Latency goes subsecond in Apache Spark Structured Streaming
Improving Offset Management in Project Lightspeed
by Jerry Peng, Pranav Anand, Sourav Gulati, Karthik Ramasamy, Michael Armbrust and Matei Zaharia
Apache Spark Structured Streaming is the leading open source stream processing platform. It is also the core technology that powers streaming on the Databricks Lakehouse Platform and provides a unified API for batch and stream processing. As the adoption of streaming is growing rapidly, diverse applications want to take advantage of it for real time decision making. Some of these applications, especially those operational in nature, demand lower latency. While Spark's design enables high throughput and ease-of-use at a lower cost, it has not been optimized for sub-second latency.
In this blog, we will focus on the improvements we have made around offset management to lower the inherent processing latency of Structured Streaming. These improvements primarily target operational use cases such as real time monitoring and alerting that are simple and stateless.
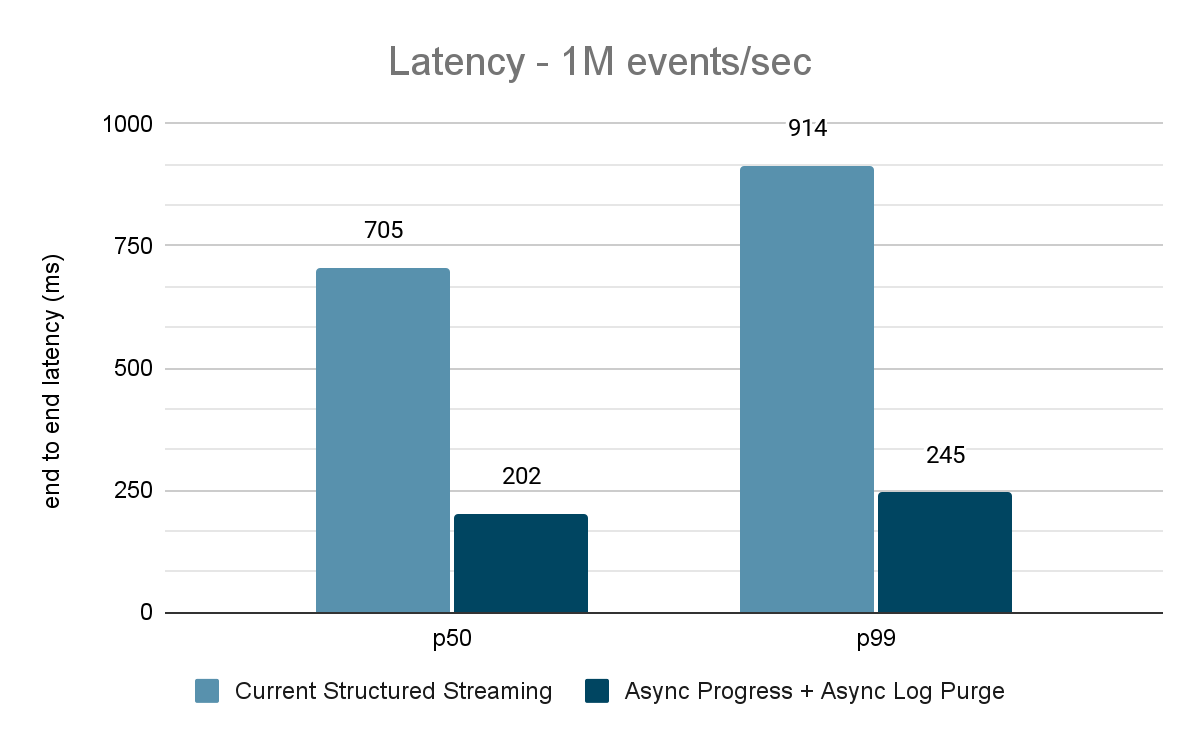
Extensive evaluation of these enhancements indicates that the latency has improved by 68-75% - or as much as 3X - from 700-900 ms to 150-250 ms for throughputs of 100K events/sec, 500K events/sec and 1M events/sec. Structured Streaming can now achieve latencies lower than 250 ms, satisfying SLA requirements for a large percentage of operational workloads.
This article assumes that the reader has a basic understanding of Spark Structured Streaming. Refer to the following documentation to learn more:
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Motivation
Apache Spark Structured Streaming is a distributed stream processing engine built on top of the Apache Spark SQL engine. It provides an API that allows developers to process data streams by writing streaming queries in the same way as batch queries, making it easier to reason about and test streaming applications. According to Maven downloads, Structured Streaming is the most widely used open source distributed streaming engine today. One of the main reasons for its popularity is performance - high throughput at a lower cost with an end-to-end latency under a few seconds. Structured Streaming gives users the flexibility to balance the tradeoff between throughput, cost and latency.
As the adoption of streaming grows rapidly in the enterprise, there is a desire to enable a diverse set of applications to use streaming data architecture. In our conversations with many customers, we have encountered use cases that require consistent sub-second latency. Such low latency use cases arise from applications like operational alerting and real time monitoring, a.k.a "operational workloads." In order to accommodate these workloads into Structured Streaming, in 2022 we launched a performance improvement initiative under Project Lightspeed. This initiative identified potential areas and techniques that can be used to improve processing latency. In this blog, we outline one such area for improvement in detail - offset management for progress tracking and how it achieves sub-second latency for operational workloads.
What are Operational Workloads?
