The Power of Fine-Tuning on Your Data: Quick Fixing Bugs with LLMs via Never Ending Learning (NEL)
by Samantha Banchik, Ta-Chung Chi, Sam Havens, Dipendra Misra, Will Tipton, Jan van der Vegt, Matei Zaharia and Emanuel Zgraggen
Summary: LLMs have revolutionized software development by increasing the productivity of programmers. However, despite off-the-shelf LLMs being trained on a significant amount of code, they are not perfect. One key challenge for our Enterprise customers is the need to perform data intelligence, i.e., to adapt and reason using their own organization’s data. This includes being able to use organization-specific coding concepts, knowledge, and preferences. At the same time, we want to keep latency and cost low. In this blog, we demonstrate how fine-tuning a small open-source LLM on interaction data enables state-of-the-art accuracy, low cost, and minimal latency.
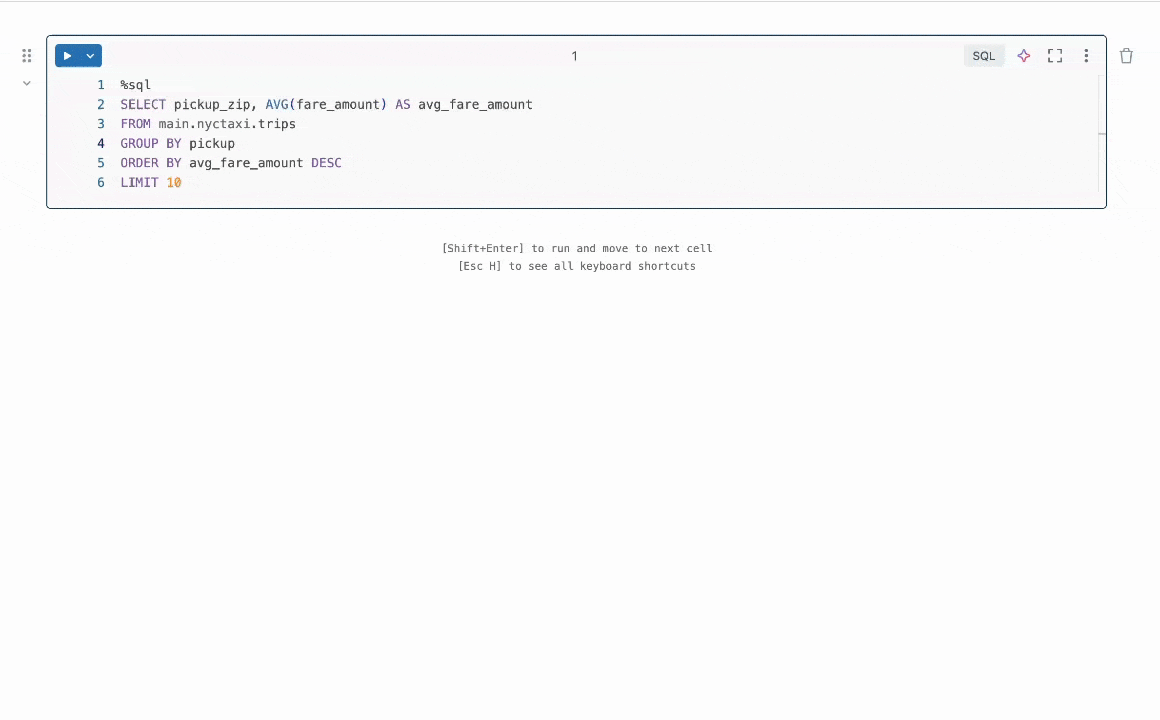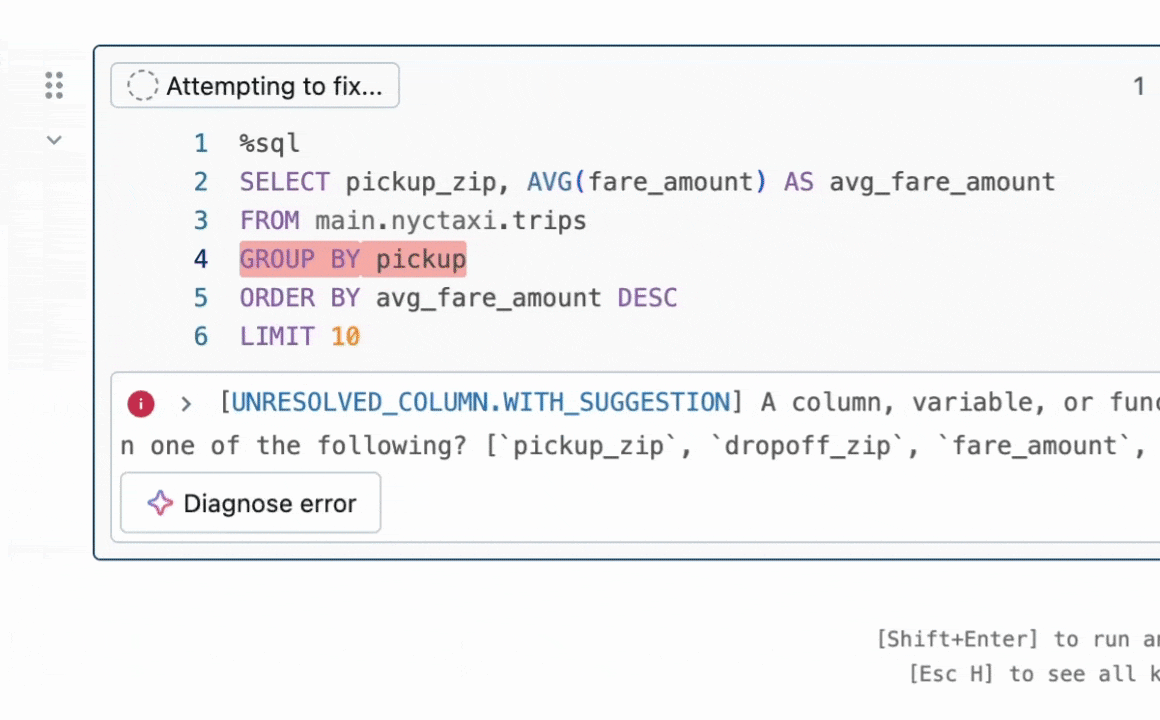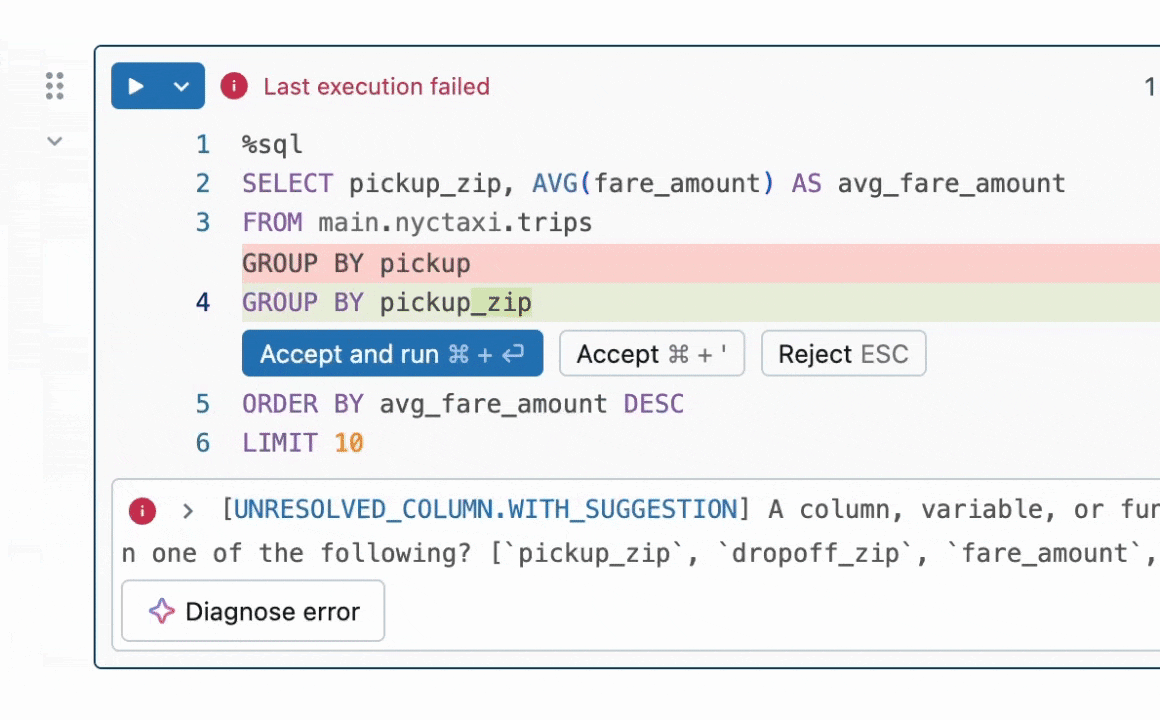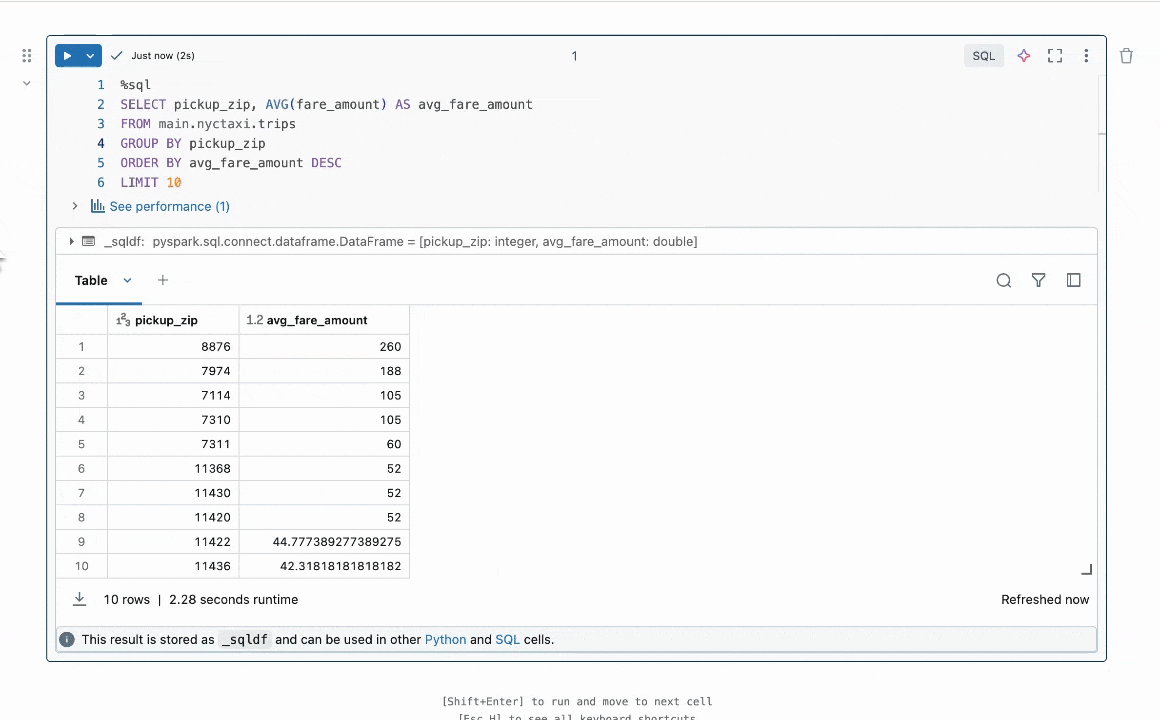
Figure 1: Quick Fix helps users resolve errors by suggesting code fixes in-line.
TL;DR of Result: We focus on the task of program repair which requires fixing bugs in code. This problem has been widely studied in the literature without LLMs [1, 2] and more recently with LLMs [3, 4]. In industry, practical LLM agents such as the Databricks Quick Fix are available. Figure 1 shows the Quick Fix agent in action in a Databricks Notebook environment. In this project, we fine-tuned the Llama 3.1 8b Instruct model on internal code written by Databricks employees for analyzing telemetry. The fine-tuned Llama model is evaluated against other LLMs via a live A/B test on internal users. We present results in Figure 2 showing that the fine-tuned Llama achieves 1.4x improvement in acceptance rate over GPT-4o while achieving a 2x reduction in inference latency.
