TEST - Una Guida Compatta alla Messa a Punto e alla Creazione di LLM Personalizzati
Introduzione
L'IA generativa (GenAI) ha il potenziale per democratizzare l'IA, trasformare ogni settore, supportare ogni dipendente e coinvolgere ogni cliente. Per essere più utile, i modelli GenAI necessitano di una profonda comprensione dei dati aziendali di un'organizzazione. Ad oggi, le tecniche più diffuse per fornire ai modelli GenAI la conoscenza dei dati aziendali sono il prompt engineering, il retrieval augmented generation (RAG), le catene (chains) e gli agenti. Tuttavia, queste tecniche raggiungono dei limiti quando si utilizzano modelli generici non specifici per domini e applicazioni particolari. Per migliorare i risultati generati e ridurre i costi, gli sviluppatori di applicazioni GenAI devono ricorrere alla creazione di modelli personalizzati tramite fine-tuning o pretraining.
Il fine-tuning specializza un modello AI esistente per un dominio o un compito specifico addestrandolo ulteriormente su un set più piccolo di dati personalizzati. Le tecniche includono il supervised fine-tuning per l'instruction-following o la chat, nonché il continued pretraining. Il pretraining crea un modello completamente nuovo addestrandolo da zero su dati completamente personalizzabili. Tutte queste tecniche consentono agli sviluppatori di creare proprietà intellettuale e differenziazione per il loro dominio o applicazione, con il potenziale di creare modelli migliori e più accurati e di utilizzare architetture di modelli più piccole e a basso costo.
In questa guida alla creazione di modelli personalizzati, trattiamo:
- Motivazione: Perché e quando dovresti creare un modello GenAI personalizzato?
- Principi: Quali pratiche di alto livello dovrebbero guidare la tua strategia e implementazione nella creazione di modelli personalizzati?
- Tecniche: Come puoi creare modelli personalizzati? Quali tecniche e “insidie” dovresti conoscere per la preparazione dei dati, l'addestramento e la valutazione?
Questa guida è rivolta ai professionisti che pianificano la creazione di modelli personalizzati. Presupponiamo una comprensione di GenAI e dei modelli linguistici di grandi dimensioni (LLM), inclusi termini come prompt engineering, RAG, agenti, fine-tuning e pretraining. Per materiale introduttivo, consulta le informazioni su IA generativa e LLM.
Informazioni su Databricks
Databricks fornisce strumenti unificati per creare, distribuire e monitorare soluzioni AI e ML, dalla creazione di modelli predittivi alle più recenti GenAI e LLM. Costruito sulla Databricks Data Intelligence Platform, Databricks consente alle organizzazioni di integrare in modo sicuro ed economicamente vantaggioso i propri dati aziendali nel ciclo di vita dell'IA con qualsiasi modello GenAI. Consentiamo ai clienti di distribuire, governare, interrogare e monitorare modelli sottoposti a fine-tuning o pre-distribuiti da Databricks, come Meta Llama 3, DBRX o BGE, o da qualsiasi altro provider di modelli come Azure OpenAI GPT-4, Anthropic Claude, AWS Bedrock e AWS SageMaker. Per personalizzare i modelli con dati aziendali, Databricks offre ogni pattern architetturale dal prompt engineering, RAG, fine-tuning e pretraining.
Databricks offre capacità di fine-tuning e pretraining GenAI ineguagliabili da qualsiasi altra piattaforma AI. A giugno 2024, i clienti di Databricks avevano creato oltre 200.000 modelli AI personalizzati nell'anno precedente. Inoltre, Databricks ha modelli pre-addestrati che possono essere utilizzati direttamente dai clienti. A marzo 2024, Databricks ha rilasciato DBRX, un nuovo LLM open source ad alte prestazioni pre-addestrato da zero, con una licenza commercialmente valida. A giugno 2024, Databricks e Shutterstock hanno rilasciato un altro modello pre-addestrato, Shutterstock ImageAI, Powered by Databricks, un modello all'avanguardia text-to-image.
L'infrastruttura e la tecnologia che abbiamo utilizzato per creare questi modelli ad alte prestazioni sono le stesse infrastrutture e tecnologie fornite ai nostri clienti. Consulta le nostre storie di successo dei clienti Databricks per leggere dei successi in data e AI in ogni settore.
Motivazione: Perché fare il fine-tuning o creare LLM personalizzati?
I clienti generalmente iniziano a creare modelli GenAI personalizzati quando i modelli esistenti presentano limitazioni problematiche in termini di qualità, costi o latenza. I dettagli variano per ogni caso d'uso, ma gli esempi includono:
- “Ho bisogno di un modello per generare il linguaggio di query speciale del mio prodotto. Posso farlo usando le API del modello e il few-shot prompting, ma è molto lento e costoso.”
- “Il mio bot RAG funziona bene, ma utilizza un'API di modello grande e potente che è troppo costosa per il mio caso d'uso ad alto throughput. Non ho bisogno di un modello così generico, quindi voglio fare il fine-tuning di un modello piccolo, mirato ed economico.”
- “Non riesco a trovare un modello open source valido per la lingua X, quindi voglio creare un modello su misura per comprendere X.”
I modelli GenAI più famosi sono modelli generici pensati per fare (quasi) tutto. Sebbene impressionanti, questi modelli sono eccessivamente grandi e costosi per la maggior parte dei casi d'uso, e non sanno nulla dei tuoi dati proprietari o della tua applicazione. In ogni esempio sopra, la creazione di un modello personalizzato e specializzato ha aumentato la qualità o ridotto i costi e la latenza. Il modello personalizzato è diventato proprietà intellettuale e ha fornito un vantaggio competitivo per il prodotto del cliente.
Una motivazione meno comune ma più pressante per la creazione di modelli personalizzati deriva da preoccupazioni legali o normative, specialmente in settori più regolamentati. Alcuni clienti desiderano o necessitano di un controllo completo sui propri modelli per gestire i rischi, come le accuse di uso illegale di contenuti per l'addestramento dei modelli. Pre-addestrando un modello completamente personalizzato, puoi sapere e dimostrare esattamente come è stato creato il modello.
Quindi, come puoi iniziare? Sebbene la GenAI sia un campo di ricerca complesso, può essere semplice iniziare a personalizzare i modelli GenAI. Esiste un percorso naturale dal fine-tuning di base al pretraining complesso, e la piattaforma Databricks supporta l'intero flusso di lavoro. Seguendo questo percorso, acquisirai competenze e dati che alimenteranno tipi futuri e più complessi di personalizzazione dei modelli.
Principi: Quando e Come Dovresti Fare il Fine-Tuning o Creare Modelli Personalizzati?
Quando, perché e come dovresti creare modelli personalizzati?
A livello generale, i sistemi GenAI possono essere personalizzati in due modi:
- IA Composta: Dati uno o più modelli esistenti, puoi creare RAG, agenti e altri sistemi di IA composti attorno a tali modelli
- Modelli personalizzati: Puoi personalizzare un modello esistente (fine-tuning) o creare un modello completamente nuovo (pretraining)
Queste due opzioni possono essere combinate, ad esempio RAG che utilizza un LLM sottoposto a fine-tuning. Tali combinazioni — e la velocità dello sviluppo GenAI — possono rendere la pianificazione e la creazione di applicazioni GenAI complesse. Per semplificare il tuo approccio, raccomandiamo tre principi guida.