Streaming workloads can be broadly categorized into analytical workloads and operational workloads. Figure 1 illustrates both analytical and operational workloads. Analytical workloads typically ingest, transform, process and analyze data in real time and write the results into Delta Lake backed by object storage like AWS S3, Azure Data Lake Gen2 and Google Cloud Storage. These results are consumed by downstream data warehousing engines and visualization tools.
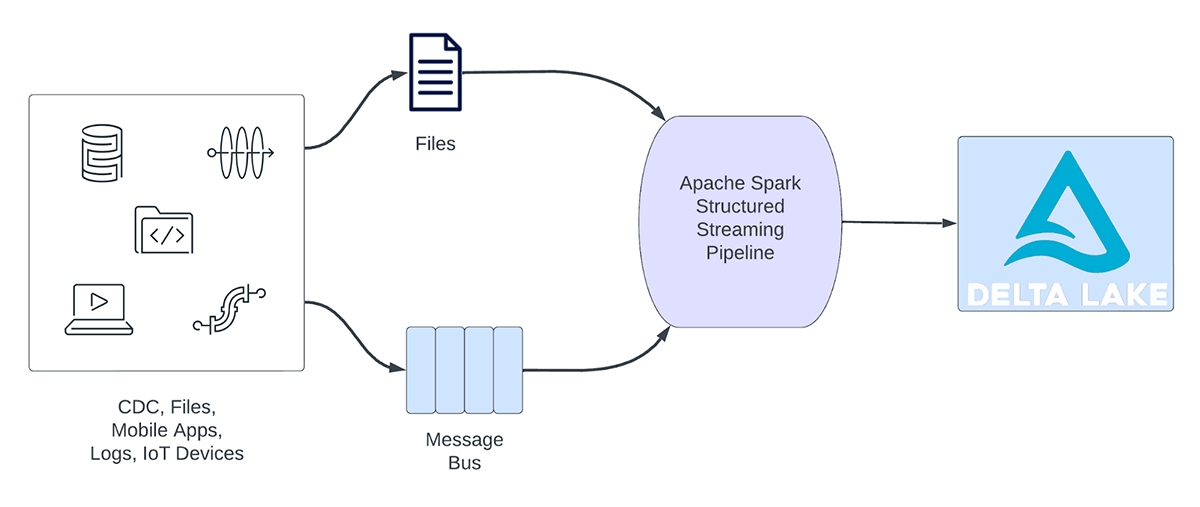
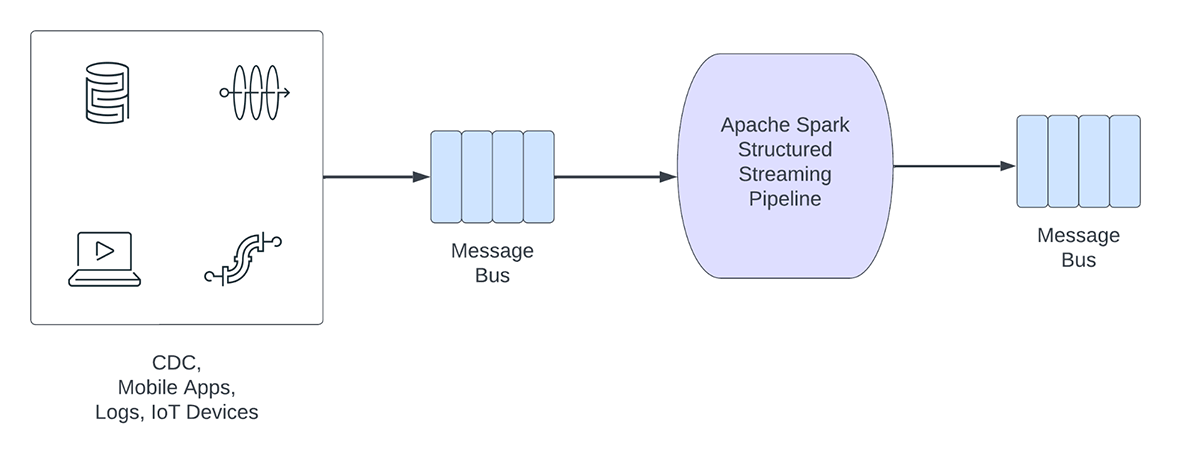
Figure 1. Analytical vs Operational Workloads
Some examples of analytical workloads include:
- Customer Behavior Analysis: A marketing firm may use streaming analytics to analyze customer behavior in real-time. By processing clickstream data, social media feeds, and other sources of information, the system can detect patterns and preferences that can be used to target customers more effectively.
- Sentiment Analysis: A company might use streaming data from its social media accounts to analyze customer sentiment in real time. For example, the company might look for customers who are expressing positive or negative sentiment about the company's products or services.
- IoT Analytics: A smart city may use streaming analytics to monitor traffic flow, air quality, and other metrics in real-time. By processing data from sensors embedded throughout the city, the system can detect trends and make decisions about traffic patterns or environmental policies.
On the other hand, operational workloads, ingest and process data in real time and automatically trigger a business process. Some examples of such workloads include:
- Cybersecurity: A company might use streaming data from its network to monitor for security or performance problems. For example, the company might look for spikes in traffic or for unauthorized access to networks and send an alert to the security department.
