Building a Regulatory Risk Copilot with Databricks Agent Bricks (Part 1: Information Extraction)
Learn how to transform unstructured FDA rejection letters into actionable insights using Databricks AI functions and Agent Bricks.
by Guanyu Chen and Diego Malaver
- Parse Complex PDFs: Unlike traditional approaches that require teams and thousands of lines of code, simply use the ai_parse_document() function to reliably parse text and images from complex PDF documents like FDA Complete Response Letters (CRLs).
- Collaboratively Extract Insights: Discover how to use the Information Extraction Agent Bricks to allow business experts and AI engineers to collaboratively define, test, and perfect the extraction of structured data in real-time.
- Productionalize with SQL: Single-click deployment of your perfected agent as a serverless endpoint and use the ai_query() function to build a scalable, production-ready pipeline for processing new documents directly within your Lakehouse.
In July 2025, the US FDA publicly released an initial batch of 200+ Complete Response Letters (CRLs), decision letters explaining why drug and biologic applications were not approved on first pass, marking a major transparency shift. For the first time, sponsors, clinicians and data teams can analyze the industry through the agency’s own language about deficiencies across clinical, CMC, safety, labeling, and bioequivalence, via centralized, downloadable open FDA PDFs.
As the FDA continues to release new CRLs, the ability to rapidly generate insight from this and other unstructured data, and add to their internal intelligence/data, becomes a major competitive advantage. Organizations that can effectively harness these unstructured data insights, in the form of PDFs, documents, images, and beyond, can de-risk their own submissions, identify common pitfalls, and ultimately accelerate their path to market. The challenge is that this data, like many other regulatory data, is locked in PDFs, which are notoriously difficult to process at scale.
This is precisely the type of challenge Databricks was built to solve. This blog demonstrates how to use Databricks' latest AI tooling to accelerate the extraction of key information trapped in PDFs - turning these critical letters into a source of actionable intelligence.
What it takes to be successful with AI
Given the technical depth required, engineers often lead development in a silo, creating a wide gap between the AI build and the business requirements. By the time a subject matter expert (SME) sees the result, it's often not what they needed. The feedback loop is too slow and the project loses momentum.
During early testing phases, it is crucial to establish a baseline. In many cases, alternative approaches require wasting months without ground truths, relying instead on subjective observation and “vibes”. This lack of empirical evidence stalls progress. Conversely, Databricks tooling provides evaluation features out-of-the-box and allows customers to emphasize quality immediately - using an iterative framework to gain mathematical confidence in the extraction. AI success requires a new approach built on rapid, collaborative iteration.
Databricks provides a unified platform where business SMEs and AI engineers can work together in real-time to build, test, and deploy production-quality agents. This framework is built on three key principles:
- Tight Business-Technical Alignment: SMEs and tech leads collaborate in the same UI for instant feedback, replacing slow email loops.
- Ground Truth Evaluation: Business-defined "ground truth" labels are built directly into the workflow for formal scoring.
- A Full Platform Approach: This isn't a sandbox or point solution; it’s fully integrated with automated pipelines, LLM-as-a-Judge evaluation, production-reliable GPU throughput, and end-to-end Unity Catalog governance.
This unified platform approach is what turns a prototype into a trusted, production-ready AI system. Let's walk through the four steps to build it.
From PDF to Production: A Four-Step Guide
Building a production-quality AI system on unstructured data requires more than just a good model; it requires a seamless, iterative, and collaborative workflow. The Information Extraction Agent Brick, combined with Databricks' built-in AI functions, makes it easy to parse documents, extract key information, and operationalize the entire process. This approach empowers teams to move faster and deliver higher-quality results. Breaking down the four key steps to build below.
Step 1: Parsing Unstructured PDFs into Text with ai_parse_document()
The first hurdle is getting clean text out of the PDFs. CRLs can have complex layouts with headers, footers, tables, charts, across multiple pages, and multiple columns. A simple text extraction will often fail, producing inaccurate, and unusable output.