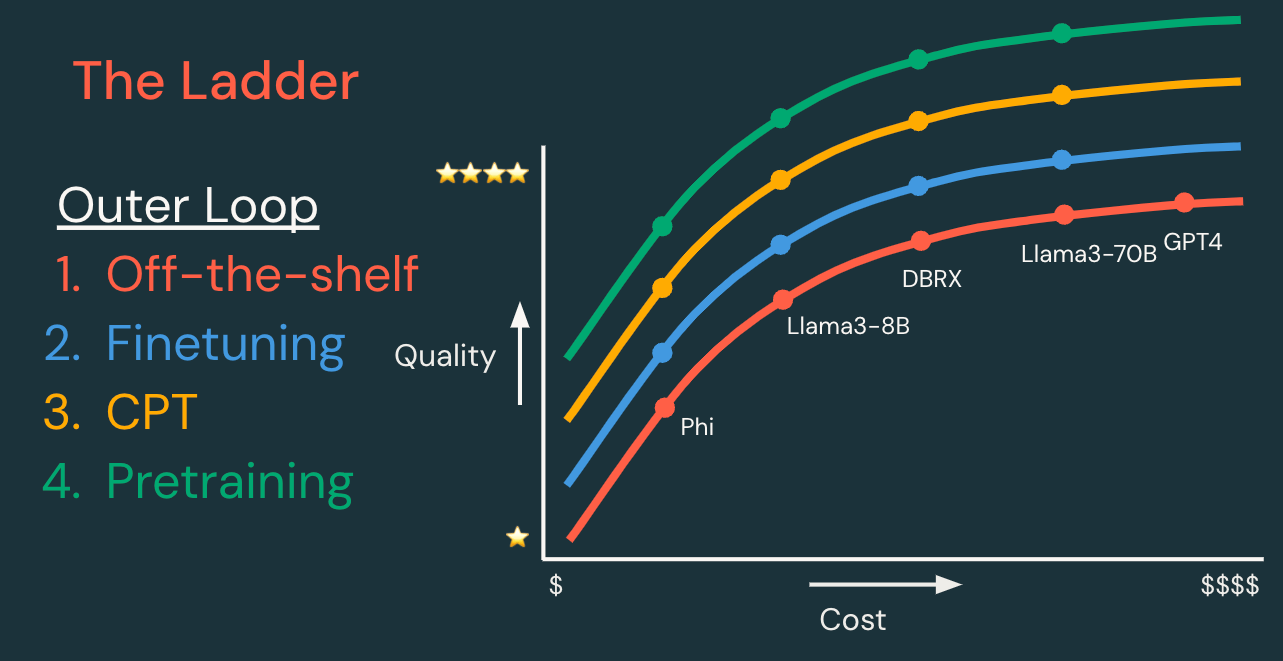
Principio 1: Inizia in piccolo e progredisci
Per qualsiasi applicazione GenAI, ti consigliamo di iniziare in modo semplice e aggiungere complessità secondo necessità. Ciò potrebbe significare iniziare con un modello esistente (come le API Databricks Foundation Model) ed eseguire un semplice prompt engineering. Quindi, aggiungi le tecniche necessarie per migliorare le tue metriche relative a qualità, costi e velocità.
La “scala” delle tecniche può essere divisa in cicli di sviluppo interni ed esterni, delineati di seguito.
Ciclo esterno: Scala di personalizzazione del modello | ||||
Ogni passaggio ha il potenziale per creare un modello di qualità superiore, a costi inferiori e/o con latenza inferiore. | Dati richiesti | Tempo di sviluppo | Costo di sviluppo | |
Modello esistente | Inizia con un modello o un'API di modello esistente e itera prima sul ciclo interno. | Nessuno, o dati per RAG | Ore | $ |
Supervised fine-tuning | Personalizza un modello per gestire meglio il tuo compito specifico. “Aspettati query come queste e restituisci risposte come queste.” | Centinaia–10.000 esempi | Giorni | $$ |
Pre-addestramento continuato | Personalizza un modello per comprendere meglio il tuo dominio. “Impara il linguaggio di questa nicchia applicativa.” | Milioni a miliardi di token | Settimane | $$$ |
Pre-addestramento | Crea un nuovo modello per avere pieno controllo, personalizzazione e proprietà. “Impara tutto da zero!” | Miliardi a trilioni di token | Mesi | $$$$$$ |
Ciclo interno: Tecniche AI composte | |
Ogni tecnica di seguito può migliorare la qualità della generazione per un dato modello. Queste tecniche sono elencate in ordine (approssimativo) di complessità, ma possono essere mescolate e abbinate. | |
Ingegneria dei prompt | Crea prompt specifici per il compito per guidare il comportamento del modello. |
Prompting few-shot | Fornisci dati nei prompt per insegnare ai modelli al momento dell'inferenza. |
RAG | Fornisci dati specifici della query ai modelli come contesto aggiuntivo. |
Agenti | Fornisci ai modelli strumenti richiamabili e/o flussi di controllo complessi. |
Adottare una tecnica dal ciclo interno è relativamente economico e veloce, rispetto a salire di un gradino nel ciclo esterno. Pertanto, ogni volta che sali nel ciclo esterno, vale la pena iterare su alcune o tutte le tecniche nel ciclo interno. Questa designazione “interna” contro “esterna” è l’inverso di quanto ti aspetteresti dall’architettura del sistema — il ciclo “interno” dell’AI composta avvolge il ciclo “esterno” del tuo modello. Chiamiamo la personalizzazione del modello “ciclo” esterno perché è il ciclo esterno in termini di flusso di lavoro, come imposto dai costi relativi dei cicli interni ed esterni.
Principio 2: Sii data-driven
Prima di investire seriamente in qualsiasi progetto, definisci attentamente il tuo metro di giudizio per il successo e segui le popolari pratiche di sviluppo guidato dalla valutazione.
A livello di sistemi AI, considera metriche per qualità, costo e latenza.
- Qualità comporterà probabilmente diverse metriche: accuratezza, feedback degli utenti, tossicità, ecc.
- Costi per i sistemi in produzione si concentrano generalmente sull’inferenza del modello e sul serving dei dati
- Latenza può significare latenza end-to-end, o tempo per il primo token per applicazioni più interattive
Quali numeri devono raggiungere queste metriche per dichiarare il successo? Quali vincoli rigidi hai su queste metriche per garantire una buona esperienza utente, un ritorno positivo sull’investimento o altri requisiti aziendali? Vedi questo intervento del nostro chief AI scientist per ulteriori discussioni.
A livello di progetto e aziendale, analizza il ritorno sull’investimento.
- Costi (investimento) dovrebbero essere divisi in due fasi:
- Costi di sviluppo potrebbero includere costi computazionali e umani per la preparazione dei dati, l’addestramento del modello e lo sviluppo del sistema
- Costi continuativi potrebbero includere il serving del modello e dei dati e le ore di manutenzione del personale
- Impatto aziendale (ritorno)
- Ricavi o altri obiettivi aziendali e risultati chiave (OKR) potrebbero variare dal risparmio di tempo umano (per un bot di supporto GenAI) ai ricavi diretti (per un prodotto basato su GenAI)
- Creazione di IP, come nuovi modelli o dati, potrebbe essere l’impatto più difficile da misurare ma il più grande a lungo termine. Tutti possono utilizzare le stesse API dei provider di modelli, ma solo tu puoi utilizzare i tuoi modelli e dati proprietari.
I tuoi obiettivi data-driven informeranno le tue scelte riguardo alla personalizzazione del modello (principio 1). Ad esempio, se soddisfi le tue metriche di qualità ma superi i tuoi vincoli di costo utilizzando un costoso API di modello, potresti passare al fine-tuning di un modello più piccolo ed efficiente, su misura per il tuo compito specifico, al fine di ridurre i costi mantenendo la qualità. Il fine-tuning comporterà costi di sviluppo aggiuntivi ma ridurrà i costi continuativi — e ridurrà il costo complessivo a lungo termine.