- Personally Identifiable Information Leaks: A company might monitor the microservice logs, parse and detect if any personally identifiable information (PII) is being leaked and if it is, inform by email the owner of the microservice.
- Elevator Dispatch: A company might use the streaming data from the elevator to detect when an elevator alarm button is activated. If activated, it might look up additional elevator information to enhance the data and send a notification to security personnel.
- Proactive Maintenance: Using the streaming data from a power generator monitor the temperature and when it exceeds a certain threshold inform the supervisor.
Operational streaming pipelines share the following characteristics:
- Latency expectations are usually sub-second
- The pipelines read from a message bus
- The pipelines usually do simple computation with either data transformation or data enrichment
- The pipelines write to a message bus like Apache Kafka or Apache Pulsar or fast key value stores like Apache Cassandra or Redis for downstream integration to business process
For these use cases, when we profiled Structured Streaming, we identified that the offset management to track the progress of micro-batches consumes substantial time. In the next section, let us review the existing offset management and outline how we improved in subsequent sections.
What is Offset Management?
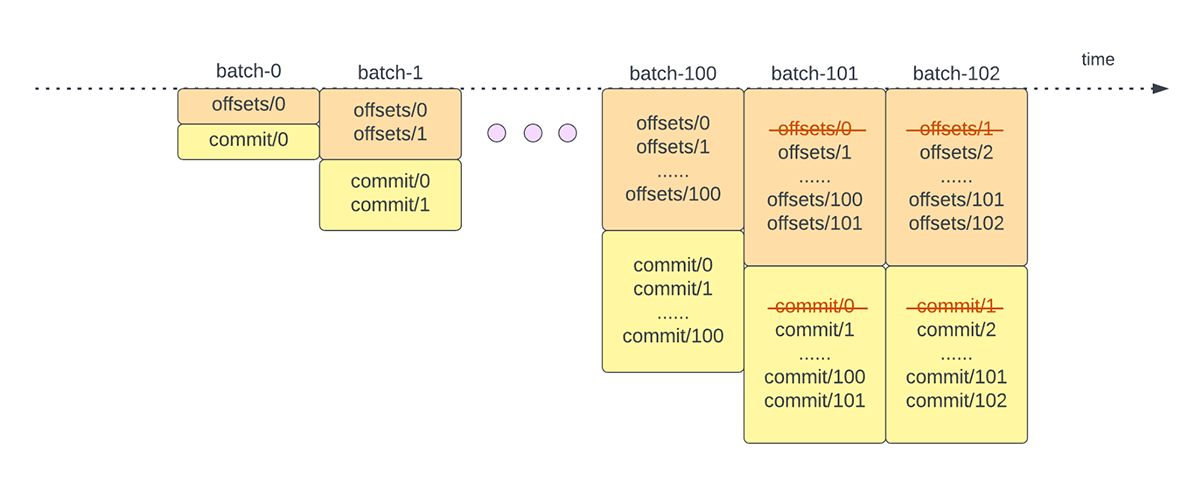
To track the progress of up to which point the data has been processed, Spark Structured Streaming relies on persisting and managing offsets which are used as progress indicators. Typically, an offset is concretely defined by the source connector as different systems have different ways to represent progress or locations in data. For example, a concrete implementation of an offset can be the line number in a file to indicate how far the data in the file has been processed. Durable logs (as depicted in Figure 2) are used to store these offset and mark completion of micro-batches.
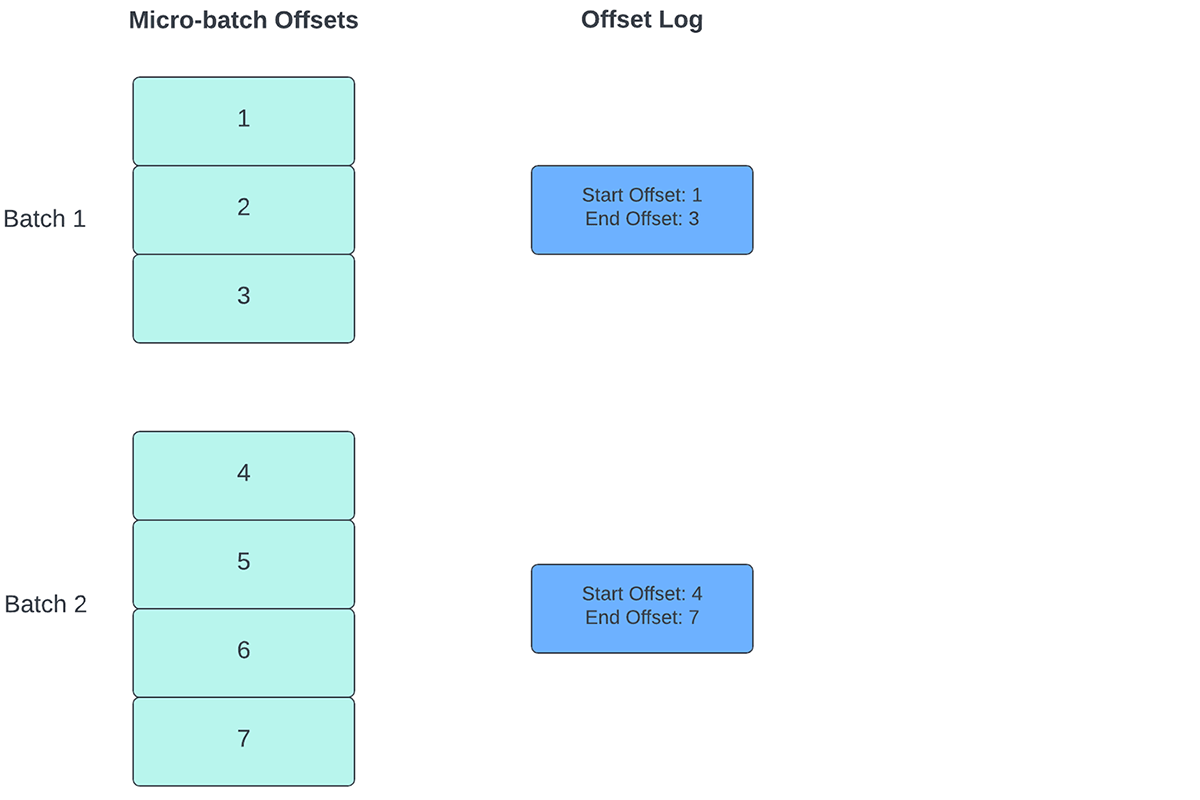
In Structured Streaming, data is processed in units of micro-batches. There are two offset management operations done for each micro-batch. One at the beginning of every micro-batch and one at the end.
