Was ist Retrieval-Augmented Generation (RAG)?
Eine Methode zur Verbesserung von LLM-Antworten, bei der vor der Generierung relevante Informationen aus externen Wissensdatenbanken abgerufen werden, um faktenbasierte Ergebnisse zu liefern.
- Retrieval-Augmented Generation ist ein AI-Muster, das die Antworten von Large Language Models verbessert, indem es zuerst relevante Dokumente aus externen Datenquellen abruft und diesen Kontext dann an das Modell weitergibt.
- RAG hilft dabei, Halluzinationen zu reduzieren, Antworten aktuell zu halten und die Ergebnisse an die eigenen Inhalte eines Unternehmens anzupassen, ohne das zugrunde liegende Modell neu trainieren zu müssen.
- Zu den häufigen RAG-Anwendungsfällen gehören Chatbots für den Kundensupport, die interne Wissenssuche und erweiterte Suchfunktionen, die Fragen direkt auf der Grundlage von Unternehmensdokumenten beantworten.
Was ist Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) ist ein hybrides AI-Framework, das Large Language Models (LLMs) durch die Kombination mit externen, aktuellen Datenquellen optimiert. Anstatt sich ausschließlich auf statische Trainingsdaten zu verlassen, ruft RAG bei einer Abfrage relevante Dokumente ab und stellt sie dem Modell als Kontext zur Verfügung. Durch die Einbindung neuer und kontextbezogener Daten kann die AI präzisere, aktuellere und domänenspezifische Antworten generieren.
RAG entwickelt sich schnell zur Standardarchitektur für die Erstellung von AI-Anwendungen auf Unternehmensebene. Jüngsten Umfragen zufolge entwickeln über 60 % der Unternehmen AI-gestützte Retrieval-Tools, um die Zuverlässigkeit zu verbessern, Halluzinationen zu reduzieren und Ergebnisse mithilfe interner Daten zu personalisieren.
Da generative AI zunehmend in Geschäftsbereichen wie dem Kundenservice, dem internen Wissensmanagement und der Compliance Einzug hält, macht die Fähigkeit von RAG, die Lücke zwischen allgemeiner AI und spezifischem Unternehmenswissen zu schließen, diese Technologie zu einer unverzichtbaren Grundlage für vertrauenswürdige Praxiseinsätze.
Wie RAG funktioniert
RAG verbessert die Ausgabe eines Sprachmodells, indem es diese mit kontextbezogenen und Echtzeit-Informationen anreichert, die aus einer externen Datenquelle abgerufen werden. Wenn ein Benutzer eine Anfrage stellt, spricht das System zuerst das Retrieval-Modell an. Dieses nutzt eine Vektordatenbank, um semantisch ähnliche Dokumente, Datenbanken oder andere Quellen nach relevanten Informationen zu durchsuchen und diese abzurufen („retrieve“). Sobald diese identifiziert sind, kombiniert das System die Ergebnisse mit dem ursprünglichen Prompt und sendet sie an ein generatives AI-Modell, das die neuen Informationen in seine Antwort einarbeitet.
Dadurch kann das LLM präzisere, kontextbezogene Antworten liefern, die auf unternehmensspezifischen oder aktuellen Daten basieren, anstatt sich lediglich auf das Modell zu verlassen, mit dem es trainiert wurde.
RAG-Pipelines umfassen in der Regel vier Schritte: Dokumentenvorbereitung und Chunking, Vektorindizierung, Retrieval (Abruf) und Prompt-Augmentierung (Erweiterung). Dieser Prozessablauf hilft Entwicklern, Datenquellen zu aktualisieren, ohne das Modell neu trainieren zu müssen. Dies macht RAG zu einer skalierbaren und kosteneffizienten Lösung für die Erstellung von LLM-Anwendungen in Bereichen wie Kundensupport, Wissensdatenbanken und interner Suche.
Welche Herausforderungen löst der Retrieval Augmented Generation-Ansatz?