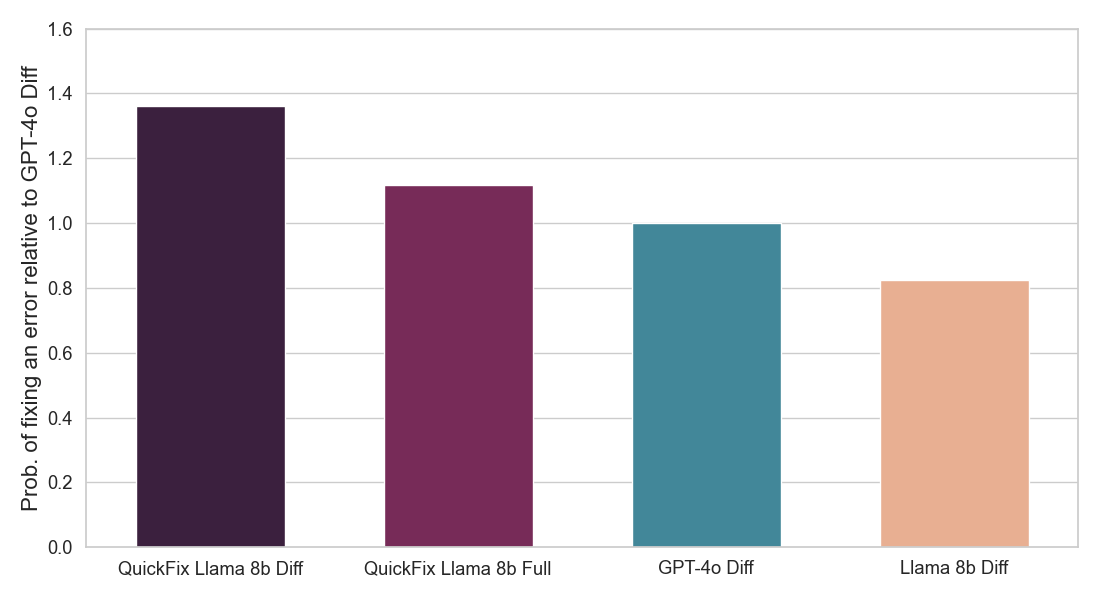
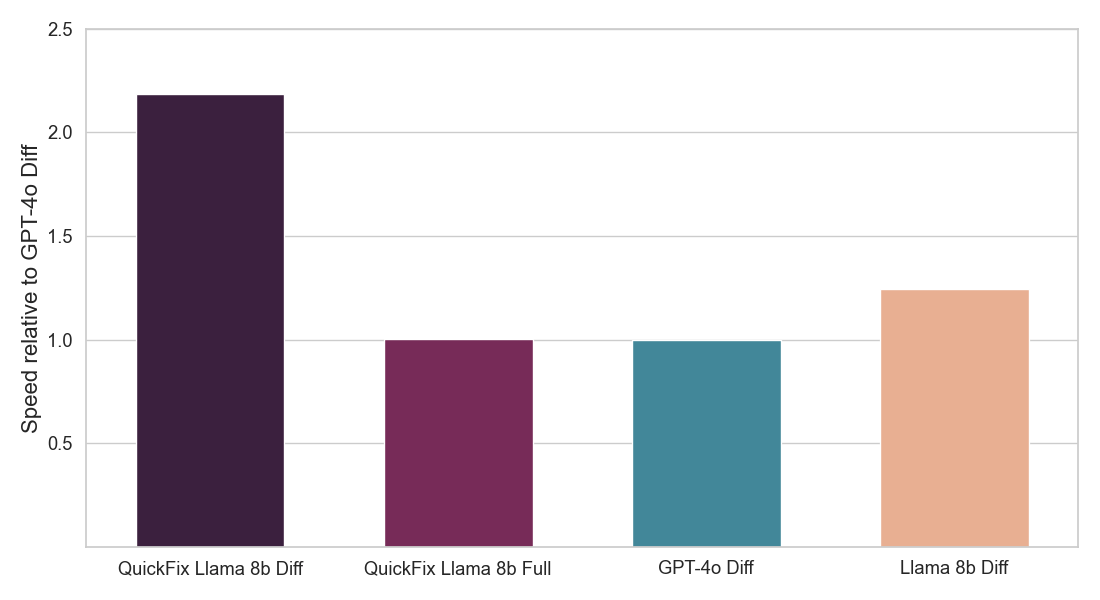
Figure 2: Shows fraction of proposed LLM fixes that were accepted by users (above) and inference speed of each Quick Fix LLM agent (below). Both numbers are normalized with respect to the GPT-4o agent (see details below). Our model (QuickFix Llama 8b Diff) achieves both the highest accuracy and lowest latency. Models with the suffix diff generate edits to the buggy code, while those with the suffix full generate the full code.
