How Ontologies Help Nuclear Scale to Meet Global Energy Demand
Making implicit plant knowledge explicit and queryable for a fleet preparing to quadruple
by Dave Geyer, Mark Ghattas, Alex Hunt, Ben Mumma and Mark Gilbert
- The nuclear fleet is scaling toward 400GW under compressed licensing timelines. The plant context that experienced staff carry needs to be captured in a form that scales with it.
- An ontology encodes component identity, system relationships, and constraint sources into a structured layer that persists across outages, modifications, and staff transitions.
- Built on Databricks with open standards, the ontology supports configuration control, licensing evidence, and analytics from governed, versioned, auditable data.
Nuclear reactors are among the most complex engineered systems we operate at scale. Safe, reliable operation depends on tightly coupled physics, engineered barriers, rotating equipment, fluid systems, and control logic that has to behave correctly across normal operation and a long list of credible faults.
Consider the scenario: A feedwater valve closes unexpectedly. Within seconds, an engineer needs to know which downstream systems lose margin first, which Technical Specification limits become relevant, and whether the current plant lineup affects their options. The data to answer those questions exists across a dozen systems. The relationships that make the data meaningful live in the heads of experienced staff.
The gap between available data and usable knowledge defines one of the central challenges in nuclear plant operations today. An ontology closes that gap by making plant relationships explicit, queryable, and defensible.
The United States is entering a “nuclear renaissance” not seen in decades. Beginning in 2024, a wave of legislation and executive action created tailwinds for nuclear energy to power everything from national security installations to the massive energy demands of the AI race. The ADVANCE Act modernized the U.S. Nuclear Regulatory Commission (NRC) licensing process, lowered fees, and directed the Commission to evaluate brownfield sites, such as former coal plants, for new builds. Executive Order (EO) 14300 went further, fundamentally shifting the NRC's mission from risk minimization to weighing the benefits of nuclear energy for economic and national security, and compressing the current 42-month average licensing process into a binding 18-month deadline for new reactors. EO 14302 invoked the Defense Production Act (DPA) to reinvigorate the domestic nuclear industrial base, focusing on fuel supply chains and restarting shuttered plants. EO 14299 explicitly linked advanced nuclear deployment to AI data center demand, designating them as critical defense facilities to be powered by onsite reactors. Meanwhile, the U.S. Department of Energy (DOE) has funded U.S. nuclear companies with billions of dollars to accelerate progress on established plants and jumpstart newcomers building small modular reactors (SMRs).
