MemEx: Ein programmierbares Scratchpad für LLM-Agenten
Im Jahr 1945 stellte sich Vannevar Bush eine schreibtischgroße Maschine vor, die das Gedächtnis eines Wissenschaftlers erweitern sollte, indem sie jedes Dokument, jede Anmerkung und jeden Gedankengang speicherte, um sie bei Bedarf abzurufen. Er nannte sie MemEx. Bush löste ein menschliches Problem: Köpfe, die von Informationen überflutet wurden, die sie nicht griffbereit halten konnten. Acht Jahrzehnte später stoßen LLM-Agenten auf eine bemerkenswert ähnliche Barriere.
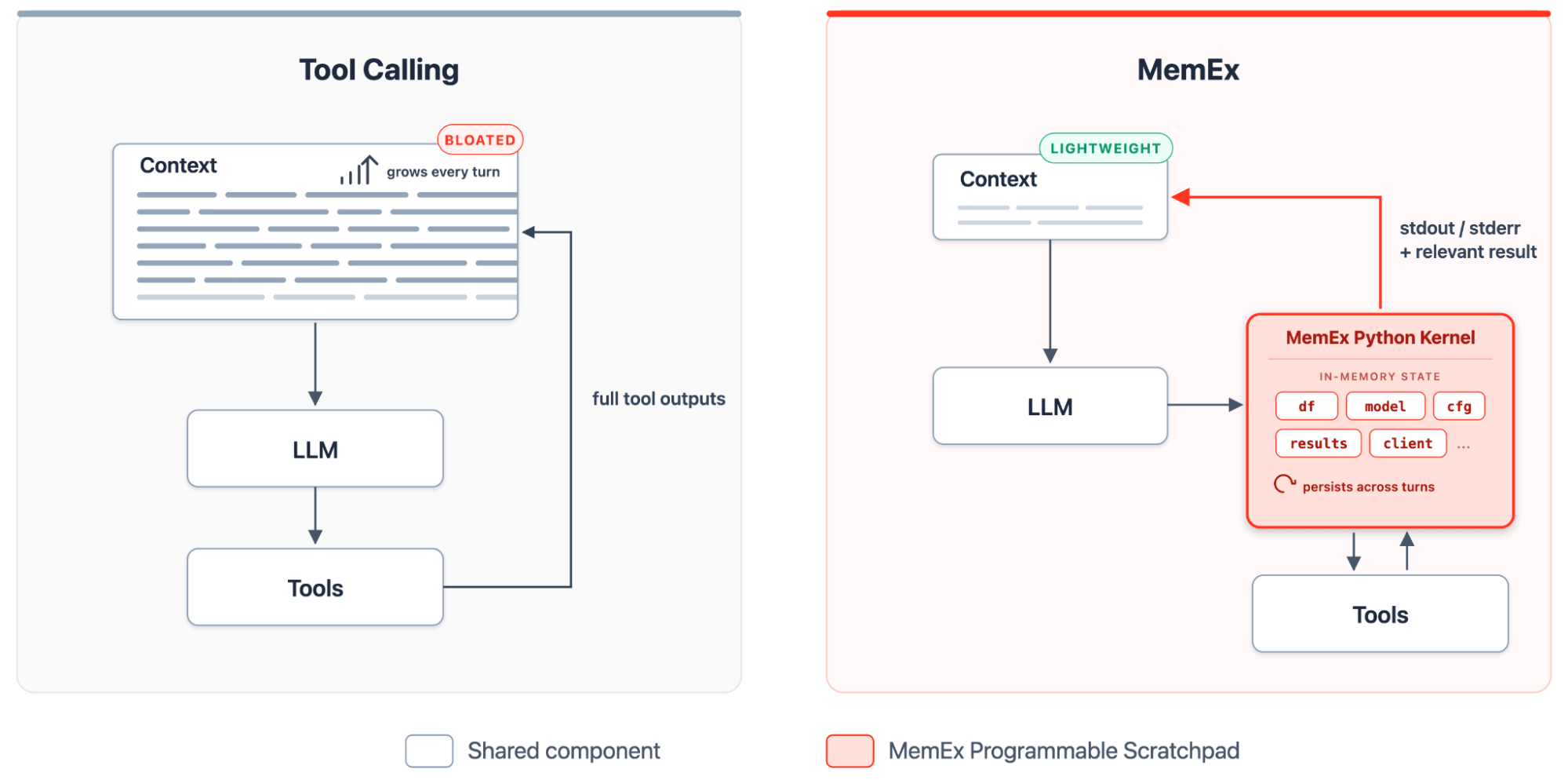
Im aktuellen Agentic-Tool-Calling-Paradigma ist das Kontextfenster das einzige persistente Substrat, auf dem das Modell operieren kann. Es ist ein gemeinsam genutzter Bereich, der den System-Prompt, die Benutzeranfrage, den Denkprozess des Modells, Tool-Aufrufe und rohe Tool-Ausgaben enthält. Tool-Ausgaben sind dabei das größte Problem: Eine einzige SQL-Abfrage kann Millionen von Zeilen zurückgeben, und in den heutigen Harnesses werden diese Zeilen bei jedem folgenden Schritt mitgeschleift, selbst wenn nur eine einzige Zelle von Bedeutung war. Der Agent hat keine Möglichkeit, das Ergebnis aufzuteilen, zusammenzufassen oder abzulegen, bevor es das Fenster überflutet.
Bei Databricks stoßen wir ständig an diese Grenze. Unsere produktiven Agenten, von Genie bis Agent Bricks, stoßen irgendwann auf dieselben Kontextbeschränkungen. Genie ist ein gutes Beispiel: Eine einzige Abfrage durchsucht den gesamten Workspace eines Kunden und ruft viele Tools auf, um Daten aus Tabellen, Vektorindizes und Dashboards abzurufen. Um dieses Problem zu lösen, haben wir unser eigenes MemEx entwickelt und es in mehreren produktiven und internen Agenten validiert.