Problem 1: LLM-Modelle kennen Ihre Daten nicht
LLMs nutzen Deep-Learning-Modelle und werden auf riesigen Datensätzen trainiert, um neue Inhalte zu verstehen, zusammenzufassen und zu generieren. Die meisten LLMs werden mit einer breiten Palette öffentlicher Daten trainiert, sodass ein einziges Modell auf viele Arten von Aufgaben oder Fragen reagieren kann. Nach dem Training haben viele LLMs keine Möglichkeit mehr, auf Daten zuzugreifen, die nach dem Redaktionsschluss ihrer Trainingsdaten (Cutoff-Date) liegen. Dies macht LLMs statisch und kann dazu führen, dass sie falsch antworten, veraltete Informationen liefern oder halluzinieren, wenn ihnen Fragen zu Daten gestellt werden, auf denen sie nicht trainiert wurden.
Problem 2: AI-Anwendungen müssen eigene Daten nutzen, um effektiv zu sein
Damit LLMs relevante und spezifische Antworten geben können, müssen Unternehmen sicherstellen, dass das Modell ihre Domäne versteht und Antworten auf Basis ihrer eigenen Daten liefert, anstatt allgemeine Antworten zu geben. Beispielsweise entwickeln Unternehmen Kundensupport-Bots mit LLMs, und diese Lösungen müssen unternehmensspezifische Antworten auf Kundenfragen liefern. Andere entwickeln interne Q&A-Bots, die Fragen von Mitarbeitern zu internen HR-Daten beantworten sollen. Wie können Unternehmen solche Lösungen entwickeln, ohne diese Modelle neu trainieren zu müssen?
Lösung: Retrieval Augmentation ist mittlerweile ein Branchenstandard
Eine einfache und beliebte Methode zur Nutzung eigener Daten besteht darin, diese als Teil des Prompts bereitzustellen, mit dem Sie das LLM-Modell abfragen. Dies wird als Retrieval Augmented Generation (RAG) bezeichnet, da Sie die relevanten Daten abrufen und als erweiterten Kontext für das LLM verwenden. Anstatt sich ausschließlich auf das aus den Trainingsdaten abgeleitete Wissen zu verlassen, ruft ein RAG-Workflow relevante Informationen ab und verbindet statische LLMs mit dem Datenabruf in Echtzeit.
Mit der RAG-Architektur können Unternehmen jedes beliebige LLM-Modell bereitstellen und es so erweitern, dass es relevante Ergebnisse für ihr Unternehmen liefert, indem sie ihm eine kleine Menge ihrer Daten zur Verfügung stellen – ohne die Kosten und den Zeitaufwand für das Fine-Tuning oder Vortrainieren des Modells.
Was sind die Anwendungsfälle für RAG?
Es gibt viele verschiedene Anwendungsfälle für RAG. Die häufigsten sind:
Frage-Antwort-Chatbots: Durch die Integration von LLMs in Chatbots können diese automatisch präzisere Antworten aus Unternehmensdokumenten und Wissensdatenbanken ableiten. Chatbots werden eingesetzt, um den Kundensupport und das Nachfassen von Website-Leads zu automatisieren, um Fragen schnell zu beantworten und Probleme rasch zu lösen.
Beispielsweise wollte Experian, ein multinationaler Datenvermittler und Kreditauskunftei, einen Chatbot für interne und kundenorientierte Anforderungen entwickeln. Sie stellten schnell fest, dass ihre aktuellen Chatbot-Technologien Schwierigkeiten hatten, mit der Nachfrage zu skalieren. Durch den Aufbau ihres GenAI-Chatbots – Latte – auf der Databricks Data Intelligence Platform war Experian in der Lage, die Prompt-Verarbeitung und die Modellgenauigkeit zu verbessern. Dies gab ihren Teams mehr Flexibilität, um mit verschiedenen Prompts zu experimentieren, Ergebnisse zu verfeinern und sich schnell an die Weiterentwicklung der GenAI-Technologie anzupassen.
- Sucherweiterung: Die Integration von LLMs in Suchmaschinen, die Suchergebnisse mit LLM-generierten Antworten anreichern, kann Informationsanfragen besser beantworten und es Benutzern erleichtern, die für ihre Arbeit benötigten Informationen zu finden.
