テスト - カスタムLLMのファインチューニングと構築に関するコンパクトガイド
によって Team Databricks による投稿
はじめに
生成AI (GenAI) は、AIを民主化し、あらゆる産業を変革し、すべての従業員をサポートし、すべての顧客を惹きつける可能性を秘めています。最も有用であるためには、GenAIモデルは組織のエンタープライズデータを深く理解する必要があります。これまで、GenAIモデルにエンタープライズの知識を与える最も一般的な手法は、プロンプトエンジニアリング、検索拡張生成 (RAG)、チェーン、エージェントでした。しかし、これらの手法は、特定のドメインやアプリケーションに特化していない汎用モデルを使用する場合に限界に達します。生成結果を改善し、コストを削減するために、GenAIアプリケーション開発者は、ファインチューニングまたは事前学習を通じて カスタムモデルの構築に目を向ける必要があります。
ファインチューニングは、既存のAIモデルを、より小規模なカスタムデータセットでさらに学習させることで、特定のドメインやタスクに特化させます。手法には、指示追従やチャットのための教師ありファインチューニング、および継続的な事前学習が含まれます。事前学習は、完全にカスタマイズ可能なデータでゼロから学習させることにより、まったく新しいモデルを作成します。これらのすべての手法により、開発者は自身のドメインやアプリケーションのための 知的財産と差別化を構築でき、 より��良く、より正確なモデルを作成し、 より小さく、低コストなモデルアーキテクチャを使用する可能性を秘めています。
このカスタムモデル作成ガイドでは、以下について説明します。
- 動機: カスタムGenAIモデルを構築する理由とタイミングは?
- 原則: カスタムモデルを構築する際に、どのような高レベルのプラクティスが戦略と実装を導くべきか?
- 手法: カスタムモデルをどのように構築できるか?データ準備、トレーニング、評価に関して、どのような手法と「落とし穴」に注意すべきか?
このガイドは、カスタムモデルの構築を計画している実務家を対象としています。プロンプトエンジニアリング、RAG、エージェント、ファインチューニング、事前学習といった用語を含む、GenAIと大規模言語モデル (LLM) に関する理解を前提としています。入門資料については、 生成AIと LLMの詳細をご覧ください。
Databricksについて
Databricksは、予測モデルの構築から最新のGenAIやLLMまで、AIおよびMLソリューションを構築、デプロイ、監視するための統合ツールを提供します。Databricks Data Intelligence Platform上に構築されたDatabricksは、組織がエンタープライズデータをあらゆるGenAIモデルとともにAI��ライフサイクルに安全かつ費用対効果の高い方法で統合することを可能にします。お客様は、Meta Llama 3、DBRX、BGEのようなDatabricksによってファインチューニングまたは事前デプロイされたモデル、あるいはAzure OpenAI GPT-4、Anthropic Claude、AWS Bedrock、AWS SageMakerのような他のモデルプロバイダーのモデルをデプロイ、管理、クエリ、監視できます。エンタープライズデータでモデルをカスタマイズするために、Databricksは、プロンプトエンジニアリング、RAG、ファインチューニング、事前学習といったあらゆるアーキテクチャパターンを提供します。
Databricksは、他のどのAIプラットフォームにも匹敵しないGenAIのファインチューニングおよび事前学習機能を提供します。2024年6月現在、Databricksのお客様は前年中に 20万以上のカスタムAIモデルを構築しました。さらに、Databricksは顧客が直接使用できる事前学習済みモデルも提供しています。2024年3月には、Databricksは商用利用可能なライセンスの下でゼロから事前学習された、新しい最高性能のオープンソースLLMである DBRXをリリースしました。2024年6月には、DatabricksとShutterstockが、最先端のテキストから画像へのモデルである Shutterstock ImageAI, Powered by Databricksをリリースしました。
これらの最高性能モデルを構築するために使用したインフラストラクチャとテクノロジーは、お客様に提供されているものと同じです。あらゆる業界におけるデータとAIの成功事例については、当社の Databricksのお客様事例をご覧ください。
動機: なぜLLMをファインチューニングまたはカスタム構築するのか?
お客様は通常、既存のモデルに 品質、コスト、またはレイテンシーにおいて深刻な制約がある場合に、カスタムGenAIモデルの構築を開始します。詳細はユースケースごとに異なりますが、例としては以下のものがあります。
- 「私の製品の特殊なクエリ言語を生成するモデルが必要です。モデルAPIとfew-shotプロンプティングを使えばできますが、非常に遅く、費用がかかります。」
- 「私のRAGボットはうまく機能しますが、高スループットのユースケースには高価すぎる大規模で強力なモデルAPIを使用しています。そのような汎用モデルは必要ないので、小さく、ターゲットを絞った、安価なモデルをファインチューニングしたいです。」
- 「言語Xに優れたオープンソースモデルが見つからないので、Xを理解するように調整されたモデルを構築したいです。」
最も有名なGenAIモデルは、(ほぼ)すべてを行うことを意図した 汎用モデルで�す。これらは印象的ですが、ほとんどのユースケースでは過度に大きく高価であり、お客様の独自データやアプリケーションについては何も知りません。上記のすべての例において、カスタムの専門モデルを構築することで、品質が向上し、コストとレイテンシーが削減されました。カスタムモデルは知的財産となり、お客様の製品に競争優位性をもたらしました。
カスタムモデルを構築する、あまり一般的ではないがより差し迫った動機は、特に規制の厳しい業界における法的または規制上の懸念から生じます。一部の顧客は、モデルトレーニングのためのコンテンツの違法使用の告発などのリスクを管理するために、モデルを完全に制御したい、または制御する必要があります。完全にカスタムなモデルを事前学習することで、モデルがどのように作成されたかを正確に知り、証明できます。
では、どのように始めればよいでしょうか?GenAIは複雑な研究分野ですが、GenAIモデルのカスタマイズを始めるのは簡単です。基本的なファインチューニングから複雑な事前学習まで自然な道筋があり、Databricksプラットフォームはこのワークフロー全体をサポートします。この道筋をたどることで、将来のより複雑な種類のモデルカスタマイズに役立つ専門知識と データを蓄積していくことができます。
原則: いつ、どのようにファインチューニングまたはカスタムモデルを構築すべきか?
いつ、なぜ、どのようにカスタムモデルを構築すべきでしょうか?
