Speicher-Skalierung für KI-Agenten
Inferenzskalierung hat LLMs dorthin gebracht, wo sie die meisten praktischen Situationen durchdenken können, vorausgesetzt, sie haben den richtigen Kontext. Für viele reale Agenten ist der Engpass nicht mehr die Denkfähigkeit, sondern die Verankerung des Agenten in den richtigen Informationen: dem Modell geben, was es für die anstehende Aufgabe benötigt.
Dies deutet auf eine neue Achse für das Agentendesign hin. Anstatt sich nur auf stärkere Modelle oder bessere Prompts zu konzentrieren, können wir fragen: Wird der Agent besser, wenn er mehr Informationen sammelt? Wir nennen dies Memory Scaling: die Eigenschaft, dass sich die Leistung des Agenten mit der Menge der vergangenen Gespräche, des Benutzerfeedbacks, der Interaktionstrajektorien (sowohl erfolgreiche als auch fehlgeschlagene) und des Geschäftskontexts, der in seinem Speicher gespeichert ist, verbessert. Der Effekt ist besonders ausgeprägt in Unternehmensumgebungen, wo Stammeswissen reichlich vorhanden ist und ein einzelner Agent vielen Benutzern dient.
Aber das ist a priori nicht offensichtlich. Mehr Speicher macht einen Agenten nicht automatisch besser: Spuren von geringer Qualität können falsche Lektionen lehren, und die Abfrage wird schwieriger, wenn der Speicher wächst. Die zentrale Frage ist, ob Agenten größere Speicher produktiv nutzen können, anstatt sie einfach anzuhäufen.
Wir haben bei Databricks durch ALHF und MemAlign, die das Agentenverhalten basierend auf menschlichem Feedback anpassen, und den Instructed Retriever, der es Suchagenten ermöglicht, komplexe Anweisungen in natürlicher Sprache und Wissensquellenschemata in präzise, strukturierte Suchanfragen zu übersetzen, erste Schritte in diese Richtung unternommen. Zusammen zeigen diese Systeme, dass Agenten durch persistenten Speicher hilfreicher sein können. Dieser Beitrag präsentiert experimentelle Ergebnisse, die das Memory Scaling-Verhalten demonstrieren, erörtert die Infrastruktur, die für die Unterstützung im Produktivbetrieb erforderlich ist, und bietet eine zukunftsorientierte Vision von speicherbasierten Agenten.
Was ist Memory Scaling?
Memory Scaling ist die Eigenschaft, dass sich die Leistung eines Agenten verbessert, wenn sein externer Speicher wächst. Hier bezieht sich "Speicher" auf einen persistenten Informationsspeicher, mit dem der Agent zur Inferenzzeit interagieren kann, getrennt von den Gewichten des Modells oder dem aktuellen Kontextfenster.
Dies macht Memory Scaling zu einer eigenständigen und komplementären Achse sowohl zur parametrischen Skalierung als auch zur Inferenzzeit-Skalierung und schließt Lücken bei Domänenwissen und Grounding, die weder die Modellgröße noch die Denkfähigkeit allein schließen können. Die Verbesserungen durch Memory Scaling beschränken sich nicht auf die Antwortqualität. Wenn ein Agent die relevanten Schemata, Domänenregeln oder erfolgreichen vergangenen Aktionen für eine Umgebung gespeichert hat, kann er redundante Erkundungen überspringen und Abfragen schneller lösen. In unseren Experimenten beobachten wir Skalierung sowohl bei der Genauigkeit als auch bei der Effizienz.
Beziehung zum kontinuierlichen Lernen
Kontinuierliches Lernen konzentriert sich typischerweise auf die Aktualisierung von Modellparametern im Laufe der Zeit, was in begrenzten Umgebungen gut funktioniert, aber bei vielen gleichzeitigen Benutzern, Agenten und sich schnell ändernden Projekten rechenintensiv und fehleranfällig wird. Memory Scaling stellt eine andere Frage: Ist ein Agent mit Tausenden von Benutzern leistungsfähiger als einer mit einem einzigen Benutzer? Durch die Erweiterung des gemeinsamen externen Zustands eines Agenten, während die LLM-Gewichte eingefroren bleiben, kann die Antwort ja lauten – ein von einem Benutzer erlernter Workflow kann sofort für einen anderen abgerufen und angewendet werden, ohne erneutes Training. Dies ist eine Eigenschaft, die kontinuierliches Lernen, das sich auf die Aktualisierung der Modellparameter eines einzelnen Benutzers konzentriert, nie bieten sollte.
Beziehung zum langen Kontext
Große Kontextfenster mögen ein Ersatz für Speicher erscheinen, aber sie lösen unterschiedliche Probleme. Das Packen von Millionen von Roh-Tokens in einen Prompt erhöht die Latenz, steigert die Rechenkosten und verschlechtert die Denkqualität, da irrelevante Tokens um Aufmerksamkeit konkurrieren. Memory Scaling setzt stattdessen auf selektive Abfrage – es wird nicht nur entschieden, wie viel Kontext einbezogen werden soll, sondern auch, was einbezogen werden soll, und nur die hochgradig relevanten Informationen für die aktuelle Aufgabe angezeigt.
