

生成 AI ソリューションの構築を開始する
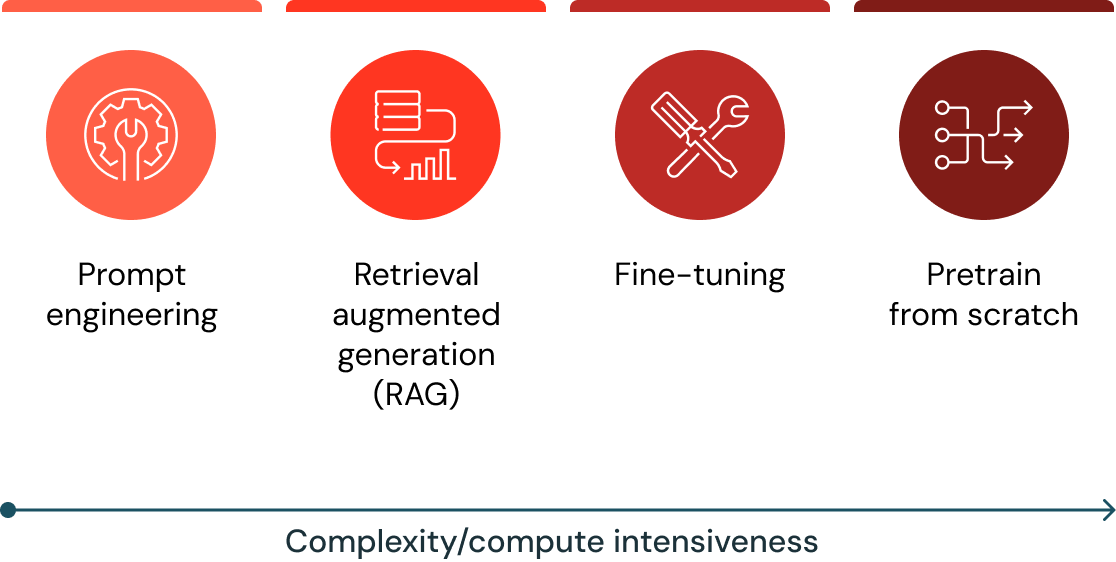
大規模言語モデル(LLM)ソリューションを構築する際に考慮すべきアーキテクチャパターンは、4 つあります。
Databricks は、4 つの生成 AI のアーキテクチャパターンの全てにおいて、高品質なソリューションを低コストで構築できる唯一のプロバイダです。
プロンプトエンジニアリング
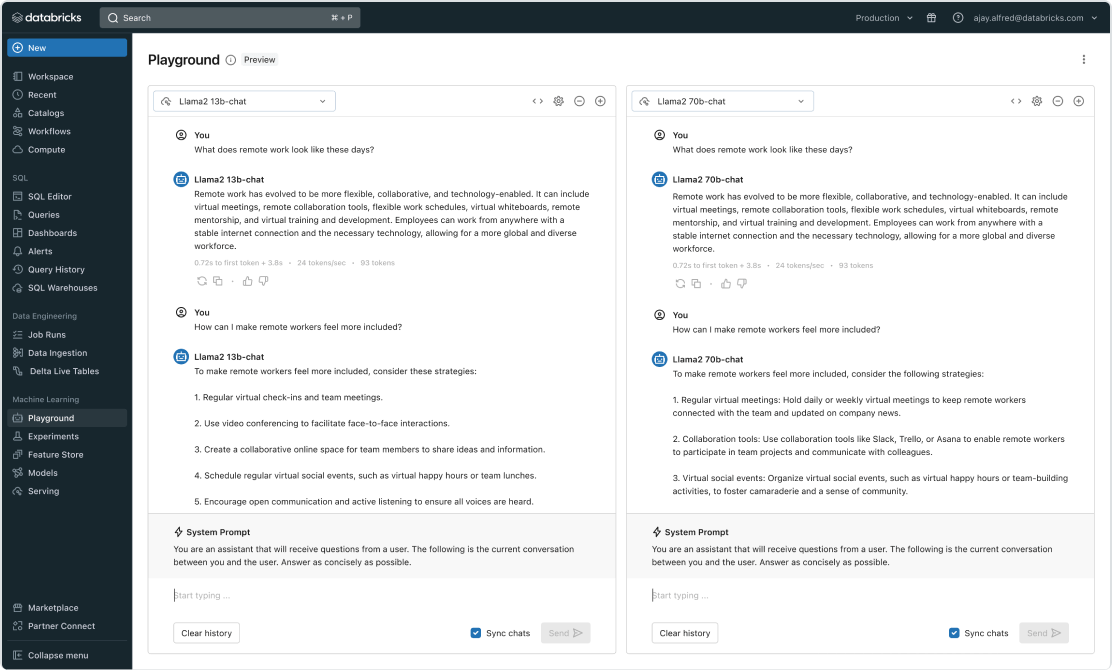
プロンプトエンジニアリングとは、基本的なモデルを変更することなく、よりよい回答を引き出すためにプロンプトをカスタマイズすることです。Databricks Marketplace で利用可能なモデル (Llama 2 や MPT