大まかに言えば、GenAIシステムは2つの方法�でカスタマイズできます。
- 複合AI: 1つ以上の既存モデルがある場合、それらのモデルを中心にRAG、エージェント、その他の 複合AIシステムを構築できます。
- カスタムモデル: 既存のモデルをカスタマイズ (ファインチューニング) するか、まったく新しいモデルを構築 (事前学習) できます。
これら2つのオプションは、ファインチューニングされたLLMを使用したRAGのように組み合わせることができます。このような組み合わせとGenAI開発の速度は、GenAIアプリケーションの計画と構築を複雑にする可能性があります。アプローチを簡素化するために、3つの指針となる原則をお勧めします。
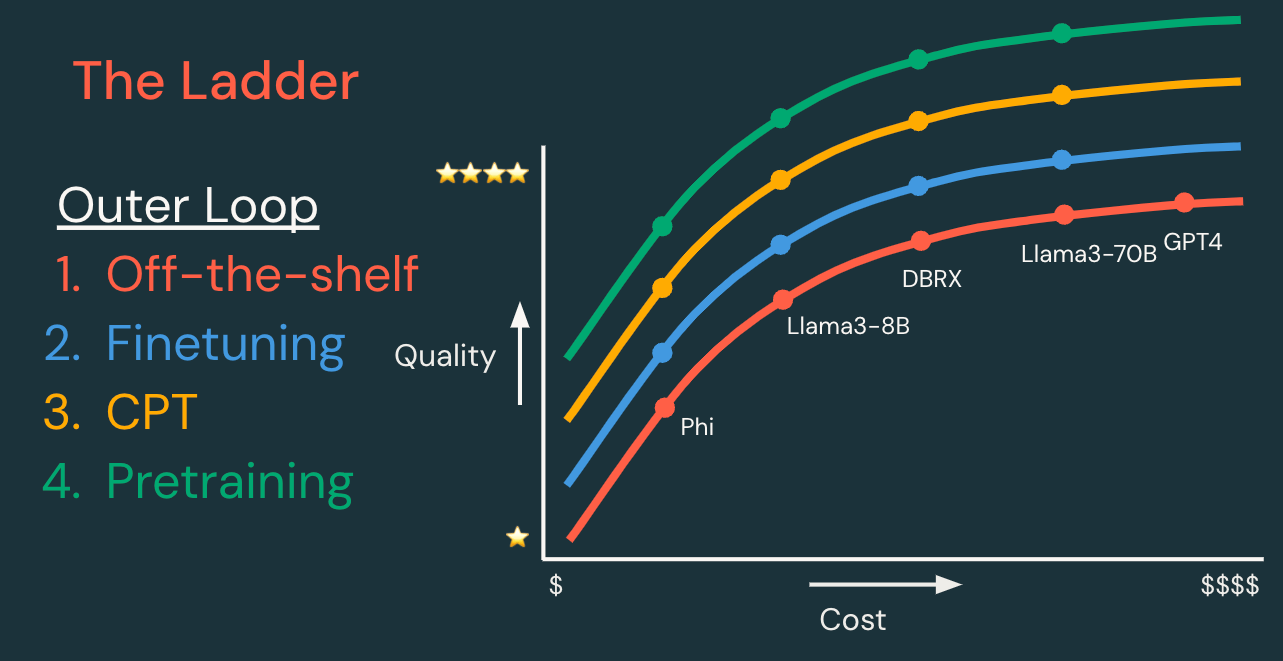
原則1: 小さく始めて段階的に進む
どのようなGenAIアプリケーションでも、シンプルに始めて必要に応じて複雑さを追加することをお勧めします。これは、既存のモデル (例: Databricks Foundation Model API) から始めて、シンプルなプロンプトエンジニアリングを行うことを意味するかもしれません。その後、品質、コスト、速度に関するメトリクスを改善するために、必要に応じて手法を追加します。
手法の「はしご」は、以下に示すように、内部開発ループと外部開発ループに分けられます。
外部ループ: モデルカスタ��マイズのはしご | ||||
各ステップは、より高品質、低コスト、および/または低レイテンシーのモデルを作成する可能性を秘めています。 | 必要なデータ | 開発時間 | 開発コスト | |
既存モデル | 既存のモデルまたはモデルAPIから始め、まず内部ループを反復します。 | なし、またはRAG用のデータ | 時間 | $ |
教師ありファインチューニング | 特定のタスクをより適切に処理するようにモデルをカスタマイズします。 「このようなクエリを期待し、そのような応答を返します。」 | 100~10,000の例 | 日 | $$ |
継続事前学習 | ドメインをよりよく理解するようにモデルをカスタマイズします。 「このニッチなアプリケーションドメインの言語を学習します。」 | 数百万~数十億のトークン | 週 | $$$ |
事前学習 | 完全な制御、カスタマイズ、所有権を持つ新しいモデルを作成します。 「すべてをゼロから学習します!」 | 数十億~数兆のトークン | 月 | $$$$$$ |
インナーループ:複合AI技術 | |
以下の各手法は、特定のモデルの生成品質を向上させる可能性があります。これらの手法は(おおよその)複雑さの順にリストされていますが、組み合わせて使用できます。 | |
プロンプトエンジニアリング | モデルの動作を導くためのタスク固有のプロンプトを構築します。 |
Few-shotプロンプティング | 推論時にモデルを学習させるために、プロンプトでデータを提供します。 |
RAG | クエリ固有のデータを追加のコンテキストとしてモデルに提供します。 |
エージェント | 呼び出し可能なツールや複雑な制御フローをモデルに提供します。 |
インナーループの手法を採用することは、アウターループでステップアップするのと比較して、比較的安価で高速です。したがって、 アウターループでステップアップする際は常に、インナーループのいくつかまたはすべての手法を反復することが価値が�あります。この「インナー」対「アウター」の指定は、システムアーキテクチャから期待されるものとは逆です。複合AIの「インナー」ループは、モデルの「アウター」ループを包み込みます。モデルのカスタマイズを「アウター」ループと呼ぶのは、インナーとアウターのループの相対的なコストによって義務付けられているように、ワークフローの観点からそれが アウターループであるためです。
原則2:データ駆動であること
どんなプロジェクトに本格的に投資する前に、成功の基準を慎重に定義し、一般的な 評価駆動型開発プラクティスに従ってください。
AIシステムレベルでは、品質、コスト、レイテンシーのメトリクスを考慮してください。
- 品質は、精度、ユーザーフィードバック、毒性など、いくつかのメトリクスを含む可能性があります。
- コストは、本番環境のシステムでは一般的にモデル推論とデータ提供に集中します。
- レイテンシーは、エンドツーエンドのレイテンシー、またはよりインタラクティブなアプリケーションの場合、最初のトークンまでの時間を意味する場合があります。
成功を宣言するために、これらのメトリクスはどの数値を達成する必要がありますか?優れたユーザーエクスペリエンス、プラスの投資収益率、またはその他のビジネス要件を確保するために、これらのメトリクスにどのような厳しい制約がありますか? 詳細については、当社のチーフAIサイエンティストによるこの講演をご覧ください。
プロジェクトおよびビジネスレベルでは、投資収益率を分析します。
- コスト(投資)は2つのフェーズに分けるべきです。
- 開発コストには、データ準備、モデルトレーニング、システム開発のための計算コストと人件費が含まれる場合があります。
- 継続コストには、モデルとデータの提供、およびメンテナンスの人件費が含まれる場合があります。
- ビジネスへの影響(リターン)
- 収益またはその他のビジネス目標と主要な結果(OKR)は、人件費の削減(GenAIサポートボットの場合)から直接的な収益(GenAI搭載製品の場合)まで多岐にわたります。
- IP作成(新しいモデルやデータなど)は、測定するのが最も難しい影響かもしれませんが、長期的には最大の影響となる可能性があります。誰もが同じモデルプロバイダーAPIを使用できますが、独自のモデルとデータを使用できるのはあなただけです。
データ駆動型の目標は、モデルのカスタマイズ(原則1)に関する選択に影響を与えます。例えば、品質メトリクスは満たしているものの、高価なモデルAPIを使用してコスト制約を超過してい��る場合、品質を維持しながらコストを削減するために、特定のタスクに合わせたより小さく効率的なモデルのファインチューニングに移行する可能性があります。ファインチューニングは追加の開発コストを伴いますが、継続コストを削減し、長期的には全体的なコストを削減します。
原則3:実用的に考える
GenAIモデルとシステムの評価は困難です。ファインチューニングと事前学習の技術は、活発な研究分野です。学術界と産業界の興奮(およびLLM)は、読み切れないほどのコンテンツを生み出しています。これらの混乱の原因により、どの技術をいつ使用すべきかを知ることが困難になっています。(「LoRAは必要か?カリキュラム学習とは何か?どのモデルアーキテクチャが最適か?」)
