Neues auf der AI-Plattform: Agenten für ML-Engineering, unsere Deep-Learning-Plattform und neue Funktionen für Echtzeit-ML
Nutzen Sie Genie Code, um den gesamten ML-Lifecycle zu beschleunigen, AI Runtime, um Deep-Learning-Modelle im großen Maßstab zu trainieren, und Feature und Model Serving, um Echtzeit-ML im großen Maßstab zu betreiben.
von Tejas Sundaresan und Mike Del Balso
- Erstellen Sie ML-Systeme schneller mit Genie Code, einem Coding-Agenten, der Data Scientists und ML-Engineers bei der Entwicklung, Evaluierung und Verbesserung traditioneller Machine-Learning-Systeme unterstützt.
- Trainieren und feintunen Sie AI-Modelle auf serverlosen GPUs mit AI Runtime, einer vereinheitlichten Deep-Learning-Plattform, die für GPU-Training und Experimente im großen Maßstab optimiert ist.
- Betreiben Sie Echtzeit-ML im großen Maßstab mit neuen Feature Store- und Model Serving-Funktionen, einschließlich Streaming-Features und High-QPS-Serving für die anspruchsvollsten Produktions-Workloads.
Es gab noch nie eine dynamischere und aufregendere Zeit, um eigene AI-Modelle und -Systeme zu entwickeln. Von der Nachfrageprognose und Betrugserkennung bis hin zu Suche, Empfehlungen, Personalisierung und multimodaler AI – Machine Learning treibt geschäftskritische Anwendungen in jeder Branche an.
Auf dem Data + AI Summit 2026 freuen wir uns sehr, die folgenden neuen Funktionen in der Databricks AI Platform vorzustellen:
- Genie Code for ML: Genie Code bietet jetzt verbesserte Intelligenz für das ML-Engineering und native Integrationen über alle Komponenten der Databricks ML-Plattform hinweg: Feature Engineering, Modelltraining, Serving und Monitoring.
- AI Runtime (Public Preview): eine serverlose GPU-Trainingsumgebung, die Deep Learning auf Forschungsniveau und Fine-Tuning ohne komplexe Infrastrukturverwaltung ermöglicht.
- Verbesserte Unterstützung für Echtzeit-ML: einschließlich geringer Latenzzeit und hoher QPS-Unterstützung für unsere Feature Store- und Model Serving-Produkte.
Zusammen vereinfachen diese Funktionen den Weg vom Experimentieren bis zur Produktion und ermöglichen es Unternehmen, AI-Anwendungen erheblich schneller als je zuvor zu entwickeln, bereitzustellen und zu skalieren.
Werfen wir einen genaueren Blick auf die Neuerungen.
Genie Code für Machine Learning
Heutzutage kann es Monate dauern, ein ML-Modell in die Produktion zu bringen, da Teams unzählige Stunden mit sich wiederholenden Aufgaben im gesamten ML-Lebenszyklus verbringen – vom Feature Engineering und der Experimentverwaltung bis hin zur Modellbewertung und Bereitstellung. Doch Agenten haben die Arbeitsweise von Engineering- und technischen Teams grundlegend verändert. Aus diesem Grund freuen wir uns, dieses Jahr auf dem DAIS die Unterstützung von Genie Code für den gesamten ML-Lebenszyklus anzukündigen.
Die Entwicklung und der Betrieb von ML-Modellen erfordern nuancierte Entscheidungen, die generische Coding-Agenten nicht treffen können. Kann ich mich auf die Aktualität und Qualität dieses Datensatzes als Feature verlassen? Führt dieses Feature dazu, dass zukünftige Informationen in das Modell einfließen? Beginnt dieser Serving-Endpunkt zu driften? Die Details im ML-Bereich richtig hinzubekommen, erfordert tiefen Kontext, und dieser Kontext entsteht nur durch eine enge Integration mit der Daten- und ML-Plattform: Ihre Daten und deren Qualität, Feature-Lineage, Experimenthistorie, Trainingsinfrastruktur und Produktionsleistung.
