Best Practices for High QPS Model Serving on Databricks
Power real-time ML applications natively within the Lakehouse
by Tejas Sundaresan, Anshul Gupta, Arjun DCunha and Mike Del Balso
- Model Serving supports real-time endpoints that scale to 300K+ QPS (CPU), with an enhanced engine specialized for low latency, real-time ML.
- Customers use Model Serving to power high QPS real-time ML applications like recommendation systems, fraud detection, search, and other use cases.
- Use route optimized endpoints, endpoint best practices, and client-side optimizations to achieve high performance targets when serving your models.
Customers expect instant responses across every interaction, whether it is a recommendation rendered in milliseconds, a fraudulent charge blocked before it clears, or a search result that feels immediate to the user. At scale, delivering these experiences depends on model serving systems that remain fast, stable, and predictable even under sustained and uneven load.
As traffic grows into the tens or hundreds of thousands of requests per second, many teams run into the same set of challenges. Latency becomes inconsistent, infrastructure costs increase, and systems require constant tuning to handle spikes and drops in demand. Failures also become harder to diagnose as more components are stitched together, pulling teams away from improving models and focusing instead on keeping production systems running.
This post explains how Model Serving on Databricks supports high QPS real time workloads and outlines concrete best practices you can apply to achieve low latency, high throughput, and predictable performance in production.
Databricks Model Serving: Simple, Scalable for High QPS Workloads
Databricks Model Serving provides a fully managed, scalable serving infrastructure directly within your Databricks lakehouse. Simply take an existing model in your model registry, deploy it, and obtain a REST endpoint on managed infrastructure that is highly scalable and optimized for high QPS traffic.
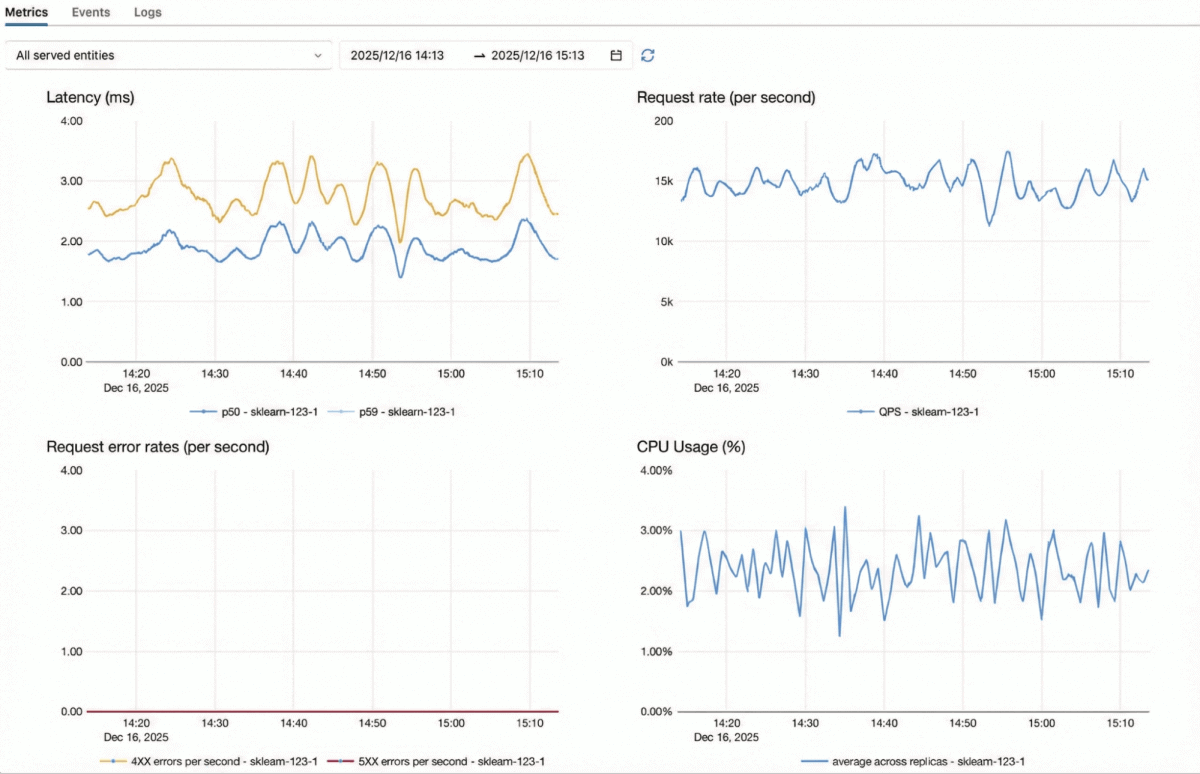
Databricks Model Serving is optimized for mission-critical high QPS workloads:
- Real Time Adaptive Engine – A self-optimizing model server that adapts to each model’s workload, driving greater throughput and resource utilization from the same hardware.
