High-availability feature flagging at Databricks
How we built a zero-downtime feature flag system for Databricks' global infrastructure
- SAFE is Databricks' in-house feature flagging platform that enables engineers to decouple code deployment from feature enablement, allowing for safer rollouts and faster incident mitigation across hundreds of services
- This post describes SAFE's architecture, which handles >25,000 active flags and over 300 million evaluations per second with microsecond-scale latency through techniques like static dimension pre-evaluation and multi-tiered global delivery.
- The system achieves high reliability through layered resilience mechanisms including fail-static behavior, out-of-band delivery paths, and cold-start configuration bundles that ensure services continue operating even during delivery pipeline failures.
Shipping software quickly while maintaining reliability is a constant tension. As Databricks has grown, so has the complexity of safely rolling out changes across hundreds of services, multiple clouds, and thousands of customer workloads. Feature flags help us manage this complexity by separating the decision to deploy code from the decision to enable it. This separation allows engineers to isolate failures and mitigate incidents faster, without sacrificing shipping velocity.
One of the key components of Databricks' stability posture is our in-house feature flagging and experimentation platform, called "SAFE". Databricks engineers use SAFE on a daily basis to rollout features, control service behavior dynamically, and measure the effectiveness of their features with A/B experiments.
Background
SAFE was started with the "north star" goal of fully decoupling service binary releases from feature enablement, allowing teams to roll out features independently from their binary deployment. This allows for many side-benefits, like the ability to reliably ramp-up a feature to progressively larger populations of users, and quickly mitigate incidents caused by a rollout.
At Databricks' scale, serving thousands of enterprise customers across multiple clouds with a rapidly growing product surface area, we needed a feature flagging system that could meet our unique requirements:
- High standards for safety and change management. The main value proposition for SAFE was to improve the stability and operational posture of Databricks, so nearly all of the other requirements flowed from this.
- Multi-cloud, seamless global delivery across Azure, AWS, and GCP, with sub-millisecond flag evaluation latency to support high-throughput and latency-sensitive production services.
- Transparent support for all places where Databricks engineers write code, including our control plane, the Databricks UI, Databricks Runtime Environment, and Databricks' Serverless data plane.
- An interface that was opinionated enough about Databricks' release practices to make common flag releases "safe by default", yet flexible enough to support a large set of more esoteric use cases.
- Extremely rigorous availability requirements, as services cannot safely launch without flag definitions loaded.
After carefully considering these requirements, we ultimately opted to build a custom in-house feature flagging system. We needed a solution that could evolve alongside our architecture, and which would provide the governance controls required to safely manage flags across hundreds of services and thousands of engineers. Achieving our scaling and safety goals successfully required deep integration with our infrastructure data model, service frameworks, and CI systems.
As of late 2025, SAFE has approximately 25k active flags, with 4k weekly flag flips. At peak, SAFE runs over 300M evaluations per second, all while maintaining a p95 latency of ~10μs for flag evaluations.
This post explores how we built SAFE to meet these requirements and the learnings we've encountered along the way.
Feature Flags in Action
To start, we will discuss a typical user journey for a SAFE flag. At its core, a feature flag is a variable that can be accessed in a service's control flow which can take different values depending on conditions controlled from an external config. One extremely common use case for feature flags is to gradually enable a new code path in a controlled fashion, first starting with a small portion of traffic and gradually enabling globally.