Principio 3: Rimani pratico
Valutare modelli e sistemi GenAI è impegnativo. Le tecniche di fine-tuning e pre-addestramento sono un’area di ricerca molto attiva. L’entusiasmo accademico e industriale (e gli LLM) stanno generando molti più contenuti di quanti se ne possano leggere. Queste fonti di confusione rendono difficile sapere quando utilizzare quali tecniche. (“Ho bisogno di LoRA? Cos’è il curriculum learning? Qual è la migliore architettura di modello?”)
Molte persone nuove a GenAI hanno sentito dire che si possono lanciare montagne di dati a GenAI e che imparerà cose incredibili. Tempera queste aspettative. La quantità di dati è importante, ma anche la qualità dei dati, le tecniche di addestramento e la valutazione sono importanti.
I clienti Databricks possono in parte fare affidamento sulla guida integrata in Databricks durante il loro percorso verso la personalizzazione GenAI. Questa guida varia da semplici API per modelli generali a Agent Bricks Custom Agents per RAG e agenti, a un UI e API per il fine-tuning e persino a un API guidata per il pre-addestramento.
Tuttavia, più approfondisci la personalizzazione, più tecniche e decisioni dovrai prendere. Ti consigliamo di rimanere pratico. Le tecniche che hanno funzionato nella ricerca potrebbero non funzionare nelle applicazioni reali. I modelli buoni per un compito potrebbero essere cattivi per un altro. Le migliori tecniche cambieranno nel tempo. Per navigare questa complessità, tieni a mente i principi 1 e 2: Definisci la tua stella polare e seguila basandoti su dati e metriche.
Ti consigliamo inoltre di collaborare con noi. Oltre al tuo team Databricks immediato, il nostro team di Servizi Professionali può guidarti da proof of concept iniziali a esecuzioni complete di pre-addestramento. Il nostro team di Ricerca Mosaic collabora con molti clienti per esecuzioni di pre-addestramento, dando loro accesso a conoscenze e consigli all’avanguardia.
Tecniche per la Creazione di LLM Personalizzati
Dato che vuoi salire nel ciclo esterno di personalizzazione del modello, come dovresti approcciare le tecniche introdotte con il principio 1? Questa sezione discute la valutazione e poi approfondisce le principali tecniche di personalizzazione.
Nota: Questa guida non si concentra sul ciclo interno di iterazione su un modello fisso. Per ulteriori informazioni su queste tecniche, consulta i corsi Fondamenti di Generative AI e Ingegneria Generative AI con Databricks.
Questa sezione sviluppa le tecniche di personalizzazione delineate in precedenza nel ciclo esterno del principio 1. Le elenchiamo qui e notiamo che la scelta della tecnica sarà in gran parte guidata dai dati disponibili (principio 2).
Ciclo esterno: Scala di personalizzazione del modello | ||
Tipo di dati richiesto | Guida alla dimensione dei dati | |
Modello esistente | NA | Nessuno, o dati per RAG |
Fine-tuning supervisionato | Dati query-risposta (o dati “etichettati” in altro modo) | Almeno centinaia-migliaia di esempi |
Pre-addestramento continuato | Testo “grezzo” per la predizione del token successivo | Milioni a miliardi di token, o 1%+ del set di addestramento originale |
Pre-addestramento | Testo “grezzo” per la predizione del token successivo | Miliardi a trilioni di token |
Nella prossima sezione, tratteremo ogni tecnica in modo più dettagliato, iniziando con le indicazioni che rimangono costanti per tutte le tecniche.
Dati
I tuoi dati devono corrispondere al tuo caso d'uso. Se stai facendo il fine-tuning di un modello per rispondere in un certo modo, allora i tuoi dati di addestramento devono dimostrare risposte “buone”. Se stai facendo pre-addestramento continuato per comprendere un dominio specifico, i tuoi dati devono rappresentare quel dominio.
Affronta le questioni legali e di licenza fin dall'inizio. Quando utilizzi dati pubblici, specialmente per il pre-addestramento, tieni presente che alcuni dataset pubblici sono ben curati per evitare complicazioni legali e alcuni dataset non lo sono. Quando utilizzi i tuoi dati aziendali, assicurati di essere certo della provenienza, in particolare se i dati provengono da clienti o da modelli GenAI con licenze restrittive.
Raccogli dati presto e spesso. Query, risposte e feedback degli utenti dalle tue applicazioni odierne possono diventare input per il tuning e l'addestramento del tuo modello GenAI in futuro, ma solo se ci fai attenzione. Molti modelli proprietari e open source sono dotati di restrizioni d'uso, quindi traccia attentamente la provenienza delle risposte generate. Per darti flessibilità futura, evita di mescolare modelli e dati con licenze incompatibili e prediligi licenze aperte.
Usa dati sintetici con cautela. I dati sintetici possono essere utili, ma i dati aziendali autentici sono quasi sempre più preziosi. I dati “reali” possono essere utilizzati per informare gli LLM su come generare dati sintetici, cosa che imparerai più avanti in questa guida. I dati sintetici sono ancora un'area di ricerca attiva.
Modelli
Sii consapevole dei modelli base rispetto a quelli instruct/chat. La maggior parte delle principali release di LLM include sia modelli base (pre-addestrati ma non sottoposti a fine-tuning) sia varianti instruction-following o chat (sottoposte a fine-tuning). Vedi le nostre raccomandazioni su quale tipo utilizzare nelle sezioni seguenti.
Utilizza i modelli suggeriti dalle funzionalità di Databricks. Mosaic Research studia architetture di modelli all'avanguardia, condivide alcune raccomandazioni principali per i modelli GenAI e dà priorità a tali modelli nelle funzionalità di Databricks Model Training e altre.
Scendi a codice più personalizzato se necessario. Se i modelli o i metodi di addestramento predefiniti non soddisfano le tue esigenze, puoi sempre “scendere nello stack” e utilizzare codice più personalizzato. I cluster con accelerazione GPU di Databricks (calcolo generale) e Databricks Model Training (calcolo specializzato per deep learning) supportano entrambi codice di addestramento arbitrario per GenAI e altri modelli di deep learning.
Identifica i modelli che mostrano promesse per il tuo caso d'uso. Prima del tuning, esamina se il modello generico mostra promesse per la tua applicazione. La “promessa” può essere misurata tramite test manuali ad hoc utilizzando l AI Playground o un test più rigoroso utilizzando un dataset di benchmark o il tuo dataset di valutazione personalizzato. I test potrebbero richiedere addestramento su piccola scala. Per il fine-tuning, il modello migliora dopo il fine-tuning su un piccolo set di 100 esempi? Per il pre-addestramento, il modello migliora dal pre-addestramento continuato su un dataset specifico?
Ricorda i tuoi vincoli. Scegli la dimensione del tuo modello in base ai vincoli di costo e latenza al momento dell'inferenza. Ricorda anche che la creazione di modelli personalizzati è solo l ciclo esterno; puoi anche ottimizzare costi e latenza nell ciclo interno, ad esempio indirizzando richieste più semplici a modelli più piccoli.
Suggerimento: Il tuo lavoro su tecniche più semplici non andrà sprecato, poiché queste tecniche formano una sequenza. Ad esempio, dopo aver pre-addestrato un modello, di solito si procede con il fine-tuning supervisionato.
Valutazione
Il Principio 2 raccomanda di essere guidati dai dati, con metriche. Prima di addentrarci nei dettagli sulla creazione di modelli personalizzati, affronteremo le metriche relative alla valutazione e alla qualità che possono guidare il tuo lavoro.
Come nell'ingegneria del software, raccomandiamo di seguire una piramide di test.
