The Emergence of the Composable Customer Data Platform
Learn how modern organizations are supercharging marketing efforts with a Composable CDP leveraging Snowplow, Databricks and Hightouch.
by Martin Lepka, Dan Morris and Alec Haase
This is a collaborative post between Databricks, Hightouch, and Snowplow. We thank Martin Lepka (Head of Industry Solutions at Snowplow) and Alec Haase (Product Evangelist at Hightouch) for their contributions.
There is no denying that one of the greatest assets to the modern digital organization is first-party customer data. The rapid rise of the privacy-centric consumer has led to a monumental shift away from third-party tracking methods. Organizations are now scrambling to implement a data infrastructure that, leveraging first-party data, can enable the personalized experiences that customers expect with every interaction.
Companies that want to engage customers effectively must build actionable intelligence on top of their first-party customer data. Actionable intelligence means improving their customer relationships, building consumer trust to capture rich first-party data, and utilizing that data to build intelligence that can be activated to continuously optimize the customer experience.
Historically, building a rich, behavioral data set of customer interest and intent was difficult. Using that data to make meaningful inferences and predictions about individual customers at scale, was even more challenging. And activating that intelligence, across a myriad of customer touchpoints and marketing channels, seemed almost unachievable.
Many companies turn to customer data platforms (CDPs) to help overcome these significant challenges. While cloud CDPs offer an off-the-shelf solution to collecting, cleaning, and activating customer data, adopting organizations have long since struggled with their rigid data models, long onboarding times and data redundancy across analytics and marketing tools. The CDP Institute's latest survey found that only "58% of companies with a deployed CDP say it delivers significant value" - leaving much to be desired from these packaged CDP solutions.
Thanks to the rise of the modern data stack and emergence of products like Snowplow, Databricks and Hightouch that offer best-in-breed alternatives to each component of off-the-shelf CDPs, the Composable CDP has emerged as a category-leading solution for modern organizations to manage their first-party data strategies.
In this post, we will discuss off-the-shelf CDPs, the rise of the Composable CDP, and how the latter can add transformational value to any modern organization.
What is a Customer Data Platform?
The definition of Customer Data Platforms has evolved numerous times since their inception in 2013. Gartner currently defines CDPs as "software application that supports marketing and customer experience use cases by unifying a company's customer data from marketing and other channels. CDPs optimize the timing and targeting of messages, offers and customer engagement activities, and enable the analysis of individual-level customer behavior over time."
The components of standard CDP offerings can be classified into the following categories:
- Data Collection: CDPs are designed to collect customer events from a number of different sources (onsite, mobile applications and server-side) and append these activities to the customer profile. These events typically contain metadata to provide detailed context about the customer's specific digital interactions. Event collection is typically designed to support marketing use cases such as marketing automation.
- Data Storage and Modeling: CDPs provide a proprietary repository of data that aggregates and manages different sources of customer data collected from most of the business's SaaS and internal applications. The unified database is a 360 degree view about each customer and a central source of truth for the business. Most CDPs have out-of-the-box identity stitching functionality and tools to create custom traits on user profiles.
- Data Activation: CDPs offer the ability to build audience segments leveraging the data available in the platform. Thanks to a wide-array of pre-built integrations, these audiences and other customer data points are then able to be pushed both to and from various marketing channels.
Evolutions of CDPs
The term CDP was first introduced by David Rabb, a marketing technology consultant and industry analyst in April 2013. The piece titled "I've Discovered a New Class of System: the Customer Data Platform. Causata Is An Example," introduced the term CDP to the market for the first time.
Tag management platforms were amongst the first to adopt this early definition of CDPs. In 2012, Google launched Google Tag Manager, a free tool allowing brands to manage their client-side web tracking. With a behemoth like Google releasing a free tool, household names in the tag management space no longer held the same value. They had to pivot their technology, focusing on data collection, a consolidated customer profile and activation through their integrations.
CDPs were at the time seen as a solution to help brands build towards a single view of their customer and activate the data either through integrations with other tools or natively within their own tool's platform.
So why aren't off-the-shelf CDPs the solution for every business? A root cause for many of the challenges that organizations face with their CDP implementations is that off-the-shelf solutions often promote the idea of sending data directly to the CDP. As a result, data engineers become frustrated with having to use data engineering tools that are native to the CDP, analysts and domain experts become concerned about having to manage audience segments in multiple places, and data scientists question how they will be able to use the value derived from the CDP for adjacent use cases, such as content optimization.
