
Vivriti Capital Limited is a fintech-focused non-banking financial company (NBFC) based in India, providing structured debt solutions to mid-market enterprises across the country. Operating in a highly regulated environment governed by the Reserve Bank of India (RBI) and SEBI, Vivriti relies on data to power credit underwriting, fraud detection, reporting, and partner integrations — often in real time.
As Vivriti grew rapidly through new lending partners and products, its technology team faced a familiar challenge: how to scale a complex, API-driven lending business while maintaining high availability, regulatory compliance, and cost efficiency. After outgrowing a combination of Amazon Redshift and an internally built open-source data platform, Vivriti partnered with Databricks to modernize its data architecture. Today, Databricks underpins Vivriti’s analytics, reporting, and emerging AI use cases, providing the reliability, automation, and scalability required to support the next phase of growth.
Migrating from Redshift and an in-house platform to reduce risk and cost
Vivriti Capital operates a high-volume B2B2C lending model where milliseconds matter. Every credit decision depends on real-time API calls for borrower identification, underwriting, fraud detection, and partner reconciliation, tying system reliability to revenue.
As Vivriti expanded its partner ecosystem and lending products, its legacy data architecture became a bottleneck. Vivriti used Amazon Redshift with an internally built stack using open-source Spark, Airflow, and custom orchestration. While sufficient early on, the environment struggled to meet the operational rigor required for regulated financial services. Pipeline failures delayed management and bureau reports, open-source dependencies introduced compliance risk, and engineers were frequently pulled into manual intervention to maintain SLAs.
Vivriti evaluated alternatives against clear criteria: reliability, scalability, and cost efficiency. After a proof of concept, the team selected Databricks as its unified platform and executed a phased migration aligned to business impact, complexity, and dependencies. Core workloads (including ~20 workflows and 50+ pipelines) migrated within eight weeks, with development and client validation running in parallel to compress the timeline. Following final validation after the two-month conversion, Vivriti fully retired Redshift and its in-house platform.
“It was a fast, predictable, and well-orchestrated journey,” said Alagu Bala Kumar Narayanan, VP of Architecture and R&D.
Consolidating analytics on Databricks SQL for performance and governance
Post-migration, Databricks SQL became Vivriti’s primary engine for analytics and reporting across credit, finance, and operations. Reports that previously ran directly on transactional application databases were moved to Databricks SQL, separating analytical workloads from transaction processing.