Arten von Speicher
Nicht alle Speicher dienen demselben Zweck. Zwei Unterscheidungen sind in der Praxis wichtig:
Episodisch vs. semantisch. Episodische Erinnerungen sind Rohaufzeichnungen vergangener Interaktionen – Gesprächsprotokolle, Tool-Aufruf-Trajektorien, Benutzerfeedback. Semantische Erinnerungen sind verallgemeinerte Fähigkeiten und Fakten, die aus diesen Interaktionen destilliert wurden (z. B. "Benutzer in diesem Bereich meinen immer das Fiskalquartal, wenn sie 'Quartal' sagen"). Jeder Typ erfordert unterschiedliche Speicher-, Verarbeitungs- und Abrufstrategien: episodische Erinnerungen für den direkten Abruf und semantische Erinnerungen, die von einem LLM destilliert wurden, für breitere Mustererkennung.
Persönlich vs. organisatorisch. Einige Erinnerungen sind spezifisch für die Präferenzen und Arbeitsabläufe eines einzelnen Benutzers; andere repräsentieren gemeinsames organisatorisches Wissen – Namenskonventionen, gängige Abfragen, Geschäftsregeln. Das Speichersystem muss die Abfrage und Aktualisierung entsprechend skalieren: organisatorisches Wissen breit anzeigen und gleichzeitig individuelle Kontexte privat halten, wobei Berechtigungen und ACLs beachtet werden.
Experimente: MemAlign auf Genie Space
MemAlign ist unsere Untersuchung, wie ein einfaches Speicherframework für KI-Agenten aussehen kann. Es speichert vergangene Interaktionen als episodische Erinnerungen, verwendet ein LLM, um sie in verallgemeinerte Regeln und Muster (semantische Erinnerungen) zu destillieren, und ruft die relevantesten Einträge zur Inferenzzeit ab, um den Agenten zu steuern. Details zum Framework finden Sie in unserem früheren Blogbeitrag.
Wir haben MemAlign auf Databricks Genie Spaces getestet, einer natürlichsprachlichen Schnittstelle, bei der Geschäftsbenutzer Datenfragen in einfachem Englisch stellen und SQL-basierte Antworten erhalten. Ein Beispiel für die Aufgabenabfrage und Antwort ist unten angegeben.
