Hidden Technical Debt of GenAI Systems
The Unseen Costs of Generative AI: Managing Tool Sprawl, Opaque Pipelines, and Subjective Evaluations
by Jeanne Choo and Conor Murphy
- Developers working on classical ML and Generative AI allocate their time very differently
- Generative AI introduces new forms of technical debt that need to be paid down
- New development practices have to be introduced to address these novel forms of technical debt
Introduction
If we broadly compare classical machine learning and generative AI workflows, we find that the general workflow steps remain similar between the two. Both require data collection, feature engineering, model optimization, deployment, evaluation, etc. but the execution details and time allocations are fundamentally different. Most importantly, generative AI introduces unique sources of technical debt that can accumulate quickly if not properly managed, including:
- Tool sprawl - difficulty managing and selecting from proliferating agent tools
- Prompt stuffing - overly complex prompts that become unmaintainable
- Opaque pipelines - lack of proper tracing makes debugging difficult
- Inadequate feedback systems - failing to capture and utilize human feedback effectively
- Insufficient stakeholder engagement - not maintaining regular communication with end users
In this blog, we will address each form of technical debt in turn. Ultimately, teams transitioning from classical ML to generative AI need to be aware of these new debt sources and adjust their development practices accordingly - spending more time on evaluation, stakeholder management, subjective quality monitoring, and instrumentation rather than the data cleaning and feature engineering that dominated classical ML projects.
How are Classical Machine Learning (ML) and Generative Artificial Intelligence (AI) Workflows different?
To appreciate where the field is now, it’s useful to compare how our workflows for generative AI compare with what we use for classical machine learning problems. The following is a high-level overview. As this comparison reveals, the broad workflow steps remain the same, but there are differences in the execution details that lead to different steps getting emphasized. As we’ll see, generative AI also introduces new forms of technical debt, which have implications for how we maintain our systems in production.
| Workflow Step | Classical ML | Generative AI |
|---|---|---|
| Data collection | Collected data represents real-world events, such as retail sales or equipment failures. Structured formats, such as CSV and JSON, are often used. | Collected data represents contextual knowledge that helps a language model provide relevant responses. Both structured data (often in real time tables) and unstructured data (images, videos, text files) can be used. |
| Feature engineering/ Data transformation | Data transformation steps involve either creating new features to better reflect the problem space (e.g., creating weekday and weekend features from timestamp data) or doing statistical transformations so models fit the data better (e.g., standardizing continuous variables for k-means clustering and doing a log transform of skewed data so it follows a normal distribution). | For unstructured data, transformation involves chunking, creating embedding representations, and (possibly) adding metadata such as headings and tags to chunks. For structured data, it might involve denormalizing tables so that large language models (LLMs) don’t have to consider table joins. Adding table and column metadata descriptions is also important. |
| Model pipeline design | Usually covered by a basic pipeline with three steps:
| Usually involves a query rewriting step, some form of information retrieval, possibly tool calling, and safety checks at the end. Pipelines are much more complex, involve more complex infrastructure like databases and API integrations, and sometimes handled with graph-like structures. |
| Model optimization | Model optimization involves hyperparameter tuning using methods such as cross-validation, grid search, and random search. | While some hyperparameters, such as temperature, top-k, and top-p, may be changed, most effort is spent tuning prompts to guide model behavior. Since an LLM chain may involve many steps, an AI engineer may also experiment with breaking down a complex operation into smaller components. |
| Deployment | Models are much smaller than foundation models such as LLMs. Entire ML applications can be hosted on a CPU without GPUs being needed. Model versioning, monitoring, and lineage are important considerations. Model predictions rarely require complex chains or graphs, so traces are usually not used. | Because foundation models are very large, they may be hosted on a central GPU and exposed as an API to several user-facing AI applications. Those applications act as “wrappers” around the foundation model API and are hosted on smaller CPUs. Application version management, monitoring, and lineage are important considerations. Additionally, because LLM chains and graphs can be complex, proper tracing is needed to identify query bottlenecks and bugs. |
| Evaluation | For model performance, data scientists can use defined quantitative metrics such as F1 score for classification or root mean square error for regression. | The correctness of an LLM output relies on subjective judgments, e.g. of the quality of a summary or translation. Therefore, response quality is usually judged with guidelines rather than quantitative metrics. |
How are Machine Learning Developers Allocating Their Time Differently in GenAI Projects?