SAFE users first start by defining their flag in their service code, and use it as a conditional gate to the new feature's logic:
The user then goes to the internal SAFE UI and registers this flag and selects a template to roll out their flag. This template defines a gradual rampup plan consisting of a list of ordered stages. Each stage is ramped up slowly by percentages. The user is presented with a UI that looks like this once the flag has been created:
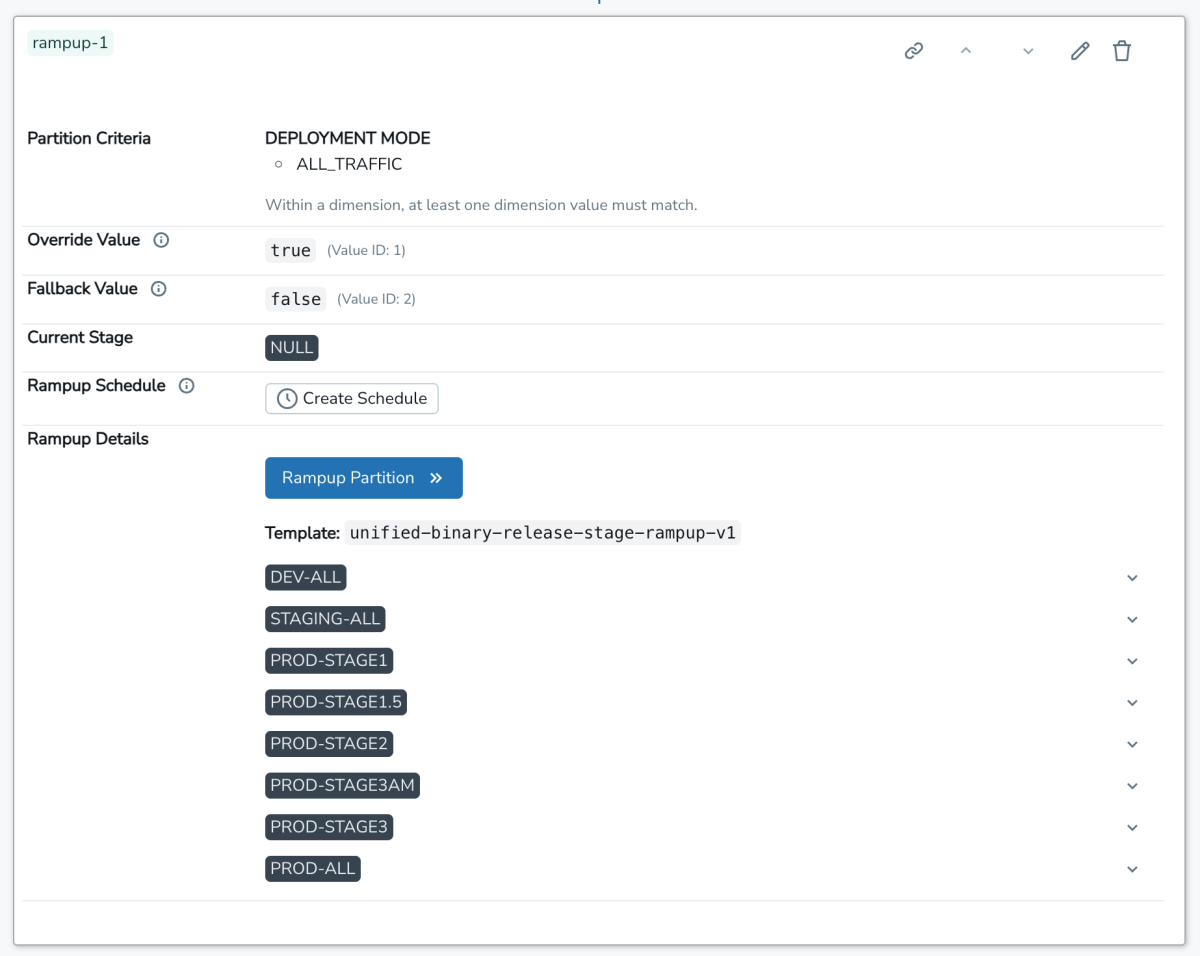
From here, the user can either manually roll out their flag one stage at a time, or set up a schedule to have the flag flips be created on their behalf. Internally, the source of truth for the flag configuration is a jsonnet file checked in to the Databricks monorepo, that uses a lightweight domain-specific language (DSL) to manage the flag config:
When users change a flag from the UI, the output of that change is a Pull Request that needs to be reviewed by at least one other engineer. SAFE also runs a variety of pre-merge checks to guard against unsafe or unintended changes. Once the change is merged, the user's service will pick up the change and start emitting the new value within 2-5 minutes of the PR being merged.