Compounding these issues, the CDP becomes a siloed copy of an organization's critical asset – customer data. The solution to these challenges is to think of the CDP as an extension of your broader data management strategy. In other words, extend the capabilities of your existing lakehouse to support additional use cases, instead of sending copies of your data to multiple places.
Introducing the Composable CDP
A Composable CDP consists of the same components as their off-the-shelf counterparts; Data Collection, Data Storage and Modeling, and Data Activation. By implementing a best-in-class product at each layer of the Composable CDP, organizations can achieve a far more extensible CDP solution that can solve problems well beyond the common use cases of off-the-shelf CDPs. Understanding each of these components allows teams to make the most informed architecture decisions when implementing their own Composable CDP.
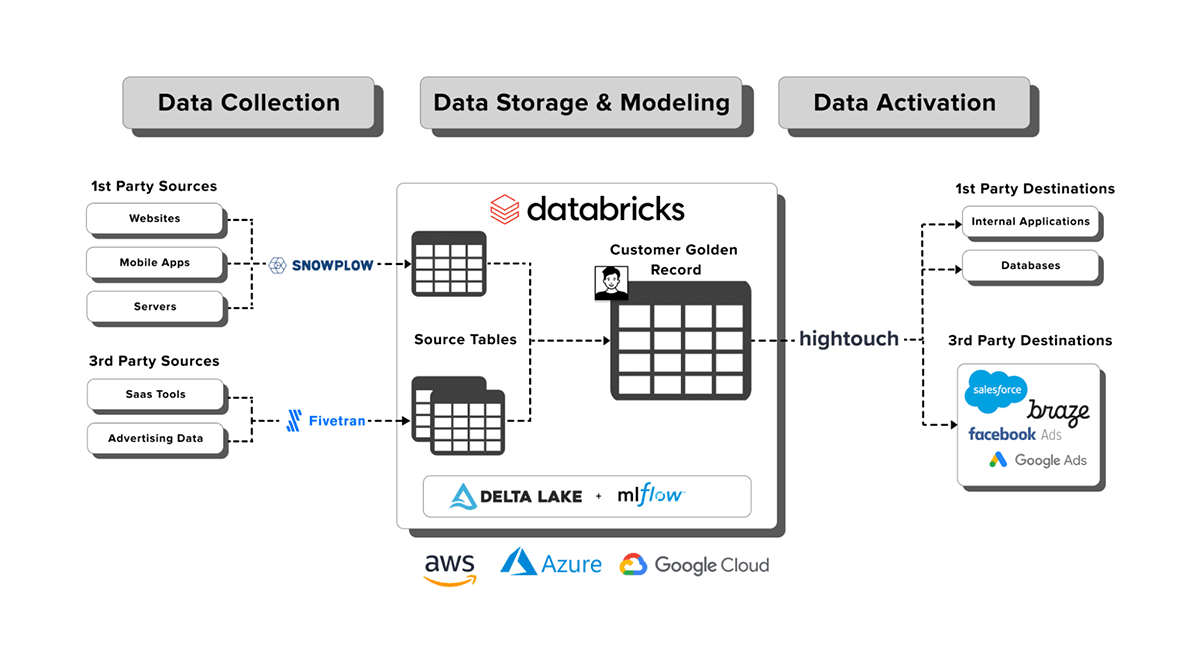
Behavioral Data Creation (Snowplow)
Behavioral data creation is the underlying foundation of the Composable CDP, providing a platform to power your personalized digital experience for your customer. Snowplow's Behavior Data Platform empowers data teams to manage end-to-end behavioral data creation with the delivery of BI and AI-ready data that is well-structured, reliable, consistent, accurate, explainable, and compliant, directly to your lakehouse.
To build a true single customer view you need to create data from across your digital platforms.
With Snowplow, data teams can define their own version-controlled custom events and entity schema, part of our Universal Data Language. Each event can also be enriched with an unlimited number of entities and properties creating data bespoke to your business and providing unlimited opportunities for activation.