- At the beginning of every micro-batch (before any data processing actually starts), an offset is calculated based on what new data can be read from the target system. This offset is persisted to a durable log called the "offsetLog" in the checkpoint directory. This offset is used to calculate the range of data that will be processed in "this" micro-batch.
- At the end of every micro-batch, an entry is persisted in the durable log called the "commitLog" to indicate that "this" micro-batch has been successfully processed.
Figure 3 below depicts the current offset management operations that occur.
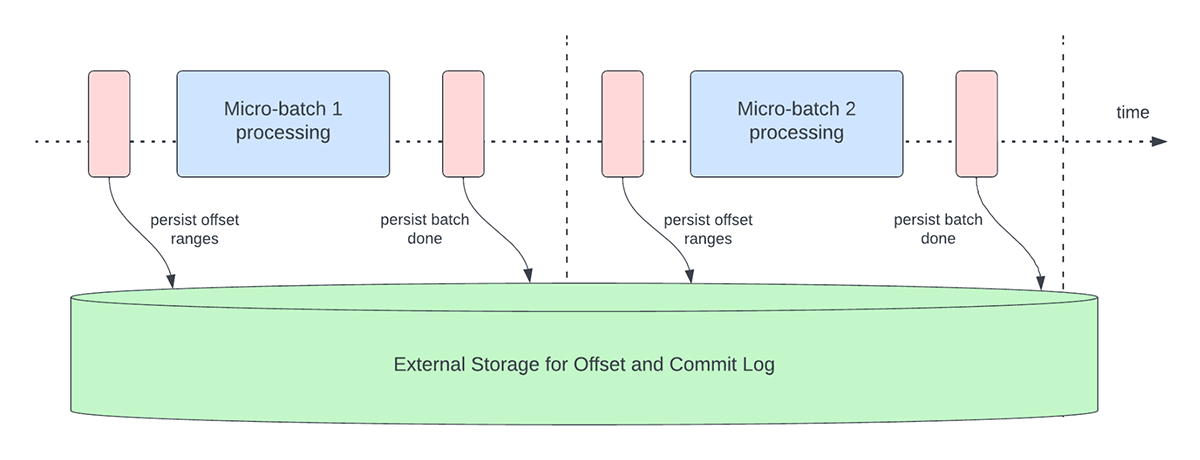
Another offset management operation is performed at the end of every micro-batch. This operation is a clean up operation to delete / truncate old and unnecessary entries from both the offsetLog and commitLog so that these logs don't grow in an unbounded fashion.
These offset management operations are performed on the critical path and inline with the actual processing of the data. This means that the duration of these operations directly impacts processing latency and no data processing can occur until these operations are complete. This directly impacts cluster utilization as well.
Through our benchmarking and performance profiling efforts, we have identified these offset management operations can take up a majority of the processing time especially for stateless single state pipelines that are often used in the operation alerting and real-time monitoring use cases.
Performance Improvements in Structured Streaming
Asynchronous Progress Tracking
This feature was created to address the latency overhead of persisting offsets for progress tracking purposes. This feature, when enabled, will allow Structured Streaming pipelines to checkpoint progress, i.e. update the offsetLog and commitLog, asynchronously and in parallel to the actual data processing within a micro-batch. In other words, the actual data processing will not be blocked by these offset management operations which will significantly improve the latency of applications. Figure 5 below depicts this new behavior for offset management.