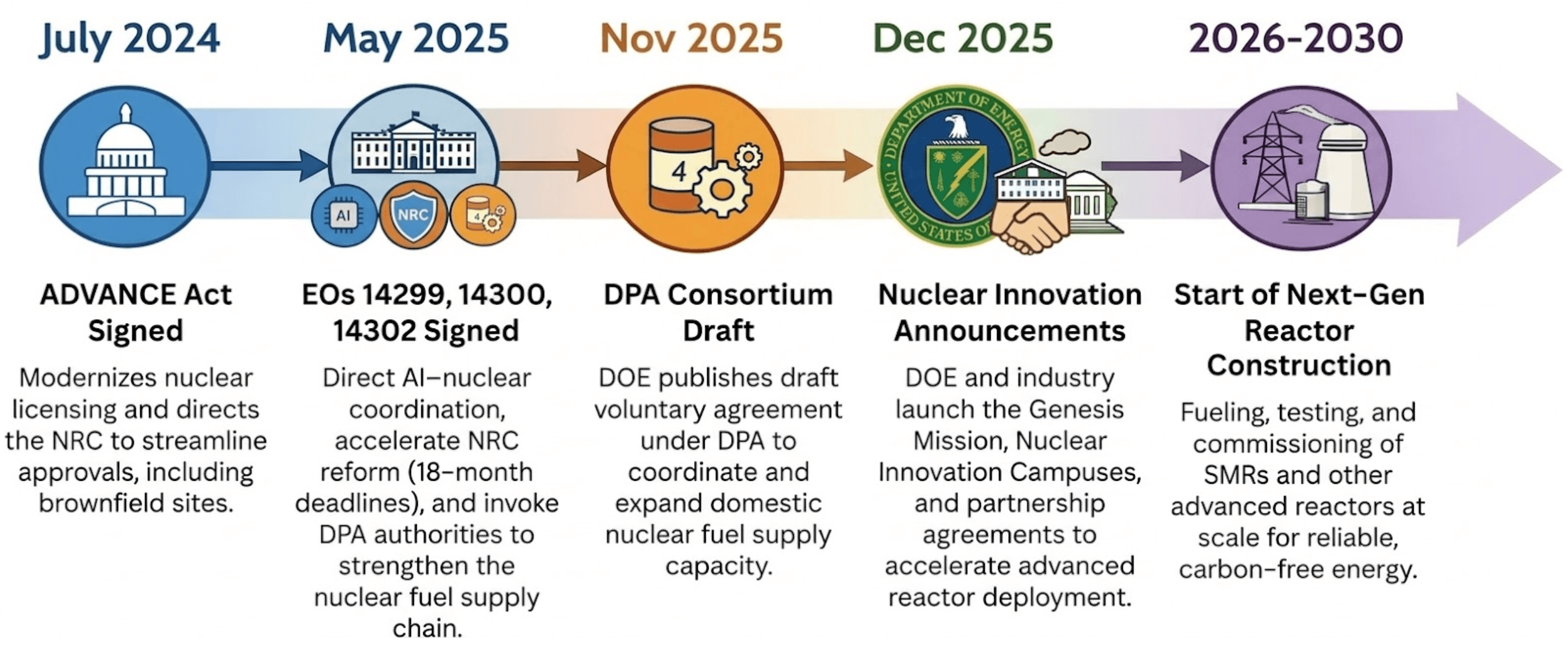
That expansion is landing on a workforce trending the other way. The number of people available to develop and defend licensing submissions is shrinking by about 10% annually, and the same pressure extends well beyond licensing. New designs, uprates, life-extension work, and digital upgrades all rely on the same chain of reasoning: what equipment is credited, which constraints apply in the current configuration, and which controlled sources support the conclusion. That chain runs through every phase of the plant lifecycle, from design through commissioning into daily operations. Today, it still depends largely on the people who carry it.
The cost of implicit knowledge
Experienced operators and engineers carry remarkable mental models of their plants. When a senior reactor operator sees rising vibration on a circulating water pump, they immediately connect that signal to the pump's role in the current lineup, known failure patterns for that equipment class, recent work history, and the consequences they'd expect if the condition progresses. They know which corroborating indications matter, which ones mislead, and what questions to ask next.
That mental model represents decades of accumulated context. It also represents a vulnerability.
The International Atomic Energy Agency (IAEA) projects global nuclear capacity could reach 992 GWe by 2050, roughly 2.6 times current levels. New builds mean new designs, more instrumentation, and more configuration states that operators and engineers must understand. Meanwhile, DOE workforce data shows experienced staff concentrated in older age brackets. The people who carry the deepest plant knowledge are retiring, and they're taking their mental models with them.
While newer staff bring technical aptitude, they often lack exposure to site-specific failure signatures and historical configurations. To optimize operations at a plant, both new and existing personnel require direct access to accurate, updated empirical data. This access enables the workforce to make informed decisions. Establishing this data availability supports DOE energy goals by preparing the workforce to manage high-instrumentation designs.
The way nuclear plants manage knowledge today has worked. It’s kept the U.S. fleet operating safely for decades. The engineers who carry plant context in their heads aren’t the problem to be solved, as they are an asset to be preserved and extended. Preservation isn’t enough when the mandate shifts from maintaining 100GW toward 400GW. The current approach can’t move at the speed the fleet requires today. Not because it’s wrong, but because it was designed for a different pace.
