Databricks Lakehouse Data Modeling: Myths, Truths, and Best Practices
Data modeling maturity, combined with new capabilities, have closed the gap on most missing features of traditional enterprise data warehouses
by Shannon Barrow and Kyle Hale
- Relational and dimensional models thrive on Delta Lake with ACID, Photon, and metric views.
- Keys, constraints, and semantic layers are supported.
- New features like multi-statement transactions and Liquid Clustering simplify performance.
Data warehouses have long been prized for their structure and rigor, and yet many assume a lakehouse sacrifices that discipline. Here we dispel two related myths: that Databricks abandons relational modeling and that it doesn’t support keys or constraints. You’ll see that core principles like keys, constraints, and schema enforcement remain first-class citizens in Databricks SQL. Watch the full DAIS 2025 session here →
Modern data warehouses have evolved, and the Databricks Lakehouse is an excellent example of this evolution. Over the past four years, thousands of organizations have migrated their legacy data warehouses to the Databricks Lakehouse, gaining access to a unified platform that seamlessly combines data warehousing, streaming analytics, and AI capabilities. However, some features and capabilities of Classic Data Warehouses are not mainstays of Data Lakes. This blog dispels lingering data modeling myths and provides additional best practices for operationalizing your modern cloud Lakehouse.
This comprehensive guide addresses the most prevalent myths surrounding Databricks’ data warehousing functionality while showcasing the powerful new capabilities announced at Data + AI Summit 2025. Whether you're a data architect evaluating platform options or a data engineer implementing lakehouse solutions, this post will provide you with the definitive understanding of Databricks’ enterprise-grade data modeling capabilities.
- Myth #1: "Databricks doesn't support relational modeling."
- Myth #2: "You can't use primary and foreign keys."
- Myth #3: "Column-level data quality constraints are impossible."
- Myth #4: "You can't do semantic modeling without proprietary BI tools."
- Myth #5: "You shouldn't build dimensional models in Databricks."
- Myth #6: "You need a separate engine for BI performance."
- Myth #7: "Medallion architecture is required"
- BONUS Myth #8: "Databricks doesn't support multi-statement transactions."
The evolution from data warehouse to lakehouse
Before diving into the myths, it's crucial to understand what sets the lakehouse architecture apart from traditional data warehousing approaches. The lakehouse combines the reliability and performance of data warehouses with the flexibility and scale of data lakes, creating a unified platform that eliminates the traditional trade-offs between structured and unstructured data processing.
Databricks SQL features:
- Unified data storage on low-cost cloud object storage with open formats
- ACID transaction guarantees through Delta Lake
- Advanced query optimization with the Photon engine
- Comprehensive governance through Unity Catalog
- Native support for both SQL and machine learning workloads
This architecture addresses fundamental limitations of traditional approaches while maintaining compatibility with existing tools and practices.
Myth #1: "Databricks doesn't support relational modeling"
Truth: Relational principles are fundamental to the Lakehouse
Perhaps the most pervasive myth is that Databricks abandons relational modeling principles. This couldn't be further from the truth. The term "lakehouse" explicitly emphasizes the "house" component – structured, reliable data management that builds upon decades of proven relational database theory.
Delta Lake, the storage layer underlying every Databricks table, provides full support for:
- ACID transactions ensure data consistency
- Schema enforcement and evolution, maintaining data integrity
- SQL-compliant operations, including complex joins and analytical functions
- Referential integrity concepts through primary and foreign key definitions (these concepts are for query performance, but are not enforced)
Modern features like Unity Catalog Metric Views, now in Public Preview, depend entirely on well-structured relational models to function effectively. These semantic layers require proper dimensions and fact tables to deliver consistent business metrics across the organization.
Most importantly, AI and machine learning models – also known as "schema-on-read" approaches – perform best with clean, structured, tabular data that follows relational principles. The Lakehouse doesn't abandon structure; it makes structure more flexible and scalable.
