Offene Plattform, vereinheitlichte Pipelines: Warum dbt auf Databricks beschleunigt
Führen Sie dbt auf einem offenen, vereinheitlichten Lakehouse mit integrierter Governance und starker Preis-Leistungs-Performance aus
von Srilekha Dornadula und Ramiz Bozai
- Offene Grundlagen verhindern Vendor Lock-in. Erstellen Sie dbt-Workflows mit offenen Tabellenformaten und Open-Source Unity Catalog Governance.
- Eine vereinheitlichte Plattform eliminiert Tool-Sprawl. Führen Sie dbt neben Ingestion und BI an einem Ort mit integrierter Governance und Orchestrierung aus.
- Erzielen Sie eine starke Preis-Leistung mit minimalem Tuning und operativem Aufwand.
dbt bringt Struktur in Daten transformations-Workflows. Teams nutzen es, um Rohdaten in kuratierte Datensätze zu verwandeln, die für nachgelagerte Zwecke wie BI-Dashboards, KI/ML-Modelle und funktionsübergreifende Berichte verwendet werden.
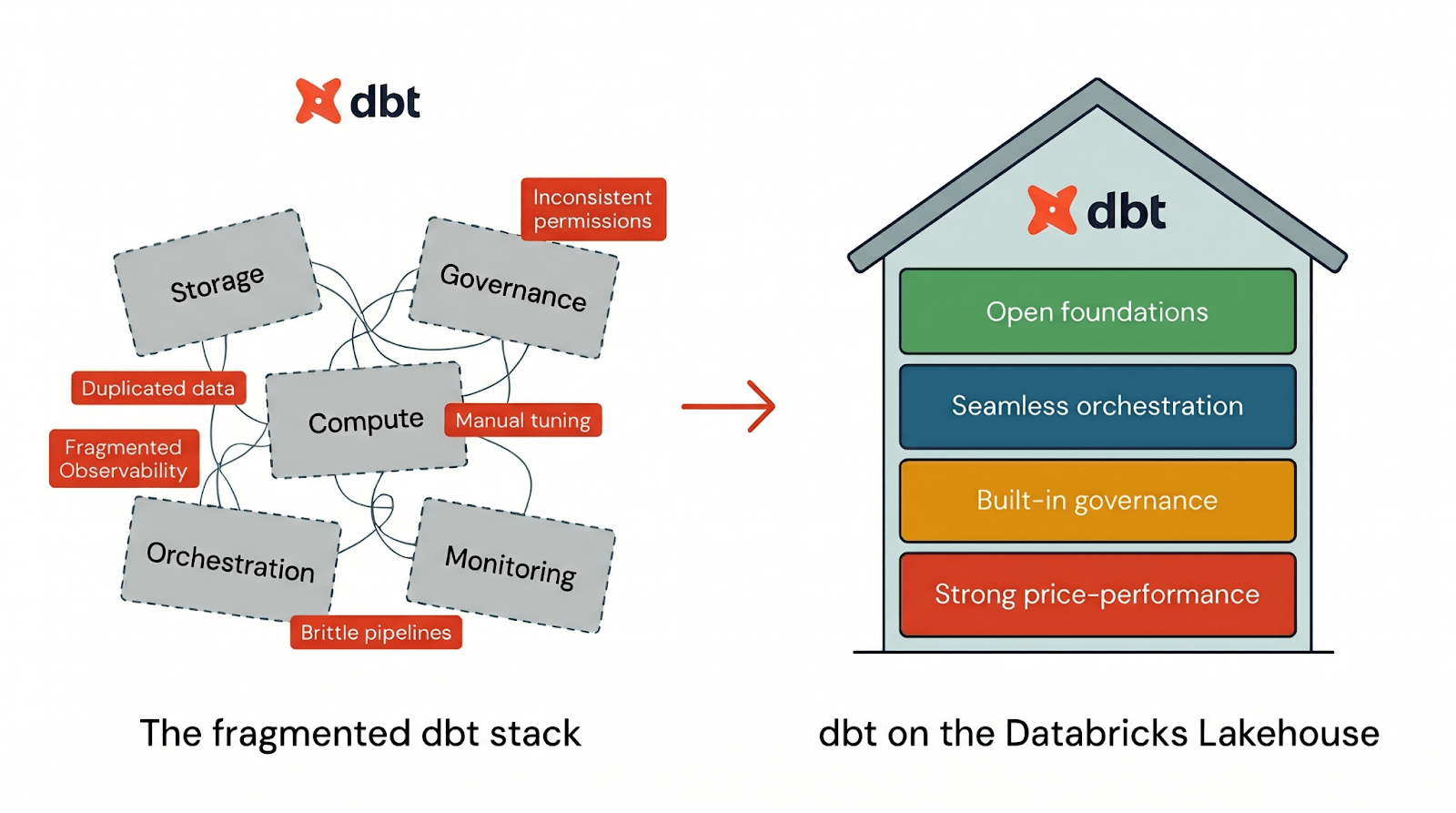
Aber die Realität ist: dbt ist nur so leistungsfähig wie die Datenplattform, auf der es läuft.