Unlike fragile point solutions that struggle with layout, ai_parse_document() leverages state-of-the-art multimodal AI to understand document structure - accurately extracting text in reading order, preserving irregular table hierarchies, and generating captions for figures.
Additionally, Databricks delivers an advantage in document intelligence by reliably scaling to handle enterprise-level volumes of complex PDFs at 3-5x lower cost than leading competitors. Teams do not need to worry about file size limits, and the OCR and VLM under the hood ensure accurate parsing of historically “problem PDFs” containing dense, irregular figures and other challenging structures.
What once required numerous data scientists to configure and maintain bespoke parsing stacks across multiple vendors can now be accomplished with a single, SQL-native function - allowing teams to process millions of documents in parallel without the failure modes that plague less scalable parsers.
To get started, first, point a UC Volume at your cloud storage containing your PDFs. In our example, we’ll point the SQL function at the CRL PDFs managed by a Volume:
This single command processes all your PDFs and creates a structured table with the parsed content and the combined text, making it ready for the next step.
Note, we did not need to configure any infrastructure, networking or external LLM or GPU calls - Databricks hosts the GPUs and model backend, enabling reliable, scalable throughput without additional configuration. Unlike platforms that charge licensing fees, Databricks uses a compute-based pricing model - meaning you only pay for the resources you use. This allows for powerful cost optimizations through parallelization and function-level customization in your production pipelines.
Step 2: Iterative Information Extraction with Agent Bricks