Myth #2: "You can't use primary and foreign keys"
**Truth: Databricks has robust constraint support with optimization benefits**
Databricks has supported primary and foreign key constraints since Databricks Runtime 11.3 LTS, with full General Availability as of Runtime 15.2. These constraints serve multiple critical purposes:
- Informational constraints that document data relationships, with enforceable referential integrity constraints on the roadmap. Organizations planning their lakehouse migrations should design their data models with proper key relationships now to take advantage of these capabilities as they become available.
- Query optimization hints: For organizations that manage referential integrity in their ETL pipelines, the `RELY` keyword provides a powerful optimization hint. When you declare `FOREIGN KEY ... RELY`, you're telling the Databricks optimizer that it can safely assume referential integrity, enabling aggressive query optimizations that can dramatically improve join performance.
- Tool compatibility with BI platforms like Tableau and Power BI that automatically detect and utilize these relationships
Myth #3: "Column-level data quality constraints are impossible"
Truth: Databricks provides comprehensive data quality enforcement
Data quality is paramount in enterprise data platforms, and Databricks offers multiple layers of constraint enforcement that go beyond what traditional data warehouses provide.
The most common are simple Native SQL Constraints, including:
- CHECK constraints for custom business rules validation
- NOT NULL constraints for required field validation
Additionally, Databricks offers Advanced Data Quality Solutions that go beyond basic constraints to provide enterprise-grade data quality monitoring.
Lakehouse Monitoring delivers automated data quality tracking with:
- Statistical profiling and drift detection
- Custom metric definitions and alerting
- Integration with Unity Catalog for governance
- Real-time data quality dashboards
Databricks Labs DQX Library offers:
- Custom data quality rules for Delta tables
- DataFrame-level validations during processing
- Extensible framework for complex quality checks
These tools combined provide data quality capabilities that surpass traditional data warehouse constraint systems, offering both preventive and detective controls across your entire data pipeline.
Myth #4: "You can't do semantic modeling without proprietary BI tools"
Truth: Unity Catalog Metric Views revolutionize semantic layer management
One of the most significant announcements at Data + AI Summit 2025 was the Public Preview announcement of Unity Catalog Metric Views – a game-changing approach to semantic modeling that breaks free from vendor lock-in.
Unity Catalog Metric Views allow you to centralize Business Logic:
- Define metrics once at the catalog level
- Access from anywhere – dashboards, notebooks, SQL, AI tools
- Maintain consistency across all consumption points
- Version and govern like any other data asset
Unlike proprietary BI semantic layers, Unity Catalog Metrics are Open and Accessible:
- SQL-addressable – query them like any table or view
- Tool-agnostic – work with any BI platform or analytical tool
- AI-ready – accessible to LLMs and AI agents through natural language
This approach represents a fundamental shift from BI-tool-specific semantic layers to a unified, governed, and open semantic foundation that powers analytics across your entire organization.
Myth #5: "You shouldn't build dimensional models in Databricks"
Truth: Dimensional modeling principles thrive in the Lakehouse
Far from discouraging dimensional modeling, Databricks actively embraces and optimizes for these proven analytical patterns. Star and snowflake schemas translate exceptionally well to Delta tables, often offering superior performance characteristics compared to traditional data warehouses. These accepted Dimensional Modeling patterns offer:
- Business understandability – familiar patterns for analysts and business users
- Query performance – optimized for analytical workloads and BI tools
- Slowly changing dimensions – easy to implement with Delta Lake's time travel features
- Scalable aggregations – materialized views and incremental processing
Additionally, the Databricks Lakehouse provides unique benefits for dimensional modeling, including Flexible Schema Evolution and Time Travel Integration. To enjoy the best experience leveraging dimensional modeling on Databricks, follow these best practices:
- Use Unity Catalog's three-level namespace (catalog.schema.table) to organize your dimensional models
- Implement proper primary and foreign key constraints for documentation and optimization
- Leverage identity columns for surrogate key generation
- Apply liquid clustering on frequently joined columns
- Use materialized views for pre-aggregated fact tables
Myth #6: "You need a separate engine for BI performance"
Truth: The Lakehouse delivers world-class BI performance natively
The misconception that lakehouse architectures can't match traditional data warehouse performance for BI workloads is increasingly outdated. Databricks has invested heavily in query performance optimization, delivering results that consistently exceed traditional MPP data warehouses.