Die meisten Daten-Stacks zwingen Sie dazu, Speicher, Rechenleistung, Governance, Orchestrierung und Überwachung über mehrere Systeme hinweg zusammenzufügen. Das Ergebnis? Duplizierte Daten, inkonsistente Berechtigungen, fragmentierte Beobachtbarkeit und Performance-Tuning, das zum Nebenjob wird. Deshalb konsolidieren immer mehr Teams ihre dbt-Workflows auf Databricks.
Um dbt effektiv auszuführen, benötigt eine Plattform vier Dinge:
- Offene Grundlagen, damit Ihre dbt-Workflows nicht an einen proprietären Stack gebunden sind
- Nahtlose Orchestrierung, um dbt-Pipelines End-to-End an einem Ort auszuführen
- Integrierte Governance, die Teil des Standard-dbt-Workflows ist
- Starke Preis-Leistung, damit dbt vom ersten Tag an schnell läuft, ohne manuelles Tuning
Databricks liefert alle vier Säulen nativ integriert auf einer Plattform. Wenn Sie dbt auf Databricks ausführen, erhalten Sie die dbt-Entwicklererfahrung auf einer Lakehouse-Architektur, die von Anfang an auf Offenheit, Governance, Leistung und operative Einfachheit ausgelegt ist. Sehen wir uns an, wie jede dieser Säulen in der Praxis funktioniert:
Das Ausführen von dbt auf Databricks ermöglichte es uns, einen weitläufigen Altbestand an Notebooks und über 7 Quellsystemen in einer einzigen, gesteuerten Datenplattform zu konsolidieren. Mit Unity Catalog verwalten wir 341 Mandanten, mehrere Umgebungen und den Datenaustausch mit externen Partnern durch Isolation auf Katalogebene. Unsere dbt-Dokumentation fließt direkt in UC, sodass Analysten ohne Engpässe Self-Service nutzen können. Durch die Veröffentlichung in offenen Formaten und Delta Sharing können Partner und nachgelagerte Teams von dbt generierte Datensätze über verschiedene Tools und Umgebungen hinweg einfach nutzen. Es ist eine Plattform zum Erstellen, aber eine offene Plattform zum Nutzen.—Sohan Chatterjee, Head of Data and Analytics, iSolved
dbt auf offenen Grundlagen ohne Vendor Lock-in ausführen
Vendor Lock-in ist eines der größten strategischen Risiken für die Datenstrategie eines Unternehmens. dbt ist mit einem offenen Adapter-Framework aufgebaut, was bedeutet, dass Ihre Transformationslogik nicht an eine einzige Plattform gebunden ist. dbt ist von Natur aus offen, und Databricks bietet eine offene Plattform, um es auszuführen. Viele moderne Daten-Stacks konzentrieren sich auf eine proprietäre Speicherschicht, die kurzfristige Bequemlichkeit bietet, aber langfristig zu Reibungsverlusten führt. Im Laufe der Zeit führt dies zu doppelten Daten und Export-Pipelines, um verschiedene Verbraucher zu bedienen, Speicherformate, die die Interoperabilität einschränken, und eskalierende Wechselkosten, wenn sich die Plattformanforderungen weiterentwickeln.