Hier kommt Genie Code ins Spiel:
- Kontext zu Ihren Daten über Unity Catalog: Genie Code versteht Ihre Daten, die Geschäftssemantik und Ihr Governance-Modell. Durch die Integration mit Unity Catalog weiß es, welche Tabellen und Features eine hohe Qualität für ML aufweisen, wie Daten durch Ihre ML-Pipelines fließen und welche Zugriffskontrollen und Richtlinien eingehalten werden müssen.
- Kontext zum Databricks ML-Stack: Genie Code wurde für ML auf Databricks entwickelt und ist tief in Feature Store, Serverless Compute, AI Runtime, Model Serving und Inference Tables integriert. Es kann Trainingsjobs optimieren, Serving-Probleme diagnostizieren, Challenger-Modelle bewerten und Aktionen im gesamten ML-Stack ausführen, anstatt nur Code zu generieren, der mit ihm interagiert.
- Kontext zu Ihrem ML-Lebenszyklus und Ihren Workflows: Durch MLflow versteht Genie Code den gesamten ML-Lebenszyklus, vom Feature Engineering und Experimentieren bis hin zu Bereitstellung, Monitoring, Drift-Erkennung, Retraining und Produktionsbetrieb. Es hört nicht auf, wenn ein Modell bereitgestellt wird; es hilft sicherzustellen, dass die geschäftlichen Kennzahlen, die dieses Modell antreibt, wie CTR, Conversion oder Umsatz, in der Produktion stabil bleiben.
Und so können Ihre ML-Teams mit Genie Code schneller agieren als je zuvor.
Genie Code übernimmt das Feature Engineering so, wie es Ihr Senior ML Engineer tun würde – es lernt die bestehenden Muster Ihres Teams, verwendet bewährte Transformationen wieder und erstellt Features, die konsistent mit dem sind, was bereits in der Produktion läuft.
Genie Code schreibt nicht nur ML-Code – es trainiert und optimiert produktionsreife Modelle. Es wählt und konfiguriert automatisch die richtige Infrastruktur, sei es CPU für einfache Experimente oder GPU für verteiltes Training, und protokolliert jeden Durchlauf nativ in MLflow.
Genie Code bringt Modelle in einem einzigen Ablauf vom Notebook in die Produktion – von der Registrierung im Unity Catalog über die Bereitstellung an einem Serving-Endpunkt bis hin zur lückenlosen Einhaltung der Governance bei jedem Schritt.
Genie Code hat meine Arbeitsweise komplett verändert. Ich führe täglich mehr als 15 parallele Threads aus, die auf verschiedene Notebooks und Assets ausgerichtet sind, und all das über verschiedene Tabs hinweg zu verwalten, ist einer der größten Reibungspunkte in meinem Workflow. Eine Vollseiten-Ansicht von Genie Code mit gleichzeitigen Sitzungen würde mir eine echte Arbeitsumgebung bieten, um alles parallel auszuführen, ohne ständig den Kontext zu verlieren.—Moritz Schiek, Solution Consultant, Bosch
Mit Genie Code sind wir in 90 Minuten von Rohdaten zu einem kontrollierten, produktionsreifen ML-Workflow gelangt. Da es produktionsreife ML-Workflows auf Databricks auf einzigartige Weise versteht, hat es uns geholfen, Delta-Tabellen zu erstellen, die Daten zu untersuchen, Modelle zu trainieren und zu vergleichen, sie in MLflow und Unity Catalog zu registrieren und das Champion-Modell an einem Serving-Endpunkt bereitzustellen – und es blieb sogar noch Zeit, um das wichtigste Geschäftsergebnis zu optimieren.—Radu Dragusin, Principal Engineer, Data & AI, Danfoss
Um mehr über Genie Code zu erfahren, legen Sie bitte hier los!
