Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave (Part 1)
by Daya Khudia and Vitaliy Chiley
Benchmarking Large Language Models on NVIDIA H100 GPUs with CoreWeave
The research and engineering teams here at MosaicML collaborated with CoreWeave, one of the leading cloud providers for NVIDIA GPU-accelerated server platforms, to provide a preview of the performance that can be achieved when training large language models (LLMs) with NVIDIA H100 GPUs on the MosaicML platform.
The NVIDIA H100 Tensor Core GPU, with its built-in Transformer Engine, is optimized for developing, training and deploying generative AI and LLMs.
The results are encouraging:
- Integrating NVIDIA’s Transformer Engine library with Composer, our PyTorch training framework, was straightforward.
- Right out of the box, training a 7B GPT model with NVIDIA H100 using FP8 precision was 3x faster than the current standard of NVIDIA A100 using BF16 precision. Further optimizations can boost this even more.
- With FP8, model convergence of a 1.3B parameter GPT model required no changes to hyperparameters.
The results show that NVIDIA H100 GPUs are more cost-efficient right out of the box -- with Coreweave’s public pricing, about 30% cheaper throughput per dollar -- than the NVIDIA A100 while still being 3x faster.
Contact us now to use the MosaicML platform to easily train and deploy large generative AI models on CoreWeave’s NVIDIA H100 instances.
CoreWeave + NVIDIA H100
For this sneak peek at the H100, the CoreWeave team gave us access to one of their NVIDIA HGX H100 cloud instances, on which we deployed the MosaicML compute plane. (See this blog post for a primer on our architecture and how we’ve made this easy to do.)
NVIDIA H100 Tensor Core GPU
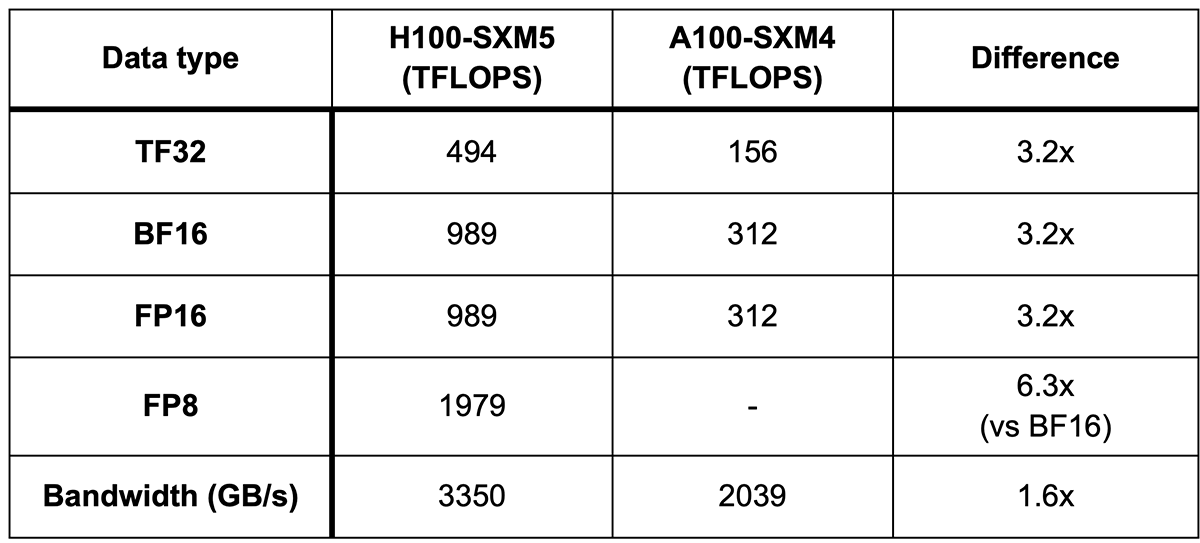
The latest-generation H100 GPU has two major improvements related to LLM training: 3.2x more FLOPS for bfloat16 (~1000 TFLOPS), and the new FP8 datatype which totals in at ~2000 TFLOPS (Table 1).
Research at NVIDIA has shown that FP8 precision can be used to accelerate specific operations (matrix multiplication and convolutions), without adversely affecting model quality. Not coincidentally, the transformer architecture – the core of LLMs and other generative AI models – uses matrix multiplication (matmul) operations extensively.
