf Databricks basierende Plattform entwickelt, die den POC in ein produktionsreifes System verwandelt hat, das Daten von Tausenden von Gesundheitseinrichtungen und Non-Profit-Organisationen weltweit aggregiert.
In diesem Artikel beschreiben wir, wie wir unsere bisherige Arbeit verbessert haben, um die Virtue Foundation weiter zu befähigen, ihre Gemeinschaft von medizinischen Freiwilligen mit kritischen Bedürfnissen in diesen Ländern abzugleichen.
Grundlagen schaffen: 72 Länder mit Gesundheitsdaten
Der Kern von VF Match ist der Foundational Data Refresh (FDR): ein umfassender Datensatz von Gesundheitseinrichtungen und Non-Profit-Organisationen, der von Grund auf aus verschiedenen webbasierten Quellen aufgebaut wird. Wir nehmen systematisch Daten aus 72 Ländern mit niedrigem und niedrigem mittlerem Einkommen weltweit auf und aktualisieren sie.
Zwei ergänzende Datenquellen treiben diesen Refresh an:
- Overture Maps: Ein Open-Source-Geodaten-Datensatz von Meta und Microsoft, der autoritative Standorte für Gesundheitseinrichtungen bereitstellt.
- Bright Data: Industrielle Web-Scraping-Infrastruktur, die Echtzeitinformationen aus dem Internet erfasst.
Das Herzstück von FDR ist eine Informationsextraktionspipeline, die von den GPT-Modellen von OpenAI angetrieben wird. Die Verarbeitung von mehr als 25 Millionen Webseiten durch LLMs mit Produktionsgarantien erforderte ein Umdenken bei traditionellen LLM-Inferenzpipelines. Anstatt eine One-Shot-Extraktion zu versuchen, zerlegt unsere Pipeline die Aufgabe in gezielte Schritte: Klassifizierung der medizinischen Relevanz, Identifizierung des Organisationstyps (entweder eine medizinische Einrichtung oder eine NGO) und Extraktion von Fachgebieten, Ausrüstung und Verfahren.