Use cases
Aside from the use case described above for feature rollout, SAFE is also used for other aspects of dynamic service configuration, such as: long-lived dynamic configurations (e.g. timeouts or rate limits), state machine control for infrastructure migrations, or to deliver small configuration blobs (e.g. targeted logging policies).
Architecture
Client Libraries
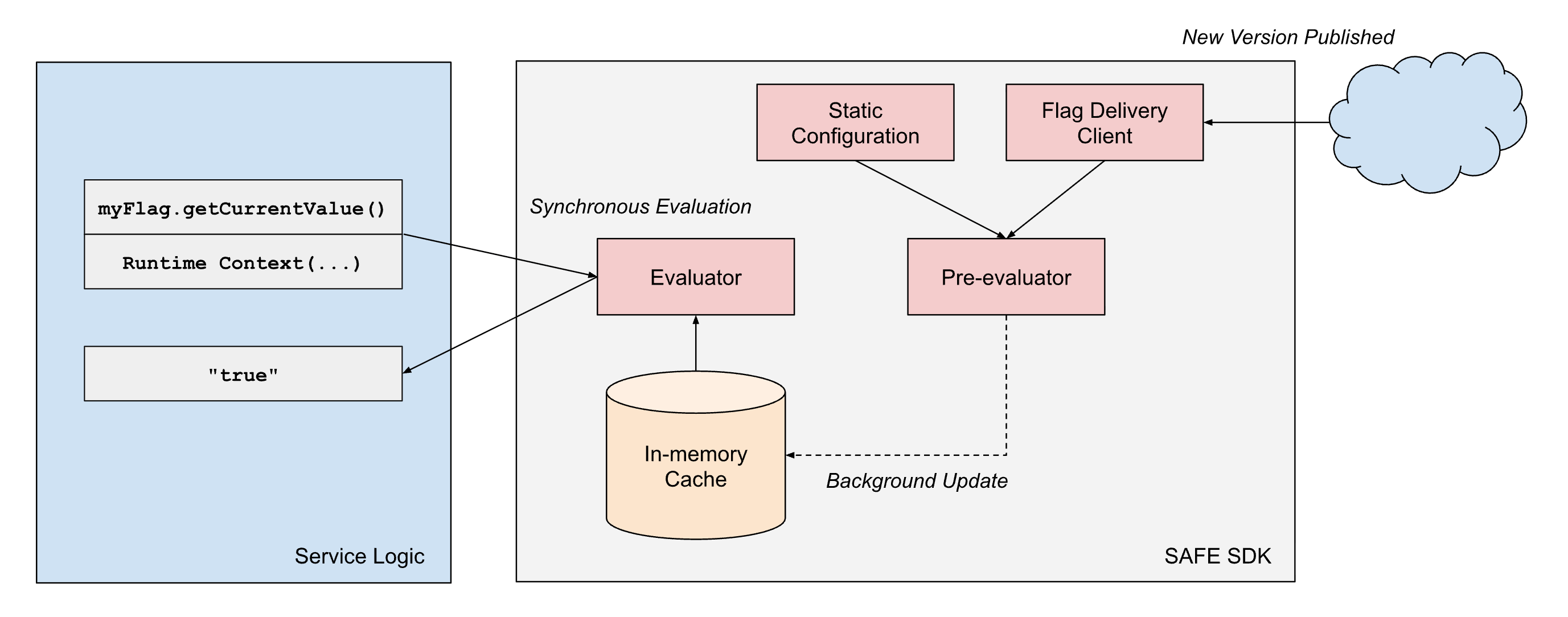
SAFE provides client "SDKs" in multiple internally supported languages, with the Scala SDK being the most mature and widely adopted. The SDK is essentially a criteria evaluation library, combined with a configuration loading component. For each flag, there is a set of criteria which control which value the SDK should return at runtime. The SDK manages loading the latest set of configuration, and needs to quickly return the result of evaluating that criteria at runtime.