Analogia dei test software | Velocità/costo vs. fedeltà | Esempi |
Test unitari | Misure proxy veloci ed economiche | Test con risposte giuste/sbagliate |
Test di integrazione | Test di velocità/costo medio | Metriche LLM-come-giudice su dataset di benchmark |
Test end-to-end | Test lenti ma realistici | Feedback umano |
Gli esempi nella piramide di test sopra sono scritti in modo generico ed evitano la questione dei test dei modelli (ciclo esterno dal principio 1) rispetto ai sistemi AI composti (ciclo interno). Quando costruisci un modello personalizzato, vorrai testare sia il modello stesso sia i sistemi AI che lo utilizzeranno. Ad esempio, le “metriche LLM-come-giudice” potrebbero essere utilizzate per testare la capacità di un modello di seguire le istruzioni, e potrebbero essere utilizzate per testare le metriche di recupero e le metriche di risposta alle domande di un sistema RAG.
Modelli e attività specifici vs. generali
La tua piramide di test sarà molto diversa quando farai il fine-tuning di un modello per un'attività specifica rispetto al pre-addestramento di un modello generico. Essere guidati dai dati e dalle metriche significa adattare la tua piramide di test ai casi d'uso downstream del tuo modello.
Se stai facendo il fine-tuning di un modello per un'attività specifica, ricorda di iniziare in piccolo (principio 1). Ad esempio, potresti:
- Costruire un dataset di query-risposta “golden” per la valutazione. Assicurati che sia bilanciato tra query e argomenti potenziali.
- Utilizzare metriche LLM-come-giudice per scalare la valutazione. Scegli o personalizza metriche per la tua attività specifica.
- Utilizzare la valutazione umana o dell'utente come test finale
Quando inizi il pre-addestramento continuato o il pre-addestramento completo, le tue valutazioni potrebbero diventare più complesse. Mentre pianifichi la tua piramide di test, suddividi la tua valutazione in base alle diverse competenze che ritieni il tuo modello debba possedere in modo da poterti concentrare sulle aree importanti. Ciò potrebbe significare:
- Competenze come conoscenza generale, logica o comprensione della lettura
- Domini come finanza, legge o assistenza sanitaria
- Lingue, comprese lingue naturali o linguaggi di programmazione
- Altre dimensioni, dalla lunghezza del contesto alle guardrail integrate
Suggerimenti:
- Personalizza la tua valutazione in base ai tuoi casi d'uso. Ad esempio, se stai modificando un modello per gestire lunghezze di contesto maggiori, ricorda che le metriche di perplexity del pre-addestramento continuo non sono sufficienti. Anche il tuo set di dati di valutazione deve includere attività a contesto lungo.
- Testa sia l'apprendimento che l'oblio. Se stai eseguendo il pre-addestramento continuo per migliorare la comprensione di un modello di una lingua specifica (ad es. Malese), considera se i tuoi casi d'uso richiedono che il modello mantenga la sua comprensione esistente delle lingue (ad es. Inglese). In tal caso, la tua valutazione dovrebbe testare sia il Malese sia l'Inglese.
- Testa ciò che i tuoi clienti utilizzeranno effettivamente. Se stai pre-addestrando un nuovo modello (base), probabilmente eseguirai il fine-tuning delle istruzioni per creare la versione del modello che i tuoi clienti utilizzeranno effettivamente. La tua valutazione finale (end-to-end) dovrebbe essere sul modello sottoposto a fine-tuning, non sul modello base.
Esempi dalla creazione di DBRX
A maggio 2024, Databricks ha rilasciato DBRX, un LLM open source all'avanguardia (all'epoca). La sua suite di valutazione fornisce un buon esempio di piramide di test, che è delineata di seguito.
Analogia dei test del software | Esempi di metriche dalla creazione di DBRX | |
Test unitari | 39 benchmark disponibili pubblicamente divisi in sei competenze principali: comprensione del linguaggio, comprensione della lettura, risoluzione di problemi simbolici, conoscenza del mondo, buon senso e programmazione | |
Test di integrazione | Dati di benchmark per conversazioni multi-turno e per seguire istruzioni | |
Dati di benchmark per seguire istruzioni | ||
Chatbot Arena–generatore basato su per dati di benchmark di preferenza umana | ||
Test end-to-end | Feedback interno e dei clienti e test A/B | Test iterativi con utenti interni ed esterni per raccogliere sia metriche di test A/B che annotazioni umane |
Red-teaming | Test esperti per generare output indesiderati (offensivi, distorti o altrimenti insicuri) |
Per maggiori informazioni sulle metriche di valutazione, consigliamo questo corso Generative AI Engineering. Per gli strumenti, consigliamo Databricks MLflow, che supporta metriche automatizzate (LLM-come-giudice), set di dati di valutazione e un'app di valutazione umana. Agent Evaluation utilizza le API open source MLflow per la valutazione degli LLM. Per una valutazione più approfondita per il pre-addestramento, possiamo collaborare con te per sviluppare il tuo piano di valutazione personalizzato.
Fine-tuning supervisionato
La prima tecnica per la personalizzazione del modello utilizzata dalla maggior parte dei professionisti è il fine-tuning supervisionato (SFT), in cui un modello viene addestrato su dati etichettati per ottimizzarlo per un'attività o un comportamento specifico.
Casi d'uso comuni includono:
- Riconoscimento di entità nominate: Esegui il fine-tuning di un modello per riconoscere entità specifiche del dominio
- Completamento chat e risposta alle domande: Esegui il fine-tuning di un modello per rispondere con un tono specifico
- Formattazione dell'output: Esegui il fine-tuning di un modello per rispondere con output specifici e strutturati
- Seguire le istruzioni: Dopo il pre-addestramento di un modello generale, è comune utilizzare il fine-tuning delle istruzioni per insegnare al modello a rispondere a istruzioni e query, piuttosto che generare semplicemente testo di completamento
Terminologia: "Fine-tuning" è spesso usato per significare "fine-tuning supervisionato", ma tecnicamente, "fine-tuning" è qualsiasi adattamento di un modello esistente. Anche il pre-addestramento continuo e l'apprendimento per rinforzo dal feedback umano (RLHF) sono tipi di fine-tuning.
Il fine-tuning è di gran lunga il tipo di personalizzazione del modello più veloce ed economico. Ad esempio, per il modello MPT-7B rilasciato a maggio 2023, il fine-tuning delle istruzioni è costato $46 per elaborare 9,6 milioni di token, mentre il pre-addestramento è costato $250.800 per elaborare 1 trilione di token.
Dati
Quando prepari i tuoi dati, il contenuto e la formattazione sono fondamentali. Una gran parte del fine-tuning consiste nell'insegnare al modello quali input aspettarsi e quali output ti aspetti. Come appariranno le query dei tuoi utenti, in termini di formato, tono, copertura dell'argomento o altri aspetti? I tuoi dati di addestramento dovrebbero rappresentare queste aspettative.
La dimensione dei dati è un argomento di discussione comune ed è in definitiva dipendente dal caso d'uso. In alcuni casi, abbiamo visto buoni risultati con il fine-tuning su set di dati minuscoli di centinaia o migliaia di esempi, ma alcune applicazioni richiedono decine di migliaia o centinaia di migliaia di esempi. Inizia in piccolo per convalidare il tuo piano, quindi aumenta iterativamente, espandendo il tuo set di dati di addestramento se necessario.
I dati sintetici possono essere utili per l'SFT, più comunemente per espandere un set troppo piccolo di dati "reali". Un LLM può essere sollecitato a generare dati SFT sintetici simili a esempi dai tuoi dati reali.
Vedi anche la documentazione sulla preparazione dei dati per Databricks Model Training.
Modelli
In precedenza in questa guida, abbiamo consigliato di utilizzare i modelli supportati da Databricks Model Training per impostazione predefinita e di testare i modelli per le promesse per il tuo caso d'uso. Un buon esempio di ciò è venuto da MPT. Sebbene MPT non fosse stato addestrato pensando al giapponese, un rapido test di fine-tuning con 100 esempi di prompt-risposta in giapponese ha prodotto un modello sorprendentemente efficace per un cliente. Quel rapido test ha convalidato l'approccio e ha aperto la strada al fine-tuning su larga scala.