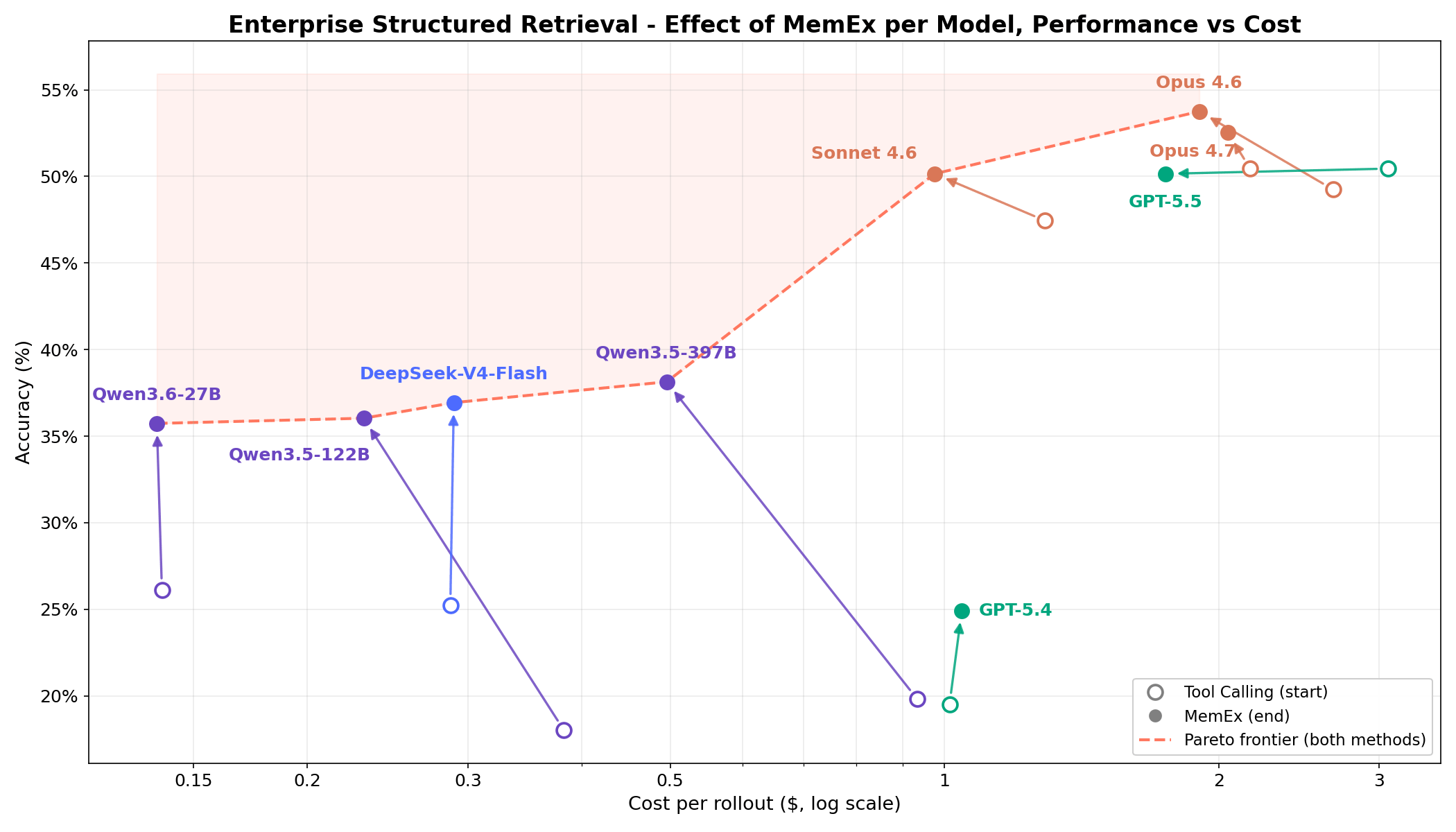
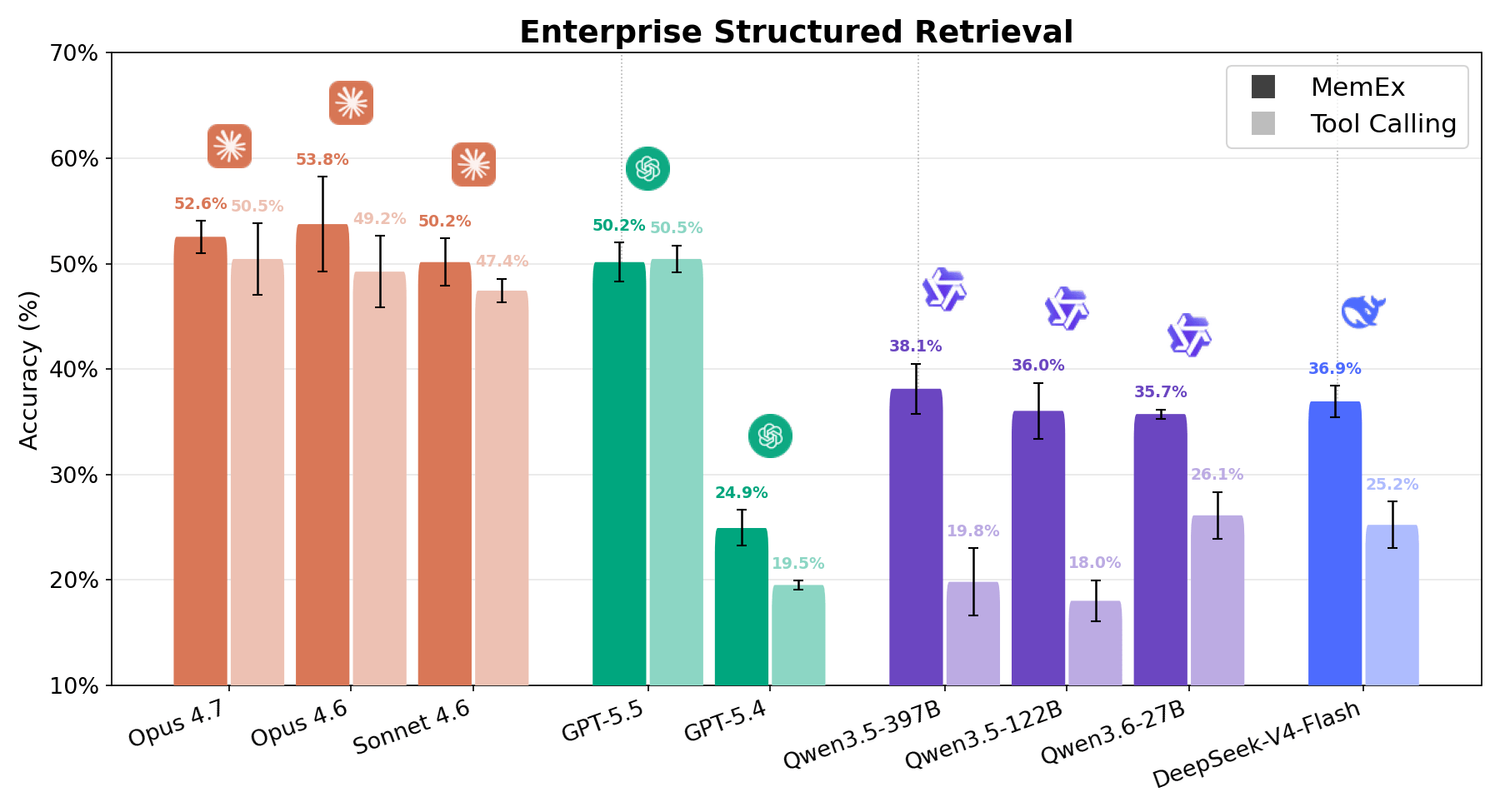
Bei anspruchsvollen strukturierten Retrieval-Aufgaben in Unternehmen zeigt Abbildung 1, dass MemEx die Kosten-Genauigkeits-Grenze für jedes Modell verschiebt. Frontier-Modelle wie Opus 4.6 und Sonnet 4.6 gewinnen 2–5 Prozentpunkte bei 25–30 % geringeren Token-Kosten. Open-Weights-Modelle wie Qwen3.5-122B (18 % → 36 %) und Qwen3.5-397B (20 % → 38 %) verdoppeln ihre Genauigkeit nahezu bei 40–50 % geringeren Token-Kosten. Da MemEx mit beliebig langen Eingaben arbeiten kann, ermöglicht es zudem zwei weitere Anwendungen: die Auditierung von Agenten-Trajektorien (einschließlich der von MemEx selbst), die normalerweise nicht in ein einziges Kontextfenster passen würden, und paralleles Denken über mehrere Trajektorien hinweg.