Einführung von AI Runtime: Eine GPU-Plattform auf Forschungsniveau im Lakehouse
GPUs treiben die fortschrittlichsten AI-Workloads von heute an – von Prognosen und Empfehlungen bis hin zu multimodalen Foundation-Modellen. Doch Deep-Learning-Teams haben oft Mühe, GPU-Infrastruktur zu beschaffen und zu verwalten, verteilte Trainingsumgebungen zu konfigurieren und Leistungsengpässe zu beheben. Sie möchten sich lieber auf die Modellierung statt auf die Infrastruktur konzentrieren.
Im März haben wir eine Preview von AI Runtime veröffentlicht, und heute freuen wir uns, im Rahmen des Data AI Summit bekannt zu geben, dass AI Runtime jetzt hochperformantes Multinode-Training unterstützt. Mit AI Runtime haben Databricks-Benutzer nun Zugriff auf:
- Serverlose NVIDIA-GPUs auf Abruf: Konfigurieren Sie Ihr Notebook einfach mit 2–3 Klicks und binden Sie serverlose A10- und H100-GPUs schnell an, um mit dem Training zu beginnen – kein Cluster erforderlich. Zahlen Sie nur für die GPUs, die Sie tatsächlich nutzen, ohne sich Gedanken über Leerlaufzeiten, Auslastung oder Vorabverpflichtungen machen zu müssen.
- Robuste Orchestrierungstools: Nutzen Sie die volle Leistung der Orchestrierungssuite von Databricks mit Unterstützung für Lakeflow Jobs und DABs für lang laufende GPU-Workloads.
- Optimiertes verteiltes Training: AIR bündelt Leistungsverbesserungen für verteilte GPUs wie RDMA und hochperformantes Laden von Daten, um eine optimale Leistung für Ihre GPU-Workloads zu erzielen.
- Zentralisierte Governance und Observability: Führen Sie GPU-Workloads genau dort aus, überwachen und steuern Sie sie, wo sich Ihre Daten befinden – mit integrierter Experimentverwaltung über MLflow, Zugriffsverwaltung mit Unity Catalog und Genie Code-gestütztem Debugging.