GenAIに不慣れな多くの人々は、大量のデータをGenAIに投入すれば驚くべきことを学習すると聞いています。これらの期待を抑えてください。データ量も重要ですが、データ品質、トレーニング手法、評価も同様に重要です。
Databricksのお客様は、GenAIカスタマイズの道のりにおいて、Databricksに組み込まれたガイダンスを部分的に利用できます。このガイダンスは、 一般的なモデル向けのシンプルなAPIから、RAGとエージェント向けの Agent Bricks Custom Agents、ファインチューニング用の UIとAPI、さらには 事前学習用のガイド付きAPIまで多岐にわたります。
しかし、カスタマイズを進めるほど、より多くの可能な手法と決定を行う必要があります。実用的に考えることをお勧めします。研究でうまくいった手法が、実際のアプリケーションではうまくいかない場合があります。あるタスクには適していても、別のタスクには不向きなモデルもあります。最適な手法は時間とともに変化します。この複雑さを乗り切るには、原則1と2を念頭に置いてください。あなたの北極星を定義し、データとメトリクスに基づいてそれに従ってください。
また、私たちとの提携をお勧めします。あなたの直属のDatabricksチームを超えて、当社のプロフェッショナルサービスチームは、 初期概念実証から完全な事前学習実行までガイドできます。当社の Mosaic Researchチームは、多くの顧客と協力して事前学習を実行し、最先端の知識とアドバイスを提供しています。
カスタムLLMを構築するための手法
モデルカスタマイズのアウターループを登りたいと考えると、 原則1で導入された手法にどのように�アプローチすべきでしょうか?このセクションでは、評価について議論し、主要なカスタマイズ手法について詳しく説明します。
注:このガイドは、固定モデルでの反復というインナーループには焦点を当てていません。これらの手法の詳細については、 Generative AI Fundamentalsおよび Generative AI Engineering With Databricksコースをご覧ください。
このセクションでは、原則1のアウターループで先に概説したカスタマイズ手法について詳しく説明します。ここにそれらを一覧表示し、どの手法を選択するかは、主に利用可能なデータ(原則2)によって決まることに注意してください。
アウターループ: モデルカスタマイズの段階 | ||
必要なデータタイプ | データサイズの目安 | |
既存モデル | 該当なし | なし、またはRAG用のデータ |
教師ありファインチューニング | クエリと応答のデータ(または「ラベル付けされた」データ) | 少なくとも数百〜数万の例 |
継続事前学習 | 次トークン予測のための「生」テキスト | 数百万〜数十億トークン、または元のトレーニングセットの1%以上 |
事前学習 | 次トークン予測のための「生」テキスト | 数十億〜数兆トークン |
次のセクションでは、すべての手法で共通するガイダンスから始め、各手法についてさらに詳しく説明します。
データ
データはユースケースに合わせる必要があります。 特定の方法で応答するようにモデルをファインチューニングする場合、トレーニングデータは「良い」応答を示す必要があります。特定のドメインを理解するために継続事前学習を行う場合、データはそのドメインを代表するものである必要があります。
法的およびライセンスに関する問題を最初から解決してください。 公開データを使用する場合、特に事前学習では、一部の公開データセットは法的問題を避けるために適切にキュレーションされていますが、そうでないものもあることに注意してください。自社のエンタープライズデータを使用する場合は、特にデータが顧客から提供されたものか、制限付きライセンスを持つGenAIモデルから提供されたものかについて、出所を明確に確認してください。
データを早期かつ頻繁に収集してください。 現在のアプリケーションからのクエリ、応答、ユーザーフィードバックは、将来のGenAIモデルのチューニングとトレーニングの入力となる可能性があります。ただし、これには注意が必要です。多くのプロプライエタリモデルやオープンソースモデルには使用制限があるため、生成された応答の出所を慎重に追跡してください。将来の柔軟性を確保するために、互換性のないライセンスを持つモデルとデータを混在させないようにし、オープンライセンスを優先してください。
合成データは慎重に使用してください。 合成データは役立つことがありますが、本物のエンタープライズデータはほとんどの場合、より価値があります。「実際の」データは、LLMに合成データの生成方法を教えるために使用でき、これについてはこのガイドの後半で説明します。合成データは依然として 活発な研究分野です。
モデル
ベースモデルと指示/チャットモデルの違いを認識してください。 ほとんどの主要なLLMリリースには、ベースモデル(事前学習済みだがファインチューニングされていない)と、指示に従うまたはチャットのバリアント(ファインチューニング済み)の両方が含まれています。どちらのタイプを使用すべきかについては、以降のセクションで推奨事項をご覧ください。
Databricks機能が推奨するモデルを使用してください��。 Mosaic Researchは最先端のモデルアーキテクチャを研究し、GenAIモデルに関する いくつかの優れた推奨事項を共有し、Databricks Model Trainingやその他の機能でそれらのトップモデルを優先しています。
必要に応じて、よりカスタムなコードに移行してください。 デフォルトのモデルやトレーニング方法がニーズに合わない場合は、いつでも「スタックを降りて」よりカスタマイズされたコードを使用できます。Databricksの GPUアクセラレーテッドクラスター(汎用コンピューティング)と Databricks Model Training(深層学習に特化したコンピューティング)はどちらも、GenAIやその他の深層学習モデル向けの任意のトレーニングコードをサポートしています。
ユースケースに有望なモデルを特定してください。 チューニングの前に、汎用モデルがアプリケーションに有望かどうかを検討してください。「有望性」は、 AI Playgroundを使用したアドホックな手動テスト、またはベンチマークデータセットやカスタム評価データセットを使用したより厳密なテストによって測定される場合があります。テストには小規模なトレーニングが必要になる場合があります。ファインチューニングの場合、100個の少数の例でファインチューニングした後、モデルは改善しますか?事前学習の場合、特定のデータセットでの継続事前学習によってモデルは改善しますか?