Knowledge Engine: Fragen zu Ihren Daten stellen (z. B. HR- oder Compliance-Dokumente): Unternehmensdaten können als Kontext für LLMs verwendet werden, sodass Mitarbeiter problemlos Antworten auf ihre Fragen erhalten, einschließlich HR-Fragen zu Zusatzleistungen und Richtlinien sowie Sicherheits- und Compliance-Fragen.
Ein Beispiel für diesen Einsatz ist Cycle & Carriage, ein führender Automobilkonzern in Südostasien. Sie wandten sich an Databricks, um einen RAG-Chatbot zu entwickeln, der die Produktivität und das Kundenengagement verbessert, indem er auf ihre proprietären Wissensdatenbanken wie technische Handbücher, Kundensupport-Transkripte und Geschäftsprozessdokumente zugreift. Dies erleichterte es den Mitarbeitern, Informationen über Suchanfragen in natürlicher Sprache zu suchen, die kontextbezogene Antworten in Echtzeit liefern.
Was sind die Vorteile von RAG?
Der RAG-Ansatz bietet eine Reihe von entscheidenden Vorteilen, darunter:
- Bereitstellung aktueller und präziser Antworten: RAG stellt sicher, dass die Antwort eines LLM nicht ausschließlich auf statischen, veralteten Trainingsdaten basiert. Stattdessen nutzt das Modell aktuelle externe Datenquellen, um Antworten zu liefern.
- Reduzierung ungenauer Antworten oder Halluzinationen: Durch die Fundierung der LLM-Modellausgabe auf relevantem, externem Wissen versucht RAG, das Risiko von Antworten mit falschen oder erfundenen Informationen (auch bekannt als Halluzinationen) zu minimieren. Die Ausgaben können Zitate von Originalquellen enthalten, was eine menschliche Überprüfung ermöglicht.
- Bereitstellung domänenspezifischer, relevanter Antworten: Mithilfe von RAG kann das LLM kontextbezogene Antworten liefern, die auf die proprietären oder domänenspezifischen Daten eines Unternehmens zugeschnitten sind.
- Effizienz und Kosteneffizienz: Im Vergleich zu anderen Ansätzen zur Anpassung von LLMs an domänenspezifische Daten ist RAG einfach und kosteneffizient. Unternehmen können RAG implementieren, ohne das Modell anpassen zu müssen. Dies ist besonders vorteilhaft, wenn Modelle häufig mit neuen Daten aktualisiert werden müssen.
Wann sollte ich RAG verwenden und wann das Modell einem Fine-Tuning unterziehen?
RAG ist der richtige Ausgangspunkt, da es einfach und für einige Anwendungsfälle möglicherweise völlig ausreichend ist. Ein Fine-Tuning ist in anderen Situationen am besten geeignet, wenn man das Verhalten des LLM ändern oder eine andere „Sprache“ erlernen möchte. Diese Ansätze schließen sich nicht gegenseitig aus. Als zukünftiger Schritt kann ein Fine-Tuning des Modells in Betracht gezogen werden, damit es die Domänensprache und das gewünschte Ausgabeformat besser versteht – während gleichzeitig RAG genutzt wird, um die Qualität und Relevanz der Antwort zu verbessern.