Why does it matter? Many organizations, including many existing Databricks customers, have coding usage data that contains inhouse knowledge, concepts, and preferences. Based on our results, these organizations can fine-tune small open-source LLMs that achieve better code quality and inference speed. These models can then be hosted by the organization or a trusted third party for cost, reliability, and compliance wins.
We emphasize that training on interaction data is particularly effective for three reasons. Firstly, it is naturally generated – so requires no annotation effort. Secondly, it contains examples that are encountered in practice and so it is particularly useful for fine-tuning even in moderate quantities. Finally, as interaction data is constantly generated by interactions with the LLM agent, we can repeatedly use newly generated interaction data to further fine-tune our LLM leading to Never Ending Learning (NEL).
What’s next? We believe that these lessons are also true for other enterprise applications. Organizations can fine-tune LLMs such as Llama for program repair or other tasks using Databricks’ fine-tuning service and serve the model in just one click. You can get started here. We are also exploring offering customers the ability to personalize Quick Fix using their own data.
Details of Our Study
A Databricks Workspace provides multiple LLM agents for enhancing productivity. These include an LLM agent for code autocomplete, an AI assistant which can engage in conversations to help users, and the Quick Fix agent for program repair. In this blogpost, we focus on the Quick Fix agent (Figure 1).
Program repair is a challenging problem in practice. The errors can range from syntactic mistakes to wrong column names to subtle semantic issues. Further, there are personalization aspects or constraints which aren’t always well handled by off-the-shelf LLMs. For example, Databricks users typically write standard ANSI or Spark SQL, not PL/SQL scripts, but a different format may be preferred by other organizations. Similarly, when fixing the code, we don’t want to change the coding style even if the proposed fix is correct. One can use a proprietary model such as GPT-4, o1, or Claude 3.5 along with prompt engineering to try and remedy these limitations. However, prompt engineering may not be as effective as fine-tuning. Further, these models are expensive, and latency is a crucial factor, since we want to suggest fixes before the user can fix the code themselves. Prompt engineering approaches such as in-context learning [5] or self-reflection [6] can further increase latency. Finally, some customers may be hesitant to use proprietary models hosted elsewhere.
Small open-source models such as Llama 8b, Gemma 4b, R1 Distill Llama 8b and Qwen 7b offer an alternative with different tradeoffs. These models can be cheap, fast, and be trained and hosted by the organization or a trusted third-party for better compliance. However, they tend to perform substantially worse than some of the proprietary models listed above. As we can see in Figure 1, the Llama 3.1 8b instruct model is the worst performing of the models tested. This raises the question:
Can we adapt small, open-source models and still outperform off-the-shelf proprietary models on accuracy, cost and speed?
While prompt engineering provides some gains (see results below), it tends to be less effective than fine-tuning the LLM, especially for smaller models. However, to perform effective fine-tuning, we need appropriate domain data. Where do we get this?
Fine-tuning Llama 8b using your Interaction Data
For program repair tasks, one can use interaction data that is organically generated by users to perform fine-tuning. This works as follows (Figure 3):
 Figure 3: We use deployment logs for fine-tuning LLMs which can be used for never ending fine-tuning of LLMs.
Figure 3: We use deployment logs for fine-tuning LLMs which can be used for never ending fine-tuning of LLMs.
- We log the buggy code y, the first time the user executes the code cell leading to an error. We also log any additional context x such as the error message, surrounding code cells, and metadata (e.g. list of available tables and APIs).