NVIDIA H100 specifications (vs. NVIDIA A100)
CoreWeave Cloud instances
CoreWeave is a specialized cloud provider for GPU-accelerated workloads at enterprise scale. It is among the first cloud service providers (CSPs) offering NVIDIA H100 clusters optimized for HPC and the largest ML use cases. Each node in those clusters is built with:
- 8x NVIDIA HGX H100 80GB SXM5
- 2x Intel 4th Gen Xeon Scalable 8462Y+ CPUs (128 vCPU)
- 1 TB DDR5 System RAM
- 3200 Gbps of GPUDirect InfiniBand Networking (8x 400 Gbps InfiniBand NDR Adapters)
- 100 Gbps Ethernet Networking
NVIDIA Transformer Engine Integration
Introducing Transformer Engine
To use the eye-watering FP8 TFLOPS, NVIDIA created an open-source library called the Transformer Engine (TE), which primarily does two things:
- Provides highly optimized framework-agnostic C++ APIs for Transformer-based models that take advantage of the H100 GPU’s FP8 hardware capabilities, along with PyTorch, JAX and TensorFlow wrappers for those APIs.
- Offers a mixed-precision context for FP8 to transparently apply FP8 in a way that preserves accuracy.
We easily added support for FP8 via Transformer Engine in the Composer 0.13.1 release.
Implementing the model with TE layers for FP8
We updated our open-source MosaicGPT model to use TE layers. Because the new layers have compatible APIs with the native PyTorch layers, integration required just changing a few lines of code (see code snippet below; for more details see the pull request here).
Enabling FP8 Automatic Mixed Precision
In the simplest case, once the model has TE layers, to enable FP8 training, simply the change the precision from amp_bf16 to amp_fp8:
Note that the `te.fp8_autocast` is not sufficient itself because many operations not compatible with FP8 would still be computed in FP32, and therefore slower. Therefore, we applied nested casting as shown below, i.e., standard torch.autocast() into bfloat16 with te.fp8_autocast(), to get the best performance.
There were a few hiccups working with the Transformer Engine that are actively being closed with the fantastic NVIDIA team:
- TE layers do not currently support the `device` argument, so we cannot initialize models with the `meta` device. Using `device = ‘meta’` shortens initialization time by materializing the tensors directly on the device instead of the CPU first.
- Transformer Engine currently does not support PyTorch's FSDP. However, we found that TE is compatible with DDP.
Our first tests focused on single-node models, given the above, which can have a measurable effect at scale. We will cover multi-node training for larger models in Part 2 of our NVIDIA H100 evaluation – coming soon!
GEMM Benchmarks
Matrix multiplication
We first compared performance on varying dimensions of matrix multiplication, the workhorse of deep learning models. The following graph shows the relative performance of NVIDIA H100 using FP8 precision vs. NVIDIA A100 80GB using BF16 precision when multiplying a matrix of size B x K with K x K (Figure N). This uses the Transformer Engine’s linear layer implementation.
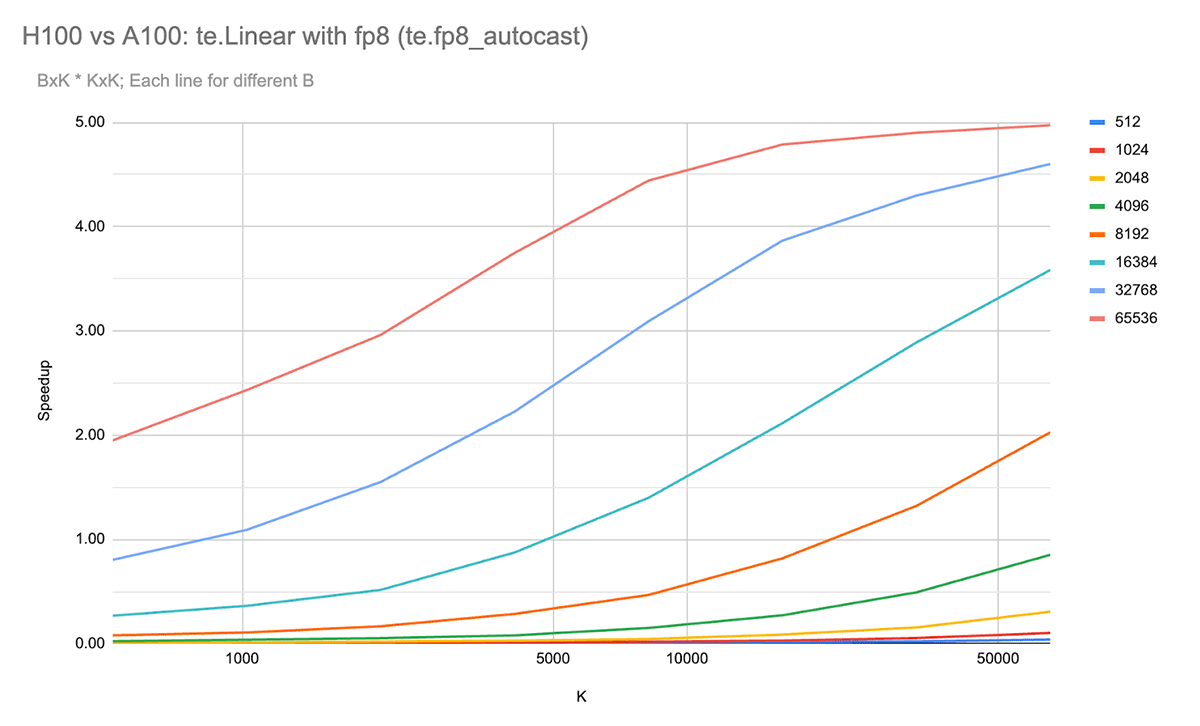
For large matrix multiply sizes (e.g. large K and B), the speedup of ~5x approaches the theoretical maximum of 6.3x based on the available TFLOPS.