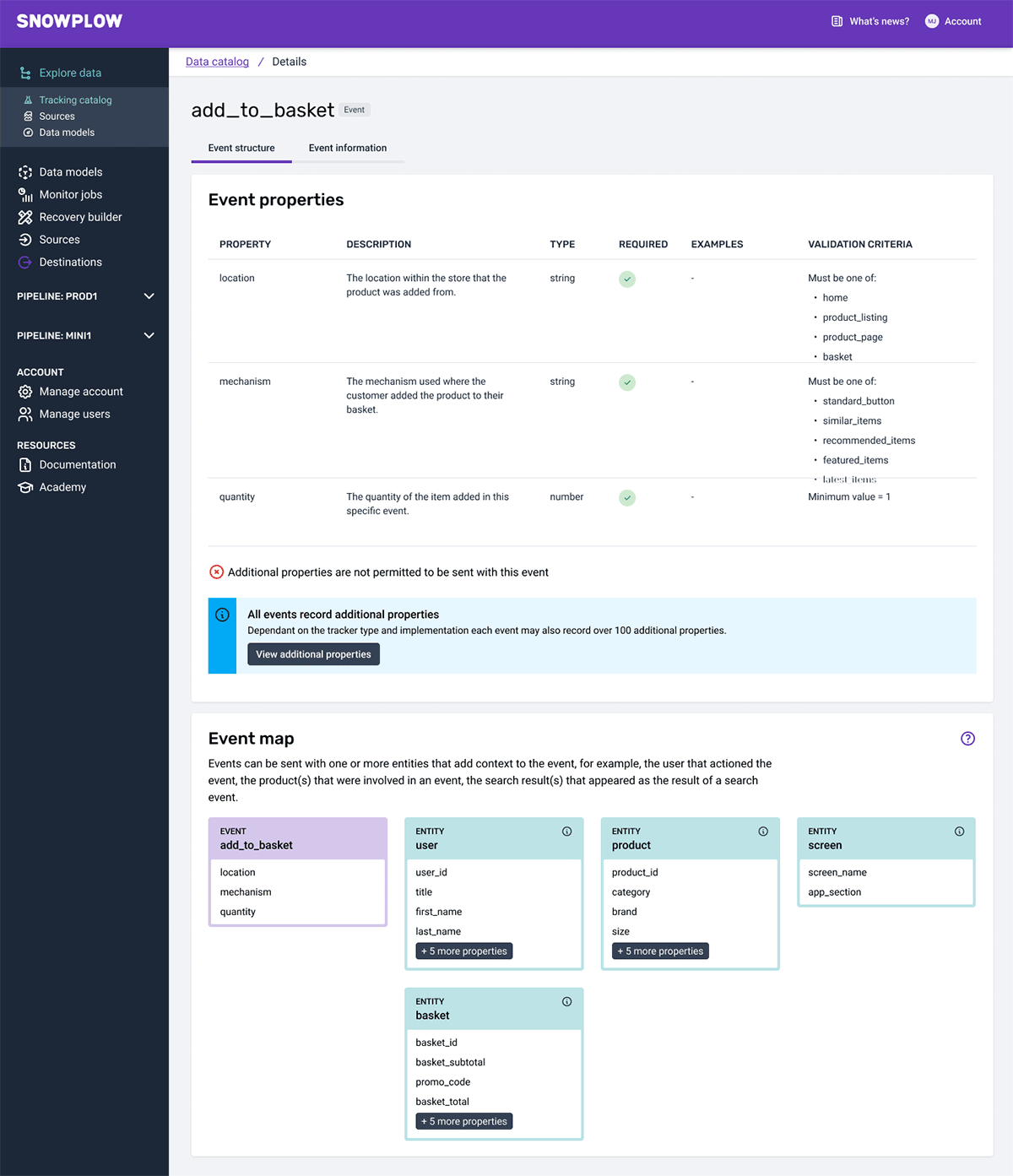
Accurate and compliant identification of users is the cornerstone of any CDP. With first-party user identifiers included with each event and in-stream privacy tooling, including PII pseudonymization, you have a complete, and compliant view of every customer interaction.
With data generated and enriched, behavioral data must be modeled with activation in mind. With Snowplow's private deployment model and native connector to Databricks, your unified event stream lands in real-time in the Delta Lake and is modeled at an interaction, session, and user level, creating your single view of your customer behavior without data wrangling - ready for identity stitching with other data sources.