The cornerstone of Databricks' performance optimizations is the Photon Engine, which is specifically designed for OLAP workloads and analytical queries.
- Vectorized execution for complex analytical operations
- Advanced predicate pushdown minimizing data movement
- Intelligent data pruning leveraging dimensional model structures
- Columnar processing optimized for aggregations and joins
Additionally, Databricks SQL provides a fully managed, serverless warehouse experience that scales automatically for high-concurrency BI workloads and integrates seamlessly with popular BI tools. Our Serverless Warehouses combine best-in-class TCO and performance to deliver optimal response times for your analytical queries. Often overlooked in recent years are Delta Lake's Foundational benefits - i.e., file optimizations, advanced statistics collection, and data clustering on the open and efficient parquet data format. The resulting performance benefits that organizations migrating from traditional data warehouses to Databricks consistently report:
- Up to 10-50x faster query performance for complex analytical workloads
- High concurrency scaling without performance degradation
- Up to 90% cost reduction compared to traditional MPP data warehouses
- Zero maintenance overhead with serverless compute
Data + AI Summit 2025 brought even more exciting announcements and optimizations, including enhanced predictive optimization and automatic liquid clustering.
Myth #7: "Medallion architecture is required"
Truth: Medallion is a guideline, not a rigid requirement
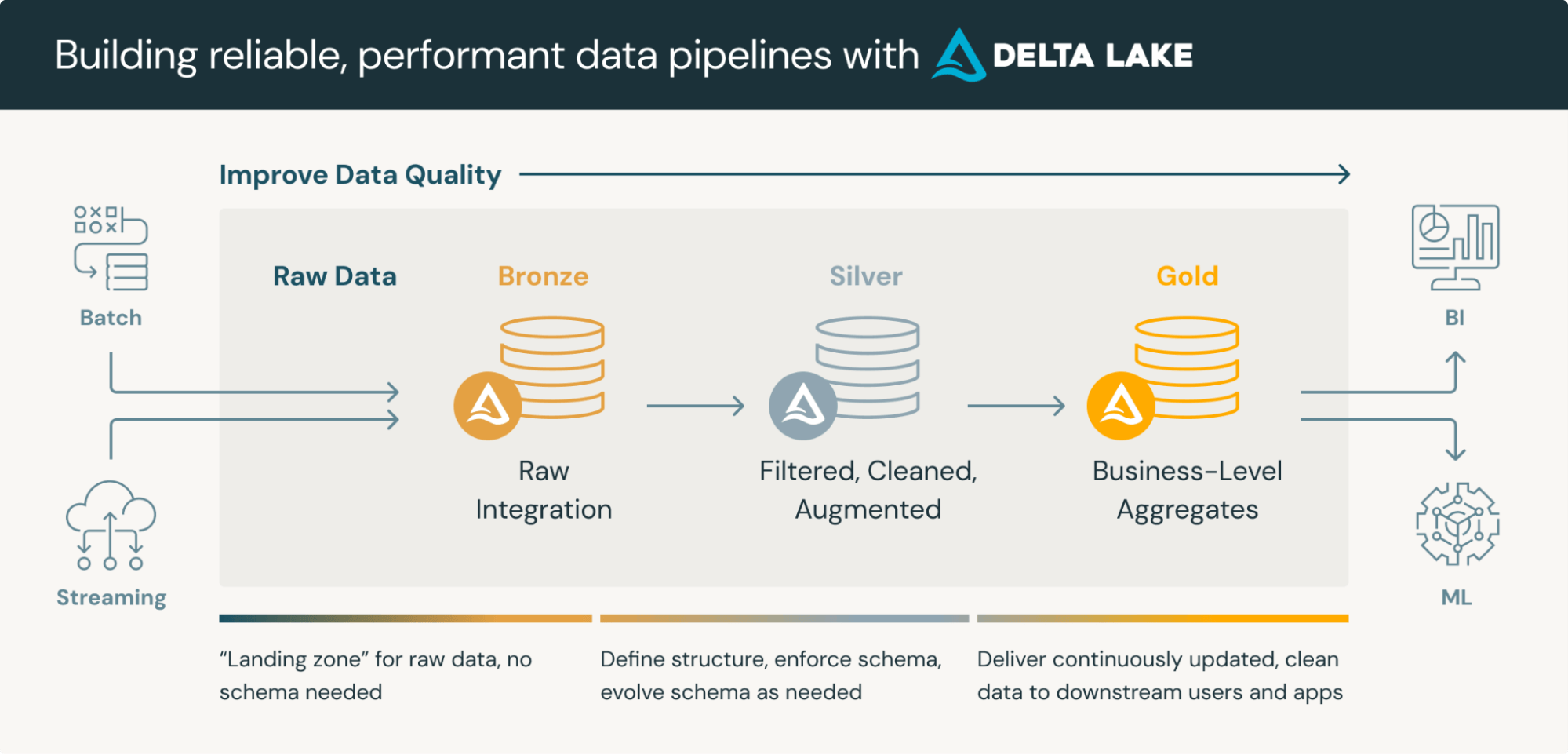
So, what is a medallion architecture? A medallion architecture is a data design pattern used to logically organize data in a lakehouse, with the goal of incrementally and progressively improving the structure and quality of data as it flows through each layer of the architecture (from Bronze ⇒ Silver ⇒ Gold layer tables). While the medallion architecture, also referred to as a "multi-hop" architecture, provides an excellent framework for organizing data in a lakehouse, it's essential to understand that it's a reference architecture, not a mandatory structure. The key to modeling on Databricks is to maintain flexibility while modeling real-world complexity, which can add or even remove layers of the medallion architecture as needed.