- Fully Horizontally Scalable Architecture – Our inference server, authentication layer, proxy, and rate limiter are all designed to scale out independently, allowing the system to sustain very high request volumes.
- Fast Elastic Scaling – Inference servers can scale up and down, adapting to sudden traffic spikes or drops without over-provisioning.
- Native Feature Store Integration: Databricks Feature Serving integrates seamlessly with Model Serving, enabling you to deploy features and models together as one complete application.
- Lakehouse Native: Customers can centralize features, training, MLOps via MLFlow, serving, and real time monitoring of their production ML systems in one unified stack, leading to reduced ops complexity and faster deployments.
Databricks Model Serving empowers our team to deploy machine learning models with the reliability and scale required for real-time applications. It is designed to handle high-QPS workloads while maximizing hardware utilization. On top of that, Databricks provides a SOTA Feature Store solution with super fast lookups needed for such workloads. With these capabilities, our ML engineers can focus on what matters: refining model performance and enhancing user experience. —Bojan Babic, Research Engineer, You.com
Best Practices for Achieving High QPS Performance on Model Serving
With this foundation in place, the next step is optimizing your endpoints, models, and client applications to consistently achieve high throughput and low latency, especially as traffic grows. The following best practices support real customer deployments running millions to billions of inferences every day.
Please see our best practices guide for more details.
Best Practice 1: Lower Latency via Using Route Optimized Endpoints
A key first step to ensure the network layer is optimized for high throughput/QPS and low latency. Model Serving does this for you through route optimized endpoints. When you enable route optimization on an endpoint, Databricks Model Serving optimizes the network and routing for inference requests, resulting in faster, more direct communication between your client and the model. This significantly decreases the amount of time a request takes to reach the model, and is especially useful for low-latency applications like recommendation systems, search, and fraud detection.

Best Practice 2: Optimize the Model and Make Endpoints Efficient
In high throughput scenarios, reducing model complexity, offloading processing from the serving endpoint, and picking the right concurrency targets helps your endpoint scale to large request volumes with just the right amount of compute needed. This way your endpoints are cost efficient but can still scale to hit performance targets.
- Model Size and Complexity: Smaller, less complex models generally lead to faster inference times and higher QPS. Consider techniques like model quantization or pruning if your model is large.
- Pre-processing and Post-processing: Offload complex pre-processing and post-processing steps from the serving endpoint whenever possible. This ensures your model serving endpoint only performs the crucial step of inference.
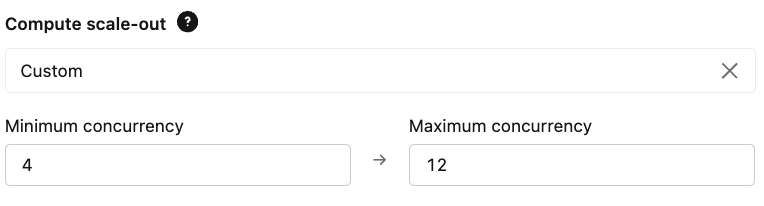
- Scaling: Configure your provisioned concurrency limits based on your expected QPS and latency requirements. This ensures the endpoint is sufficient to handle baseline load and the maximum allows for peak demand.
With Databricks Model Serving, we can handle high-QPS workloads like personalization and recommendations in real time. It gives our brands the scale and speed needed to deliver bespoke content experiences to our millions of readers. —Oscar Celma, SVP of Data Science and Product Analytics at Conde Nast
Best Practice 3: Optimize Client Side Code
Optimizing client-side code ensures requests get processed quickly and your endpoint compute instances are fully utilized - leading to better QPS throughput, cost savings and lower latency.
- Connection Pooling: Use connection pooling on the client side to reduce the overhead of establishing new connections for each request. The Databricks SDK always uses connection best practices, however, if you need to use your own client, be mindful about the connection management strategy.
- Payload Size: Keep request and response payloads as small as possible to minimize network transfer time.
- Client-Side Batching: If your application can send multiple requests in a single call, enable batching at the client side. This can significantly reduce the overhead per prediction.
Batch requests together when calling Databricks Model Serving Endpoints
Get Started Today
- Try out Databricks Model Serving! Start deploying ML models as a REST API.
- Dive Deeper: Please see the Databricks documentation for Custom Model Serving.
- High QPS Guide: Please check out the best practices guide for High QPS serving on Databricks Model Serving on Databricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.