Mit dieser Einführung können Databricks-Kunden nun dieselbe GPU-Plattform auf Forschungsniveau nutzen, die unser eigenes Team für das Training von Foundation-Modellen wie DBRX und KARL verwendet hat. Heute treibt AI Runtime wegweisende Workloads für Hunderte von Databricks-Kunden an und hilft dabei, modernste AI aus der Forschung in produktive Unternehmensanwendungen zu bringen.
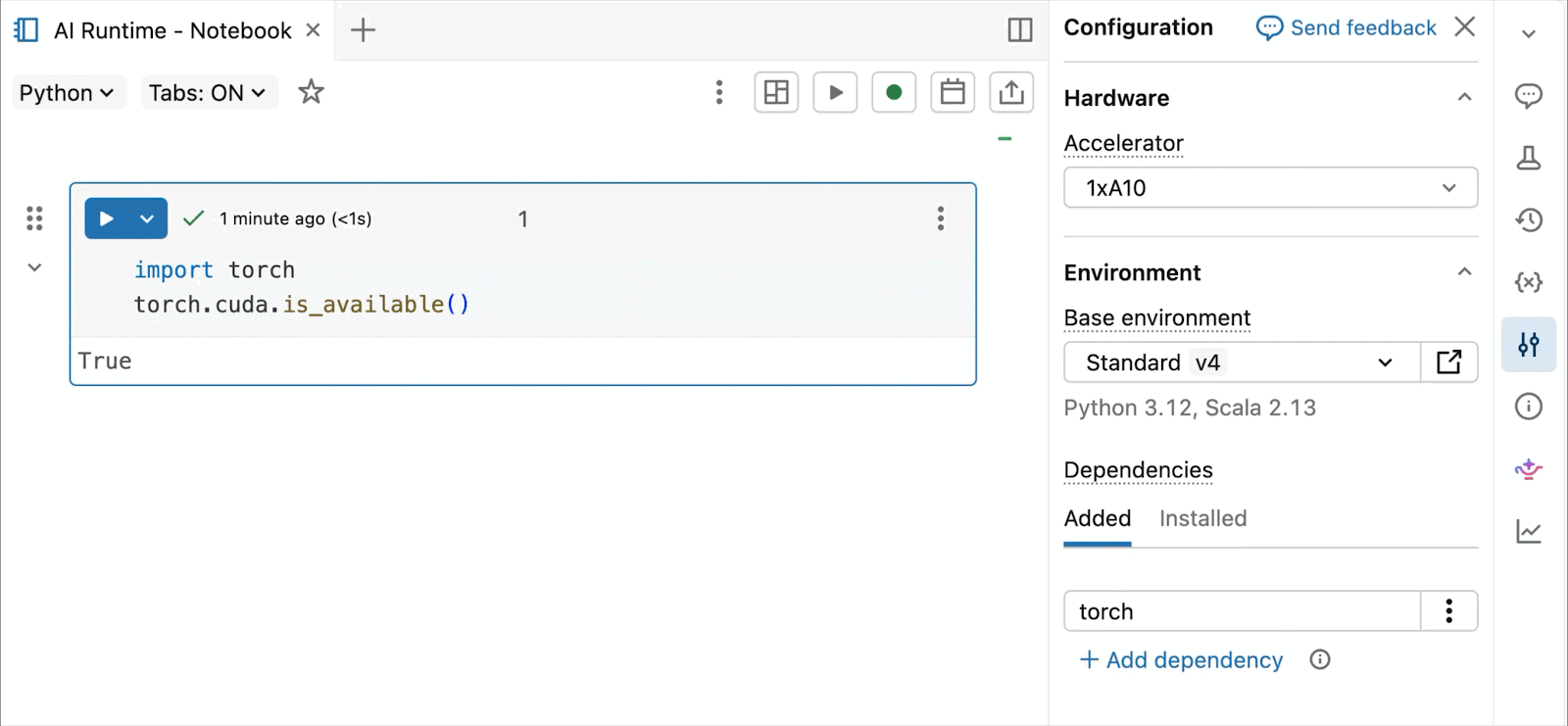
Binden Sie serverlose A10- und H100-GPUs mit 2–3 Klicks an Ihr Notebook an. Keine Clusterverwaltung erforderlich; zahlen Sie nur für das, was Sie tatsächlich nutzen.
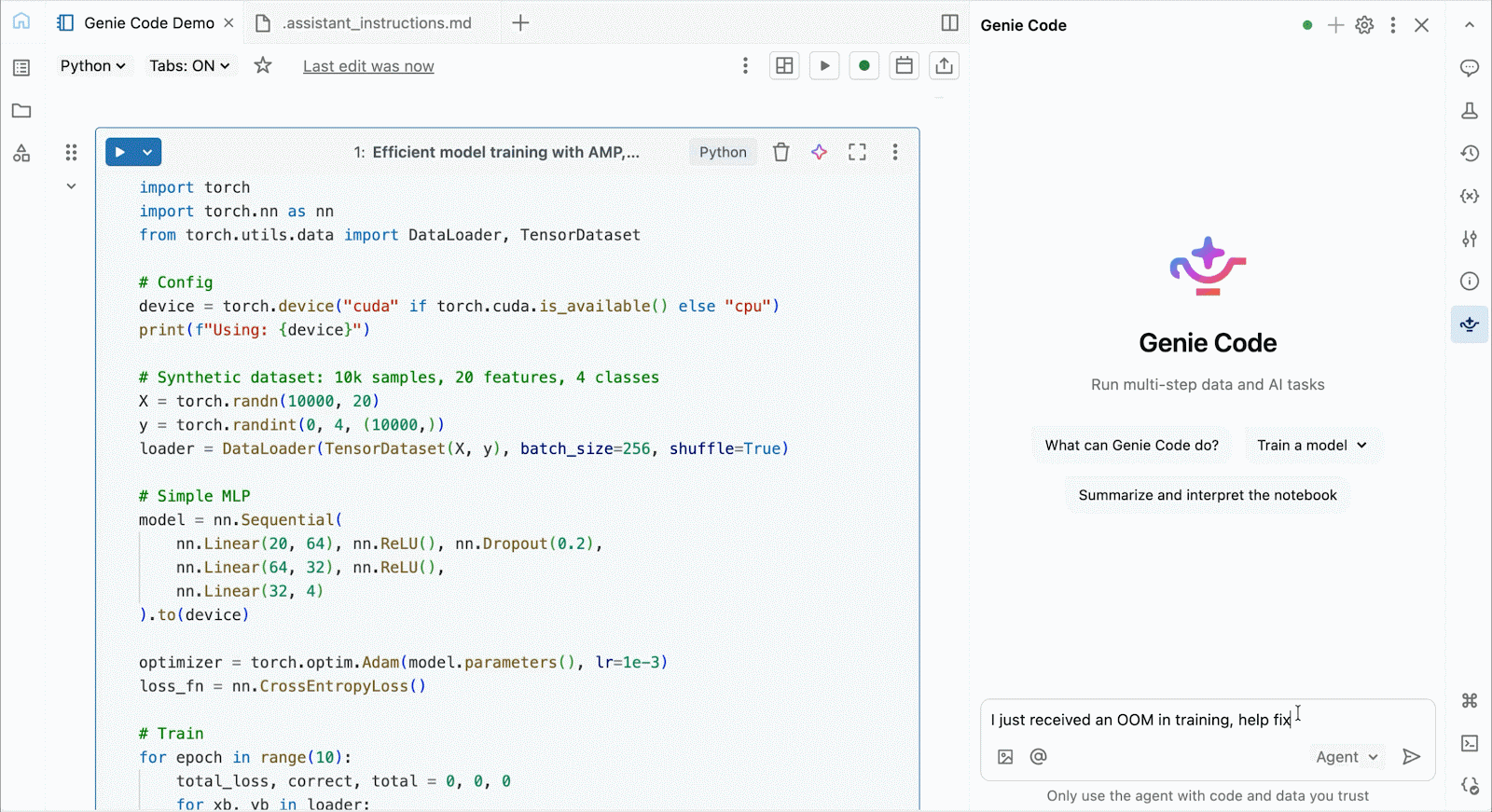
Nutzen Sie Genie Code, um Leistungsengpässe zu beheben, mit neuen Architekturen zu experimentieren oder knifflige Fehler bei der Modellkonvergenz oder kryptische Framework-Fehler zu beheben.
