Mitigating The Risk of Prompt Injection for AI Agents on Databricks
by JD Braun, Arun Pamulapati, Andrew Weaver, Nishith Sinha, Caelin Kaplan, Alex Warnecke and Jean Verrons
- Autonomous AI agents need sensitive data, untrusted inputs, and external actions to be useful, but combining all three creates exploitable attack chains.
- The Databricks Security team developed a practical guide to securing AI agents on Databricks using Meta's "Agents Rule of Two," a framework for mitigating prompt-injection risk.
- The guide covers nine specific layered controls on Databricks across data access, input validation, and egress restrictions to reduce prompt injection risks.
Overview:
Since we released the Databricks AI Security Framework (DASF) in 2024, the threat landscape for AI has shifted dramatically. AI has transformed from the stereotypical chatbot into agents that can reason, use tools, and take actions on behalf of users with little to no intervention. Security teams no longer just need to think about users interacting with models, they also need to think about a swarm of intelligent agents acting autonomously, interacting with services via MCP, and exploring the internet on their own.
Prompt injection was a known risk in the inference era, but it was largely contained to the user's request and response. With agents that can take actions autonomously, the risk has increased exponentially.
Consider a data professional who tasks their AI agent with writing a script that calls a third-party API. The agent searches the internet for documentation, drafts the code, and runs it. What the user doesn't realize is that the documentation page had a malicious prompt embedded in it, one that directed the agent to exfiltrate credentials from the user's compute environment to a webhook. Attacks like this are well-documented in practice. But there are frameworks that help us reason about when and why they succeed.
Recent industry research, including Meta’s “Agents Rule of Two” and similar models like Simon Willison’s “Lethal Trifecta”, highlights the conditions under which prompt injection attacks succeed. These patterns align closely with the controls defined in the Databricks AI Security Framework (DASF), which provides a practical model for securing AI agents operating on enterprise data.
Both arrive at the same conclusion: an AI agent becomes vulnerable to prompt injection when it has all three of the following characteristics, and to mitigate the risk, it should only be permitted two:
- Access to sensitive systems or private data
- Exposure to untrustworthy inputs
- The ability to change state or communicate externally
In practice, these risks map directly to the defense-in-depth controls defined in the Databricks AI Security Framework (DASF), which organizes AI security across data access, model interaction, and operational execution. In the sections below, we show how these risks can be mitigated using native controls on the Databricks Platform.
Understanding the Core Risks for AI Agents
As mentioned in the overview, Meta's Agents Rule of Two framework helps break down the core pillars that make AI agents vulnerable to prompt injection:
- Access to sensitive systems or private data: The agent can read or interact with sensitive user data.
- Process untrustworthy inputs: The agent can consume content supplied by external or attacker-controlled sources.
- Change state or communicate externally: The agent can take actions outside its local environment, such as making HTTP requests or modifying external systems.
When all three pillars are present, the system already has access to sensitive systems or private data (first), and an attacker can then inject malicious instructions through untrustworthy inputs (second), causing the agent to exfiltrate that data externally (third). In this section, we'll explore how each of these applies in the context of Databricks.
Pillar 1: Access to Sensitive Systems or Private Data
For an attacker to exfiltrate something valuable, the agent first needs access to it. This is the first pillar of the Agents Rule of Two, and in practice, it is almost never optional. Agents are most useful when they can operate on real, high-value data. They are increasingly used for tasks such as sentiment analysis on customer feedback, demand forecasting, fraud detection, or code assistance. To be effective, these agents are deliberately granted access to customer records, transaction histories, proprietary documents, or large internal codebases. In other words, the very data that gives organizations a competitive advantage is also the data that attackers are most interested in.
As a unified data and intelligence platform, Databricks is designed to centralize and process an organization's most valuable datasets. Applications and agents running on the platform are, by design, operating close to sensitive information. This means that in many real-world deployments, the first pillar of the Agents Rule of Two should be assumed to be present rather than treated as a hypothetical concern.
Pillar 2: Process Untrustworthy Inputs
The second pillar of the Agents Rule of Two focuses on how untrusted data enters the system. In the simplest case, this risk is obvious: an LLM chat interface can directly accept user input that contains malicious instructions. This is direct prompt injection, where the attacker supplies the payload explicitly as part of the interaction.