Wie MemEx funktioniert
{kind=link}
MemEx bietet dem LLM ein programmierbares Scratchpad: einen typisierten Python-Kernel, der Tool-Ausgaben speichert, sie mit Code transformiert und nur die Print-Anweisungen als Token im Kontext materialisiert. In dieser Umgebung wird das Rollout zu einem selbst-erweiternden Python-Programm. Bei jedem Schritt schreibt der Agent einen neuen Block, der Kernel hält den Zustand aufrecht und der nächste Block baut auf dem vorherigen auf. Tools werden als typisierte Python-Funktionen mit typisierten Parametern und typisierten Rückgabewerten bereitgestellt. Tool-Ausgaben landen als Python-Objekte im Scope von MemEx, wo sie über Schritte hinweg bestehen bleiben. Der Agent verknüpft sie mit Code, definiert Hilfsfunktionen, wenn sich ein Muster wiederholt, und startet Sub-Agenten als asynchrone Funktionsaufrufe über denselben Scope.
MemEx gehört zur „Code-as-Action“-Familie, die durch CodeAct (Wang et al., 2024) eingeführt wurde, mit Produktionsvarianten in Anthropics Programmatic Tool Calling und Cloudflare Code Mode. MemEx hebt sich ab, indem es sich nahtlos in ein bestehendes agentenbasiertes Framework im ReAct-Stil (Yao et al., 2022) integriert – mit persistentem Scope, Sub-Agenten-Primitiven und integrierten typisierten Rückgaben. Zusammen erschließen diese Funktionen Möglichkeiten, die dem JSON/XML-Tool-Calling-Paradigma fehlen:
- Verarbeitung beliebig großer Eingaben: Dokumente, Datensätze und andere große Objekte können als Variablen im Python-Scope gehalten werden.
- Rückgabe typisierter Objekte: Tool-Ausgaben sind typisierte Python-Objekte, die im Speicher gehalten werden, und keine Strings, die das Modell bei jedem Schritt materialisieren oder neu parsen muss.
- Verknüpfen von Tool-Aufrufen: Die Ausgabe eines Aufrufs fließt innerhalb einer einzigen Codezeile direkt in die Argumente des nächsten Aufrufs. Zwischenergebnisse müssen nicht im Kontext des Agenten materialisiert werden.
- Aufteilen von Tool-Ausgaben: Ausgaben können im Code vorverarbeitet, gefiltert oder zusammengefasst werden, bevor das Modell sie sieht.
- Starten asynchroner Sub-Agenten: Agenten können programmatisch Sub-Agenten starten, die parallel zum übergeordneten Agenten ausgeführt werden, und deren Ergebnisse aggregieren, ohne den Umweg über das Hauptmodell zu nehmen.
Beispiel für einen LLM-Agenten mit MemEx
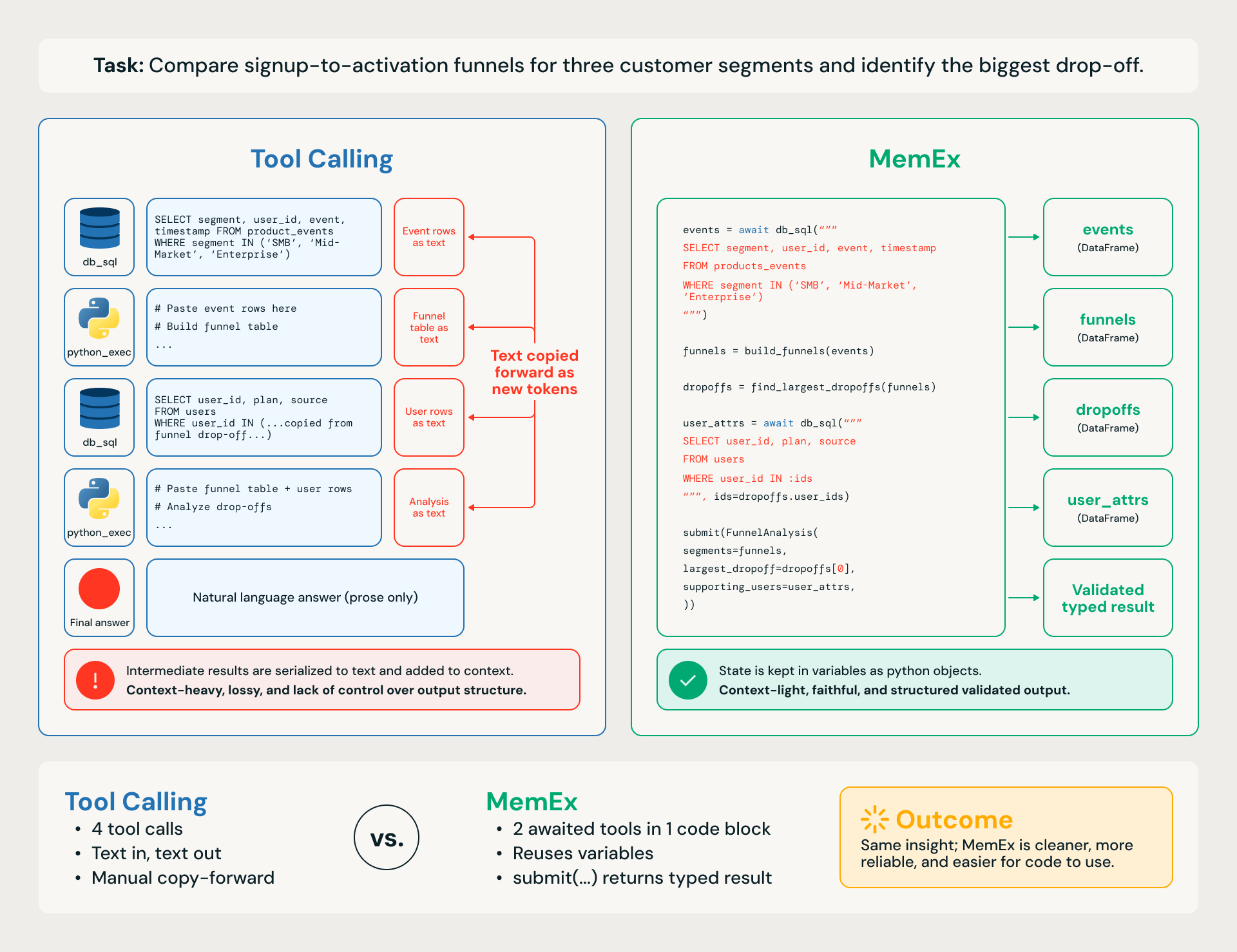
Nehmen wir eine konkrete Aufgabe aus einem Unternehmen, wie den Vergleich von Registrierungs-zu-Aktivierungs-Funnels für drei Kundensegmente und die Identifizierung des größten Drop-offs (Abbildung 1). Der Workflow umfasst vier Schritte:
- Registrierungs- und Aktivierungsereignisse aus dem Data Warehouse abrufen
- diese pro Benutzer zusammenführen
- Conversion-Rates pro Segment für jede Phase berechnen
- die Drop-offs über die Segmente hinweg einstufen.