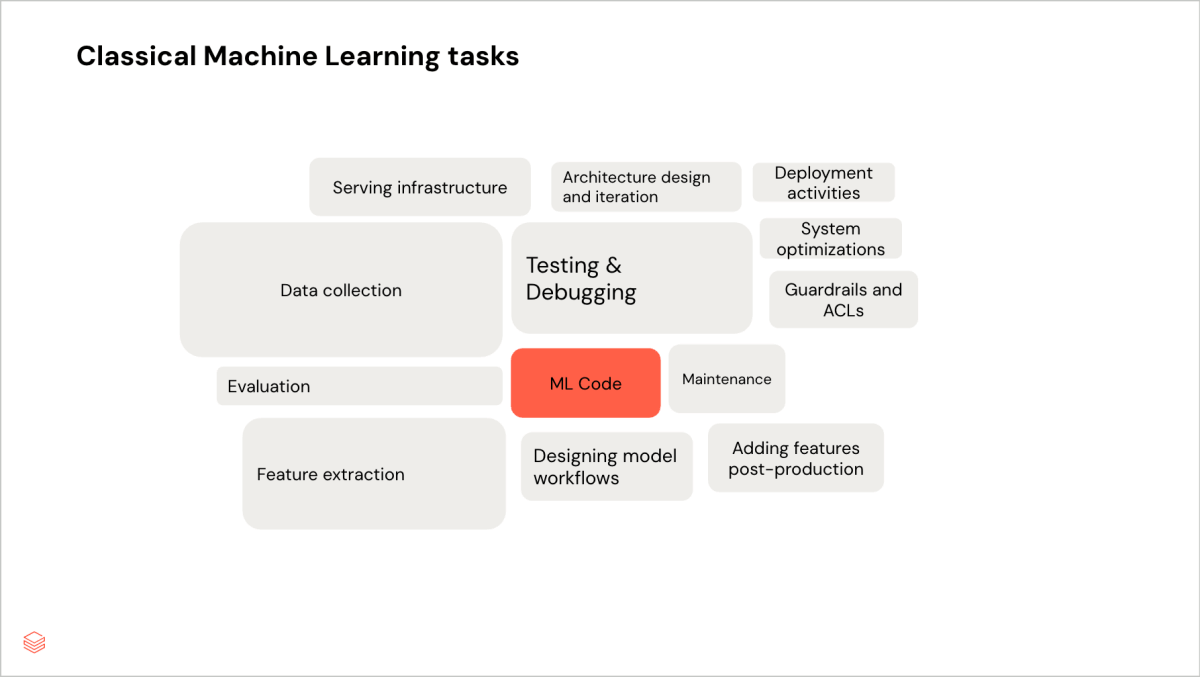
From first-hand experience balancing a price forecasting project with a project building a tool-calling agent, we found that there are some major differences in the model development and deployment steps.
Model development loop
The inner development loop typically refers to the iterative process that machine learning developers go through when building and refining their model pipelines. It usually occurs before production testing and model deployment.
Here’s how classic ML and GenAI professionals spend their time differently in this step:
Classical ML model development timesinks
- Data collection and feature refinement: On a classical machine learning project, most of the time is spent on iteratively refining features and input data. A tool for managing and sharing features, such as Databricks Feature Store, is used when there are lots of teams involved, or too many features to easily manage manually.
In contrast, evaluation is straightforward—you run your model and see whether there has been an improvement in your quantitative metrics, before returning to consider how better data collection and features can enhance the model. For example, in the case of our price forecasting model, our team observed that most mispredictions resulted from failing to account for data outliers. We then had to consider how to include features that would represent these outliers, allowing the model to identify those patterns.
Generative AI model and pipeline development timesinks
- Evaluation: On a generative AI project, the relative time allocation between data collection and transformation and evaluation is flipped. Data collection typically involves gathering sufficient context for the model, which can be in the form of unstructured knowledge base documents or manuals. This data does not require extensive cleaning. But evaluation is much more subjective and complex, and consequently more time-consuming. You are not only iterating on the model pipeline; you also need to iterate on your evaluation set. And more time is spent accounting for edge cases than with classical ML.