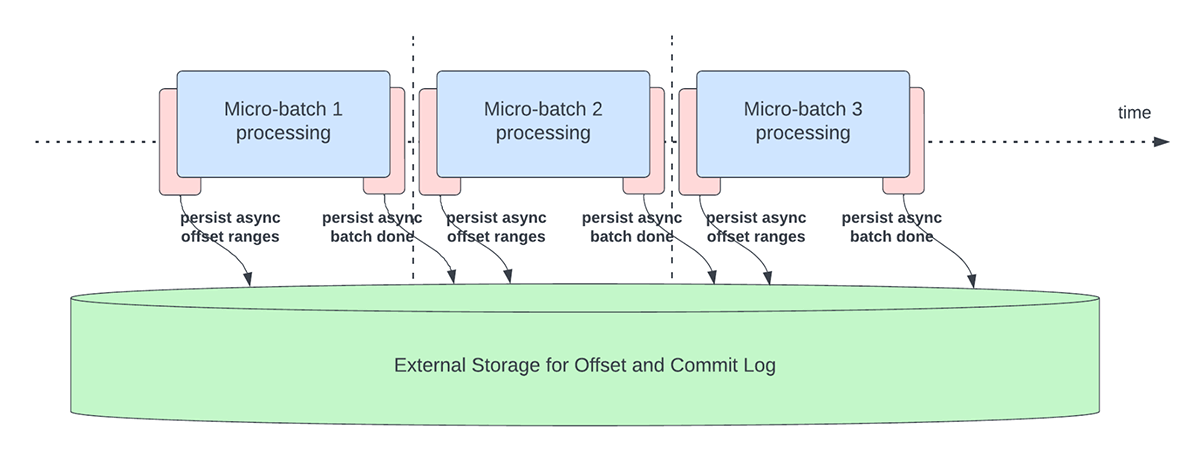
In conjunction with asynchronously performing updates, users can configure the frequency at which the progress is checkpointed. This will be helpful for scenarios in which offset management operations occur at a higher rate than they can be processed. This happens in pipelines when the time spent actually processing data is significantly less compared to these offset management operations. In such scenarios, an ever increasing backlog of offset management operations will occur. To stem this growing backlog, data processing will have to be blocked or slowed down which will essentially revert the processing behavior to being the same as if these offset management operations were executed inline with the data processing. A user will typically not need to configure or set the checkpoint frequency as an adequate default value will be set. It is important to note that failure recovery time will increase with the increase in checkpoint interval time. In case of failure, a pipeline has to reprocess all the data before the previous successful checkpoint. Users can consider this trade-off between lower latency during regular processing and recovery time in case of failure.
Following configurations are introduced to enable and configure this feature:
asyncProgressTrackingEnabled - enable or disable asynchronous progress trackingDefault: false
asyncProgressCheckpointingInterval - the interval in which we commit offsets and completion commitsDefault: 1 minute
Following code sample illustrates how to enable this feature:
Note that this feature will not work with Trigger.once or Trigger.availableNow as these triggers execute pipelines in manual/scheduled fashion. Therefore, asynchronous progress tracking will not be relevant. Query will fail if it is submitted using any of the aforementioned triggers.
Applicability and Limitations
There are a couple of limitations in the current version(s) that might change as we evolve the feature:
- Currently, asynchronous progress tracking is only supported in stateless pipelines using Kafka Sink.
- Exactly once end-to-end processing will not be supported with this asynchronous progress tracking because offset ranges for a batch can be changed in case of failure. However, many sinks, such as the Kafka sink, only support at-least once guarantees, so this may not be a new limitation.
Asynchronous Log Purging
This feature was created to address the latency overhead of the log cleanups that were done in line within a micro-batch. By making this log cleanup/purge operation asynchronous and performed in the background, we can remove the latency overhead this operation will incur on actual data processing. Also, these purges do not need to be done with every micro-batch and can occur on a more relaxed schedule.
Note that this feature / improvement does not have any limitations on what type of pipelines or workloads can use this, thus this feature will be enabled in the background by default for all Structured Streaming pipelines.
Benchmarks
In order to understand the performance of async progress tracking and async log purging, we created a few benchmarks. Our goal with the benchmarks is to understand the difference in performance that the improved offset management provides in an end-to-end streaming pipeline. The benchmarks are divided into two categories:
- Rate Source to Stat Sink - In this benchmark, we used a basic, stateless, stats-collecting source and sink which is useful in determining the difference in core engine performance without any external dependencies.
- Kafka Source to Kafka Sink - For this benchmark, we move data from a Kafka source to Kafka sink. This is akin to a real-world scenario to see what the difference would be in a production scenario.