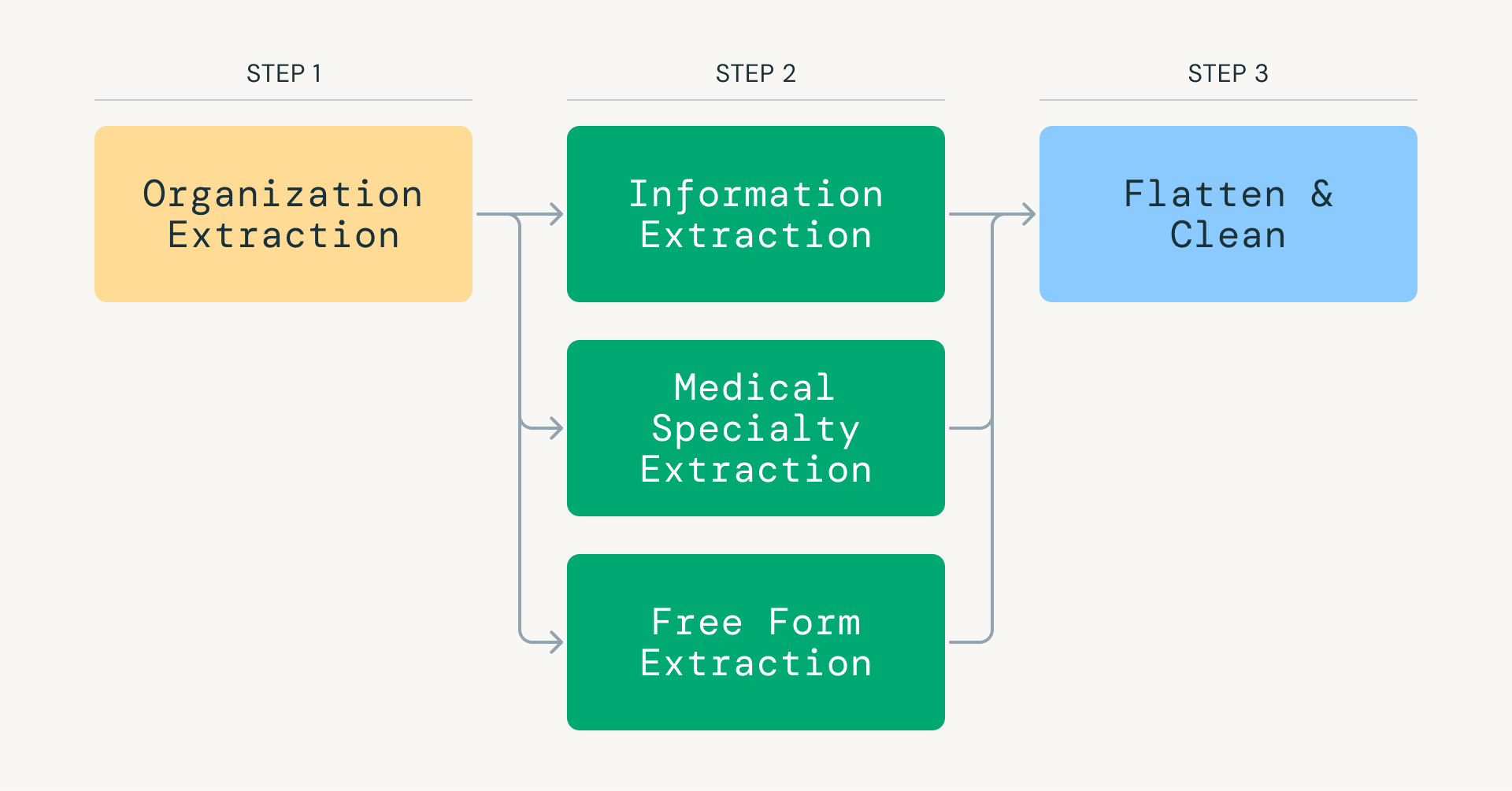 Abb. 1: Wichtige Schritte des Foundational Data Refresh (FDR).">
Abb. 1: Wichtige Schritte des Foundational Data Refresh (FDR).">Dieser Ansatz reduziert den Token-Verbrauch drastisch und konzentriert jede Modell-Injektion auf eine enge, hochpräzise Aufgabe. Databricks und Apache Spark werden verwendet, um die gesammelten Daten effizient zu orchestrieren und zu parallelisieren, Workloads über Tausende von Exekutoren zu verteilen und LLM-Inferenz mit hohem Durchsatz zu ermöglichen.
Eine Reihe kritischer Funktionen machen diese Pipeline skalierbar und produktionsreif:
- Erweiterbare Datenmodellierung: Daten werden in jedem Schritt in einem Star-Schema gespeichert, was die nachgelagerte Analyse vereinfacht und die Abfrageleistung verbessert.
- Statusbasierte Checkpoints: Jeder Datensatz verfolgt seinen Verarbeitungsstatus, sodass Pipelines von jedem Punkt aus fortgesetzt werden können, ohne Zeilen mit teuren LLM-Aufrufen erneut verarbeiten zu müssen.
- Konfigurierbare Extraktionsregistrierung: Jede Extraktionsmethode wird durch ein strukturiertes Objekt gesteuert, das den System-Prompt angibt, wodurch die Extraktionslogik modular, reproduzierbar und erweiterbar wird.
- Skalierbare verteilte Verarbeitung: Das System verarbeitet verzerrte Multi-Terabyte-Workloads mithilfe von Spark für Parallelität, Photon für Leistung im großen Maßstab und produktionsreifen Orchestrierungsfunktionen.
Diese Garantien werden durch Lakeflow Jobs durchgesetzt, die mehr als 15 voneinander abhängige Aufgaben mit bedingter Verzweigung, paralleler Ausführung und intelligenten Wiederholungsrichtlinien orchestrieren. Das Ergebnis ist ein System, das Daten von Gesundheitseinrichtungen im großen Maßstab mit der Präzision von medizinischen Experten verarbeitet.
