Announcing the Launch of Delta Live Tables: Reliable Data Engineering Made Easy
by Michael Armbrust, Awez Syed and Sam Steiny
As the amount of data, data sources and data types at organizations grow, building and maintaining reliable data pipelines has become a key enabler for analytics, data science and machine learning (ML). Prioritizing these initiatives puts increasing pressure on data engineering teams because processing the raw, messy data into clean, fresh, reliable data is a critical step before these strategic initiatives can be pursued.
At Data + AI Summit, we announced Delta Live Tables (DLT), a new capability on Delta Lake to provide Databricks customers a first-class experience that simplifies ETL development and management. DLT vastly simplifies the work of data engineers with declarative pipeline development, improved data reliability and cloud-scale production operations.
We developed this product in response to our customers, who have shared their challenges in building and maintaining reliable data pipelines. So let’s take a look at why ETL and building data pipelines are so hard.
Data teams are constantly asked to provide critical data for analysis on a regular basis. To do this, teams are expected to quickly turn raw, messy input files into exploratory data analytics dashboards that are accurate and up to date. While the initial steps of writing SQL queries to load data and transform it are fairly straightforward, the challenge arises when these analytics projects require consistently fresh data, and the initial SQL queries need to be turned into production grade ETL pipelines. This fresh data relies on a number of dependencies from various other sources and the jobs that update those sources. To solve for this, many data engineering teams break up tables into partitions and build an engine that can understand dependencies and update individual partitions in the correct order.
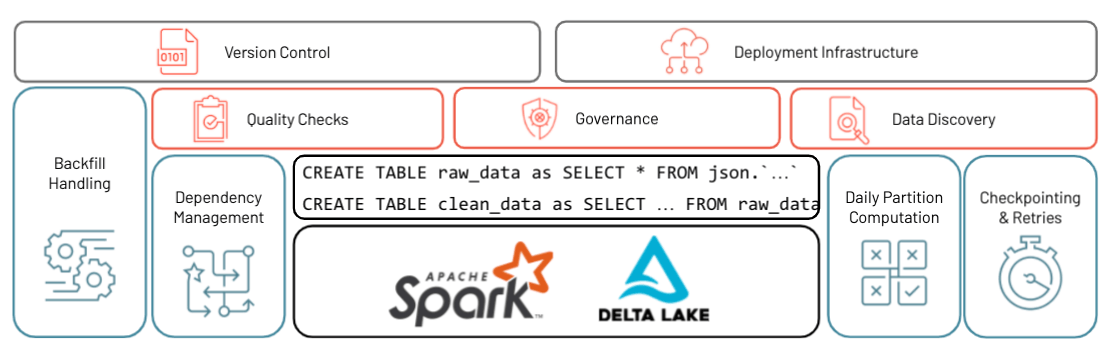
Once this is built out, check-points and retries are required to ensure that you can recover quickly from inevitable transient failures. On top of that, teams are required to build quality checks to ensure data quality, monitoring capabilities to alert for errors and governance abilities to track how data moves through the system. And once all of this is done, when a new request comes in, these teams need a way to redo the entire process with some changes or new feature added on top of it.
With all of these teams’ time spent on tooling instead of transforming, the operational complexity begins to take over, and data engineers are able to spend less and less time deriving value from the data.
Delta Live Tables
DLT enables data engineers to streamline and democratize ETL, making the ETL lifecycle easier and enabling data teams to build and leverage their own data pipelines by building production ETL pipelines writing only SQL queries. By just adding “LIVE” to your SQL queries, DLT will begin to automatically take care of all of your operational, governance and quality challenges. With the ability to mix Python with SQL, users get powerful extensions to SQL to implement advanced transformations and embed AI models as part of the pipelines.
