Ingesting the Milky Way: Petabyte-Scale with Zerobus Ingest
A deep dive behind the architecture enabling 12 GB/s per table—and limitless possibilities
by Aleksandar Tomić, Victoria Bukta, Nikola Obradović, Danilo Najkov, Branko Grbić and Milos Milovanovic
- Databricks Zerobus Ingest is a serverless streaming API that enables teams to instantly deploy petabyte-scale data pipelines without manual infrastructure management.
- Zerobus’ architecture relies on dynamic partitioning to automatically scale compute resources, efficiently handling unpredictable data volumes without complex tuning.
- This zero-setup framework easily processes massive workloads, demonstrating the ability to sustain over 12 GB/s throughput to a single table during 24-hour benchmarks.
Telemetry data is everywhere. IoT sensors on factory floors. Satellite arrays scanning the atmosphere. Autonomous vehicles are logging thousands of events per second. Every one of these systems has the same underlying problem: a continuous, high-volume stream of time-series observations that needs to land somewhere queryable. It needs to be fast, reliable, and without an engineering team spending weeks tuning and maintaining infrastructure that is typical of Kafka based workloads.
That's the problem Zerobus Ingest is built to solve. Zerobus is Databricks' fully managed, serverless streaming ingest service. It's a push-based API that accepts data from any producer and writes it directly into Delta tables, governed by Unity Catalog.
- No infrastructure to provision.
- No connector pipeline to maintain.
- No partitions or broker decision-making.
Instead, you create a table and push data. It lands in your lakehouse, ready to query in seconds. You no longer need to run Kafka as a pipe when your destination is the lakehouse.
We used NASA’s NEOWISE dataset, representing 200 billion data points over 11 years, to benchmark Zerobus Ingest, ingesting 1 petabyte in under 24 hours, with zero pre-configuration and stable latency.
By ingesting 1PB within 24 hours, we demonstrate Zerobus’s ability to maintain continuous throughput of 12 GB/s to a single table! 🚀
Now Delivering Petabyte scale: Streaming the Milky Way (12GB/sec/table)
For more on how to run the benchmark yourself, read this companion blog on Databricks Community.
This post walks through three of our design decisions that made this possible.
- Designing a system that autoscales via dynamic partitioning.
- Building our own zero-copy protobuf decoder.
- Implementing a latency-optimized write-ahead log before data is published to the lakehouse.
Our key design decisions
Our aspiration was to build a streaming system that could support petabyte-scale and auto-scale to handle fluctuating ingestion patterns.
Traditional streaming architectures require you to decide how many brokers and partitions a given workload needs. This requires knowledge of peak load and consumer ingestion constraints, as well as forecasting and an understanding of the end-to-end pipeline.
By going back to first principles, we designed and built a system that scales to handle petabyte-sized workloads for data producers “magically.”
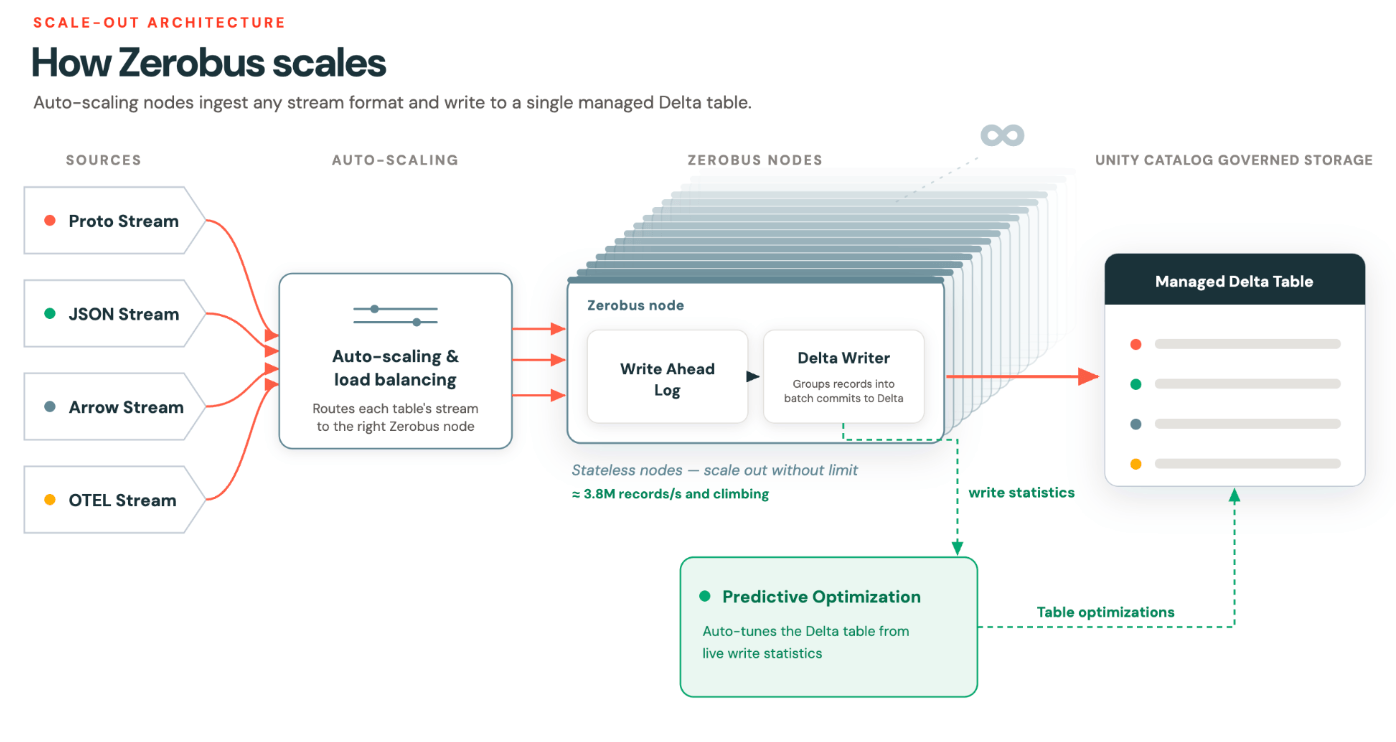
Autoscaling achieved through dynamic partitioning