The risk, however, extends beyond direct user input. Agents and LLM-powered applications often retrieve and process data from external sources such as databases, documents, APIs, or knowledge bases. In these cases, malicious instructions may be embedded within otherwise legitimate content and only surface when the agent reads or reasons over that data. This is indirect prompt injection. The challenge is compounded by the fact that modern LLMs are designed to interpret a wide range of inputs, including natural language, structured data, special characters, images, and encoded payloads. This diversity makes malicious instructions difficult to detect using traditional input validation techniques.
On the Databricks platform, the diversity of data sources makes this particularly relevant. A single Unity Catalog table might contain transaction records from an order management system, support conversations between staff and customers, or product feedback submitted through a web form. When an agent is given access to that data, it is important to ask a simple but critical question: could any part of this data have been influenced by an external actor?
If the answer is yes, then the second pillar of the Agents Rule of Two is already in place.
In practice, this assessment is rarely straightforward. It often requires tracing data back to its original source and considering less obvious injection points, such as comments, free-text fields, metadata, or attachments, where malicious instructions could be embedded. What looks like ordinary business data may, from an agent's perspective, be executable guidance.
Pillar 3: Change State or Communicate Externally
The final pillar of the Agents Rule of Two focuses on what the agent is actually allowed to do, and therefore how large the blast radius of an attack can become. In early LLM applications, the model was effectively read-only. A user provided a prompt, the model generated a response, and that response was simply displayed. Even if an attacker influenced the model's output, the impact was generally limited to the text shown to the user, since the model had no ability to access private runtime data or execute actions.
Modern agents are fundamentally different. They are no longer limited to producing text, but can also change state through actions such as executing Python code or running SQL queries, and communicate externally by calling APIs or interacting with systems via mechanisms such as the Model Context Protocol (MCP).
On the Databricks platform, agents built with AI capabilities can easily be connected to MCP servers, user-defined functions, or external APIs. During the design phase, it's important to consider not just the intended use of these tools, but also their potential misuse. If a tool allows the agent to communicate externally or overwrite tables, the last pillar of the Agents Rule of Two is active.
As with the other pillars, building a complete picture of the agent's capabilities is not always straightforward. A tool that appears harmless at first glance may still be usable in unexpected ways. Developers therefore need to think in terms of effective capabilities, meaning what the agent could do under adversarial influence, not just the tasks it was designed to perform.
Putting It All Together
Taken individually, each of the three pillars may appear manageable. Prompt injection is less concerning if the agent cannot access sensitive data. Access to sensitive data is less risky if the agent has no ability to act on it. And powerful tools are less dangerous if the agent only processes trusted inputs. The risk becomes significant when these factors converge. Under those conditions, an adversary can influence the agent's behavior in ways that extend beyond its intended use, turning what appears to be a routine interaction into a security incident with real-world consequences.
From a defensive perspective, this gives us a practical design principle: try to break up the three pillars. In most real-world AI applications, it is difficult to remove any single element entirely. Agents need data to be useful, they need to process diverse inputs, and they often need tools to automate tasks. Still, there are concrete ways to contain the risk associated with each pillar.
On many AI platforms, these risks are addressed through a patchwork of tools spanning identity systems, network controls, model gateways, and data governance solutions. Databricks takes a different approach. Because data, AI models, and applications run on a unified platform governed by Unity Catalog and Agent Bricks, organizations can apply layered controls across the entire AI system �— from data access to model interaction to runtime execution — without introducing additional security silos.
The Databricks platform provides controls at each of these layers, which we'll explore in the following sections using a real-life example, our new AI agent: Social Gauge.