Ein Tool-Calling-Agent, der mit python_exec ausgestattet ist, arbeitet Schritt für Schritt. Jede SQL-Abfrage und jede programmatische Berechnung ist ein separater Tool-Aufruf, wobei dazwischen liegende DataFrames in Text serialisiert und in nachfolgende Schritte wieder eingefügt werden. Der Trace ist tokenintensiv, was ihn verlustbehaftet, langsam, teuer und anfällig für kleine kaskadierende Fehler in der nachgelagerten Aufgabe macht.
Ein MemEx-Agent schreibt denselben Workflow als einen einzigen Codeblock: Abfragen geben native DataFrames im Scope zurück, Hilfsfunktionen verknüpfen sie und die endgültige Antwort wird als typisiertes, validiertes Objekt über submit() zurückgegeben. Gleicher Gedanke, anderer Aktionsraum.
Für Aufgaben, die sich in Teilprobleme zerlegen lassen, kann der Agent Sub-Agenten aus einem Block heraus starten. Beim Starten von Sub-Agenten kann der übergeordnete Agent gemeinsamen Zugriff auf jedes beliebige Objekt gewähren. Sub-Agenten werden direkt parallel zum übergeordneten Agenten ausgeführt und können nach Abschluss Ergebnisse an den Hauptagenten zurückgeben. Zum Beispiel:
Die rekursive Zerlegung wird zu einem weiteren Ausdruck im selben Python-Programm.
MemEx wurde auf Basis von aroll entwickelt, dem agentenbasierten Rollout-Framework von Databricks. Aroll treibt bereits Produktionssysteme wie Genie, den Supervisor-Agenten von Agent Bricks und Forschungsinitiativen wie KARL an. MemEx klinkt sich in dieselbe Agenten-Schleife und dieselben Tools ein, die aroll bereits für das Tool Calling nutzt.
Wie schneidet MemEx bei agentenbasierten Aufgaben in Unternehmen ab?
Wir haben direkte Vergleiche (Evals) für 9 Frontier-Modelle durchgeführt, bei denen wir parallele strukturierte Tool-Aufrufe (Tool Calling) mit Python-Codeblöcken (MemEx) verglichen haben. Kein Prompt-Tuning, keine aufgabenspezifische Anpassung. Wir vergleichen zwei Arten von agentenbasierten Aufgaben in Unternehmen: fundiertes Lesen über einen großen Textkorpus (OfficeQA) und strukturierte Informationsbeschaffung über einen großen Workspace mit verschiedenen relationalen Daten (Enterprise Structured Retrieval).
Bei beiden Aufgaben ist der MemEx-Agent besser und günstiger als der Tool-Calling-Agent!
{kind=link}
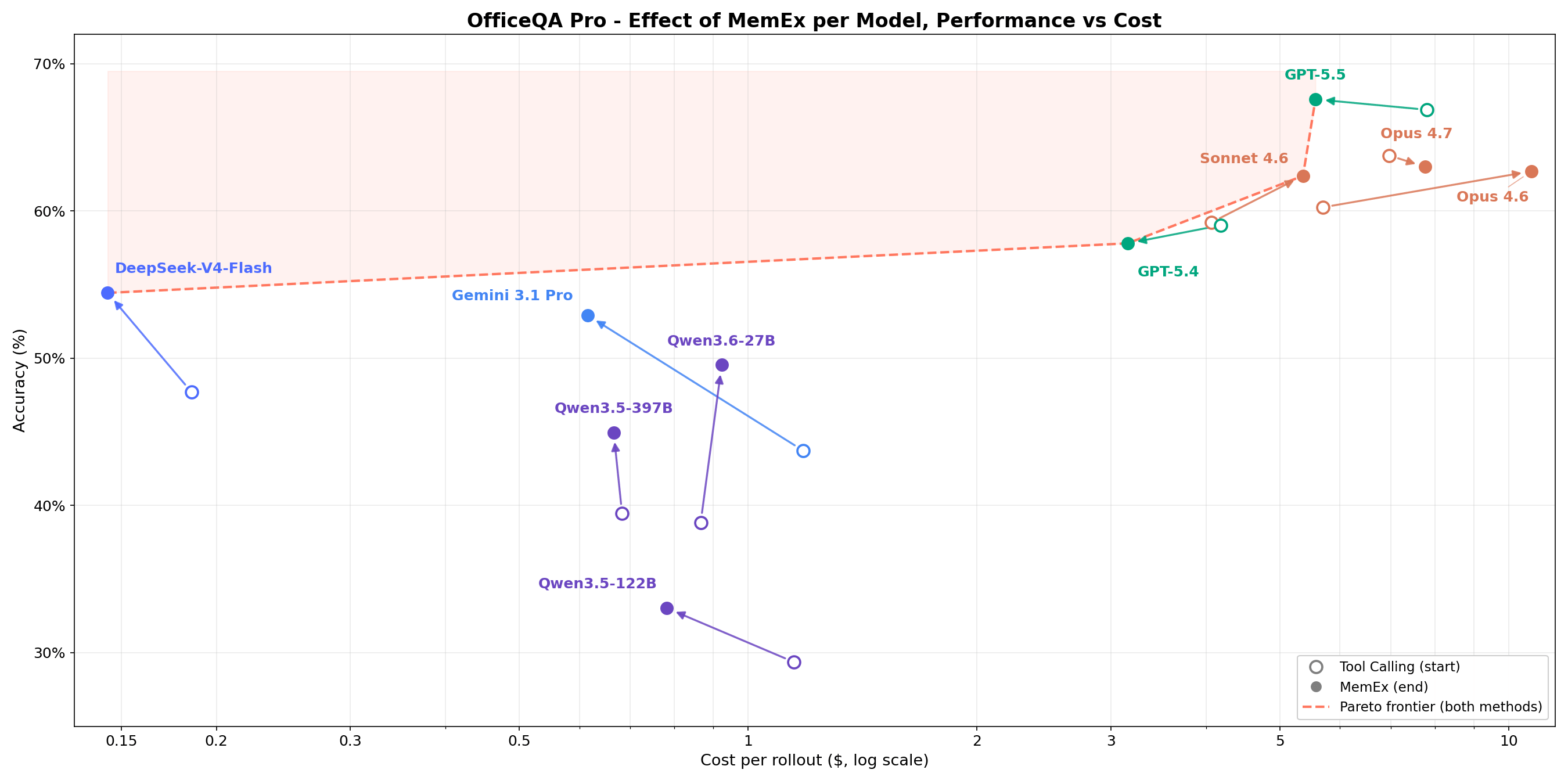
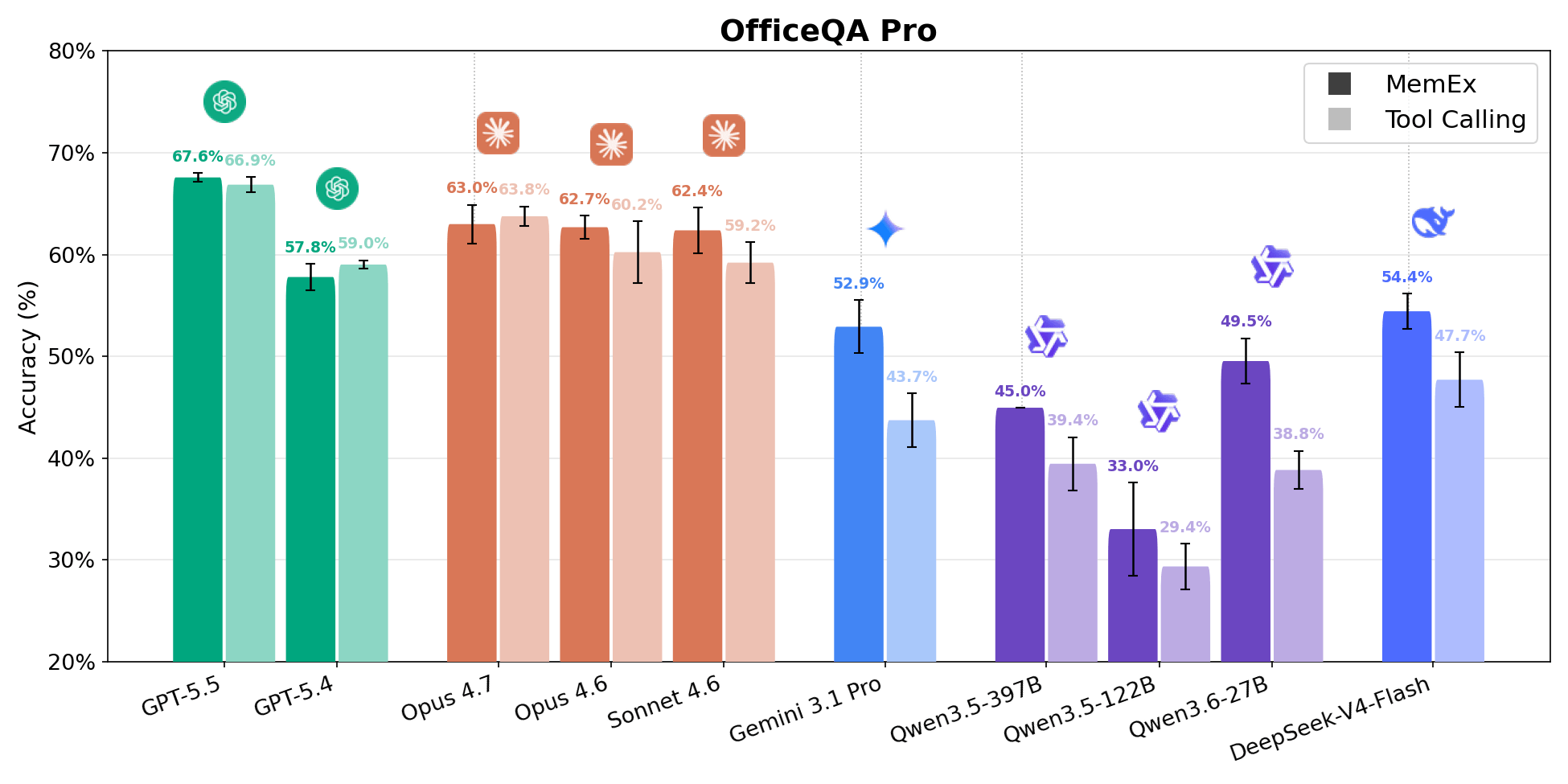