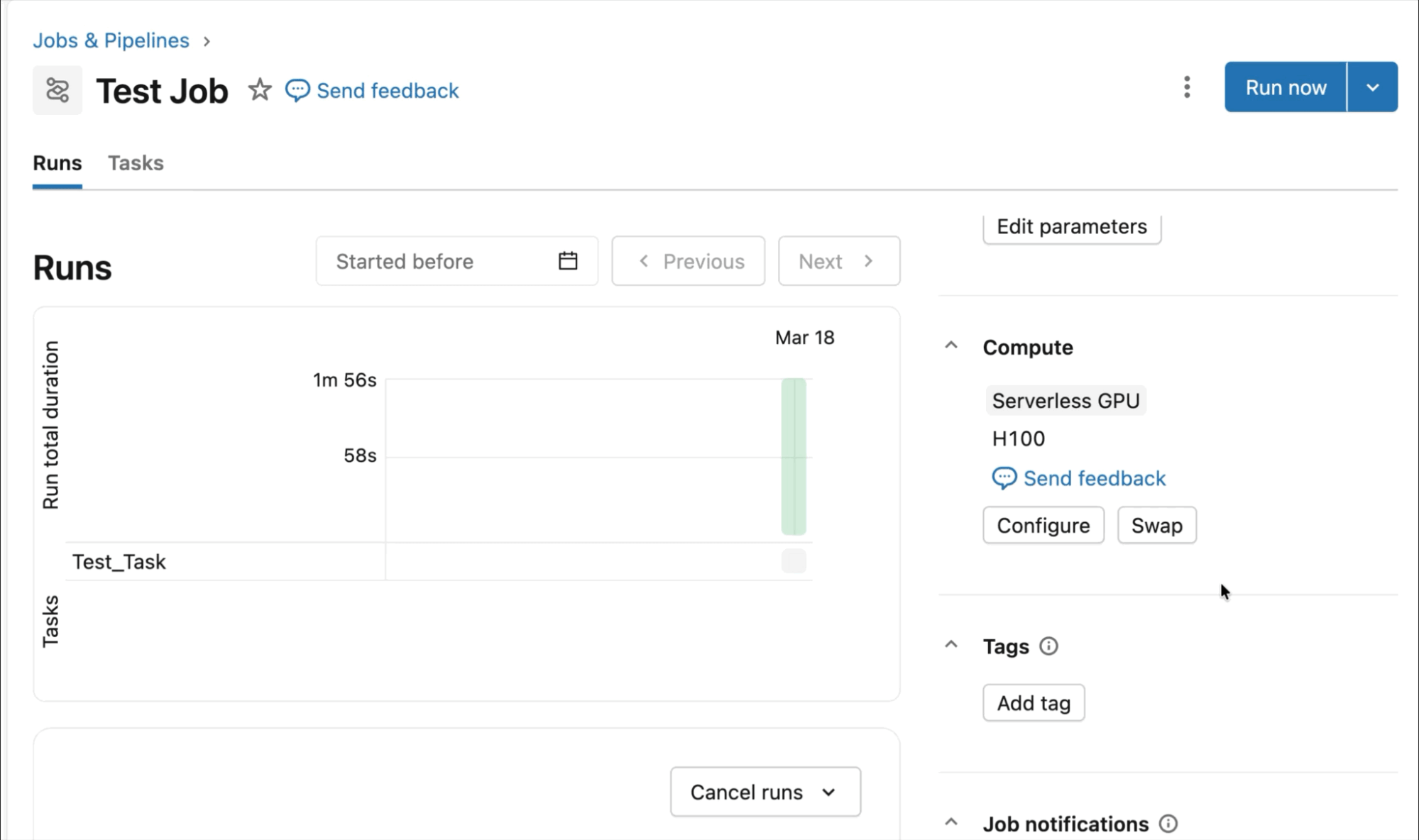
AI Runtime ist eine produktionsreife Plattform für beschleunigtes Computing. Entwickeln Sie Ihren Deep-Learning-Code in interaktiven Notebooks und nutzen Sie dann die volle Leistung von Lakeflow, um Jobs auf GPU-Compute-Ressourcen zu übermitteln und zu orchestrieren.
Die AI Runtime von Databricks hat den Prozess des Trainierens eines benutzerdefinierten Text-To-Formula (TTF)-Modells erheblich rationalisiert. Ohne Infrastruktureinrichtung oder Verzögerungen war es einfach, die passende Compute-Ressource basierend auf der Prompt-Größe und der Generierung von Output-Token auszuwählen. Dadurch konnten wir schnell agieren, unsere Lakehouse-Workflows beibehalten und ein qualitativ hochwertiges Modell mit vollständiger Governance bereitstellen, was die Zeit für Einrichtung, Training und Bereitstellung unseres Modells von Tagen auf Stunden verkürzte.—Nikhil Sunderraj, Principal Machine Learning Engineer, FactSet Research Systems, Inc.