For example, an initial set of 10 evaluation questions might not cover the full spectrum of questions that a user might ask a support bot, in which case you’ll need to gather more evaluations, or the LLM judges that you have set up might be too strict, so that you need to reword their prompts to stop relevant answers from failing the tests. MLflow’s Evaluation Datasets are useful for versioning, developing, and auditing a “golden set” of examples that must always work correctly. - Stakeholder management: In addition, because response quality depends on end-user input, engineers spend much more time meeting with business end users and product managers to gather and prioritize requirements as well as iterate on user feedback. Historically, classical ML was often not broadly end user facing (e.g. time series forecasts) or was less exposed to non-technical users so the product management demands of generative AI is much higher. Gathering response quality feedback can be done via a simple UI hosted on Databricks Apps that calls the MLflow Feedback API. Feedback can then be added to an MLflow Trace and an MLflow Evaluation Dataset, creating a virtuous cycle between feedback and model improvement.
The following diagrams compare classical ML and generative AI time allocations for the model development loop.

Model deployment loop
Unlike the model development loop, the model deployment loop does not focus on optimizing model performance. Instead, engineers are focused on systematic testing, deployment, and monitoring in production environments.
Here, developers might move configurations into YAML files to make project updates easier. They might also refactor static data processing pipelines to run in a streaming fashion, using a more robust framework such as PySpark instead of Pandas. Finally, they need to consider how to set up testing, monitoring, and feedback processes to maintain model quality.
At this point, automation is essential, and continuous integration and delivery is a nonnegotiable requirement. For managing CI/CD for data and AI projects on Databricks, Databricks Asset Bundles are usually the tool of choice. They make it possible to describe Databricks resources (such as jobs and pipelines) as source files, and provide a way to include metadata alongside your project’s source files.
As in the model development stage, the activities that take the most time in generative AI versus classical ML projects in this stage are not the same.
Classical ML model deployment timesinks
- Refactoring: In a classical machine learning project, notebook code can be quite messy. Different dataset, feature, and model combinations are continuously tested, discarded, and recombined. As a result, significant effort may need to be spent on refactoring notebook code to make it more robust. Having a set code repository folder structure (like the Databricks Asset Bundles MLOps Stacks template) can provide the scaffolding needed for this refactoring process.
Some examples of refactoring activities include:- Abstracting helper code into functions
- Creating helper libraries so utility functions can be imported and reused multiple times
- Lifting configurations out of notebooks into YAML files
- Creating more efficient code implementations that run faster and more efficiently (e.g., removing nested
forloops)
- Quality monitoring: Quality monitoring is another timesink because data errors can take many forms and be hard to detect. In particular, as Shreya Shankar et al. note in their paper “Operationalizing Machine Learning: An Interview Study,” “Soft errors, such as a few null-valued features in a data point, are less pernicious and can still yield reasonable predictions, making them hard to catch and quantify.” What’s more, different types of errors require different responses, and determining the appropriate response isn’t always easy.
An additional challenge is that different types of model drift (such as feature drift, data drift, and label drift) need to be measured across different time granularities (daily, weekly, monthly), adding to the complexity. To make the process easier, developers can use Databricks Data Quality Monitoring to track model quality metrics, input data quality, and potential drift of model inputs and predictions within a holistic framework.
Generative AI model deployment timesinks
- Quality monitoring: With generative AI, monitoring also takes up a substantial amount of time, but for different reasons:
- Real-time requirements: Classical machine learning projects for tasks such as churn prediction, price forecasting, or patient readmission can serve predictions in batch mode, running perhaps once a day, once a week, or once a month. However, many generative AI projects are real-time applications such as virtual support agents, live transcription agents, or coding agents. Consequently, real-time monitoring tools need to be configured, which means real-time endpoint monitoring, real-time inference analysis pipelines, and real-time alerting.
Setting up API gateways (such as Databricks AI Gateway) to perform guardrail checks on LLM API can support safety and data privacy requirements. This is a different approach to traditional model monitoring, which is done as an offline process. - Subjective evaluations: As mentioned previously, evaluations for generative AI applications are subjective. Model deployment engineers have to consider how to operationalize collecting subjective feedback in their inference pipelines. This might take the form of LLM judge evaluations running on model responses, or selecting a subset of model responses to surface to a domain expert to evaluate. Proprietary model providers optimize their models over time, so their “models” are actually services prone to regressions and evaluation criteria has to account for the fact that model weights aren’t frozen like they are in self-trained models.