The problem we were trying to solve was how to have efficient autoscaling to achieve elastic “limitness” scaling.
Our thesis was that by moving away from static partitioning and toward the logical unit of a stream/connection, we could unlock true autoscaling and rebalancing while maintaining ordering guarantees, which are important for consumption workloads.
The static partition problem
In message bus architectures, partitions are the unit of both parallelism and ordering. This coupling creates a constraint that can be painful once you have consumers who depend on it.
Ordering is typically a per-partition guarantee, not per-producer. The number of partitions and the distribution of data across them affect a consumer's ability to keep up with ingestion. This means:
- If your partition count changes, the routing function that maps a producer's messages to a partition may now send them to a different partition. The consumer now has to reconcile this.
- In practice, most teams treat partition topology as immutable. You provision for peak load and carry that infrastructure forever. You can add partitions but you typically cannot safely decrease them.
- The standard workaround is a partition routing key derived from a field in the message. This helps with ordering consistency but still doesn't solve the scale-down problem.
We moved the ordering guarantee to the stream connection
In traditional systems, ordering is a partition-level guarantee. In Zerobus Ingest, ordering is a stream connection-level guarantee.
When a producer opens a stream with Zerobus (a connection to our server), they're registering a logical identity with the service. For the lifetime of that connection, their data arrives in order, regardless of which “partition” pod processes it.
"Your stream is ordered", not "your partition is ordered." That's the contract.
Hot routing and true autoscaling
Internally, Zerobus Ingest distributes streams across a pool of pods. Routing is heuristic-based: if a pod is running hot, new incoming streams are routed to a different pod. The producer is unaware. Their ordering guarantee is unaffected.
Ordering lives at the stream level, which means pods can be added when demand spikes and removed when demand drops. Existing streams then drain gracefully, and new streams stop routing there. The pool then shrinks, keeping compute utilization efficient.
This is true autoscaling. The unit of granularity is the stream connection, not the partition assignment.
Our dynamic partitioning design enables Zerobus to autoscale to over 12GB per second throughput for a table while remaining cost-efficient.
Zero-copy high-performance data handling
Zerobus's main goal is to allow an efficient, row-by-row transfer of data streams of any volume. To achieve this, we needed to completely avoid any needless copying and memory allocations - from the input formats that clients send to Zerobus, to the internal formats that guarantee durability and open Delta formats.
Zerobus currently supports the following message formats.
Among the many optimizations we made, we will illustrate the zero-copy approach through ZeroParser - our custom protobuf decoder.
Standard protobuf decoders force you to choose between speed and flexibility. Protobuf decoders typically rely on either build-time code generation (codegen) or runtime reflection.