Many successful Databricks implementations may even combine modeling approaches. Databricks is capable of a myriad of Hybrid Modeling Approaches to accommodate Data Vault, star schemas, snowflake or Domain-Specific Layers to handle industry-specific data models (i.e. healthcare, financial services, retail).
The key is to use medallion architecture as a starting point and adapt it to your specific organizational needs while maintaining the core principles of progressive data refinement and quality improvement. There are many organizational factors that influence your Lakehouse Architecture, and the implementation should come after careful consideration of:
- Company size and complexity – larger organizations often need more layers
- Regulatory requirements – compliance needs may dictate additional controls
- Usage patterns – real-time vs. batch analytics affect layer design
- Team structure – data engineering vs. analytics team boundaries
BONUS Myth #8: "Databricks doesn't support multi-statement transactions"
Truth: Advanced transaction capabilities are now available
One of the capability gaps between traditional data warehouses and lakehouse platforms has been multi-table, multi-statement transaction support. This changed with the announcement of Multi-Statement Transactions at Data + AI Summit 2025. With the addition of MSTs, now in Private Preview, Databricks provides:
- Multi-format transactions across Delta Lake and Apache Iceberg™ tables
- Multi-table atomicity ensures all-or-nothing semantics
- Multi-statement consistency with full rollback capabilities
- Cross-catalog transactions spanning different data sources

Databricks’ approach offers significant advantages compared to its traditional data warehouse counterparts:
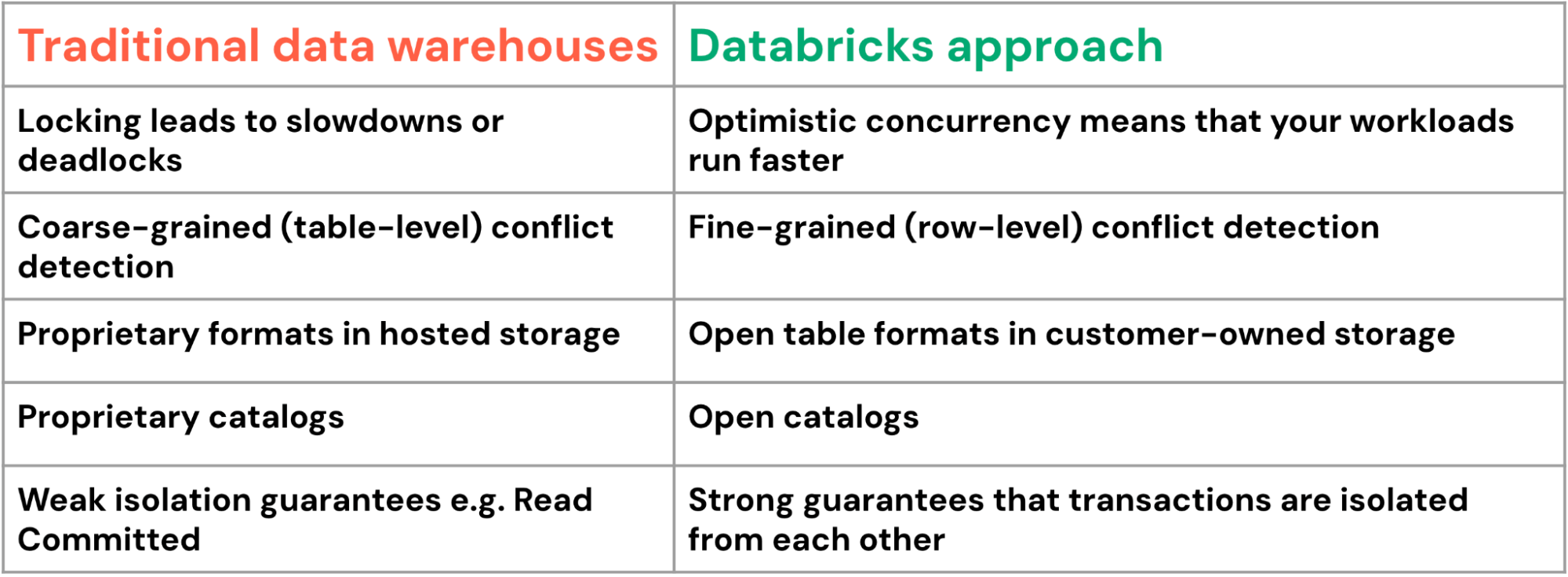
Multi-statement transactions are compelling for complex business processes like supply chain management, where updates to hundreds of related tables must maintain perfect consistency. Multi-statement transactions enable powerful patterns:
Consistent multi-table updates
Complex data pipeline orchestration
Conclusion: Embracing the modern data warehouse