Of course, these are just for matrix-matrix multiplications. For LLMs, other operations such as LayerNorm, softmax, and element-wise operations are often more dependent on memory bandwidth, and thus we expect at most 1.6x increase (the H100 memory bandwidth advantage over A100).
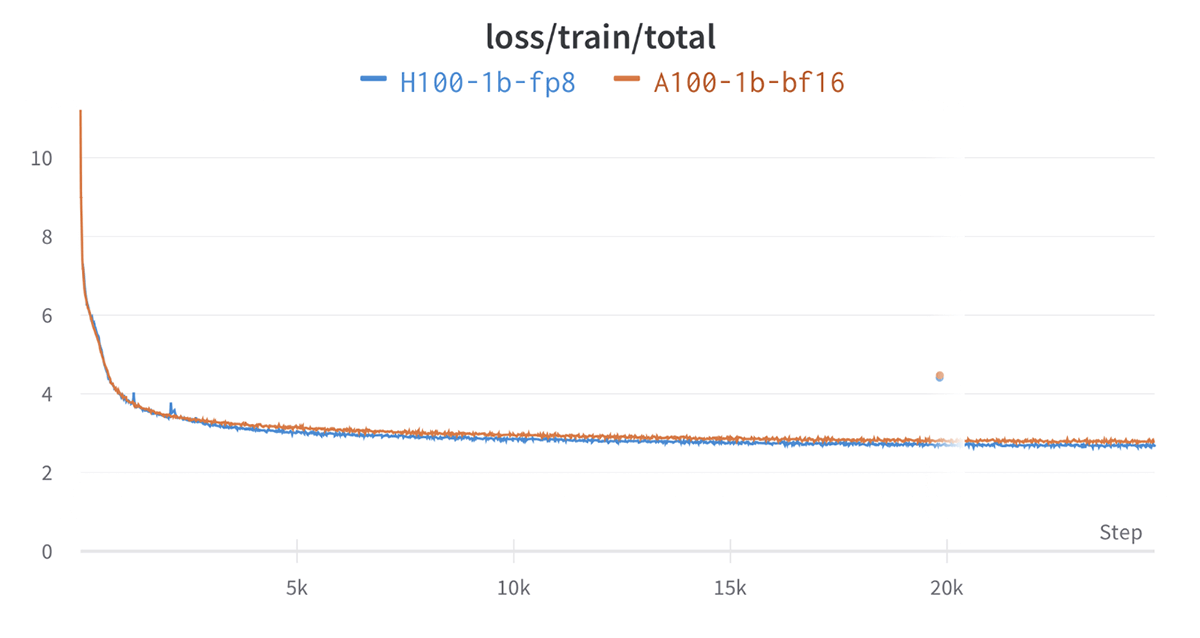
Convergence with FP8
So how well do the models converge when trained using FP8? We trained a 1.3B parameter model using FP8 up to the Chinchilla optimal point (for a 1.3B parameter model, ~26 billion tokens). As the figure below shows, the loss curve for H100 FP8 is very similar to the A100 on BF16 using the same model architecture and learning hyperparameters. We also observed similar scores on downstream metrics such as 0-shot accuracy on HellaSwag dataset, PIQA dataset and others.