- Code generation is fast, but it requires descriptors at compile time. Zerobus receives descriptors dynamically at runtime, from arbitrary user schemas. Codegen isn't an option.
- Runtime reflection solves the flexibility problem, but creates a performance one. Dynamic protobuf decoders are slow and require building an object graph in memory at runtime, leading to many small memory allocations.
Neither approach was acceptable. We needed dynamic descriptor support with the performance profile of codegen.
The result was that we built zeroparser: Bridging this gap by using single-pass parsing with zero memory allocations, enabling it to sustain throughputs of ~1 GB/s protobuf parsing per CPU core even with dynamic descriptors and complex schemas.
Zeroparser allows direct wire format parsing without deconstruction of incoming objects, which leads to memory copying and allocations. With this approach, Zerobus can achieve better performance than existing code-generated protobuf parsing solutions while still maintaining the full flexibility of dynamically providing protobuf descriptors.
Rust's lifetime system was central to Zeroparser’s design: it guarantees compile-time safety during protocol parsing while keeping raw wire bytes under exclusive network ownership, eliminating unnecessary data copies.
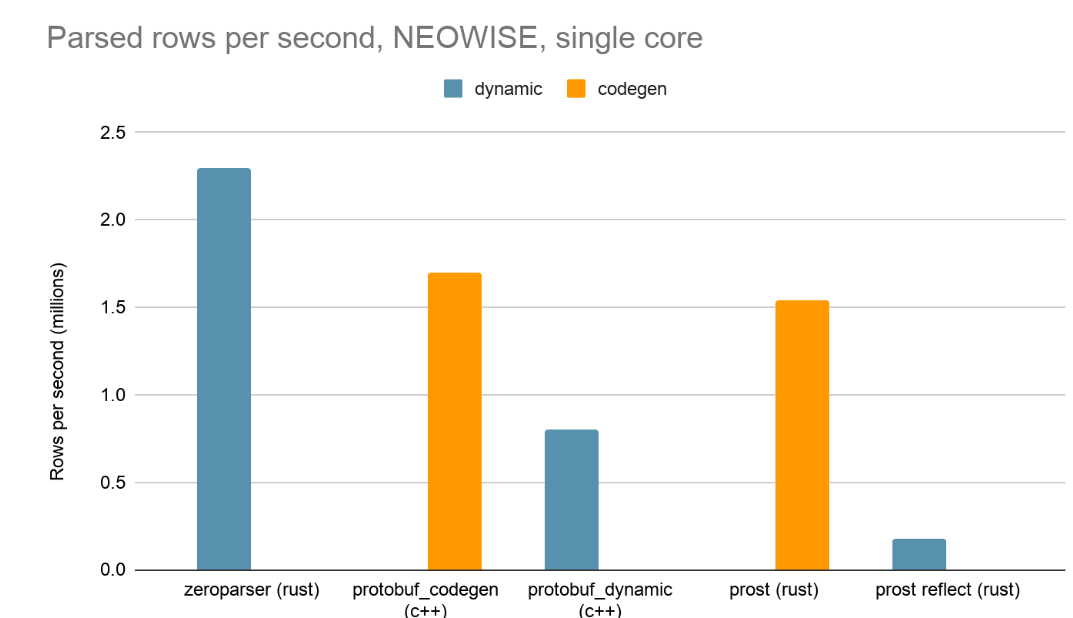
Results show that Zeroparser, although being in the dynamic group, outperformed two industry standard codegen based implementations.
Zeroparser is open-sourced as part of the Zerobus SDK available here.
