Introducing Photon Engine
Maximum performance for traditional analytics workloads on Delta Lake
by Adam Conway and Joel Minnick
Databricks Photon is now generally available on AWS and Azure.
Today, we announced Photon Engine, which ties together a 100% Apache Spark-compatible vectorized query engine to take advantage of modern CPU architecture with optimizations to Spark 3.0’s query optimizer and caching capabilities that were launched as part of Databricks Runtime 7.0. Together, these features significantly accelerate query performance on data lakes, especially those enabled by Delta Lake, to make it easier for customers to adopt and scale a lakehouse architecture.
Scaling Execution Performance
One of the big hardware trends over the last several years is that CPU clock speeds have plateaued. The reasons are outside the scope of this blog, but the takeaway is that we have to find new ways to process data faster beyond raw compute power. One of the most impactful methods has been to improve the amount of data that can be processed in parallel. However, data processing engines need to be specifically architected to take advantage of this parallelism.
In addition, data teams are being given less and less time to properly model data as the pace of business increases. Poorer modeling in the interest of better business agility drives poorer query performance. Naturally, this is not a desired state, and organizations want to find ways to maximize both agility and performance.
Announcing Photon Engine for high performance query execution
Photon Engine accelerates the performance of Delta Lake for SQL and data frame workloads through three components: an improved query optimizer, a caching layer that sits between the execution layer and the cloud object storage, and a native vectorized execution engine that’s written in C++.
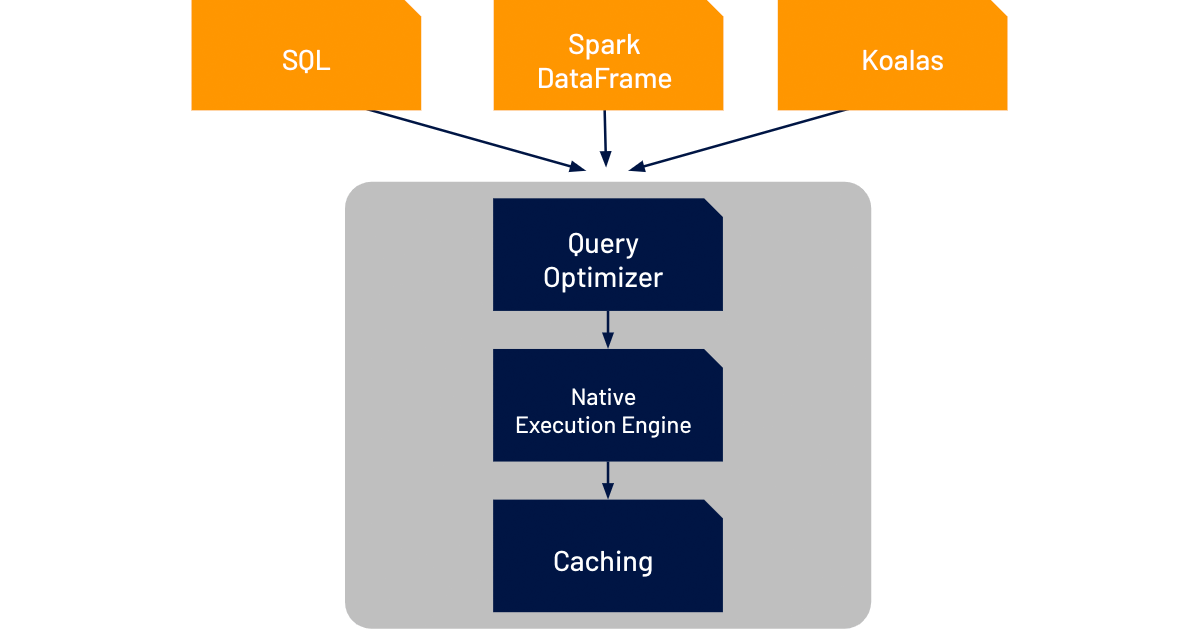
The improved query optimizer extends the functionality already in Spark 3.0 (cost-based optimizer, adaptive query execution, and dynamic runtime filters) with more advanced statistics to deliver up to 18x increased performance in star schema workloads.
Photon Engine’s caching layer automatically chooses which input data to cache for the user, transcoding it along the way in a more CPU-efficient format to better leverage the increased storage speeds of NVMe SSDs. This delivers up to 5x faster scan performance for virtually all workloads.
However, the biggest innovation in Photon Engine to tackle the challenges facing data teams today is the native execution engine, which we call Photon Engine. (We know. It’s in an engine within the engine...) This completely rewritten execution engine for Databricks has been built to maximize the performance from the new changes in modern cloud hardware. It brings performance improvements to all workload types, while remaining fully compatible with open Spark APIs.
In the near future, we’ll dive under the hood of Photon Engine in another blog to show you how it works and, most importantly, how it performs.
Getting started with Photon Engine
By linking these three components together, we think it will be easier for customers to understand how improvements in multiple places within the Databricks code aggregate into significantly faster performance for analytics workloads on data lakes. The improved query optimizer and caching improvements are available today, and we’ll be making Photon Engine available to increasingly more customers throughout the rest of the year.
We’re excited with the value that Photon Engine delivers to our customers. While the time and cost savings are already valuable, its role in the lakehouse pattern supports new advances in how data teams design their data architectures for increased unification and simplicity.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.