Unser Ziel ist es, zu messen, wie sich die Agentenleistung skaliert, wenn wir ihm mehr Speicher zuführen, unter Verwendung von zwei Datenquellen: kuratierte Beispiele (gelabelt) und rohe Benutzergesprächsprotokolle (ungelabelt).
Skalierung mit gelabelten Daten
Wir haben MemAlign auf ungesehenen Fragen in 10 Genie-Bereichen evaluiert und schrittweise Shards von annotierten Trainingsbeispielen zum Speicher des Agenten hinzugefügt. Unsere Baseline ist ein Agent, der von Experten kuratierte Genie-Anweisungen verwendet (manuell geschriebene Tabellenschemata, Domänenregeln und Few-Shot-Beispiele).
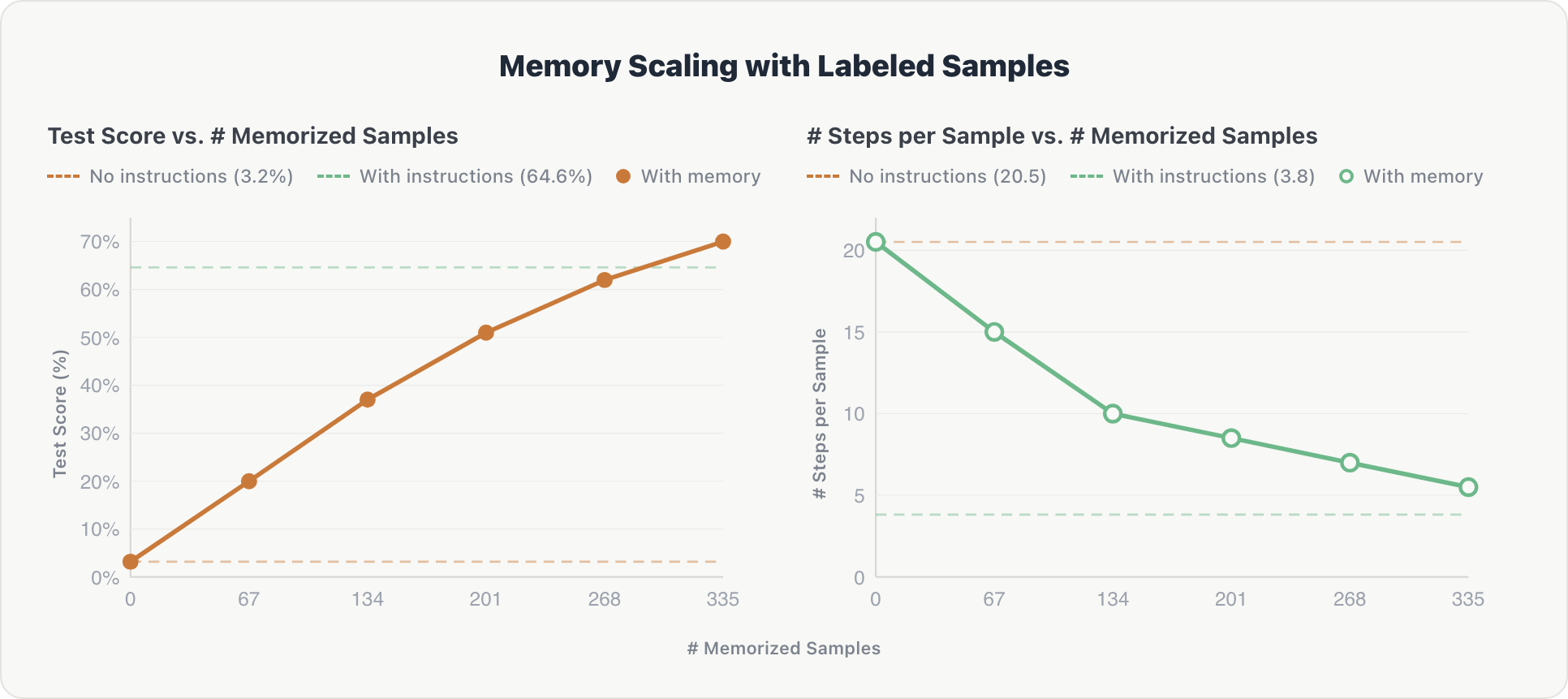
Die Ergebnisse zeigen eine konsistente Skalierung in beiden Dimensionen:
Genauigkeit. Die Testpunktzahlen stiegen mit jedem zusätzlichen Speicher-Shard stetig an, stiegen von fast Null auf 70 % und übertrafen schließlich die von Experten kuratierte Baseline um ~5 %. Bei der Inspektion erwiesen sich menschlich gelabelte Daten als umfassender und daher nützlicher als manuell geschriebene Tabellenschemata und Domänenregeln.
Effizienz. Die durchschnittliche Anzahl der Denk-Schritte pro Beispiel sank mit wachsendem Speicher von ~20 auf ~5. Der Agent lernte, relevante Kontexte direkt abzurufen, anstatt die Datenbank von Grund auf zu erkunden, und näherte sich der Effizienz hartcodierter Anweisungen (~3,8 Schritte).
Der Effekt ist kumulativ: Da die gespeicherten Beispiele 10 verschiedene Genie-Bereiche umfassen, trägt jeder Shard domänenübergreifende Informationen bei, die auf vorhandenem Wissen aufbauen.
Skalierung mit ungelabelten Benutzerprotokollen
Kann der Speicher mit verrauschten, realen Daten skaliert werden? Um dies herauszufinden, haben wir MemAlign in einem Live-Genie-Bereich ausgeführt und ihm historische Benutzergesprächsprotokolle ohne Gold-Antworten zugeführt. Ein LLM-Richter filterte diese Protokolle auf Hilfreichkeit, und nur die hochwertigen wurden gespeichert.