Quando scegli una dimensione del modello, considera di iniziare con un modello sovradimensionato. Quando esegui il tuning con un piccolo set di dati, è più probabile che un modello più grande produca buoni risultati rispetto a un modello più piccolo. Iniziare con un modello di grandi dimensioni può informarti sul potenziale dei tuoi dati e del tuo caso d'uso, e l'SFT è relativamente economico. Dopo aver visto il potenziale, puoi testare con modelli più piccoli e più dati.
Puoi eseguire l'SFT su varianti base o instruct/chat dei modelli. Per impostazione predefinita, ti consigliamo di utilizzare una variante instruct/chat, specialmente se hai un piccolo set di dati. Se hai eseguito il pre-addestramento continuo per creare un modello base personalizzato, allora puoi eseguire l'SFT sul tuo modello base personalizzato.
Databricks Model Training
Databricks Model Training fornisce interfacce semplici (UI e API) per attività di fine-tuning supervisionato. Oltre ai suggerimenti su dati e modelli già presentati in questa guida, considera:
- Attività: Le attività SFT possono essere specificate in modi diversi, a seconda del formato della query previsto. Nota che consigliamo la formattazione del completamento della chat per impostazione predefinita, anche per le attività di istruzione, per adattarsi agli standard comuni.
- Configurazione: Man mano che si procede, il primo iperparametro da ottimizzare è il tasso di apprendimento. Prova una griglia di tassi, quindi ingrandisci una griglia di tassi di apprendimento più raffinati centrati sui migliori tassi iniziali, in modo simile alla regolazione dei tassi di apprendimento negli algoritmi di machine learning (ML) tradizionali. Considera anche la regolazione della durata dell'addestramento (epoche o token) in base ai grafici del progresso dell'apprendimento. Alcuni task di fine-tuning richiedono poche epoche, mentre altri beneficiano di 50+ epoche.
- Valutazione: Specifica un set di dati di valutazione per consentire a Databricks Model Training di calcolare le valutazioni iniziali (“unit test”). Anche un piccolo set di dati di 50 coppie query-risposta può fornire un segnale, sebbene set di dati più grandi e vari siano migliori. Utilizza Databricks MLflow per valutazioni più approfondite, soprattutto perché la perdita di valutazione in fase di addestramento (o l'accuratezza) potrebbe non correlare bene con le valutazioni degli utenti finali.
Altro sul fine-tuning supervisionato
Consigliamo Databricks Model Training per un flusso di lavoro semplice ed efficiente per impostazione predefinita. Tuttavia, se è necessario utilizzare un'architettura di modello non supportata o metodi di tuning più personalizzati, è possibile eseguire codice completamente personalizzato su cluster Databricks accelerati da GPU (calcolo generale) e Databricks Model Training.
Questa guida non approfondisce il fine-tuning efficiente dei parametri (PEFT), una famiglia di tecniche come l'adattamento a basso rango (LoRA) per rendere più efficienti il fine-tuning e l'inferenza. Vedere questo blog, questo blog o Hugging Face PEFT per descrizioni ed esempi di queste tecniche.
Pre-addestramento continuo
Il fine-tuning supervisionato (SFT) non è progettato per insegnare a un modello come comprendere un nuovo dominio. Per personalizzare un modello per comprendere una nuova lingua, un settore di nicchia o un'altra area specifica, i professionisti possono ricorrere al pre-addestramento continuo (CPT). Il CPT è simile al pre-addestramento, tranne per il fatto che si prende un modello pre-addestrato esistente e quindi si *continua* il processo di pre-addestramento utilizzando nuovi dati. Dopo il CPT per adattarsi a un nuovo dominio, il modello viene generalmente adattato a task specifici tramite fine-tuning supervisionato.
Casi d'uso comuni includono:
- Lingue: I modelli generali hanno spesso visto molte lingue naturali nei loro dati di addestramento, ma potrebbero essere deboli in tutte le lingue tranne quelle principali. Il CPT può potenziare la comprensione di un modello di una lingua specifica.
- Programmazione: I modelli generali hanno spesso visto almeno alcune lingue di programmazione nei loro dati di addestramento, ma i modelli potrebbero non essere principalmente progettati per la codifica o potrebbero non comprendere bene una specifica lingua di programmazione. Il CPT può insegnare a un modello come codificare in una specifica lingua di programmazione.
- Domini industriali: I modelli generali potrebbero non avere una conoscenza approfondita di aree tematiche specifiche, come la biologia molecolare, il diritto ambientale o le normative finanziarie. Il CPT può potenziare la conoscenza e la comprensione di un modello di un dominio specifico.
Per migliorare il modello di istruzioni del mio bot RAG Q&A, dovrei usare il fine-tuning supervisionato (SFT) o il pre-addestramento continuo (CPT)?
Entrambe le tecniche possono essere applicabili, ma dipende dai dati di addestramento che hai e da cosa vuoi migliorare del modello. Se vuoi insegnare al modello a rispondere in un certo modo, usa SFT — se hai dati query-risposta per l'addestramento. Se il modello non comprende il tuo dominio o la tua lingua, usa CPT — se hai una quantità considerevole di dati testuali per l'addestramento. Tieni presente che dopo il CPT, probabilmente dovrai eseguire SFT per re-insegnare al modello come rispondere alle query.
Posso usare SFT o CPT per insegnare al mio modello nuove conoscenze e fatti?
Sì, entrambe le tecniche possono impartire alcune conoscenze, ma il CPT è più applicabile. Indipendentemente da ciò, potrebbe essere necessario utilizzare RAG per rendere robusto il tuo sistema AI basando le risposte sui dati di origine.
Dati
Quando consideri quali dati ti servono per il CPT, ricorda il principio 2 (“guidato dai dati”). *Cosa vuoi migliorare del modello originale?* I tuoi dati dovrebbero rappresentare il dominio, la lingua, la conoscenza, ecc. che vuoi instillare nel modello. Per un caso d'uso specifico, ciò si tradurrà probabilmente nell'esecuzione del CPT sui tuoi dati aziendali proprietari pertinenti al caso d'uso — la tua knowledge base interna, articoli di ricerca pertinenti degli ultimi 20 anni, ecc. Per un modello più generale, la nostra guida per i dati diventa più simile a quella per il pre-addestramento, dove potresti selezionare diversi set di dati per rappresentare le diverse competenze importanti per il tuo caso d'uso.
Suggerimento: Dimenticare vs. imparare. Mentre testi il CPT, tieni presente che ci sono compromessi tra dimenticare le conoscenze passate e acquisire nuove conoscenze. Il tuo obiettivo è spostare il comportamento del modello per imitare i tuoi dati di addestramento CPT, ma ciò potrebbe significare dimenticare aspetti dei dati di pre-addestramento originali. Pertanto, assicurati che sia i tuoi dati di addestramento CPT sia la tua suite di valutazione coprano i domini che ti interessano.
Per il *formato dei dati*, i tuoi dati saranno testo “grezzo”. Cioè, eseguirai il CPT facendo la predizione del token successivo, proprio come nel pre-addestramento.
Per la *dimensione dei dati*, il CPT può variare da un aggiustamento di un modello utilizzando meno token a un cambiamento significativo di un modello utilizzando molti token. “Meno” e “molti” dipenderanno dalla dimensione del modello, ma una stima ragionevole sono miliardi di token per gli LLM moderni di medie dimensioni. Una regola empirica è che il CPT richiederà almeno circa l'1% della dimensione del set di addestramento originale.
Ho bisogno sia di dati grezzi per il CPT che di dati prompt-risposta per SFT?