Storage and Modeling (Databricks)
Creating and maintaining a single view of the customer delivers a tremendous amount of value for organizations big and small. Whether it's used by a marketing team to facilitate cross-sell/upsell opportunities or a product team to personalize the user experience, the value of this asset can and should be realized across all organizational boundaries. This can be achieved by using the Databricks Lakehouse Platform as the storage and modeling layer of your Composable CDP. The benefit of this approach is three-fold.
First, the Databricks Lakehouse Platform natively supports any type of data, whether it's batch or streaming, structured or unstructured. This means having a common way to work with all of your data, whether it's clickstream data streaming in from Snowplow, marketing data that is updated in batches from Fivetran, unstructured text data from a customer service tool, such as Zendesk, or otherwise.
Second, all of this data that you're managing in your lakehouse can be used directly for BI and ML/AI. For example, using Databricks SQL, return on ad spend for marketing campaigns can be easily analyzed using your BI tool of choice. Likewise, with MLflow and AutoML natively integrated into Databricks, data scientists can easily train and productionize models, such as propensity to churn, and then use the output of those models for activation via Hightouch.
Lastly, because the Databricks Lakehouse Platform is simple, open, and collaborative, the single view of the customer can be managed and governed in a consistent, and scalable way, for present and future use cases alike.
Data Activation (Hightouch)
Data Activation is the final piece of the Composable CDP. All business teams, from sales and marketing, to support and customer success, need relevant, accurate, and near real-time customer data to add critical context inside the software they already use.
Leveraging a technology coined "Reverse ETL," Data Activation platforms stream data out from the data lakehouse to any business application. Whether you're enhancing communications with customers via CRM, optimizing ad spend with audience targeting, or personalizing email/sms campaigns, Hightouch makes your data actionable - no scripts or APIs required.
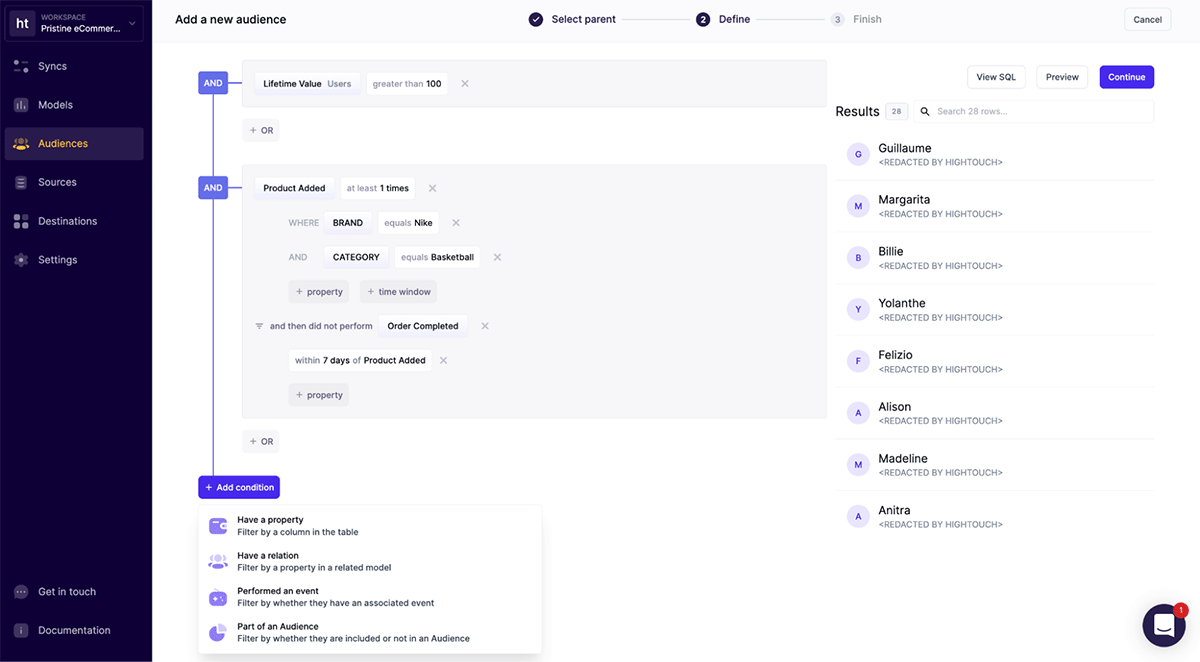
Thanks to Hightouch's easy to use audience and trait builders, marketing teams are able to centrally manage all of their cross-channel personalization and targeting efforts within the platform. Teams can connect Databricks as a Hightouch source, and in minutes, take action on their lakehouse data in any of their various downstream marketing tools.