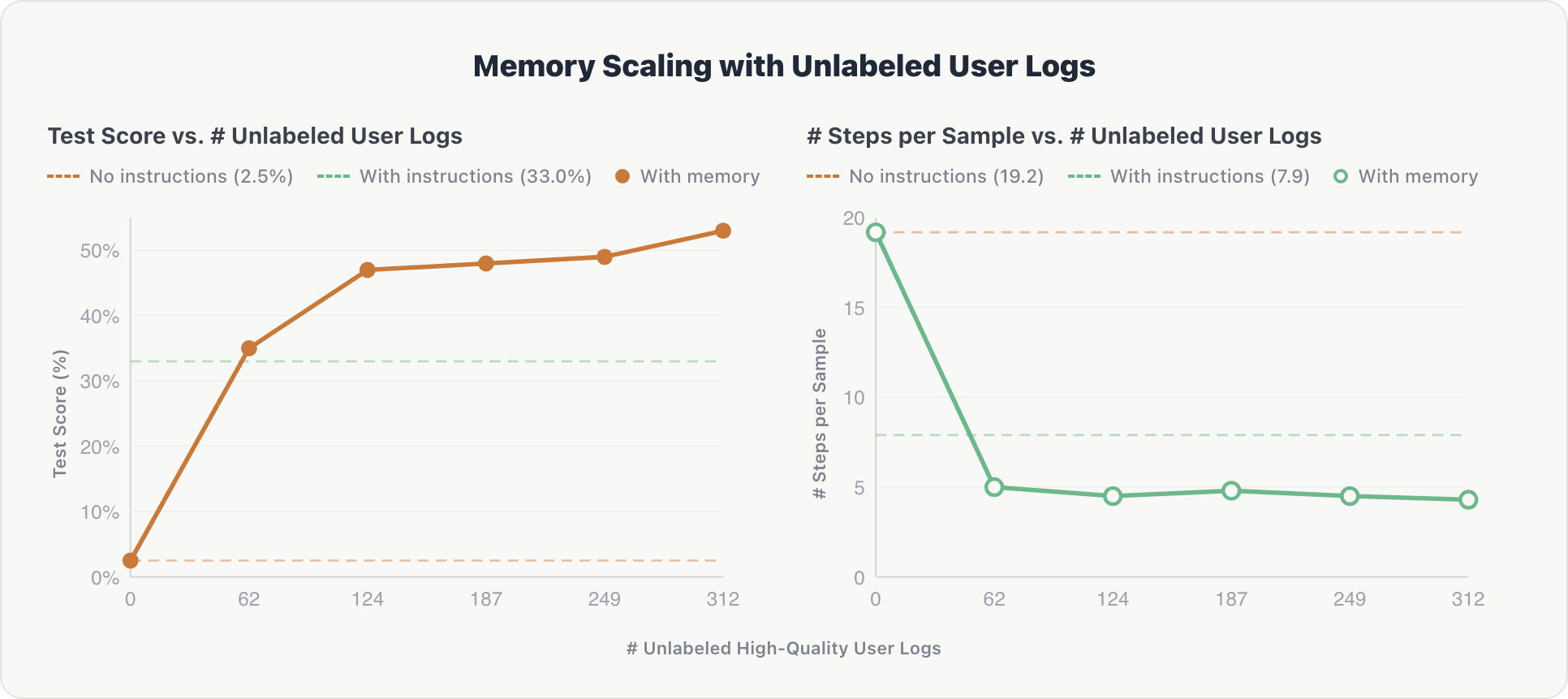
Die Skalierungskurve folgt einem ähnlichen Muster und ist am Anfang steiler:
Genauigkeit. Der Agent zeigte einen starken anfänglichen Gewinn. Nach dem ersten Protokoll-Shard extrahierte er wichtige Informationen über relevante Tabellen und implizite Benutzerpräferenzen. Die Leistung stieg von 2,5 % auf über 50 % und übertraf die von Experten kuratierte Baseline (33,0 %) nach nur 62 Protokollsätzen.
Effizienz. Die Denk-Schritte sanken nach dem ersten Shard von ~19 auf ~4,3 und blieben stabil. Der Agent internalisierte früh das Schema des Bereichs und vermied redundante Erkundungen bei nachfolgenden Abfragen.
Die Quintessenz: Unkuratierte Benutzerinteraktionen, die nur von einem automatisierten, referenzfreien Richter gefiltert werden, können die kostspieligen und zeitaufwändigen handgefertigten Domänenanweisungen ersetzen. Dies deutet auch auf Agenten hin, die sich durch normale Nutzung kontinuierlich verbessern und über die Grenzen menschlicher Annotation hinaus skalieren können.
Experimente: Organisational Knowledge Store
Die obigen Experimente zeigen, wie die Skalierung des Speichers mit Benutzerinteraktionen erfolgt. Unternehmen verfügen jedoch auch über vorhandenes Wissen, das jeder Benutzerinteraktion vorausgeht: Tabellenschemata, Dashboard-Abfragen, Geschäftsglossare und interne Dokumentationen. Wir haben getestet, ob die Vorabkompilierung dieses organisatorischen Wissens in einem strukturierten Speicher die Leistung von Agenten verbessern könnte.
Wir haben diesen Wissensspeicher auf einem internen Datenforschungs-Benchmark und auf PMBench evaluiert, das die erschöpfende Faktenrecherche über gemischte interne Dokumente wie Besprechungsnotizen von Produktmanagern und Planungsunterlagen testet.