The ability to provide free-form feedback and subjective ratings takes center stage. Frameworks such as Databricks Apps and the MLflow Feedback API enable simpler user interfaces that can capture such feedback and tie that feedback back to specific LLM calls.
- Real-time requirements: Classical machine learning projects for tasks such as churn prediction, price forecasting, or patient readmission can serve predictions in batch mode, running perhaps once a day, once a week, or once a month. However, many generative AI projects are real-time applications such as virtual support agents, live transcription agents, or coding agents. Consequently, real-time monitoring tools need to be configured, which means real-time endpoint monitoring, real-time inference analysis pipelines, and real-time alerting.
- Testing: Testing is often more time-consuming in generative AI applications, for a few reasons:
- Unsolved challenges: Generative AI applications themselves are increasingly more complex, but evaluation and testing frameworks have yet to catch up. Some scenarios that make testing challenging include:
- Long multi-turn conversations
- SQL output that may or may not capture important details about an enterprise’s organizational context
- Accounting for the correct tools being used in a chain
- Evaluating multiple agents in an application
The first step in handling this complexity is usually to capture as accurately as possible a trace of the agent’s output (an execution history of tool calls, reasoning, and final response). A combination of automatic trace capture and manual instrumentation can provide the flexibility needed to cover the full range of agent interactions. For example, the MLflow Tracestracedecorator can be used on any function to capture its inputs and outputs. At the same time, custom MLflow Traces spans can be created within specific code blocks to log more granular operations. Only after using instrumentation to aggregate a reliable source of truth from agent outputs can developers begin to identify failure modes and design tests accordingly.
- Incorporating human feedback: It’s crucial to incorporate this input when assessing quality. But some activities are time-consuming. For example:
- Designing rubrics so annotators have guidelines to follow
- Designing different metrics and judges for different scenarios (for example, is an output safe versus is an output helpful)
In-person discussions and workshops are usually required to create a shared rubric of how an agent is expected to respond. Only after human annotators are aligned can their evaluations be reliably integrated into LLM-based judges, using functions like MLflow’smake_judgeAPI or theSIMBAAlignmentOptimizer.
- Unsolved challenges: Generative AI applications themselves are increasingly more complex, but evaluation and testing frameworks have yet to catch up. Some scenarios that make testing challenging include:
AI Technical Debt
Technical debt builds up when developers implement a quick-and-dirty solution at the expense of long-term maintainability.
Classical ML Technical Debt
Dan Sculley et al. have provided a great summary of the types of technical debt these systems can accumulate. In their paper “Machine Learning: The High-Interest Credit Card of Technical Debt,” they break these down into three broad areas:
- Data debt Data dependencies that are poorly documented, unaccounted for, or change silently
- System-level debt Extensive glue code, pipeline “jungles,” and “dead” hardcoded paths
- External changes Modified thresholds (such as the precision-recall threshold) or remove previously important correlations
Generative AI introduces new forms of technical debt, many of which may not be obvious. This section explores the sources of this hidden technical debt.
Tool sprawl
Tools are a powerful way to extend an LLM’s capabilities. However, as the number of tools used increases, they can become hard to manage.
Tool sprawl doesn’t only present a discoverability and reuse problem; it also can negatively affect the quality of a generative AI system. When tools proliferate, two key failure points come up:
- Tool selection: The LLM needs to be able to correctly select the right tool to call from a wide range of tools. If tools do roughly similar things, such as calling data APIs for weekly versus monthly sales statistics, making sure the right tool is called becomes difficult. LLMs will start to make mistakes.
- Tool parameters: Even after successfully selecting the right tool to call, an LLM still needs to be able to parse a user’s question into the correct set of parameters to pass to the tool. This is another failure point to account for, and it becomes particularly difficult when multiple tools have similar parameter structures.
The cleanest solution for tool sprawl is to be strategic and minimal with the tools a team uses.
However, the right governance strategy can help make managing multiple tools and access scalable as more and more teams integrate GenAI into their projects and systems. Databricks products Unity Catalog and AI Gateway are built for this type of scale.
Prompt stuffing
Even though state-of-the-art models can handle pages of instructions, prompts that are overly complex can introduce issues such as contradicting instructions or out-of-date information. This is especially the case when prompts are not edited, but are just appended to over time by different domain experts or developers.
As different failure modes come up, or new queries are added to the scope, it’s tempting to just keep adding more and more instructions to an LLM prompt. For example, a prompt might start by providing instructions to handle questions related to finance, and then branch out to questions related to product, engineering, and human resources.