などの一般的なオープンソースモデルを含む) を検索し、モデルサービングのエンドポイントでモデルを提供し、Playground や MLflow を使用した使いやすい UI でプロンプトを評価することで、プロンプトエンジニアリングを簡単に行うことができます。
検索拡張生成(RAG)
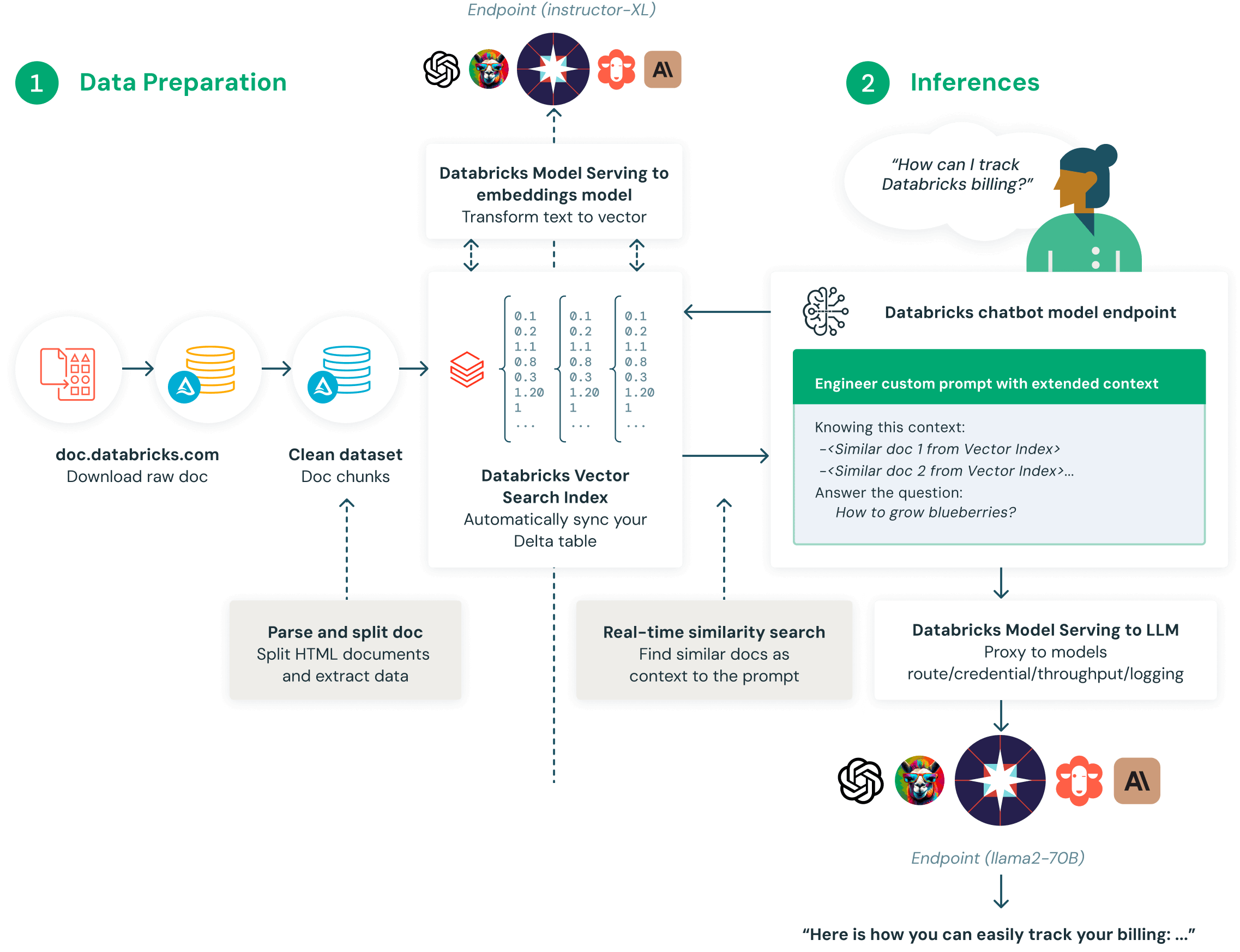
RAG は、質問またはタスクに関連するデータや文書を見つけ、LLM がより適切な回答をするためのコンテキストとして提供します。
Databricks には、データの準備、検索モデル、言語モデル(SaaS またはオープンソース)、ランキングおよび後処理パイプライン、プロンプトエンジニアリング、カスタムエンタープライズデータでのモデルのトレーニングなど、RAG プロセスのあらゆる側面を組み合わせて最適化するのに役立つ RAG ツールスイートがあります。