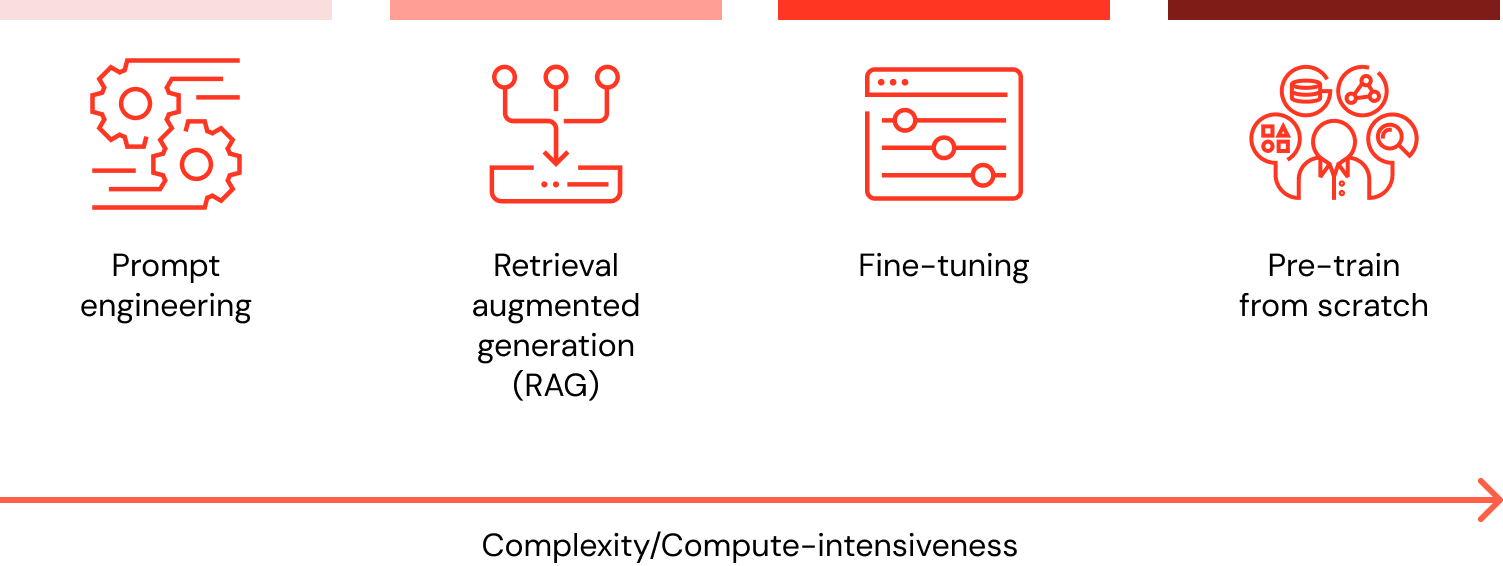
Wenn ich mein LLM mit Daten anpassen möchte, welche Optionen gibt es und welche Methode ist die beste (Prompt Engineering vs. RAG vs. Fine-Tuning vs. Pre-Training)?
Es gibt vier Architekturmuster, die bei der Anpassung einer LLM-Anwendung an die Daten Ihres Unternehmens zu berücksichtigen sind. Diese Techniken sind im Folgenden beschrieben und schließen sich nicht gegenseitig aus. Vielmehr können (und sollten) sie kombiniert werden, um die jeweiligen Stärken optimal zu nutzen.
| Methode | Definition | Hauptanwendungsfall | Datenanforderungen | Vorteile | Überlegungen |
|---|---|---|---|---|---|
Prompt-Engineering | Erstellung spezialisierter Prompts zur Steuerung des LLM-Verhaltens | Schnelle, spontane Modellsteuerung | Keine | Schnell, kostengünstig, kein Training erforderlich | Weniger Kontrolle als beim Fine-Tuning |
Retrieval-Augmented Generation (RAG) | Kombination eines LLM mit externem Wissensabruf | Dynamische Datensätze und externes Wissen | Externe Wissensdatenbank oder Datenbank (z. B. Vektordatenbank) | Dynamisch aktualisierter Kontext, verbesserte Genauigkeit | Erhöht die Prompt-Länge und den Rechenaufwand bei der Inferenz |
Fine-Tuning | Anpassung eines vortrainierten LLM an spezifische Datensätze oder Domänen | Spezialisierung auf Domänen oder Aufgaben | Tausende domänenspezifische oder instruktionsbasierte Beispiele | Granulare Kontrolle, hohe Spezialisierung | Erfordert gelabelte Daten, Rechenaufwand |
Vortraining | Training eines LLM von Grund auf | Einzigartige Aufgaben oder domänenspezifische Unternehmen | Große Datensätze (Milliarden bis Billionen von Token) | Maximale Kontrolle, maßgeschneidert für spezifische Anforderungen | Extrem ressourcenintensiv |

Unabhängig von der gewählten Methode stellt die Entwicklung einer gut strukturierten, modularisierten Lösung sicher, dass Unternehmen für Iterationen und Anpassungen gerüstet sind. Erfahren Sie mehr über diesen Ansatz und vieles mehr in The Big Book of MLOps.