An ontology that closes the gap
The nuclear industry has recognized this problem, and several organizations are already working on it. Idaho National Laboratory built DeepLynx, an open-source integration framework designed to connect engineering tools and preserve context across the lifecycle. Their DIAMOND initiative developed data structures specifically for nuclear design and operational data. ISO 15926 and IEC 81346 established common frameworks for lifecycle data and equipment identification. NRC guidance on digital systems continues to push toward transparency, traceability, and performance-based evidence.
What these efforts share is a common approach. The approach starts by defining the objects a plant reasons about (systems, components, sensors, documents, constraints, licensing commitments) and then define how they connect. A pump belongs to a system. A sensor measures a variable on a component. A valve defines part of an isolation boundary. A component inherits qualification requirements from its installed location. A licensing commitment traces to the configuration assumptions that support it. That structure is an ontology.
Back to our aforementioned scenario, a single motor-operated valve replacement requires an engineer to pull from 6+ systems, reconcile 3 to 4 naming conventions and verify roughly 12 document revisions, which could result up to 4 to 8 hours. This work becomes ephemeral when the next question or issue about the same component resurfaces. Nuclear systems run on relationships and dependencies. An ontology makes those relationships explicit, searchable, and defensible. The relationships in a nuclear plant aren't tabular. A change to one component affects the boundary it supports, the train it belongs to, and the constraints it inherits. Graph structures map naturally to that kind of reasoning, but that doesn't mean you need a separate graph database. Ontologies encode these relationships as triples, atomic units that link two entities with a specific relationship. They also encode business rules directly into the structure standards, such as RDF (Resource Description Framework) and SHACL (Shape Constraint Language). Concrete criteria define what constitutes valid data, things like safety constraints, configuration rules, and qualification requirements. Those rules become part of the data model itself, so violations surface structurally rather than depending on someone catching them during review.
The ontology and its curated triples are the durable asset. They persist beyond any specific application or user interface. Open standards like RDF and OWL (Web Ontology Language) ensure the data stays portable, so the data aligns with existing industry ontologies and creates clean interchange formats for supplier data and licensing submittals. Nothing gets locked in. But the data still needs somewhere to be governed, versioned, and queried at scale.
For nuclear applications, the ontology needs to do three things well to be worth building.
- Canonical identity over time. The same pump might appear as "P-123" in work management, "P123_DIS_PRES" in the historian, and "P-123A" in drawings. The ontology resolves these to a single entity and tracks how that entity changes through replacements, modifications, and outages. You can answer "what is installed now" and "what was installed when we made that decision" from the same structure.
- Explicit relationships. Not just "this component exists" but "this component belongs to Train A, defines part of the containment isolation boundary, is measured by these sensors, and inherits environmental qualification (EQ) constraints from its location." The relationships that experienced engineers hold in their heads become visible and traversable.
- Explicit sourcing of asset constraints. When we have a valve with a specific leakage limit, it's critical to understand where that constraint comes from and why. An ontology traces this back explicitly to the specific technical specifications that underpin that constraint.