Controls for Prompt Injection Risks on AI Agents by Pillar
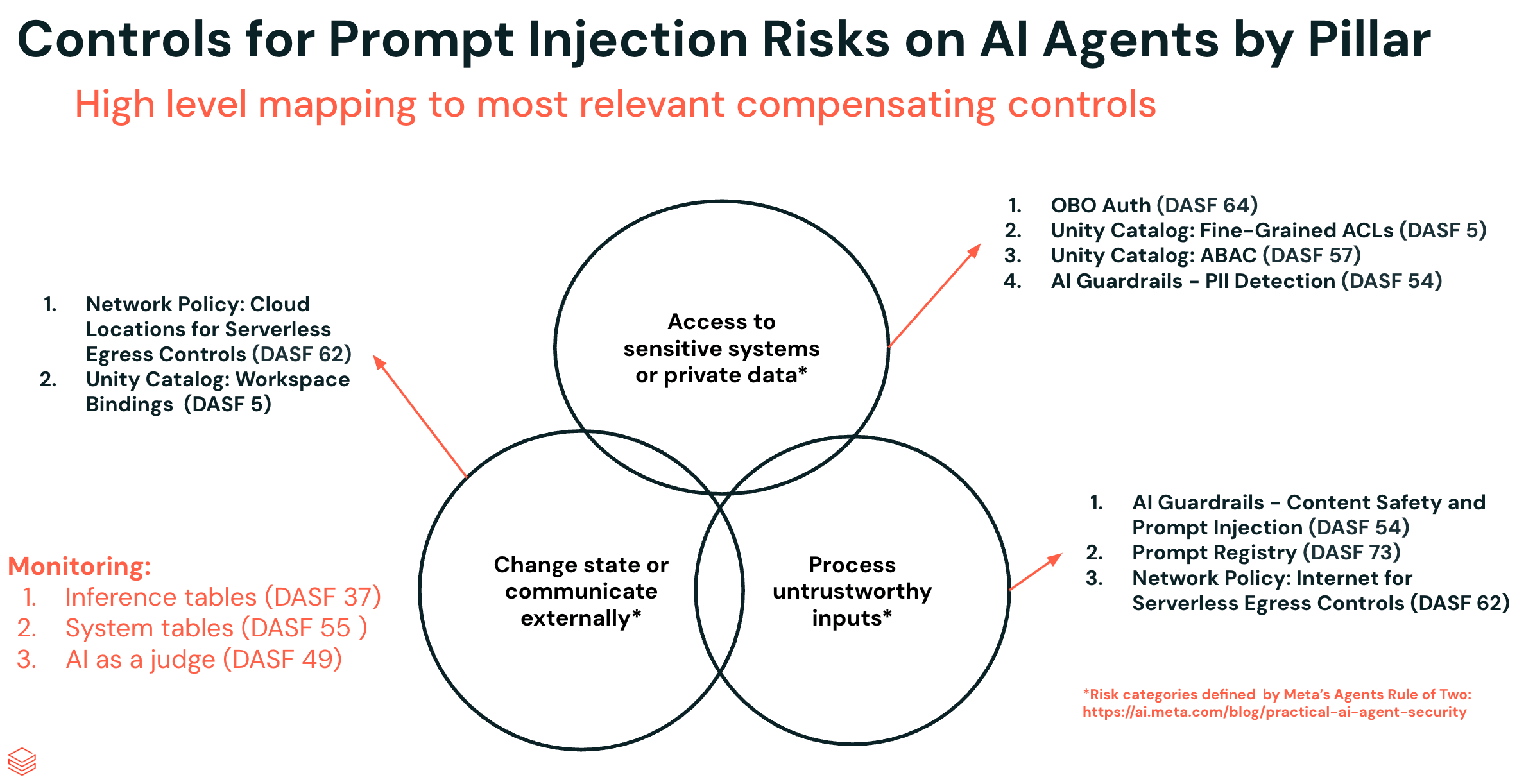
The most effective way to mitigate prompt injection is to remove one of the three pillars entirely- that remains true. But in practice, most agents need some degree of all three: access to sensitive data, exposure to external inputs, and the ability to take action. So instead of removing a pillar, the goal becomes hardening each one to shrink the attack surface.
We'll walk through nine controls across all three pillars using a running example: Social Gauge, an agent embedded in a Databricks App that pulls from social media and news sources, then combines that data with existing customer records governed by Unity Catalog. Think marketing teams tracking sentiment on product launches, finance teams consolidating quarterly coverage, or newsrooms monitoring wire services. For this walkthrough, we'll focus on a retail customer using Social Gauge to track user sentiment around new products.
With that context in place, as we examine each of the three pillars, keep the following attack scenario in mind:
- Social Gauge has access to sensitive financial data beyond what is necessary for its intended use.
- A social media post containing a prompt injection that embeds malicious instructions is ingested.