Häufige Herausforderungen bei der RAG-Implementierung
Die Implementierung von RAG in großem Maßstab bringt verschiedene technische und betriebliche Herausforderungen mit sich.
- Retrieval-Qualität. Selbst die leistungsstärksten LLMs können schlechte Antworten generieren, wenn sie irrelevante oder qualitativ minderwertige Dokumente abrufen. Daher ist es von entscheidender Bedeutung, eine effektive Retrieval-Pipeline zu entwickeln, die eine sorgfältige Auswahl von Embedding-Modellen, Ähnlichkeitsmetriken und Ranking-Strategien umfasst.
- Einschränkungen des Kontextfensters. Da dem Modell theoretisch die gesamte Dokumentation der Welt zur Verfügung steht, besteht das Risiko, dass zu viele Inhalte in das Modell eingespeist werden, was zu abgeschnittenen Quellen oder ungenauen Antworten führt. Chunking-Strategien sollten die semantische Kohärenz gegen die Token-Effizienz abwägen.
- Datenaktualität. Der Vorteil von RAG liegt in der Fähigkeit, aktuelle Informationen heranzuziehen. Dokumentenindizes können jedoch ohne geplante Ingestion-Jobs oder automatisierte Updates schnell veralten. Indem Sie sicherstellen, dass Ihre Daten aktuell sind, können Sie Halluzinationen oder veraltete Antworten vermeiden.
- Latenz. Beim Umgang mit großen Datensätzen oder externen APIs kann die Latenz den Abruf, das Ranking und die Generierung beeinträchtigen.
- RAG-Evaluierung. Aufgrund des hybriden Charakters von RAG greifen traditionelle KI-Evaluierungsmodelle zu kurz. Die Bewertung der Genauigkeit von Ausgaben erfordert eine Kombination aus menschlichem Urteilsvermögen, Relevanzbewertung und Groundedness-Prüfungen, um die Antwortqualität zu beurteilen.