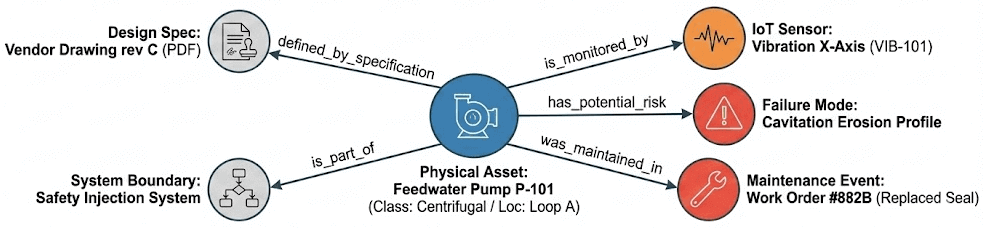
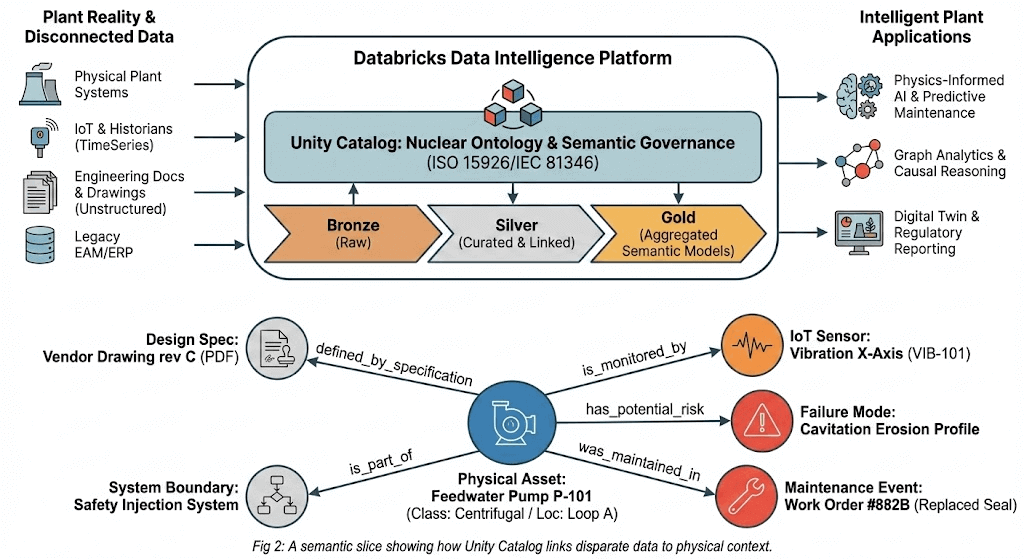{kind=link}
Working within nuclear's regulatory boundaries
Nuclear is one of the most heavily regulated industries in the world, and for good reason. A range of regulatory frameworks may apply, including export control rules such as the Export Administration Regulations (EAR) and Title 10 of the Code of Federal Regulations, Part 810 (10 CFR Part 810), as well as data protection and emerging AI governance requirements such as GDPR and the EU AI Act. These obligations can affect where analysis occurs, how evidence is stored, what information can be shared across borders or outside defined boundaries, and who can access it. Taken together, these regulations directly shape how digital infrastructure in nuclear is designed, deployed, and governed.
An ontology provides a way to separate structure from sensitive content. Plant relationships, constraints, and configuration logic can be defined and maintained as a distinct layer, separate from the operational data underneath. Engineers can work with the full relational context of the plant, querying how components connect, what constraints apply, and where those constraints originate, without the underlying operational data leaving controlled environments. Scenario libraries built on the ontology's structure can be versioned, reviewed, and shared as governed assets, grounded in real plant physics without exposing protected information.
For new builds, this is especially relevant. Design verification, vendor collaboration, and licensing analysis all involve multiple organizations exchanging technical information under export control scrutiny. An ontology lets you share the structure and relationships that support engineering decisions without distributing sensitive operational data or proprietary design details. Vendors, constructors, and operators can work from a common framework while each organization maintains control over its own protected information. That reduces the friction that typically slows down multi-party nuclear programs and helps keep first-of-a-kind designs on schedule.
For operating facilities, the same principle applies. You can develop and validate reasoning frameworks, train new staff on plant context, and prepare compliance packages without moving sensitive data outside appropriate boundaries.
A practical way to understand what an ontology does is to walk through a single workflow.
Use case: design validation and configuration control
Design validation and configuration control force the same question over and over: given the plant's current configuration, is this change acceptable, and can we prove it from controlled sources? Any time you touch a safety-related component, update a design input, substitute a part, or revise a calculation, you have to re-establish context across systems. What exactly is this component in this plant? Where is it installed? What safety function or boundary does it support? What requirements does it inherit from that location? Which documents control the work window? The data to answer those questions exists. The connections between the data usually do not.
Outages stress-test this. Equipment gets replaced under schedule pressure. Field work, procurement, and engineering review run in parallel. The mistakes that create real pain are rarely dramatic. They're quiet mismatches that surface late: a qualification basis that doesn't match the installed location, a drawing revision that wasn't current, an incorrect train assignment, a boundary assumption that changed, or an operating envelope limit pulled from the wrong source.