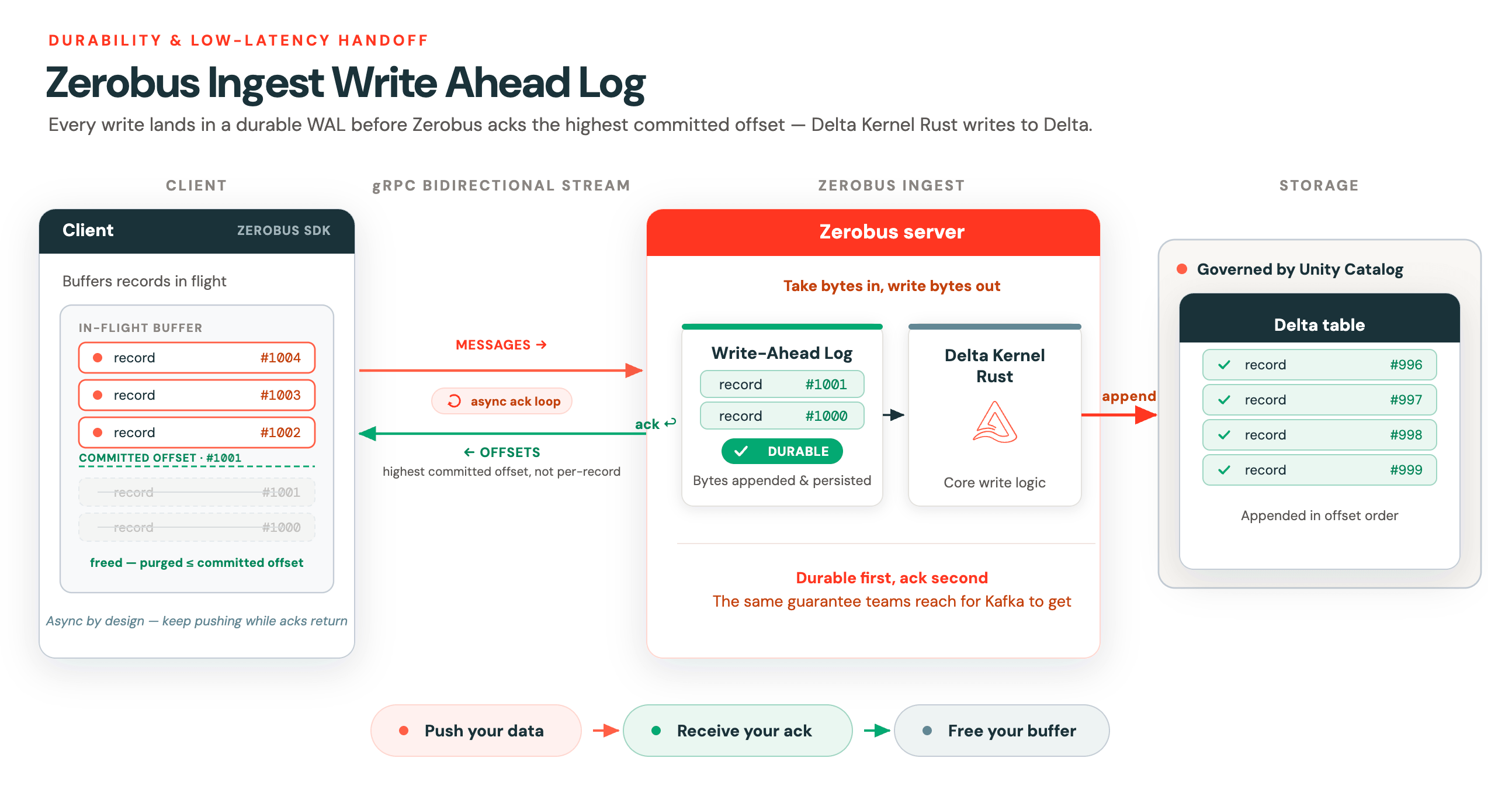
Write Ahead Log
Streaming is not just about being able to handle high-throughput workloads. To be a true streaming service, you also need to support message handoff as quickly as possible. This low latency of handing off data is what truly distinguishes streaming workloads from batch.
To support this low-latency handoff with a durability guarantee, Zerobus implements a latency-optimized write-ahead log (WAL). Once messages are durable, Zerobus sends an acknowledgement back to the client. Rather than acknowledging every record individually, the server returns the highest committed offset on the stream. The result is this async ack loop. Delta Kernel Rust is then used for the core logic for writing to Delta.
This async design is key for clients that buffer data in flight. Zerobus uses gRPC bidirectional streaming, where each Zerobus stream has two lines of communication:
- One for sending messages
- The other for receiving offsets acknowledgements.
Once the client receives that offset, it can safely purge everything up to that point from its local in-flight buffer. This is all handled for you by the Zerobus SDKs.
The WAL is what keeps clients lean. Push your data, receive your ack, free your buffer. That low-latency, high-durability handoff has always been the reason teams reach for Kafka. Zerobus gives you the same guarantee.
Proof: Ingesting the Milky Way
The key to benchmarking a system comes with the understanding of how it would be used in a production setting, and then emulating that behavior and usage. That’s why to stress Zerobus Ingest we decided to choose NASA’s NEOWISE dataset and we used Locust to emulate real-world fan-in patterns.