OfficeQA Pro fordert den Agenten auf, Fragen zum fundierten logischen Schließen über das U.S. Treasury Bulletins-Korpus zu beantworten, das rund 89.000 Seiten von 1939 bis heute umfasst. Eine typische Frage erfordert das Finden von Belegen in mehreren Dokumenten, das Navigieren durch Tabellen mit verschachtelten Hierarchien und verbundenen Zellen sowie das Durchführen von Berechnungen auf den abgerufenen Daten. Die Antworten werden nach genauer Übereinstimmung bewertet. Vier der fünf Punkte auf der Pareto-Front für Kosten vs. Genauigkeit sind MemEx-Konfigurationen. Gemini 3.1 Pro MemEx ist mit 0,62 $ pro Rollout (52,9 % Genauigkeit) der günstigste Punkt auf der Pareto-Front, und Sonnet 4.6 MemEx nähert sich der Genauigkeit von GPT-5.5 Tool Calling bei etwa 70 % der Kosten an. Über alle neun Modelle hinweg schneidet MemEx bei jedem Modell gleich gut oder besser ab. Das Mittelfeld bewegt sich am meisten, wobei Qwen 3.6 27B und Gemini 3.1 Pro rund 10 Prozentpunkte zulegen.
{kind=link}
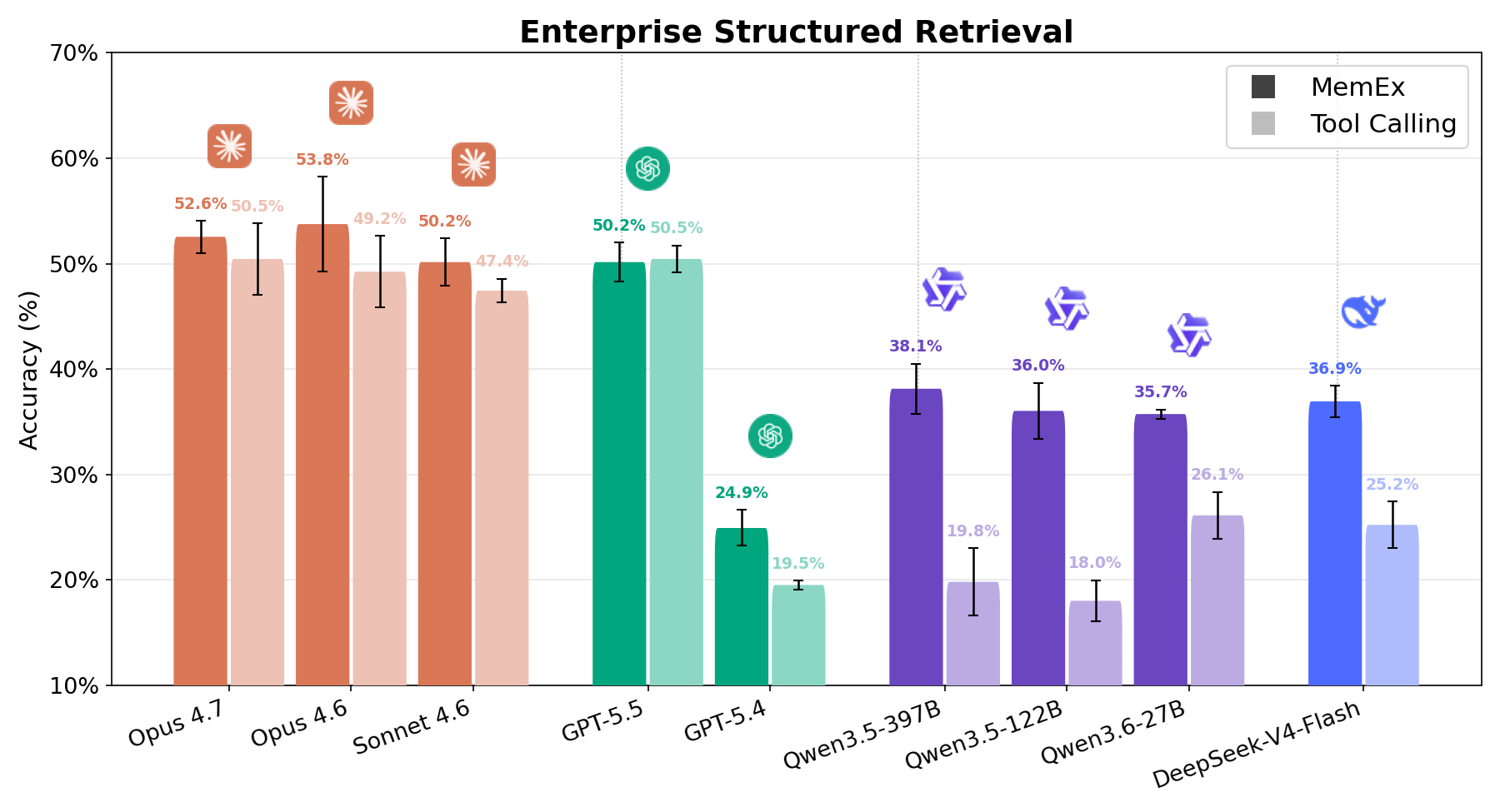
Bei Enterprise Structured Retrieval soll der Agent Fragen in natürlicher Sprache zu relationalen Unternehmensdaten beantworten. Dem Agenten werden Tools für die Schema-Erkennung und SQL-Abfrageausführung zur Verfügung gestellt. Er muss diese verwenden, um die vom Benutzer angeforderte Datenanalyseaufgabe auszuführen – meist mit nur wenigen Informationen darüber, wo im vielfältigen Workspace die relevanten Informationen zu finden sind. Die Antworten des Agenten werden mithilfe von deterministischer Datenvalidierung und LLM-as-a-Judge mit den Ground-Truth-Antworten verglichen. Wie in den Abbildungen 1 und 6 zu sehen ist, zeigt jedes Modell unter MemEx starke Zuwächse, mit Ausnahme von GPT 5.5, das eine gleichwertige Leistung erbringt. Auch auf der Kostenseite ist das Ergebnis überzeugend. Qwen 122B sinkt von 56 auf 28 Tool-Aufrufe pro Rollout, während sich sein Score verdoppelt; Sonnet von 28 auf 17; Opus von 33 auf 21.1 Dies führt bei den meisten Modellen zu einer ungefähren Halbierung der Kosten. Das Muster ähnelt dem von OfficeQA Pro: Je schwieriger die Aufgabe, desto mehr machen sich native Objekte und persistente Zustände bezahlt.
Jeder Vergleich wurde ohne Prompt-Tuning, ohne aufgabenspezifische Anpassung und ohne modellspezifische Optimierungen durchgeführt. Die Agenten-Schleife, die System-Prompts und die Tools sind in beiden Testumgebungen identisch. Der einzige Unterschied ist der Aktionsraum: strukturierte JSON/XML-Tool-Aufrufe im Vergleich zu den Python-Codeblöcken von MemEx.
MemEx im Einsatz bei Agenten-Traces