A common example is replacing a motor-operated valve on a safety-related line. Before an engineer can even evaluate the replacement, they have to rebuild the context: what system and train it belongs to, what boundary or credited function it supports, which EQ and seismic requirements apply at that location, what operating limits govern the component, and which controlled documents establish those limits.
Today, every step of that is manual. The engineer opens the work order for a tag number. Separately navigates to the drawing set for boundary context. Pulls up qualification and seismic files from another system. Tracks down the controlling calculations for operating limits and checks revision status. Each lookup is a separate system, a separate search, a separate judgment call about whether the information is current. Then the engineer synthesizes all of it in their head to determine whether the replacement is acceptable. If someone else asks the same question later, an inspector, a reviewer, or a different shift, the process starts over.
A plant ontology changes this by making the evidence chain part of the structure. The component has a canonical identity. That identity links to its installed location and configuration state, and from there to the requirements that follow: train assignment, boundary role, EQ and seismic constraints, operating envelope limits, and the authoritative sources that define them. The engineer starts from the component, and the relationships are already there. The full lifecycle record, design verification, procurement, manufacturing, testing, and shipping, is reachable from that single identity. Supporting quality documents like NDE reports, factory acceptance tests, and traceable references link directly to the component rather than sitting in separate systems waiting to be found.
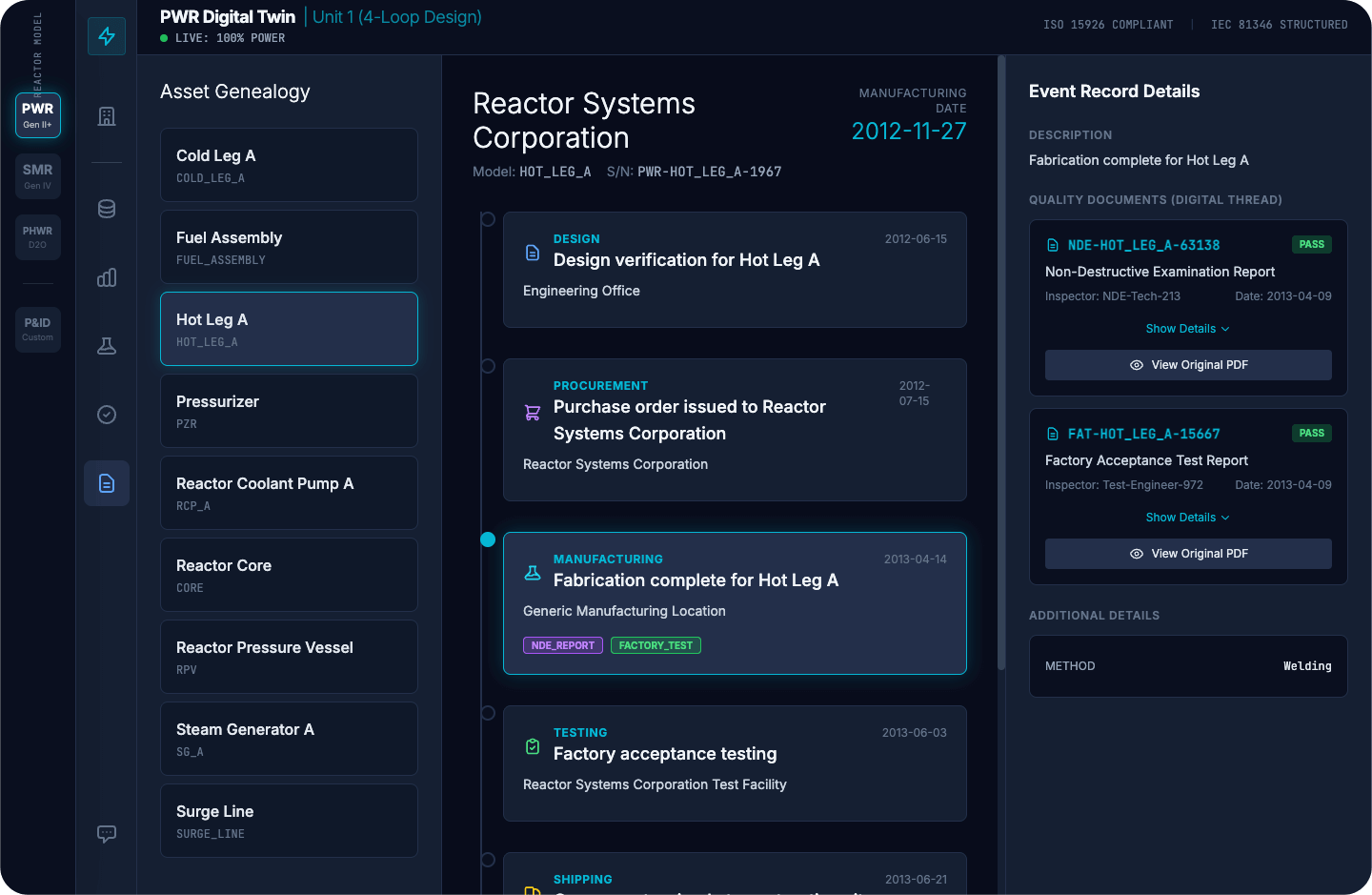
Because the constraints and their sources are encoded in the structure, tooling can be built that flags when something doesn't align, such as an incorrect EQ basis, an outdated revision, or a mismatched train assignment. The engineer still makes the call. The infrastructure gets them there faster and provides a complete picture, rather than a partial one assembled under time pressure.
Operating the ontology at scale
An ontology is only as useful as the platform running it. Relationships, identities, and constraints have to be governed, versioned, and queryable at scale. The platform has to stay aligned with the plant's actual state throughout outages, modifications, temporary alterations, and document updates, with auditability that holds up under inspection. If it can't do that, the ontology drifts, and people stop trusting it.