Se esegui CPT seguito da SFT, allora sì. Tuttavia, se hai dati per CPT ma pochi dati per SFT, puoi aumentare il tuo piccolo set di dati SFT con dati query-risposta utilizzando altri set di dati SFT o dati sintetici.
Dati sintetici possono essere utili per il CPT, specialmente per la distillazione, in cui un modello grande e potente viene utilizzato per generare dati per addestrare un modello più piccolo. La distillazione può aiutare a creare modelli più piccoli, più veloci ed economici e può integrare i tuoi dati non sintetici specifici per i tuoi casi d'uso.
Vedi anche la documentazione sulla preparazione dei dati per Databricks Model Training.
Modelli
Proprio come per SFT, consigliamo di utilizzare i modelli supportati da Databricks Model Training per impostazione predefinita e di testare i modelli per la promessa per il tuo caso d'uso.
Le nostre raccomandazioni sulla messa a punto di un modello di base rispetto a una variante instruct/chat, e sull'esecuzione di SFT dopo CPT, sono intrecciate. Il percorso più comune, e la nostra raccomandazione predefinita, è eseguire CPT su un modello di base, seguito da SFT per il fine-tuning di istruzioni o chat. Tuttavia, ci sono delle sfumature:
- Variante base vs. instruct/chat: È più comune eseguire CPT sul modello di base. L'esecuzione di CPT su un grande set di dati su una variante instruct o chat potrebbe far perdere a quel modello alcune capacità di seguire istruzioni o di chat.
- SFT dopo CPT: Se esegui CPT su una grande quantità di dati, probabilmente la seguirai con SFT. Tuttavia, se esegui CPT su un modello di istruzioni o chat utilizzando una piccola quantità di dati, potresti non aver bisogno di SFT in seguito. Abbiamo visto alcuni clienti farlo e poi utilizzare il modello risultante direttamente nelle loro applicazioni.
Databricks Model Training
Databricks Model Training offre interfacce semplici (UI e API) per il CPT. I suggerimenti per l'SFT menzionati in precedenza in questa guida si applicano in gran parte anche al CPT. Convenientemente, la funzionalità di Model Training può essere utilizzata per eseguire sia CPT che SFT.
La tua piramide di test dalla precedente discussione sulla valutazione richiederà test più robusti e generali, poiché il CPT può modificare il modello in modo più fondamentale rispetto all'SFT. Man mano che aumenti il CPT, la tua piramide di test potrebbe assomigliare di più a una suite di test di pre-training.
Ulteriori informazioni sul CPT
Man mano che i tuoi carichi di lavoro CPT diventano più personalizzati e più grandi, potresti anche voler esplorare lo stack di pre-training discusso di seguito.
Il CPT è utile per testare i dati per il pre-training. Se i tuoi dati CPT coprono un nuovo dominio (come un nuovo linguaggio di programmazione), allora dimostrare successo con il CPT indica che i dati potrebbero essere utili come parte di un set di dati di pre-training.
Pre-training
Supponiamo che la tua applicazione GenAI sia progredita attraverso il pre-training continuo e tu ritenga che il pre-training di un modello completamente personalizzato sia il prossimo passo necessario per migliorare la tua applicazione. Questa sezione delinea il processo e le best practice ad alto livello, ma in pratica, dovresti seguire il processo di pre-training con il tuo team Databricks.
Dovresti mai passare direttamente al pre-training?
No. Anche se vincoli normativi o di altro tipo richiedono la creazione di un nuovo modello di cui sei pienamente proprietario, è meglio prototipare prima sui gradini inferiori della scala di personalizzazione. Ciò ti consente di ridurre il rischio di esecuzioni di pre-training più costose e complesse.
Quali sono i passaggi per il pre-training?
La realtà è che il pre-training è un processo iterativo e adattivo, ma i passaggi comuni ad alto livello nel pre-training includono:
- Prima lavora attraverso il fine-tuning e il pre-training continuo. Fai la dovuta diligenza!
- Prepara i set di dati. Ciò avviene durante il passaggio 1, in cui il CPT ti aiuta a testare l'utilità di determinati set di dati.
- Pre-traina un modello di base in grado di completare il testo. Ciò comporta il monitoraggio dell'addestramento, la modifica dell'esecuzione lungo il percorso e tecniche adattive come il curriculum learning per regolare il mix di dati.
- Esegui l'addestramento di istruzioni o chat per creare una variante di istruzioni/chat.
- Potenzialmente utilizza tecniche come il reinforcement learning from human feedback (RLHF) per ottimizzare ulteriormente il modello.
- Durante ogni passaggio sopra, valuta i tuoi modelli lungo il percorso.
Questo breve riepilogo procedurale enfatizza la dovuta diligenza e la valutazione a causa del costo relativamente elevato del pre-training completo. Ricorda l'esempio citato in precedenza del modello MPT-7B, per il quale il pre-training è costato 5452 volte di più del fine-tuning delle istruzioni.
Dati
La tua scelta e il trattamento dei dati giocheranno un ruolo enorme nel determinare il successo delle tue esecuzioni di pre-training.
Quali dati?
Il tuo mix di dati dovrebbe essere scelto attentamente per rappresentare la tua applicazione di destinazione.
- Proprio come le valutazioni devono essere suddivise per le competenze che desideri che il tuo modello abbia, considera cosa insegnerà al modello ciascun set di dati che porti al pre-training. Puoi testare in anticipo l'impatto di questi set di dati utilizzando il pre-training continuo.
- Pochi modelli ad alte prestazioni forniscono dettagli pubblicati sui loro mix di dati. Alcuni modelli più vecchi hanno elenchi pubblicati (ad es. MPT, LLaMA, OLMo). Vedi anche questa discussione sul mix di dati.
- Probabilmente mescolerai set di dati pubblici e proprietari. I set di dati pubblici, adeguatamente verificati, possono soddisfare alcune delle tue esigenze di addestramento, come insegnare capacità linguistiche, conoscenza generale e alcune competenze specifiche. I set di dati proprietari offrono ai tuoi modelli un vantaggio competitivo non disponibile per nessun altro.
La quantità e la qualità dei dati sono importanti, ma in momenti diversi. È comune iniziare il pre-training su “tutti i dati” con controlli di qualità meno rigorosi. Inizialmente, più token si traducono in un maggiore apprendimento delle capacità linguistiche di base. Tuttavia, in seguito, durante il pre-training, è comune cambiare il mix di dati in un set più piccolo e di qualità superiore. “Alta qualità” non ha una definizione accademica, ma intuitivamente significa curato utilizzando tecniche di buon senso. Vedi quanto segue per ulteriori informazioni sulla preparazione dei dati.
Quanti dati?
- La tua dimensione dei dati dovrebbe essere scelta tenendo conto delle dimensioni e dell'architettura del modello.
- La regola empirica “Chinchilla” è la regola più famosa: # token = 20 * # parametri. Per ridurre i costi di inferenza, ti consigliamo di addestrare un modello più piccolo con più dati per ottenere una qualità di generazione simile, secondo i risultati di questo paper LLaMA.
- Le architetture Mixture of Experts (MoE) possono cambiare questo calcolo, richiedendo spesso meno dati per una data dimensione del modello. Per le MoE, utilizzare il numero di parametri attivi (non i parametri totali) per effettuare questo calcolo.
- Tieni presente che alcuni compiti sono più difficili di altri. Ad esempio, i modelli da 7 miliardi di parametri richiedono generalmente almeno 2 trilioni di token di dati di addestramento per affrontare il benchmark di codifica HumanEval.
Come dovrebbero essere preparati i dati?
- Download e parsing: Generalmente è necessario acquisire i dati da soli. Pochi provider offrono dati su scala internet pre-scaricati e i requisiti normativi possono variare per cliente.