Just as a “god class” in software engineering is not a good idea and should be broken up, mega-prompts should be separated into smaller ones. In fact, Anthropic mentions this in its prompt engineering guide, and as a general rule, having multiple smaller prompts rather than a long, complex one helps with clarity, accuracy, and troubleshooting.
Frameworks can help keep prompts manageable by tracking prompt versions and enforcing expected inputs and outputs. An example of a prompt versioning tool is MLflow Prompt Registry, while prompt optimizers such as DSPy can be run on Databricks to decompose a prompt into self-contained modules that can be optimized individually or as a whole.
Opaque pipelines
There’s a reason why tracing has been receiving attention lately, with most LLM libraries and tracking tools offering the ability to trace the inputs and outputs of an LLM chain. When a response returns an error—the dreaded “I’m sorry, I can’t answer your question”—examining the inputs and outputs of intermediate LLM calls is crucial for pinpointing the root cause.
I once worked on an application where I initially assumed that SQL generation would be the most problematic step of the workflow. However, inspecting my traces told a different story: The biggest source of errors was actually a query rewriter step where we updated entities in the user question to entities that matched our database values. The LLM would rewrite queries that didn’t need rewriting, or start stuffing the original query with all sorts of extra information. This would regularly then mess up the subsequent SQL generation process. Tracing helped here to rapidly identify the problem.
Tracing the right LLM calls can take time. It’s not enough to implement tracing out of the box. Properly instrumenting an app with observability, using a framework such as MLflow Traces, is a first step to making agent interactions more transparent.
Inadequate systems for capturing and utilizing human feedback
LLMs are remarkable because you can pass them a few simple prompts, chain the results together, and end up with something that seems to understand nuance and instructions really well. But go too far down this path without grounding responses with user feedback, and quality debt can build up quickly. This is where creating a “data flywheel” as soon as possible can help, which consists of three steps:
- Deciding on success metrics
- Automating how you measure these metrics, perhaps through a UI that users can use to give feedback on what’s working
- Iteratively adjusting prompts or pipelines to improve metrics
I was reminded of the importance of human feedback when developing a text-to-SQL application to query sports statistics. The domain expert was able to explain how a sports fan would want to interact with the data, clarifying what they would care about and providing other insights that I, as someone who rarely watches sports, would never have been able to think of. Without their input, the application I created likely would not have met the users’ needs.
Although capturing human feedback is invaluable, it’s usually painfully time-consuming. One first needs to schedule time with domain experts, then create rubrics to reconcile differences between experts, and then evaluate the feedback for improvements. If the feedback UI is hosted in an environment that business users can’t have access, circling with IT administrators to provide the right level of access can feel like an interminable process.
Building without regular stakeholder check-ins
Regularly consulting with end users, business sponsors, and adjacent teams to see whether you are building the right thing is table stakes for all kinds of projects. However, with generative AI projects, stakeholder communication is more crucial than ever before.
Why frequent, high-touch communication is important:
- Ownership and control: Regular meetings help stakeholders feel like they have a way to influence an application’s final quality. Rather than being critics, they can become collaborators. Of course, not all feedback is created equal. Some stakeholders will inevitably start requesting things that are premature to implement for an MVP, or are outside what LLMs can currently handle. Negotiating and educating everyone on what can and cannot be achieved is important. If not, another risk can appear: too many feature requests with no brake applied.
- We don’t know what we don’t know: Generative AI is so new that most people, technical and non-technical alike, don’t know what an LLM can and cannot handle properly. Developing an LLM application is a learning journey for all involved, and regular touchpoints are a way of keeping everyone informed.
There are many other forms of technical debt that may need to be addressed in generative AI projects, including by enforcing proper data access controls, putting guardrails in place to manage safety and prevent prompt injections, preventing costs from spiraling, and more. I’ve only included the ones that seem most important here, and that might easily be overlooked.
Conclusion
Classical ML and generative AI are different flavors of the same technical domain. While it’s important to be aware of the differences between them and consider the impact of these differences on how we build and maintain our solutions, certain truths remain constant: communication still bridges gaps, monitoring still prevents catastrophes, and clean, maintainable systems still outperform chaotic ones in the long run.
Want to assess your organization’s own AI maturity? Read our guide: Unlock AI value: The enterprise guide to AI readiness.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.