What is Sparklyr?
An R package that provides dplyr-style syntax for Apache Spark, allowing R users to perform distributed data manipulation and machine learning on massive datasets
- Sparklyr is an open source R package that connects R to Apache Spark so analysts can use familiar dplyr style syntax on datasets that are too large for a single machine.
- Sparklyr lets R users manipulate Spark DataFrames, run SQL and orchestrate distributed machine learning through Spark MLlib and H2O SparkingWater from within their R environment.
- Sparklyr can load data from many sources and connect to both local Spark and remote Databricks clusters, giving teams an easy path to scale existing R workflows.
What is Sparklyr?
Sparklyr is an open-source package that provides an interface between R and Apache Spark. You can now leverage Spark’s capabilities in a modern R environment, due to Spark’s ability to interact with distributed data with little latency. Sparklyr is an effective tool for interfacing with large datasets in an interactive environment. This way you can benefit from the familiar tools in R in order to analyze data in Spark., giving you the best of both worlds. 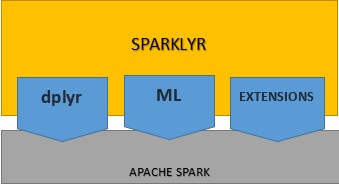 Through Sparklyr you can use Spark as the backend for dplyr, a popular data manipulation package. Sparklyr provides a range of functions that allow us to access the Spark tools for transforming/pre-processing data, On top of that, it also provides interfaces to Spark’s distributed machine learning algorithms and much more. Sparklyr is also extensible. R packages that depend on Sparklyr to call the full Spark API can be created. One such extension is H2O’s Rsparkling, an R package compatible with H2O’s machine learning algorithm.
Through Sparklyr you can use Spark as the backend for dplyr, a popular data manipulation package. Sparklyr provides a range of functions that allow us to access the Spark tools for transforming/pre-processing data, On top of that, it also provides interfaces to Spark’s distributed machine learning algorithms and much more. Sparklyr is also extensible. R packages that depend on Sparklyr to call the full Spark API can be created. One such extension is H2O’s Rsparkling, an R package compatible with H2O’s machine learning algorithm.
The agentic AI playbook for the enterprise

Main highlights of Sparklyr:
- Users can interactively manipulate Spark data using dplyr as well as SQL (via DBI).
- Spark datasets can be filtered and aggregated and afterward brought into R to be analyzed.
- You will be able to orchestrate distributed machine learning from R using either Spark MLlib or H2O SparkingWater.
- Sparklyr users are able to generate extensions that call the full Spark API and provide interfaces to Spark packages.
- Sparklyr tool offers an exhaustive dplyr backend useful in case of data manipulation, analysis, and visualization
- Loads data into Spark DataFrames from various locations such as local R data frames, Hive tables, CSV, JSON, and Parquet files.
- Sparklyr is able to connect to both local instances of Spark as well as to remote Spark clusters
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.