Databricks ist ein offenes Lakehouse: eine einheitliche Plattform, auf der Ihre Daten in offenen Tabellenformaten gespeichert und über offene Schnittstellen zugänglich sind, sodass Speicher und Governance nicht an eine einzige Abfrage-Engine gebunden sind. Auf Databricks werden dbt-Modelle zu Tabellen in offenen Formaten, Delta Lake und Apache Iceberg, wodurch sichergestellt wird, dass Ihre transformierten Daten über die gesamte Datenlandschaft hinweg zugänglich bleiben, ohne dass parallele Kopien exportiert oder verwaltet werden müssen. Diese Offenheit ist besonders wichtig für dbt-Workflows. Ihre sorgfältig modellierten Silver- und Gold-Tabellen werden zu wiederverwendbaren Datenprodukten, die nachgelagerte Benutzer über jede Abfrage-Engine nutzen können, nicht nur über die Plattform, auf der dbt läuft.
Diese Offenheit erstreckt sich über den Speicher hinaus. Unity Catalog basiert auf offenen Katalog- und Zugriffsstandards, die gesteuerte Lese- und Schreibvorgänge von externen Engines unterstützen. Databricks SQL folgt ANSI-Standards, sodass Ihre Abfragen plattformübergreifend portierbar bleiben und herstellerspezifische Umschreibungen reduziert werden. Das bedeutet, dass Ihre dbt-Workflows auf einem Stack laufen, der auf Portabilität ausgelegt ist, nicht auf Lock-in.
dbt-Pipelines End-to-End mit Lakeflow Jobs orchestrieren
Orchestrierung ist der Punkt, an dem operative Komplexität entsteht. Die Kopplung von dbt mit einem externen Orchestrator neben Databricks bedeutet zwei zu betreibende Systeme, zwei Orte zum Debuggen und brüchige Übergaben dazwischen.
Lakeflow Jobs beseitigt diese Komplexität, indem es dbt als erstklassigen Aufgabentyp innerhalb einer einheitlichen Pipeline behandelt. Anstatt eine separate Orchestrierungsschicht zu unterhalten, führen Teams dbt zusammen mit Upstream-Ingestion und Downstream-Aktionen in einem einzigen Workflow aus. Sie können beispielsweise Rohdaten mit Auto Loader ingestieren, Daten mit dbt-Modellen transformieren und dann Dashboard-Aktualisierungen oder ML-Retraining auslösen, alles in einer Pipeline mit einheitlicher Wiederholungslogik und Abhängigkeitsverwaltung. dbt auf Databricks ermöglicht auch die direkte Ingestion über Streaming-Tabellen. Für dbt Platform-Benutzer ermöglicht die dbt Platform-Aufgabe (in Beta) Lakeflow, dbt-Workflows, die in der dbt Platform ausgeführt werden, auszulösen und zu verwalten.