Entity Resolution im großen Maßstab
Sobald die Daten von Einrichtungen und Non-Profit-Organisationen mithilfe eines LLM gesammelt und extrahiert wurden, entsteht eine klassische Herausforderung: Entity Resolution. Dieselbe Einrichtung kann in mehreren Datenquellen mit Namensvariationen, inkonsistenten Adressen oder fehlenden Kontaktdaten erscheinen. Traditionelle Deduplizierung scheitert in diesen Szenarien aufgrund unsauberer Daten, daher verwenden wir Splink, ein Open-Source-Framework für probabilistische Record Linkage. Anhand der in unserem IE-Schritt gesammelten Informationen bewertet Splink übereinstimmende Paare durch gewichtete Vergleiche über Felder wie Telefonnummer, Straßenadresse und mehr. Das Ergebnis ist ein einheitlicher Schlüssel pro Einrichtung, der sicherstellt, dass Endbenutzer einen autoritativen Datensatz für jede medizinische Einrichtung und NGO sehen.
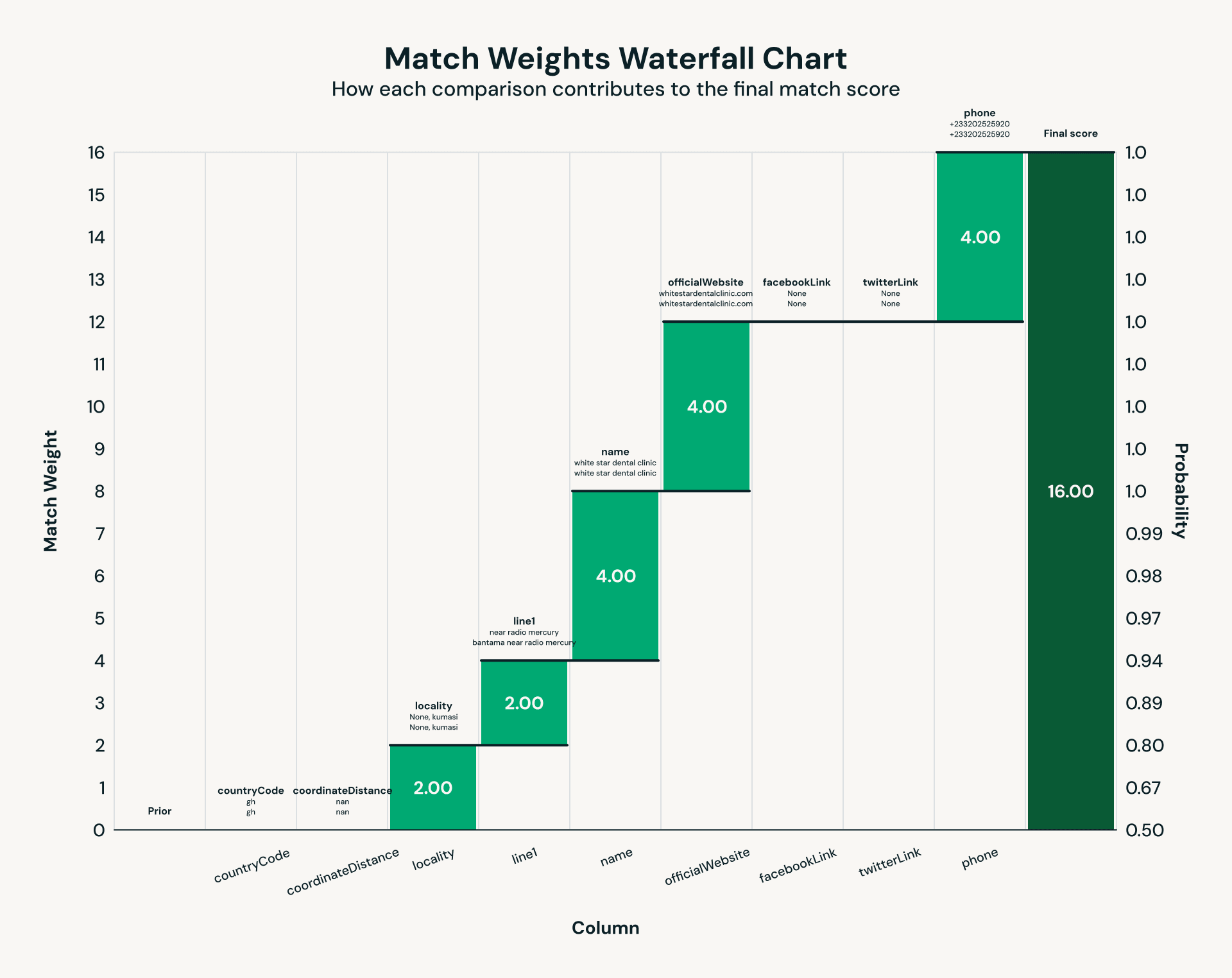 Abb. 2: Beispiel-Regelsatz für Entity Resolution mittels Splink.">
Abb. 2: Beispiel-Regelsatz für Entity Resolution mittels Splink.">Die Durchführung von probabilistischen Abgleichen für Tausende von Gesundheitseinrichtungen und Non-Profit-Organisationen deckte klassische Leistungsengpässe auf, die bei Terabyte-Skalierung