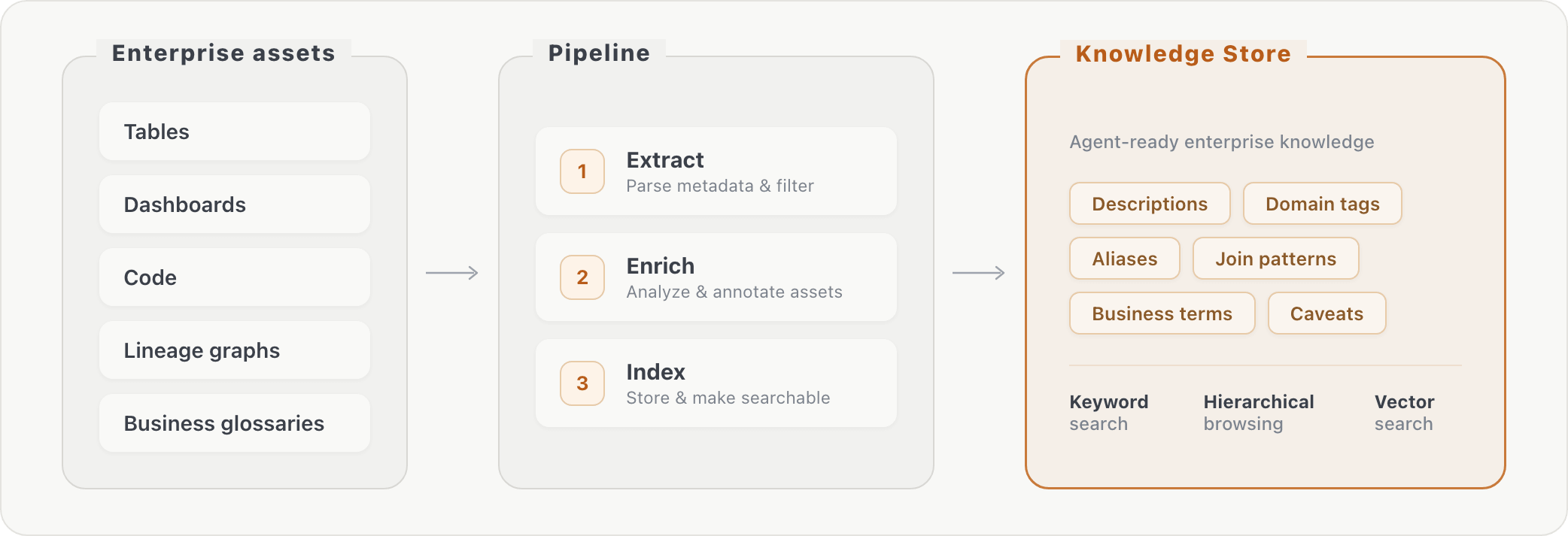
Unsere Pipeline verarbeitet Rohdatenbankmetadaten in drei Stufen zu abrufbarem Wissen: (1) Extraktion von Informationen über Assets, (2) Anreicherung von Assets durch zusätzliche Transformationen und (3) Indizierung des angereicherten Inhalts. Zur Abfragezeit kann der Agent den Unternehmenskontext über Stichwortsuche oder hierarchisches Browsen abrufen. Dies schließt die Lücke zwischen der Art und Weise, wie Benutzer Fragen formulieren („KI-Konsum“), und der tatsächlichen Speicherung von Daten (spezifische Spaltennamen in bestimmten Tabellen).
Das Hinzufügen des Wissensspeichers verbesserte die Genauigkeit auf beiden evaluierten Benchmarks um etwa 10 %. Die Gewinne konzentrierten sich auf Fragen, die Vokabularbrücken, Tabellenverknüpfungen und spaltenbezogenes Wissen erforderten, d. h. Informationen, die der Agent nicht allein durch Schemaerkundung hätte entdecken können.
Infrastruktur für die Skalierung des Speichers
Die Skalierung des Speichers in Unternehmensbereitstellungen erfordert eine robuste Infrastruktur über einen einfachen Vektorspeicher hinaus. Im Folgenden werden wir drei Schlüsselherausforderungen diskutieren, die diese Infrastruktur bewältigen muss: skalierbare Speicherung, Speicherverwaltung und Governance.
Skalierbare Speicherung
Der einfachste Speichermechanismus ist das Dateisystem: Markdown-Dateien in hierarchischen Ordnern, die mit Standard-Shell-Tools durchsucht und abgefragt werden. dateibasierter Speicher funktioniert gut im kleinen Maßstab und für einzelne Benutzer, ihm fehlen jedoch Indizierung, strukturierte Abfragen und effiziente Ähnlichkeitssuche. Wenn der Speicher auf Tausende von Einträgen über viele Benutzer hinweg anwächst, verschlechtert sich die Abrufbarkeit und die Durchsetzung der Governance wird schwierig.
Dedizierte Datenspeicher sind der nächste logische Schritt. Standalone-Vektordatenbanken eignen sich gut für die semantische Suche, ihnen fehlen jedoch relationale Fähigkeiten wie Joins und Filterung. Moderne PostgreSQL-basierte Systeme bieten eine einheitlichere Alternative: Sie unterstützen nativ strukturierte Abfragen, Volltextsuche und Vektorähnlichkeitssuche in einer einzigen Engine.
Serverless-Varianten dieser Architektur, die Speicher von Rechenleistung trennen und kostengünstige, dauerhafte Speicherung bieten, sind eine natürliche Wahl. Wir verwenden Lakebase, das auf dem serverlosen PostgreSQL-Engine von Neon basiert, dank seiner Skalierbarkeit auf Null-Kosten und seiner Unterstützung für Vektor- und exakte Suche. Die integrierte Datenbankverzweigung vereinfacht auch den Entwicklungszyklus – Ingenieure können den Speicherzustand des Agenten für Tests verzweigen, ohne die Produktion zu beeinträchtigen.