Was ist eine Referenzarchitektur für RAG-Anwendungen?
Es gibt viele Möglichkeiten, ein Retrieval-Augmented-Generation-System zu implementieren, je nach den spezifischen Anforderungen und Datennuancen. Im Folgenden finden Sie einen häufig verwendeten Workflow, der ein grundlegendes Verständnis des Prozesses vermittelt.
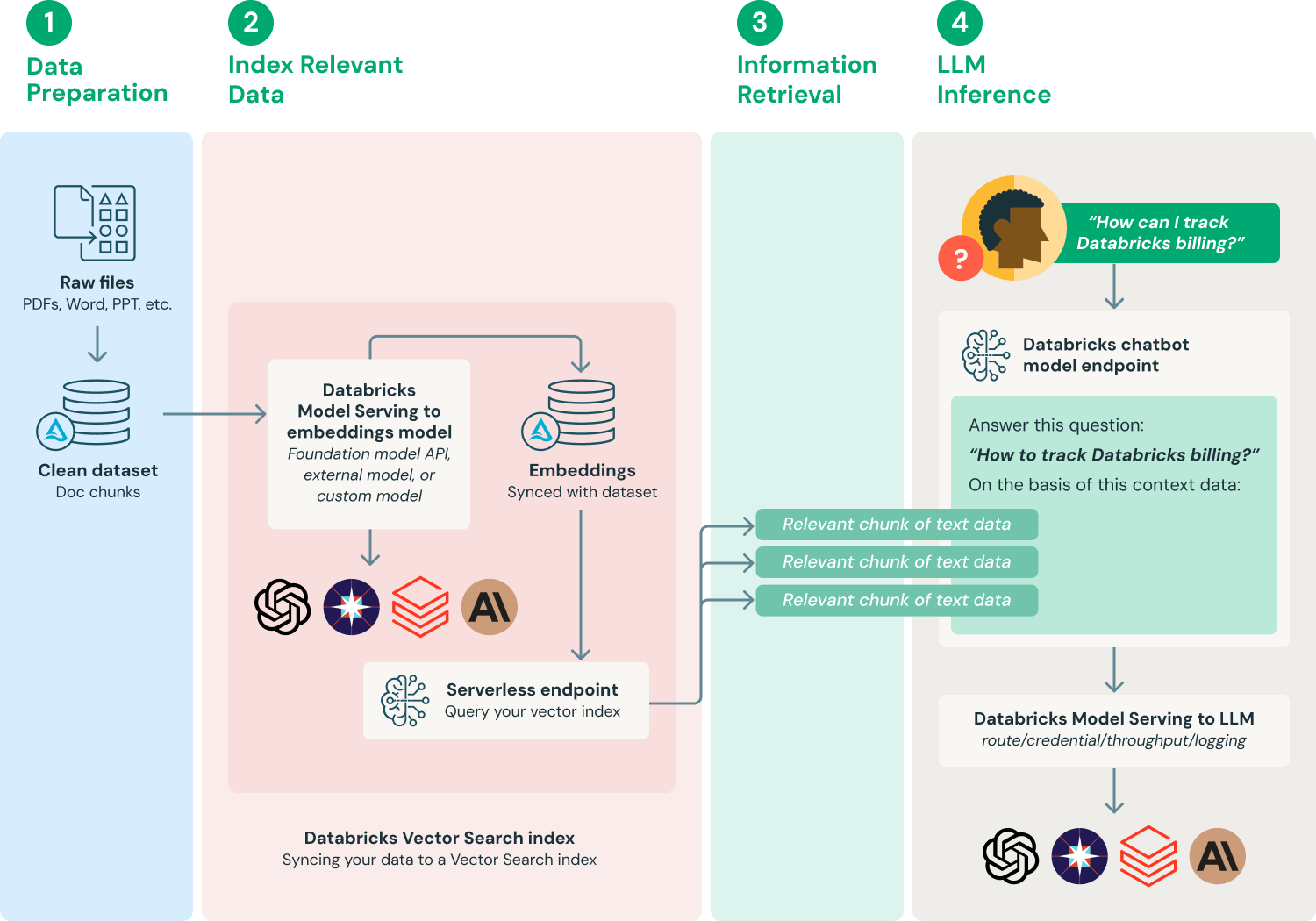
- Daten vorbereiten: Dokumentdaten werden zusammen mit Metadaten erfasst und einer ersten Vorverarbeitung unterzogen – beispielsweise der Verarbeitung von PII (Erkennung, Filterung, Schwärzung, Ersetzung). Für die Verwendung in RAG-Anwendungen müssen Dokumente basierend auf der Wahl des Embedding-Modells und der nachgelagerten LLM-Anwendung, die diese Dokumente als Kontext verwendet, in geeignete Längen aufgeteilt (gechunkt) werden.
- Relevante Daten indexieren: Erstellen Sie Dokument-Embeddings und befüllen Sie einen AI Search-Index mit diesen Daten.
- Relevante Daten abrufen: Abrufen von Teilen Ihrer Daten, die für die Anfrage eines Benutzers relevant sind. Diese Textdaten werden dann als Teil des Prompts bereitgestellt, der für das LLM verwendet wird.
- LLM-Anwendungen erstellen: Kapseln Sie die Komponenten der Prompt-Erweiterung und der LLM-Abfrage in einem Endpunkt. Dieser Endpunkt kann dann über eine einfache REST-API für Anwendungen wie Q&A-Chatbots bereitgestellt werden.