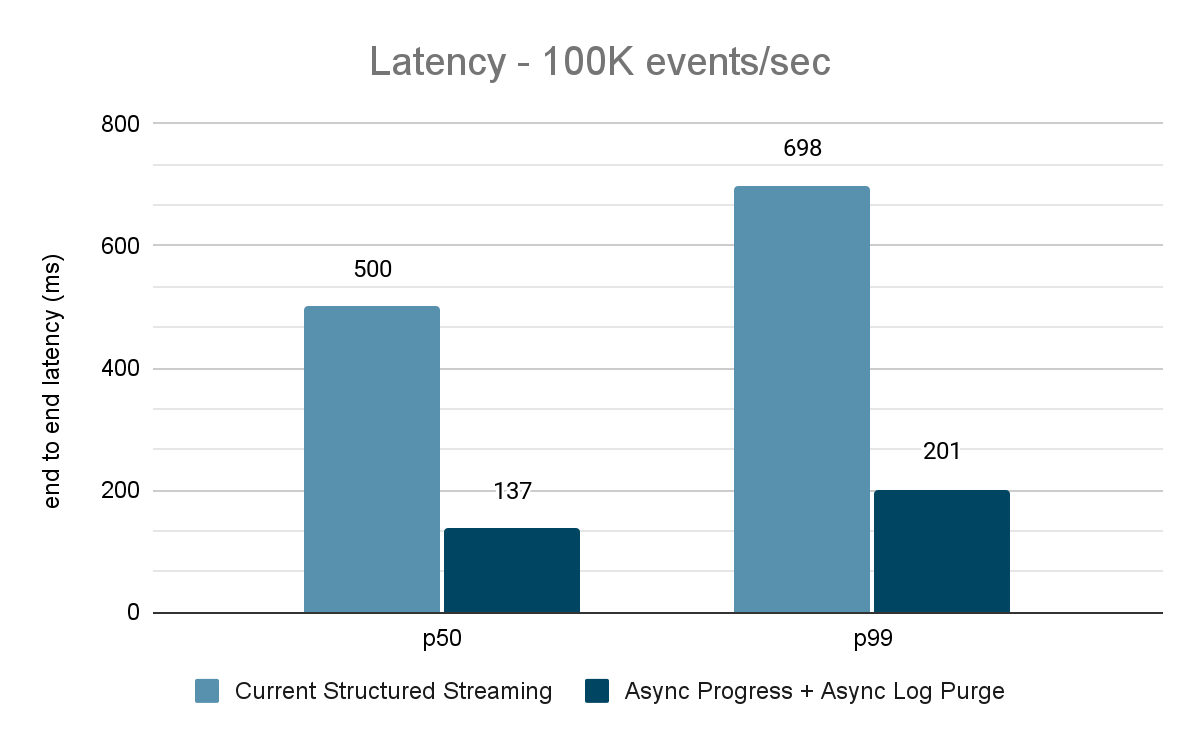
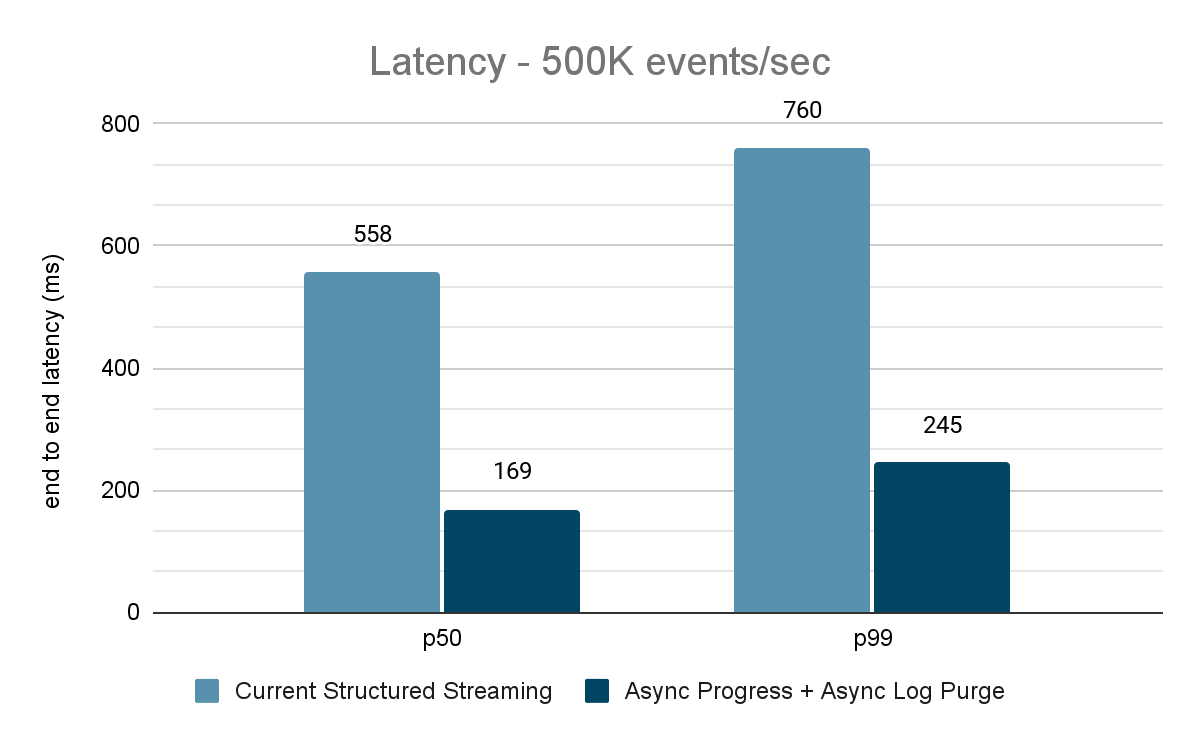
For both these benchmarks, we measured the end to end latency (50th percentile, 99th percentile) at different data input rates (100K events/sec, 500K events/sec, 1M events/sec).
Benchmark Methodology
The main methodology was to generate data from a source at a particular constant throughput. The generated records contain information about when the records were created. On the sink side, we use the Apache DataSketches library to collect the difference between the time the sink processes the record and the time that it was created in each batch. This is used to calculate the latency. We used the same cluster with the same number of nodes for all experiments.