"Data Activation is the method of unlocking the knowledge stored within your lakehouse, and making it actionable by your business users in the end tools that they use every day. In doing so, Data Activation helps bring data people toward the center of the business, directly tying their work to business outcomes." - Tejas Manohar, Co-founder of Hightouch
Benefits of a Composable CDP
By harnessing the power of best-in-class tooling to create a Composable CDP, there are four key benefits over an off-the-shelf CDP;
Better Data Governance
In today's privacy-conscious world and with ever-evolving data legislation, taking ownership and having full control of your customer data is paramount. Rather than an off-the-shelf CDP managing all of your customer data, a Composable CDP provides you with full transparency, assurance, and auditability at each step of your customer's data architecture.
Controlling what personally identifiable information is collected, how data is stored and modeled, and what data is shared with your marketing partners, ensures that you can comply with GDPR and CCPA and future legislation.
Better Results With Better Data Quality
Advanced personalization and segmentation of your campaigns rely on a consistent source of well-structured, reliable, accurate, explainable, and compliant behavioral data describing what customers are doing minute-by-minute. With a Composable CDP, you can determine the events and entities that match your business and decide how your data is modeled for activation.
Although behavioral data can be exported from an off-the-shelf CDP, in reality their data models were never intended to be used outside of their platform. CDP data exports from irregular table structures requiring complex joins and transformation before data can be activated.
With a Composable CDP, data science teams can directly leverage the behavioral data in your lakehouse, along with Databricks' enormous data processing capability, to build AI models specific to your data, product, or business goal instead of relying on the black box models offered by off-the-shelf CDPs. With greater model accuracy, you can create additional opportunities and revenue from your campaigns.
Future Proof and Modular by Design
Composable CDPs are future-proof by design, allowing you to avoid the vendor lock-in and one size fits all approach associated with off-the-shelf CDPs. With every element in a Composable CDP modular, you can choose the best-in-class collection, storage, modeling, and activation tools that fit the requirements of each of your teams. As the requirements of the business evolve you can continue to invest on top of your Composable CDP opposed to implementing a new stack from scratch which has high risk and cost to the business.
With a modular design, you also have the flexibility to determine your approach to identity resolution to ensure your team is able to deliver accurate and compliant marketing campaigns. Your business has complete control over how and when to stitch together user identities - leveraging every customer data point available.
Single Source of Truth Across Marketing and Other Teams
Instead of adding another data silo to the tech stack, teams can do more with the single source of truth they already have, their lakehouse. With the lakehouse as the single source of truth for the Composable CDP, all teams have access to the most comprehensive customer profiles and insights from across the business and can activate it through Hightouch with an easy-to-use UI and workflow.
The single source of truth also has applications outside just marketing use cases, it can also power other use-cases ranging from internal reporting to product analytics.
Getting Started
As we've seen, implementing an off-the-shelf CDP can be challenging, especially at an enterprise level. Because CDPs revolve around their customer database, product engineering teams must implement data collection by tracking user traits and events across various websites, backend services, and apps via CDP APIs and SDKs. Implementation can often take 3-6 months before marketing efforts can even begin.
The Composable CDP allows you to solve the most important problem in front of you incrementally-enabling you to choose the best solution and components for your business. You can educate yourself throughout the process and future-proof and swap out specific components down the line when your needs change or when a particular tool isn't "cutting it."
Thanks to the partnerships of Snowplow, Databricks and Hightouch, getting started with a composable CDP has never been easier. Snowplow's new Databricks Loader allows you to load directly into both Delta Lake and Databricks. To get started with Snowplow and Databricks contact us or deploy Snowplow Open Source. And with the launch of Hightouch on Databricks Partner Connect, Databricks customers can establish a secure Hightouch integration in just a few clicks.
Further instructions on how to get started with each of the market-leading Composable CDP tools can be found below. Additionally, you can attend Data + AI Summit 2022 in-person in San Francisco, June 27-30, and talk to experts at booth 323 (Hightouch) or 832 (Snowplow).
- Snowplow Getting Started: https://snowplowanalytics.com/get-started/
- Databricks Getting Started: https://www.databricks.com/try-databricks
- Hightouch Getting Started: https://app.hightouch.com/login
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.