Speicherverwaltung
Skalierbare Speicherung allein reicht nicht aus. Ein Speichersystem muss auch seinen Inhalt verwalten:
- Bootstrapping. Neue Agenten leiden bekanntermaßen unter Kaltstartproblemen. Die Aufnahme vorhandener Unternehmensressourcen (Wikis, Dokumentationen, interne Anleitungen) durch Dokumentenanalyse und -extraktion bietet eine anfängliche Speicherbasis, die einige dieser Probleme lindern kann, wie unsere Experimente mit organisatorischen Wissensspeichern gezeigt haben.
- Destillation. Rohe episodische Erinnerungen sind für den direkten Abruf nützlich, werden aber im großen Maßstab teuer in der Speicherung und Abfrage. Die periodische Destillation in semantische Erinnerungen (komprimierte Regeln und Muster) hält den Speichermechanismus überschaubar und liefert dem Agenten verallgemeinerbare Erkenntnisse, die aus episodischen Erinnerungen allein möglicherweise nicht ersichtlich sind.
- Konsolidierung. Wenn der Speicher wächst, ist es wichtig, das System konsistent, kompakt und aktuell zu halten. Dies erfordert Pipelines, die Duplikate entfernen, veraltete Informationen kürzen und Konflikte zwischen alten und neuen Einträgen auflösen.
Sicherheit
Speicher führt Governance-Anforderungen ein, die für zustandslose Agenten nicht existieren. Da Agenten tiefgreifendes kontextbezogenes Wissen ansammeln, einschließlich Benutzerpräferenzen, proprietärer Workflows und interner Datenmuster, müssen die gleichen Governance-Prinzipien, die für Unternehmensdaten gelten, auf den Agentenspeicher erweitert werden.
Zugriffskontrollen müssen identitätsbewusst sein: Einzelne Erinnerungen sollten privat bleiben, während organisatorisches Wissen innerhalb zugriffskontrollierter Grenzen geteilt werden kann. Dies passt natürlich zu der Art von feingranularen Berechtigungen, die Plattformen wie Unity Catalog bereits für Datenassets erzwingen, wie zeilenbasierte Sicherheit, Spaltenmaskierung und attributbasierte Zugriffskontrolle.
Die Erweiterung dieser Kontrollen auf Speicher-Einträge bedeutet, dass ein Agent, der Kontext für einen Benutzer abruft, nicht versehentlich die privaten Interaktionen eines anderen Benutzers preisgeben kann.
Über die Zugriffskontrolle hinaus sind Datenherkunft und Auditierbarkeit wichtig. Wenn das Verhalten eines Agenten durch seinen Speicher geprägt ist, müssen Teams nachvollziehen können, welche Erinnerungen eine bestimmte Antwort beeinflusst haben und wann diese Erinnerungen erstellt oder aktualisiert wurden. Compliance- und regulatorische Anforderungen, insbesondere in regulierten Branchen, verlangen, dass Speicher die gleichen Beobachtbarkeitsgarantien wie die zugrunde liegenden Daten unterstützen: vollständige Herkunftsverfolgung, Aufbewahrungsrichtlinien und die Möglichkeit, bestimmte Einträge auf Anfrage zu löschen.
Sicherzustellen, dass die richtigen Erinnerungen den richtigen Benutzer erreichen und nur diesen Benutzer, ist im großen Maßstab ein zentrales Designproblem.
Was im Wege steht
Jede Skalierungsachse stößt schließlich auf ihre eigene Engstelle. Die parametrische Skalierung wird durch die Verfügbarkeit hochwertiger Trainingsdaten begrenzt. Die Skalierung zur Inferenzzeit kann in übermäßigem Nachdenken ausarten, wo längere Schlussfolgerungsketten Kosten hinzufügen, ohne Signal hinzuzufügen, und letztendlich die Leistung mit zunehmender Sequenzlänge verschlechtern. Die Skalierung des Speichers hat analoge Grenzen: Probleme mit Qualität, Umfang und Zugriff.
Die Qualität des Speichers ist schwer aufrechtzuerhalten. Einige Erinnerungen sind von Anfang an falsch; andere werden im Laufe der Zeit falsch. Ein zustandsloser Agent macht isolierte Fehler, aber ein speichergestützter Agent kann einen Fehler in einen wiederkehrenden verwandeln, indem er ihn speichert und später als Beweis abruft. Wir haben gesehen, wie Agenten Notebooks aus früheren Läufen zitierten, die selbst falsch waren, und diese Ergebnisse dann mit noch größerem Selbstvertrauen wiederverwendeten. Veraltung ist subtiler: Ein Agent, der das Schema des letzten Quartals gelernt hat, fragt möglicherweise weiterhin Tabellen ab, die seitdem umbenannt oder gelöscht wurden. Die Filterung bei der Aufnahme hilft, aber Produktionssysteme brauchen mehr als Filterung. Sie brauchen Herkunft, Vertrauensschätzungen, Aktualitätssignale und periodische Neubewertung.