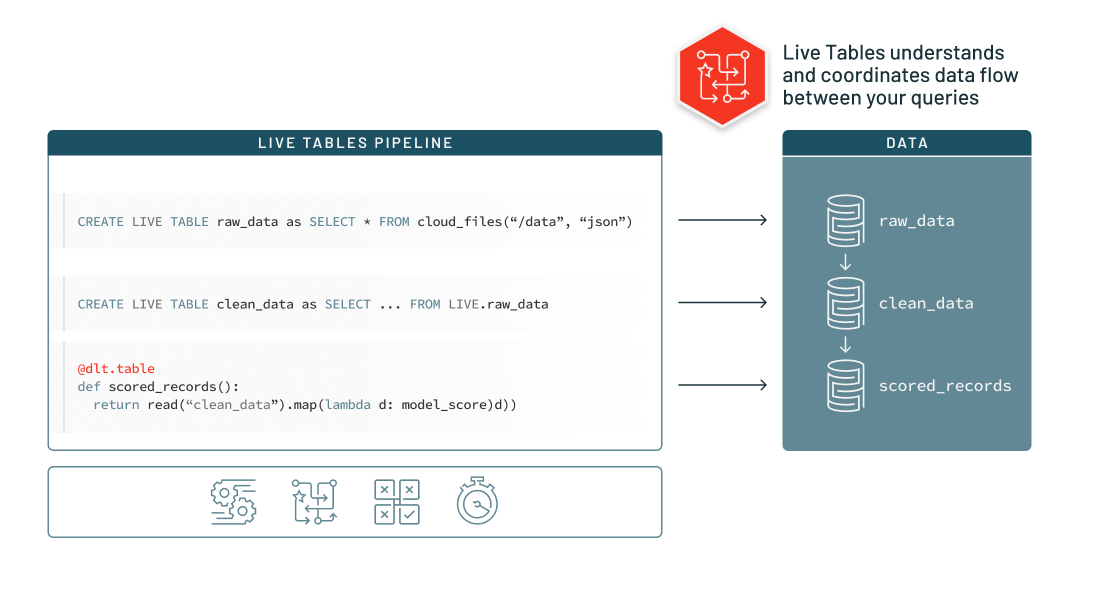
Understand your data dependencies
DLT takes the queries that you write to transform your data and instead of just executing them against a database, DLT deeply understands those queries and analyzes them to understand the data flow between them. Once it understands the data flow, lineage information is captured and can be used to keep data fresh and pipelines operating smoothly.
What that means is that because DLT understands the data flow and lineage, and because this lineage is expressed in an environment-independent way, different copies of data (i.e. development, production, staging) are isolated and can be updated using a single code base. The same set of query definitions can be run on any of those data sets.
The ability to track data lineage is hugely beneficial for improving change management and reducing development errors, but most importantly, it provides users the visibility into the sources used for analytics - increasing trust and confidence in the insights derived from the data.
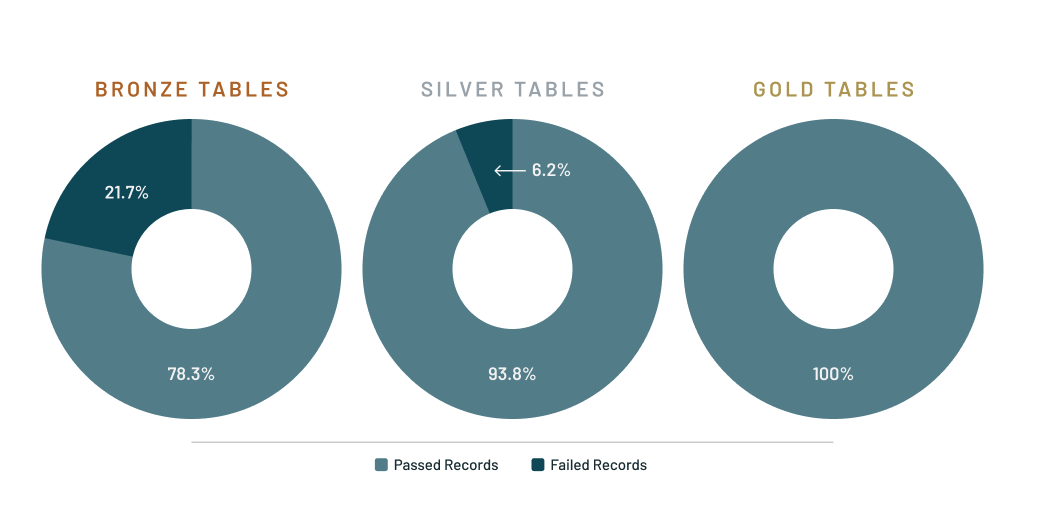
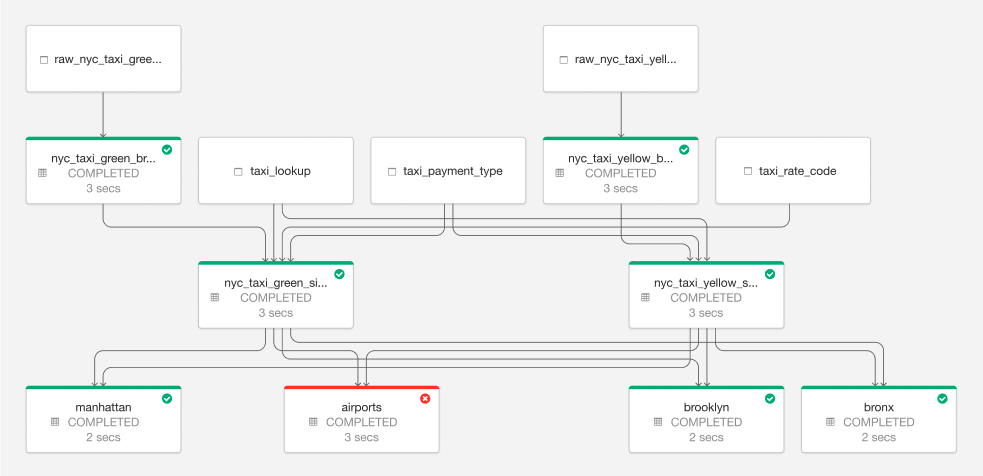
Gain deep visibility into your pipelines
DLT provides deep visibility into pipeline operations with detailed logging and tools to visually track operational stats and quality metrics. With this capability, data teams can understand the performance and status of each table in the pipeline. Data engineers can see which pipelines have run successfully or failed, and can reduce downtime with automatic error handling and easy refresh.
Treat your data as code
One of the core ideas we considered in building this new product, that has become popular across many data engineering projects today, is the idea of treating your data as code. Your data should be a single source of truth for what is going on inside your business. Beyond just the transformations, there are a number of things that should be included in the code that defines your data.
- Quality Expectations: With declarative quality expectations, DLT allows users to specify what makes bad data bad and how bad data should be addressed with tunable severity.