Note: For the Kafka benchmark, we put aside some nodes of a cluster for running Kafka and generating the data for feeding to Kafka. We calculate the latency of a record only after the record has been successfully published into Kafka (on the sink)
Rate Source to Stat Sink Benchmark
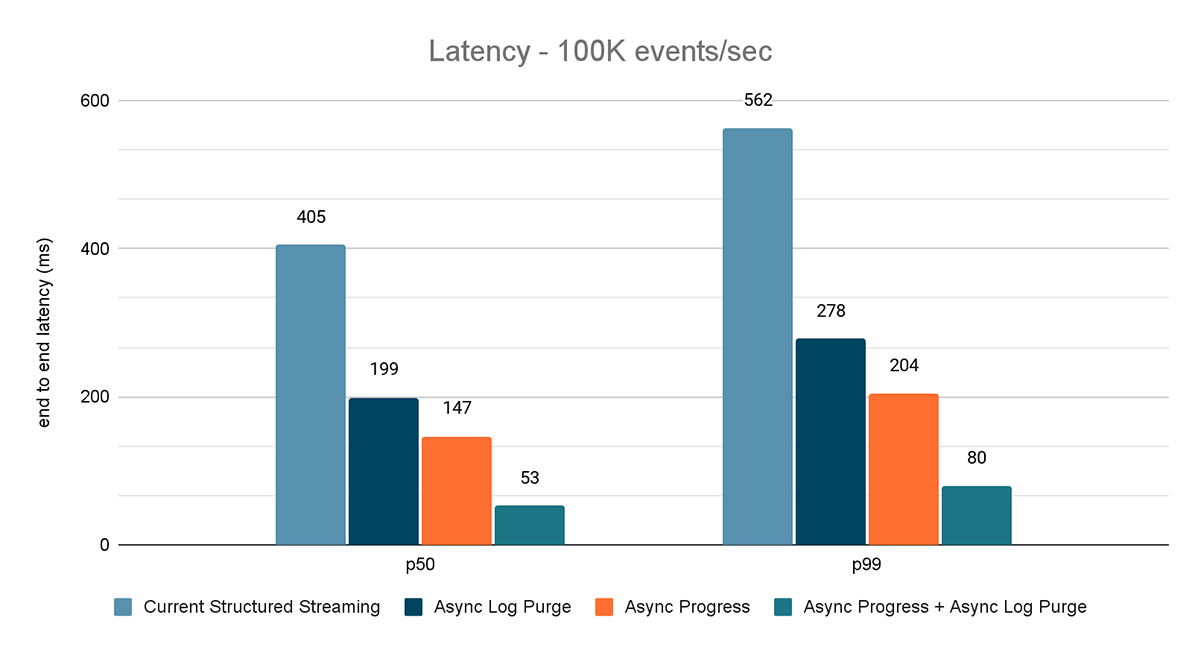
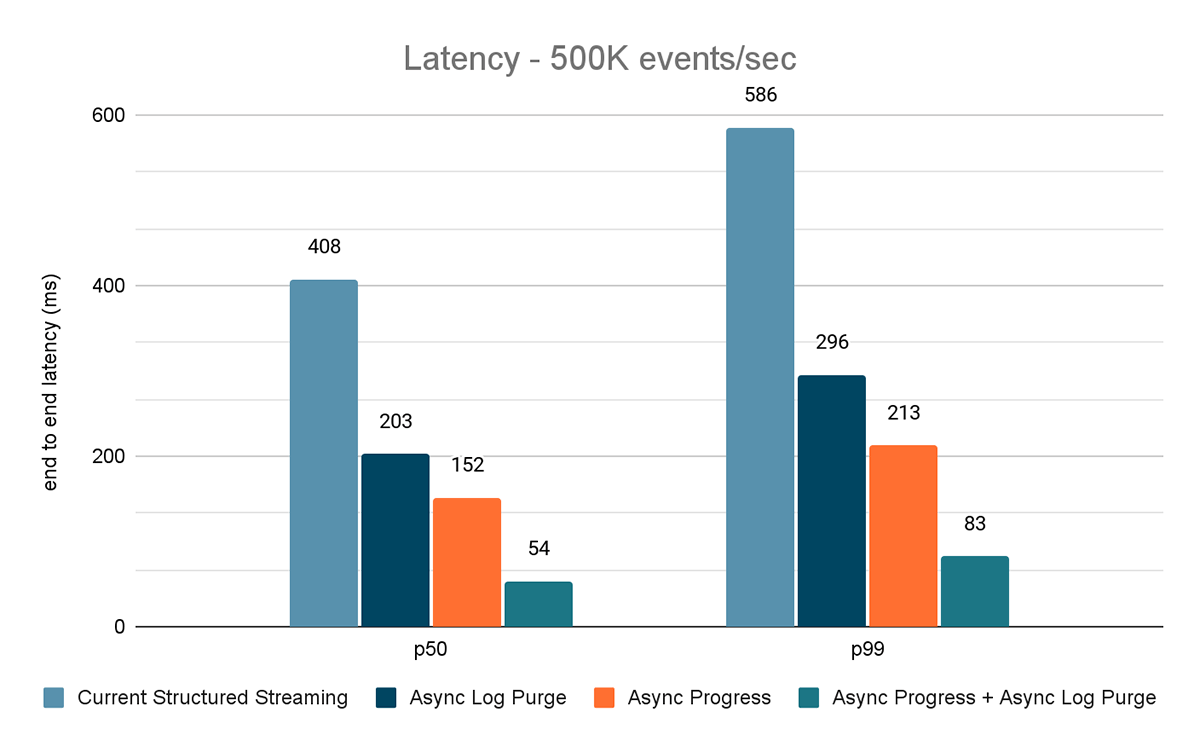
For this benchmark, we used a Spark cluster of 7 worker nodes (i3.2xlarge - 4 cores, 61 GiB memory) using the Databricks runtime (11.3). We measured the end to end latency for the following scenarios to quantify the contribution of each improvement.