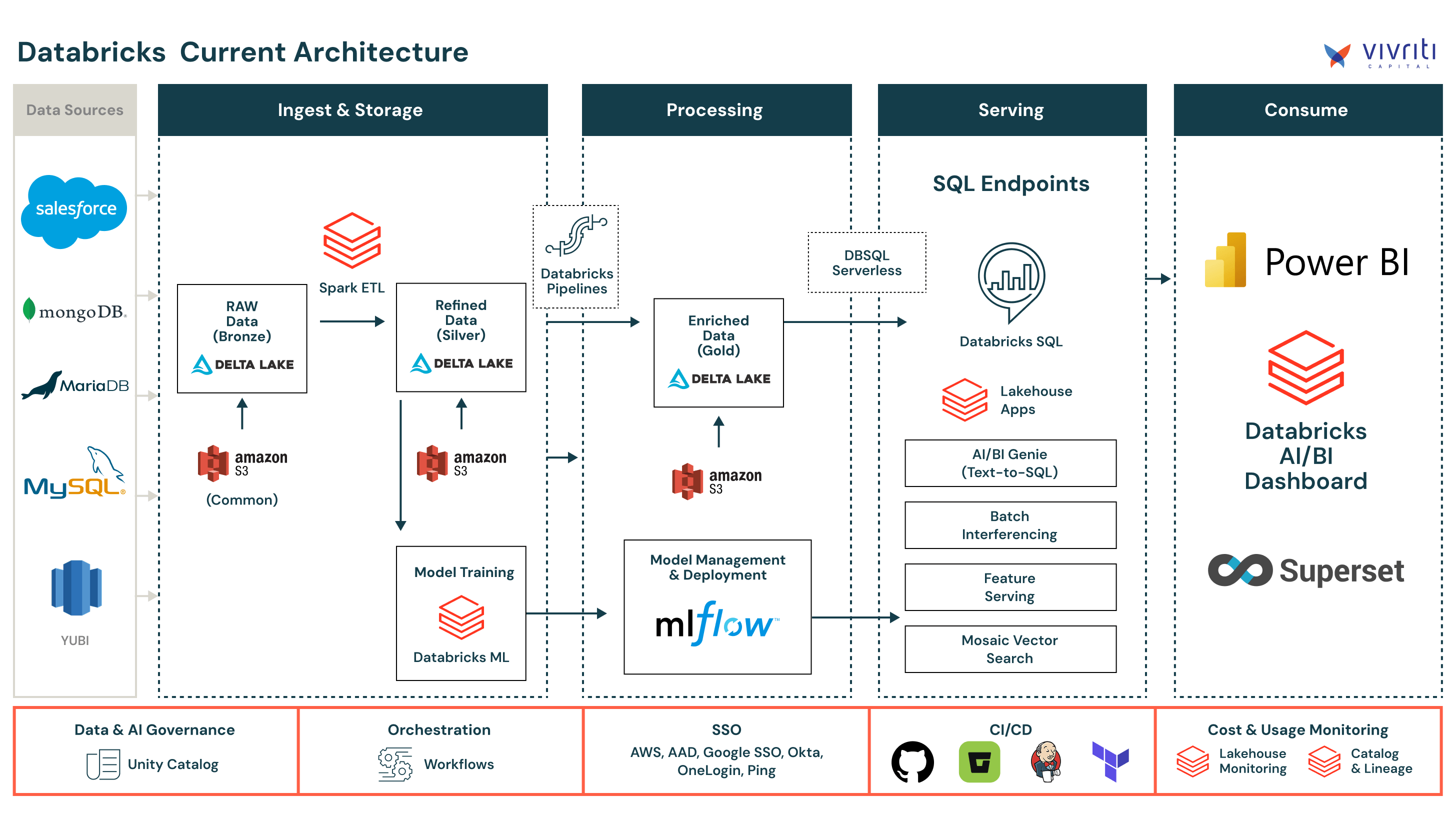
This shift reduced pressure on lending systems while improving reporting consistency and performance. Offloading analytics to Databricks SQL supported stability across high-volume transaction flows and gave analysts a scalable SQL environment for complex queries. The architecture now supports tens of thousands of loan transactions per day, with headroom to scale as new partners, products, and regions are added.
Strengthening auditability, lineage, and regulatory confidence
In a lending environment governed by RBI and SEBI, auditability is non-negotiable. On Databricks, Vivriti standardized pipelines on governed lakehouse tables, enabling built-in lineage and time travel without custom controls.
Time travel plays a critical role in regulatory and bureau reporting, allowing teams to reconstruct historical snapshots during audits or compliance reviews.
By eliminating self-managed infrastructure, Databricks also reduced failure rates and operational overhead. Engineering teams no longer manage nodes, patch open-source vulnerabilities, or troubleshoot orchestration issues under time pressure — improving turnaround times for regulatory deliverables.
Enabling faster underwriting decisions and AI-assisted analytics at scale
With a strong analytics foundation in place, Vivriti is looking to real-time decisioning and AI-driven insights. Databricks supports API-based ingestion of partner data for automated credit checks, fraud detection, and borrower de-duplication within strict latency requirements.
Vivriti also uses Databricks Genie for semantic search and conversational analytics, replacing an in-house text-to-SQL solution built on large language models. By adopting a native capability, the team reduced infrastructure complexity and avoided additional spend. “I don’t need to re-build capabilities,” Narayanan said. “Databricks already solved these problems, so I can focus on business functionality.”
Operational teams also engage more directly with data. With Databricks SQL–powered reports, non-technical teams can deliver management, bureau, and regulatory reporting faster — helping identify credit trends, operational issues, and portfolio risks earlier in the decision cycle.
Simultaneously, Vivriti has seen total cost of ownership improvements of ~25-30% between platform and contract consolidation, reduced cloud and DevOps overhead, and improved engineering productivity.
For Vivriti Capital, migrating to Databricks SQL was not just a data modernization project. It was a strategic investment in credit risk management, regulatory confidence, and operational resilience, ensuring the business can scale lending volumes, meet supervisory requirements, and prepare for AI-driven underwriting without compromising uptime or trust.