The ontology encodes plant relationships, constraints, and configuration logic in open standards. The platform that governs it needs to match that openness. If the governance layer is proprietary, it doesn't matter how portable the ontology is on paper. In an industry where a component's lifecycle record needs to be auditable by an operator, reviewable by the NRC, and traceable by an OEM across decades, the ability to share data cleanly between organizations and tools is table stakes.
Databricks is built on open formats and open interfaces. Ontology triples, component registries, relationship tables, and constraint records all sit on Delta Lake and are accessible from other tools. If you need to share subsets with a partner or regulator, the formats are standardized. Nothing is locked in.
On that foundation, four capabilities come up again and again in nuclear work:
- Unified governance. When QA or the NRC asks how a specific asset was controlled, the answer must be consistent across component identity, document control, relationships, and licensing basis references. That falls apart when each of those lives under a separate permission model. Unity Catalog provides a single governance layer across the entire ontology. Permissions, change tracking, and auditing apply uniformly across every asset, so there's one defensible answer rather than four partial ones.
- Time-indexed configuration. Engineering and licensing decisions depend on the plant state at a specific point in time. Under 10 CFR 50.59, plants evaluate whether a proposed change requires prior NRC approval by assessing its impact against the existing licensing basis. That evaluation is only as good as the configuration data behind it, and the same is true for operability determinations, setpoint basis questions, post-modification validation, and routine outage reviews. All of them require knowing what was installed and the controlling revisions at the time a decision was made. Delta Lake's time-travel capability supports as-designed, as-built, as-installed, and as-maintained views from the same underlying data, without requiring separate manual snapshots. Every table version is retained and queryable, so reconstructing the plant state at any prior decision point is a query rather than an archaeology project.