制約を忘れないでください。 推論時のコストとレイテンシーの制約に基づいてモデルサイズを選択してください。また、カスタムモデルの構築は アウターループに過ぎないことも忘れないでください。より単純なリクエストをより小さなモデルにルーティングするなど、 インナーループでもコストとレイテンシーを最適化できます。
ヒント: これらの手法は一連の流れを形成するため、より単純な手法での作業が無駄になることはありません。例えば、モデルを事前学習した後、通常は次に教師ありファインチューニングを行います。
評価
原則2では、メトリクスを用いたデータ駆動型のアプローチを推奨しています。カスタムモデルの構築に関する詳細に入る前に、作業を導く評価と品質に関するメトリクスについて説明します。
ソフトウェアエンジニアリングと同様に、テストピラミッドに従うことを推奨します。
ソフトウェアテストの類推 | 速度/コスト vs. 忠実度 | 例 |
単体テスト | 高速で安価な��代替測定 | 正誤判定テスト |
統合テスト | 中程度の速度/コストのテスト | ベンチマークデータセットでのLLM-as-a-judgeメトリクス |
エンドツーエンドテスト | 低速だが現実的なテスト | 人間によるフィードバック |
上記のテストピラミッドの例は汎用的に書かれており、モデル(原則1のアウターループ)と複合AIシステム(インナーループ)のどちらをテストするかという問題は避けています。カスタムモデルを構築する際には、モデル自体と、それを使用するAIシステムの両方をテストする必要があります。例えば、「LLM-as-a-judgeメトリクス」は、モデルの指示追従能力をテストするために使用でき、RAGシステムのリトリーバルメトリクスや質問応答メトリクスをテストするためにも使用できます。
特定モデルと汎用モデル、およびタスク
特定のタスクのためにモデルをファインチューニングする場合と、汎用モデルを事前学習する場合では、テストピラミッドは大きく異なります。データとメトリクスに基づいたアプローチとは、 モデルのダウンストリームユースケースに合わせてテストピラミッドを調整することを意味します。
特定のタスクのためにモデルをファインチューニングする場合は、小さく始めること(原則1)を忘れないでください。例えば、次のようなことができます。
- 評価用の「ゴールデン」クエリ応答データセットを構築します。潜在的なクエリとトピック全体でバランスが取れていることを確認してください。
- LLM-as-a-judgeメトリクスを使用して評価をスケールアップします。特定のタスクに合わせてメトリクスを選択またはカスタマイズしてください。
- 最終テストとして人間またはユーザーによる評価を使用します。
継続事前学習または完全な事前学習を開始すると、評価はより複雑になる可能性があります。テストピラミッドを計画する際には、モデルが必要とすると考えるさまざまなスキルセットに沿って評価を分解し、重要な領域に集中できるようにしてください。それは次のような意味です。
- スキル(一般知識、論理、読解力など)
- ドメイン(金融、法律、医療など)
- 言語(自然言語やプログラミング言語を含む)
- その他の側面(コンテキスト長から組み込みのガードレールまで)
ヒント:
- ユースケースに合わせて評価を調整する。例えば、より長いコンテキスト長を処理するようにモデルを修正する場合、継続事前学習のパープレキシティメトリクスだけでは不十分であることに注意してください。評価データセットには、長コンテキストタスクも含まれている必要があります。
- 学習と忘却の両方をテストする。特定の言語(��例:マレー語)のモデルの理解度を向上させるために継続事前学習を行っている場合、そのモデルが既存の言語(例:英語)の理解度を維持する必要があるかどうかをユースケースで検討してください。もしそうであれば、評価ではマレー語と英語の両方をテストする必要があります。
- 顧客が実際に使用するものをテストする。新しい(ベース)モデルを事前学習する場合、顧客が実際に使用するモデルバージョンを作成するために、命令ファインチューニングを行う可能性が高いです。最終的な(エンドツーエンドの)評価は、ベースモデルではなく、ファインチューニングされたモデルに対して行うべきです。
DBRX構築の例
2024年5月、DatabricksはDBRXをリリースしました。これは(当時)最先端のオープンソースLLMです。その評価スイートは、以下に示すテストピラミッドの良い例を提供しています。
ソフトウェアテストの類推 | DBRX構築からのメトリクス例 | |
単体テスト | 言語理解、読解、記号問題解決、世界知識、常識、プログラミングの6つの主要能力にわたる39の公開ベンチマーク | |
統合テスト | マルチターン会話および命令追従ベンチマークデータ | |
命令追従ベンチマークデータ | ||
Chatbot Arenaベースの人間選好ベンチマークデータジェネレーター | ||
エンドツーエンドテスト | 内部および顧客からのフィードバックとA/Bテスト | 内部および外部ユーザーとの反復テストにより、A/Bテストメトリクスと人間によるアノテーションの両方を収集 |
レッドチームテスト | 専門家によるテストで、望ましくない出力(攻撃的、偏見のある、またはその他の安全でない出力)を生成 |
評価メトリクスの詳細については、このGenerative AI Engineeringコースをお勧めします。ツールとしては、自動化された(LLM-as-a-judge)メトリクス、評価データセット、人間による評価アプリをサポートするDatabricks MLflowをお勧めします。エージェント評価は、LLM評価のためのオープンソースのMLflow APIを使用します。事前学習のためのより詳細な評価については、お客様と協力してカスタム評価計画を策定できます。
教師ありファインチューニング
ほとんどの実務家が使用するモデルカスタマイズの最初のテクニックは、教師ありファインチューニング(SFT)です。これは、特定のタスクや動作のためにモデルを最適化するために、ラベル付きデータでモデルをトレーニングするものです。
一般的なユースケースには以下が含まれます。
- 固有表現認識: ドメイン固有のエンティティを認識するようにモデルをファインチューニングする
- チャット補完と質問応答: 特定のトーンで応答するようにモデルをファインチューニングする
- 出力フォーマット: 特定の構造化された出力で応答するようにモデルをファインチューニングする
- 命令追従: 一般的なモデルを事前学習した後、単に補完テキストを生成するのではなく、命令やクエリに応答するようにモデルを教えるために命令ファインチューニングを使用するのが一般的です
用語:「ファインチューニング」は「教師ありファインチューニング」を意味することが多いですが、技術的には「ファインチューニング」は既存モデルのあらゆる適応を指します。継続事前学習や人間からのフィードバックによる強化学習(RLHF)もファインチューニングの一種��です。
ファインチューニングは、モデルカスタマイズの中で最も速く、最も安価なタイプです。例えば、2023年5月にリリースされたMPT-7Bモデルの場合、命令ファインチューニングは960万トークンの処理に46ドルかかりましたが、事前学習は1兆トークンの処理に250,800ドルかかりました。
データ
データを準備する際、コンテンツとフォーマットが重要です。ファインチューニングの大部分は、モデルにどのような入力を期待し、どのような出力を期待するかを教えることです。フォーマット、トーン、トピックの範囲、その他の側面に関して、ユーザーのクエリがどのように見えることを期待しますか?トレーニングデータはこれらの期待を反映している必要があります。
データサイズはよくある質問のトピックであり、最終的にはユースケースに依存します。数百または数千の例からなる小さなデータセットでファインチューニングして良い結果が得られたケースもありますが、一部のアプリケーションでは数万または数十万の例が必要です。計画を検証するために小さく始め、必要に応じてトレーニングデータセットを構築しながら反復的にスケールアップしてください。
合成データはSFTに役立ち、最も一般的には小さすぎる「実際の」データセットを拡張するために使用されます。LLMにプロンプトを与えて、実際のデータの例に似た合成SFTデータを生成させることができます。