- Documentation with Transformation: DLT enables users to document where the data comes from, what it’s used for and how it was transformed. This documentation is stored along with the transformations, guaranteeing that this information is always fresh and up to date.
- Table Attributes: Attributes of a table (e.g., Contains PII) along with quality and operational information about table execution is automatically captured in the Event Log. This information can be used to understand how data flows through an organization and meet regulatory requirements.
With declarative pipeline development, improved data reliability and cloud-scale production operations, DLT makes the ETL lifecycle easier and enables data teams to build and leverage their own data pipelines to get to insights faster, ultimately reducing the load on data engineers.
“At Shell, we are aggregating all our sensor data into an integrated data store — working at the multi-trillion-record scale. Delta Live Tables has helped our teams save time and effort in managing data at this scale. We have been focusing on continuously improving our AI engineering capability and have an Integrated Development Environment (IDE) with a graphical interface supporting our Extract Transform Load (ETL) work. With this capability augmenting the existing lakehouse architecture, Databricks is disrupting the ETL and data warehouse markets, which is important for companies like ours. We are excited to continue to work with Databricks as an innovation partner.” — Dan Jeavons, General Manager —Data Science, Shell
Getting started
Delta Live Tables is currently in Gated Public Preview and is available to customers upon request. Existing customers can request access to DLT to start developing DLT pipelines here. Visit the Demo Hub to see a demo of DLT and the DLT documentation to learn more.
As this is a gated preview, we will onboard customers on a case-by-case basis to guarantee a smooth preview process. We have limited slots for preview and hope to include as many customers as possible. If we are unable to onboard you during the gated preview, we will reach out and update you when we are ready to roll out broadly.

Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.