- Those instructions direct the agent to retrieve the out-of-scope financial data and either exfiltrate it externally or modify it within an internal schema to influence downstream decisions.
The controls we discuss in each section are designed to break, mitigate, or monitor this attack chain at different stages.
Pillar 1: Access to Sensitive Systems or Private Data - Controls
This pillar is nearly unavoidable. Agents are useful precisely because they operate on real data. Social Gauge needs to query customer records through Unity Catalog to answer questions like "Is there a reason my product sales dipped in January? Is it related to any customer sentiment?" Without that access, the agent can't deliver real insights.
In our attack scenario, the Pillar 1 risk is that Social Gauge has access to financial data beyond what is necessary for its intended use, leaving the agent vulnerable to indirect prompt injection that instructs it to retrieve this out-of-scope data. Since we can't eliminate this pillar, we want to constrain it, limiting Social Gauge's reach to only the data relevant to the user making the request.
Databricks is uniquely positioned to mitigate this risk because AI agents operate directly on governed enterprise data through Unity Catalog. This allows organizations to apply fine-grained access controls, policy enforcement, and data protection mechanisms consistently across both human users and AI agents.
On-Behalf-Of-User Authentication:
When building integrations with AI agents, customers can opt to use on-behalf-of-user (OBO) authentication for Databricks APIs. This means that when the underlying SDK is invoked to access data, it uses the permissions of the end user interacting with the agent rather than a service principal tied to the agent itself.
This should be the first step when building any AI application. It inherently limits permissions and prevents an over-permissioned agent from becoming a single point of compromise.
Unity Catalog - Fine-Grained Access Control Lists:
For OBO authentication to be effective, customers need fine-grained access control lists in Unity Catalog, ensuring that no user or workspace has access to data they shouldn't.
Privileges on securable objects are the access controls most customers will be familiar with. These dictate what actions a user can perform on a Unity Catalog securable — whether that's a catalog, schema, table, volume, or otherwise. For many customers, these settings are already in place as part of their governance strategy. See our documentation on best practices for Unity Catalog for more on managing permissions.
Unity Catalog - Attribute-based Access Controls (ABAC):
Fine-grained access controls work well when users fall into clearly defined groups like data engineers, analysts, or business users. But what about business users working across different business lines, or users based in different regions? That's where ABAC comes in.
ABAC lets you define policies once and apply them across catalogs, schemas, tables, and more. There are two policy types. Row filter policies automatically filter tables based on a user's attributes — for example, if a user is based out of EMEA, the table is reduced to only records from that region. Column mask policies mask sensitive columns unless a user belongs to a specific group, providing a straightforward way to reduce PII exposure.
AI Guardrails - PII Detection:
The controls above focus on limiting who can access what. But it's equally important to monitor what's actually being returned by the agent. Many customers use Agent Bricks AI Gateway as their central governance layer for AI access. Beyond unified model access, routing, usage tracking, and rate limits, AI Gateway provides guardrails like PII detection, automatically blocking or redacting sensitive data wherever it appears in the inputs or outputs of a model. This protects against scenarios where an agent is being manipulated into surfacing data it shouldn't.
Summary: Controls for access to sensitive systems or private data
With these controls in place, Social Gauge's exposure looks fundamentally different. Even if the agent is manipulated by a prompt injection attack, it can only reach the data that the requesting user already has access to, scoped to their region, masked where sensitive columns are involved, and monitored for PII on the way out. An attacker who compromises the agent doesn't inherit the keys to the kingdom; they inherit the permissions of a single user, with a guard watching the door.
Pillar 2: Process Untrustworthy Inputs - Controls
Databricks provides many platform controls that mitigate exposure to unauthorized external users: SSO with MFA, context-based ingress controls, front-end PrivateLink, or IP ACLs. But the risk of exposure to untrustworthy inputs doesn't end at the login screen.
Social Gauge's core function is searching the internet for social media posts and news articles about consumer products. That function opens it up to indirect prompt injection, malicious instructions embedded in otherwise legitimate web content. So while unauthorized users can't directly access Social Gauge's interface, the indirect attack surface is very much alive.
There's also the insider risk: users who attempt jailbreaking techniques to access data they're not supposed to see, repurpose Social Gauge for something it wasn't built for, or manipulate its analysis (e.g., "make up a source that says my product is doing amazing!").