ファインチューニング
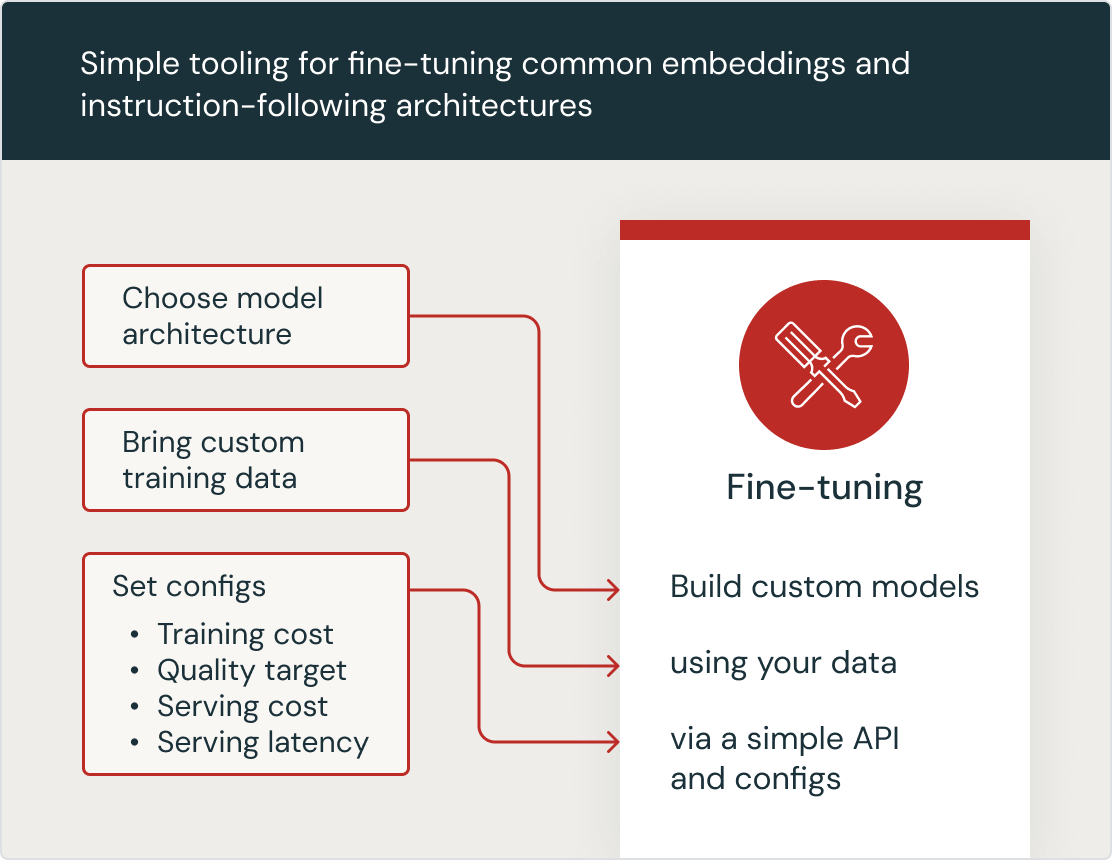
ファインチューニングは、既存の汎用 LLM モデルをお客さまの組織の IP とデータを使用し、追加トレーニングを行うことで適応させます。Databricks のファインチューニングは、MPT-30B、Llama 2、BGE などの Databricks がキュレートしたモデルを含むご希望の LLM モデルでスタートし、新しいデータセットでさらにトレーニングを行うことができるため、簡単に実施可能です。
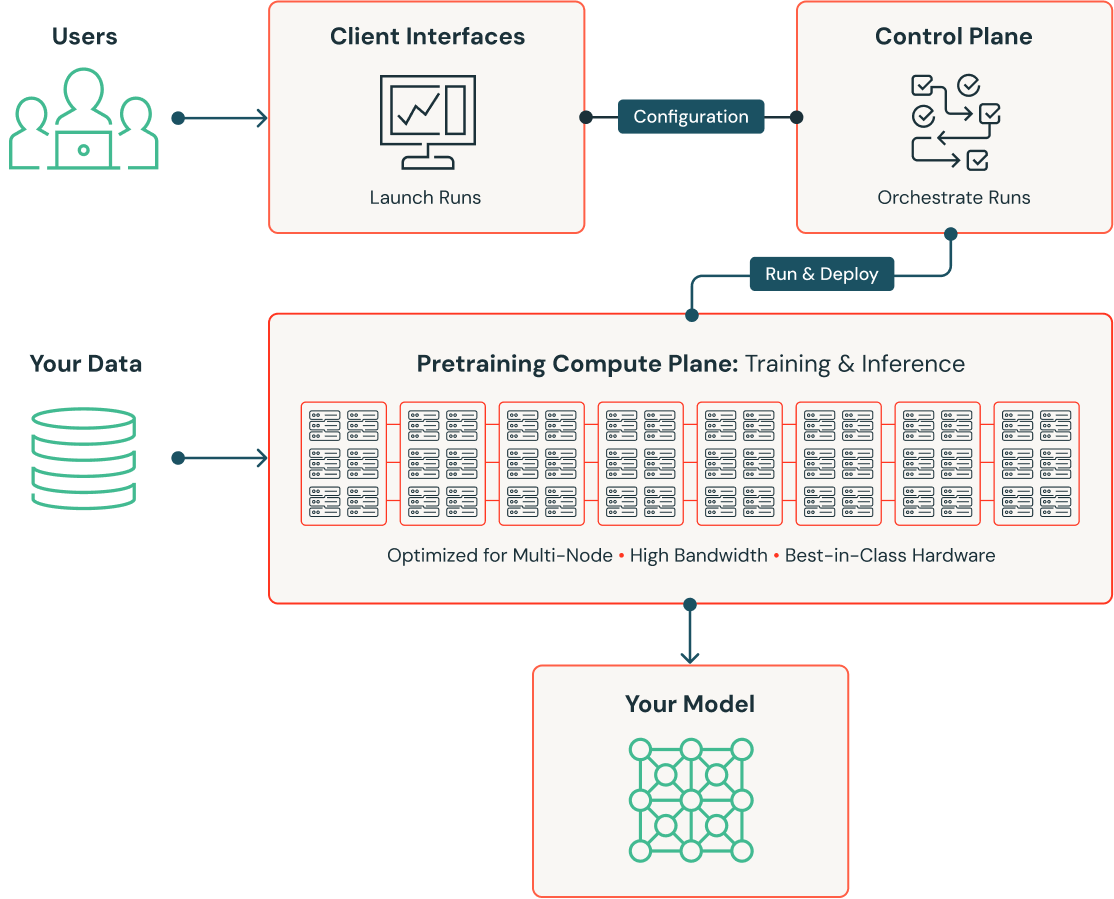
事前トレーニング
事前トレーニングとは、新しい LLM モデルをゼロから構築することで、モデルの基礎知識が特定のドメインにあわせて調整されていることを確認します。組織の IP をお客さまのデータでトレーニングすることで、独自に差別化されたカスタマイズモデルを作成します。Databricks の事前トレーニングは、数十億パラメータの LLM を数日で構築し、トレーニングコストを最大 10 倍削減できる最適化されたトレーニングソリューションです。
最適なパターンの選択
これらのアーキテクチャパターンは、相互に排他的なものではありません。むしろ、さまざまな生成 AI のデプロイメントにおいてそれぞれの長所を活かすために組み合わせることが可能であり、そうすべきです。Databricks は、4 つの生成 AI のアーキテクチャパターンの全てに対応する唯一のプロバイダです。最も多くの選択肢を提供し、ビジネス要件の要求に応じて進化させることが可能です。