- Reproducible evidence chains. 10 CFR 50 Appendix B establishes the quality assurance requirements for safety-related systems, structures, and components. Having the right conclusion isn't sufficient if you can't reproduce the basis from controlled sources. Unity Catalog's automated lineage tracking captures which document revisions, constraint records, and relationship versions were used in a specific workflow. Delta Lake's audit log records every mutation to the underlying data. Together, when a reviewer or inspector needs to see what supported a decision, the platform provides a complete, timestamped answer rather than requiring someone to piece it together after the fact.
- Analytics on governed data. Governance, versioning, and lineage ensure the data is in a trustworthy state. The next question is what you can do with it once it's there. Databricks Lakeflow Jobs provide the orchestration layer for analytical pipelines that operate directly on the ontology's governed assets. MLflow tracks model versions, training data, parameters, and outputs with the same rigor that Unity Catalog applies to the data itself. Condition monitoring models can track degradation patterns across an entire valve class by pulling maintenance history, sensor trends, and design limits from the governed structure. Proposed changes can be screened automatically against the licensing basis because the constraints and their sources are already encoded. The models and their outputs trace back to controlled sources through the same lineage that the platform provides for everything else. That traceability is what separates analytics that inform decisions from analytics that can actually be credited in a regulated environment.
This connects directly to where DOE investment is heading. The DOE's Genesis Mission is building the next generation of digital tools for the energy sector, covering advanced simulation, digital twins, AI-assisted design, and operational analytics. The ontology and governed data you stand up today for configuration control and compliance are the same assets that those programs will build on. The infrastructure that reduces today's cycle time and rework becomes the foundation for what comes next. An open platform means the investment carries forward rather than requiring a rewrite when the requirements evolve.
Business and strategic implications
The value of an ontology compounds. Because the structure persists, the work done to resolve a component's context for one decision carries forward to the next.
For the existing fleet, plants are extending operations, taking on more complex modifications, and doing it with a smaller pool of experienced staff under tighter regulatory timelines. What used to take days of pulling from separate systems to assemble a conformance package can now be compressed into a structured query against relationships that already exist. Inspection-ready evidence bundles that used to require reconstructing the basis from memory can be assembled from the structure that's already in place. The percentage of assets with resolved canonical identity across data sources climbs steadily as the ontology matures.
For new builds, the advantages begin in the design phase and continue through licensing. If the ontology is in place early, the relationships between design intent, credited functions, and licensing commitments are structured before the first component ships. Constraint mismatches get flagged during design review because constraints and their sources are encoded in the structure. Without that, they're typically discovered during field installation, when the cost of correction is orders of magnitude higher. Licensing evidence assembles as the design matures rather than getting reconstructed after the fact. The result is fewer rework cycles, faster coordination among vendors and constructors, and lower costs to demonstrate safety. The safety standard doesn't change. The work required to show you've met it does.
Once the ontology is working for configuration control, it doesn't stay there. The same relationships that support a valve replacement also support the condition-monitoring program tracking degradation for that valve class. The same constraint lineage that feeds a compliance package feeds the licensing analysis for the next uprate. Because the ontology is built on standards-aligned identity and constraint lineage, it provides OEMs, engineering firms, and regulators with a common reference point rather than another system to integrate with.
That changes how new engineers come up to speed. Instead of building context by finding the right person to ask, they can query a component and see its train assignment, boundary role, constraint sources, and maintenance history in one place. Institutional knowledge becomes infrastructure rather than something that walks out the door with retirement. Experienced staff spend less time answering the same contextual questions and more time on the judgment calls that actually need their expertise.
If the fleet is going to quadruple in capacity and modernize at the same time, this is the kind of infrastructure that has to be planned early and carried forward.
Building the foundation for nuclear digital transformation
Ready to explore how ontologies can strengthen knowledge management and decision-making for the nuclear industry? Download the Databricks Solution Accelerator for Digital Twins in Manufacturing, accelerate your implementation using Ontos from Databricks Labs, or read How to Build Digital Twins for Operational Efficiency on the Databricks Blog to see the reference architecture in practice.
If you want to apply these concepts to your own systems, workflows, and governance constraints, reach out to your Databricks account team to discuss a scoped starting point.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.