Databricks Model Trainingのデータ準備に関するドキュメントも参照してください。
モデル
このガイドの冒頭で、Databricks Model Trainingがサポートするモデルをデフォルトで使用し、ユースケースに適したモデルをテストすることをお勧めしました。その良い例がMPTです。MPTは日本語を念頭に置いてトレーニングされたわけではありませんが、100個の日本語プロンプト応答例で迅速なファインチューニングテストを行ったところ、顧客にとって驚くほど効果的なモデルが生まれました。この迅速なテストがアプローチを検証し、大規模なファインチューニングへの道を開きました。
モデルサイズを選択する際は、大きすぎるモデルから始めることを検討してください。小さなデータセットでチューニングする場合、小さいモデルよりも大きいモデルの方が良い結果を生み出す可能性が高くなります。大きなモデルから始めることで、データとユースケースの可能性を知ることができ、SFTは比較的安価です。可能性が見えたら、より小さなモデルとより多くのデータでテストできます。
モデルのベースまたは指示/チャットバリアントのいずれかでSFTを実行できます。デフォルトでは、特にデータセットが小さい場合は、指示/チャットバリアントを使用することをお勧めします。カスタムベースモデルを作成するために継続事前学習を実行した場合は、そのカスタムベースモデルでSFTを実行できます。
Databricks Model Training
Databricks Model Trainingは、UIとAPIというシンプルなインターフェースを、教師ありファインチューニングタスクのために提供します。このガイドで既に提示されているデータとモデルに関するヒントに加えて、以下を考慮してください。
- タスク: SFTタスクは、期待されるクエリ形式に応じてさまざまな方法で指定できます。一般的な標準に合わせるため、命令追従タスクであっても、デフォルトでチャット補完形式を推奨することに注意してください。
- 設定: イテレーションを繰り返す中で、最初に最適化すべきハイパーパラメータは学習率です。従来の機械学習 (ML) アルゴリズムで学習率を調整するのと同様に、まず学習率のグリッドを試し、次に最適な初期学習率を中心とした、よりきめ細かい学習率のグリッドに絞り込んでください。また、学習の進捗状況のプロットに基づいて、トレーニング期間 (エポック数またはトークン数) の調整も検討してください。ファインチューニングタスクによっては少ないエポック数で済むものもあれば、50エポック以上が有効なものもあります。
- 評価: 評価データセットを指定して、Databricks Model Training が初期評価(「単体テスト」)を計算できるようにします。50組のクエリと応答のペアというごく小さなデータセットでもシグナルを得られますが、より大規模で多様なデータセットの方が優れています。特に、トレーニング時の評価損失(または精度)がエンドユーザーの評価と必ずしも相関しない場合があるため、より徹底した評価には Databricks MLflow を使用してください。
教師ありファインチューニングの詳細
デフォルトでは、シンプルで効率的なワークフローのために Databricks Model Training を推奨します。 ただし、サポートされていないモデルアーキテクチャを使用する必要がある場合や、よりカスタマイズされたチューニング方法が必要な場合は、Databricks GPU-accelerated clusters (汎用コンピュート) および Databricks Model Training で完全にカスタムのコードを実行できます。
このガイドでは、ファインチューニングと推論をより効率的にするための低ランク適応 (LoRA) などの手法群である、パラメーター効率の良いファインチューニング (PEFT) については詳しく説明しません。これらの手法の説明と例については、 こちらのブログ、 こちらのブログ、または Hugging Face PEFT を参照してください。
継続事前学習
教師ありファインチューニング (SFT) は、モデルに新しいドメインを理解させるよう設計されていません。モデルを新しい言語、ニッチな業界、またはその他の特定の領域を理解するようにカスタマイズするには、継続事前学習 (CPT) を利用できます。CPT は事前学習と似ていますが、既存の事前学習済みモデルを使用し、新しいデータを使って事前学習プロセスを 継続する点が異なります。新しいドメインに適応するための CPT の後、モデルは通常、教師ありファインチューニングによって特定のタスクに適応されます。
一般的なユースケースは次のとおりです。
- 言語: 一般的なモデルは、トレーニングデータで多くの自然言語を学習していることが多いですが、主要な言語以外では弱い場合があります。CPT は、特定の言語に対するモデルの理解を向上させることができます。
- プログラミング: 一般的なモデルは、トレーニングデータで少なくともいくつかのプログラミング言語を学習していることが多いですが、主にコーディング用に設計されていなかったり、特定のプログラミング言語を十分に理解していなかったりする場合があります。CPT は、特定のプログラミング言語でコーディングする方法をモデルに教えることができます。
- 業界ドメイン: 一般的なモデルは、分子生物学、環境法、金融規制などの特定のトピック領域に関する深い知識を持っていない場合があります。CPT は、特定のドメインに対するモデルの知識と理解を向上させることができます。
RAG Q&A ボットの指示追従モデルを改善するには、教師ありファインチューニング (SFT) と継続事前学習 (CPT) のどちらを使用すべきですか?
どちらの手法も適用可能ですが、利用可能なトレーニングデータと、モデルの何を改善したいかによって異なります。モデルに特定の方法で応答するように教えたい場合は、トレーニング用のクエリと応答のデータがあれば SFT を使用します。モデルがあなたのドメインや言語を理解していない場合は、トレーニング用のかなりの量のテキストデータがあれば CPT を使用します。CPT の後には、モデルにクエリへの応答方法を再学習させるために SFT を実行する必要がある可能性が高いことに留意してください。
SFT または CPT を使用して、モデルに新しい知識や事実を教えることはできますか?
はい、どちらの手法も何らかの知識を与えることができますが、CPT の方がより適用可能です。いずれにせよ、ソースデータに基づいて回答を根拠づけることで、AI システムを堅牢にするために RAG を使用する必要があるかもしれません。
データ
CPT に必要なデータを検討する際には、原則2(「データ駆動」)を思い出してください。 元のモデルの何を改善したいですか? あなたのデータは、モデルに注入したいドメイン、言語、知識などを表している必要があります。特定のユースケースの場合、これはおそらく、そのユースケースに関連する独自の企業データ(社内ナレッジベース文書、過去20年間の関連研究論文など)で CPT を実行することになるでしょう。より一般的なモデルの場合、データのガイダンスは 事前学習 のガイダンスとより似ており、ユースケースにとって重要なさまざまなスキルセットを表すために複数のデータセットを選択する場合があります。
ヒント: 忘却と学習。CPT をテストする際には、過去の知識を忘れることと新しい知識を学習することの間にはトレードオフがあることに留意してください。目標は、モデルの動作を CPT トレーニングデータに模倣させることですが、それは元の事前学習データの一部を忘れることを意味するかもしれません。したがって、CPT トレーニングデータと評価スイートの両方が、あなたが重視するドメインをカバーしていることを確認してください。
データ 形式については、データは「生」のテキストになります。つまり、事前学習と同様に、次トークン予測を行う CPT を実行することになります。
データ サイズについては、CPT は少数のトークンを使用してモデルを微調整することから、多数のトークンを使用してモデルを大幅に変更することまで、幅広い範囲にわたります。「少ない」と「多い」はモデルのサイズに依存しますが、現代の中規模 LLM では数十億トークンが妥当な見積もりです。経験則として、CPT には元のトレーニングセットサイズの少なくとも約1%が必要です。
CPT 用の生データと SFT 用のプロンプト応答データの両方が必要ですか?