In pseudocode, the criteria looks something like internally:
The criteria can be modeled as something akin to a sequence of boolean expression trees. Each conditional expression needs to be evaluated efficiently to return a quick result.
To meet our performance requirements, the SAFE SDK design embodies a few architectural principles: (1) separation of configuration delivery from evaluation, and (2) separation of static and runtime evaluation dimensions.
- Separation of delivery from evaluation: The SAFE client libraries always treat delivery as an asynchronous process, and never block the "hot path" of flag evaluation on configuration delivery. Once the client has a snapshot of a flag configuration, it will continue to return results based on that snapshot until an asynchronous background process does an atomic update of that snapshot to a newer snapshot.
- Separation of dimension types: Flag evaluation in SAFE operates on two types of dimensions:
- Static dimensions represent characteristics of the running binary itself, things like cloud provider, cloud region, and environment (dev/staging/prod). These values remain constant for the lifetime of a process.
- Runtime dimensions capture request-specific context, like workspace IDs, account IDs, application-provided values, and other per-request attributes that vary with each evaluation.
To reliably achieve sub-millisecond evaluation latency at scale, SAFE employs preevaluation of parts of the boolean expression tree which are static. When a SAFE configuration bundle is delivered to a service, the SDK immediately evaluates all static dimensions against the in-memory representation of the flag configuration. This produces a simplified configuration tree that contains only the logic relevant to that specific service instance.