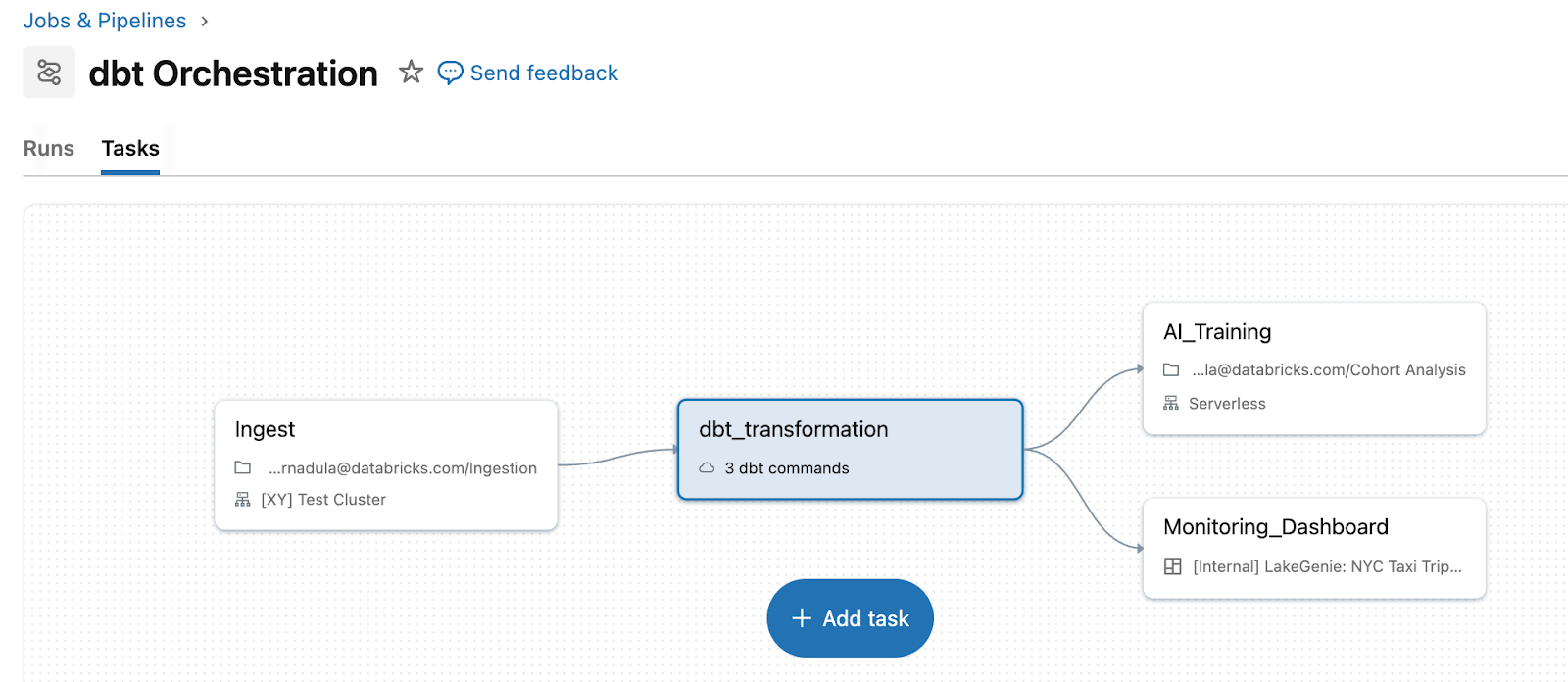
Wenn dbt über Lakeflow orchestriert wird, sind Fehler, Wiederholungsversuche und Kontext an einem Ort sichtbar. Anstatt zwischen einem separaten dbt-Orchestrator und Databricks-Protokollen zu wechseln, können Sie den Fehler, betroffene nachgelagerte Aufgaben und beeinträchtigte Dashboards direkt in der gleichen Job-Laufansicht sehen.
Governance als Teil des Standard-dbt-Workflows
Wenn dbt-Workflows skaliert werden, wird Governance zum Engpass. Teams benötigen klare Antworten zu Tabelleninhalten, Eigentümerschaft und Zugriffsrechten. In herkömmlichen Stacks ist dieser Kontext über separate Katalog-Tools, Berechtigungssysteme und unvollständige Lineage-Ansichten fragmentiert, die keine durchgängige Verbindung herstellen.
Databricks löst dies mit Unity Catalog, das Zugriffskontrolle, Erkennung und Lineage für Ihr gesamtes Lakehouse vereinheitlicht – nicht nur innerhalb von dbt, sondern auch über Ingestion, BI, ML/AI und darüber hinaus. Mit Unity Catalog müssen Sie keine Grant-Anweisungen erneut ausführen, jedes Mal, wenn dbt eine Tabelle neu erstellt. Berechtigungen werden auf Schemaebene verwaltet und bleiben über Tabellen-Neuerstellungen hinweg bestehen. Fein granulare Kontrollen wie Zeilenfilter, Spaltenmasken und attributbasierte Zugriffskontrolle gelten konsistent für dbt, BI-Tools und Notebooks.