In our attack scenario, the Pillar 2 risk is that a social media post containing a prompt injection is ingested, and the embedded malicious content is interpreted as legitimate instructions by the agent. This risk can be mitigated through controls that strengthen the agent’s handling of untrusted inputs.
AI Guardrails: Content Safety and Prompt Injection:
As we have seen, with Agent Bricks AI Gateway, there are several built-in guardrails such as safety filtering and PII detection that can be applied. These guardrails can be applied to either the input or output of an agent (or both). In addition to these built-in guardrails, you can also deploy custom models on Databricks Model Serving and leverage those. For example, the latest Llama Protection models are specialized LLMs that have been fine-tuned to detect prompt injections, toxic content, or code interpreter abuse. These models can act as a defensive layer around your agents, inspecting interactions before they turn into incidents.
To get a sense of how effective these guardrails can be, we ran a small experiment. We collected a few hundred malicious prompts from the Garak vulnerability scanner, an open-source tool developed by NVIDIA that integrates easily with Databricks for automated LLM security testing. From this dataset, we selected three common attack categories:
- Prompt Injections: Malicious instructions hidden in contexts like websites, translation tasks, or emails, designed to manipulate the model into unintended behavior.
- Jailbreaks: Carefully crafted prompts intended to bypass alignment safeguards and elicit harmful or restricted outputs.
- Downstream Injection Attacks: Prompts that attempt to make the model generate content that becomes dangerous only when interpreted by another system, for example, a malicious SQL statement that gets executed by an application, or a crafted Markdown image tag that exfiltrates sensitive data when rendered as HTML.
We then measured the success rate of these attacks against a baseline model, in this case a Llama-4-Maverick deployment. The results were clear. Without guardrails, a significant portion of the malicious prompts successfully triggered the targeted behavior. When a customized guardrail model (Prompt Guard 2 for prompt injections and jailbreaks, llama guard 3-8b for downstream injections) was placed in front of the model, the success rate dropped by more than 90% across all three categories.
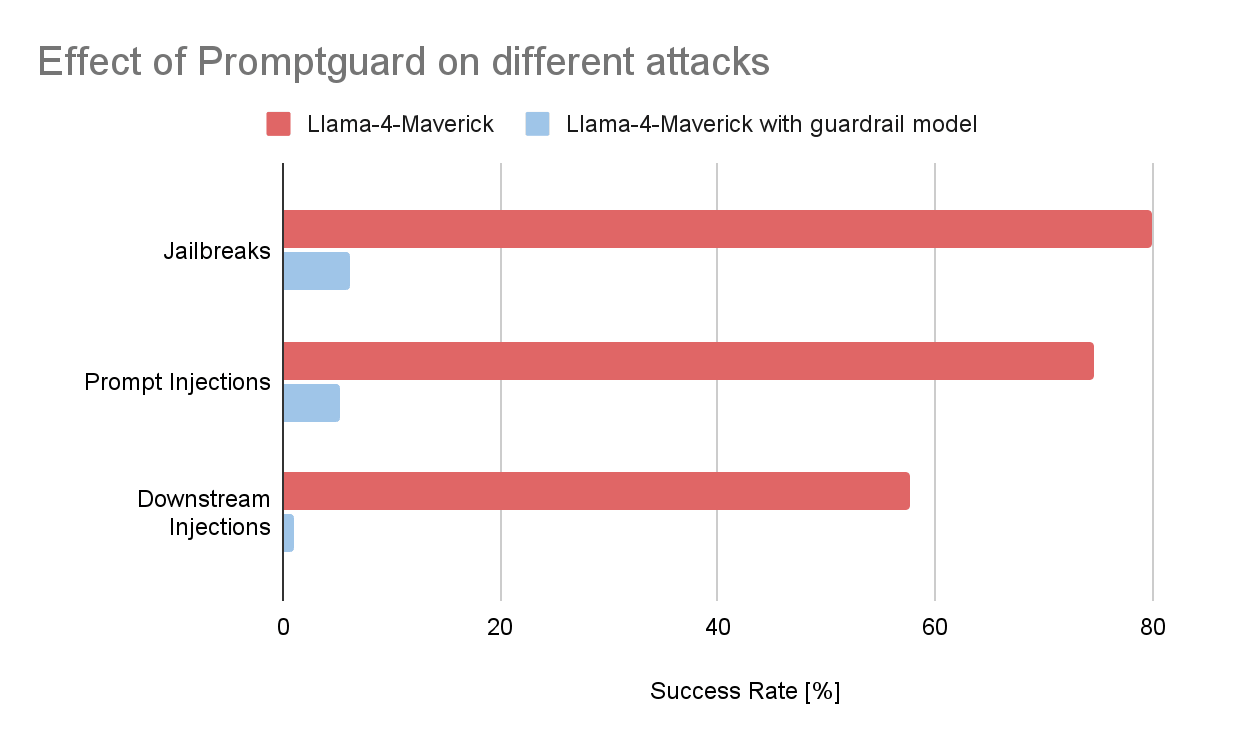
If you're interested in exploring additional guardrail techniques, open-source approaches, or state-of-the-art PII detection models, reach out to your Databricks representative to learn more about custom guardrail deployments.