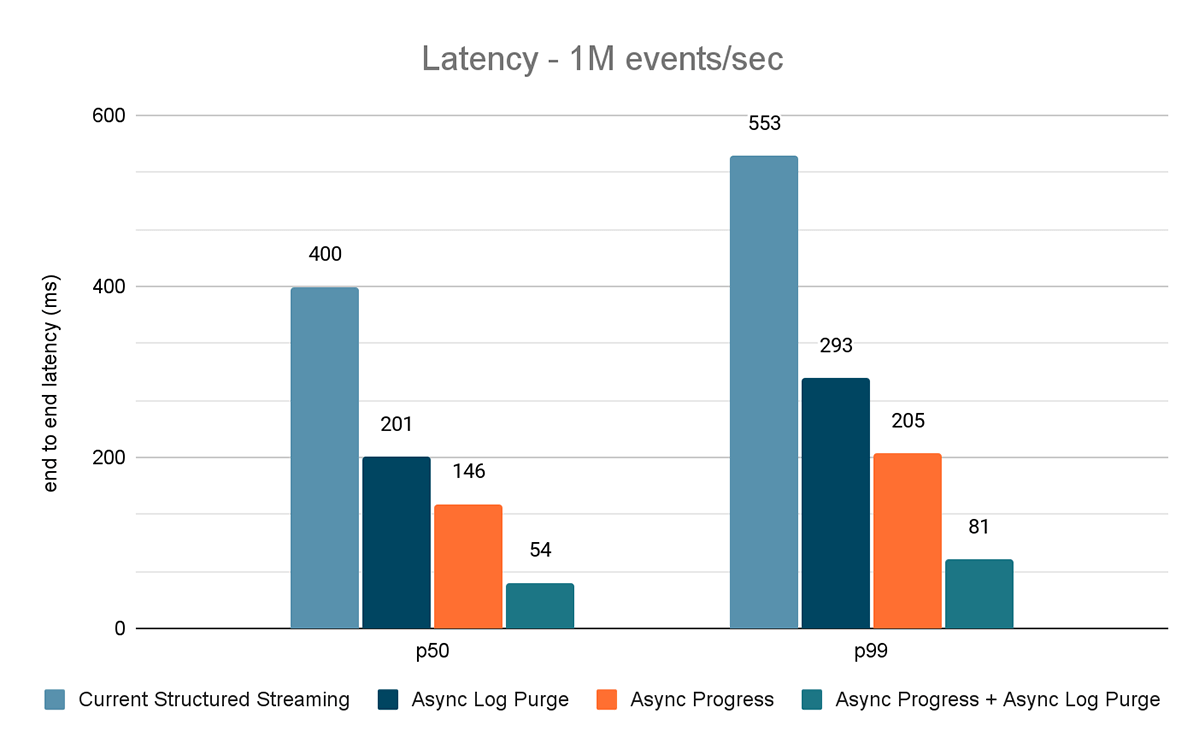
- Current Structured Streaming - this is the baseline latency without any of the aforementioned improvements
- Async Log Purge - this measures the latency after applying asynchronous log purging only
- Async Progress - this measures the latency after applying asynchronous progress tracking
- Async Progress + Async Log Purge - this measures the latency after applying both the improvements
The results of these experiments are shown in Figures 6, 7 and 8. As you can see, async log purging consistently reduces the latency approximately by 50%. Similarly, async progress tracking alone improves latency by approximately 65%. Combined together, the latency reduces by 85-86% and the latency goes below 100 ms.
Kafka Source to Kafka Sink Benchmark
For the Kafka benchmarks, we used a Spark cluster of 5 worker nodes (i3.2xlarge - 4 cores, 61 GiB memory), a separate cluster of 3 nodes to run Kafka and an additional 2 nodes to generate data added to the Kafka source. Our Kafka topic has 40 partitions and a replication factor of 3.
The data generator publishes the data into a Kafka topic and the structured streaming pipeline consumes data and republishes into another Kafka topic. The results of the performance evaluation are shown in Figures 9, 10 and 11. As one can see, after applying async progress and async log purging, the latency reduces by 65-75% or 3-3.5X across different throughputs.
Summary of Performance Results
With the new asynchronous progress tracking and asynchronous log purge, we can see that both configs reduce latency as much as 3X. Working together, latency is greatly reduced across all throughputs. The charts also show that the amount of time saved is usually a constant amount of time (200 - 250 ms for each config) and together they can shave off around 500 ms across the board (leaving enough time for batch planning and query processing).
Availability
These performance improvements are available in Databricks Lakehouse Platform from DBR 11.3 onwards. Async log purging is enabled by default in DBR 11.3 and subsequent releases. Furthermore, these improvements have been contributed to Open Source Spark and is available from Apache Spark 3.4 onwards.
Future Work
There are currently some limitations to the types of workloads and sinks supported by the asynchronous progress tracking feature. We will be looking into supporting more types of workloads with this feature in the future.
This is only the beginning of the predictable low latency features we are building in Structured Streaming as part of Project Lightspeed. In addition, we will continue to benchmark and profile Structured Streaming to find more areas of improvement. Stay tuned!
Join us at the Data and AI Summit in San Francisco, June 26-29 to learn more about Project Lightspeed and data streaming on the Databricks Lakehouse Platform.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.