What are ML Pipelines?
Learn how ML pipelines automate and streamline the machine learning workflow from data preprocessing to model validation
- ML pipelines organize the steps of a machine learning workflow, from data preparation through model training and prediction, into a single sequence. They chain together transformers and estimators so the same processing is applied consistently during training and inference. Using ML pipelines makes experiments easier to manage and helps move models into production with less manual glue code.
Typically when running machine learning algorithms, it involves a sequence of tasks including pre-processing, feature extraction, model fitting, and validation stages. For example, when classifying text documents might involve text segmentation and cleaning, extracting features, and training a classification model with cross-validation. Though there are many libraries we can use for each stage, connecting the dots is not as easy as it may look, especially with large-scale datasets. Most ML libraries are not designed for distributed computation or they do not provide native support for pipeline creation and tuning.
The agentic AI playbook for the enterprise

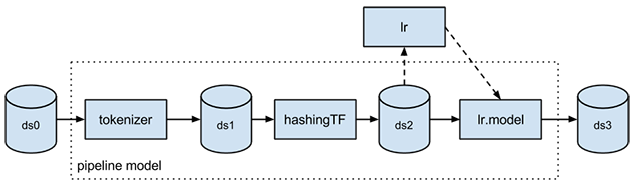
The ML Pipelines is a High-Level API for MLlib that lives under the "spark.ml" package. A pipeline consists of a sequence of stages. There are two basic types of pipeline stages: Transformer and Estimator. A Transformer takes a dataset as input and produces an augmented dataset as output. E.g., a tokenizer is a Transformer that transforms a dataset with text into an dataset with tokenized words. An Estimator must be first fit on the input dataset to produce a model, which is a Transformer that transforms the input dataset. E.g., logistic regression is an Estimator that trains on a dataset with labels and features and produces a logistic regression model.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.