- Pulizia: Mentre il pre-training può sfruttare grandi quantità di dati di bassa qualità, vale la pena migliorare la qualità dei dati. Ad esempio, questo paper RefinedWeb stima che circa l'11% di Common Crawl sia utile. La pulizia dei dati per il pre-training è un argomento vasto e complesso con molte ricerche attive. Vedi questo paper per un'eccellente panoramica dei passaggi comuni, tra cui:
- Filtraggio linguistico per ridurre il testo alle lingue principali di interesse
- Filtraggio euristico per rimuovere testo boilerplate, documenti troppo brevi o lunghi, testo non naturale, ecc.
- Filtraggio di qualità per identificare testo che è più probabile che sia stato scritto o revisionato da esseri umani
- Filtraggio per dominio per identificare testo sui domini di interesse
- De-duplicazione del contenuto all'interno o tra i set di dati
- Filtraggio di contenuti tossici ed espliciti in base all'origine o al testo
- Nota che tutte queste tecniche presentano delle avvertenze. Per ciascuna, la rigidità del filtro deve essere calibrata per bilanciare precisione e richiamo. Per alcune, il filtro potrebbe essere fuorviante: la duplicazione potrebbe indicare che il testo è più valido o importante, e un modello che non ha mai visto contenuti tossici potrebbe non riconoscere la tossicità e quindi ripetere facilmente gli input tossici dell'utente.
- Come accennato, il pre-training iniziale può utilizzare più dati con controlli di qualità meno rigorosi, mentre il pre-training successivo può concentrarsi su sottoinsiemi di dati più attentamente puliti.
- Pre-calcolo: Pre-tokenizzare e concatenare i dati per ottimizzare il loro formato per il pre-training può migliorare l'efficienza.
L'elaborazione dei dati è il punto di forza originale di Databricks. Fai uso di quanto segue:
- Workflows per definire job e orchestrazione, con Apache Spark™ e ottimizzazioni Delta per l'elaborazione su larga scala
- Delta Lake come formato di archiviazione dei dati
- Unity Catalog per la gestione dei dati
- Notebook, integrazione IDE e Databricks SQL per lo sviluppo e l'esplorazione dei dati
- Lakehouse Monitoring per il monitoraggio a lungo termine di pipeline e origini dati
Modelli
Sebbene i ricercatori esaltino naturalmente le nuove architetture di modelli come grandi scoperte, c'è un motivo per cui l'architettura Transformer domina ancora, nonostante risalga al 2017 (risale al 2017): funziona davvero bene. Allo stesso modo, generalmente consigliamo di attenersi a scelte architettoniche comprovate, come:
- Utilizzare meccanismi di attenzione standard come l'attenzione quadratica o FlashAttention-2, piuttosto che metodi meno testati dalla ricerca
- Considerare architetture mixture of experts (MoE) per un training e un'inferenza più efficienti, nonché per aritmetica a precisione inferiore
- Addestrare il proprio transformer utilizzando la predizione del token successivo
Databricks supporta il pre-training su architetture arbitrarie, ma forniamo configurazioni di pre-training più semplici per le architetture consigliate tramite Databricks Model Training, che fornisce versioni gestite e ottimizzate di strumenti come Mosaic LLM Foundry e Mosaic Diffusion. Questo tooling può semplificare le scelte fornendo impostazioni predefinite standard e ben testate. Ad esempio, a luglio 2024, LLM Foundry consiglia FlashAttention-2 come meccanismo di attenzione standard e supporta architetture MoE come DBRX. Per la tua applicazione specifica, possiamo fornire consulenza sui dettagli dell'architettura.
Per quanto riguarda le dimensioni del modello, ricorda di iniziare in piccolo (principio 1). Addestrare un modello da 7 miliardi di parametri costa circa 10 volte meno di un modello da 70 miliardi e può informare le tue scelte di modellazione per quando scalerai. Considera anche i vincoli di latenza e costo del tuo caso d'uso come limiti alla dimensione potenziale del modello.
Stack di training e infrastruttura
Con i dati e le scelte di modellazione preparati, potresti essere pronto per il pre-training. Questo potrebbe essere il passaggio più costoso che intraprendi con GenAI, da qui la preparazione attenta nei passaggi precedenti. Durante questo passaggio, è fondamentale utilizzare strumenti robusti e consulenti esperti per garantire che il pre-training proceda senza intoppi.
I processi di pre-training presentano molte sfide. La piattaforma Databricks gestisce automaticamente molte di queste sfide per l'utente.
Sfida | Databricks |
Caricamento dati: Potrebbe essere necessario caricare trilioni di token. | Databricks offre tempi di avvio e ripristino rapidi. |
Scalabilità e ottimizzazione: Potrebbe essere necessario scalare da 10 a 1000 GPU. Esistono molte tecniche per ottimizzare le prestazioni di training. | Databricks offre uno scaling-out senza interruzioni tramite parallelismo dei dati e FSDP, e una libreria di ottimizzazioni componibili. Raggiunge un utilizzo dei FLOPS del modello (MFU) di prim'ordine. |
Ripristino da errori: Ci si può aspettare circa 1 errore infrastrutturale ogni 1000 GPU-giorno sulla maggior parte dei cloud. I processi di pre-training potrebbero mostrare picchi di perdita o divergenza. | Databricks rileva automaticamente gli errori ed esegue riavvii rapidi. Lo stack di training riduce anche i picchi di perdita. |
Determinismo: Il caricamento e il training distribuiti dei dati rendono difficile il determinismo, ma è prezioso per il ripristino e la riproducibilità. | Gli algoritmi di caricamento dati e training di Databricks rendono il pre-training molto più riproducibile. |
Lo stack Databricks Training si estende dall'hardware alla gestione dei carichi di lavoro. La tabella seguente elenca i componenti chiave da conoscere per primi.
Fase | Componente Databricks | Dettagli |
Caricamento dati | Fornisce streaming rapido e riproducibile di dati di training dall'archiviazione cloud, inclusi avvii e riavvii rapidi. | |
Training | Fornisce best practice e tecniche componibili per un training distribuito ed efficiente. | |
Configurazione del flusso di lavoro | Consente una semplice definizione dei flussi di lavoro, inclusi preparazione dei dati, training, fine-tuning e valutazione. Databricks può fornire configurazioni standard per aiutarti a iniziare il pre-training di architetture comuni. | |
Tracciamento esperimenti | Traccia metriche di valutazione e altre durante i processi di pre-training. Databricks supporta anche Weights & Biases. |
Il tuo caso d'uso potrebbe seguire i percorsi ben battuti delineati come "ricette" di configurazione da LLM Foundry, nel qual caso il tuo flusso di lavoro potrebbe essere molto guidato dalla configurazione. Oppure, se richiedi architetture o codice più personalizzati, potresti concentrarti su parti di livello inferiore dello stack come MCLI, lavorando più direttamente con l'infrastruttura Databricks.
Calcolo e costi
Prima di pre-addestrare un modello, è importante stimare i costi. Il costo di calcolo del pre-training è spesso semplice da stimare poiché si riduce alla stima delle ore GPU, in base alle dimensioni dei dati e del modello. Il tuo team Databricks può fornire stime accurate, ma per qualsiasi provider, assicurati di comprendere due calcoli chiave:
FLOPS = 6 x parametri x token
Questa regola empirica indica che il calcolo (e il costo) aumenteranno linearmente con le dimensioni del modello e con le dimensioni dei dati. Nota che "parametri" si tradurrà in "parametri attivi" per architetture sparse come MoE.
Utilizzo dei FLOPS del modello (MFU) = utilizzo medio della GPU in pratica
L'MFU non è mai il 100% in pratica, ed è spesso molto inferiore. Diversi modelli e tipi di dati possono raggiungere diversi MFU. Lo stack Databricks è ottimizzato per raggiungere MFU ad alte prestazioni.