CPT の後に SFT を実行する場合は、はい、必要です。ただし、CPT 用のデータはあるが SFT 用のデータが少ない場合は、他の SFT データセットや合成データを使用して、小さな SFT データセットをクエリ応答データで補強できます。
合成データ は CPT、特に大規模で強力なモデルを使用してより小さなモデルをトレーニングするためのデータを生成する蒸留において有用です。蒸留は、より小さく、より速く、より安価なモデルを作成するのに役立ち、ユースケースに特化した非合成データを補完することができます。
Databricks Model Training のデータ準備に関する ドキュメントも参照してください。
モデル
SFT と同様に、デフォルトでは Databricks Model Training でサポートされているモデルを使用し、ユースケースに適しているかどうかをテストすることをお勧めします。
ベースモデルと指示/チャットモデルのバリアントのチューニング、および CPT の後に SFT を実行することに関する推奨事項は密接に関連しています。最も一般的なパスであり、当社のデフォルトの推奨事項は、ベースモデルで CPT を実行し、その後に指示またはチャットのファインチューニングのために SFT を実行することです。ただし、いくつかのニュアンスがあります。
- ベースモデル vs. 指示/チャットモデルのバリアント: ベースモデルで CPT を実行するのが最も一般的です。指示またはチャットモデルのバリアントで大規模なデータセットに対して CPT を実行すると、そのモデルが指示追従能力やチャット能力の一部を失う可能性があります。
- CPT の後の SFT: 大量のデータで CPT を実行する場合、その後に SFT を実行することになるでしょう。ただし、少量のデータを使用して指示追従モデルまたはチャットモデルで CPT を実行する場合、その後に SFT は必要ないかもしれません。一部の顧客がこれを行い、結果のモデルをアプリケーションで直接使用しているのを見てきました。
Databricks Model Training
Databricks Model Trainingは、CPT向けにシンプルなインターフェース(UIと API)を提供します。このガイドで以前に述べたSFTのヒントは、CPTにもほとんど適用されます。便利なことに、Model Training機能はCPTとSFTの両方を実行するために使用できます。
CPTはSFTよりもモデルを根本的に変更する可能性があるため、前回の 評価に関する議論で示されたテストピラミッドには、より堅牢で一般的なテストが必要になります。CPTをスケールアップするにつれて、テストピラミッドは事前学習テストスイートのようになるかもしれません。
CPTの詳細
CPTのワークロードがよりカスタマイズされ、大規模になるにつれて、以下で説明する事前学習スタックを検討することもできます。
CPTは事前学習用のデータをテストするのに役立ちます。CPTデータが新しいドメイン(新しいコーディング言語など)をカバーしている場合、CPTでの成功は、そのデータが事前学習データセットの一部として有用である可能性を示します。
事前学習
GenAIアプリケーションが継続的な事前学習を経て進歩し、完全にカスタムなモデルの事前学習がアプリケーションを改善するために必要な次のステップであると信じているとします。このセクションでは、プロセスとベストプラクティスを大まかに説明しますが、実際には、Databricksチームと一緒に事前学習プロセスを進める必要があります。
すぐに事前学習に移行すべきでしょうか?
いいえ。規制やその他の制約により、完全に所有する新しいモデルを作成する必要がある場合でも、まずはカスタマイズの低い段階でプロトタイプを作成する方が良いでしょう。これにより、よりコストがかかり複雑な事前学習の実行のリスクを軽減できます。
事前学習のステップとは?
実際には、事前学習は反復的で適応的なプロセスですが、事前学習における高レベルで一般的なステップには以下が含まれます。
- まず、ファインチューニングと継続的な事前学習を段階的に進めます。デューデリジェンスを行いましょう!
- データセットを準備します。これはステップ1で行われ、CPTは特定のデータセットの有用性をテストするのに役立ちます。
- テキスト補完ができるベースモデルを事前学習します。これには、トレーニングの監視、実行中の調整、カリキュラム学習のような適応技術によるデータミックスの調整が含まれます。
- 指示またはチャットのファインチューニングを実行して、指示/チャットバリアントを作成します。
- 人間からのフィードバックによる強化学習(RLHF)のような技術を使用して、モデルをさらに調整することも可能です。
- 上記のすべてのステップで、モデルを随時評価します。
この簡潔な手順の要約は、完全な事前学習の比較的高コストであるため、デューデリジェンスと評価を強調しています。以前に引用したMPT-7Bモデルの例を思い出してください。そのモデルの事前学習は、指示ファインチューニングよりも5452倍のコストがかかりました。
データ
データの選択と処理は、事前学習の成功を決定する上で非常に大きな役割を果たします。
どのようなデータか?
ターゲットアプリケーションを代表するように、データミックスを慎重に選択する必要があります。
- 評価がモデルに持たせたいスキルセットごとに分解される必要があるのと同様に、事前学習に持ち込む各データセットがモデルに何を教えるかを考慮してください。これらのデータセットの影響は、継続的な事前学習を使用して事前にテストできます。
- データミックスに関する詳細を公開している高性能モデルはほとんどありません。一部の古いモデルはリストを公開しています(例: MPT、 LLaMA、 OLMo)。この データミックスに関する議論も参照してください。
- 公開データセットと独自デー��タセットを組み合わせることになるでしょう。適切に精査された公開データセットは、言語能力、一般知識、特定のスキルセットを教えるなど、トレーニングニーズの一部を満たすことができます。独自データセットは、他の誰も利用できない競争優位性をモデルに与えます。
データの量と質は重要ですが、その重要性は時期によって異なります。事前学習は、品質管理を緩くして「すべてのデータ」で開始するのが一般的です。初期段階では、より多くのトークンが基本的な言語能力の学習につながります。しかし、事前学習の後半では、データミックスをより小さく、より高品質なセットに変更するのが一般的です。「高品質」には学術的な定義はありませんが、直感的には常識的な手法を用いてキュレーションされたものを意味します。データ準備の詳細については、以下を参照してください。
どのくらいのデータが必要か?
- モデルのサイズとアーキテクチャを考慮して、データサイズを選択する必要があります。
- 「Chinchilla」の経験則は最も有名なルールです:#トークン = 20 * #パラメーター。推論コストを削減するために、この LLaMA論文の結果に基づき、より多くのデータでより小さなモデルをトレーニングして、同様の生成品質を達成することをお勧めします。
- Mixture of experts (MoEs) アーキテクチャは、この計算を変える可能性があり、多くの�場合、特定のモデルサイズに対してより少ないデータを必要とします。MoEsの場合、この計算にはアクティブなパラメーター数(合計パラメーター数ではない)を使用してください。
- 一部のタスクは他のタスクよりも難しいことに留意してください。例えば、7Bパラメーターモデルは、HumanEvalコーディングベンチマークに取り組むために、通常少なくとも2兆トークンのトレーニングデータを必要とします。
データはどのように準備すべきか?
