Apache Spark™ Tutorial: Getting Started with Apache Spark on Databricks
Structured Streaming Overview
Sensors, IoT devices, social networks, and online transactions all generate data that needs to be monitored constantly and acted upon quickly. As a result, the need for large-scale, real-time stream processing is more evident than ever before. This tutorial module introduces Structured Streaming, the main model for handling streaming datasets in Apache Spark. In Structured Streaming, a data stream is treated as a table that is being continuously appended. This leads to a stream processing model that is very similar to a batch processing model. You express your streaming computation as a standard batch-like query as on a static table, but Spark runs it as an incremental query on the unbounded input table.
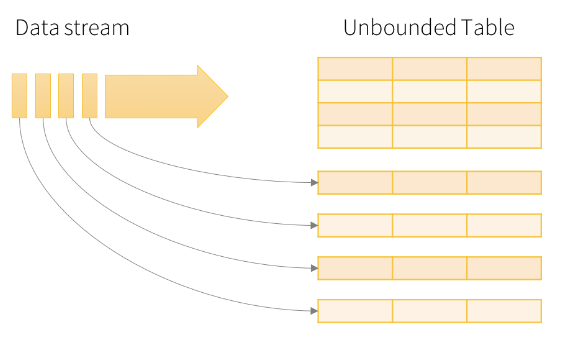
Consider the input data stream as the input table. Every data item that is arriving on the stream is like a new row being appended to the input table.
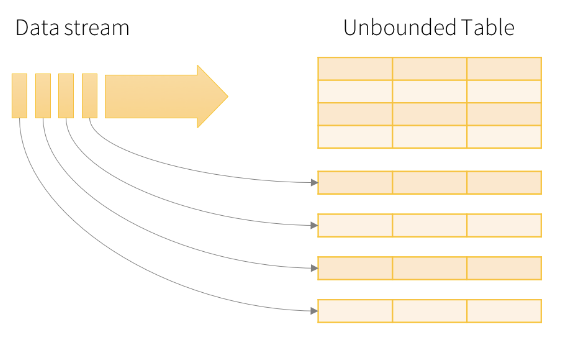
A query on the input generates a result table. At every trigger interval (say, every 1 second), new rows are appended to the input table, which eventually updates the result table. Whenever the result table is updated, the changed result rows are written to an external sink. The output is defined as what gets written to external storage. The output can be configured in different modes:
- Complete Mode: The entire updated result table is written to external storage. It is up to the storage connector to decide how to handle the writing of the entire table.
- Append Mode: Only new rows appended in the result table since the last trigger are written to external storage. This is applicable only for the queries where existing rows in the Result Table are not expected to change.
- Update Mode: Only the rows that were updated in the result table since the last trigger are written to external storage. This is different from Complete Mode in that Update Mode outputs only the rows that have changed since the last trigger. If the query doesn't contain aggregations, it is equivalent to Append mode.
In this tutorial module, you will learn how to:
- Load sample data
- Initialize a stream
- Start a stream job
- Query a stream
We also provide a sample notebook that you can import to access and run all of the code examples included in the module.
Load sample data
The easiest way to get started with Structured Streaming is to use an example Databricks dataset available in the /databricks-datasetsfolder accessible within the Databricks workspace. Databricks has sample event data as files in /databricks-datasets/structured-streaming/events/to use to build a Structured Streaming application. Let's take a look at the contents of this directory.
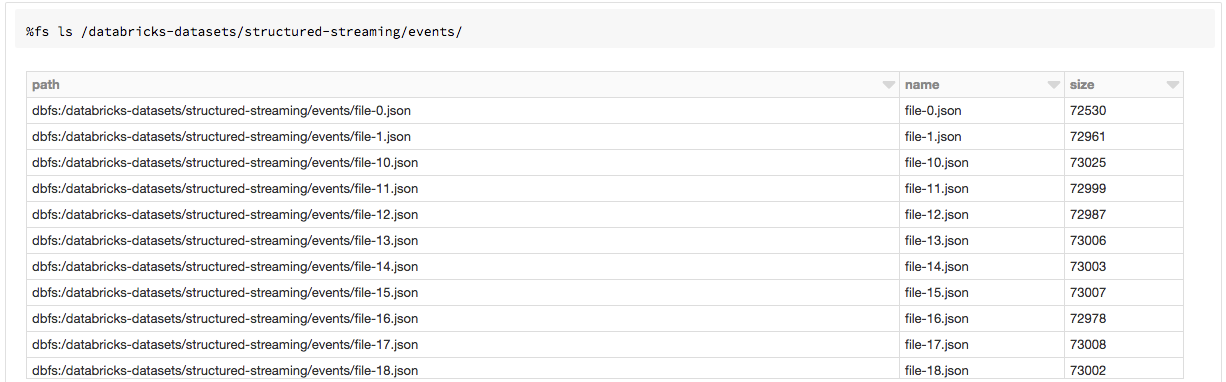
Each line in the file contains a JSON record with two fields: timeand action.
Initialize the stream
Since the sample data is just a static set of files, you can emulate a stream from them by reading one file at a time, in the chronological order in which they were created.