Cosa ne pensi delle epoche?
Addestrare per N epoche costerà N volte di più di 1 epoca. Tuttavia, per il pre-training, è comune utilizzare una singola epoca, anche se potresti ripetere alcuni dati chiave di alta qualità nel tuo training. Questo è diverso dalle molte epoche utilizzate nell'apprendimento profondo più tradizionale. Vedi questo paper per ulteriori informazioni.
Oltre ai costi di calcolo del pre-training, fai anche delle stime per:
- Costi dei dati, inclusi acquisto, cura ed etichettatura
- Costi di inferenza
Durante il pre-training
Una volta avviato il pre-training, potrebbe funzionare "senza problemi" su Databricks, ma è comunque importante monitorare il training e sapere come eseguire il debug o migliorare l'apprendimento. Il tuo team Databricks può aiutarti a monitorare e risolvere i problemi.
Il monitoraggio comporta due aree principali:
- Infrastruttura: Databricks Training gestisce la maggior parte dei problemi infrastrutturali per te. Ad esempio, eseguirà automaticamente il checkpoint e riprenderà il training in caso di guasti a GPU, rete o altre infrastrutture. È utile monitorare l'utilizzo, soprattutto quando si utilizzano configurazioni non standard.
- Progresso nell'apprendimento: è necessario monitorare la perdita e altre metriche sui dati di training e valutazione per verificare problemi di dati e configurazione. I sintomi più comuni da osservare sono picchi di perdita e divergenza. In Databricks Training, consigliamo di registrare negli esperimenti MLflow per impostazione predefinita per il monitoraggio in tempo reale e la revisione post hoc.
Il debug richiede più frequentemente la regolazione di:
- Configurazioni: se le tue configurazioni sono impostate male, questi problemi spesso si manifestano presto durante il training. Il tasso di apprendimento è la configurazione più comune che richiede aggiustamenti.
- Dati: ad esempio, un problema comune di training è osservare picchi di perdita dovuti a dataset non mescolati correttamente. Databricks Training semplifica il mescolamento tramite la libreria Mosaic Streaming, ma il mescolamento comporta un costo, quindi Streaming supporta diverse impostazioni di mescolamento per supportare compromessi tra qualità e costo. Se osservi picchi di perdita, è possibile che l'impostazione di parametri di mescolamento più robusti in Streaming possa prevenirli. Ad esempio, se i tuoi dati provengono da diversi bucket (domini, lingue, ecc.) e non sono mescolati correttamente, è più probabile che tu osservi picchi di perdita.
Curriculum learning: il pre-training spesso non viene eseguito su un singolo dataset omogeneo. Il modello finale può spesso essere migliorato variando il mix di dati durante il processo di training, e la tecnica più comune per questo è il curriculum learning, in cui dataset di qualità superiore e più mirati vengono enfatizzati nel mix di dati più avanti nel training. I mix di dati possono essere specificati in anticipo, oppure il mix di dati può essere regolato manualmente per rafforzare il modello in determinate aree.
Dopo il pre-training
Dopo il pre-training, potrebbero esserci ulteriori passaggi per preparare un modello per le applicazioni finali, come:
- Ulteriore curriculum learning o pre-training continuato per mettere a punto il modello
- Fine-tuning supervisionato, ad esempio per l'instruction-following o la chat
- Apprendimento per rinforzo da feedback umano (RLHF), una tecnica avanzata per mettere a punto un modello per adattarlo alle preferenze umane. Questo può essere molto potente ma complesso da fare correttamente, e non è necessario per tutte le applicazioni. Per molte applicazioni, il fine-tuning supervisionato o i guardrail possono essere sufficienti.
- Iterare su quanto sopra, in base alle valutazioni degli utenti finali del modello o dell'applicazione
Il Futuro
Il ritmo dello sviluppo GenAI non sta rallentando. Le GPU e altri hardware specializzati diventeranno più veloci ed economici. Gli stack software miglioreranno. Nuove architetture di modelli e tecniche di training passeranno dalla ricerca alla pratica. Cosa puoi fare per prepararti?
Con Databricks, sarai in grado di sfruttare molti sviluppi per impostazione predefinita. Databricks Model Training, Model Serving e altre funzionalità continueranno ad aggiungere supporto per i modelli più recenti. Nuove tecniche di training e inferenza saranno integrate sotto il cofano. Per carichi di lavoro più grandi e complessi, Databricks supporterà la personalizzazione completa, e i carichi di lavoro più all'avanguardia saranno realizzati di pari passo con il team di ricerca Mosaic.
Nella tua organizzazione, concentrati sul supporto di carichi di lavoro flessibili e personalizzabili ora e in futuro:
- Sviluppa la tua infrastruttura AI. Imposta la governance delle API dei modelli tramite un gateway AI. Imposta processi di sicurezza utilizzando un framework di sicurezza AI. Standardizza e unifica la governance dei dati e dell'AI sotto Unity Catalog. Sviluppa sia il loop interno utilizzando Agent Framework sia il loop esterno utilizzando Model Training. Sviluppa la tua pratica MLOps, inclusi Model Serving e Monitoring robusti.
- Sviluppa la tua expertise AI. Collabora con il tuo team Databricks per sviluppare un centro di eccellenza (CoE) per l'AI. Sfrutta Databricks Training per guidare i team lungo percorsi di apprendimento personalizzati per i loro ruoli.
- Sviluppa la tua proprietà intellettuale. Questa IP includerà non solo modelli personalizzati ma, cosa più importante, i tuoi dati aziendali. Raccogli dati dalle applicazioni e dagli utenti attuali, traccia la provenienza e fai attenzione alla regolamentazione e alle licenze. Questi dati alimenteranno tutta la tua personalizzazione GenAI, sia RAG nel loop interno sia tuning e pre-training nel loop esterno.
Risorse
Corsi
- Segui il tutorial self-paced Get Started With Generative AI e ottieni un certificato Databricks
- Generative AI Fundamentals (Databricks Academy)
- Generative AI Engineering with Databricks (Formazione con istruttore e Databricks Academy)
- Consulta Databricks Training e Databricks Academy per nuovi corsi
Letture
- The Big Book of Generative AI per una raccolta di post di blog che approfondiscono diversi aspetti dello sviluppo di modelli e sistemi di intelligenza artificiale generativa
- A Compact Guide to Retrieval Augmented Generation (RAG) per un approfondimento sulla creazione di applicazioni di intelligenza artificiale generativa utilizzando LLM che sono stati aumentati con dati aziendali
- Post del blog Mosaic Research
- The Big Book of MLOps: Second Edition per un approfondimento su MLOps con Databricks, incluso LLMOps
- Pagina Databricks per una panoramica del prodotto, dettagli sulle funzionalità e collegamenti a molte risorse
- Documentazione Databricks per GenAI per AWS, Azure e GCP
Talk del Data + AI Summit 2024
- Personalizzare i tuoi modelli: RAG, Fine-Tuning e Pre-training
- In the Trenches with DBRX: Building a State-of-the-Art Open-Source Model
Informazioni su Databricks
Databricks è l'azienda di dati e intelligenza artificiale. Più di 10.000 organizzazioni in tutto il mondo — tra cui Block, Comcast, Condé Nast, Rivian, Shell e il 70% delle aziende Fortune 500 — si affidano alla Piattaforma di Intelligenza dei Dati Databricks per prendere il controllo dei propri dati e utilizzarli con l'IA. Databricks ha sede a San Francisco, con uffici in tutto il mondo, ed è stata fondata dai creatori originali di Lakehouse, Apache SparkTM, Delta Lake e MLflow. Per saperne di più, segui Databricks su LinkedIn, X e Facebook.
Contattaci per una demo personalizzata:
databricks.com/contact
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.