Databricks empfiehlt außerdem einige wichtige Architekturelemente einer RAG-Architektur:
- Vektordatenbank: Einige (aber nicht alle) LLM-Anwendungen verwenden Vektordatenbanken für schnelle Ähnlichkeitssuchen, meist um Kontext oder Domänenwissen in LLM-Abfragen bereitzustellen. Um sicherzustellen, dass das bereitgestellte Sprachmodell Zugriff auf aktuelle Informationen hat, können regelmäßige Aktualisierungen der Vektordatenbank als Job geplant werden. Beachten Sie dass die Logik zum Abrufen aus der Vektordatenbank und zum Einfügen von Informationen in den LLM-Kontext in dem in MLflow protokollierten Modellartefakt unter Verwendung der MLflow-Modell-Flavors LangChain oder PyFunc verpackt werden kann.
- MLflow LLM Deployments oder Model Serving: In LLM-basierten Anwendungen, in denen eine LLM-API von Drittanbietern verwendet wird, kann die Unterstützung von MLflow LLM Deployments oder Model Serving für externe Modelle als standardisierte Schnittstelle verwendet werden, um Anfragen von Anbietern wie OpenAI und Anthropic weiterzuleiten. Zusätzlich zur Bereitstellung eines API-Gateways der Enterprise-Klasse zentralisiert MLflow LLM Deployments oder Model Serving die Verwaltung von API-Schlüsseln und bietet die Möglichkeit, Kostenkontrollen durchzusetzen.
- Model Serving: Im Fall von RAG unter Verwendung einer Drittanbieter-API besteht eine wesentliche architektonische Änderung darin, dass die LLM-Pipeline externe API-Aufrufe vom Model Serving-Endpunkt an interne oder externe LLM-APIs von Drittanbietern richtet. Es ist zu beachten, dass dies zusätzliche Komplexität, potenzielle Latenzzeiten und eine weitere Ebene für die Verwaltung von Anmeldedaten mit sich bringt. Im Gegensatz dazu werden im Beispiel des feinabgestimmten Modells das Modell und seine Modellumgebung bereitgestellt.
Ressourcen
- Databricks-Blogposts
- Databricks-Demo
- Databricks-E-Book — The Big Book of MLOps
Databricks-Kunden, die RAG nutzen
JetBlue
JetBlue hat „BlueBot“ eingeführt, einen Chatbot, der auf Open-Source-Modellen für generative AI basiert, durch Unternehmensdaten ergänzt wird und von Databricks unterstützt wird. Dieser Chatbot kann von allen Teams bei JetBlue genutzt werden, um auf Daten zuzugreifen, die durch Rollen gesteuert werden. Beispielsweise kann das Finanzteam Daten aus SAP und behördlichen Einreichungen einsehen, während das Betriebsteam nur Wartungsinformationen sieht.
Lesen Sie auch diesen Artikel.
Chevron Phillips
Chevron Phillips Chemical nutzt Databricks zur Unterstützung seiner Initiativen im Bereich der generativen AI, einschließlich der Automatisierung von Dokumentenprozessen.
Thrivent Financial
Thrivent Financial untersucht generative AI, um die Suche zu verbessern, besser zusammengefasste und zugänglichere Erkenntnisse zu gewinnen und die Produktivität im Engineering zu steigern.
Wo finde ich weitere Informationen zu Retrieval Augmented Generation?
Es stehen viele Ressourcen zur Verfügung, um weitere Informationen über RAG zu erhalten, darunter:
Blogs
- Erstellung hochwertiger RAG-Anwendungen mit Databricks
- Databricks AI Search Public Preview
- Verbesserung der Antwortqualität von RAG-Anwendungen mit strukturierten Echtzeitdaten
- Schnellere Erstellung von GenAI-Apps mit neuen Foundation-Model-Funktionen
- Best Practices für die LLM-Evaluierung von RAG-Anwendungen
- Nutzung von MLflow AI Gateway und Llama 2 zur Erstellung generativer AI-Apps (Erzielen Sie eine höhere Genauigkeit durch den Einsatz von Retrieval Augmented Generation (RAG) mit Ihren eigenen Daten)
E-Books
Demos
Kontaktieren Sie Databricks, um eine Demo zu vereinbaren und mit uns über Ihre LLM- und Retrieval Augmented Generation (RAG)-Projekte zu sprechen
Das Playbook für agentenbasierte KI für Unternehmen

Die Zukunft der RAG-Technologie
RAG entwickelt sich rasant von einer provisorischen Behelfslösung zu einer grundlegenden Komponente der AI-Architektur in Unternehmen. Da LLMs immer leistungsfähiger werden, verändert sich auch die Rolle von RAG. Sie entwickelt sich von der bloßen Schließung von Wissenslücken hin zu Systemen, die strukturiert, modular und intelligenter sind.