- We then log the code y' the next time the user successfully executes the code in the originally-buggy cell. This response could be potentially generated by the Quick Fix Llama agent, by the user themselves, or by both.
- We store (x, y, y') in a dataset for fine-tuning.
We filter two extreme cases: where the supposed fixed code y' is the same as the actual code y, indicating bugfix due to external reasons (e.g., fixing a permission issue via changing config elsewhere), and where y' is substantially different than y, indicating a potential re-write rather than a targeted fix. We can use this data to perform fine-tuning by learning to generate y' given context x and buggy code y.
We use Databricks’ own internal interaction data, processed as described above, to fine-tune a Llama 3.1 8b Instruct model. We train two types of model – one which generates the entire fixed code (full models) and one which only generates the code diff needed to fix the buggy code (diff models). The latter tends to be faster as they need to produce fewer tokens, but they solve a harder task. We used Databricks’ fine-tuning service and did a sweep over different learning rates and training iterations. The results of our A/B test in Figure 2 show that our fine-tuned Llama model is both significantly better at fixing bugs than off-the-shelf LLMs and is also much faster.
We select the best hyperparameters using an offline evaluation where we measure exact-match accuracy on a held-out subset of our interaction data. The exact-match accuracy is a 0-1 score that measures whether our LLM can generate the fixed code y' given the buggy code y and context x. While this is a noisier metric than A/B testing, it can provide a useful signal for hyperparameter selection. We show offline evaluation results in Figure 4. While the original Llama models perform substantially worse than GPT-4o models, our fine-tuned Llama model performs the best overall. Further, while prompt-engineering via in-context learning (ICL) offers a substantial gain, it is still not as effective as performing fine-tuning.
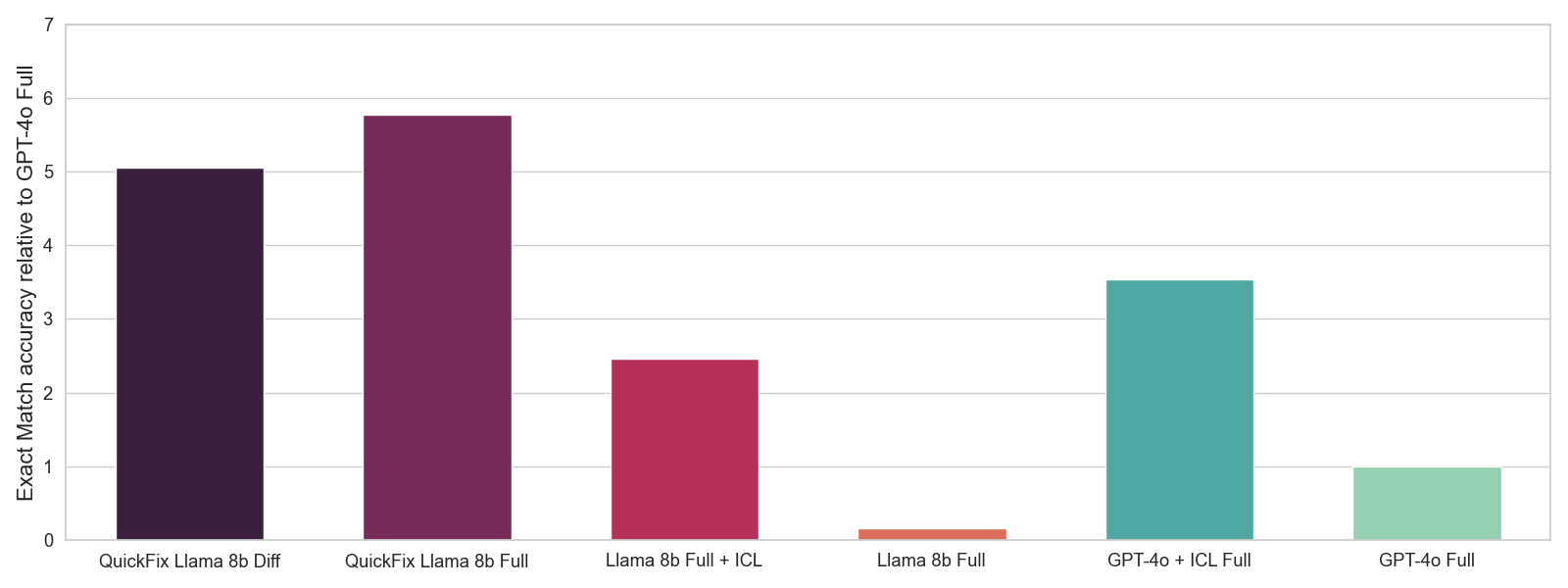 Figure 4: Offline evaluation with different LLMs. We use 5 examples for ICL. We report mean 0-1 exact-match accuracy based on whether the generated fix matches the ground truth fix. We normalize accuracies relative to GPT-4o accuracy.