Technological advancements and real-world implementations have thoroughly debunked the myths surrounding Databricks’ data warehousing capabilities. The platform not only supports traditional data warehousing concepts but also enhances them with modern capabilities that address the limitations of legacy systems.
For organizations evaluating or implementing Databricks for data warehousing:
- Start with proven patterns: Implement dimensional models and relational principles that your team understands
- Leverage modern optimizations: Use Liquid Clustering, Predictive Optimization, and Unity Catalog Metrics for superior performance.
- Design for scalability: Build data models that can grow with your organization and adapt to changing requirements
- Embrace governance: Implement comprehensive access controls and lineage tracking from day one.
- Plan for AI integration: Design your data warehouse to support future AI and machine learning initiatives
The Databricks Lakehouse represents the next evolution of data warehousing – combining the reliability and performance of traditional approaches with the flexibility and scale required for modern analytics and AI. The myths that once questioned its capabilities have been replaced by proven results and continuous innovation.
As we move forward into an increasingly AI-driven future, organizations that embrace the Lakehouse architecture will find themselves better positioned to extract value from their data, respond to changing business requirements, and deliver innovative analytics solutions that drive competitive advantage.
The question is no longer whether Lakehouse can replace traditional data warehouses—it's how quickly you can begin realizing its benefits to enterprise data management.
The Lakehouse architecture combines openness, flexibility, and full transactional reliability — a combination that legacy data warehouses struggle to achieve. From medallion to domain-specific models, and from single-table updates to multi-statement transactions, Databricks provides a foundation that grows with your business.
Ready to transform your data warehouse? The best data warehouse is a lakehouse! To learn more about Databricks SQL, take a product tour. Visit databricks.com/sql to explore Databricks SQL and see how organizations worldwide are revolutionizing their data platforms.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.