
EQT is the leading natural gas producer in the United States, operating upstream and midstream assets with a strong commitment to sustainability, including becoming the first traditional energy company of scale in the world to achieve net zero on a Scope 1 and Scope 2 basis across upstream assets. To keep operations efficient and data-driven, EQT’s BI team runs the enterprise analytics foundation that supports executives, field operations, production and commercial teams. When Synapse became a performance bottleneck, the team migrated to Databricks to modernize pipelines, unify governance with Unity Catalog and accelerate analytics with Databricks SQL.
Migrating from Synapse to remove bottlenecks
EQT’s BI team supports data and analytics across departments—from executives to drilling, production and commodities. Over time, Synapse became the constraint. Teams spent real effort tuning and managing long-running workloads, and a single runaway query could drag down everyone sharing the same environment.
EQT’s path to Databricks started pragmatically: stabilize performance, reduce “blast radius,” and create a safer way to scale usage. Databricks made it easier to isolate compute by group, so one workload didn’t take down the rest of the business.
The team also avoided a risky cutover. They ran Synapse and Databricks in parallel, using Delta as an intermediary layer to keep the systems aligned while migrating pipelines and rewriting views. As Frank D’Ambrosio, Data Engineer, put it, they were able to “shut off the change data feed to Synapse and redirect traffic onto Unity Catalog,” which enabled them to switch consumers with confidence. EQT completed the migration in six months without any external help.
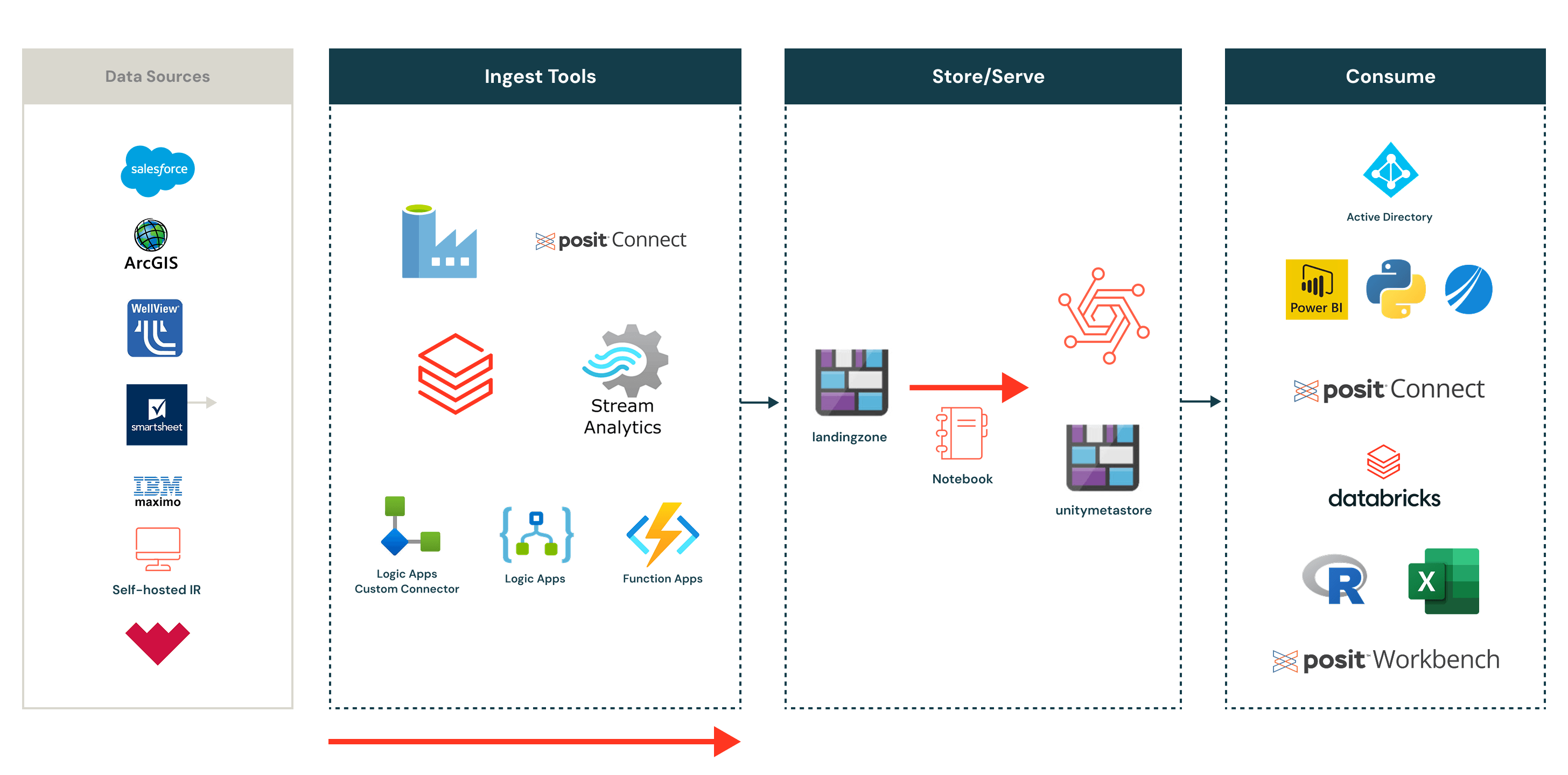
Unity Catalog as the primary driver
Once EQT began building on Delta, Unity Catalog shifted the project from a “performance fix” to a “new foundation.” The team wanted a single place to manage data access, discovery and lineage—without duplicating data across multiple systems or creating a separate warehouse just to support analytics.
Unity Catalog reinforced a simple operating model: land data once, govern it once and let every team work from the same governed source. In EQT’s words, “we put data in the data lake, but we don’t have to move the data into any other data warehouse. All Delta tables are there,” said Josh Rosenstein, BI Operations Manager.