Prompt Registry:
A well-crafted system prompt can sometimes be the difference between an attack succeeding or not, not as robust as a dedicated detection model, but worth getting right. MLflow Prompt Registry streamlines prompt engineering and management for GenAI applications, letting you version, track, test, and reuse prompts across your organization rather than cobbling them together ad hoc.
Summary: Controls for processing untrustworthy inputs
Social Gauge still reads from the open internet, that's its core requirement. But the surface area an attacker can exploit has narrowed considerably. Malicious prompts embedded in web content now have to survive a fine-tuned detection model before they reach the agent, and the system prompt is versioned and tested rather than thrown together on the fly. Neither of these controls are bulletproof on their own, but stacked together they turn a wide-open attack surface into something an attacker has to work significantly harder to exploit.
Pillar 3: Change State or Communicate Externally - Controls
In the final stage of our attack scenario, the Pillar 3 risk is that once the prompt injection is processed, the agent has the capability to carry out the malicious instructions, either by exfiltrating data externally or modifying it within an internal schema to influence downstream decisions.
Social Gauge augments existing data with third-party data for users investigating product performance, which means it inherently needs to write to catalogs, schemas, tables, and other objects. The underlying state is changing. We'll focus on three controls: restricting outbound network access, restricting access to external storage, and restricting state changes within Unity Catalog.
Serverless Egress Controls - Internet Locations:
Even if a prompt injection is processed by the agent, the resulting blast radius can be materially reduced by applying serverless egress controls through Databricks network policies. These let administrators define a deny-by-default posture for outbound connections from serverless workloads (including Databricks Apps), and then explicitly allow only the trusted destinations the agent actually needs.
By attaching a restricted network policy to the workspace running an agent like Social Gauge, you limit the agent's ability to reach arbitrary internet endpoints, shrinking the indirect prompt injection attack surface and reducing the risk of data exfiltration to unknown destinations.
Serverless Egress Controls - Unity Catalog Objects:
In addition to restricting access to known endpoints via FQDN filtering, the second capability of serverless egress controls is the ability to restrict access to cloud storage locations like S3 buckets. Buckets associated with the workspace, system tables, and sample datasets remain read-only by default, but this control goes further, it prevents an AI agent from writing to any non-sanctioned bucket, closing off one of the most common exfiltration paths.
Unity Catalog - Workspace Bindings:
Workspace-catalog bindings let customers limit access to catalogs from specific workspaces. This matters when developers can access data across multiple environments but that data shouldn't cross development boundaries. A data engineer might have permission to read production data, but they shouldn't be able to do so from a development workspace.
Since Social Gauge operates with OBO credentials, workspace bindings mitigate the chance that the agent inadvertently changes the state of production while operating in development.
Summary: Controls for change state or communicate externally
With serverless egress controls enforcing a deny-by-default posture on outbound connections and locking down external storage, and with workspace bindings enforcing environment boundaries, we've closed off the most obvious exfiltration and state-manipulation paths. Now let's talk about how to catch what slips through.
Monitoring your AI Agents for Security Risks
As mentioned above, customers can use Agent Bricks AI Gateway to manage and govern access to all AI models and agents across the enterprise, and this unification extends to observability and monitoring too. With AI Gateway, you can centrally log all inputs to and outputs from AI models and agents across your organization via inference tables, allowing you to use this data to monitor and audit AI requests and to enhance model performance and security.
