What are Hash Buckets?
A feature engineering technique mapping high-cardinality categorical variables into fixed-size vectors using hash functions for efficient ML memory usage
- Hash buckets group records based on the output of a hash function applied to one or more key fields. They are used to distribute data evenly across partitions or storage locations for faster lookups and joins. Hash bucketing can improve performance when operations repeatedly access data using the same keys.
In computing, a hash table [hash map] is a data structure that provides virtually direct access to objects based on a key [a unique String or Integer]. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found. Here are the main features of the key used:
- The key used can be your SSN, your telephone number, account number, etc
- Must have unique keys
- Each key is associated with–mapped to–a value
The agentic AI playbook for the enterprise

Hash buckets are used to apportion data items for sorting or lookup purposes. The aim of this work is to weaken the linked lists so that searching for a specific item can be accessed within a shorter timeframe. 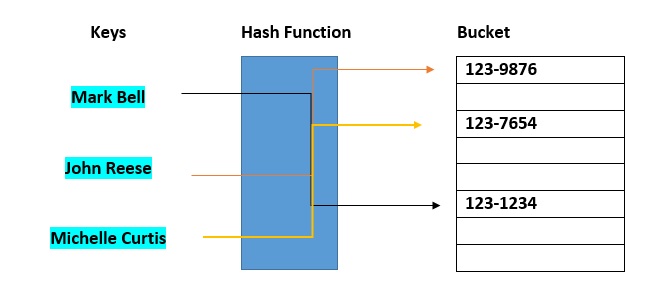 A hash table that uses buckets is actually a combination of an array and a linked list. Each element in the array [the hash table] is a header for a linked list. All elements that hash into the same location will be stored in the list. The hash function assigns each record to the first slot within one of the buckets. In case the slot is occupied, then the bucket slots will be searched sequentially until an open slot is found. In case a bucket is completely full, the record will get stored in an overflow bucket of infinite capacity at the end of the table. All buckets share the same overflow bucket. However, a good implementation will use a hash function that distributes the records evenly among the buckets so that as few records as possible go into the overflow bucket.
A hash table that uses buckets is actually a combination of an array and a linked list. Each element in the array [the hash table] is a header for a linked list. All elements that hash into the same location will be stored in the list. The hash function assigns each record to the first slot within one of the buckets. In case the slot is occupied, then the bucket slots will be searched sequentially until an open slot is found. In case a bucket is completely full, the record will get stored in an overflow bucket of infinite capacity at the end of the table. All buckets share the same overflow bucket. However, a good implementation will use a hash function that distributes the records evenly among the buckets so that as few records as possible go into the overflow bucket.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.