auftreten. Der Kern des Record Linkage ist der paarweise Vergleich, der von Natur aus verzerrte Workloads erzeugt: Häufige Vergleiche erzeugen massive Partitionen, während die meisten anderen viel kleiner bleiben. Frühe Läufe machten dies schmerzlich deutlich, mit einer Spark-Partition, die 30 Minuten lief, während die Median-Partition in 52 Sekunden abgeschlossen war – ein Lehrbuchfall von „Stragglern“ (dem „Fluch des letzten Reducers“), die die Job-Leistung beeinträchtigen. Die Aktivierung von Photon, der vektorisierten Abfrage-Engine von Databricks, reduzierte die schlimmsten Datenpartitionen von 30 Minuten auf etwa 2 Minuten: eine 15-fache Verbesserung.
VF Agent: Natürliche Sprache trifft auf Gesundheitsdaten
Mit Blick auf die Zukunft haben wir einen Prototyp eines Agenten entwickelt, der es Experten ermöglicht, Daten mithilfe natürlicher Sprache zu analysieren. Wir verwenden eine Multi-Agenten-Architektur, die in LangGraph aufgebaut ist, und nutzen Databricks Model Serving, AI Search und Genie.
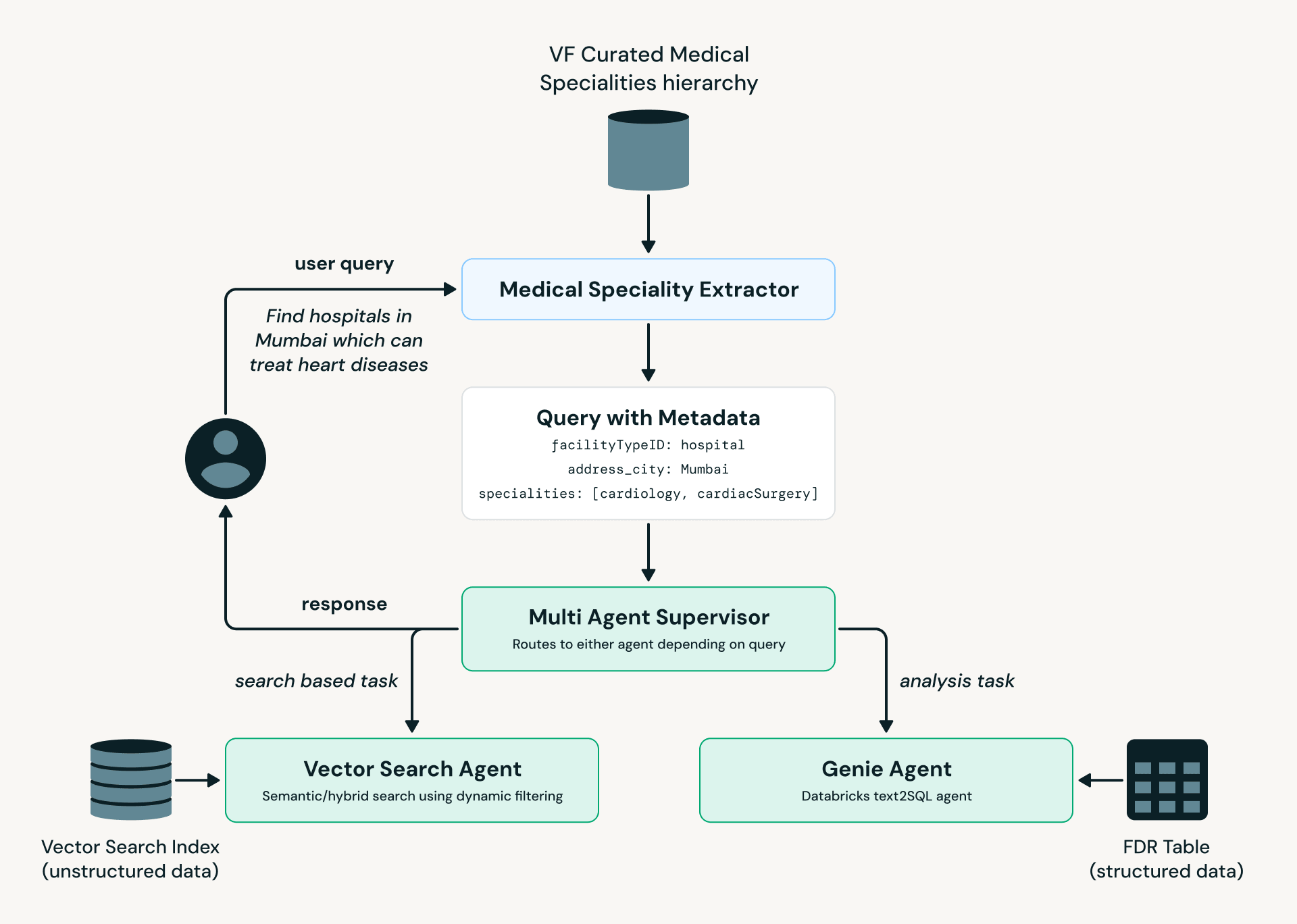 Abb. 3: VF Agent: Prozessflussdiagramm">