Start the streaming job
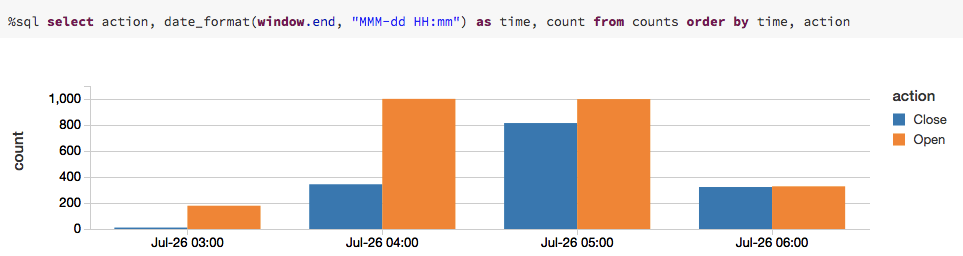
You start a streaming computation by defining a sink and starting it. In our case, to query the counts interactively, set the completeset of 1 hour counts to be in an in-memory table.
queryis a handle to the streaming query named countsthat is running in the background. This query continuously picks up files and updates the windowed counts. The command window reports the status of the stream:

When you expand counts, you get a dashboard of the number of records processed, batch statistics, and the state of the aggregation:
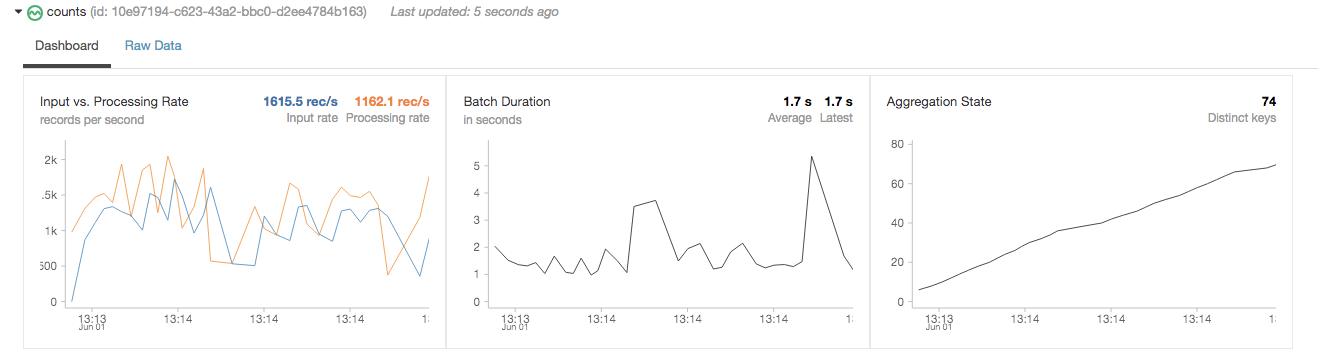
Interactively query the stream
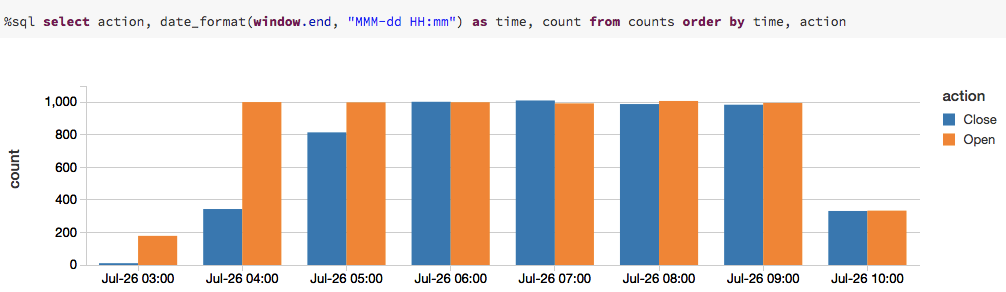
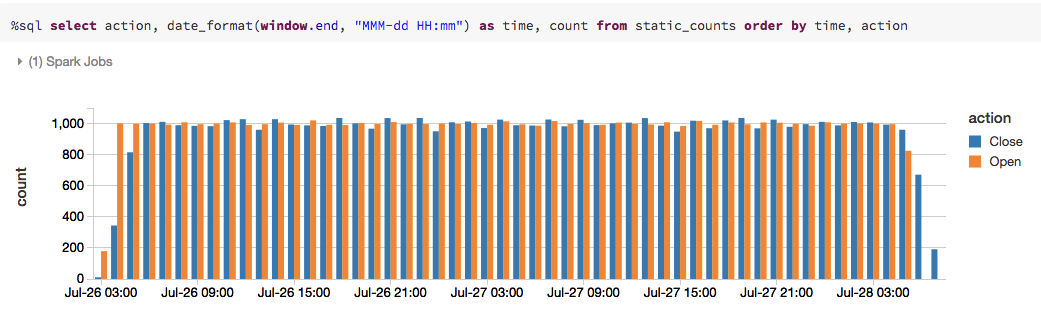
countsaggregation:
As you can see from this series of screenshots, the query changes every time you execute it to reflect the action count based on the input stream of data.
We also provide a sample notebook that you can import to access and run all of the code examples included in the module.