Um mit dem Training Ihres nächsten Modells auf GPUs zu beginnen, lesen Sie bitte unsere Beispiele und Dokumentation hier!
Echtzeit-ML im großen Stil: Feature Store und Model Serving
Die wirkungsvollsten Machine-Learning-Anwendungen arbeiten in Echtzeit: Sie liefern Empfehlungen in Millisekunden, stoppen betrügerische Transaktionen, bevor sie genehmigt werden, und liefern Suchergebnisse, die sich verzögerungsfrei anfühlen.
Die Bereitstellung eines Modells in der Produktion ist ein empfindliches Gleichgewicht: Jede Anfrage muss innerhalb weniger Millisekunden abgeschlossen sein, selbst bei Traffic-Spitzen – aber Ihre Kosten sollten niedrig bleiben, wenn der Traffic ruhig ist. Dieses Gleichgewicht im großen Stil zu halten, war in der Vergangenheit ebenso schwierig wie die Erstellung des Modells selbst. Bei hohen QPS wird die Serving-Infrastruktur zum Engpass. Die Latenz wird unvorhersehbar, die Kosten steigen und Teams belasten ihre besten Engineers damit, bei jeder Änderung eines Modells oder seines Traffics Replikatanzahlen, Concurrency-Limits und Autoscaling-Schwellenwerte neu anzupassen.
Auf dem Data + AI Summit kündigen wir neue Funktionen an, die diese Last beseitigen – und die Bereitstellung mit geringer Latenz und hohen QPS auf Databricks optimieren:
- Deklaratives Feature Engineering — Definieren Sie Features einmal und materialisieren Sie sie automatisch für Training und Serving.
- Streaming Features — Erstellen Sie hochaktuelle Features auf Ihren Event-Streams für ML, das in Echtzeit auf Kundenaktivitäten reagiert.
- High-QPS Model Serving — Eine verbesserte Inference Engine und Netzwerk-Routing für Serving mit geringer Latenz sowohl für CPU- als auch für GPU-Modelle, ohne dass Einstellungen manuell angepasst werden müssen. Die Plattform passt sich automatisch an jedes Modell und dessen Traffic an und erreicht über 300.000 QPS bei einem p99-Latenz-Overhead von unter 10 ms.
- Online Feature Serving auf Lakebase — Bereitstellung aktueller Features mit Zugriff mit geringer Latenz für Produktionsanwendungen.
- Genie ZeroOps für ML — Genie Code kann Inference-Tabellen abfragen, Performance-Probleme in Serving-Endpoints debuggen und Ursachenanalysen für Warnmeldungen durchführen, was eine agentische operative Observability für Modelle in der Produktion ermöglicht.
Kunden, die Databricks Model Serving nutzen, haben ihre Infrastrukturkosten im Vergleich zu selbstverwalteten Stacks um bis zu über 90 % gesenkt, die p99- und p50-Latenz um das Doppelte verbessert und im Produktionsbetrieb mit minimalem bis gar keinem Wartungsaufwand über 100.000 QPS erreicht – und das alles bei Zuverlässigkeit und Verfügbarkeit auf Enterprise-Niveau. Führende ML-Teams wie Grammarly, GoGuardian und Tausende andere Kunden verlassen sich auf Databricks, um ihre Echtzeit-ML-Systeme bereitzustellen.
Erfahren Sie mehr auf dem Data + AI Summit 2026!
Probieren Sie diese neuen Funktionen für Ihr nächstes AI-Modell aus! Erfahren Sie mehr in der Dokumentation oder in unseren ausführlichen Walkthrough-Blogbeiträgen:
Erleben Sie die AI Platform in Aktion und erfahren Sie auf dem Data + AI Summit 2026, wie führende Unternehmen AI-Modelle im großen Stil entwickeln und bereitstellen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.