When a flag evaluation is requested during request processing, the SDK only needs to evaluate the remaining runtime dimensions against this pre-compiled configuration. This significantly reduces the computational cost of each evaluation. Since many flags only use static dimensions in their boolean expression trees, many flags can effectively be entirely pre-evaluated.
Flag Delivery
To reliably deliver configuration to all services at Databricks, SAFE operates hand-in-hand with our in-house dynamic configuration delivery platform, Zippy. An in-depth description of the Zippy architecture is left as a topic for another post, but in short, Zippy uses a multi-tiered global/regional architecture and per-cloud blob storage to transport arbitrary configuration blobs from a central source to (among other surfaces) all Kubernetes pods running in the Databricks Control Plane.
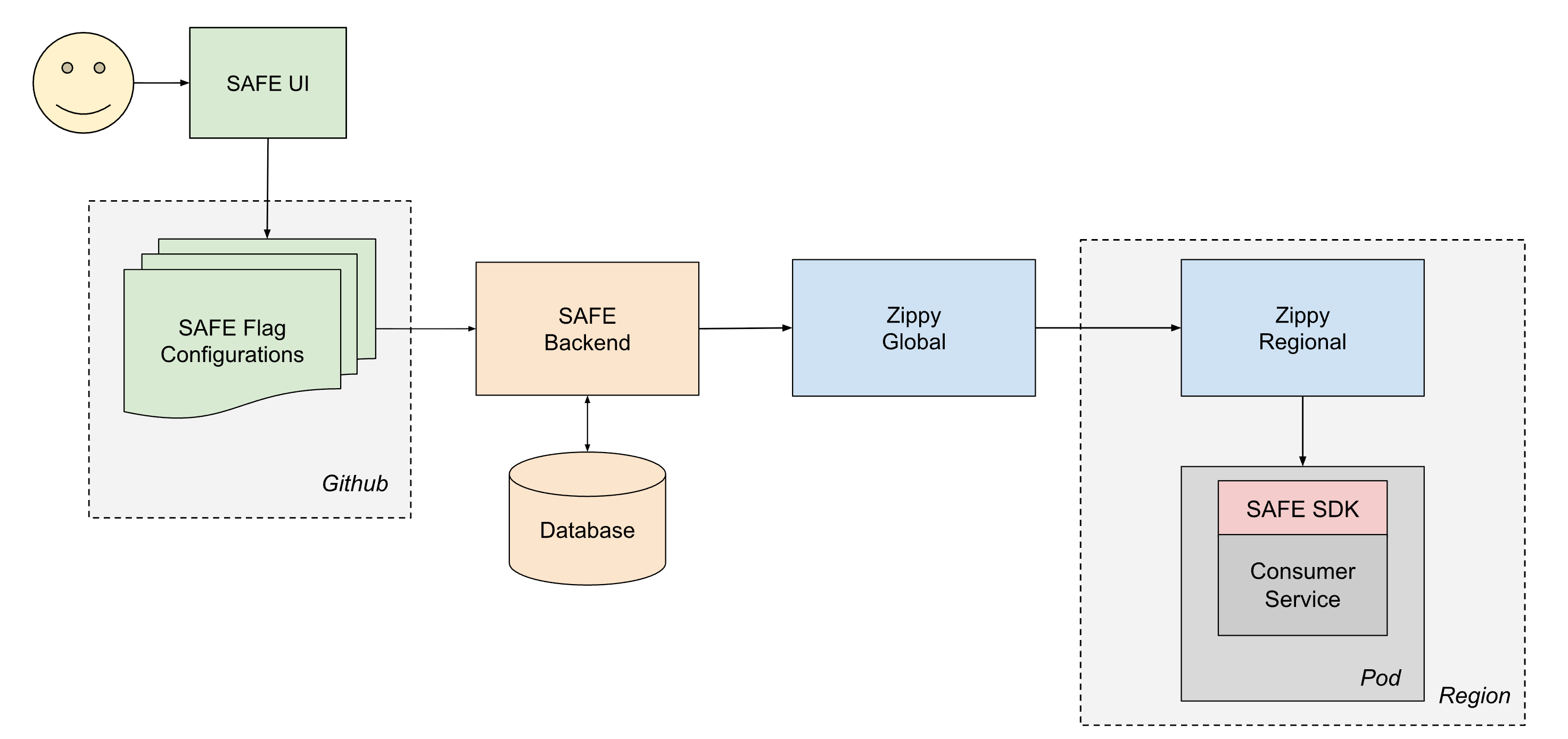
The life of a delivered flag is as follows:
- A user creates and merges a PR to one of their flag configuration jsonnet files, which then gets merged into the Databricks monorepo in Github.
- Within ~1 minute, a post-merge CI job picks up the modified file and sends it to the SAFE backend, which subsequently stores a copy of the new configuration in a database.
- Periodically (~1 minute intervals), the SAFE backend bundles up all the SAFE flag configurations and sends them to the Zippy Global backend.
- Zippy Global distributes these configurations to each of its Zippy Regional instances, within ~30 seconds.
- The SAFE SDK, running in each service pod, periodically receives the new version bundles using a combination of push and pull based delivery.
- Once delivered, the SAFE SDK can use the new configuration during evaluation.
End-to-end, a flag change typically propagates to all services within 3-5 minutes of a PR being merged.