That mattered even more as EQT’s footprint expanded through acquisition and new regulated datasets entered the environment. Instead of splitting sensitive data into separate databases or schemas, the team could keep data centralized and apply policies—scaling security without multiplying copies.
Democratizing self-service across the business
EQT’s BI organization is designed to enable the business, not gate it. The team supports two main self-service modes: notebook-style development for more technical builders and SQL-first access for analysts who live in queries and dashboards. Both groups can create and test within Databricks while the BI team maintains a governed foundation.
The bigger win was reducing friction for everyday users. Moving to Databricks meant fewer prerequisites, fewer local setup steps, and less “how do I even connect?” overhead. “Everything is in one place. Analysts did not have to configure anything on their local machine,” said Rosenstein, “which substantially boosted our productivity.”
To make self-service sustainable at scale, EQT also standardized how data flows through the business: ingest into Databricks first, then publish out to tools like Power BI, dashboards and downstream systems. That front-door pattern reduced point-to-point sprawl and sped up onboarding new use cases.
Databricks SQL speed changes what teams expect
The payoff showed up as soon as users tried migrating workloads. Instead of debating theoretical benchmarks, teams felt the difference in their day-to-day work. “Databricks SQL is so fast… it took minutes to run in our legacy warehouse, and it takes seconds to run in Databricks.”, said Marcha van Wyk, BI Data Architect. That kind of reaction from the data analysts gave the BI team immediate business validation.
On large operational datasets, EQT also saw measurable gains. For large SCADA telemetry workloads (hundreds of GB), the team benchmarked 3.5x faster performance. Just as importantly, speed removed downstream pain: when Synapse stopped being the bottleneck, Power BI experienced fewer timeouts and less compute wasted waiting on slow extraction.
Finally, performance unlocked freshness. EQT didn’t only move to incrementals to reduce load sizes—they used it to increase update velocity. As D’Ambrosio explained, key tables moved from once-daily updates to 12 refreshes across the business day, enabling faster dashboards and more frequent integration with other systems. Now that fast is the baseline, the team is shifting from migration mode to optimization mode—keeping performance high while tightening cost and operational efficiency.