Agenten-Trajektorien sind an sich schon sperrige Objekte. Im Tool-Calling-Paradigma erfordert die Analyse von Trajektorien im Allgemeinen deren Umwandlung in flachen Text, was verlustbehaftet und kontextintensiv ist. Zudem ist die gleichzeitige Analyse mehrerer Trajektorien oft nicht machbar. Trajektorien können sich sogar über mehrere Kontextfenster erstrecken, mit Komprimierung dazwischen. Wie kann ein LLM einen Trace analysieren, der definitionsgemäß nicht in seinen Kontext passt? Da eine Trajektorie jedoch nur ein weiteres Python-Objekt ist, kann MemEx sie direkt in den Scope laden und logische Schlüsse daraus ziehen. Wir zeigen zwei Anwendungen: erstens einen MemEx-basierten Audit-Agenten, der Qwen 3.6-27B-Trajektorien auf OfficeQA-Pro analysiert, um zu erklären, warum MemEx besser abschneidet als Tool Calling; zweitens Test-Time-Scaling auf OfficeQA-Pro mit einem MemEx-Agenten, der einen entsprechenden Tool-Calling-Agenten übertrifft.
MemEx prüft MemEx: Analyse von Agenten-Traces
Um zu analysieren, warum der Wechsel zu MemEx bei Open-Source-Modellen wie Qwen 3.6-27B zu einer Leistungssteigerung geführt hat, lassen wir uns dies von MemEx erklären. Konkret instanziieren wir einen Audit-Agenten, der eine OfficeQA-Frage, die dazugehörige Ground-Truth-Antwort und sechs Solver-Trajektorien (3 von einem MemEx-Agenten und 3 von einem Tool-Calling-Agenten) direkt in seinen Python-Scope übernimmt. Anschließend lassen wir einen MemEx-basierten Sonnet 4.6-Agenten jede fehlerhafte Trajektorie anhand einer vierachsigen Taxonomie von Fehlermustern klassifizieren.
| Fehlerachse | Definition | MemEx-Fehler | Tool-Calling-Fehler |
|---|---|---|---|
Source Selection | Das Modell zielt auf das falsche Dokument oder die falsche Tabelle ab | 32 | 45 |
Interpretation | Das Modell ruft die richtigen Daten ab, extrahiert aber die falsche Bedeutung | 28 | 38 |
Search Strategy | Das Modell stoppt zu früh oder schweift an der Antwort vorbei | 6 | 15 |
Execution | Fehler bei der Zwischenberechnung oder der Formatierung der finalen Ausgabe | 3 | 6 |
Total | - | 69 | 104 |
Unsere Analyse konzentriert sich auf 66 OfficeQA Pro-Fragen, bei denen nicht alle sechs Versuche korrekt oder inkorrekt waren, was 173 Trajektorien ergibt. Die vier Achsen lassen sich in zwei große Gruppen unterteilen:
- Grounding-Fehler (~83 %): Fälle, in denen das Modell einen vorläufigen Wert anstelle einer korrigierten Zahl abruft, mehrdeutige Begriffe falsch interpretiert (z. B. Stichproben- vs. Populationsvarianz oder Rundungsgenauigkeit für „Hundertstel“) oder die falsche Spalte aus einer gültigen Tabelle extrahiert.
- Suchstrategie- und Ausführungsfehler: Fehler bei der Planung der Abfragesequenz oder das Versäumnis, abgerufene Daten korrekt in finale Berechnungen zu integrieren.