Wenn Sie beispielsweise dbt-Dokumentation mit der persist_docs-Funktion von dbt in Unity Catalog speichern, werden Spaltenbeschreibungen und im dbt erstellter Kontext dort auffindbar, wo Daten abgefragt und genutzt werden. Unity Catalog bietet eine Spalten-Level Daten-Lineage, die den Datenfluss von der Rohdatenerfassung über dbt-Transformationen bis zur nachgelagerten Nutzung verfolgt. Wenn sich ein Quellschema ändert, können Sie sofort sehen, welche dbt-Modelle und nachgelagerten Assets betroffen sind. Dieses Maß an Transparenz ist unmöglich, wenn Daten-Pipelines getrennte Systeme umfassen.
Kostenkontrolle ist genauso wichtig wie Datenkontrolle. Mit Query Tags können Sie dbt-Läufen Geschäftskontext zuweisen und Ausgaben nach Team, Projekt oder Umgebung über System Tables verfolgen. Teams können endlich mit echten Daten statt mit Schätzungen die Frage beantworten: „Wie viel kosten unsere Marketing-Analyse-dbt-Pipelines?“ Zusätzlich bietet DBSQL Granular Cost Monitoring (in Private Preview) eine aggregierte Kostenüberwachung für alle dbt-Workloads.
Führen Sie dbt von Anfang an mit starker Preis-Leistungs-Optimierung aus
Die Optimierung eines Data Warehouse für Leistung erfordert normalerweise fortlaufende manuelle Arbeit. Teams tauschen oft Entwicklergeschwindigkeit gegen Leistungs-Hygiene ein.
Databricks abstrahiert diese Komplexität, indem es eine Hochleistungs-Ausführungs-Engine mit Funktionen kombiniert, die nativ mit dbt funktionieren und Geschwindigkeitsverbesserungen ohne manuellen Aufwand liefern.
Integrierte Leistung
- Photon-Engine beschleunigt SQL-Workloads durch vektorisierte Ausführung und liefert eine bis zu12-mal bessere Preis-Leistung im Vergleich zu Cloud Data Warehouses. Serverless SQL Warehouses beinhalten Photon standardmäßig, sodass Teams beschleunigte Leistung ohne zusätzliche Kosten erhalten.
- Predictive Optimization nutzt KI zur Überwachung von Tabellen und automatisiert die Wartung, wodurch Abfragen bis zu20-mal schneller werden. Dies reduziert die Notwendigkeit von manuellen OPTIMIZE-Post-Hooks, auf die sich dbt-Ingenieure bisher verlassen haben.
Leistungsmerkmale, die durch dbt-Konfiguration freigeschaltet werden
- dbt-Integration mit Liquid Clustering, das starre Partitionierungsstrategien durch einen flexiblen Ansatz ersetzt, der sich dynamisch an das Datenvolumen anpasst und zu bis zu 10-mal schnelleren Geschwindigkeiten ohne manuelle Abstimmung führt
- Materialized Views in dbt, die von Open-Source-Spark-Declarative-Pipelines unterstützt werden, verarbeiten inkrementelle Daten automatisch. Databricks verwaltet die Komplexität der Bestimmung, was aktualisiert werden muss, und verarbeitet nur neue oder geänderte Datensätze, anstatt ganze Datensätze neu zu berechnen. Dies führt im Vergleich zu ineffizienten geplanten Batch-Aktualisierungen zu geringeren Rechenkosten.
Mit diesen Funktionen verbringen Benutzer weniger Zeit mit der Abstimmung und mehr Zeit mit dem Aufbau von Pipelines, die bei wachsenden Datensätzen performant bleiben. Allein im Jahr 2025 erreichte Databricks SQL eine Leistungssteigerung von 10 % bei ETL-Workloads (Abfragen mit Schreibvorgängen) ohne zusätzliche Konfigurationen.
Jetzt loslegen
Databricks vereint offenen Speicher, einheitliche Governance, starke Preis-Leistungs-Optimierung und integrierte Abläufe an einem Ort für dbt-Workflows. Schließen Sie sich über 2900 Kunden an, die dbt bereits auf Databricks ausführen. Beginnen Sie mit dem Schnellstart-Leitfaden.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.