GPT training performance
We compared the training speeds of H100 GPUs with A100 80GB GPUs on GPT models of various sizes (Table 2). All models used Flash Attention and used our LLM training library with the Transformer Engine integration. We maximized the settings (per-device microbatch size, different combinations of te.layers types) for throughput. Note that this performance was obtained right out of the box -- future optimizations will surely boost these numbers over time.
Because the 30B model does not fit in memory, we benchmarked the layer widths but with fewer blocks (depth=4) to fit into memory.
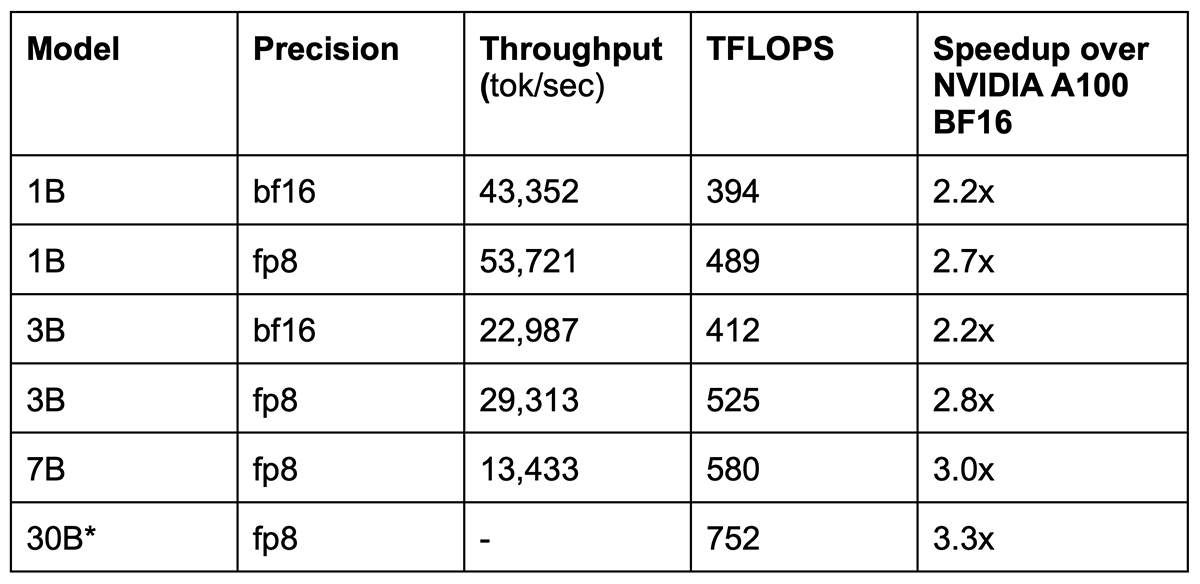
A few key observations:
- Benchmarking just in BF16 (no Transformer Engine) already yields 2.2x speedup over A100 GPUs
- With FP8, we achieve up to 3.3x speedup out of the box
- The benefit of FP8 increases for larger models, which makes sense as larger models have larger matrix multiply sizes.
We are actively optimizing the speed of FP8 training over the next few months and releasing optimizations into our LLM training library. However, the initial results are encouraging, and yield significant time and cost benefits out of the box.
Cost savings
How do these performance gains with NVIDIA H100 impact the total costs to train these LLMs? CoreWeave’s public pricing has the H100 SXM GPU pricing ($4.76/hr/GPU) about 2.2x more than the A100 80GB GPU pricing ($2.21/hr/GPU). Recall that just training with BF16 was about 2.2x faster, which means that the H100 is always the better choice compared to the A100.
We estimated the training time and cost for a 7B MosaicGPT model to the compute-optimal point (Table 3) and found the NVIDIA H100 to be 30% more cost-effective and 3x faster than the NVIDIA A100.

Get Started with MosaicML Platform and CoreWeave
Contact us now to reserve CoreWeave’s NVIDIA H100 instances and take advantage of faster, cost-efficient training for your workloads with the MosaicML platform.
Our platform provides an optimized LLM stack that “just works” on CoreWeave and other cloud providers. We take care of the infrastructure, FP8 code optimizations, and LLM configurations so you can focus on the data and the modeling. Our platform is packed with features, including seamless scaling of model sizes, automatic fault detection and recovery, optimized data streaming, and integration with your favorite MLOps tools.
Looking ahead
Our next benchmarking effort will involve workloads that span multiple NVIDIA H100 nodes. We will share our performance numbers, tips and tricks in Part 2 of our blog, coming soon. If you have questions, join the conversation in our community Slack. For updates on all the new features we’re adding, follow us on Twitter!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.