Once you have the text, the next goal is to extract specific, structured fields. For example: What was the deficiency? What was the NDA ID? What was the rejection citation? This is where AI engineers and business SMEs need to collaborate closely. The SME knows what to look for, and can work with the engineer to quickly prompt the model on how to find it.
Agent Bricks: Information Extraction provides a real-time, collaborative UI for this exact workflow.
As shown below, the interface allows a technical lead and a business SME to work together:
- The Business SME provides specific fields that need to be extracted (e.g.,
deficiency_summary_paragraphs, NDA_ID, FDA_Rejection_Citing). - The Information Extraction Agent will translate these requirements into effective prompts - these editable guidelines are in the right-hand panel.
- Both the Tech Lead and Business SME can immediately see the JSON output in the center panel and validate if the model is correctly extracting the information from the document on the left. From here, either of the two can reformulate a prompt to ensure accurate extractions.
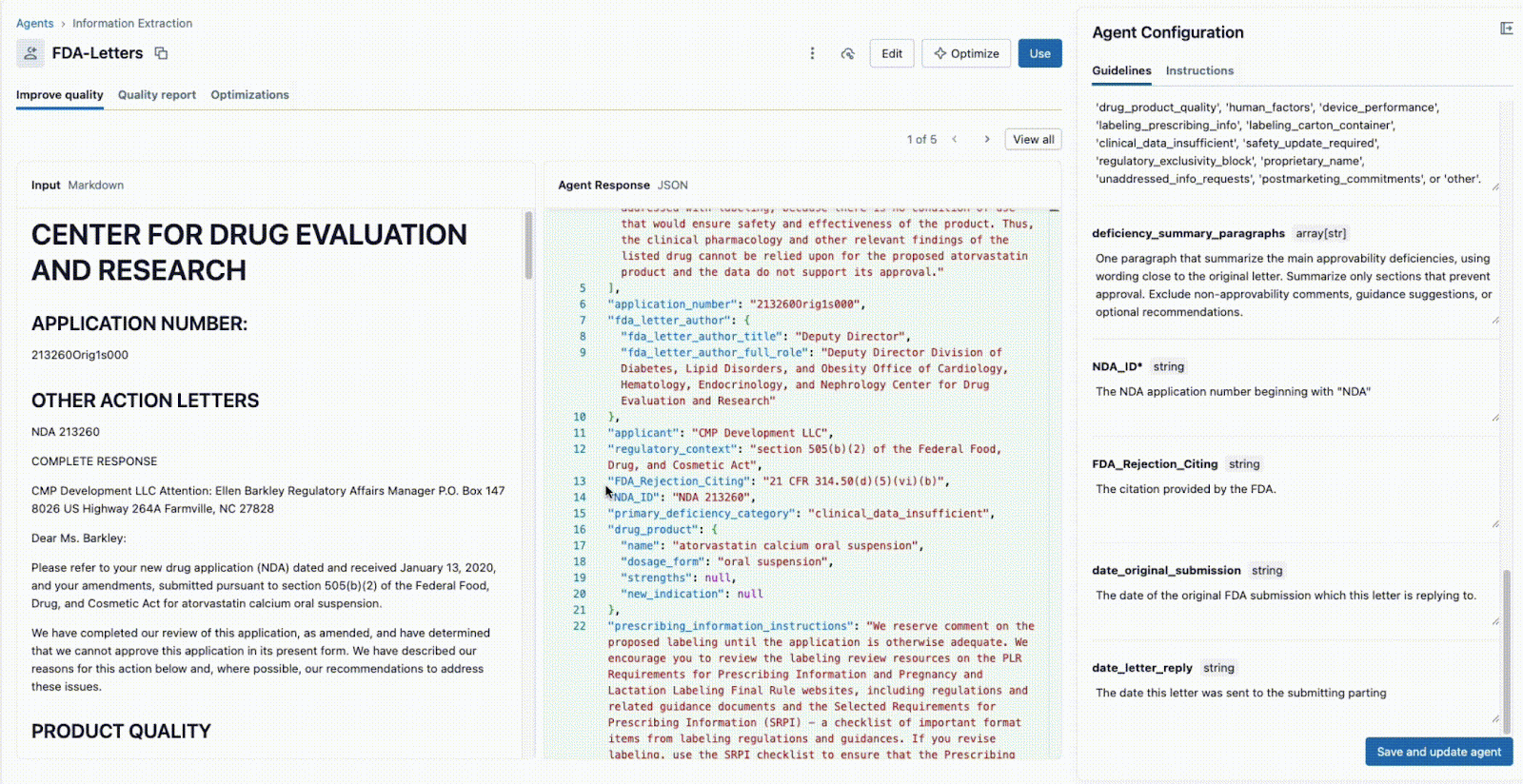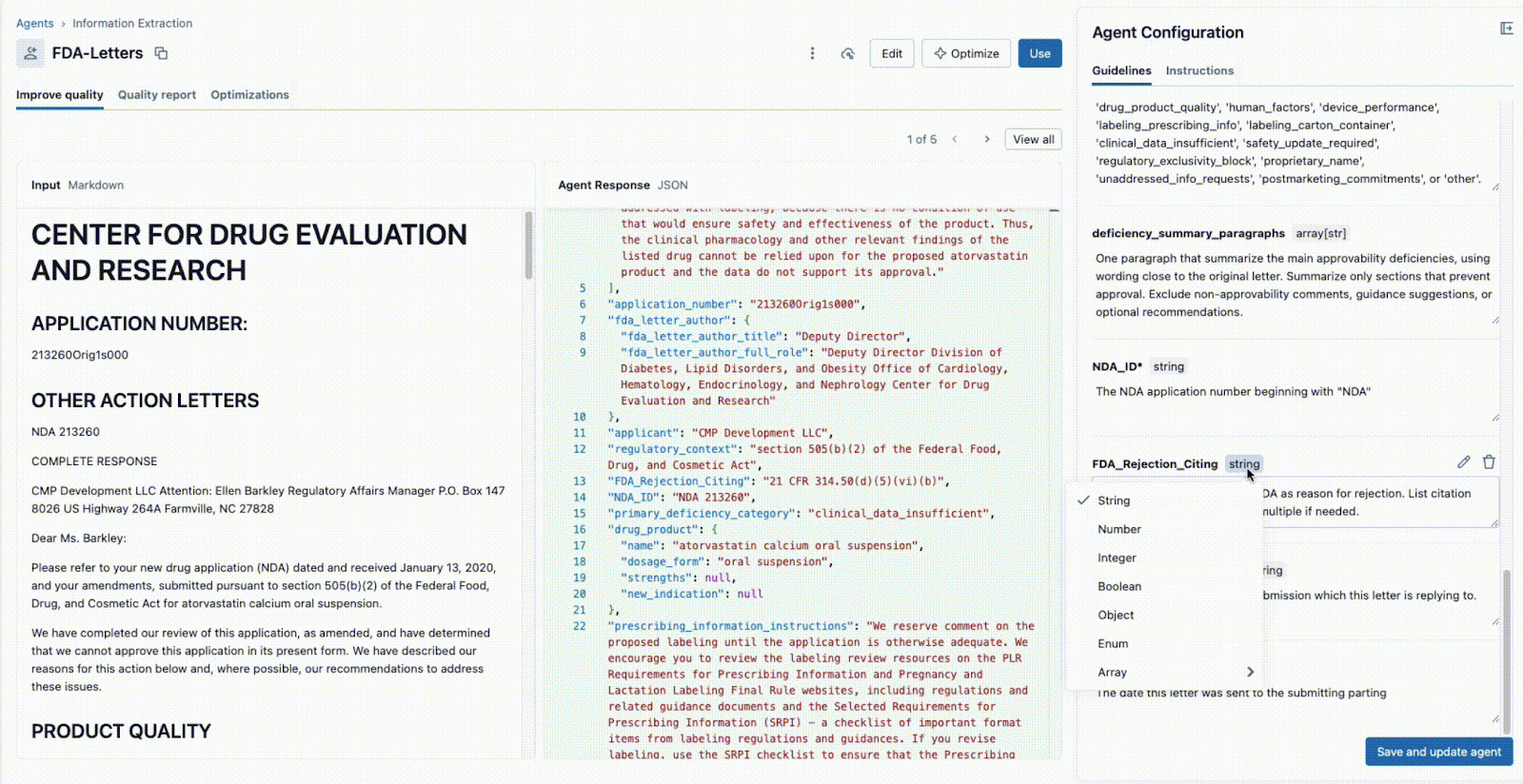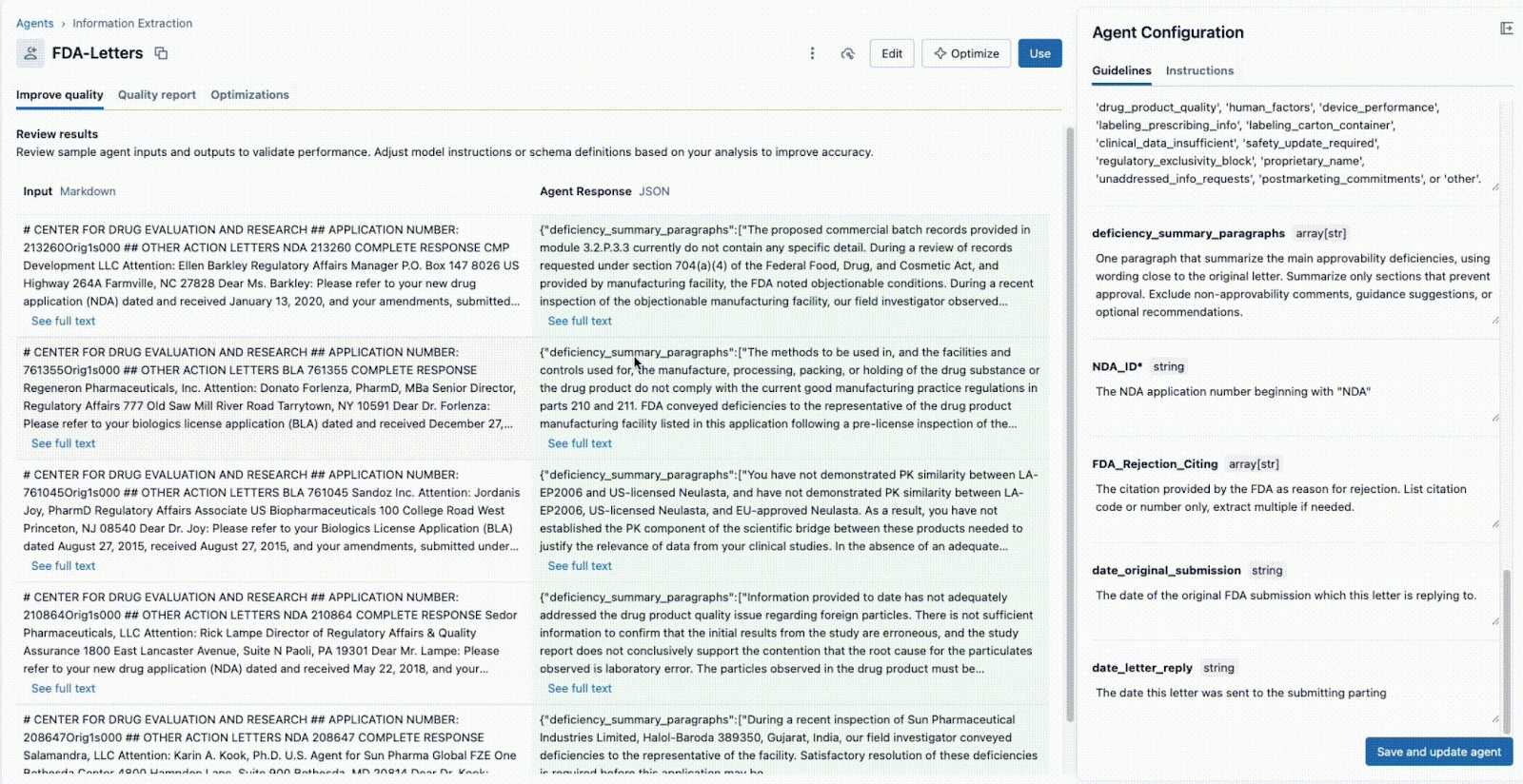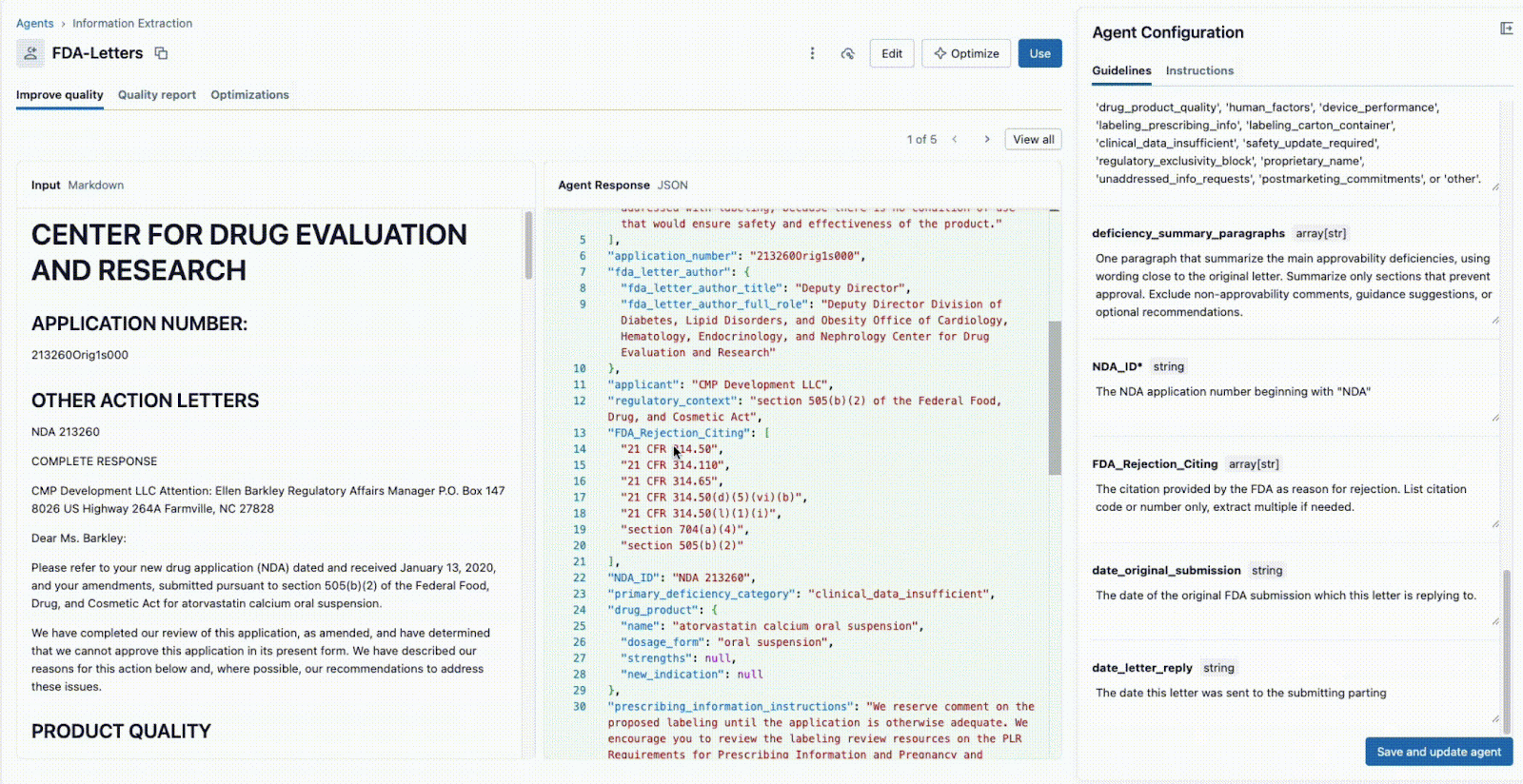
This instant feedback loop is the key to success. If a field is not extracted correctly, the team can tweak the prompt, add a new field, or refine the instructions and see the result in seconds. This iterative process, where multiple experts collaborate in a single interface, is what separates successful AI projects from ones that fail in silos.
Step 3: Evaluate and Validate the Agent
In Step 2, we built an agent that from a “vibe check”, looked correct during iterative development. But how do we ensure high accuracy and scalability when surfacing new data? A change in the prompt that fixes one document might break ten others. This is where formal evaluation - a critical and built-in part of the Agent Bricks workflow - comes in.
This step is your quality gate, and it provides two powerful methods for validation:
Method A: Evaluate with Ground Truth Labels (The Gold Standard)
AI, like any data science project, fails in a vacuum without proper domain knowledge. An investment from SMEs to provide a "golden set" (aka ground truth, labeled datasets) of manually extracted and human validated correct and relevant information, goes miles to ensure this solution generalizes across new files and formats. This is because labeled key:value pairs quickly help the agent tune high quality prompts which lead to business relevant and accurate extracts. Let’s dive into how Agent Bricks uses these labels to formally score your agent.
Within the Agent Bricks UI, provide the ground truth testset and, in the background, Agent Bricks runs across test documents. The UI will provide a side-by-side comparison of your agent's extracted output versus the "correct" labeled answer.