Bei Suchstrategie- und Ausführungsfehlern stellt MemEx fest, dass der MemEx-Agent eine doppelt so hohe Fehlerreduktion im Vergleich zu Tool Calling aufwies. Dies liegt daran, dass bei MemEx die abgerufenen Daten direkt in Python-Variablen landen können. So muss das Modell Werte nicht mehr aus der Ausgabe eines Tools in den nächsten Tool-Aufruf kopieren, und mehrere Tool-Aufrufe können in einem einzigen Durchgang gebündelt werden. Tool Calling bietet keine solche Abkürzung und muss Werte stets zwischen den Aufrufen übertragen, was manchmal zu Fehlern führt. Beispielsweise wurde in einer Trajektorie ein Wert von 3.501 aus einem abgerufenen Dokument im nächsten Aufruf fälschlicherweise als 3531 eingegeben.
Paralleles Denken von Agenten mit MemEx
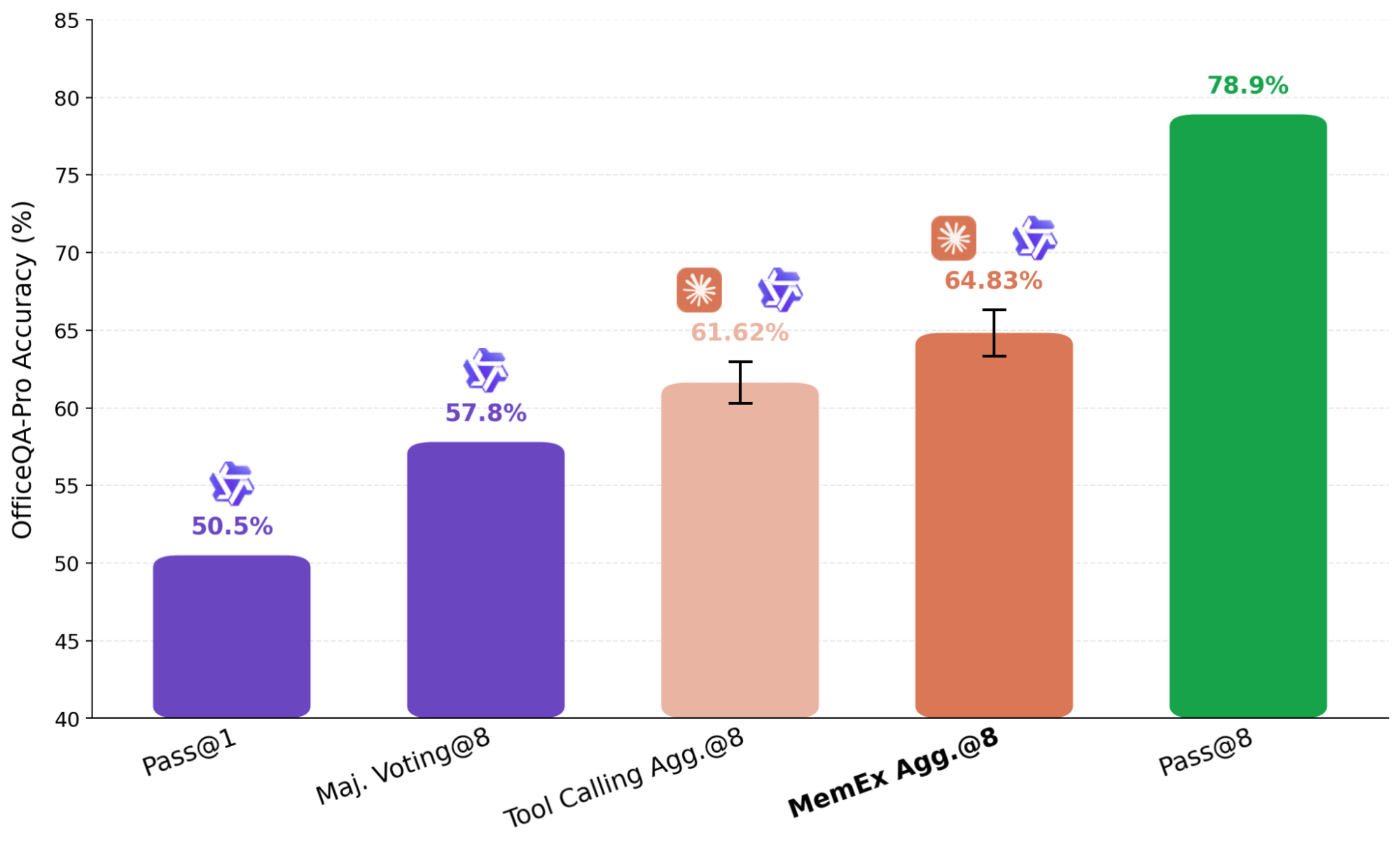
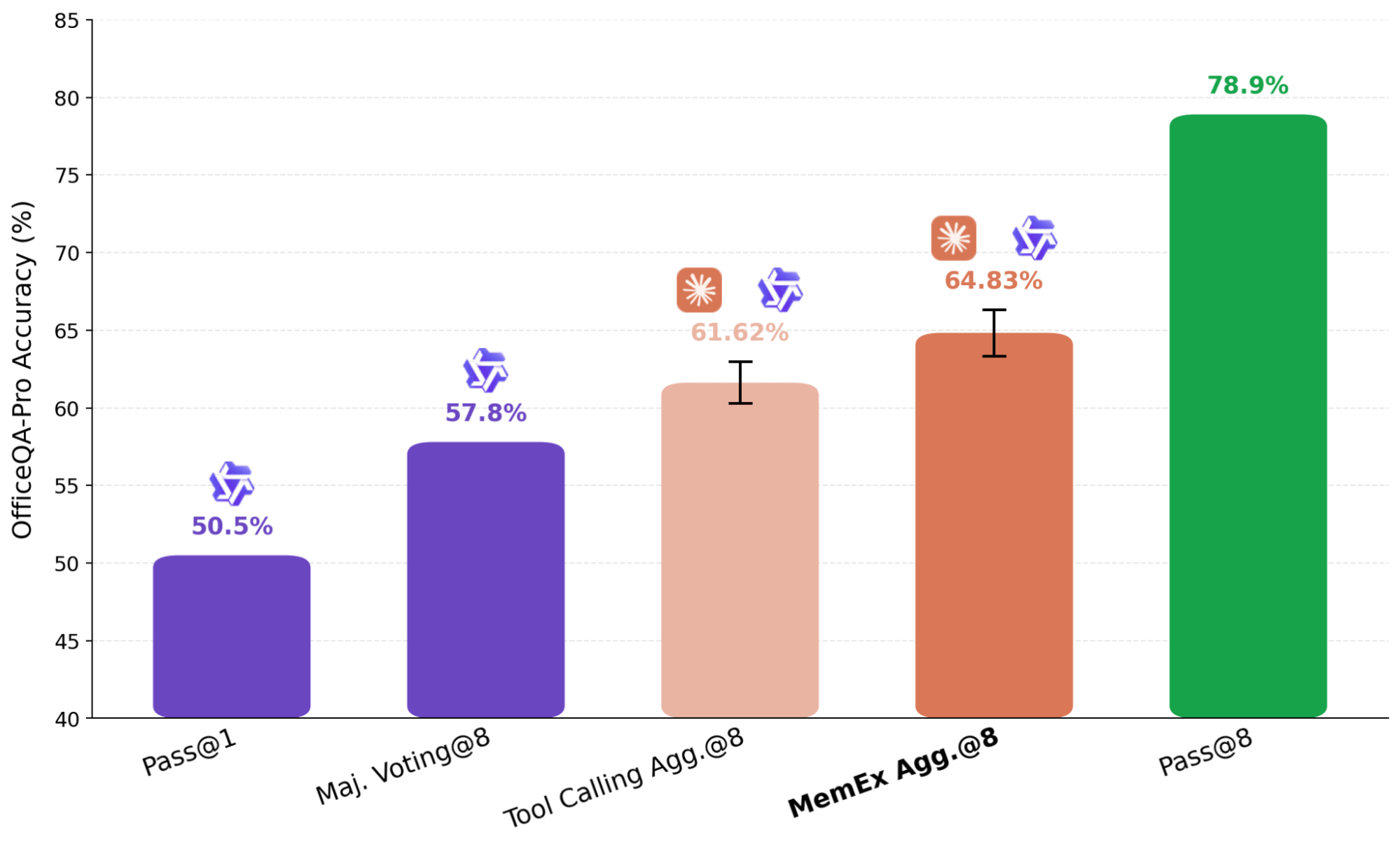
Ein gängiger Ansatz zur Skalierung von Berechnungen zur Testzeit ist das parallele Denken (Parallel Thinking), bei dem mehrere unabhängige Rollouts einer Aufgabe zu einer finalen Antwort zusammengeführt werden. Beim parallelen Denken von Agenten, wie es beispielsweise in KARL verwendet wird, werden Zusammenfassungen der unabhängigen Versuche an einen Aggregator-Agenten übergeben. Dieser Zusammenfassungsschritt ist verlustbehaftet, aber im Standard-Setup unvermeidlich, da es unpraktisch ist, mehrere vollständige Trajektorien in das Kontextfenster eines Modells einzupassen. Mit MemEx können wir diese Trajektorien stattdessen als Scope-Variablen laden und so die verlustbehaftete Darstellung komplett umgehen.
{kind=link}
In dem in Abbildung 7 gezeigten Ergebnis verwenden wir Claude Sonnet 4.6 als Aggregator über acht unabhängig generierte Qwen-3.6-27B-Trajektorien. Um sicherzustellen, dass der Aggregator das Problem nicht einfach selbst neu löst, entfernen wir seine Dateisuchwerkzeuge und beschränken ihn auf Verifizierung und Auswahl. Der MemEx-basierte Agent, der die vollständigen Trajektorien als Input erhält, übertrifft den entsprechenden Tool Calling-Agenten, der nur deren Zusammenfassungen erhält. In einem Fall erkannte der Trajektorien-Aggregator einen Duplizierungsfehler in einem früheren Bulletin, indem er die rohen Tool-Ausgaben aus den Input-Trajektorien las; der Tool Calling-Aggregator konnte den Anspruch auf doppelte Daten nicht überprüfen, da sein Input auf die Zusammenfassungen beschränkt war, und fiel auf eine Mehrheitsentscheidung über die fehlerhafte Quelle zurück.
MemEx-Architektur
Tool Calling-Agenten geben pro Runde einen oder mehrere strukturierte Tool-Aufrufe (JSON oder XML) aus, die jeweils einem vordefinierten Tool-Schema entsprechen, und zwar in der von ReAct (Yao et al., 2022) eingeführten Action-Observation-Schleife. CodeAct (Wang et al., 2024) ersetzte dieses Format durch einen persistenten Python-Kernel: Der Agent gibt beliebigen Python-Code aus, und Variablen sowie Funktionsdefinitionen bleiben über Runden hinweg erhalten. Produktionsvarianten desselben Paradigmas umfassen das Programmatic Tool Calling (PTC) von Anthropic und Cloudflare Code Mode; PTC behält den Zustand auch über Anfragen hinweg bei, indem derselbe Container wiederverwendet wird, während Code Mode dies nicht tut. MemEx erweitert dieses Paradigma um vier zusätzliche Funktionen:
- Direkte Tool-Integration unter Beibehaltung der Parameterschemata.
- Live-Python-Scope beim Start des Rollouts.
- Typisierte
submit()für strukturierte Rückgaben. - Nicht-blockierende
spawn_agent()für parallele Sub-Agenten, was eine Generalisierung von Recursive Language Models (Zhang et al., 2025) darstellt.
Die Implementierung basiert auf drei Designentscheidungen:
Code als Aktion in einer persistenten REPL
Die Aktion des Agenten ist ein beliebiger Python-Codeblock, der in einem Namensraum ausgeführt wird, der über Runden hinweg bestehen bleibt. Tools, Scope-Objekte und vorherige Ergebnisse befinden sich alle in diesem Namensraum. Der Agent liest Beobachtungen (stdout, Rückgabewerte, Fehler) und schreibt dann weiteren Code. Dieselbe Observe-Act-Schleife, die Tool Calling ausführt, führt auch MemEx aus; nur der Aktionsraum ändert sich.
Direkter Ersatz für Tool Calling
Bestehende Tool Calling-Tools werden automatisch als Python-Funktionen injiziert, einschließlich Parameterschemata und Rückgabetyp-Metadaten. Der Wechsel eines bestehenden Agenten von Tool Calling zu MemEx ist eine einzige Konfigurationsänderung.
Backend-agnostische Ausführung
Derselbe Agenten-Code läuft in drei Backends, die zum Konfigurationszeitpunkt ausgewählt werden:
- In-Process für schnelle Iterationen während der Forschung.
- Subprocess für die Isolation während der Evaluierung.
- Pool für Batch-Generierung mit hohem Durchsatz (Trainingsdaten, großflächige Rollouts).
Für Produktionsumgebungen kann der Kernel gegen eine gehostete Sandbox wie die Managed Agents von Anthropic ausgetauscht werden. Derselbe Agenten-Code, wobei Dateisystem-Isolierung, Netzwerk-Ausgangskontrollen und Ressourcenbegrenzungen vom Host übernommen werden.
Wie geht es weiter?
MemEx kommt in die Hände Ihrer Agenten. Wir führen es für die First-Party-Agenten von Databricks und Agent Bricks ein: Wenn Sie heute auf Databricks-Agenten aufbauen, können Sie bald MemEx nutzen.
Wir trainieren unsere Modelle für den MemEx-Aktionsraum nach (Post-Training). MemEx selbst ist das Substrat: Es generiert synthetische Daten, führt agentische Verifizierer aus und speist die Trainingsschleife.
Autoren: Ashutosh Baheti, Shubham Toshniwal, Arnav Singhvi, Krista Opsahl-Ong, Sean Kulinski, Sam Havens, Jonathan Li, Marco Cusumano-Towner, Jonathan Chang, Wen Sun, Alexander Trott, Jonathan Frankle, Xing Chen, Matei Zaharia
1 In MemEx sind Tool-Aufrufe Python-Codeblöcke, die Datenanalysen oder andere Tools als asynchrone Funktionen aufrufen können.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.