Flag Configuration Pipeline
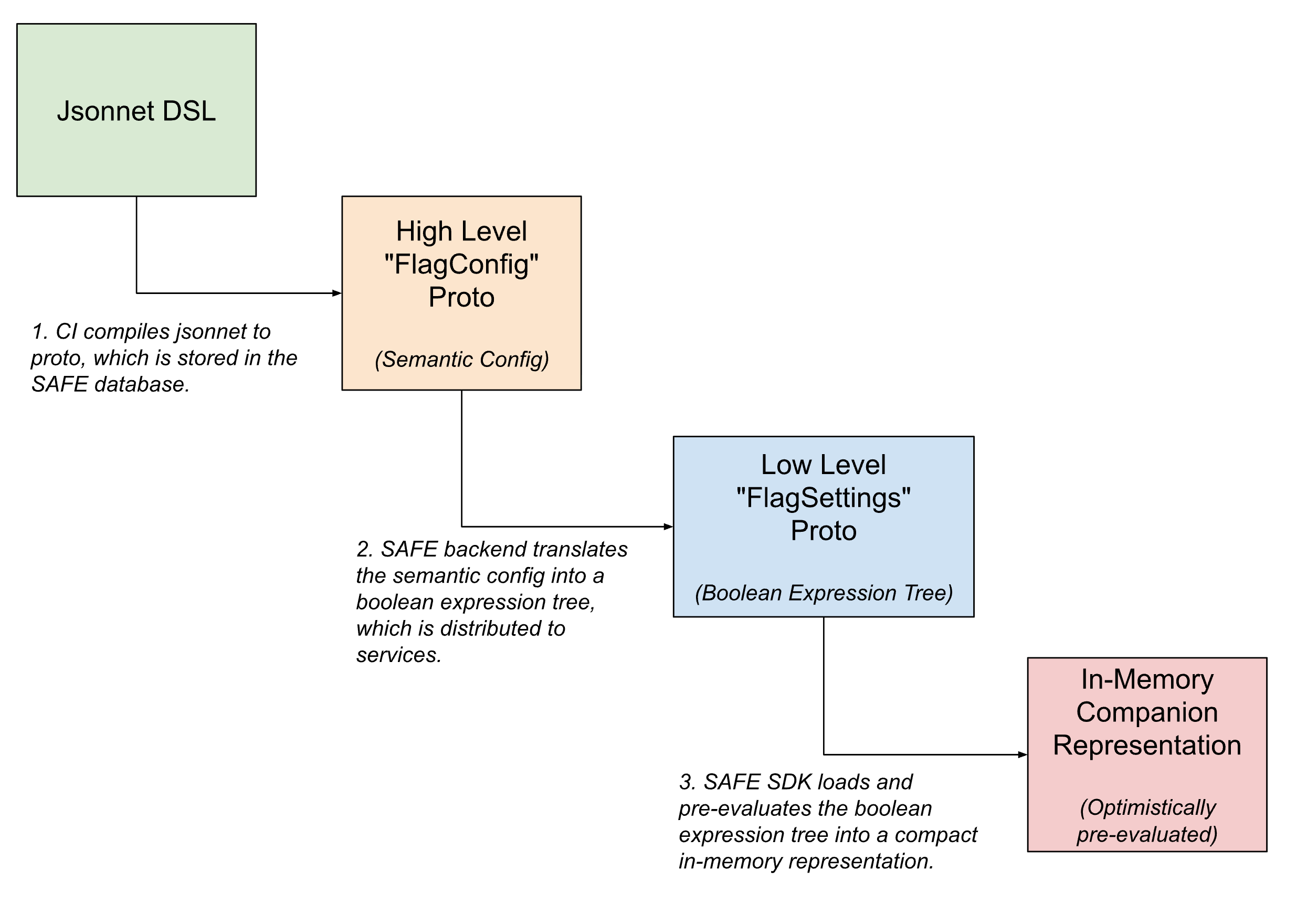
Within the flag delivery pipeline, the flag configurations take multiple forms – being progressively translated from higher-level, human readable semantic configurations to compact machine-readable versions as the flag gets closer to being evaluated.
In the user-facing interface, flags are defined using Jsonnet with a custom DSL to allow for arbitrarily complicated flag configurations. This DSL has affordances for common use cases, like configuring a flag to rollout using a pre-defined template, or for setting specific overrides on slices of traffic.
Once checked-in, this DSL is translated into an internal protobuf equivalent, which captures the semantic intent of the configuration. The SAFE backend then further translates this semantic configuration into a boolean expression tree. A protobuf description of this boolean expression tree is delivered to the SAFE SDK, which loads it into a further compacted in-memory representation of the configuration.
UI
Most flag flips are initiated from an internal UI for managing SAFE flags. This UI allows users to create, modify, and retire flags through a workflow that abstracts away much of the Jsonnet complexity for simple changes while still providing access to most of the full power of the DSL for advanced use cases.
A rich UI has also allowed us to surface additional quality-of-life features, such as the ability to schedule flag flips, support for post-merge health checks, and debugging tooling for determining recent flag flips which impacted a particular region or service.