Ein Weg, wie sich RAG weiterentwickelt, sind hybride Architekturen, bei denen RAG mit Tools, strukturierten Datenbanken und Agenten für Funktionsaufrufe kombiniert wird. In diesen Systemen sorgt RAG für eine unstrukturierte Fundierung, während strukturierte Daten oder APIs präzisere Aufgaben übernehmen. Diese multimodalen Architekturen bieten Unternehmen eine zuverlässigere End-to-End-Automatisierung.
Eine weitere wichtige Entwicklung ist das gemeinsame Training von Retriever und Generator (Retriever-Generator Co-Training). Dies ist ein Modell, bei dem der RAG-Retriever und der Generator gemeinsam trainiert werden, um die Antwortqualität des jeweils anderen zu optimieren. Dies kann den Bedarf an manuellem Prompt Engineering oder Fine-Tuning verringern und führt zu Aspekten wie adaptivem Lernen, weniger Halluzinationen und einer besseren Gesamtleistung von Retrievern und Generatoren.
Mit zunehmender Reife der LLM-Architekturen wird RAG voraussichtlich nahtloser und kontextbezogener werden. Diese neuen Systeme gehen über begrenzte Speicher- und Informationsbestände hinaus und werden in der Lage sein, Echtzeit-Datenströme, dokumentenübergreifende logische Schlussfolgerungen und persistenten Speicher zu verarbeiten, was sie zu sachkundigen und vertrauenswürdigen Assistenten macht.
Häufig gestellte Fragen (FAQ)
Was ist Retrieval Augmented Generation (RAG)?
RAG ist eine AI-Architektur, die LLMs stärkt, indem sie relevante Dokumente abruft und in den Prompt einfügt. Dies ermöglicht präzisere, aktuellere und domänenspezifische Antworten, ohne dass Zeit für das erneute Trainieren des Modells aufgewendet werden muss.
Wann sollte ich RAG anstelle von Fine-Tuning verwenden?
Verwenden Sie RAG, wenn Sie dynamische Daten einbinden möchten, ohne die Kosten oder die Komplexität von Fine-Tuning in Kauf nehmen zu müssen. Es ist ideal für Anwendungsfälle, in denen präzise und aktuelle Informationen erforderlich sind.
Reduziert RAG Halluzinationen bei LLMs?
Ja. Indem die Antwort des Modells auf abgerufenen, aktuellen Inhalten basiert, verringert RAG die Wahrscheinlichkeit von Halluzinationen. Dies gilt insbesondere für Bereiche, die eine hohe Genauigkeit erfordern, wie das Gesundheitswesen, juristische Arbeiten oder den Support in Unternehmen.
Welche Art von Daten benötigt RAG?
RAG verwendet unstrukturierte Textdaten – wie PDFs, E-Mails und interne Dokumente –, die in einem abrufbaren Format gespeichert sind. Diese werden in der Regel in einer Vektordatenbank gespeichert, und die Daten müssen indexiert und regelmäßig aktualisiert werden, um ihre Relevanz zu behalten.
Wie bewertet man ein RAG-System?
RAG-Systeme werden mithilfe einer Kombination aus Relevanzbewertung, Groundedness-Prüfungen, menschlichen Bewertungen und aufgabenspezifischen Leistungskennzahlen evaluiert. Aber wie wir gesehen haben, könnten die Möglichkeiten des gemeinsamen Trainings von Retriever und Generator die regelmäßige Evaluierung erleichtern, da die Modelle voneinander lernen und sich gegenseitig trainieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.