Why Locust? The Fan-In Problem
Zerobus Ingest is built to aggregate streams from many independent producers into a single destination table. Its throughput scales with the number of concurrent open streams. This means you cannot stress it fairly from a single machine or a small cluster. A single powerful host would saturate its own bandwidth or CPU before it placed meaningful pressure on our service, therefore benchmarking the producer, not Zerobus.
To simulate a real-world fan-in pattern, we use Locust to coordinate opening separate streams by pods to pressure-test ingestion at scale.
Zerobus's autoscaling then responds to stream count and throughput to handle the rate of ingestion.
Test Configuration
Our benchmark was deployed on Kubernetes with one Locust master and a fleet of Locust workers, each running as a separate pod. Key parameters:
Each worker gets a unique list of parquet files to ingest. A worker streams its slice and does not repeat rows.
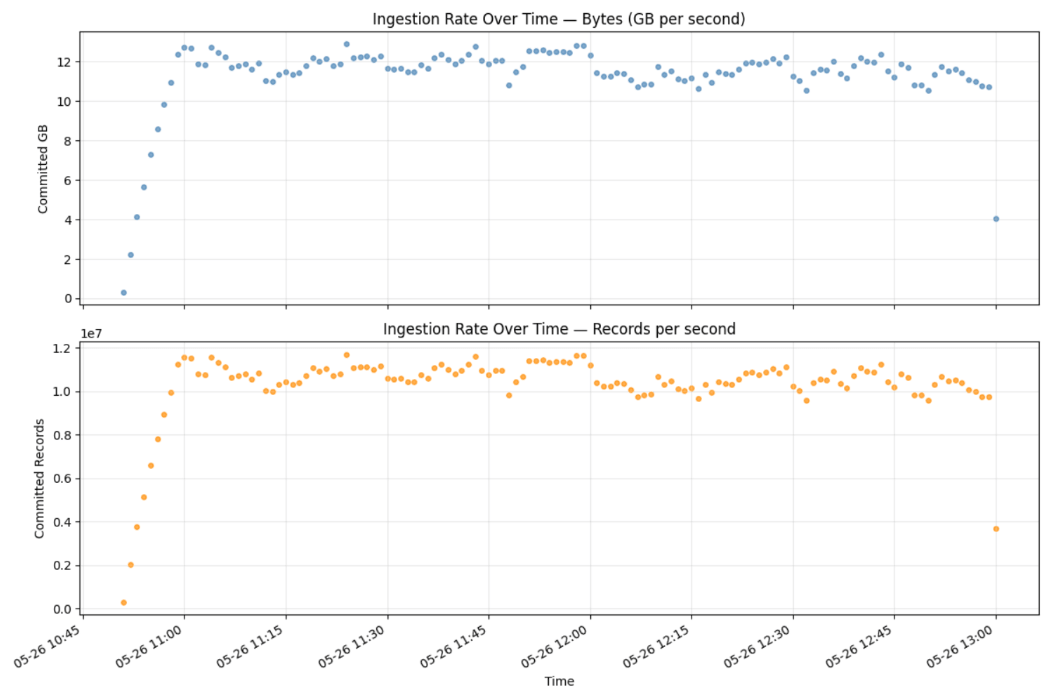
The results
Our test results showed Zerobus Ingest’s ability to sustain 12 GB/s to a single table over a 24-hour period from 2,048 concurrent workers to a single table. Over this period, Zerobus ingested over a trillion records.
Aggregating over 5-second buckets over the client_ts_ms column gives a precise, server-confirmed view of rows committed and bytes received:
This query runs against the live Unity Catalog table. The numbers reflect rows that were fully committed to Delta storage.
Want to run it yourself?
The full benchmark harness with dataset preparation, producer code, and instructions for running against your own Zerobus endpoint. Check it out here.
What's next
Zerobus Ingest is now Generally Available on Databricks and ready for all your production workloads.
Our performance metrics of 12gb/s to a table are what you get out of the box with Zerobus Ingest. Quotas can be increased by reaching out to your account team.
On the roadmap:
- Kafka Producer API support
- MQTT API support
- Rescue column
- System metadata column
- Avro support
Let us know where you want us to take Zerobus next! What do you think the next frontier of streaming is? Send us your comments on our companion Databricks Community blog.
If you are ready to get started with Zerobus Ingest, refer to our technical documentation, the Zerobus Ingest SDK, or check out the GitHub repo with the Neowise benchmark.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.