Flag Config Review
All SAFE flag changes are created as normal Github PRs and are validated using an extensive set of pre-merge validators. This set of validators has grown to encompass dozens of individual checks, as we've learned more about how to best safeguard against potentially unsafe flag changes. During the initial introduction of SAFE, post-mortem reviews of incidents that were either caused by or mitigated through a SAFE flag flip informed many of these checks. We now have checks that, for example, require specialized review on large blast radius changes, require that a particular service binary version be deployed before a flag can be enabled, prevent subtle common misconfiguration patterns, and so on.
Teams can also define their own flag- or team-specific pre-merge checks, to enforce invariants for their configurations.
Handling Failure Modes
Given SAFE's critical role in service stability, the system is designed with multiple layers of resilience to ensure continued operation even when parts of the delivery pipeline fail.
The most common failure scenario involves disruptions to the configuration delivery path. If anything in the delivery path results in a failure to update configurations, services simply continue serving their last known configuration until the delivery path is restored. This "fail static" approach ensures that existing service behavior remains stable even during upstream outages.
For more severe scenarios, we maintain multiple fallback mechanisms:
- Out-of-band delivery: If any piece of CI or Github push path is unavailable, operators can push configurations directly to the SAFE backend using emergency tooling.
- Regional failover: If the SAFE backend or Zippy Global are down, operators can temporarily push configurations directly to Zippy Regional instances. Services can also poll cross-region to mitigate the impact of a single Zippy Regional outage.
- Cold-start bundles: To handle cases where Zippy itself is unavailable during service startup, SAFE periodically distributes configuration bundles to services via an artifact registry. While these bundles may be a few hours stale, they provide sufficient backup for services to start safely rather than blocking on live delivery.
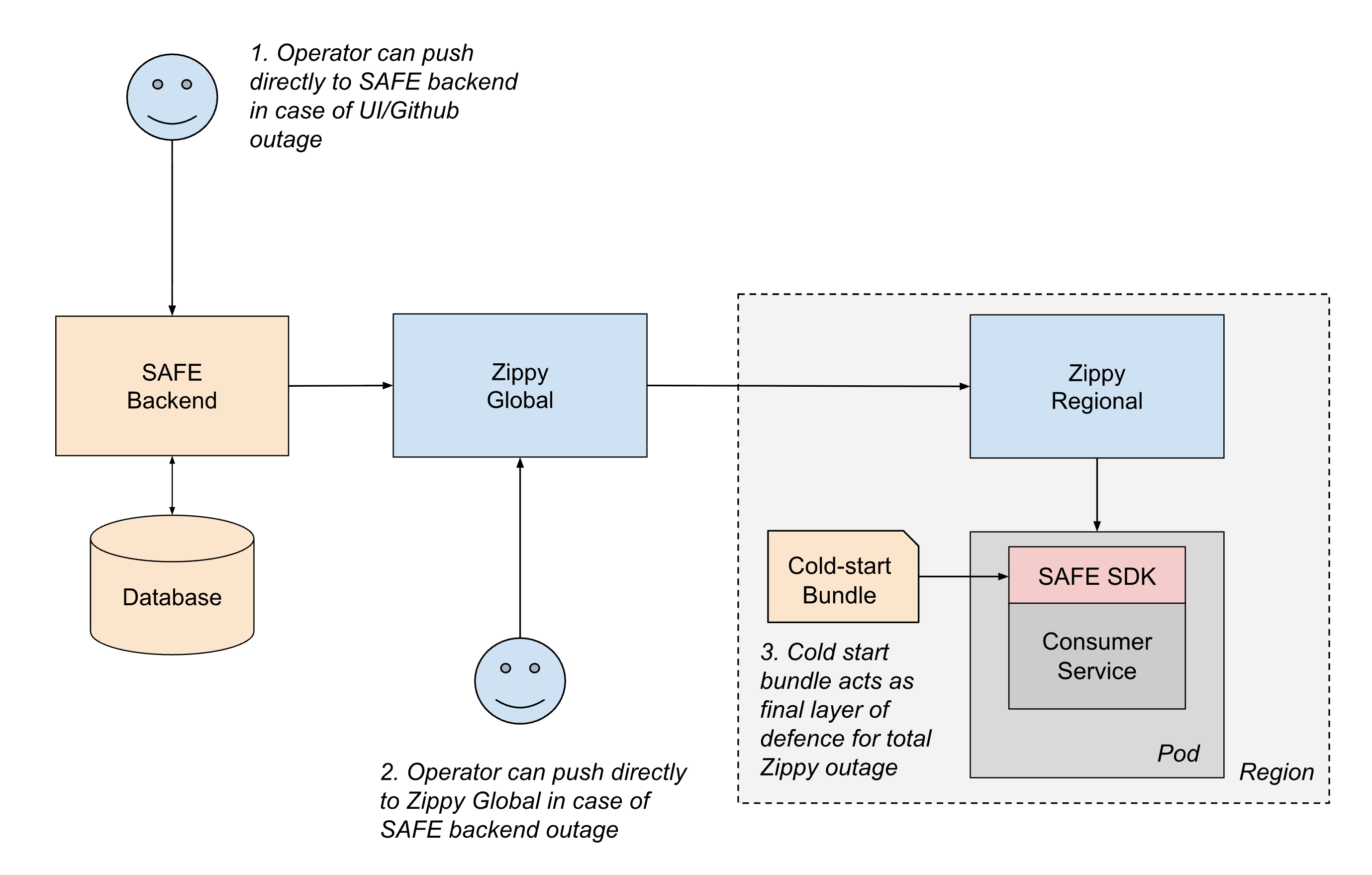
Within the SAFE SDK itself, defensive design ensures that configuration errors have limited blast radius. If a particular flag's configuration is malformed, only that single flag is affected. The SDK also maintains the contract of never throwing exceptions, and always fails open to the code default value, so application developers do not need to treat flag evaluation as a fallible. The SDK also immediately alerts on-call engineers when any configuration parsing or evaluation faults occur. Due to the maturity of SAFE and extensive pre-merge validation, such failures are now extremely infrequent in production.