Governance muss auf die Destillation ausgeweitet werden. Die Skalierung des Speichers in einer Organisation erfordert die Destillation wiederholter Interaktionen in wiederverwendbare semantische Erinnerungen. Aber Abstraktion beseitigt keine Sensibilität. Eine Erinnerung wie „für Unternehmen Y, verknüpfe die CRM-, Market-Intelligence- und Partnerschaftstabellen“ mag harmlos erscheinen und dennoch vertrauliche Übernahmeinteressen offenbaren. Die Herausforderung besteht darin, den Speicher breit nutzbar zu machen, ohne private Muster in gemeinsames Wissen zu verwandeln. Zugriffskontrollen und Sensibilitätskennzeichnungen müssen die Destillation überstehen, nicht nur die Aufnahme.
Nützliche Erinnerungen können unerreichbar bleiben. Selbst wenn der Speicher korrekt und aktuell ist, muss der Agent immer noch feststellen, dass er existiert. Abruf ist inhärent metakognitiv: Der Agent muss entscheiden, was er seinen Speichermechanismus fragen soll, bevor er weiß, was darin enthalten ist. Wenn er nicht antizipiert, dass eine relevante Erinnerung helfen könnte, gibt er nie die richtige Abfrage aus und greift auf langwierige, redundante Erkundungen zurück. In der Praxis kann die Lücke zwischen gespeichertem und abrufbarem Wissen die Hauptbeschränkung für die Skalierung des Speichers sein.
Dies sind keine Argumente gegen die Skalierung des Speichers. Es sind die Forschungsprobleme, die noch gelöst werden müssen, um die Skalierung des Speichers robust zu machen. Das zentrale Problem ist nicht nur, mehr Verlauf zu speichern; es geht darum, dem Agenten beizubringen, wie er die richtige Erinnerung findet, wie er sie angemessen verwendet und wie er sie aktuell und richtig eingegrenzt hält.
Ausblick: Der Agent als Speicher
Die obigen Experimente und die Infrastruktur deuten auf ein natürliches Designmuster hin: ein Agent, dessen Identität in seinem Speicher und nicht in seinen Modellgewichten liegt.
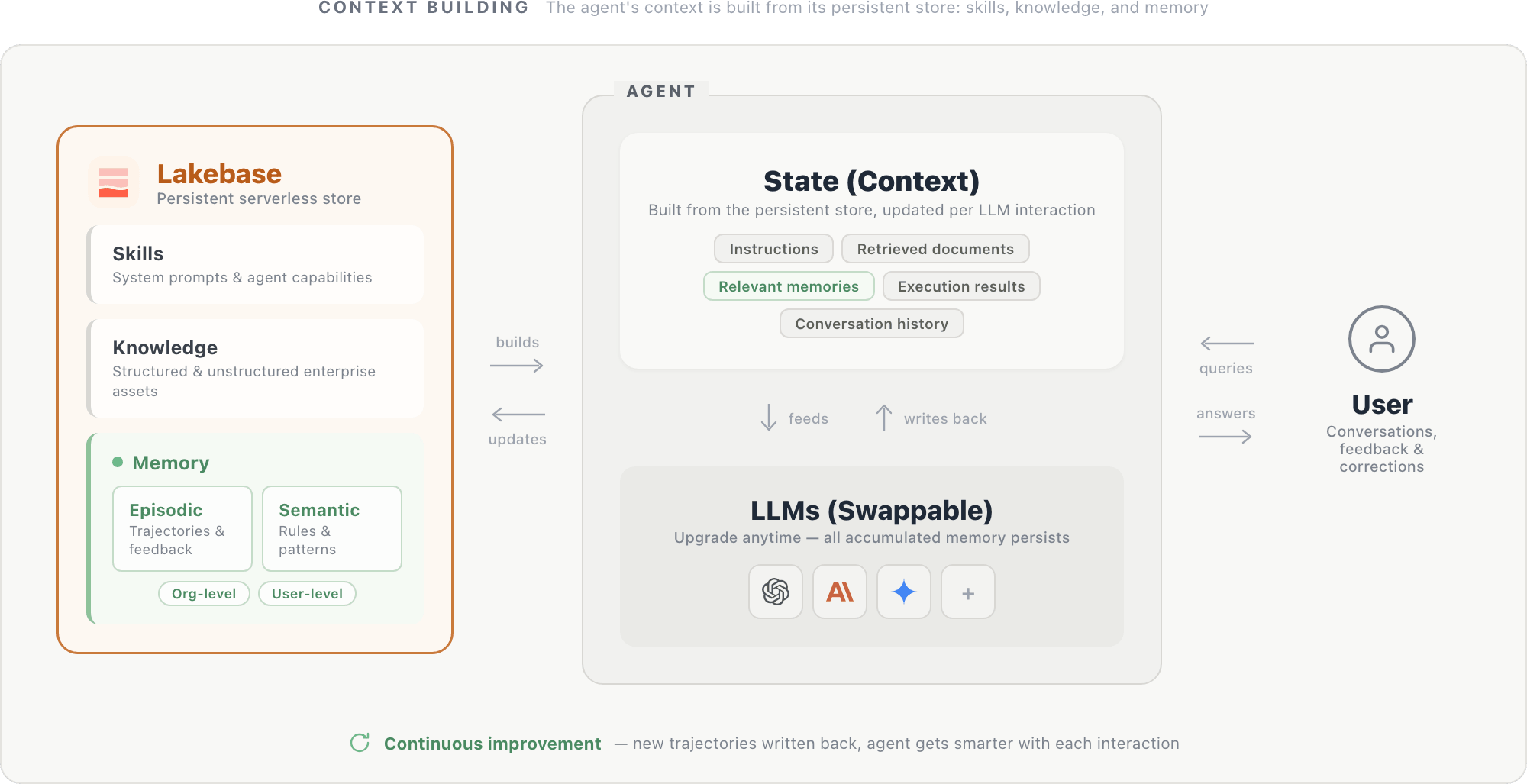
In diesem Design wird der Kontext eines Agenten aus einem persistenten Speicher aufgebaut, der in einer serverlosen Datenbank wie Lakebase untergebracht ist. Der Speicher enthält drei Komponenten: System-Prompts und Agenten-Fähigkeiten (Skills), strukturierte und unstrukturierte Unternehmensressourcen (Wissen) sowie episodische und semantische Erinnerungen, die auf Organisations- und Benutzerebene eingegrenzt sind. Zusammen bilden diese Komponenten den Zustand des Agenten: Anweisungen, abgerufene Dokumente, relevante Erinnerungen, Ausführungsergebnisse (von SQL-Abfragen, API-Aufrufen und anderen Tools) und Konversationsverlauf. Dieser Zustand wird bei jedem Schritt an die LLM übergeben und nach jeder Interaktion aktualisiert.