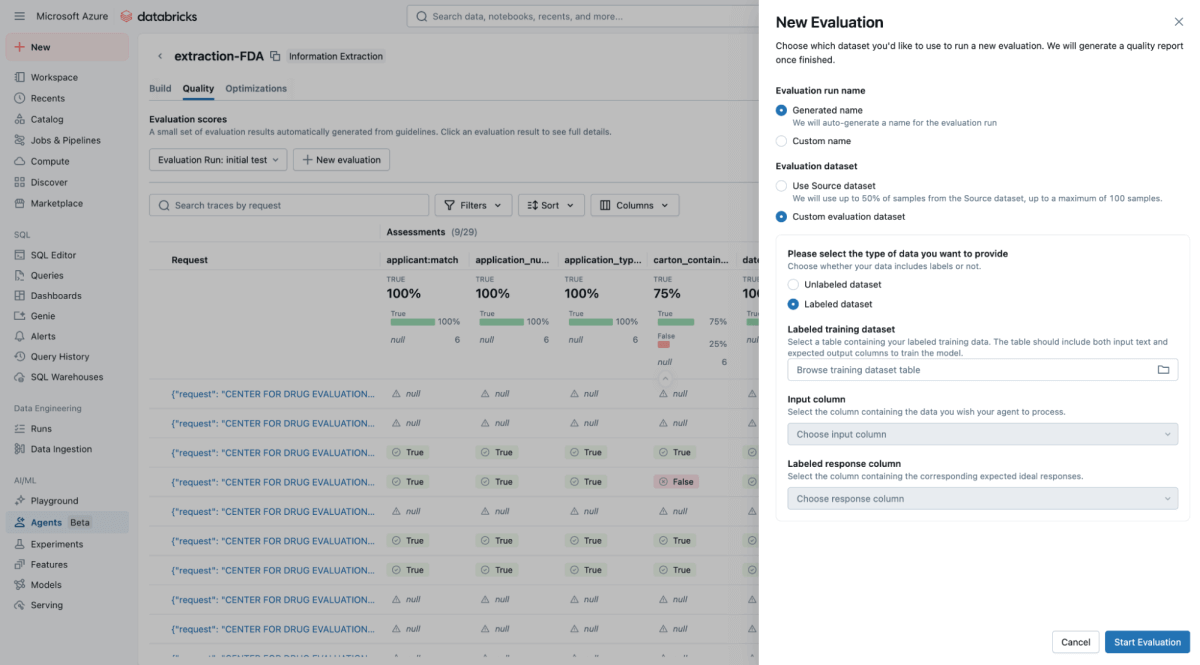
The UI provides a clear accuracy score for each extraction field which allows you to instantly spot regressions when you change a prompt. With Agent Bricks, you gain business-level confidence that the agent is performing at, or above, human-level accuracy.
Method B: No Labels? Use LLM-as-a-Judge
But what if you're starting from scratch and have no ground truth labels? This is a common "cold start" problem.
The Agent Bricks evaluation suite provides a powerful solution: LLM-as-a-Judge. Databricks provides a suite of evaluation frameworks, and Agent Bricks will leverage evaluation models to act as an impartial evaluator. The "Judge" model is presented with the original document text and a set of field prompts for each document. The role of the “Judge” is to generate an "expected" response and then evaluate it against the output extracted by the agent.
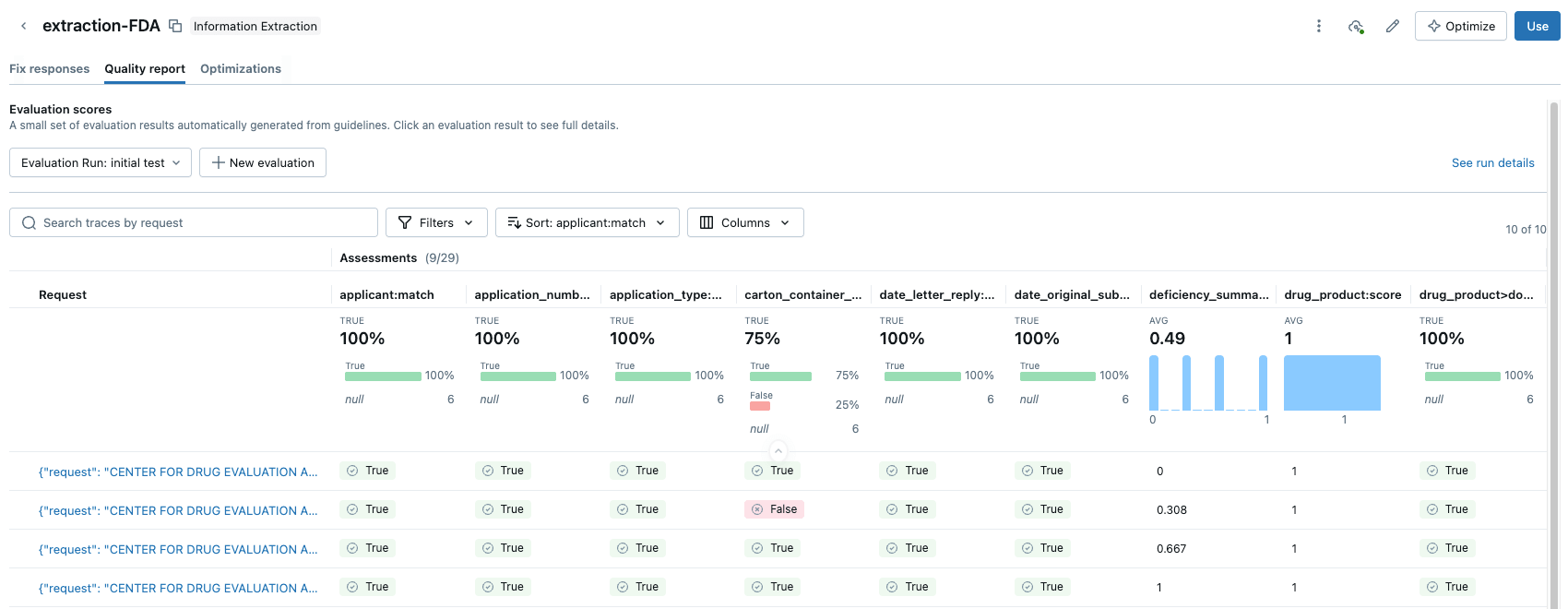
LLM-as-a-Judge allows you to get a scalable, high-quality evaluation score and, note, can also be used in production to ensure agents remain reliable and generalizable to production variability and scale. More on this in a future blog.
Step 4: Integrating the Agent with ai_query() in your ETL pipeline
At this point, you built your agent in Step 2 and validated its accuracy in Step 3, and now have the confidence to integrate the extraction into your workflow. With a single click, you can deploy your agent as a serverless model endpoint - immediately, your extraction logic is available as a simple, scalable function.
To do so, use the ai_query() function in SQL to apply this logic to new documents as they arrive. The ai_query() function allows you to invoke any model serving endpoint directly and seamlessly in your end-to-end ETL data pipeline.