Figure 4: Offline evaluation with different LLMs. We use 5 examples for ICL. We report mean 0-1 exact-match accuracy based on whether the generated fix matches the ground truth fix. We normalize accuracies relative to GPT-4o accuracy.
Finally, what does our Quick Fix Llama model learn? We give two examples below to illustrate the benefit.
 Example 1: Prediction with GPT-4o and QuickFix Llama model. Real table names and constants were redacted.
Example 1: Prediction with GPT-4o and QuickFix Llama model. Real table names and constants were redacted.
In the first example, the GPT-4o agent incorrectly transformed the buggy SQL code into PySpark SQL, whereas the fine-tuned QuickFix Llama model kept the original code style. The GPT-4o edits may result in users spending time reverting unnecessary diffs, thereby diminishing the benefit of a bugfix agent.
 Example 2: Prediction with GPT-4o and QuickFix Llama model. We don’t show the context for brevity but the context in this case contains a column _partition_date for table table2. Real table names and constants were redacted.
Example 2: Prediction with GPT-4o and QuickFix Llama model. We don’t show the context for brevity but the context in this case contains a column _partition_date for table table2. Real table names and constants were redacted.
In the second example, we found that the GPT-4o agent incorrectly replaced the column date with _event_time by over-indexing on the hint given in the error message. However, the right edit is to use the column named _partition_date from the context which is what both the user and the QuickFix Llama does. The GPT-4o’s edits do look superficially correct, using a time variable suggested by the SQL engine. However, the suggestion actually demonstrates a lack of domain-specific knowledge which can be corrected by fine-tuning.
Conclusion
Organizations have specific coding needs that are best handled by a custom LLM agent. We’ve found that fine-tuning LLMs can significantly improve the quality of coding suggestions, out-performing prompt-engineering approaches. In particular, our fine-tuned small Llama 8B models were faster, cheaper, and more accurate than significantly larger proprietary models. Finally, training examples can be generated using interaction data which is available at no extra annotation cost. We believe these findings generalize beyond the program repair task as well.
With Databricks Model Training, customers can easily fine-tune models such as Llama. You can learn more about how to fine-tune and deploy open-source LLMs at Databricks here. Interested in a personalized Quick Fix model for your organization? Reach out to your Databricks account team to learn more.
Acknowledgments: We thank Michael Piatek, Matt Samuels, Shant Hovsepian, Charles Gong, Ted Tomlinson, Phil Eichmann, Sean Owen, Andy Zhang, Beishao Cao, David Lin, Yi Liu, Sudarshan Seshadri for valuable advice, help, and annotations.
References
- Automated program repair, Goues, et al., 2019. In Communications of the ACM 62.12 (2019): 56-65.
- Semfix: Program repair via semantic analysis, Nguyen et al. 2013. In the 35th International Conference on Software Engineering (ICSE). IEEE, 2013.
- Inferfix: End-to-end program repair with LLMs, Jin et al., 2023. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering.
- RepairAgent: An Autonomous, LLM-Based Agent for Program Repair, Bouzenia et al., 2024. In arXiv https://arxiv.org/abs/2403.17134.
- Language models are few-shot learners, Brown et al. 2020. In the Advances in Neural Information Processing Systems (NeurIPS).
- Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies, Pan et al., 2024. In Transactions of the Association for Computational Linguistics (TACL).
*Authors are listed in alphabetical order
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.