Abb. 3: VF Agent: Prozessflussdiagramm">Wie im obigen Diagramm dargestellt, wandelt der Medical Specialty Extractor die Sprache des Benutzers in standardisierte medizinische Terminologie um, die dann an den Multi-Agent Supervisor weitergeleitet wird. Je nach Absicht und Komplexität der Abfrage wird sie entweder an den AI Search Agent (Einrichtungsfindung und -suche) oder an den Genie Agent (analytische Abfragen gegen strukturierte Daten) weitergeleitet.
Zusammenfassung
Gesundheitsexperten können nun schneller aktuelle Möglichkeiten entdecken, Übereinstimmungen mit ihren medizinischen Fachgebieten finden und auf globale Daten zu Tausenden von Einrichtungen weltweit zugreifen. Die Reise der Virtue Foundation vom Proof of Concept zur Produktion zeigt, was möglich ist, wenn fortschrittliche KI-Systeme mit einer einheitlichen Datenplattform kombiniert werden.
Das Endergebnis ist eine globale Sicht auf die Gesundheitsinfrastruktur – die aufzeigt, wo medizinische Freiwillige am dringendsten benötigt werden.
Wenn Sie mehr über dieses Projekt erfahren möchten, sehen Sie sich bitte an:
- Databricks x Virtue Foundation Project Overview - YouTube
- UN Bloomberg Interview (YouTube) - ca. Minute 38:00
- Video-Testimonial: Bright Initiative x Virtue Foundation x Databricks
Lesen Sie mehr über einige unserer anderen Databricks for Good-Projekte unten:
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.