Die LLM selbst ist eine austauschbare Reasoning-Engine: Das Upgrade auf ein neueres Modell ist unkompliziert, da das neue Modell aus demselben persistenten Speicher liest und sofort von dem gesamten angesammelten Kontext profitiert.
Da die Fähigkeiten von Foundation Models immer ähnlicher werden, wird das Unterscheidungsmerkmal für Unternehmensagenten zunehmend darin bestehen, über welche Erinnerungen sie verfügen, anstatt welches Modell sie aufrufen. Hypothetisch kann ein kleineres Modell mit einem reichhaltigen Speicher besser abschneiden als ein größeres Modell mit weniger Speicher – wenn ja, könnte die Investition in Speicherinfrastruktur größere Erträge bringen als die Skalierung von Modellparametern. Domänenwissen, Benutzereinstellungen und betriebliche Muster, die für Ihr Unternehmen spezifisch sind, sind nicht in jedem Foundation Model enthalten. Sie können nur durch Nutzung aufgebaut werden und sind, im Gegensatz zu Modellfähigkeiten, für jede Bereitstellung einzigartig.
Fazit
Wir schlagen Memory Scaling vor, bei dem sich die Leistung eines Agenten verbessert, wenn er durch Benutzerinteraktion und Geschäftskontext mehr Erfahrungen im Speicher sammelt. Unsere ersten Experimente zeigen, dass sowohl Genauigkeit als auch Effizienz mit der Menge der im externen Speicher gespeicherten Informationen skalieren.
Die Realisierung im Produktivbetrieb erfordert Speichersysteme, die strukturierte und unstrukturierte Suchen vereinheitlichen, Management-Pipelines, die den Speicher konsistent halten, und Governance-Kontrollen, die den Zugriff angemessen einschränken. Dies sind lösbare Probleme mit der aktuellen Technologie. Der Lohn sind Agenten, die sich durch fortgesetzte Nutzung wirklich verbessern.
Die verbleibende Arbeit ist beträchtlich: Der Speicher muss korrekt, aktuell und zugänglich bleiben, während er wächst. Aber genau deshalb ist Memory Scaling interessant. Es eröffnet eine konkrete System- und Forschungsagenda für den Aufbau von Agenten, die sich durch fortgesetzte Nutzung auf eine Weise verbessern, die für jedes Unternehmen und jedes Problem spezifisch ist.
Autoren: Wenhao Zhan, Veronica Lyu, Jialu Liu, Michael Bendersky, Matei Zaharia, Xing Chen
Wir möchten Kenneth Choi, Sam Havens, Andy Zhang, Ziyi Yang, Ashutosh Baheti, Sean Kulinski, Alexander Trott, Will Tipton, Gavin Peng, Rishabh Singh und Patrick Wendell für ihr wertvolles Feedback während des gesamten Projekts danken.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.