This layered approach to resilience ensures that SAFE degrades gracefully, and minimizes the risk of it becoming a single point of failure.
Lessons Learned
Minimizing dependencies and layered redundant fallback reduce operational burden. Despite being deployed in and heavily used by nearly every compute surface at Databricks, the operational burden of maintaining SAFE has been quite manageable. Adding layered redundancies, such as the cold start bundle and the SDK's "fail static" behavior, has made much of the SAFE architecture self-healing.
Developer experience is paramount. Scaling the "people aspect" of a robust flagging system required a strong UX focus. SAFE is a mission critical system, often used to mitigate incidents. As such, building a user-friendly UX for flipping flags during emergencies was high leverage. Adopting a product-focussed mindset led to fewer papercuts, less confusion, and ultimately a lower company-wide mean-time-to-recovery (MTTR) for incidents.
Make "best practices" the low-friction route. One of our biggest learnings was that you cannot only document best practices and expect engineers to follow them. Engineers have many competing priorities when shipping features. SAFE makes the safe path the easy path: gradual rollouts require less effort and have more quality-of-life features available than riskier enablement patterns. When the system incentivises safer behavior, the platform can nudge engineers towards a culture of responsible change management.
Current State and Future Work
SAFE is now a matured internal platform within Databricks, and is widely used. The investments made into availability and developer experience pay dividends as we see continued reduction in both mean-time-to-resolution and blast radius production incidents through usage of SAFE flags.
As Databricks' product surface area continues to expand, the infrastructure primitives underlying those products expand in both breadth and complexity. As a result, there has been significant ongoing investment to ensure that SAFE supports all places where Databricks engineers write and deploy code.
If you're interested in scaling mission-critical infrastructure like this, please explore open roles at Databricks!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.