Inference tables
You can use the query below to monitor your inference tables to see whether any of the built-in guardrails have been triggered. The query will extract which guardrail (input or output) was triggered, as well as which harmful categories were detected. Of course, where security is concerned, being proactive is always better than being reactive, so once you've validated the query, it's well worth taking the additional steps to configure it as an alert, automatically notifying you or your Security Operations Center (SOC) when something might warrant investigation.
System tables
In addition to inference tables, Databricks system tables contain a wealth of insight into the material events happening in Databricks. We've blogged in the past about how they can be leveraged to proactively monitor and alert on potential security threats and Indicators of Compromise (IoCs), and this can be extended to core security risks for AI agents. The query below, for example, can be used to monitor serverless egress control and whether someone (or some agent) is trying to bypass them in order to communicate externally.
AI as a Judge
Using AI as a judge is ubiquitous across the field of agents and artificial intelligence in general. In fact, most guardrail models are essentially LLMs that are fine-tuned and/or guided by specific system prompts to serve that specific purpose. As we mentioned above, it’s easy to deploy custom models on Databricks Model Serving, and we have examples of deploying most of the latest and greatest guardrail models such as Llama Guard 4 and Llama Prompt Guard 2 on Databricks. Beyond deploying them as custom guardrails, one of the benefits of the open, pluggable architecture of Databricks is that once you have logged a model using MLflow's generic mlflow.pyfunc flavor, you can leverage it in any number of different ways. Some examples include deploying them as batch Spark workflows or Spark Declarative Pipelines, calling them via SQL with ai_query, or even applying them in near real-time or micro-batch scenarios with Spark Structured Streaming.
In some cases, applying guardrails to every request or response may not be feasible. It's a perfectly valid scenario in which guardrails may interfere with the business goal or subject domain that the agent is operating within. Even if guardrails are not enforced, we can still monitor the safety of our agents by using their inference tables and a batch or streaming pipeline to classify potentially harmful content.
More Resources
The controls in this post are a starting point, not a finish line. Prompt injection risk evolves as agents get more capable, and the goal is a repeatable security program that keeps pace, this will not be a one-time hardening exercise!
These agent security patterns are also shaping the next evolution of the Databricks AI Security Framework. An upcoming update to DASF expands the framework to address autonomous AI agents, tool usage, and emerging prompt injection risks, helping organizations secure full AI systems, not just models.
We've organized the most relevant resources around three phases:
Define:
- The Databricks AI Security Framework (DASF) 2.0 offers a comprehensive risk analysis across 12 core components of AI systems, mapping to standards such as MITRE ATLAS, NIST, OWASP, and HITRUST. It provides 67 practical controls to reduce risks like prompt injection, jailbreak, and data exfiltration. DASF controls discussed in this blog:
- DASF 5: Control access to data and other objects
- DASF 64: Limit access from AI models and agents
- DASF 57: Use attribute-based access controls (ABAC)
- DASF 58: Protect data with filters and masking
- DASF 54: Implement AI guardrails
- DASF 62: Implement network segmentation
- DASF 37: Set up inference tables for monitoring and debugging models
- DASF 49: Automate LLM evaluation
- DASF 73: Register prompts
- DASF 55: Monitor audit logs
- The Databricks AI Governance Framework (DAGF) defines how organizations should govern AI systems across their lifecycle, from design and development to deployment and monitoring.
- Databricks Security Best Practice guides (for AWS, Azure, and GCP) provide a detailed overview of the main security controls we recommend for typical and highly secure environments, based on what we see working in partnership with our most security-conscious customers.
Deploy:
- Databricks Security Reference Architecture - Terraform Templates (SRA) enables deployment of Databricks workspaces and cloud infrastructure configured with security best practices.
Monitor:
- The Security Analysis Tool (SAT) helps security and platform teams quickly assess the security posture of Databricks workspaces.
- Databricks Detection Tool a series of opinionated detections, brought together in an easy to use notebook, that help you monitor activity on your workspaces.
Bringing these resources together gives your teams a pragmatic way to move from point-in-time hardening of a single agent to a repeatable, scalable security program for AI on Databricks, one that can keep pace with both your innovation and the evolving threat landscape.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.