With this, Databricks Lakeflow Jobs ensures you have a fully automated, production-grade ETL pipeline. Your Databricks Job takes raw PDFs landing in your cloud storage, parses them, extracts structured insights using your high quality agent, and lands them in a table ready for analysis, reporting, or referenced in a retrieval of a downstream agent application.
Databricks is the next-generation AI platform - one that breaks down the walls between deeply technical teams and the domain experts who hold the context needed to build meaningful AI. Success with AI isn’t just models or infrastructure; it’s the tight, iterative collaboration between engineers and SMEs, where each refines the other’s thinking. Databricks gives teams a single environment to co-develop, experiment quickly, govern responsibly, and put the science back in data science.
Agent Bricks is the embodiment of this vision. With ai_parse_document() to parse unstructured content, Agent Bricks: Information Extraction’s collaborative design interface to accelerate high quality extractions, and ai_query() to apply the solution in production-grade pipelines, teams can move from millions of messy PDFs to validated insights faster than ever.
In our next blog, we’ll show how to take these extracted insights and build a production-grade chat agent capable of answering natural-language questions like: “What are the most common manufacturing readiness issues for oncology drugs?”
- Learn more: Read the official documentation for ai_parse_document(), Agent Bricks: Information Extraction, and ai_query().
- Get Started: Sign up for a free trial of Databricks to build your own AI-powered solutions today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.