- ダウンロードと解析: 通常、データは自分で取得する必要があります。インターネット規模のデータを事前にダウンロードして提供するプロバイダーは少なく、規制要件は顧客ごとに異なる場合があります。
- クリーニング: 事前学習は大量の低品質データを活用できますが、データ品質を向上させる価値はあります。例えば、この RefinedWeb論文では、 Common Crawlの約11%が有用であると推定しています。事前学習のためのデータクリーニングは、多くの活発な研究が行われている大きく複雑なテーマです。一般的なステップの優れた調査については、 この論文を参照してください。これには以下が含まれます。
- 言語フィルタリング:関心のある主要言語にテキストを絞り込むため
- ヒューリスティックフ�ィルタリング:定型文、過度に短いまたは長いドキュメント、非自然言語テキストなどを削除するため
- 品質フィルタリング:人間によって書かれた、またはレビューされた可能性が高いテキストを特定するため
- ドメインフィルタリング:関心のあるドメインに関するテキストを特定するため
- 重複排除:データセット内またはデータセット間のコンテンツの重複を排除するため
- 有害および露骨なコンテンツのフィルタリング:出所またはテキストに基づいて
- これらの技術はすべて注意点があることに留意してください。それぞれについて、精度と再現率のトレードオフを考慮してフィルタリングの厳密さを調整する必要があります。一部のフィルターは誤解を招く可能性があります。重複はテキストがより有効または重要であることを示す場合があり、有害なコンテンツを見たことがないモデルは有害性を認識せず、有害なユーザー入力を容易に繰り返す可能性があります。
- 前述のとおり、初期の事前学習では品質管理が緩いより多くのデータを使用する場合がありますが、後の事前学習ではより慎重にクリーニングされたデータサブセットに焦点を当てる場合があります。
- 事前計算: データを事前トークン化し、連結して事前学習用の形式を最適化することで、効率を向上させることができます。
データ処理はDatabricksの本来の強みです。以下を活用してください。
- Workflows:ジョブ定義とオーケストレーションのため、およびスケールアウト処理のための Apache Spark™と Delta最適化
- Delta Lake:データストレージ形式として
- Unity Catalog:データ管理のため
- ノートブック、 IDE連携、および Databricks SQLによる開発とデータ探索
- Lakehouse Monitoringによるデータパイプラインとソースの長期的な監視
モデル
研究者は新しいモデルアーキテクチャを画期的な進歩として当然のように宣伝しますが、Transformerアーキテクチャが 2017年に登場したにもかかわらず、いまだに主流であるのには理由があります。それは非常にうまく機能するからです。同様に、私たちは一般的に、以下のような実績のあるアーキテクチャの選択肢に従うことを推奨します。
- 研究で十分にテストされていない手法ではなく、二次アテンションやFlashAttention-2のような標準的なアテンションメカニズムを使用する
- より効率的なトレーニングと推論、および低精度演算のために、混合エキスパート (MoEs) アーキテクチャを検討する
- 次トークン予測を使用してトランスフォーマーをトレーニングする
Databricksは任意のアーキテクチャでの事前学習をサポートしていますが、 Databricks Model Trainingを通じて、推奨される主要なアーキテクチャ向けに、よりシンプルな事前学習セットアップを提供しています。Databricks Model Trainingは、 Mosaic LLM Foundryや Mosaic Diffusionなどのツールのマネージドで最適化されたバージョンを提供します。このツールは、標準的で十分にテストされたデフォルトを提供することで、選択を簡素化できます。例えば、2024年7月現在、LLM FoundryはFlashAttention-2を標準的なアテンションメカニズムとして推奨しており、DBRXのようなMoEsアーキテクチャをサポートしています。お客様の特定のアプリケーションについては、アーキテクチャの詳細についてアドバイスできます。
モデルサイズに関しては、小さく始めることを忘れないでください( 原則1)。70億パラメータのモデルをトレーニングするコストは、700億パラメータのモデルの約10分の1であり、スケールアップする際のモデリングの選択に役立ちます。また、潜在的なモデルサイズの制約として、ユースケースのレイテンシとコストの制約を考慮してください。
トレーニングスタックとインフラストラクチャ
データとモデリングの選択肢が準備できたら、事前学習の準備が整ったことになります。これはGenAIで行う最もコストのかかるステップになる可能性があるため、以前のステップでの慎重な準備が重要です。このステップでは、堅牢なツールと専門家のアドバイザーを使用して、事前学習をスムーズに進めることが重要です。
事前学習の実行には多くの課題が伴います。Databricksプラットフォームは、これらの課題の多くをユーザーのために自動的に処理します。
課題 | Databricks |
データロード: 数兆個のトークンをロードする必要がある場合があります。 | Databricksは、高速な起動と回復時間を提供します。 |
スケーリングと最適化: 数十から数千のGPUにスケールする必要がある場合があります。トレーニングパフォーマンスを最適化するための非常に多くの手法があります。 | Databricksは、データ並列処理とFSDPによるシームレスなスケー�ルアウトと、構成可能な最適化のライブラリを提供します。これにより、最高レベルのモデルFLOPS利用率 (MFU) を達成します。 |
障害回復: ほとんどのクラウドで、1000 GPU日あたり約1回のインフラストラクチャ障害が発生する可能性があります。事前学習ジョブでは、損失の急増や発散が見られる場合があります。 | Databricksは障害を自動的に検出し、高速な再起動を行います。トレーニングスタックは損失の急増も軽減します。 |
決定性: 分散データロードとトレーニングは決定性を困難にしますが、回復と再現性にとって価値があります。 | Databricksのデータロードおよびトレーニングアルゴリズムは、事前学習の再現性を大幅に向上させます。 |
Databricks Trainingスタックは、ハードウェアからワークロード管理までを網羅しています。以下の表に、まず学ぶべき主要な要素を示します。
ステージ | Databricksコンポーネント | 詳細 |
データロード | クラウドストレージからのトレーニングデータの高速で再現可能なストリーミングを提供し、��高速な開始と再開を含みます。 | |
トレーニング | 効率的な分散トレーニングのための構成可能なベストプラクティスと手法を提供します。 | |
ワークフロー構成 | データ準備、トレーニング、ファインチューニング、評価を含むワークフローの簡単な定義を可能にします。Databricksは、一般的なアーキテクチャの事前学習を開始するのに役立つ標準構成を提供できます。 | |
実験追跡 | 事前学習の実行中に評価やその他のメトリクスを追跡します。DatabricksはWeights & Biasesもサポートしています。 |
お客様のユースケースは、LLM Foundryによって構成の「レシピ」として示された実績のあるパスに従うことができ、その場合、ワークフローは非常に構成駆動型になる可能性があります。あるいは、よりカスタムなアーキテクチャやコードが必要な場合は、 MCLIのようなスタックの下位レベルの部分に焦点を当て、Databricksインフラストラクチャとより直接的に連携することもできます。
計算とコスト
モデルを事前学習する前に、コストを見積もることが重要です。事前学習の計算コストは、データとモデルのサイズに基づいてGPU時間を推定することに帰着するため、見積もりが容易な場合が多いです。Databricksチームは正確な見積もりを提供できますが、どのプロバイダーに対しても、次の2つの主要な計算を理解していることを確認してください。
FLOPS = 6 x parameters x tokens
この経験則は、計算量(およびコスト)がモデルサイズとデータサイズに線形に比例することを示しています。MoEsのようなスパースアーキテクチャの場合、「parameters」は「active parameters」に変換されることに注意してください。
Model FLOPS utilization (MFU) = average GPU utilization in practice
MFUは実際には100%になることはなく、しばしばはるかに低いです。異なるモデルやデータ型では、異なるMFUを達成する可能性があります。Databricksスタックは、最高のMFUを達成するように最適化されています。
エポックについてはどうでしょうか?
Nエポックのトレーニングは、1エポックのN倍のコストがかかります。しかし、事前学習では、トレーニングでいくつかの重要な高品質データを繰り返す場合でも、単一のエポックを使用するのが一般的です。これは、より伝統的な深層学習で使われる多くのエポックとは異なります。詳細については、 この論文を参照してください。
事前学習の計算コスト以外に、以下の見積もりも行ってください。
- デー�タコスト(購入、キュレーション、ラベリングを含む)
- 推論コスト
事前学習中
事前学習を開始すれば、Databricks上で「ただ動く」かもしれませんが、トレーニングを監視し、学習をデバッグまたは改善する方法を知ることは依然として重要です。Databricksチームは、問題の監視とデバッグをサポートできます。
監視には主に2つの領域があります。
- インフラストラクチャ: Databricks Trainingは、ほとんどのインフラストラクチャの問題を自動的に処理します。例えば、GPU、ネットワーク、その他のインフラストラクチャに障害が発生した場合、自動的にチェックポイントを作成し、トレーニングを再開します。ただし、特に非標準の構成を使用している場合は、利用状況を監視することが重要です。
- 学習の進捗: データや構成の問題を確認するために、学習データと評価データにおける損失やその他のメトリクスを監視する必要があります。最も一般的な兆候は、損失の急増と発散です。Databricks Trainingでは、ライブ監視と事後レビューのために、デフォルトで MLflow Experimentsへのログ記録を推奨しています。
デバッグでは、多くの場合、以下の調整が必要です。
- 構成: 構成��が適切に設定されていない場合、これらの問題は学習の早い段階で現れることがよくあります。学習率は、調整が必要となる最も一般的な構成です。
- データ: 例えば、一般的な学習の問題の1つに、不適切にシャッフルされたデータセットによる損失の急増があります。Databricks Trainingでは、 Mosaic Streamingライブラリを介してシャッフルを簡素化しますが、シャッフルにはコストがかかるため、Streamingは さまざまなシャッフル設定をサポートし、品質とコストのトレードオフに対応します。損失の急増が見られる場合、Streamingでより強力なシャッフル設定を行うことで、急増を防ぐことができる可能性があります。例えば、データが異なるバケット(ドメイン、言語など)から来ており、適切にシャッフルされていない場合、損失の急増が見られる可能性が高くなります。
カリキュラム学習: 事前学習は、単一の均質なデータセットでは実行されないことがよくあります。最終モデルは、学習プロセス中にデータミックスを変化させることで改善されることが多く、そのための最も一般的な手法は カリキュラム学習です。これは、学習の後期に、より高品質でターゲットを絞ったデータセットがデータミックスで強調される手法です。データミックスは事前に指定することも、特定の領��域でモデルを強化するために手動で調整することもできます。
事前学習後
事前学習後、モデルを最終的なアプリケーション向けに準備するためのさらなるステップがある場合があります。例えば、以下の通りです。
- モデルを微調整するためのさらなるカリキュラム学習または継続的な事前学習
- 指示に従う、またはチャットなどのための教師ありファインチューニング
- 人間のフィードバックからの強化学習 (RLHF) は、人間の好みに合わせてモデルを微調整するための高度な手法です。これは非常に強力ですが、正しく実装するには複雑であり、すべてのアプリケーションに必要というわけではありません。多くのアプリケーションでは、教師ありファインチューニングやガードレールで十分です。
- モデルまたはアプリケーションのエンドユーザー評価に基づいて、上記を反復する
未来
GenAI開発のペースは衰えることがありません。GPUやその他の特殊なハードウェアは、より高速かつ安価になります。ソフトウェアスタックは改善されます。新しいモデルアーキテクチャと学習手法は、研究から実践へと移行します。準備のために何ができるでしょうか?
Databricksを使用すると、多くの開発をデフォルトで活用できます。Databricks Model Training、Model Serving、およびその他の機能は、最新のトップモデルのサポートを引き続き追加します。新しい学習および推論技術は、内部で統合されます。より大規模で複雑�なワークロードの場合、Databricksは完全なカスタマイズをサポートし、最先端のワークロードはMosaic Researchチームと協力して行われます。
組織では、現在および将来にわたって柔軟でカスタマイズ可能なワークロードのサポートに注力してください。
- AIインフラストラクチャを開発する。AIゲートウェイを介してモデルAPIガバナンスを確立します。 AIセキュリティフレームワークを使用してセキュリティプロセスを確立します。データとAIガバナンスを Unity Catalogの下で標準化し、統合します。 Agent Frameworkを使用してインナーループを開発し、 Model Trainingを使用してアウターループを開発します。堅牢な MLOpsプラクティスを、 Model Servingと Monitoringを含めて開発します。
- AIの専門知識を開発する。Databricksチームと協力して、AIのCoE(Center of Excellence)を開発します。 Databricks Trainingを活用し、チームをそれぞれの役割に合わせた学習パスに沿って導きます。
- 知的財産を開発する。このIPには、カスタムモデルだけでなく、より重要なこととして、企業の データが含まれます。現在のアプリケーションやユーザーからデータを収集し、出所を追跡し、規制やライセンスに注意を払ってください。このデータは、インナーループでのRAGと、アウターループでのチューニングおよび事前学習の両方を含む、すべてのGenAIカスタマイズを強化します。
リソース
コース
- Get Started With Generative AIの自習型チュートリアルを修了してDatabricks認定資格を取得しましょう
- Generative AI Fundamentals (Databricks Academy)
- Generative AI Engineering with Databricks (インストラクター主導型トレーニングおよびDatabricks Academy)
- 新しいコースについては、 Databricks TrainingとDatabricks Academyをご覧ください
読み物
- The Big Book of Generative AIは、生成AIモデルとシステムの開発におけるさまざまな側面を深く掘り下げたブロ��グ記事のコレクションです
- A Compact Guide to Retrieval Augmented Generation (RAG)は、 エンタープライズデータで拡張されたLLMを使用して生成AIアプリケーションを構築することに関する詳細な解説です
- Mosaic Researchのブログ記事
- The Big Book of MLOps: 第二版は、DatabricksでのMLOps(LLMOpsを含む)に関する詳細な解説です
- Databricksページには、製品概要、機能の詳細、および多くのリソースへのリンクが掲載されています
- GenAIに関するDatabricksドキュメント( AWS、 Azure、および GCP向け)
Data + AI Summit 2024の講演
Databricksについて
DatabricksはデータとAIの企業です。Block、Comcast、Condé Nast、Rivian、Shell、そしてFortune 500企業の70%を含む世界中の10,000以上の組織が、Databricks Data Intelligence Platformを活用してデータを管理し、AIで活用しています。Databricksはサンフランシスコに本社を置き、世界中にオフィスを展開しており、Lakehouse、Apache SparkTM、Delta Lake、MLflowの生みの親たちによって設立されました。詳細については、Databricksの LinkedIn、 X、 Facebookをフォローしてください。
パーソナライズされたデモについては、お問い合わせください:
databricks.com/contact
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。